-
JPEG XR (就是 Microsoft HD Photo 啦) 已經是 ISO 正式標準了...
先寫在前面,這篇不是什麼技術的探討或是評論,純脆是我個人看到這消息的想法而已。很久沒貼些軟體相關的文章了,最近比較少在動手寫 Code, 自然就沒什麼新題材好寫 @@,不過這兩天倒是看到一個蠻令人興奮的新聞,就是:
JPEG XR 已經正式通過 ISO 標準了!!
http://jpeg.org/newsrel26.html
http://blogs.msdn.com/billcrow/archive/2009/07/29/jpeg-xr-is-now-an-international-standard.aspxJPEG 應該已經無人不知,無人不曉了吧? 不過當年還是有朋友鬧過笑話… 曾有人正經八百的來問我
“什麼是 [結合照片專業群組] 啊???” 就是 JPEG 啦 (無聊的話看一下底下的題外話)
我還丈二金剛摸不著頭腦,把他在看的整篇文章拿過來看,才晃然大悟他到底在問啥 =_= … 原來是 “JPEG: Joint Photographic Experts Group”的縮寫… 當然類似的 MPEG (Moving Picture Experts Group) 也碰過類似的笑話… 無聊 GOOGLE 一下,竟然還查的到一篇範例…
http://support.microsoft.com/default.aspx/kb/235928/zh-tw
My God… 這翻譯真是比之前碰到了 “註冊傑克” 還絕 XD…
之前其實沒特別注意這些標準,曾經有印像的就是用 wavelet 壓縮方式的 JPEG2000… 嘗試取代 JPEG,也取得 ISO 的標準化,不過一直沒達成它的目的,只在特定領域還有應用空間。兩年前 Microsoft 隨著 Vista / WPF 推出 Windows Media Photo 的格式,後來為了讓它成為標準,換了個叫沒有 MS 色彩的名字: HD Photo, 最後變成現在的 JPEG XR ..
我是在兩年前,隨著 .NET 3.0 推出 WPF,剛好自己用的 CANON 相機的 RAW FILE 又被 WPF 支援,所以開始研究相關的 API 及 support .. 在關於 HD Photo 眾多報導中,有個觀點是我相當認同的。找不到較具代表性的消息來源,我就憑記憶寫一下,大意是:
隨著技術進步,未來影像設備 (如印表機,掃描器,顯示器等等) 的色彩表現能力及色域會遠超過 JPEG 格式的範圍 (現在就是了),因此儲存格式支援的動態範圍 (dynamic range) 越高,對於影像的長期保存越重要。
這就是處女座的龜毛個性啊… 衝著這個看法,我從 Canon PowerShot G2 時代開始,我就試著盡量用 .CRW 格式 (CANON RAW) 來保存相片,而不是用 JPEG。後來換了 Canon PowerShot G9,正好 WPF 出來,我就開始改用保存 .CR2 檔,而另外轉一份 JPEG 檔來作一般用途 (畢竟 JPEG 還是方便的多)。不過一張照片花掉 15 ~ 20mb, 保存起來壓力還真不小 =_=
現在看到 JPEG XR 的標準化,正好是我要的東西啊 :D 我需要的正是個能妥善保存這些影像資料細節的方式,同時能讓我輕鬆愉快的使用,不用耽心工具支不支援,或是其它五四三等問題困擾…。這些問題對阿宅來說,一點都不困難,有一缸子的工具辦的到,不過… 如果隨變看個照片,或是要 COPY 給家人朋友看,還要動用一堆雞絲,那也太辛苦了一點… 能有個通用的標準格式及大廠背書,那是再好也不過了 :D
所以,接下來要做什麼? 我突然慶興我一直都有留著這幾年拍下來的 RAW file (.CRW / .CR2) 檔案… 該是替我的歸檔程式翻新的時後了,下一步是開始嘗試用 .WDP 來取代現在放兩份 RAW + JPEG 的方式…
-
拼了! 80公里長征... (關渡 - 鶯歌)
自從上次騎了一次關渡到八里之後,其實後來又去騎了幾次,發現也沒想像中的困難嘛,於是這次就計劃來拼長一點的路線… 關渡到鶯歌。會挑這路線,主要是上次騎到二重疏洪道時,有個路人問我:
“請問往鶯歌要怎麼騎?”
我才發現,原來可以騎到鶯歌啊… 不過當下的反應是騎到那邊腿會斷掉吧? 不過用 google maps 看了一下,單程 35 公里 (加上迷路的一段路,來回應該有 80 了)… 之前近 30 公里都拼完了,騎到鶯歌好好休息,再騎回來應該沒什麼了不起吧? 加上上次那篇有人留話嗆了一句
“是男人就要挑戰百里長征啦”
…. 愛面子的男人於是就很天真的出發了… =_=
很多人問我,為什麼每次都從關渡出發? 哈哈… 原因只有一個: 我很懶 :D,因為那邊捷運出站就有租車店,一輛還可以的變速登山車,當天租一次一台只要一百塊… 想想我一個月頂多騎一次,帶車子搭捷運票價也不止這個錢… 用租的比較方便,所以每次騎的路線就都挑從關渡為起點..
不過這次騎完,開始改變想法了… 哈哈,最後面再講。先來看看這次計劃的路線:
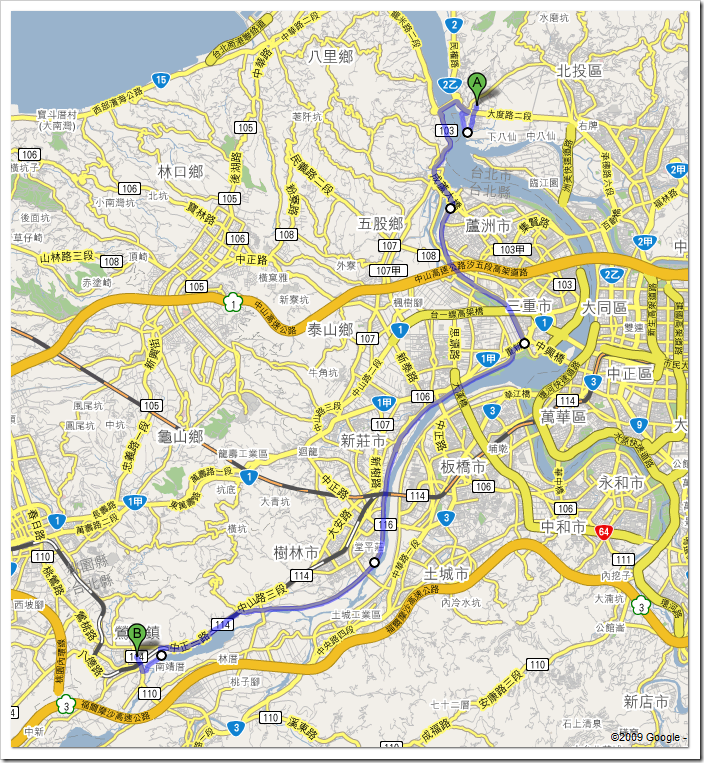
有 GOOGLE Maps 真是方便… 這次路線很簡單,前 1/3 是之前騎過的,之前是繞蘆洲三重一圈就回關渡了,這次會過重新橋,就改沿著大漢溪左岸,一路騎到鶯歌鎮…
出發前上網查了查,發現很多人騎過這段,最後是參考這個人的行程,看了才知道原來鶯歌有個 [阿婆壽司] … 特色是便宜又不錯吃。雖然我沒有特別愛吃壽司,不過就把它當個目標吧,不然拼到鶯歌我也不知道要幹嘛 XD
算了算時間,一趟算 2.5 hr, 來回 5 hr, 加上一個小時休息吃東西,嗯,不用太早出門…
(啊,大家不要學… 你會後悔的 =_=)
2009/07/19 12:25
過程就不多說了 :P,到了關渡捷運站後,東摸西摸,騎上車開始動身後,過了大度路就先拍一張。我懶的拿紙筆出來計了,就拿起相機拍一拍了事 (時間可以從 EXIF 查,正好省掉記錄的動作),只可惜我的 G9 不支援 GPS … 不然連地圖都不用標了 :D Canon 你什麼時後要出內建 GPS 的相機…
路上的便利商店,買了兩罐冰釀綠茶,加上租車店老闆送的一罐水… 就上路了…
2009/07/19 13:37
悠哉的騎了一個小時,到了重新橋… 橋下有跳蚤市場,真熱鬧… 好多人 :D,不過騎著車不好人擠人,就沒進去逛了..
2009/07/19 13:43
雖然沒進去逛,不過也是要拍張照紀念。這邊的路標示實在不怎麼清楚,到了橋下就迷路了 :D 哈哈.. 在那邊摸了十幾分鐘,地圖拿出來,還看太陽在那邊認一認方向,硬著頭皮找了對的方向就騎下去… 沒有自行車道,只好走省道,自己識相一點靠邊邊騎…
好在沒騎多遠,就找到自行車道 =_=,就一路沿著大漢溪左岸的自行車道一路往西南騎…
雖然是 “自行車道”,不過實際上也只是快速道路隔一條出來給自行車專用… 經費的關係吧 @@,沒關係,有就好,標示清楚一點就好。至少這邊不會騎一段就找不到路… 這是好處 :P
2009/07/19 14:02
騎到一半,才發現,原來新莊的 IKEA 就在路邊耶 :D
沒想到第一次來新莊的 IKEA 是騎著自行車來… 今天沒機會進去逛逛,只好拍張照紀念一下。
2009/07/19 14:15
騎到一半,看到一座天橋,上去後就可以在河提上面繼續騎,或是跨過河提到另一面的巷道裡。我也忘了看誰的文章介紹,他特別介紹了天橋兩側的鐵管… 我就糊理糊塗的跟著牽上去…
(大家不要學啊,這條路是錯的 XD 請不要上橋,繼續沿著自行車道騎就好 …)
都走錯了,不過走過總要留個記錄,還是貼一下好了,不要小看那兩根鐵管併起來的軌道,這樣子牽單車上橋還真的很輕鬆耶 (Y)(Y)(Y),不但很輕鬆就推上去了,鐵管中間還能卡著腳踏車的輪胎,不會亂跑,連車子都不用特別去控制它的方向,只要花點力氣把車往前推就好,真是聰明的設計 (Y)
2009/07/19 14:32
沿著河岸騎了一段之後,自行車道到這邊就結束了… 這邊下來把車扛上河提之後,就進入最後一段 [淡水-鶯歌] 10KM 的車道…
我是不知道為什麼這段叫 [淡水-鶯歌] 啦 @@,不曉得的人還以為真的 10 KM 就到了… 總之,這 10 KM 騎完就到鶯歌了,快到了快到了…
2009/07/19 14:49
遠遠看到這棟建築,還以為是什麼紀念館還是啥的… 原來是個抽水站…
2009/07/19 15:05
路過看到的,覺的很有意思就拍一下 :D
河邊放了一堆消波塊,竟然有人把它漆成這個樣子… 哈哈,真有創意,看起來就像一堆躲在草叢裡探出頭找獵物的迅猛龍…
2009/07/19 15:37
一路都沒看到路標,也不知道到底還多久 @@,最後怎麼覺的那一公里好遠… 騎到這邊早就沒力氣了,都慢慢騎… 總算撐到了鶯歌。看看地圖,其實離火車站沒多遠,不過懶的過去照相了 @@,動身去找阿婆壽司..
2009/07/19 16:12
一開始問了一個媽媽,說往前騎,看到中正三路左轉就到了 (最後找到的地點是中正一路右轉)…
騎錯之後又問一個廿歲左右的小妹妹… 前面路口右轉就到了 (最後是左轉才對 =_=)
路人都報錯,我怎麼還找的到? @@,一切都要感謝全家便利商店外面整面牆上畫的地圖… 哈哈,最後是靠那張地圖找到的…
停下來吃了盒壽司 + 茶碗蒸,肚子餓了什麼都好吃… 50塊就吃飽了… 順手多帶了一盒回去… 水到這邊也都喝光光,去便利商店再補兩罐…
2009/07/19 19:00
回程的路線都一樣,就不再多介紹了,當然迷路過的地方就不會再走錯了 :P
路上河邊有好多人在玩搖控飛機,看了好想也去買來玩… :D 有個傢伙好強,控制的好靈活,其它的只是在亂飛而已。看他表演了好幾招,最後還表演了高級空戰技巧 - 英麥曼迴轉 (Immelman turn) … 可惜他秀完這招就降落了 (降落的動作也很乾淨利絡… 其它的看起來都像要墜機的樣子 XD),不然我大概會在旁邊一直看吧…
其實從鶯歌要回程起,早就沒啥力氣了 :D,回來的速度就慢多了,騎回二重已經七點了… 當天天空雲還蠻厚的,不過我鐵齒沒搽防曬油,兩隻手被曬的好痛 Q_Q …
不過也多虧這樣的天氣,當天有晚霞耶… 趕路歸趕路,有大景還是要停下來照一下 :D
不過沒背腳架,騎的很累手也拿不穩相機 @@,只好亂拍一通… 貼幾張還可以看的相片….
2009/07/19 19:27
騎到關渡大橋,那段上坡早就沒力了,連試著騎上來的念頭都沒有.. 當大家都往前衝時我就很沒面子的下來用牽的… 哈哈。一路上一直很納悶,怎麼那些身材嬌小的長腿正妹,每個體力都這麼好 =_= 騎在前面跟都跟不上…. 車子比較好的關係嘛 @@
牽上橋後,休息一下,相機靠著欄干拍了幾張夜景,拍完就繼續往捷運站趕路了…
2009/07/19 19:50
總算… 我頭一次這麼期待進到捷運站… 哈哈,總算可以坐下來了… 不然騎一天下來,屁股還真的會痛 @@
趕在 20:00 之前,總算拼完今天的行程了 :D 哈哈… 今天這樣騎下來,才發現裝備是很重要的… 平時騎兩三個小時那種就沒差了,要騎長程一點的真的要準備一下… 喝的一次就喝掉五罐小保特瓶… 延路都沒便利商店好補貨… 手套要戴 (不然手會握的很痛),排汗衣褲 (不然流一堆汗很難過),適合的背包 (一樣… 不然背很難過),還有電池夠力的 MP3 (我買了台 iPico, 還不錯 (Y),連續聽了七個小時… 只有最後一小段路沒得聽)…
最後,挑台自己的車好像也很重要… 哈哈… 這天我動過不只一次的念頭,很想到鶯歌就扛著腳踏車,搭火車回台北… 不過想到還要回到關渡去還車,就很懶… 還是騎回去好了。看看地圖,如果有自己的車的話,搭捷運到永寧,出來就樹林那一帶了,騎一個小時左右就可以到鶯歌了吧,省了不少路 :D 不過等到有買車再試吧…
這次相片放在 facebook 上,有興趣的人過去看看吧 :D
這次在鶯歌,又有路人在鶯歌問我 “請問大溪要怎麼去” @@
嗯,再說… 這一定是巧合… 這一定是巧合…
-
555555 人次紀念!
正好想到,開了自己的部落格來看,啊!!! 總點閱次數: 555551 …
多按了幾下 F5,就抓到這個畫面 :D
沒啥特別的,單純記念一下… 這個幸運兒,只是個 Bot 啦… T_T
-
關渡騎單車
這次來寫點不一樣的,寫點休閒的吧。
上個月跟家裡大人跟兩個小孩,去了趟關渡騎腳踏車,騎完覺的那邊還不錯 :D,不過因為小孩狀況多,最後沒能騎到八里天就黑了,租來的腳踏車又沒燈,只好半路就折回來了。回家翻了一下地圖,發現只剩 1/3 不到的路程啊 @_@… 於是這次趁著大人帶著小孩回娘家,碰到難得的好天氣,就自己一個人帶著裝備出發去了 :D
計劃要騎的路線很簡單,一點都不困難… 就是從捷運 [關渡站],往關山公園,沿著淡水河岸的腳踏車道,騎過關渡大橋,到八里老街,再一路騎到十三行博物館。 不過計劃總是跟實際執行時不一樣 =_= … 直接來寫流水帳吧… 照我騎的順序看下去…
這篇不是什麼專業的介紹,老實說我也是第一次騎而已,沒做什麼功課,想來參考的可能會失望吧 :D 只是單純的記下來自己留個紀錄而以。有興趣的請繼續往下看 :D
1. 捷運關渡站(15:09) ~ 八里渡船碼頭 (16:05), 共 8.4 KM
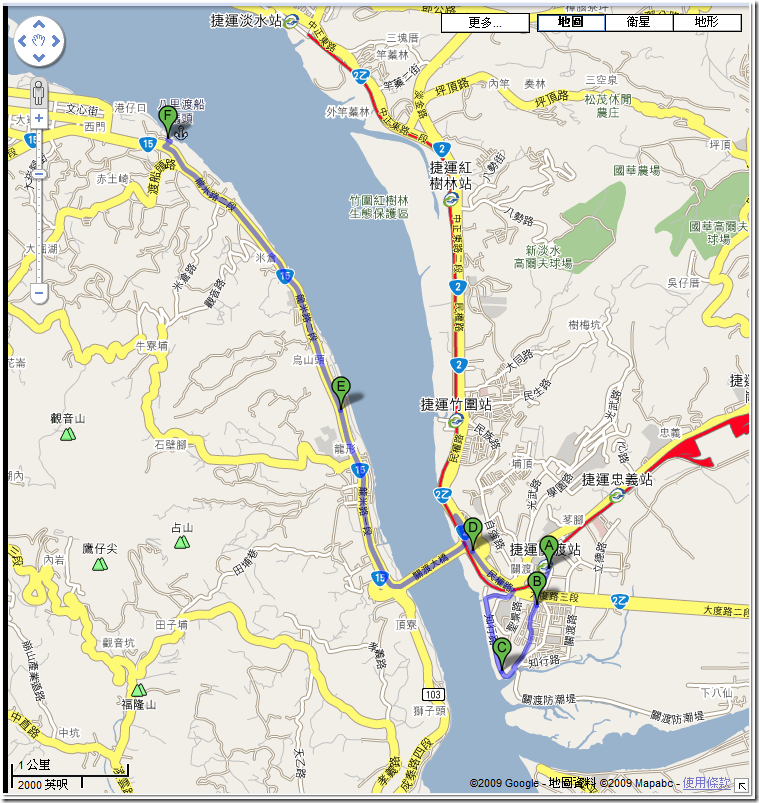
GOOGLE MAPS 還蠻好用的,地圖跟路線都標的好好的 :D 上面的路線其實是車子走的,跟我真正騎的腳踏車道有點不同… 不過差不多啦,我就借用它的地圖標示一下。上面的每個點 (綠色的英文字母) 就是底下照片標的 ABC,各位可以對照著看。
第一段的路限很簡單,就是到了關渡捷運站後,租了腳踏車就上路了。從關渡捷運站出發,一路騎到八里渡船口而以.. 太陽還不小,但是天空雲也很多,還頗耽心會不會下雨… 因為這次出發帶了一堆配備 (腳架,相機,閃光燈,耳機…),就是沒帶傘 …
A. 15:09,捷運關渡站 ( 0.0 km )

搭了半個多小時的捷運,到了關渡站,拍個照紀念一下。其實這裡沒什麼好照的,只是我也懶的拿紙筆出來記時間了… 哈哈,直接拍個照,回家可以看到照片,也看的到時間… 突然覺的應該買個有 GPS 的照相手機,這樣拍出來連座標都有了 [Y]
另外一個敗家目標是 MP3 隨身聽… 平常沒在聽,不過自己一個人邊騎車邊聽還真愜意,聽了一下午的陳綺貞… 結果聽到連手機都沒電了 =_=,看來用手機聽 MP3 不是長久之計,有空來物色一台…
好,列入敗家清單內… 出了捷運站就有租腳踏車的地方。雖然看其它網站,都是說要步行 15 分鐘到關渡宮那邊再租車,不過… 實在是懶的多走這 15 分鐘的路程了,在門口的租車店就租下去,到晚上八點,一次一百…
B. 15:16,大度路 (0.3km)

騎出巷子口,穿過橋下就到大度路口了,單純覺的這個景跟這個建築,好像在國外的感覺,就順手拍了一張…
C. 15:26,關渡棧橋碼頭 (1.1km)


騎著腳踏車還蠻快的,穿過巷子,經過關渡醫院,到了關度宮,就到 [關渡棧橋碼頭] 了… 十分鐘不到的車程而已。在這邊看到天氣有點陰陰的,遠方已經看的到等等要過去的關渡大橋…
D. 15:32,關渡大橋上 (2.5km)

騎起來好像真的沒什麼挑戰 @_@,跟上次載著小孩完全不一樣,一方面親子車本來就不好騎,另一方面自己騎也比較自在一點,不到十分鐘已經在關渡大橋上了… 上橋是吃力了一點,人也多,只好下車用牽的… 這張照片就是在橋邊的步道拍的… 再往前左轉就在橋上了..
E. 15:56,已經到對岸了 (5.5km)


過到對岸後,沿著河畔騎了廿分鐘左右,這個點不知道叫啥名字,會停下來只是喝帶來的冰釀綠茶,也剛好看到有個左右相反的 [八里左岸] 石碑,停下來照個相記錄一下… 不過有對姊妹 (應該是姊妹吧) 抱著狗一直在那邊照… 哈哈,心裡噓了半天還是不肯走… 還一直猛拍,一直拍,一直拍…. ==,我又不想跟她們慢慢耗…,就讓妳們倆跟愛犬免費登上我的部落格一次吧 == …
騎到這邊已經快到八里渡船頭了,沒有想像中的久嘛… 上次竟然騎不到 @_@
F. 16:05,八里渡船頭 (8.4km)


再往前騎不到十分鐘,就… 到.. 了 @_@,從租到車到騎到八里,也才五十分鐘左右,扣掉停下來喝個水,照個相的時間… Hmm… 果然是很休閒的路線…
這裡一樣一堆人,趕不走 (我也沒那個膽.. 哈哈),就照進去了 :D
這邊是八里渡船頭,可以直接搭渡輪到淡水碼頭… 就是有顆大蓉樹那邊,還有一堆阿給小吃店的地方。


照完相想繼續往下騎,一路直攻十三行博物館… 不過… My God! 那來這麼多人… 我最討厭人擠人了 :@,看到一堆人就很沒力… 何況牽著車跟本動彈不得… 就放棄繼續往前走的念頭了。
翻了翻地圖,另一邊有生態公園,看看時間跟騎的速度,應該還很夠吧 :D,就改變計劃往回走了…
2. 八里渡船碼頭 (16:05) ~ 疏洪生態公園 (17:20),共 8.0 KM
在決定不想擠過人群,往十三行博物館前進之後,看了看地圖,就決定往南騎到生態公園看看,這種地方人應該不會那麼多吧 :D
這一趟的路程也差不多一樣八公里,沒騎過,反正自己一個人就騎看看 :D
B. 16:26,八里左岸石碑 (11.3km)


又回來這裡了! 不過,這次那對姊妹跟狗已經不在了 :D,沒人在拍照… 終於輪到我拍了 :D
石碑旁邊原來還有說明啊… 剛才都沒看到。本來想拿起相機自拍,不過技術不好,都拍不到後面,腳架也懶的扛出來… 就算了…,繼續往下一站!
C. 16:38 岸邊某個休息區 (12.3km)

回程的途中,有一小片沙灘,正好看的到關渡大橋,就照一下紀錄時間…
D. 16:50,虹橋廣場 (12.9km)



已經騎回來到關渡大橋橋下了,這邊剛好是從橋上下來的自行車道的地方,原來這 SQUARE 叫 “虹橋廣場” 啊… 拍個照。
不過這次沒有要過橋了,繼續沿著左岸往南騎…
E. 17:06 獅子頭長橋 (14.5km)


這裡是個半園型的橋… 不大會講,我剛好也沒照 @_@,抓張 GOOGLE MAP 的衛星照來看看… 那個像量角器的東西,就是獅子頭長橋啦…
這邊我只停下來拍照而已,沒多休息就往下一站去了…
17:12 觀音坑溪橋 (15.2km)


還蠻特別的一座橋,造型不錯就照了一下,其實橋很小一座… 就貼個照片跟 GOOGLE 衛星空照圖意思一下..
17:20 疏洪生態公園 (16.0km)

不知不覺就騎到目的的了,果然沒很多人,一邊是河一邊是草地,在這邊坐著休息還蠻舒服的… 陪我騎了半天的腳踏車,終於有機會入鏡頭了 :D,叫不出來的牌子,不過還蠻好騎的 (Y),一次一百塊,我是覺的不貴啦,自己買一台少說四五千吧? 光是帶車子搭捷運就不只這一百塊了 =_=,還是當場用租的方便…
3. 疏洪生態公園 (17:20) ~ 捷運關渡站 (19:00),共 6.6 KM
看看時間也差不多了,還得趕回去接大人跟少爺公主回家 ==,在疏洪生態公園休息一下就回頭了。一路上的風景跟景點都介紹過,就不多提了。在回程的路上,才發現 MP3 隨身聽的重要啊 @@,一整天聽下來,也沒幾個小時 (3HR左右),我的手機在接到大人打來的電話之後,就… 沒… 電… 了,嘖嘖,windows mobile 的手機聽個 MP3 就這麼耗電…
不過這樣一路聽聽 MP3 還真是過癮,就是這樣我才想去買台來用… 有沒有推薦的? iPod 就不用推了,我沒這麼時尚 @_@…
17:42 關渡大橋 (八里 –> 淡水,19.0 km)


又回到關渡大橋了,這次是從左岸南方的步道上橋,第一張照片是還沒過橋前照的,第二張照片則是同一個地點,拍上來的地方,就是從畫面中間一路往右邊爬上來… 第三張是 GOOGLE MAPS 的空照圖,順手放上來…
這次因為時間的關係,不能待太晚,可惜沒等到晚一點天黑,沒機會拍到關渡大橋的夜景… @_@,看來腳架是白帶了…
18:14 關渡宮前的小吃 (21.5km)


繼續往回騎,騎到關渡宮前面的小市集吃東西… 其實當地我也不知道有什麼特別的小吃,就點了平常愛吃的就好… 這邊的鹹鴨蛋好像還蠻出名的,上回大人有買一些,不過這次就沒買了。另外離這裡不遠的淡水很有名的鐵蛋,這邊也有… 不過 $$ 幾乎便宜了一半 (9顆50),這個吃起來比鹹鴨蛋方便 (哈哈,不用剝殼),常常買了就當零嘴吃.. =_=
關渡宮就是 GOOGLE 衛星照中間的橘色建築,隔著馬路對面 (橘色屋頂),一個正方型的建築就是個小吃攤集中的場地… 無奈當天沒啥胃口,吃了一盤蚵仔煎 (五十元) … 一份花生糖冰淇淋 (卅五元) … 一顆鐵蛋 (帶了一包回家,九顆 50 元) 就… 飽了 =_= 不然還有其它的東西想吃一吃…
18:24 一堆怪名字的租車店



除了蚵仔煎是坐在裡面的位子吃之外,其它我就在路邊的椅子買了就坐下來吃,路邊不是小吃就是租車店,發現他們店名還真有創意… 哈哈,害我邊吃邊笑..
第一家叫 “租八借”,虧老闆想的出來…
第二家叫 “租羅記”,老闆八成姓羅吧… =_=
這邊租一次只要 80,不過搭捷運的話,大概來回得多走個卅分鐘吧,算了,我是懶人,就讓另外的店家多賺廿塊錢吧…
第三家在旁邊一點,喵喵休閒車,人氣就差多了… 哈哈,招牌還在,不過店已經收起來了,底下是掛著店面出租的紅紙… 果然名字好不好記還是有差.. @_@
最後 19:00 整,回到捷運站前的租車店 (22.6km)
這裡就沒再拍照了 @@ 沒想到這樣很輕鬆的騎下來,也不知不覺騎了廿幾公里… 夠高速公路從台北開到桃園了吧? 這樣看起來好像還蠻遠的.. 哈哈。自己一個人騎,聽聽 MP3 就不無聊了,騎了多遠也沒什麼感覺,很適合來放鬆的。騎單車還真不錯,有風景可以看不會無聊 (平常騎機車或開車,都不能看風景 ==),也 “好像” 有運動到,聽起來比較健康一點… :D
下次再看看天氣怎樣,試試別條路線… 看了看台北縣市自行車道的介紹 (這裡有地圖PDF檔下載),其它路線有往淡水 (不過淡水去過幾次,都像八里一樣人擠人 @_@),也有往關渡自然公園看水鳥的路線 (這路途比較短,不用一個小時就到了吧)….,另外還有往三重方向,可以繞一整圈三重/蘆洲… 還會經過三和夜市… 不知道有沒有好吃的小吃? 還有不知道會不會經過很紅的爆米花店? 哈哈,順便買個兩桶回來 :D
雖然自己騎蠻自在的,不過有人要跟團也接受報名啦 :D 看看下次有沒有機會拼完三重蘆洲這條自行車道…
-
個人檔案 + 版本控制...
自從過年時換了 SERVER 的作業系統,加上過年前 NOTEBOOK 掛掉換 X40 + SSD 之後,這幾個月都陷在東換換西調調的狀態中 @_@, 好在換了 2008 之後,有 Hyper-V 的幫忙,問題簡化不少…。不過今天要講的倒是很不起眼的小東西: SVN (Subversion)。
SVN 這種版本控制系統,通常是用來作程式碼的版本管理。也對啦,除了軟體開發之外,其它場合好像也不大需要這麼複雜的版本機制。不過這類系統弄多了,平常在非軟體開發的場合,也發現其實很多時後都有檔案版本問題要處理。像是平常的文件 (WORD),簡報 (PPT) 等等,都會作好一份通用的,碰到 A 客戶就改一改拿來用,B 客戶再改一改… 這不就是 brench / merge 之類的問題嘛? 所以我一直在找這樣的 solution,看看有沒有適合一般使用的。不過到現在,也換了好幾種作法,歷年來試過的作法有好幾種:
-
VSS (Microsoft Visual SourceSafe 5.0)
這個有用過的人,看版本號碼就知道有多古老了… 不過真正在用是 6.0 版開始。因為工作上會用的到,就順便拿來用了。它的好處是很簡單,搞懂它的邏輯就很容易上手。架設也簡單,完全是 File Based, 不需要架設專用的 Server。不過這也是後來換掉它的原因之一。
它的使用方式,是以嚴格的控制為主要邏輯。什麼意思? 意思是你不能隨意更改檔案,要開使改檔案之前,要先 check-out 才能開始改。這樣的邏輯就是要避免未來一連串的版本衝突 (conflict) 及合併 (merge) 帶來的問題。 以軟體開發的角度來看,這樣的作法還不錯,整個團隊的開發是值得這樣作的。不過拿來管理個人檔案的話,就太過頭了。個人檔案不大會發生 LOCK 的問題,就是我改你也改,最後存檔總會有一個人的資料被蓋掉… 不過,如果我是大老闆,有十幾個秘書在幫我打雜的話就難說了 [H]
-
VSS (Windows Volume Shadow Copy Service)
Visual Source Safe 用了之後,發現障礙多於它帶來的優點 (以處理一般文件而言)。主要的缺點是,VSS 透過網路 / Internet / VPN 使用的速度實在是龜到可以,雖然後來 Microsoft 推出了 LAN Boost Service (還是很慢),也另外推出了 HTTP / Web Service 的存取方式 (只能透過 Visual Studio) 速度也不快。另一個缺點是一定要先開 VSS Explorer / Visual Studio, 我不過只是想開個 WORD 檔啊…
所以後來換了另一個角度找 solution, 就試用了 windows 2003 內建的 VSS (Volume Shadow Copy Service), 替代版本控制用的軟體。它是做在 File System 層次上的機制,用了 Copy On Write (COW.. 這是縮寫,不是在罵人…) 的方式,做版本的差異控制。因此只要把檔案放在開啟 VSS 的磁碟機,完全不用更改任何使用習慣..。
但是太自動的東西還是不適用。這種作法主要的問題在於版本太不精確了。VSS 仰賴定期作快照 (snapshot) 來作版本的管理。定期做的快照,留下來的版本很可能是無意義的,你也無法針對特定檔案的特定版本作註記 or 回複… 另外自動的快照也無法選則那些檔案要進版本,那些要退出。總之一切全自動,沒有什麼好選的。很簡單,但是功能也很有限。
不過即使如此,一般情況下也夠用了,操作也夠簡單,當作第二種保護機制也不錯。這個 solution 我也用了好一陣子…。
-
TFS (Team Foundation Server)
老實說,連一般小型軟體開發,用到 TFS 都太肥了一點,自己的檔案管理用到這個真是太離譜了… 哈哈,因此這個 solution 只是閃過念頭而已,跟本沒實際裝起來試過。用這個方案,工具會是個大問題… 用的時後得開個 Visual Studio, SERVER 還得裝一大票軟體 (IIS, TFS, SQL + Reporting, SharePoint Team Service, AD…)
-
USB DISK + PortableApps
其實這個算不上是個 SOLUTION,只不過順便把它列上來,待會說明用。某次無意間,同事告訴我 PortableApps.com 這個工具,它是個灌在 USB 隨身碟上面的工具 & 一些綠色軟體,有自己專用的 “開始” 選單,方便你插上隨便一台電腦,就把它當作你自己的 PC 一樣使用… 老實說還不錯用 (Y),我就試著用一陣子,把所有個人相關的資料都移到上面了。現在的工作環境有點複雜,公司一台 PC,家裡一台 PC,偶爾還需要用 notebook 去客戶那邊簡報 (咳,就是我那台只有 8GB SSD 的 X40,正好沒地方放檔案)
用了一陣子還不錯,不過碰到的又是很常見的問題: 檔案掉了怎辦? 備份問題? 讀寫速度問題? Flash Disk 寫入次數限制問題… 不外乎常備份,每天一份 ZIP 檔,用苦力作好版本控制…
-
USB DISK + SVN
最後,就是現在用的方案了… 主要是補 (4) 的不足: 一般的定期 ZIP 備份就跟快照一樣,事後要追出變更其實很麻煩,每次變更想加個註解又更麻煩了。當然搭配 Visual Source Safe 這種工具,把 Working Folder 指到 USB DISK 上就可以兩全齊美了。
不過使用便利則是另一個問題,我希望能夠找個無腦一點的工具,不需事先 check-out (lock) 的動作就可以開始編輯,改完再決定 check-in (commit) 或是 undo (revert) 的模式最好。用了 USB DISK 就是希望能拔來拔去,如果必需配合特定工具 & 要即時連上 SERVER,那就有點麻煩… 想看看,當我 USB DISK 插到 NOTEBOOK 帶到客戶那邊去,都按兩下打開 PPT 在簡報了,臨時要改幾個字,用 VSS 的話,我得關掉 PPT,打開 VSS,CHECK-OUT,打開PPT,修改…
所以後來的首選就變成 SVN 了。SVN 因應 internet / open source project 的開發模式,採取的就跟 Microsoft 是不同的策略,就是先改再說。SVN 賭你不會多人同時編同一個檔案,就算會,也不會編同一段 code … 真的碰到就再人工處理吧。另外它支援各種不同的 protocol, 透過 internet 這種連線來使用,效能也不會很糟糕…
到目前為止,我用的就是 (5) USB DISK + SVN 這種 solution, 老實說越用越覺的它不錯 (Y)。SVN 我還是個新手,應該輪不到我來介紹他的特色吧 XD,不過我還是挑幾個特別的地方介紹一下,這些是我用它的主要原因啊…
-
操作邏輯合適
SVN 是 CVS 的接班人,它先天就繼承了 CVS 的特性: 就是適用 open source 的開發團隊。Open Source 的開發團隊跟一般的開發團隊有什麼差別? 一般商業開發都是正職的工作,很固定且很密集的進行開發及變更,因此像 Microsoft Solution (VSS / TFS) 那種要事先 lock 的機制會比較有效率。不過 open source project 就反過來,業餘的比例比較高,而且人都散布在世界各地,如果真正用 LOCK 的機制大概會哭出來吧…。我要改的檔案被你 LOCK 住了,不過我又不知道你是誰? 除了等就沒辦法了…。
因此 SVN 先天就是以這樣的觀點來設計: 你先改了再說,改完就 commit 。反正只要沒人跟你改同一個檔案就沒事… 如果運氣真的不好,那這個人不要跟你改同一段 code 也沒事,直接 merge 就好… 只有真的很背的時後,有人跟你改同一段,那麼後 commit 的人就要負責處理 merge 的問題。不過機率很低嘛 (沒錯,尤其是只有我自己用的時後),你可以不用管它…
過去用 VSS 常碰到這種情況: 原本只是開個文件起來看 (READ),跟本沒想要去改它,就沒有先作 check-out 的動作了。不過看到一半發現內容有誤,想要修正時… 問題就來了。以 WORD 來說,已經開起來才去 check-out 檔案的話,WORD還是會認為檔案是唯讀的… 除非你關掉 WORD 再開啟一次才有用。不過這麼一來思緒都被打斷了…。
當然,還是一樣,正規的開發動作還可以要求,一般的文書處理要求到這樣就有點過頭了。因此 SVN 這樣的邏輯就佔了點優勢,我最常碰到的案例就是: 要出門開會,把 USB_DISK 拔出來帶走。開會過程中 (在外面,沒有網路連線) 修修改改 PPT 的內容,回到公司後直接在 NB 或是把 USB DISK 插回 PC,再用 SVN 作 commit 的動作…。
-
SERVER 的資訊跟著目錄
有些工具 (像是 TFS),你的工作目錄對應到那個 SERVER,是工具在維護的 (TFS 的 workspace),這時搭配 USB DISK 可能會在不同的電腦 (可能是我的 PC,也可能是我的 NOTEBOOK,甚至是帶回家裡用)。一般把設定綁在工具上的作法就很頭痛,因為好幾台都要設成一樣的,而且 USB DISK 還有可能每次的磁碟機路逕都不大一樣…
我用的工具是小烏龜 (TortoiseSVN),它的設定就是在每個目錄下放個 .svn / _svn 的子目錄,檔案總管按右鍵叫出 SVN 的選單後,藏在裡面的設定就自動套上來了。這種操作模式,剛好對於我的用法 (USB_DISK) 很方便…
-
更精確,更有效率的 “備份機制”
現在隨身碟廠商,都很愛在商品上加一些小工具,有的有壓縮,有的有密碼保護… 不過 USB DISK 很容易掉,所以所有廠商都不會忘記附上一個備份工具。連我前面介紹的 PortableApps.com 都有附一個 ( 7-ZIP + SHELL )。不過這些備份工具都有個通病… 它就真的只是 “備份” 而已,是讓你心安的。使用時機是你自己要勤勞點,記得每天按 BACKUP。要還原回來,通常就是整支 USB DISK 的內容都還原回來了,如果你只想要還原某幾個檔,或是只要查看過去備份的某個檔,那你得點好幾下滑鼠,甚至是要把整個備份解開才看的到。
另一個備份問題是,每次都是 FULL BACKUP … 雖然有些工具作的比較好,有差異備份 ( PortableApps.com 就有提供 7-ZIP 的差異備份),不過不還原還好,一旦要把舊資料撈出來也是很辛苦。當然這些並不是備份工具的錯,備份本來就是作這些事。中間有落差的地方在於 USER 需要的是一個歸檔的機制啊,除了備份也需要調閱舊的版本內容。這時版本控管工具,正好就成為 USB DISK 在 PC 上的第一線 “備份資料庫” 了。當你在 check-in / commit 時,不自覺的就在版本系統內放了一份備份了,不放心的人可以再啟用像 VSS (Volume Shadow Copy Service) 或是定期壓 ZIP 這類一般的備份機制作第二層保護,就很足夠了。
這裡的重點倒不是備份安不安全啦,而是這樣的操作方式,很自然的就會在 SVN Repository 內留下一份內容,同時也方便你替這個版本作註記,未來要調閱,甚至是比對內容差異都很容易…
-
異地存取
USB DISK 雖然很方便,也可以隨身攜帶,但是我就是會常常忘掉它… 常常忘了拔就出門… 在外面如果還要存取我的 USB DISK 的內容,有網路的話,版本控制系統也很好用。我用的 SVN SERVER 是 Visual SVN,它就有個很簡易的 WEB 介面,真的忘了帶還可以連回我自己的 PC,把檔案下載回來。
如果用的電腦有灌 SVN CLIENT,那你還可以做些基本的操作…。這套比起來就比 VSS 強的多。VSS 完全是 file system base, 透過遠端的操作必需先用網芳之類模擬 file I/O 的方式,效能很糟糕… 雖然 2003 年左右 Microsoft 替 VSS 加其了很多功能,像是 LAN Boost Service (我搞不懂它怎麼做的),或是替 VSS 加上 Web Service Interface (可以透過 HTTP),不過效果都不盡理想。
這些功能加一加,就是我現在在用的個人檔案管理方案了啦。家裡有台現成 SERVER,很多問題就更好解了。這套作法正好给有需要的人參考看看,如果你用了有什麼心得,或是有其它更好的用法也歡迎分享 :D
-