-
困難重重的 x64
即使是做足了功課,還是敗下陣來... Orz
之前 Vista x64 用的都還不錯,直到加上 4GB 之後,才是惡夢的開始... 之前貼了一篇 6GB 很爽的 POST,之前插上去只偵測到4.8GB,想說小事情,一定是 BIOS Remap沒打開的關係,果然一開就是 6GB,一切正常,就貼了 POST ..
不過隔一兩天,想開個 MCE 來看電視,怎麼沒訊號? 查了半天確定線路都正常,才想到之前剛裝好不是都 OK 嗎? MCE 還列為重點測試項目之一,driver早都打聽好了,怎麼還會這樣? 就一個一個設定 rollback 試看看...
搞半天,問題出在想都沒想到的地方... 我的 TV 卡,在Vista x64開了Memory Remap後就會出問題了。Device Manager沒有任何異狀,但是MCE就一直說訊號微弱... 跟本沒辦法看. Memory Remap 關掉就正常了。寫Mail去圓剛跟華碩的客服反應,果然再怎樣還是要買大廠的...
ASUS 有回,不過沒用...
圓剛? 沒人鳥我...
雖然切回 4.8GB 還是戡用,不過多買的 4GB 只能當 2.8GB 不到,感覺有點鳥... 加上裝了 X64 有一半以上的軟體都是 X86 ... 看起來實在有點礙眼... 其實現階段用 X64 也是有些缺點的,第一就是很多軟體及 DLL 都要分兩套, x64 + x86,很佔空間。第二,一樣的程式 x64 吃的 memory 比較多,為何? 每個 Pointer 都多兩倍空間... 多少都會有影響... 第三,幾乎用到 COM 元件的都得靠 WOW,效能有點下滑... 所以暫時還是換回 x86 版了.
換回 x86 vista 後第一件事就是試試電視卡,在 x86 mode 下開不開 REMAP 就都正常,看來 Driver 要負一點責任,不過工作忙,暫時就不理它了,下次擇日再挑戰一次 x64. Ram 裝太多果然還是有一堆問題,新問題是我的主機板 (ASUS P5B-E Plus) 如果開了 BIOS Remap,進 Vista 後只能看到 2048MB Ram @_@,關掉反而還有 2.8GB... 搞什麼飛機...
又是搞了半天,確定無解,網路上很多人跟我一樣... 本想就讓它 2.8GB 吧,不過又讓我發現了個評價不錯的 Ram Disk 軟體: "Gavotte Ramdisk"
評價不外呼是免費,沒有容量限制,很穩定等等,不過它有個特異功能倒是 RAM 插太多的人要試試... 它可以把像我這樣失去的 RAM 挖回來用!!
真的蠻神奇的,只要 Vista 起用 PAE (Physical Address Extension),這套 RAM DISK 就能自動把 OS 不會抓來用的 RAM 當成 RAMDISK. 不過不開 BIOS Remap 就沒輒... 因此當場我的組態變成: RAM: 2GB, RamDisk: 4GB ...
真的是 Orz,我要那麼大的 RamDisk 幹嘛? 像網路一堆人把 Page File 放到 RamDisk 上的作法又覺的有點蠢,雖然很多時後非得要 Page File 不可,不過把 RAM 不夠時某些 RAM 的資料搬到 DISK,而這 DISK 又是 RAM 模擬的,感覺就像是做了一堆白工... 算了,拔掉 2GB 吧,剩下 2GB 就當 TEMP 用,可以塞 TEMP 的就塞過去..
看起來 x64 還是小問題多多,沒那個人生跟他耗的話,還是過一陣子再試試吧,反正照這情勢,RAM很快就會漲到不得不換 X64 的地步了,往好的方面想,這應該會加速廠商移到 x64 的腳步吧? [H]
-
爽一下, 6GB RAM ...
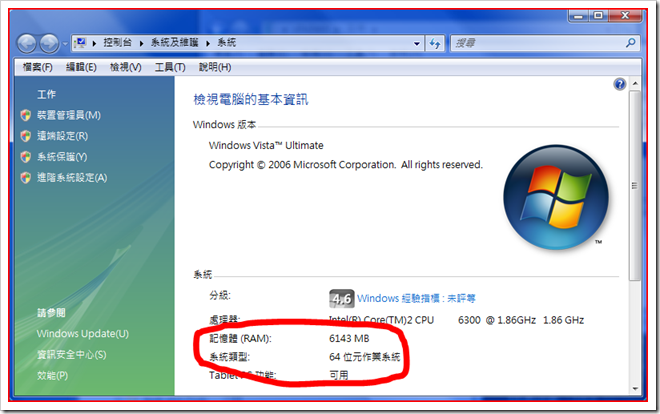
哇哈哈, 雖然現在RAM便宜到翻掉, 不過要突破4GB的先天限制, 還真花了不少功夫... 不想用 Server 版的 OS, 也不想用 PAE 等等其它不乾不脆的方式, 走的是換 64 Bits OS 這條路, 總算成功了, 當然要貼來紀念一下.
原本有 2GB RAM, 想趁過年加個 4G 來用用... 過年期間跑了光華商場, 無奈帶了小皮問了好幾家店, 每家都說沒貨 @_@, 說是大盤過年前一周就因為盤點, 都停止出貨, 買不到 2GB DDR2 ... 只好等過完年了...
回想才幾年前, 想說4GB這麼大, 對於當時的RAM容量 (4MB算很奢侈了) 跟本是天文數字, 跟本沒在想那天 RAM 超過 4GB 怎麼辦... 沒想到現在隨便就超過了... 我看未來會帶動 x64 升級的理由不是效率也不是安全性... 完全只是為了能用超過 4GB 的 RAM 吧... 反正 RAM 這麼便宜...
扯遠了, 這篇純脆是突破多年來的限制, 紀念一下而以 [H], 想敗的人快點去敗吧, 很值得的... [:D]
-
再度換裝 Vista ... Vista Ultimate (x64)
暨之前升級到 VISTA 的經驗, 到最後不適用又換回 XP 到現在, 差一個月就一年了 (真久), 這陣子因為陸陸續續解決掉一些問題, 加上一些誘因, 不得不換到 VISTA, 於是又再度換了一次...
這次會想換, 主要有幾個原因:
- 因為硬碟滿了, 過年前買了顆 750G 的新硬碟, 可以有辦法裝新 OS 而不影響到舊系統
- 想加 RAM, 不過原本已經是 2GB 了, 32 位元的系統 (XP) 再加上去效益不大, 想直接換到 64 位元, 個人用我也不大想換 server 版的 OS, 不大好用. 可用的 memory 雖然能突破 4GB, 但是它終究是 32 位元的系統, 對於記憶體的使用仍有一堆限制, 換成 x64 才是正途.
- 原本用的是 XP MCE2005, 如果要保有 MCE 的功能, 又要64位元, 那只剩 Vista x64
- Canon Raw Codec 已推出, 常用的轉檔作業都已經用 .NET Framework 3.0 改寫完成, 加上先前在 VM 試過, 可以初步解決 Canon Raw Codec 不支援 x64 的問題. 過去的障礙已經排除
- 想開始研究一下 IIS7, Win2008 還太遙遠, 直接用現成的 vista 比較快
- 家裡大人已經用 vista 好一段時間了, 看她用也沒啥問題...
- 內建的東西夠多, 我是只要內建的堪用就會用的人... 內建 DVD codec, 基本的 Video DVD 編輯程式對我還蠻有用的
- 雖然 Vista 沒啥重要的大改進, 但是每個小地方的改良加起來也不少
- Tablet PC 功能. 前陣子弄了塊陽春的數位板, 可以直接用現成的 for Tablet PC 軟體. 又是跟 MCE 一樣的例子, 過去是有特定版本的 XP, 沒辦法同時保有 Tablet PC / Media Center / x64 等好處, 只有換 Vista 一途...
- 雖然 Vista 預先載入你常用 AP 的功能常被罵到臭頭, 但是我倒是不介意多餘的 RAM 先拿去當 Cache 使用. 幾個常用的大型軟體, 在 Vista 下載入的速度還真的快很多, 雖然是錯覺, 但是至少也是有用到...
- 過去 Visual Studio 2005 在 Vista 上有些小問題 (要加裝 patch), 在 x64 下問題更多... 尤其是 debugging 時. 現在 Visual Studio 2008 出來, 這類問題都解決的差不多了
- Vista SP1 快出了, 時機應該成熟了, 預先準備一下...
- 最重要的原因: 都買了正版 Vista 了, 放著不用是怎樣... [H]
補充個事後才發現的好處, Vista Complete PC 是內建的磁碟備份工具, 類似 GHOST 那樣, 是把你整顆硬碟做成映像檔. Microsoft 當然用它推廣的格式 *.vhd, 正好跟我常用的 Virtual PC / Virtual Server 的格式一致. 多好用? 簡單在 Vista 內點兩下就可以做 Disk Image, 以後需要的話可以直接用 Vista DVD 還原, 就像 GHOST 一樣. 或是直接用 Virtual Server 2005 R2 SP1 附的工具: VHDMOUNT, 直接掛起來用 [Y]
另外一點也要特別提一下. 原本搜遍了 GOOGLE, 得到的答案清一色都是 Canon Raw Codec 不支援 Vista X64. 官方說法跟使用者討論都是這樣. 我是硬著頭皮先在 VM 裡試了一下, 耶? 至少還可以安裝上去. 不過果然不行. 我自己寫的轉檔工具不能用, 如預期的找不到對應的 Codec. 在 Windows Live Gallery 及檔案總管下也不能直接看到 .CR2 的縮圖...
不過想到過去跟 X64 + WOW (是 Windows On Windows, 不是魔獸世界) 奮戰的經驗, 其實 Microsoft 做的 32 位元回朔相容作的還不錯. 只是有一個大前題: 32 / 64 兩種 CODE 不能混在一起執行. 同一個處理程序 (Process) 內必需都是 32 或是 64 位元的 code. 第一個碰到這種問題的就是各式軟應體的 driver. 硬體的就不說了, 軟體的像一堆 "虛擬" 裝置, virtual cdrom, virtual disk, virtual network adapter ... 等等. 第二個碰到的就是各式的 DLL, 它本來就是讓你載入到你的 Process 內使用的, 像一堆 ODBC driver, COM 元件, ActiveX Control, Video Codec, 加上 WPF 使用的 Image Codec, 都在此列. 這種才是真正的問題, 就像 Microsoft 可以把 IE 重新用 64 位元改寫, 但是它無法替所有的 ActiveX Control 改寫為 64 位元, 因此未來的五年內, 光是 IE 這東西, 你大概還是甩不掉 32 位元版本...
這類相容問題通常都是整套用 32 位元版本就可以解決, 就像 IE 你只要開啟 32 位元版本的話, 即使你是在 x64 OS, 也不會有太大問題. 32 位元的程式在 64 位元 OS 下執行, 還附帶了一些額外的好處. 記憶體管理就佔了不少便宜. 光是記憶體各種管理的動作就快很多 (以前看過相關文章, 不過找不到了 [:P], 下次寫 code 來測看看), 加上 32 位元的基本限制: 4GB memory size, 因為 OS 已經是 64 位元了, 4GB 可用的定址空間不用再切 2GB 給 OS 使用... 因此你的程式可用的定址空間也從 2GB 擴張到 4GB, 不無小補.
想到這些案例, 我就試了一下... 我自己寫的歸檔工具不能跑, 如果我把它切到 32 位元模式呢? 改了改 compile option, target platform 從原本的 "Any CPU" 改為 "x86", 耶! 可以了耶... 程式能正確的抓到 Canon Codec, 並且正確的解碼跟抓到 metadata.
再試一下 Windows Live Gallery, Microsoft 還算有良心, 裝好後就有兩種 32/64 版本. 我開了 32 位元版, .CR2 的照片也都可以正確顯示.. 哇哈哈... 讚 [Y]
不過 Windows Live Gallery 有些地方要注意, 它似忽載入後會留著, 類似古早的 OLE server 一樣的技術, 跑起來後就會留在系統內, 待下次有人要執行時繼續使用. 因此如果沒有在 BOOT 後第一次就開正確的版本, 以後就有可能你開 32 位元版, 它還是跑 64 位元的給你看...
這個問題可以解決, 算是讓我願意換 Vista x64 最主要的原因, 不然我大概會傻傻的等到 Canon 好心的推出 64 位元版的 codec 才換吧 [H], 這次升級 Vista 應該不會再像上次一樣, 用一用就換回去了... 想換 x64 的人就不用再撐了, 上吧!!!
-
MSDN Magazine 閱讀心得: Stream Pipeline
前一陣子研究了幾種可以在 .NET 善用多核心的作法之後, 最近剛好又在在 MSDN Magazine 看到這篇不錯的文章: http://msdn.microsoft.com/msdnmag/issues/08/02/NETMatters/default.aspx 裡面點出了另一種作法: 串流管線 (Stream Pipeline)...
如果你是以多核心能有效利用為目標, 那這篇對你可能沒什麼用... 不過如果你要處理的資料必需經過幾個 Stream 處理的話, 這篇就派的上用場. 這篇是以一個常見的例子為起點: 資料壓縮 + 加密...
在 .NET 要壓縮資料很簡單, 只要把資料寫到 GzipStream 就好, 建立 GzipStream 時再指定它要串接的 FileStream 就可以寫到檔案了 (串 Network 就可以透過網路傳出去... etc), 而加密則是用 CryptoStream, 也是一樣的用法, 可以串接其它的 Stream ...
正好利用這個特性, 資料要壓縮又要加密, 可以這樣作:
(single thread) [INPUT] --> GzipStream --> CryptoStream --> [OUTPUT]
不過那裡跟多核 CPU 扯上關係? 因為壓縮跟加密都是需要大量 CPU 運算, 這樣的作法等於是只用單一 thread 來負責 Gzip 跟 Crypto 的工作. 即使透過串接 stream , 動作被切成很多小段, 壓縮一點就加密一點, 但是仍然只有一個 thread... 再忙也仍然只有用到單一核心, 除非等到未來改板, 用類似上一篇 [TPL] 的方法改寫的 library 才有機會改善...
作者提出另一個觀點, 這兩個 stream 能不能分在兩個 thread 各別執行? 弄的像生產線 (pipeline) 一樣, 第一個作業員負責壓縮, 第二個作業員負責加密, 同時進行, 就可以有兩倍的處理速度... 答案當然是 "可以" ! 我佩服 Stephen Toub 的地方在於他很漂亮的解決了這個問題, 就是它寫了 BlockingStream 就把問題解掉了, 乾淨又漂亮... 真是甘拜下風.. 這也是我為什麼想多寫這篇的原因.
之前在念作業系統, 講到多工的課題, 有提過 "生產者 / 消費者" 的設計, 就是一部份模組負責丟出一堆工作, 而另一個模組則負責把工作處理掉. 如何在中間協調管控就是個重要的課題. 生產的太快工作會太多, 因此多到某個程度就要降低生產者的速度, 通常就是暫停. 消費者消化的太快也會沒事作, 就需要暫停來休息一下等待新的工作. 而消費者這端如果是用 thread pool 來實作, 就剛好是 [上篇] 提到的動態調整 thread pool 裡的 worker thread 數量的機制. 工作太多會動態增加 worker thread 來處理, 工作太少就會讓多餘的 worker thread 睡覺, 睡太久就把它砍了...
而這次 Stephen Toub 解決的方式: BlockingStream 則是處理生產者跟消費者之間的橋樑. Stream 這種類型, 正好是身兼消費及生產者的角色. 他舉了郵件處理的例子. 如果你有一堆信要寄, 你也許會找一個人把卡片折好, 放進信封貼郵票. 這些動作由一個人 (one thread) 來作, 就是原本的作法. 生產者就是那堆要寄的信件, 這個可憐的工人就是要把這些信裝好信封貼好郵票的消費者.
如果有第二個人呢? 他們可以分工, 一個裝信封, 一個黏郵票. 第一個人 ( thread 1 ) 裝好信封交給第二個人 (thread 2), 第二個人再黏郵票就搞定了. 這就是典型的生產線模式. 這樣在第一個人裝信封的同時, 第二個人可以貼上一封信的郵票... 因此除了裝第一封信, 第二個人沒事作, 及貼最後一張郵票, 第一個人沒事作之外, 其它過程中兩個人都有工作, 對應到程式就是一個 thread 負責壓縮, 壓縮好一部份後就交給後面的 thread 負責加密, 同時前面的 thread 則繼續壓縮下一塊資料... 剛好搭配雙核 cpu, 效能就能提高. 兩個 stream 之間就靠 StreamPipeline 及 BlockingStream 隔開在兩個不同的 thread. 原本的流程改為:
[INPUT] --> GzipStream (thread 1) --> BlockingStream --> CryptoStream (thread 2) --> [OUTPUT]
雖然技術細節才是精華, 但是這部份就請各位看原文就好, 我寫再多也比不過原文講的清楚... 我想要比較的是這樣作跟之前碰到的幾種平行處理 or thread pool 差在那裡? 這種作法有什麼好處?
其實最大的差異在於, pipeline 以外的作法 (TPL, ThreadPool) 都是把大量的工作分散給多個工人來處理. 每個人處理的內容其實都是獨立的. 比如之前我處理的問題, 要把一堆照片轉成縮圖. 每個動作都互獨立, 可以很容易的分給多個人處理, 也能得到明顯的加速, 更大的好處是人手越多效能越好.
但是事情不是一直這麼理想. 某些情況是另一個極端, 沒有辦法靠人海戰術解決. 比如這個寄信的例子, 折信紙裝到信封不難, 但是要貼郵票的話, 工人可能就得放下信紙, 到旁邊拿起郵票膠水貼上去. 反覆下來他會浪費時間在交換作這兩件事情上. 這時較好的分工就不是找兩個人一人各處理一半的信, 而是一人負責折信裝信封, 一人負責貼郵票.
當然還有另外一種考量, 如果這些信 *必需* 依照順序處理, 你也無法用 thread pool 這種人海戰術來處理, 一定要把工作切成不同階段, 由專人負責才可以. 這就是 pipeline 能夠應用的時機. 其實這種作法在 CPU 很普遍, 多虧之前修過 micro-processor, 也多少學到皮毛. X86 CPU 從 80386 開始稱作 "超純量" (super scaler) CPU, 就是代表它在單一 clock cycle 能執行完超過一個指令, 靠的也是 pipeline.
再講下去就離題了, 簡單的說以往平行處理都是用 multi thread 來分配工作, 就像銀行有好幾個櫃台, 每個客戶在單一櫃台就辦完他的手續. 而 pipeline 就像拿選票一樣, 第一位查證件, 第二位蓋章, 第三位給你選票, 第四位問你要不要領公投票... 咳咳 (我實在不支持公投題目這麼無聊, 無關黨派)... 這是屬於兩種不同維度的工作切割方式. 使用 pipeline 的方式切割有幾個好處:
- 每個階段都負責單一工作, 動作簡單明確, 因此就可以更簡潔快速, 不會有額外的浪費
- 不會像 thread pool 那樣, 會有不固定個數的 worker thread 在服務, thread 數量一定是固定的, 減少了 thread create / destory 的成本
不過呢, 缺點也不少, 文章內也列了幾點:
- 效能不見得能照比例提升. 整個 pipeline 過程中只要有一階段較慢, 會卡住整條生產線. 以此例來說, 只提升了 20% 的效能, 因為管線的兩個階段花費的時間並不相等.
- 如果我有足夠的人手, 但是工作的特質不見得能切成這麼多階段, 因此擴充性有限, 以此例來說, 你用四核CPU就派不上用處了, 仍然只能分成兩階來處理.
- pipeline 啟動及結束的成本較高. 一開始只有前面階段有工作做, 最後只有後面階段有工作做. pipeline 切越多 stage 問題就越嚴重. 這在 CPU 的架構設計上比較常在探討這問題, 就是管線清空後造成的效能折損. 這也是為什麼常聽到園區停電一分鐘, 台積電就會損失幾億的原因... 因為它的生產線很長, 停掉生產線跟啟動生產線的成本高的嚇人.
廢話講了很多, 主要是這篇文章提供了另一種平行處理的方式, 是較少看到的, 就順手把心得寫一寫了, 自己留個心得, 以後才不會忘掉 [:D]. 最後, 很豬頭的是, 整篇英文很辛苦的 K 完, 才發現有中文版的, 真是... 下次各位看文章前請先注意一下有沒有中文版 [H], 當然你英文很好的話就沒差... 哈哈..
-
遲來的正義
看來 Google 沒幾個看的懂中文的員工... 不過我的破英文倒是看的懂, 真是不簡單... [Y]
話說前陣子我的文章被盜連, 最初只是點了 Blogger 上面的回報不恰當內容的標幟, 嗯, 不鳥我...
後來在 Google 網站找了半天, 才找到回報 Google 所有不當內容的網頁, 看它訊息都寫中文的, 我就不客氣的用中文回報了... 等了一兩個禮拜果然沒鳥我...
上禮拜就用我的破英文再回報一次, 這次只貼了兩三句鼈腳英文, 簡單說明文章是我寫的, 他盜用我文章 blah blah... 耶! 果然有效... 現在再點那篇文章就變這樣了:
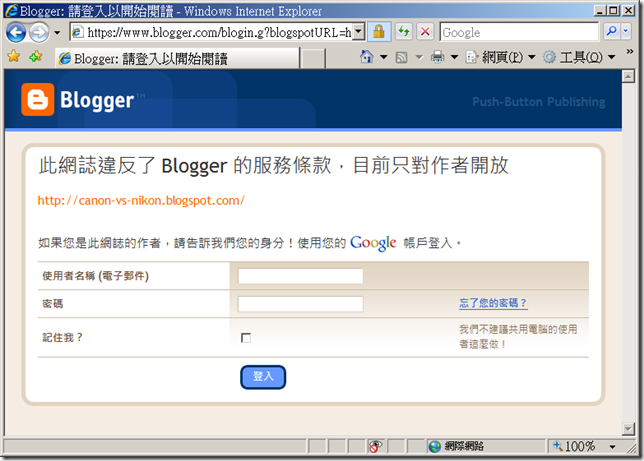
看來 Google 還是有在做事, 哈哈... 特別在此感謝一下..

