-
該如何學好 "寫程式" #4. 你的程式夠 "可靠" 嗎?
撐了很久,續篇來了。這次要進階一點,直接從 software engineer (軟體工程師) 的階段開始。
所謂的軟體工程師,我對它的定義是在這個領域已經算是資深人員了。programmer 該作的是把程式寫好,要挑正確的方式及技術寫好你的程式 (如之前幾篇介紹的演算法及資料結構等等)。而軟體工程師呢? 之前介紹的那些已經不夠了,你該好好的安排你的 code 及工具,要能把你的 solution (如會用到的演算法及資料結構),跟你手上能運用的資源 (如程式語言、開發工具及函式庫) 作最佳化的搭配及整合。
-
生產者 vs 消費者 - BlockQueue 實作
過去寫了 好幾篇跟執行緒相關的文章,講的都是如何精確控制執行緒的問題。不過實際上有在寫的人就知道,那些只是 “工具 “,最重要的還是你該怎樣安排你的程式,讓它能有效率的用到執行緒的好處,那才是重點。大部份能有效利用到多執行緒的程式,大都是大量且獨立的小動作,可以很簡單的撒下去給
ThreadPool處理,不過當你的程式沒辦法這樣切,就要想點別的辦法了。開始看 code 前先講講簡單的概念。這篇要講的是另一種模式: “生產者 v.s. 消費者“。這是個很典型的供需問題,唸過作業系統 (Operation System) 的人應該都被考過這個課題吧 @_@。簡單的說如果你的程式要處理的動作可以分為 “生產者 “ (產生資料,載入檔案,或是第一階段的運算等等) 及消費者 (匯出資料,或是第二階段的運算等等) 這種模式,而前後兩個階段各自又適合用執行緒來加速的話,那你就值得來研究一下這種模式。第一手資料就是去看看作業系統的書,恐龍書 足足有一整章在講,足夠你研究了。本篇重點會擺在怎樣用 C# / .NET 實作的部份。
舉個具體一點的例子,如果你想寫個程式,從網站下載幾百個檔案,同時要把它們壓縮成一個 ZIP 檔,在過去你大概只能全部下載完之後,再開始ZIP的壓縮動作。第一階段都是 IO (網路) bound 的程式,第二階段則是 CPU bound。如果是完全獨立的兩個程式,很適合擺在一起執行,因為它們需要的資源不一樣,不會搶來搶去。但是就敗在他們要處理的資料是卡在一起的。
把這個動作想像成我們有兩組人分別負責下載及壓縮的動作,下載的部份可以多執行緒同時進行沒問題,但是下載好一個檔案,就可以先丟給後面的那組人開始壓縮了,不用等期它人下載完成。如果下載的暫存目錄空間有限,我們甚至可以這樣調整: 當 TEMP 滿了的話,下載動作就暫停,等到 TEMP 裡的東西壓縮好清掉一部份後再繼續。而壓縮的部份則相反,如果 TEMP 已經空了就暫停,等到有東西進來再繼續,直到完成為止。
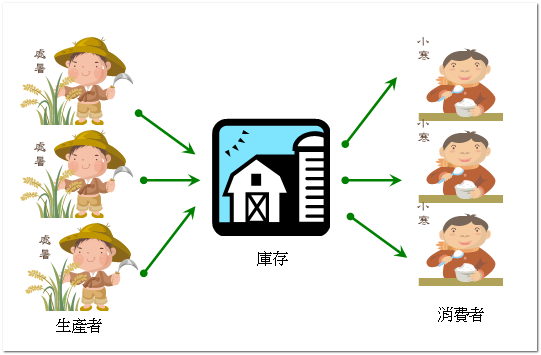
前後兩階段該如何利用多執行緒,我就跳過去了, 過去那幾篇 就足以應付。這種模式的關鍵在於前後兩階段的進度該如何平衡。有些範例是有照規矩的把這模式實作出來,不過… 你也知道,看起來就是像作業的那種,完全不像是可以拿來正規的用途。
我認定 “好” 的實作,是像
System.Collections.Generics之於 DataStructure 那樣,能很漂亮的把細節封裝起來,很容易重複利用的才是我認為好的實作。不能容易的使用,那就只能像作業一樣寫完就丟…。這個問題看過有人用Semaphore來做,也是作的很棒,不過我比較推薦的是 Queue 的作法。從上圖來看,生產者跟消費者都很簡單,就是過去講的多執行緒或是執行緒集區就搞定,關鍵在於中間的控制。我的想法是把庫存管理的東西實作成佇列 (QUEUE),生產者產出的東西就放到 QUEUE,而消費者就去 QUEUE 把東西拿出來。不過現成的 QUEUE 不會告訴你 QUEUE 滿了,QUEUE 空了也只會丟 EXCEPTION 而以。這次我做了個
BlockQueue就是希望解決這個問題。我期望這個 QUEUE 能跟一般的 QUEUE 一樣使用,但是要有三個地方不一樣:
- 要設定大小限制,當 QUEUE 達到容量上限時 EnQueue 的動作會被暫停 (Block),而不是丟出例外。
- QUEUE 已經空了的時後,DeQueue 的動作會被暫停 (Block),而不是丟出例外。
- 要多個 QUEUE 關機的動作 (SHUTDOWN),以免生產者都不出貨了,消費者還苦苦的等下去的窘況。
先看看這樣的 QUEUE 我希望它怎麼被使用。看一下簡單的範例程式 (主程式,不包含
BlockQueue):使用 BlockQueue 來實作的生產者/消費者範例:
public static BlockQueue<string> queue = new BlockQueue<string>(10); public static void Main(string[] args) { List<Thread> ps = new List<Thread>(); List<Thread> cs = new List<Thread>(); for (int index = 0; index < 5; index++) { Thread t = new Thread(Producer); ps.Add(t); t.Start(); } for (int index = 0; index < 10; index++) { Thread t = new Thread(Consumer); cs.Add(t); t.Start(); } foreach (Thread t in ps) { t.Join(); } WriteLine("Producer shutdown. "); queue.Shutdown(); foreach (Thread t in cs) { t.Join(); } } public static long sn = 0; public static void Producer() { for (int count = 0; count < 30; count++) { RandomWait(); string item = string.Format("item:{0} ", Interlocked.Increment(ref sn)); WriteLine("Produce Item: {0} ", item); queue.EnQueue(item); } WriteLine("Producer Exit "); } public static void Consumer() { try { while (true) { RandomWait(); string item = queue.DeQueue(); WriteLine("Cust Item: {0} ", item); } } catch { WriteLine("Consumer Exit "); } } private static void RandomWait() { Random rnd = new Random(); Thread.Sleep((int)(rnd.NextDouble() * 300)); } private static void WriteLine(string patterns, params object[] arguments) { Console.WriteLine(string.Format("[#{0:D02}] ", Thread.CurrentThread.ManagedThreadId) + patterns, arguments); }主程式很簡單,你知道怎麼寫多執行緒程式的話那麼一看就懂了。一開始替 Producer / Consumer 各建立三個執行續,而每個 Producer 只作很簡單的事,就是連續生產 30 個字串放到 BlockQueue, 當所有的 Producer thread 都執行完後,會呼叫
queue.Shutdown( );通知 QUEUE 已經全部生產完畢。Consumer 也很簡單,每個 Consumer 只是去 Queue 拿東西出來,顯示在 Console 上。直到 Dequeue 動作失敗,接到 Exception 之後就結束。
要試試生產者/消費者模式的各種狀況,可以試著調整兩者的執行緒數量。舉例來說,調大 Producer 執行緒數量時 (P: 10 / C:5),結果是這樣:
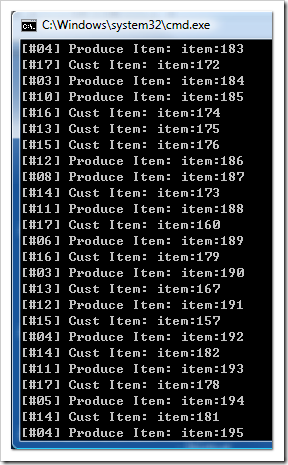
Producer 的進度大約就是領先 Consumer 的進度 10 筆資料左右,領先的幅度就暫停了,不會無止境的成長下去。證明卡在 QUEUE 內的數量受到控制。接下來再來看看調高 Consumer 的執行緒數量的結果:
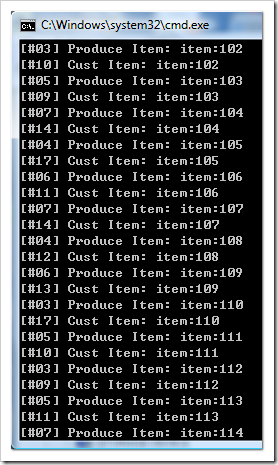
好像 iPhone 上市搶購熱潮 一樣 @_@,供不應求,Producer 提供的資料馬上被搶走了…。
效果不錯,看來這樣的實作有達成它的目的。最後來看的是 BlockQueue 的程式碼:
public class BlockQueue<T> { public readonly int SizeLimit = 0; private Queue<T> _inner_queue = null; private ManualResetEvent _enqueue_wait = null; private ManualResetEvent _dequeue_wait = null; public BlockQueue(int sizeLimit) { this.SizeLimit = sizeLimit; this._inner_queue = new Queue<T>(this.SizeLimit); this._enqueue_wait = new ManualResetEvent(false); this._dequeue_wait = new ManualResetEvent(false); } public void EnQueue(T item) { if (this._IsShutdown == true) throw new InvalidCastException("Queue was shutdown. Enqueue was not allowed. "); while (true) { lock (this._inner_queue) { if (this._inner_queue.Count < this.SizeLimit) { this._inner_queue.Enqueue(item); this._enqueue_wait.Reset(); this._dequeue_wait.Set(); break; } } this._enqueue_wait.WaitOne(); } } public T DeQueue() { while (true) { if (this._IsShutdown == true) { lock (this._inner_queue) return this._inner_queue.Dequeue(); } lock (this._inner_queue) { if (this._inner_queue.Count > 0) { T item = this._inner_queue.Dequeue(); this._dequeue_wait.Reset(); this._enqueue_wait.Set(); return item; } } this._dequeue_wait.WaitOne(); } } private bool _IsShutdown = false; public void Shutdown() { this._IsShutdown = true; this._dequeue_wait.Set(); } }重點只在重新包裝 Queue 的 Enqueue / Dequeue ,及追加的
Shutdown( )裡做的執行緒同步機制。在BlockQueue尚未 Shutdown 之前,Enqueue / Dequeue 都不會引發 Exception, 取代的是用ManualResetEvent的WaitOne( )來暫停這個動作,直到另一端資料準備好為止。然而當 Shutdown 被呼叫過之後,Queue 就不再接受新的東西被塞進來了,而東西拿光因為不再補貨,所以就維持原本 Queue 的設計扔出 Exception。
其實真的要挖的話,這個 Queue 可以進一步的改善,以資料結構來看,這種有固定 SIZE 上限的 QUEUE,最適合用 CircleQueue 來實作了。有興趣的朋友們可以換上回介紹過的 NGenerics 改看看,我就不再示範了。其實還有其它變型,像是 Priority Queue, 進去跟出來的順序不一定一樣,意思是你地位比較高的話是可以 “插隊 “ 的,後加入 QUEUE 的物件,可以優先被拿出來。這些機制都是可以進一步改善 “生產者/消費者 “ 模式的方法,有需要的讀者們可以朝這個方向思考看看!
這篇只是個開始,運用這種機制,可以進一步延伸出 Pipeline 模式 (生產線),甚至更進一步運用到串流 (Stream) 的應用。運氣好的話下個月應該看的到完整的探討跟解說吧 …,敬請期待 :D
-
NGenerics - DataStructure / Algorithm Library
其實本來沒打算寫這篇的,不過之前在寫第二篇: [該如何學好 “寫程式” #2. 為什麼 programmer 該學資料結構 ??] 時,寫的太高興,忘了查 System.Collections.Generics.SortedList 的 KEY 能不能重複… 結果貼出來後同事才提醒我,SortedList 的 KEY 一樣得是唯一的… Orz
實在是不想自己再去寫這種資料結構的作業… 一來我寫不會比較好,二來自己寫的沒支援那堆 ICollection, IEnumerable 等 interface 的話,用起來也是很難用… 就到 www.codeplex.com 找了找,沒想到還真的找到一個: NGenerics :D 找到之後才發現挖到寶了,裡面實作的資料結構還真完整,Heap, BinaryTree, CircularQueue, PriorityQueue… 啥的一應俱全,好像看到資料結構課本的解答本一樣 @_@,有興趣研究的人可以抓它的 Source Code 來看..
這套 LIB 的實作範圍很廣,除了我前兩篇介紹很基本的那幾個之外,其它連一些數學的跟圖型,甚至是各種排序法的實作都包含在內。要看介紹就到它的官方網站看吧! 很可惜的是它的文件不像 MSDN 一般,有明確的標示時間複雜度… 不過它有附 Source Code, 拼一點的話還是可以自己看程式… 哈哈 :D
我就拿 NGenerics 來改寫之前我提供的範例程式吧,那個查通訊錄的程式就不用再改寫了,看不大出來效果差在那。我們來改寫複雜一點的,也就是高速公路的例子。
先來看看有什麼東西可以用? NGenerics.DataStructures.General 這個 Namespace 下竟然有現成的 Graph 類別!! 而 NGenerics.Algorithms 下也有現成的 GraphAlgorithm 這演算法的實作… Orz, 裡面提供了三種演算法,光看名字還真搞不懂它是啥… 分別查了一下,是這三個… 找到的都是教授或是考古題之類的網站 … 咳咳…
- Dijkstras Algorithm (代克思托演算法): … 這種名字難怪我記不住 @_@,這演算法就是我在第三篇提過比較好的演算法,由起點一路擴散出去的作法。
- Kruskals Algorithm: 這名字大概太難翻了,沒人把它翻成中文的.. 哈哈,這演算法是找出 minimal spanning tree (最小生成樹),這篇不講教條了,跳過跳過,有興趣自己看 :D
- Prims Algorithm (普林演算法): 這名字好記多了… 一樣是找
最短路逕minimal spanning tree 的演算法
來看看原本我寫了上百行的程式 (請參考上一篇),用這個 LIB 改寫有多簡單吧! 先來看看建地圖的部份。Graph
的 T 是指圖的節點型別。暫時不管收費站的問題,因為 GRAPH 的模型裡,只有路逕是有成本的,點本身沒有。直接用 string 來識別點 (vertex),兩個點跟它的距離就當作路段 (edge)。建資料還真有點囉唆,打了不少字: 利用 NGeneric 的 Graph 來建立高速公路的模型
Graph<string> highway = new Graph<string>(false); highway.AddVertex("基金"); highway.AddVertex("七堵收費站"); highway.AddVertex("汐止系統"); // 以下略 highway.AddEdge( highway.GetVertex("基金"), highway.GetVertex("七堵收費站"), 4.9 - 0); highway.AddEdge( highway.GetVertex("七堵收費站"), highway.GetVertex("汐止系統"), 10.9 - 4.9); // 以下略都是我一行一行慢慢打的 @_@… 地圖建完後,怎麼找出兩點之間的最短路逕? 只要這段…
找出 [機場端] 到 [基金] 的最短路逕
Graph<string> result = GraphAlgorithms.DijkstrasAlgorithm<string>( highway, highway.GetVertex("機場端")); Console.WriteLine(result.GetVertex("基金").Weight);因為每個路段的 weight 我是填上油錢 (一公里兩塊錢),所以印出來的就是兩端要花的油錢。那麼被我們忽略掉的收費站怎麼算? 因為圖型的 MODEL 裡,點是沒有 weight 的,因此我們必需把路段改成有方向的,也就是南下及北上分別算不同的路段 (edge), 同時把過路費加到 weight 裡。
這個演算法的實作有個小缺點,它只傳回結果,沒把過程傳回來…,所以我們只能算出要花多少錢,沒有很簡單的方法拿到該怎麼走。不過好在它有附原始碼,需要的人就拿來改一下吧 :D,多傳個 delegate 或是用它定義的 IVisitor 讓它走完所有的點,你就可以取得沿路的資訊了。
這篇主要是介紹這個意外發現的LIB,就不深入的挖這些細節了,有興趣的讀者們可以自己試看看,不難的。見識到這類演算法函式庫的威力了嗎? 用起來一點都不難,不過要知道怎麼用還真的要好好研究一下…。整套 NGenerics 都是這類的東西,有興趣的讀者好好研究吧 :D
-
終於升速了!
都什麼年代了,台北市宣稱光纖覆蓋率要達到八成,結果我家這邊到現在還是沒 FTTB 可以用… 決定把龜了很久的 ADSL 從 2M/256K 升級到 8M/640K … 上傳速度提升了 2.5 倍,多少應該有快一點吧?
雖然填單變更速率的過程碰到一堆鳥狀況,不過總算升速成功了 :D
特此留念
-
該如何學好 "寫程式" #3. 進階應用 - 資料結構 + 問題分析
這類文章還真不好寫,想了好幾天,才擠的出一篇文章。第一篇已經講了一堆教條了,第二篇也舉了簡單的例子,說明挑對資料結構的重要性,接下來這篇會把主題放在更複雜的例子上,到底那些地方該注重技術,而那些地方該把重點放在基礎的資料結構及演算法身上。