-
CaseStudy: 網站重構, NGINX (REVERSE PROXY) + 文章連結轉址 (Map)
網站架構調整後有感: 要學習另一個陣營的技術,還真是條不歸路,越挖越覺得要摸索的東西越多 @@ 照例前面先來點碎碎念,正題後面再來。這年頭,大型的佈署是少不了 Linux + OpenSource Solution 的,再加上我吃飯的傢伙 ASP.NET 的下一版 (vNext, .NET Core) 也要正式跨各種平台了,不熟悉一下 Linux 以後怎麼會有能力把寫出來的 code 搬到 Linux 上面執行? 不過,要跨到完全另一個生態體系的環境,還真要下點決心才跨得過去… 所幸,我挑對了切入點 (把自己的 BLOG 從 BlogEngine 轉移到 WordPress, 架設在 NAS + DOCKER 環境),這幾個月下來,也算累積了不少的心得 :D 要在 Linux 的世界裡打滾,最痛苦的就是安裝各種軟體了,只能說那真是地獄… @@,尤其是對於不熟 Linux 的人來說更是如此。現在有各種套件安裝的工具,向是 APT-GET 之類的,其實已經簡化很多了,但是難的在後頭,各種的 configuration 都要自己編 conf 檔,而每套系統用的語法都不一樣… 我不論是在 Coding 或是 System Admin 時,都很講究系統架構。因此往往預設的安裝我都不滿意,我都會想盡辦法用最基礎的模組,搭建出我認為最理想最適合的架構。很多組態都必須自己研究摸索,都需要碰到進階的安裝設定,這也是要開始認真用 Linux 的我最大的障礙… 然而我的目的不是要熟悉這些 configuration 啊,我目的是架設出期望的系統,來解決後續的問題,這些繁瑣的安裝設定機制 (除非必要,像是這篇要講的 Rewrite ) 就能省則省… 所幸 Docker 的出現,正好給了我這種人一個機會,我只要搞定最基本的 Docker 執行環境,其他安裝就簡單了,找到正確的 container image 就一切搞定。加上我用的 NAS 內建 Docker 的支援,連 Linux + Docker 架設都免了… 至於為何要這麼大費周章的熟悉 Linux ? 轉貼一則最近看到的新聞… 連 Microsoft CEO Satya Nadella 都公開表示 “Linux is Best for Cloud” 了,多年的 Microsoft 信徒軟絲當然要花時間去研究一下.. XD

Microsoft Agrees Linux is Best for Cloud
Ever since the new CEO, Satya Nadella, has taken the place of the Linux-hater Steve Balmer, the change in Microsoft’s rhetoric regarding Linux has been clear. Now, Microsoft is officially recommending Linux on Twitter.
好,看到分隔線,就代表正題開始! 前面幾篇有跟到的讀者們,應該都知道我之前在研究甚麼.. 為了在我能力範圍內用最快的方式搭建能夠執行 .NET Core 的 Linux 環境,我選用了 Synology NAS + Docker 來踏出第一步. 為了快速熟悉各種實作技巧,我把自己的 BLOG 從原本的 BlogEngine ( ASP.NET ) 轉移到 WordPress (現在還是 PHP, 以後要變成 Node.js 了)。前兩篇說明了用 Apache 做前端的 Reverse Proxy, 同時也為了 新舊系統的文章轉址,用 Apache 的 RewriteMap 解決 400 篇文章 x 6 種網址格式,多達 2400 種組合的新舊網址轉址。 就當越用越熟練之際,我擔心的問題來了! NAS 再好用,他終究不是正規的 SERVER … NAS 的硬體都不怎麼樣,我的 Synology 412+ (Atom 2701D + 2GB RAM) 很快地就碰到瓶頸了,多開兩個 container 就明顯 的感覺的到回應變慢了… 於是我決定開始把我的 BLOG 系統轉移到 Ubuntu Server 上,用專屬的硬體來架設 (NB)。架設的硬體其實也很巧,是我老姊請我幫她處理掉的舊 NB。拿舊的 NB 其實很適合,一來省電,二來 Linux 省資源, 跑 Windows 跑不動,換成裝 Linux 跑個人 BLOG 其實還綽綽有餘,三來 NB 內建的電池正好當成 UPS,也省了一筆開銷… 。接手的 NB 硬體只是貧弱的 Intel Pentium P6100 + 4GB RAM,不過不管在運算能力或是 RAM 都遠比 我現在的 NAS 強… 於是架好 Ubuntu Server + Docker 後就開始動手了
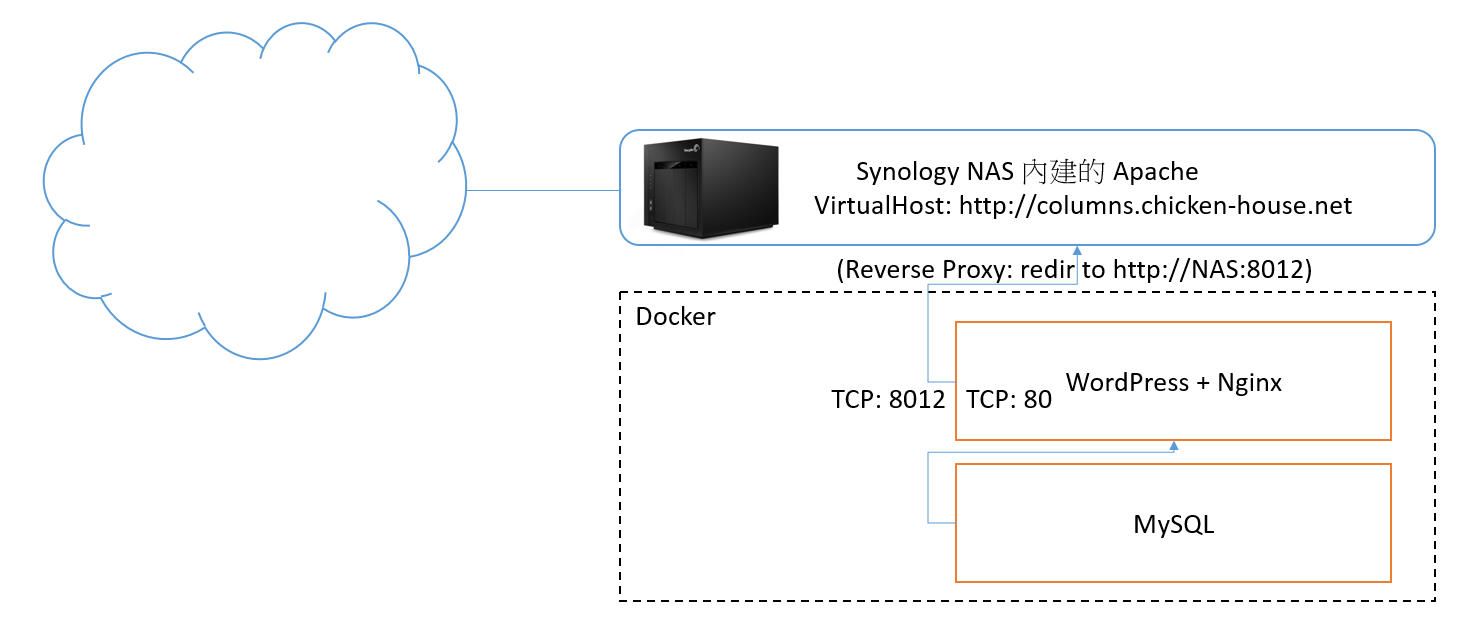
先來看看這次我想調整的架構圖。第一張圖是現有的架構,就是兩個月前剛轉移 BLOG 用的架構:
 第二張是我想調整的新架構,也就是這次要做的:
第二張是我想調整的新架構,也就是這次要做的: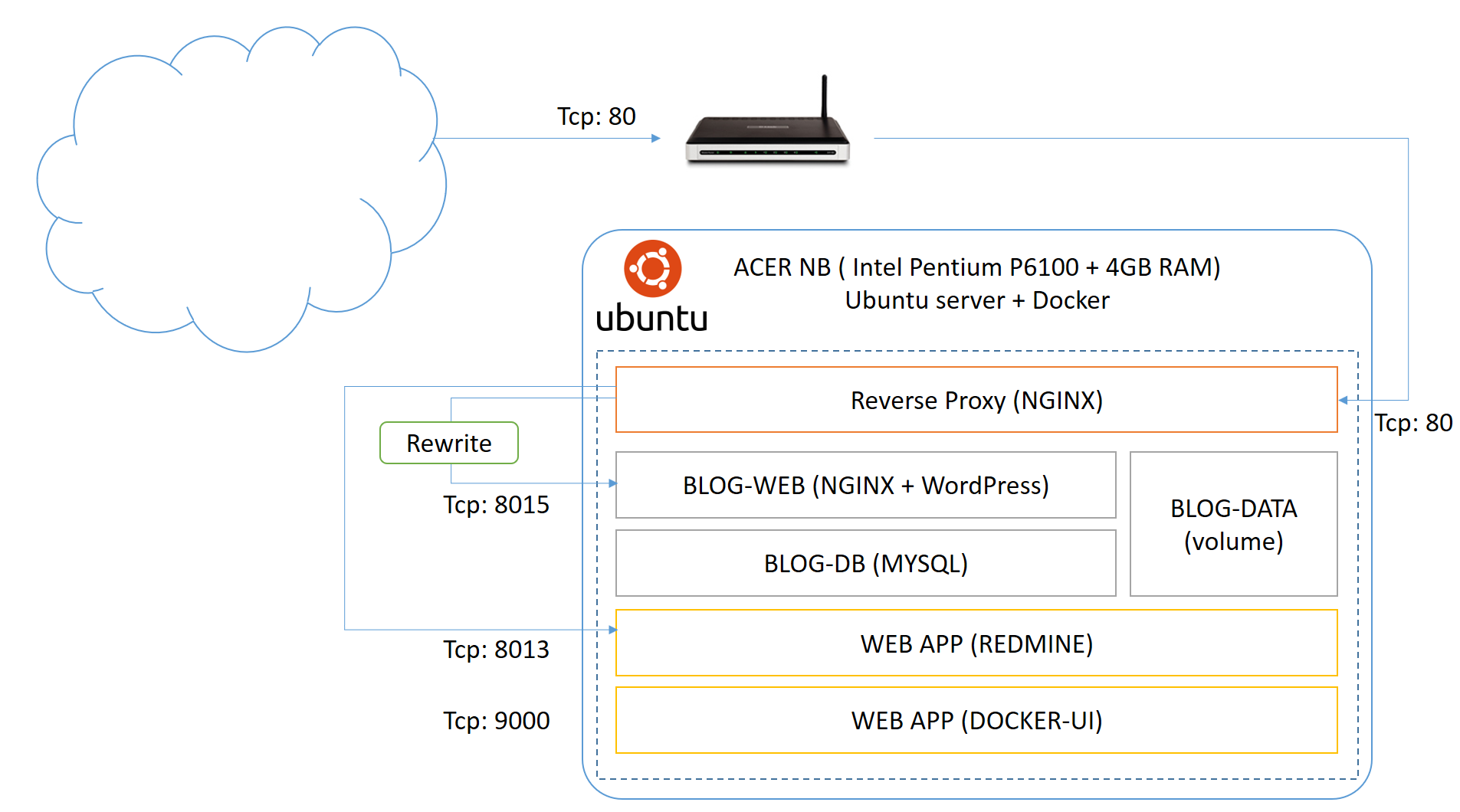
這次的調整,我決定沿用之前的架構,就是前端用 Reverse Proxy 來發布藏在後面的 WEB application, 因為後面有好幾個 Docker Container 需要同時用一個 IP + 80 port 發布,這層是跑不掉的。加上大量舊網址轉址的需求,我不想把這個複雜度加在 WordPress 上面,所以這需求就落在 Reverse Proxy 身上。原先的架構中,Reverse Proxy 是用 Apache Httpd 來負責 (因為 NAS 內建 apache httpd, 而且已經把 port 80 佔住了,沒辦法換掉),現在自己架設 Ubuntu Server 就沒有這些限制,我當然就改用現在當紅的 NGINX 來代替。 既然都用 Docker 了,其實找到正確的套件,設定一下就搞定,單純系統安裝的部分我就跳過去了。架構上調整的兩個較大的工程我補充一下:
- 前端 Reverse Proxy 的部分,改用 Nginx 。這邊面臨的是上一篇文章說明的轉址技巧,還有對照表的部分必須重新來過,改用 nginx 的 conf 重新設定一次。
- 原本架構只用了兩個 container, 分別負責 WEB 及 DB,資料檔案是直接掛上 local server 的目錄。這次則按照 Docker 官方建議,建立了專門管理資料用的 VOLUME-CONTAINER。
調整後的架構跟效能,應該都會遠比原本的好。直到現在用了 Docker, 才開始對當年學 UML 的 deployemnt diagram 有感覺… 後來 Visual Studio Team Suite 也出現過這個功能,可以繪製 deploy diagram (強的是還能跟你實際的 code 雙向同步)。但是當年的實作上,總覺得實際要處理的問題遠比 diagram 要複雜得多,系統架設跟UML表達的架構,中間距離還很遠,往往高階架構都只在架構師腦袋裡,真正執行的工程師則被一堆設定的細節給淹沒了,直到現在有了 container 技術,才開始覺得佈署系統就真的跟 deployment diagram 上講的是同一件事,真的就是把元件拉出來,按照設計圖一個一個擺到定位,線接一接就完成了。 Volume-Container 的應用,有機會再另外寫一篇吧,先來看看 NGINX Reverse Proxy 的部分: 在上一篇在解決新舊系統網址對應最主要的技巧,就是如何簡潔又有效率地做好 2400 條轉址的需求。主要就是用 Apache 的 RewriteMap 來兼顧 Rule 的撰寫及對照表的維護。而同樣的機制,在 nginx 上也有,不過語法不大一樣,我先貼一段 example:
# map blogengine with slug (encodded title) format if ($uri ~* "^(/columns)?/post(/\d+)?(/\d+)?(/\d+)?/(.*).aspx$") { set $slug $5; return 301 /?p=$slugwpid; }Nginx 的 Map 簡潔到不能再簡潔了,加上他用的 C Like 設定擋語法,老是讓我有個錯覺,覺得我在寫得是 script 而不是在寫設定擋… 然而簡潔到極致的 Map 用法,我看了半天才看出他的端倪… 上面這幾行,背後有條看不見的線,把 $slug 跟 $slugwpid 這兩個變數串起來… 當我把某個數值 assign 給
$slug時,Map 的機制就會偷偷的啟動,用$slug的值去查表,把查到的結果放到$slugwpid, 然後接著 run 後面 的 script / config. 上面這幾行,意思就是每個 request, 會把他的 URI 部分 (不含 hostname) 抓出來,用後面的 regular express 比對, 抓出第五個match ($5)的內容,指定到$slug這個變數內。接著透過 MAP 的機制,下一段指令return 301 /?p=$slugwpid;就是 用 HTTP 301 的方式轉址,轉到/?p=xxxx這樣的網址。 這看不到的機制,靠的就是整個 nginx 設定擋的另一個部分定義 MAP 的效果:map $slug $slugwpid { include maps/slugmap.txt; * 0; }Map 這精巧的機制想通後就很簡單了,Map 的宣告後面直接接兩個變數,一個是原變數 ($slug), 另一個是查表後對照的結果變數 ($slugwpid)。你在任何地方把數值指定給 $slug 的話,同時間另一個變數 $slugwpid 的值就會被替換掉。 說穿了不值錢,這些可是我研究了好一陣子才搞懂的。研究的過程中我也去找了 NGINX for Win32, 這樣測是起來比較方便,有需要快速體驗或測試 nginx 的朋友可以參考。用這個來研究設定擋的寫法,可以省掉很多時間 (畢竟我還是 windows 操作比較熟悉…) 最後就是對照表的定義了。NGINX 的設定蠻有彈性的,如果你的對照表不多,可以直接寫再 CONF 裡面就好。不過我的狀況有四百多篇文章,我選擇放到外部檔案再引用。我貼片段的對照表內容出來:
GoodProgrammer1 65; # 2008/09/27, 該如何學好 "寫程式" ?? IBM-ThinkPad-X111- 252; # 2005/06/28, IBM ThinkPad X111 ... e6b0b4e99bbbe5b7a5e697a5e8aa8c-1-Cable-TV-e99da2e69dbf 146; # 2007/09/12, 水電工日誌 1\. Cable TV 面板 e5a682e4bd95e59ca8e59fb7e8a18ce6aa94-(NET)-e8a3a1e99984e58aa0e9a18de5a496e79a84e8b387e69699 180; # 2007/02/28, 如何在執行檔 (.NET) 裡附加額外的資料? X31-2b-e99b99e89ea2e5b995e79a84e68c91e688b0-_ 273; # 2005/03/06, X31 + 雙螢幕的挑戰 @_@ e588a9e794a8-NUnitLite2c-e59ca8-App_Code-e4b88be5afabe596aee58583e6b8ace8a9a6 215; # 2006/10/29, 利用 NUnitLite, 在 App_Code 下寫單元測試格是很簡單,就是新舊對照的值,一筆一行。兩個字串用空格隔開,最後用 ; 結尾。如果有需要的話, # 之後的字串會被當成註解忽略掉,就像上面這樣。還好這格式跟之前 Apache 用的 RewriteMap TXT 格是很類似,我用文字編輯器簡單替換一下其實就搞定了 看了 NGINX 官網的說明,他的 MAP 彈性大很多,除了靜態的字串對應 ( key / value pair ) 之外,可以包含萬用字元,也可以包含 Regular Express, 也就是說他也包含某些運算能力在 Map 裡。我擔心的是這麼一來 MAP 也許就無法像 Apache 一樣,把 Map 編譯成二進位的 Hash table 格式,大量查表的效能也許會受影響… 這邊我就沒有像上次一樣查 benchmark 了,不過新環境運算能力本來就強很多了,同時 nginx 本身效能也比 apache 強的多,加上我的舊文章數量又是固定的 (400),數量還不算太大,也不會再繼續成長下去,測試過沒有明顯的影響,我就暫時不理它了 XD 好! 寫到這邊,其實搬家動作大概就告一段落。雖然如此,也是花掉我幾個下班休息時間才搞定的… 我想應該很多人跟我一樣,想從熟 Microsoft 領域,跨越到 Linux / Open Source 的領域而不得其門而入的困境吧? 我這系列文章都會用實際的案例,說明我 “為什麼” 會這樣做,而不是只有單純的 step by step. 畢竟比我熟這些操作的人太多了,人外有人.. 這應該輪步道我來寫。而我真正想分享的,是這些架構規劃面的經驗。希望我這些實作的案例 & 紀錄,可以幫到跟我一樣從 Microsoft Solution 要跨越到 Linux 這邊的人 :)
-
Case Study: BlogEngine -> WordPress 大量(舊)網址轉址問題處理
前情提要:
起因很簡單,上個月才把我的 BLOG 從 BlogEngine 轉移到 WordPress… 這種轉換系統一定會碰到的問題,就是新舊系統的 URL 格式一定不一樣的,不過好不容易累積起一些文章連結 (別人連到我的文章) 不處理的話,這些連結就失效了。算算文章數量,約 400 篇.. 統計一下每篇文章可能連到的格式,有 6 種,若不放掉每個連結,則有 400 x 6 = 2400 個連結要轉換..
究竟,在 Apache 做這麼多網址轉換的動作,怎樣才是最理想的方法? 這就是這篇文章想探討的… 讓我們繼續看下去 :D
到底有多少舊網址要轉換?
人家說做事要講究事實,開始動工前,先來了解一下到底有哪些情況需要轉址? 我之前用的 Blog 系統是 ASP.NET 寫的 BlogEngine 1.6, 算是老字號的 .NET 部落格了,先從我知道的開始:
預設的格式:
最基本的格式,按照日期 (年/月/日) 後面加上編碼過的文章標題。用我最常被引用的這篇當例子,像這樣:
http://columns.chicken-house.net/post/2008/07/10/GoodProgrammer1.aspx (這是第一類)
不過,不知哪個版本開始,多了 multi-tenancy 的概念,所以系統允許多個部落格同時存在,有些網址就多了這層路徑:
http://columns.chicken-house.net/columns/post/2008/07/10/GoodProgrammer1.aspx (這是第二類)
從 Google Search Console:
本以為這樣就結束了,順手開啟 Google Search Console 看看新上線的 WordPress 被檢索的狀態… Ouch! 狀況還真不少…
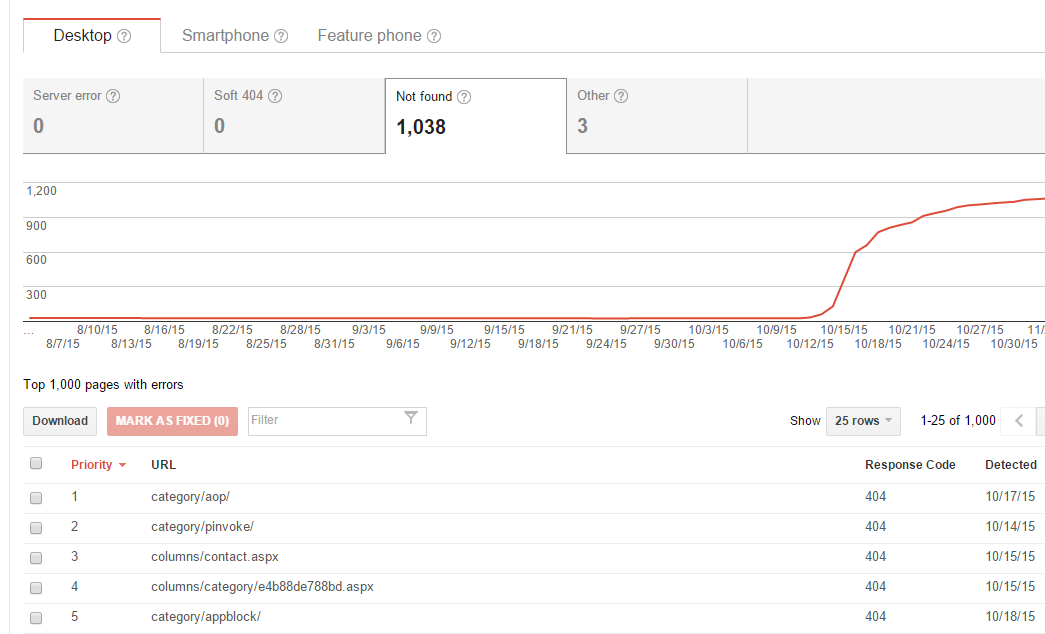
Google WebMaster Tools 還真的是好工具,幫我挖出了很多想都沒想到的連結。這是列出來 Google 認為應該存在的網址,卻檢索不到的清單及統計。從統計圖看的到,10/10 換完系統之後檢索錯誤的狀況就暴增,很明顯地這些都是轉換系統後產生的問題… Google 提供下載 .CSV 清單,要確認就方便多了..
用肉眼逐條歸納,發現了好幾種我連想都沒想過的連結格式 @@,包括這種不包含日期的格式:
http://columns.chicken-house.net/post/GoodProgrammer1.aspx (這是第三類)
http://columns.chicken-house.net/columns/post/GoodProgrammer1.aspx (這是第四類)
再挖下去,竟然還有… @@,這是直接用 post id (GUID) 當參數的格式:
http://columns.chicken-house.net/post.aspx?id=52e998ee-ee02-4a66-bb27-af3f4b16c22e (這是第五類)
http://columns.chicken-house.net/columns/post.aspx?id=52e998ee-ee02-4a66-bb27-af3f4b16c22e (這是第六類)
更扯的是,最基本含日期格式的 (第一類),竟然還找的到日期錯誤的 @@,這我就真的不知道怎麼來的了… Orz 這種無法預測的先當例外處理,晚點再說… 我算了一下,我總共有近 400 篇文章,如果不放過任何一類連結格式的話,共有這六種 URL format 得搞定:
http://columns.chicken-house.net/post/GoodProgrammer1.aspx http://columns.chicken-house.net/columns/post/GoodProgrammer1.aspx http://columns.chicken-house.net/post/2008/07/10/GoodProgrammer1.aspx http://columns.chicken-house.net/columns/post/2008/07/10/GoodProgrammer1.aspx http://columns.chicken-house.net/post.aspx?id=52e998ee-ee02-4a66-bb27-af3f4b16c22e http://columns.chicken-house.net/columns/post.aspx?id=52e998ee-ee02-4a66-bb27-af3f4b16c22e開始動手,設定 Apache 啟用 Redirect 轉址
在之前的文章就已經提到,我的架構是在 NAS 用 Docker 架設 WordPress, 前端用 NAS 內建的 Apache 擔任 Reverse Proxy 來負責前端。既然都有前端擋著了,轉址這件事也理所當然地讓 Apache 負責。由於實在對 Apache 不熟 @@,我就找了最簡單的方法,其他就… 勤能補拙,靠寫 code 產生正確的設定擋來搞定他,於是第一版就上線了!
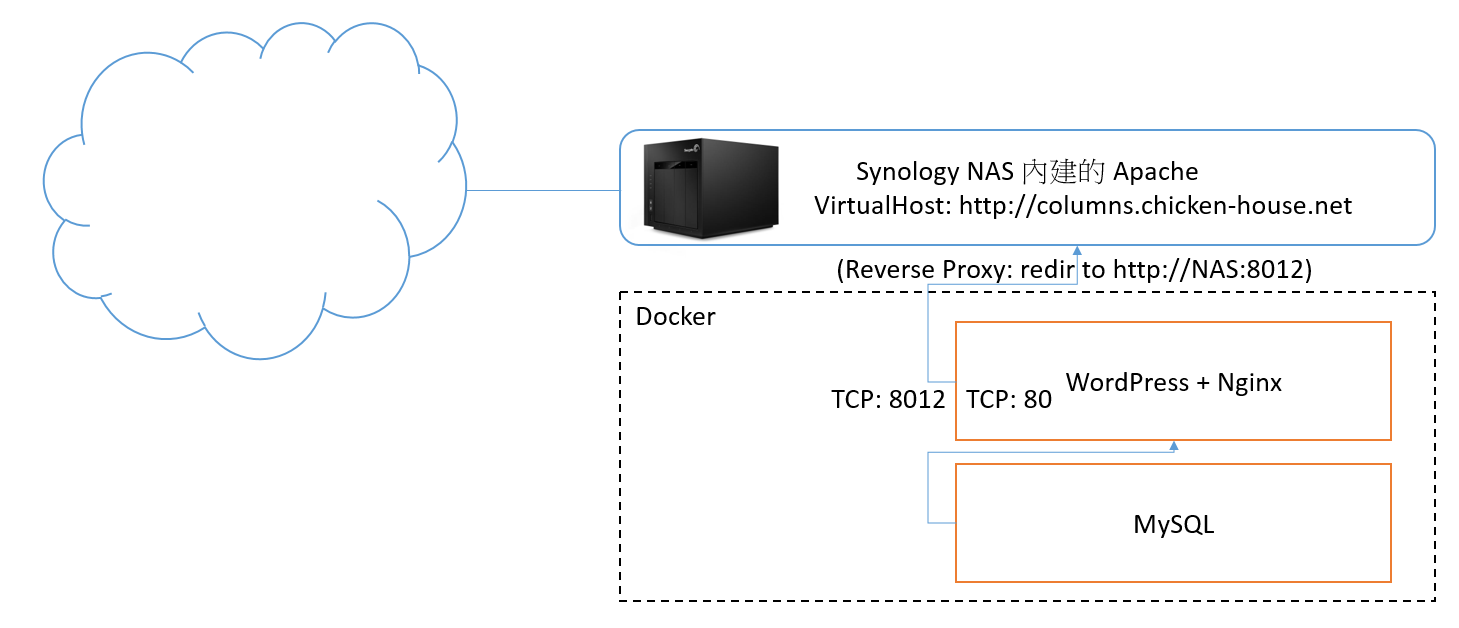 圖: NAS 架設 WordPress + Reverse Proxy 架購說明
圖: NAS 架設 WordPress + Reverse Proxy 架購說明找到 apache 最簡單的轉址方式,就是寫 Redirect 指令,Apache 會用 http status code 301 來轉,於是.. 如果要搞定全部的6種格式,得寫 2400 條 rules… 這種時候就很慶幸我自己會寫 code,搬出 Visual Studio 2012, 自動替這 400 篇文章產生這樣的 redirect 指令:
Redirect 301 /post/2008/07/10/GoodProgrammer1.aspx /?p=65 Redirect 301 /columns/post/2008/07/10/GoodProgrammer1.aspx /?p=65 Redirect 301 /post/GoodProgrammer1.aspx /?p=65 Redirect 301 /columns/post/GoodProgrammer1.aspx /?p=65 Redirect 301 /post.aspx?id=52e998ee-ee02-4a66-bb27-af3f4b16c22e /?p=65 Redirect 301 /columns/post.aspx?id=52e998ee-ee02-4a66-bb27-af3f4b16c22e /?p=65 # 以下略過這方法 “暫時” 解決我的燃眉之急了,的確可以把大部分的文章轉到正確的內容,不過連我自己都看不下去了,這樣做的缺點還真不少:
- 不好維護: 沒錯,這根本沒辦法手動調整了,要異動就得重跑一次 config generator 後再貼上… 不過,舊文章也不會變多,再怎麼樣就是那400篇,除了麻煩一點也還好
- 無法處理例外狀況: (對,就是上面提到竟然有日期錯誤的文章連結) .. 只要錯一個字就連不到了,但是若 BlogEngine 還在線上的話,是看的到文章內容的…
- 效能問題: 我一向最講究演算法跟時間複雜度了 XD,這 2400 條 rules, 我試著猜想看看 apache 會怎麼執行? 一定是每個 request 進來,就逐條判斷… 若第一條就 match 那還算簡單,要是每條都不 match 不就做了 2400 次白工? 何況沒 match 的一定是大多數..
有了這些想法,才有這篇文章的後續… 因此開始想其他解決辦法了 XD
改用 RewriteMap,用 RegExp 來判定格式, 解決例外狀況
Apache 有進階一點的轉址語法,是 RewriteRule .. 跟上一段 Redirect 不同的是,他可以靠 RegExp 來 Match, 之後可以替換出正確的網址… 比 Redirect 有彈性的多,於是上述 1 ~ 4 類格式,我可以用一條 regular expression 來 match:
^/?(columns\/)?(post\/)?(.+\/)?(.+\/)?(.+\/)(.*).aspx
看不懂嗎? 對,我也看不懂… Regular Expression 號稱 Write Only 的語言實在不為過.. 這條正規運算式,可以檢測出上述第一 ~ 第四類的格式,還可以把編碼的標題 (slug) 給抓出來… 因此我只要寫這條 rules ,就可以取代上個例子的四條 redirect 指令:
RedirectMatch 301 ^/?(columns\/)?(post\/)?(.+\/)?(.+\/)?(.+\/)GoodProgramer1.aspx /?p=65
不過,這樣改下來一樣有 400 條啊,三個問題裡,第一個維護問題沒解決,第二個例外處理有解決,第三個效能問題… 雖沒實測,但是我直覺告訴我,應該不會好到那裡去吧?
大量使用轉址指令的效能問題探討
於是我就開始 google 大量轉址的效能問題.. 效能應該都花在大量比對 rules 上,屬於 CPU 密集的運算,這種吃 CPU 效能的運算,我在 NAS 上貧弱的 CPU 跑起來,執行時的影響更大啊… 不解決不行,查了幾篇有關這種大量 redirect 的效能問題,這篇是我覺得最有說服力的一篇,直接貼一張圖來看就知道差別:
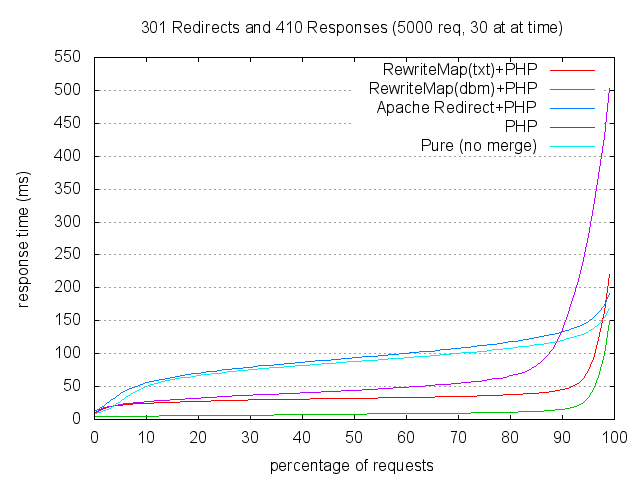
先解釋一下這張圖怎麼看。測試案例裡面,用了 benchmark 不斷的去點擊大量的網頁。被測試的 apache 設定了 1500 條轉址,而不同顏色的線則是用了不同的方法來寫這些 rules.
圖表的 Y 軸代表點擊網頁的回應時間 (越短越好),X 軸則代表有多少比例的點擊數回應時間最大值落在哪裡.. 簡單的講,曲線越低的做法越好啦!
我用的第一招,就是 Apache Redirect, 慘不忍睹… RewriteRule 基本上也屬於同一層級的,也沒好到哪裡.. 看到還有另一招 RewriteMap ! 效能出奇的好,大約只花了 1/10 的回應時間… 這是甚麼? :D
改用 RewriteMap 來實作 Apache 轉址機制
終於看到一道曙光了! 研究了一下,果然這才是適合我用的好物! 先看看官方文件: Using RewriteMap !
RewriteMap 就像是 C# 裡的 Dictionary<string, string> 一樣,提供你一個快速有效的 Hash Table 去查表。Hash Table 的時間複雜度是 O(1), 不受你的資料筆數影響,是很理想的做法。單純的 regular expression 就是沒辦法做這點,我才需要寫 400 條 rules 啊! 找到這做法之後,改寫果然簡單多了,改寫後變這樣:
RewriteEngine ON RewriteMap slugmap "txt:/volume/slugmap.txt" RewriteRule "^(/columns)?/post(/\d+)?(/\d+)?(/\d+)?/(.*).aspx" "?p=${slugmap:$5}" [R=301,L]真正的 match 比對,一行就搞定了。當然,要搭配他提供另一個文字檔當作對照表,像這樣把全部 400 篇的 slug-id v.s. wp post id 對照表列出來:
# blogengine post slug ==> wp post id RUNPC-2008-11 52 VCR-e5b08fe79aaee887aae5b7b1e8b2b7e5a49ae5a49a 225 e6b0b4e99bbbe5b7a5e697a5e8aa8c-5-e9858de68ea5-cable-e7b79a 142 e58d87e7b49ae5a4b1e69597-Orz 201 e6adb8e6aa94e5b7a5e585b7e69bb4e696b0-CR2-Supported 197 e6adb8e6aa94e5b7a5e585b7e69bb4e696b0---CR2-Supported 197 Community-Server 281 x86-x64-e582bbe582bbe58886e4b88de6b885e6a59a 85 e58e9fe4be86-XmlWellFormedWriter-e4b99fe69c89-Bug- 48 e5808be4babae6aa94e6a188-2b-e78988e69cace68ea7e588b6 40 video-e5b08fe79aaee887aae5b7b1e59083e69db1e8a5bf-II 244改用這個做法,原本的效能問題,就分兩個部份解決掉了。一來需不需要進行轉址,只需要進行一次 regular expression 計算就能知道。每一個 http reques 不會浪費太多時間去重複 400 次的運算。如果 match 成功需要轉址,用 hash table 查表也很快,完全不會受到 400 筆的影響..
繼續查下去,文字檔的效能還是稍差,所幸 apache 有提供工具,可以把它編譯為二進為 dbm 檔案,效能更好.. 細節我就不多說了,官方文件都有寫..
成效評估
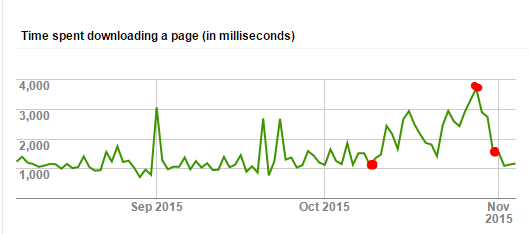
其實效能到底有沒有改善很多,我是不曉得啦,但是光是衝著好維護這點就值得做了。我一樣從 google webmaster tools 抓了檢索的回應時間統計來看,我標上三個時間點,由左到右,依序是:
10/11: 將部落格從 GoDaddy Web Hosting (BlogEngine) 搬回家,用 HiNet 光世代 (PPPoE 取得的固定IP),架在 Synology DS-412+ 上面架設的 WordPress. 這時間點之後很明顯地看到效能掉下來了,回應時間暴增,可能跟網路 & NAS 的效能較差有關。
10/28: 由於一直覺得搬回來之後 BLOG 跑很慢,於是下載了 W3 Total Cache 這個 WordPress 的 Cache 套件來用。啟用 Cache 之後效能就快速提升了
11/01: 進一步啟用這篇文章說明的 RewriteRules 改善及最佳化工程,回應時間繼續下降,到目前為止,已經降到跟 10/11 之前一樣的水準 :D
從結果來看,很明顯地搬回來後被 NAS 的效能給拖下來了,回應時間從原本的 1 秒左右飆到 4 秒.. Cache 啟用後看來大幅改善 NAS 效能問題,而改善 Apache Rules 寫法理論上又更進一步的改善效能.. 也讓 rules 好維護的多。更重要的是回應時間回復到之前放 GoDaddy 代管的水準… 其實能做到這樣,BLOG 搬回家其實也不錯啊… :D
這次改善計畫,唯一的缺憾就是,觀察的不夠久就開始改用 RewriteMap ,還沒有足夠的數據來看看改用 RewriteMap 實際上到底有多少改善… 我也無從判斷起11/01厚的效能改善,是 cache 還是 rewritemap… 不過這樣其實也夠了,光是能用更少的 rules, 理論上 更好的效能,可以達到更好的舊網址相容性,降低檢索錯誤的數量,其實我也該滿足了 XD
看來這次的研究沒有白費,寫篇文章紀念一下,下個禮拜再來看看改善的狀況 :D
成效評估 (2015/11/09 更新):
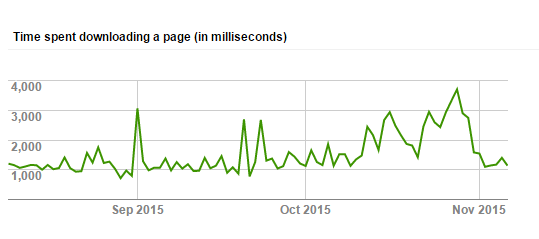
補上 2015/11/09 從 google search console 看到的狀態,在轉移系統前 (2015/10/10 前),Not Found 的網址穩定的維持在 25 筆,轉移後一直沒有好好的處理這個問題,直到處理完之後 (11/5) 才寫了這篇文章,將 google 回報的一千多筆 404 Not Found 網址全標記為 “已解決” 之後讓 google 重新檢索,目前只回報了仍然有 6 個網址檢索後仍是 404 … 不過看了看網址內容,加上看了來源是哪裡來的,就決定不理她了 XD
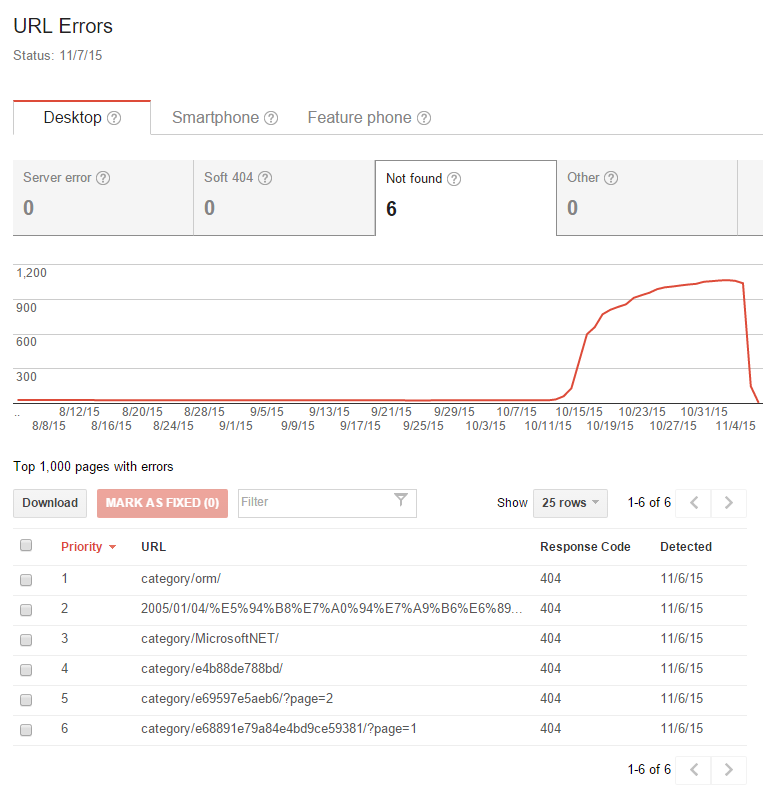
另外,再看看透過 google 檢索我的網站的回應時間。看來經過調整改善後,回應時間的水準也穩定下來,這水準已經跟當初 Hosting 在 GoDaddy 那邊的水準不相上下了,老實說我本來預期會慢上一截的,現在有這種表現,其實還不錯啦,可以接受 :D
成效評估 (2015/11/13 更新):
Google Search Console 總算提供到 11/11 的統計資料了,離 RewriteMap 機制上線的時間 (11/06) 已經五天過去了,可以來檢視成果了 :D
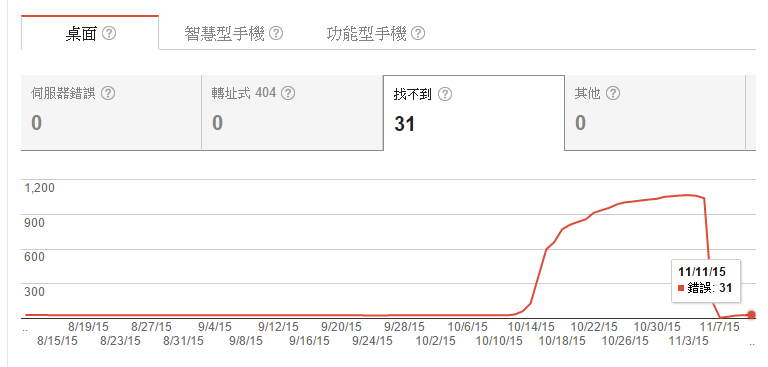
一樣,先來看看 404 not found 的數量。跟 11/09 的統計差不多,略增加了幾筆,不過增加的就真的是應該回應 404 的錯誤連結了,看來這部分沒有問題,可以收工了。
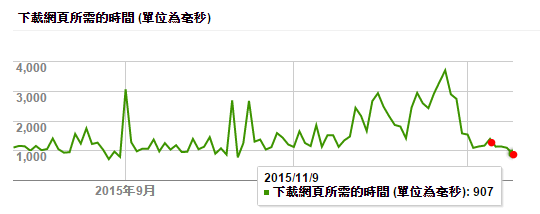
接下來來看看回應時間的改善。由於之前才剛啟用過 WP cache plugins, 因此大部分的效能改善是來自 cache 的關係。多了五天的 LOG,其實是可以多看出一些端倪的。上圖我標了兩個紅點,由左至右,第一個是 11/6,就是改用 RewriteMap 機制的時間點。在那之前可以看到因為 cache 帶來的效能改善已經穩定下來了,開始持平。 11/6 ~ 11/11 還有些微的改善 (平均回應時間從 1130ms 下降到 907ms),這部分除了 RewriteMap 之外就沒有任何其他異動了。看來 2400 條 rules 改寫之後,在 NAS 這種運算能力不高的系統上,改善還算明顯,約有 15% ~ 20% 的改善,算是超出預期的收穫了
-
同場加映: 用 Synology NAS 的 Docker 環境,執行 .NET Core CLR Console App

繼上一篇講完我落落長的研究過程後,這篇補上昨天想寫最後卻沒加進去的內容,就是一樣的動作改用我自己的 NAS 所提供的 Docker 環境來做 (官網)。試過之後只有一個感想… 果然買現成的實在輕鬆太多了 XD,如果不是很在意效能,只是想有個環境驗證看看,想避開整套 Linux 從無到有的 setup 過程的人可以試看看!
廢話上一篇都講過了,直接進入主題.. 這步驟跟昨天的比起來,實在是簡單太多了,這篇改一改就變成葉佩雯了,以後寫 ASPNET5 的人應該都去買台 NAS 才對… 不知以後會不會有 Visual Studio + NAS 同捆包? XD
以下是 step by step 的步驟:
開發環境準備: Core CLR 版 “Hello World !”
-
開啟 Visual Studio 2015, 新增專案。這邊要留意的是專案類型,不知 RTM 後會不會改.. 我是找 Visual C# / Web / Console Application (Package) 才找到的, Console 歸類在 Web 下是有點怪.. 這邊的專案才是支援 Core CLR 的版本。建立名稱為 “HelloCoreCLR” 的新專案
-
左上角 runtime 切到 DNX Core 5.0,補上一行印出訊息的 Code,按下 Ctrl-F5 執行
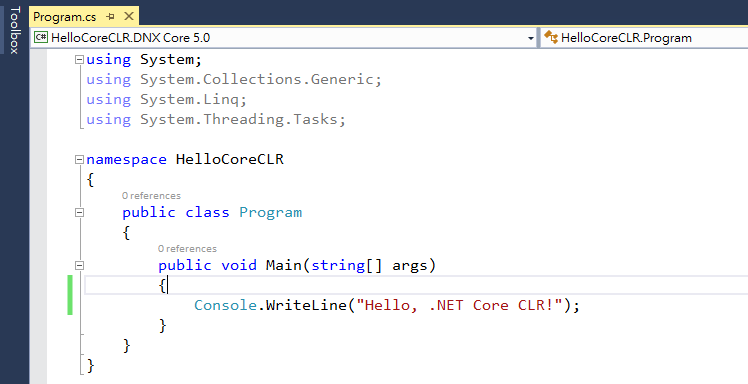
-
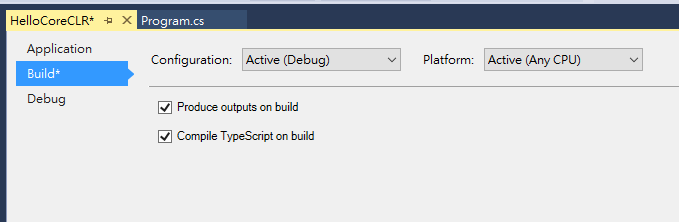
專案的設定頁面,記得勾選 “Produce outputs on build”, 才看的到編譯好的輸出檔案.. 設定完之後存檔,BUILD,到 solution / artifacts / bin / 下可以看到編譯好的檔案
編譯後的輸出,目錄結構跟過去不大一樣:
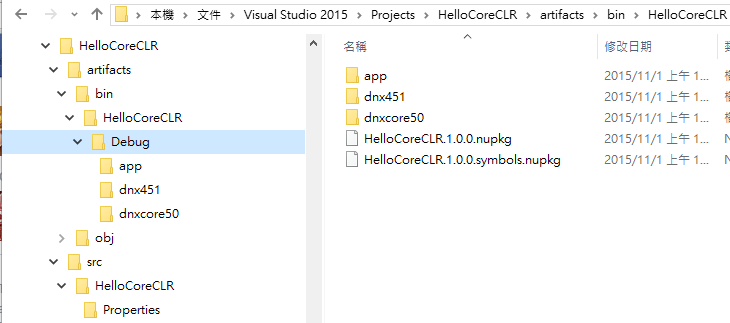
事前準備: NAS + Docker
-
NAS 安裝 Docker 套件。我只有 Synology 的,Q 牌的用戶就抱歉了~
裝這個套件:
-
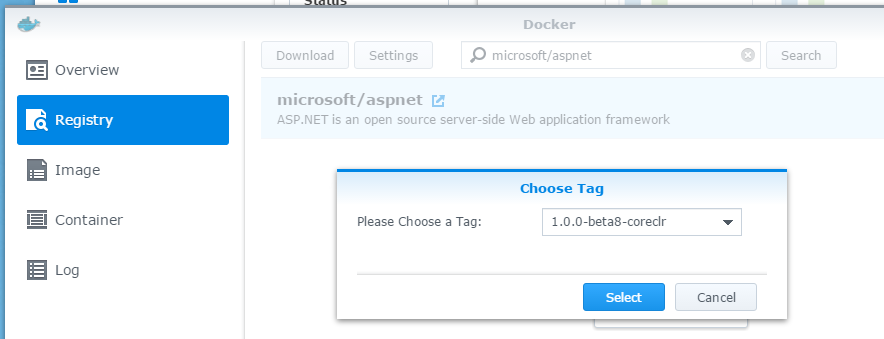
到 Docker / Registry 搜尋 image, keyword: microsoft/aspnet, 我是指定 tag: 1.0.0-beta8-coreclr
-
image大小約 350mb, 完成後 DSM 會通知,到這邊準備動作就完成了
佈署與執行
-
Launch Container, 這動作等同於 docker run 這個指令。選取剛才下載的 image, 上方的 “launch” 按下去之後就有精靈引導你設定。
-
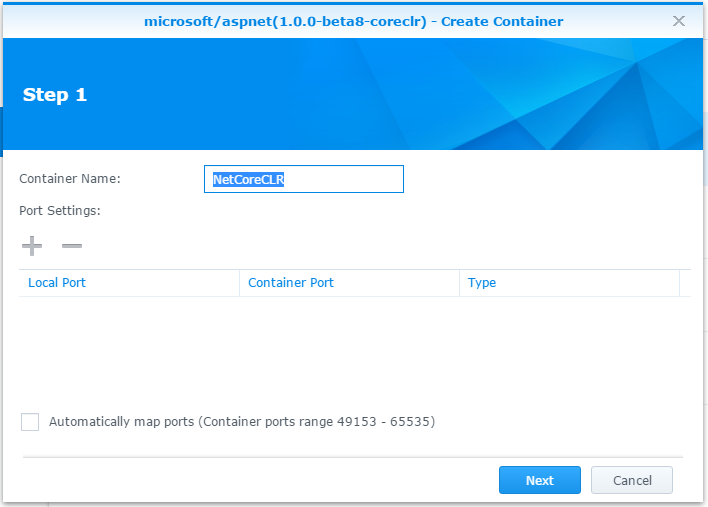
Step 1. Container Name: NetCoreCLR
-
Step 2, 資源限制跳過
-
按下 “Advanced Settings”, 加掛目錄到 container 內,等等可以簡化把檔案丟進去的過程。把 NAS 的 /docker/netcore 目錄,掛載到 container 內的 /home 目錄下,取消 ReadOnly 的選項。
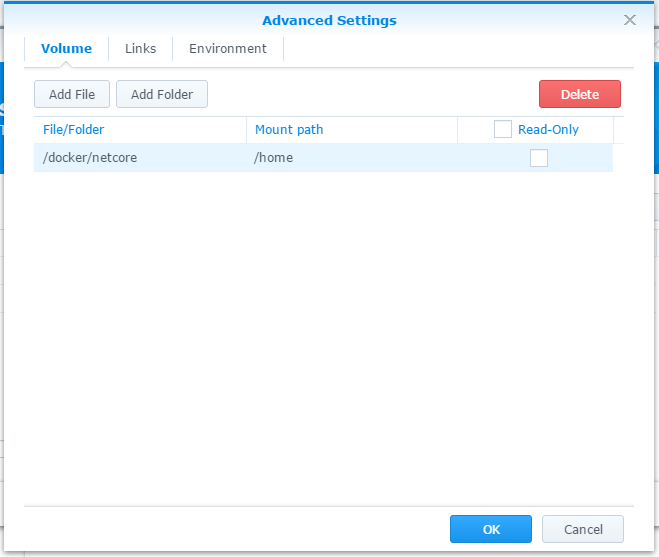
完成後按下 Apply 完成設定
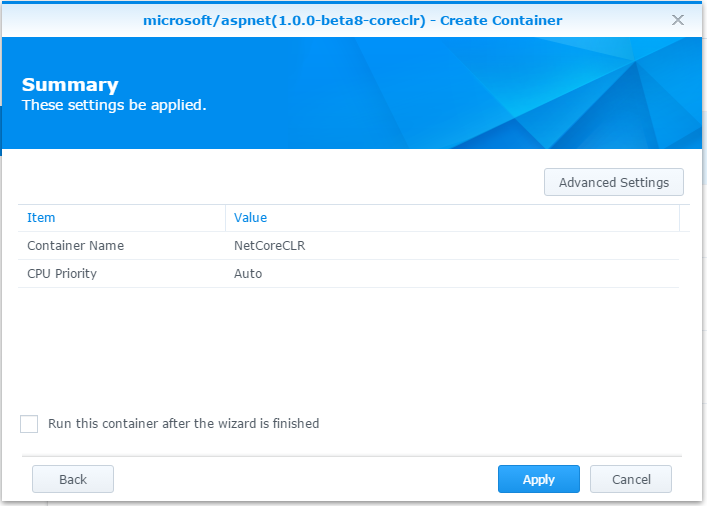
最後記得,把剛才 Visual Studio 2015 編譯出來的檔案,COPY 到 NAS 的 /docker/netcore 目錄下。
-
完成之後,Docker Container 清單應該就會多一項 NetCoreCLR, 右邊開關打開就可以啟動這個 container 了。
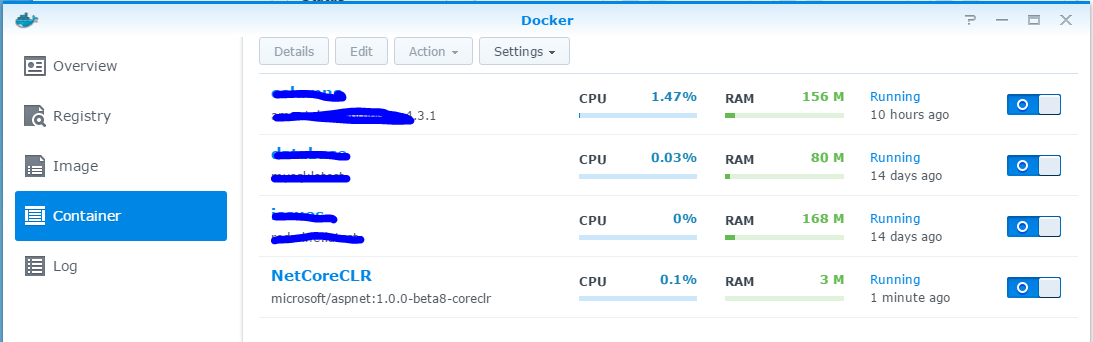
-
選取這個 container, 按上方的 “details”, 可以看到這個 container 的運作情況,切到最後一個 tab, create new termainal, 進入終端機模式
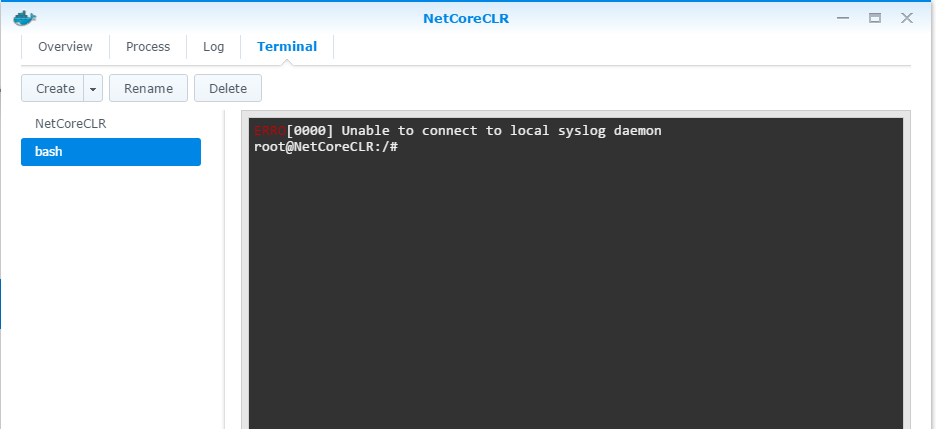
-
好,到這邊之後,剩下的就跟昨天那篇講得一模一樣了,先切換工作目錄到 /home/dnxcore50:
確認一下 .NET Core 版本:
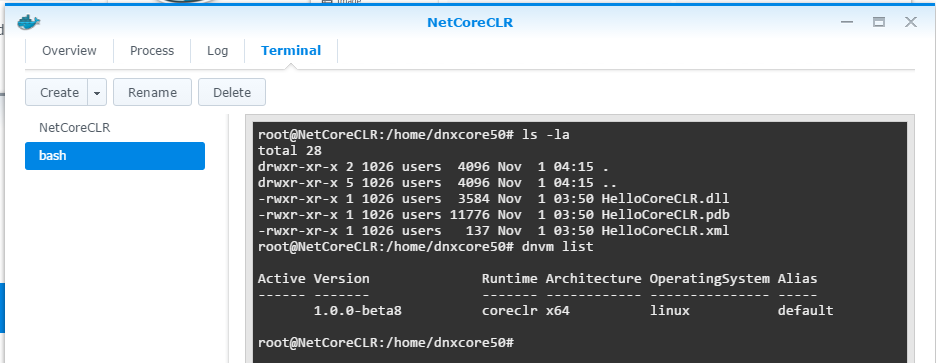
-
第一次執行,用 dnu restore 確認是否還有相依的 package 需要下載:
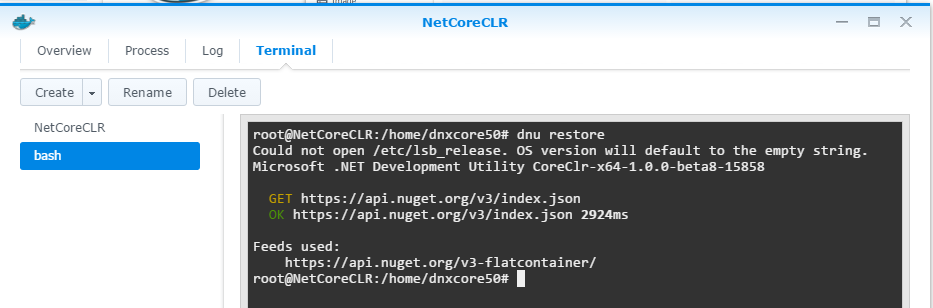
-
準備就緒,可以執行了! dnx HelloCoreCLR.dll
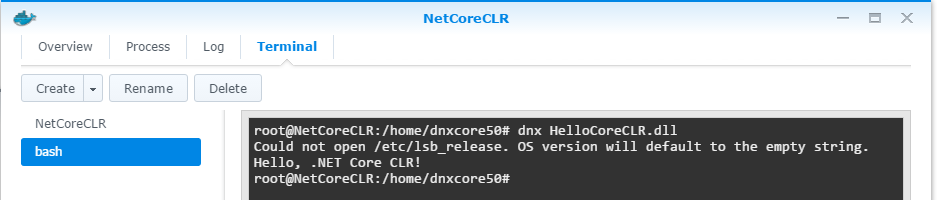
果然 NAS 包裝過的 Docker 簡單好用的多,省了很多腦細胞… 最後補張圖,大家猜猜這樣的 .NET Core CLR 環境需要吃多少記憶體? 很省啦,整個 container 才 6M ..
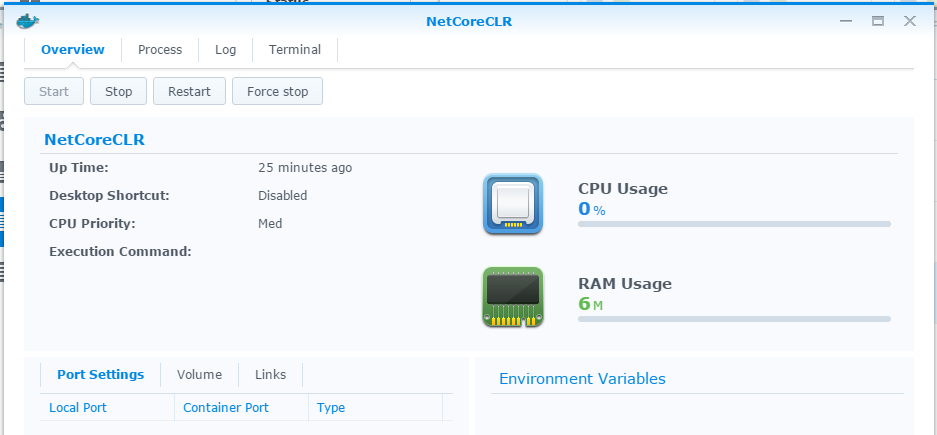
看完別太興奮,馬上衝去買 NAS …,如果真的是為了 Docker 想採購的話,務必先看一下支援清單.. 以 Synology 的來說,只有部分機種 (都是 intel cpu 為主) 才支援。詳細清單可以參考這裡:
https://www.synology.com/zh-tw/dsm/app_packages/Docker
適用機種
16-系列 : RS2416RP+, RS2416+, RS18016xs+ 15-系列 : RC18015xs+, DS3615xs, DS2415+, DS1815+, DS1515+, RS815RP+, RS815+, DS415+ 14-系列 : RS3614xs+, RS3614xs, RS3614RPxs, RS2414RP+, RS2414+, RS814RP+, RS814+ 13-系列 : DS2413+, RS3413xs+, RS10613xs+, DS1813+, DS1513+, DS713+ 12-系列 : DS3612xs, RS3412xs, RS3412RPxs, RS2212RP+, RS2212+, DS1812+, DS1512+, RS812RP+, RS812+, DS412+, DS712+ 11-系列 : DS3611xs, DS2411+, RS3411xs, RS3411RPxs, RS2211RP+, RS2211+, DS1511+, DS411+II, DS411+ 10-系列 : DS1010+, RS810RP+, RS810+, DS710+ -
-
在 Docker 上面執行 .NET (CoreCLR) Console App

from: blog.docker.com
Microsoft 官方宣布能在 Linux 上面運行 .NET (v5) 應用程式.. 其實這已經不是什麼新聞了,去年 Microsoft TechEd 2014 North America 就正式的發布這個消息了,不過因為種種原因,去年看到這新聞的時候,只停留在 “看看” 的階段而已,直到現在時機成熟了才開始動手研究。一來是因為官方的開發工具 Visual Studio 2015 已經 RTM 了 (這麼大的軟體,實在不大想安裝 preview 版本).. 二來 Docker 用的很高興,NAS / Ubuntu Server 也都已經準備好,執行環境我也上手了.. 萬事俱備只欠東風,於是今天就趁周末,把 .NET Core 版的 “Hello World” 丟到 Docker 裡面執行的任務給搞定了 :D
Microsoft 自從新任 CEO Satya Nadella 上任後,宣布了一連串改變,我覺得對未來影響最大的就是 .NET Open Source + Support Linux 這件事了。我認為這決策帶來的影響,遠遠大於 ASP.NET5 本身開發技術及架構上的改變 (例如 MVC6.. 動態編譯.. Dependency Injection 等等)。因為前者影響的是整個 .NET 生態的改變,可能會影響到將來大型應用部屬的架構決策,而後者影響的只是開發團隊,完全是不同層級的問題..。如果你的職責是 system architect, 那千萬別忽略這個改變.. 以後 “混搭” 風格的架構一定會越來越盛行,不管是在 windows server 上面,或是在 Linux server 上都是。
在這兩年內,另一個很快竄起的技術: Docker, 也是另一個關鍵。Docker 這才出來兩年就紅翻天的 Container 技術,這種東西實在太對 architect 的胃口了。過去 VM 的技術沒甚麼不好,不過最大的問題就是: 充分虛擬化之後,帶來的副作用是多一堆 “虛擬” 的機器要管理… 每個 VM 裡面都要裝一套 OS,不論是 Linux or Windows,都要花力氣去維護,要執行這些 OS 也要花費運算資源… 舉個慘痛的經歷,我就碰過在同一台實體機器上,上面的 10 台 VM 都開始掃毒,那狀況真的只能用 Orz 來形容… 上面的 APP 都還沒認真在跑,系統就被 OS + AntiVirus 給拖垮了…
Docker 只虛擬化 Application 的執行環境,巧妙的避開了 VM 過度使用帶來的副作用… 舉例來說,如果你的應用規模不大,只要一台最低規格的 VM 就跑得動的話,你會為了架構考量把他分裝在三台 VM,實作三層式架構嗎? 應該沒人會這麼幹吧? 除非你要展示應用架構,或是可預見的將來會需要 scale out, 不然這樣搞只是自找麻煩而已。 但是現在用了 Docker 你就可以盡可能的採用你認為最理想的架構,分成幾個獨立的 container 可以維持架構上的正確性,同時也不必擔心架構帶來效能的折損。
因為這個原因,了解這種跨界的應用,對我來說遠比了解 ASP.NET5 本身 coding 帶來的改變還重要的多。裝了 Visual Studio 2015 之後,第一件事不是先寫看看 MVC6,而是先弄了個 Hello World, 試看看該怎樣丟到 Linux 上面跑.. 為了這件事,前置作業就花了快一個月… 有在 follow 我的 facebook 或是訂閱 blog 的就知道,之前我都在研究 Docker ,包括在 NAS 上用我理想的架構,來架設我自己的 blog.. 也弄了台差點要被扔掉的舊筆電,架了台研究用的 Ubuntu Server .. 接下來主角要上場了,就是 .NET CoreCLR !
進入主題: .NET Core CLR 體驗
終於進入主題了 =_= ,要是各位跟我一樣長期使用 Microsoft Solution 的話,應該會踢到很多塊鐵板吧? 分享一下我如何讓自己跨進來的步驟,既然目標都很清楚了 (以 docker 為主要的執行環境),所以我自己計畫的步驟是:
-
先用最快的時間了解 Docker 是什麼? 可以怎麼應用? 如何實作?
我挑了最無腦的作法,從 NAS 上的 Docker 套件.. 我自己有台 Synology DS-412+ , 正好支援 Docker, 於是我自己挑了個實作的目標,就是把我原本的 Blog 搬回家,打算用 Docker 架設 WordPress。部落格再怎麼少人看,至少也是我的門面吧 XD,因此有些事情是省不掉的。例如我上一篇文章就提到 reverse proxy 把對外的 port / url 歸位這件事,還有整個 application 的維護及備份等等,都是不能忽略的部分。如果你不拿一個實際的應用來練習,那你做的只會是 POC (Prove Of Concept) 層級的事情,很容易就淪為 “啊! 成功了,會跑了” 之後就告一段落,很多實繼運作要顧慮的部分就不見了。想參考這段過程的,可以看我這篇文章。順利搬完部落格,至少讓我親身體驗 Docker 的應用方式。過去我是真的養了台 PC 架 windows server, 在裝個 VM 跑 windows server 來架站的,現在可以在 NAS 裡用同樣等級的架構作一樣的事,而運算資源只有以前的 1/4 不到 (NAS: atom 2cores, 1GB ram.. PC server Q9400 4cores, 8GB ram).. 我想優勢很明顯了.. 體驗過這一段,以後要如何把 Docker 應用在整體的系統架構內,心裡就有個譜了。 -
親手架設實際的運作環境
NAS 的 Docker 使用實在太無腦了,害我以為裝實體 server 也是滑鼠按兩下就結束,結果真的是動手就吃鱉了 @@,過程我也不多說了,上一篇文章有紀載 :D自己動手架設的好處是,你會親自走過安裝過程的所有細節,將來要 upgrade 或是 change configuration 就不會不知如何下手了。做到這步我才發現,NAS 廠商其實還蠻強的 XD,我自己用指令來管理 Docker 就已經一個頭兩個大了,找了一些 Docker Web UI 來用 (docker-ui), 發現也很難用 @@,但是 Synology / Qnap 自己的 Docker 管理介面就做得不錯…實際走過這段 setup ubuntu, configuration docker environment 之後,以後實際佈署時會碰到什麼問題,一樣心裡大概就有個譜了。 -
進入主題,熟悉 .NET CoreCLR 的運用 (DNVM, DNU, DNX) 方式
這是這次的目的,我想先解決我最不熟悉的部分,往後的 Coding 我反而不擔心,好歹我有 2x 年的 coding 經驗,這應該難不倒我的… 所以我直接跳過 Coding, 拿了最基本的 Console Application, 寫了 Hello World, 以成功在 Docker 環境內執行為主要目標。這步驟搞定的話,後面的路就順了,就可以正式進入研究 ASP.NET5 的階段了這段就沒有連結可以看了 XD,對,沒錯,就是這篇文章。請繼續看下去!
.NET Core CLR 的名詞定義
開始之前,先惡補一下,這次 .NET CoreCLR 的底層改變幅度很大, 如果只打算裝起來玩一玩按一按就搞懂的話,應該沒那麼簡單。幾個一定要知道的 keyword 我先筆記一下。推薦兩篇寫得不錯的介紹:

DNVM, DNX, and DNU - Understanding the ASP.NET 5 Runtime Options
Understanding the relationship between the .NET Version Manager (DNVM), the .NET Execution Environment (DNX) and .NET Development Utilities (DNU) is fundamental to developing with ASP.NET 5. In this post we will look at installing and using DNVM, DNX, and DNU on to work with ASP.NET from the command

DNN: What are DNX, DNVM, DNU and other ASP.NET 5 components?
In a previous post on the upcoming ASP.NET ‘vNext’ release, I covered all of the terminology around ‘Project K’ – which is what it was known as in early betas. Things have moved along a lot since then, and with that has come a change in terminology as the release gets closer. The trend of calling everything ‘K’ is no more – sadly in my opinion as I liked the quirkiness of it.
This post will cover the new terminology, relate it back to the Project K era terminology and relate that back to existing ASP.NET (1-4) concepts where possible. Again, this is intended as a primer for the existing ASP.NET developer to learn what is coming next and get themselves familiar with the changes.
底下就我自己整理的內容了。幾個名詞還是要先定義一下,否則看來看去腦袋會打結:
Core CLR ( .NET Core Common Language Runtime )
CLR 就是 Common Language Runtime, 套用 Java 的說法其實就是 VM,也就是能執行 .NET IL 的環境。包含 VM,JIT,還有 BCL (Base Class Library) 都算在內。而過去常講的 .NET Framework 就是所謂的 CLR,在 windows 平台上有完整的功能。Core CLR 則是重新包裝的可跨平台版本,包括 Linux / MacOS. Core CLR 有其他特性,向是 CLR 可以個別佈署,同時裡面的 BCL 都只需要佈署你用的到的部分即可。
DNX ( .NET Execution Environment )
.NET 的執行環境,可以執行及啟動 .NET app / ASP.NET 的命令列指令。一樣套用 Java 的說法,就像是對應到 java.exe 的東西,
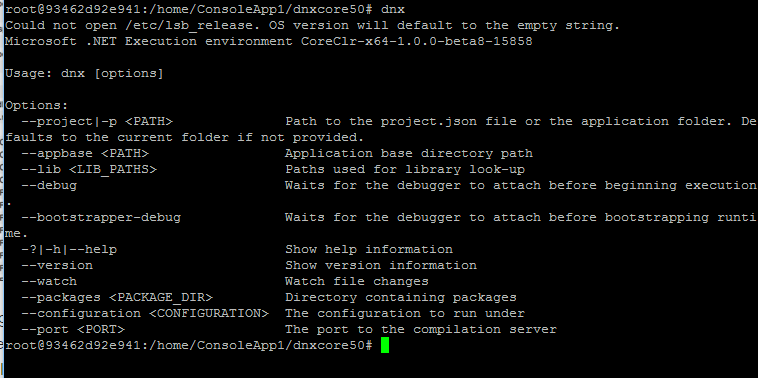
DNVM ( .NET Version Manager )
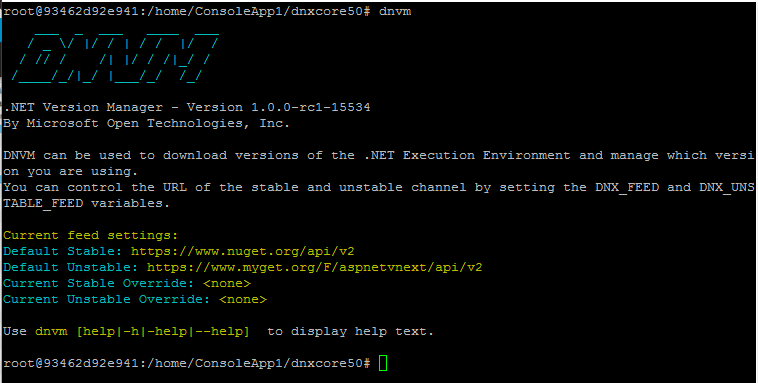
.NET 的版本維護工具,類似 APT-GET 這樣的命令列指令,用來維護及更新 DNX. DNX 各種版本的維護工具就叫做 DNVM,可別看到 VM 就以為是 Virtual Machine, 他是各種 DNX 的 Version Manager.
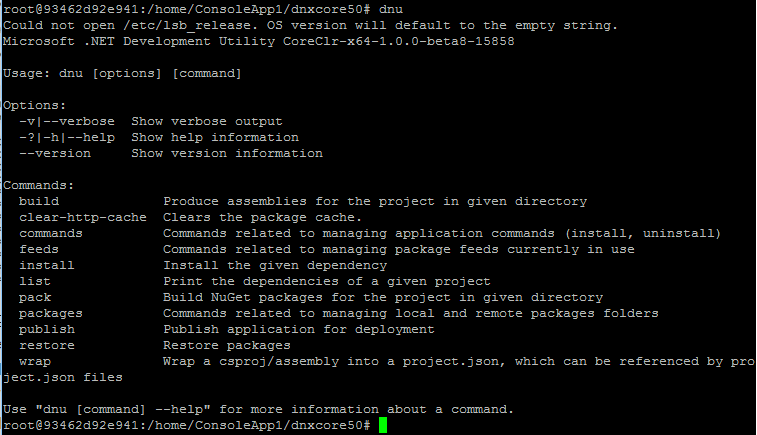
DNU ( .NET Utilities )
.NET 開發人員維護工具,有點像是 Java 的 Javac.exe, 可以進行 build, 下載或是更新相依的 NuGet 套件。
這幾個指令的關係搞清楚之後,今天的主角終於… 終於可以上場了。
將 .NET Core APP 放進 Docker 執行

第一步,首先你要有個 Docker 執行環境可以用.. 其實這是小事,你有 NAS 的話,規格別太差又剛好有支援 Docker 那你就賺到了,直接用就好。不然可以像我一樣自己裝一台 Linux, 或是用 VM 都可以。如果你甚麼都沒有,可以考慮看看用 Docker Toolbox (windows 版), 他包含了 windows 上的 docker client, 也包含了 VirtualBox 虛擬環境,還有一個包裝好的 Boot2Docker, 專為執行 Docker 而生的 Linux 開機 image.
我畢竟不是用 Linux 長大的那群人,對我而言能越簡單解決環境問題越好。因此我並不打算直接在 Linux 上安裝 DNX .. 我只想搞定 Docker 後,找 Microsoft 官方提供的 Container Image 來用。我用的是這個: ASP.NET 5 Preview Docker Image ,抓下來後就有現成的執行環境.. 其他動作通通都省了,真的是適合我用的懶人包 XD
不過看了幾篇怎麼使用這 container image 的文章 (官方: Running ASP.NET 5 Applications in Linux Containers with Docker),發現跟我要的不大一樣。官方都是教你要寫 DockerFile, 把自己的 application 包裝成一個新的 image, 然後丟進去 docker 執行.. 這樣是沒錯啦,不過我只想把我的 app 丟進某個現成的環境來測試,還不想搞到自己包 image ..
於是,花了點時間,總算找到切入點。多虧這個念頭,讓我沒有一步一步照著官方文件來走,也意外地讓我多了解了 Docker 的運作機制。Docker 提供一個跟外界隔離的應用程式的執行環境,但是裡面能執行的不一定只有我的 application 啊,也不一定只能執行一個。我可以多執行一個 shell, 對我來說就好像開了一個 VM 然後 ssh 連進去一樣,這就是我現階段想要的,將來有正式的佈署需求再來照官方文件進行就好。
環境搞定後,確定可以正確操作 DNVM, DNU, DNX 等指令後, 就幾乎達成我的目標了。方向想通了,剩下的舊是查察指令文件,找出正確的操作步驟就可以了。我最後整理下來的執行步驟是:
在 Docker Host:
- 下載官方 image
sudo docker pull microsoft/aspnet:1.0.0-beta8-coreclr - 啟動 container (daemon mode, 加上 -d)
sudo docker run -d --restart always microsoft/aspnet - 查詢 container id:
sudo docker ps -a
- 在 container 內執行 bash, 同時進入互動模式直到 bash 結束為止:
sudo docker exec -t -i 93462d92e941 /bin/bash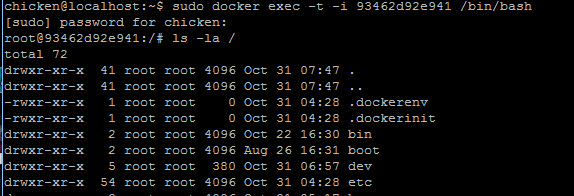 這時 command prompt 已經變了,由原本的 chicken@localhost:~$ 變成 root@93462d92e941:/# , 代表 shell 已經啟動成功,且順利進去 conainer 內了,接下來我就可以把它當作 VM 開始大玩特玩..
這時 command prompt 已經變了,由原本的 chicken@localhost:~$ 變成 root@93462d92e941:/# , 代表 shell 已經啟動成功,且順利進去 conainer 內了,接下來我就可以把它當作 VM 開始大玩特玩.. -
打開 visual studio 2015, 開 console app project, 寫一段不入流的 code, 印出 “Hello! .Net Core! “ ..
-
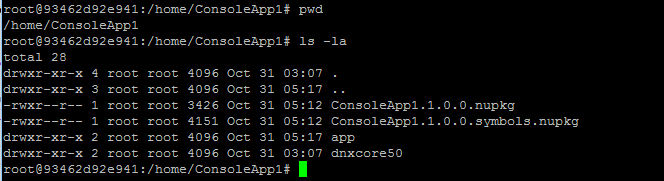
完成後,想辦法把檔案丟到 container 裡面… docker 提供 cp 這個指令,可以跨過 docker host / container 的界線 copy 檔案。細節我就跳過,總之 (5) 編譯出來的檔案,我放在 container 內的 /home/ConsoleApp1/ 目錄下:
-
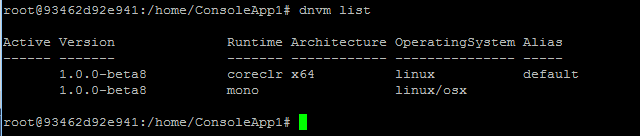
接下來就是主要步驟了,先用 dnvm list 確認你能用的 dnx 版本,有需要可以用 dnvm install 來安裝,或是用 dnvm upgrade 來升級.. 我這次要用的是 coreclr x64 的版本:
-
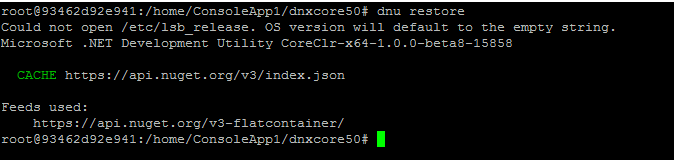
進入 dnxcore50 的目錄,用 dnu restore 指令,確認所有相依的 package 都已存在 (若沒有的話會自動到 NuGet 去抓回來)
- 噹噹! 萬事俱備,最後就是執行了! 用 dnx 來跑我的 console application:
為了避免有人誤會,我是用 windows command prompt 充數,順手把 OS information 印出來以資證明..

哇哈哈,終於成功了。看到我寫的 C# code 的控制範圍能擴大到 Ubuntu Server 上,那個成就感實在是不可言喻 :D 這次碰到最大的困難,是查到的指令都是講 ASP.NET 如何在 docker 上執行,可是我只是要 run console app 啊,沒找到文章把這整傳邏輯跟做法整理再一起,只好自己摸索…。好在當年學生時代有好好的學 unix (當年用 solaris … 自己有用過一陣子的 linux.. ), 基本觀念跟 shell script 都還有,硬是闖出一條路。
就為了這行 “Hello .Net Core!”, 花了我一個上午… 不過至少達到我的目標,把最基本的命令列執行成功了! 能夠親手在 Linux 上操作 dnvm, dnu, dnx 這幾個核心指令把程式跑起來,也算值回票價了 :D 這些步驟整理起來就當作我的筆記。應該有不少人跟我一樣,不熟 Linux 又想跨入這個領域的吧? 有需要的盡管取用,也歡迎分享這篇文章~
-
-
終於搞定 Ubuntu Server 15.10 @@

原本只是想在 NAS 上簡單玩玩 Docker, 為了接下來的 ASP.NET 5 做準備.. 不過實在太好用,還沒開始做正事 (ASP.NET 5), 就先把原本的 BLOG 從 GoDaddy 的 hosting 搬回來放 NAS 了,順手也架了 reverse proxy … 現在 NAS Docker 有正式用途了, 而 NAS 的運算能力又很有限 (我的是 DS-412+, CPU 只是 atom d2700, 雙核而已, 1GB RAM), 裝沒幾個就跑開始擔心了,於是就開始想另外搞一個可以隨便玩得 docker engine 環境..
其實 PC 上弄個 VM 是很容易啦,windows 10 內建的 hyper-v 根本就不用花甚麼功夫, 不過我想弄個像 NAS 這樣省電不大需要去管它, 24hr 開著隨時都可以用.. 就把腦筋動到古董要丟掉的筆電.. 我老姊正好有台筆電要丟掉,找我幫他先把硬碟資料清掉她才敢丟…一切都來的太巧了! 於是這台就被我拿來大整修一番…
這台的規格是 Acer Aspire 5742Z:
- 15.6” LCD (已經裂開沒辦法顯示了)
- 320GB HDD
- 4G RAM
- Intel Pentium P6200
看來正和我需要 :D,螢幕我也不需要,直接拆掉可以放桌上當鍵盤,還不用擔心螢幕翻起來遮到我真正的螢幕… 用舊 NB 當 SERVER 好處還蠻多的,一來省電,二來快報廢的電池其實當成內建的 UPS 也不錯,夠撐幾分鐘關機就好了。
不過開始安裝 Ubuntu, 就是噩夢的開始… 平常我連使用 windows 都常常開 dos command prompt 下指令,命令列對我來說不是甚麼問題,不過 linux 從研究所畢業之後就很少在碰了,這次光安裝就踢到鐵板..
從一開始,抓錯 USB 開機工具,做出來的開機 USB 好像只支援 net install, 硬要我設定網路才能繼續… 無奈網路卡又抓不到, 查了一堆說明又說這步驟可以跳過, 後來才發現另一套 USB 開機工具就沒這問題..
再來,不知碰到啥問題,我抓了 12.04 LTS, 14.04 LTS, CentOS 都試過了,裝到一半跟我講 CDROM 內容不對,不過我重下載了幾次,也比對過 MD5 hash 都無誤.. 想說換 desktop 板好了,desktop 版應該會比較親民吧? 結果開到桌面就又不動了 @@
最後把 wireless lan 卡直接拔掉,換 15.10 版,終於裝起來 =_=
果然隔行如隔山,裝好後光是要設定 SSH server, 要改固定 IP, 設定 samba 開網路分享… 都花了一些時間, 這部分就還好, 只是花點時間查指令,照著打進去就搞定…
現在終於把基本環境搞定了,特此留念 :D 過程解決的問題對於熟 linux 的人來說應該都是小兒科吧? 我就不貼了,自己記載我私人的 onenote 就好.. 貼幾張照片作紀念:

我用雙螢幕,旁邊的螢幕是轉成直的,方便看文件。因為有現成的 D-SUB,想說裝一裝就可以改用 SSH ,就懶得把他轉正了,結果搞了半天 =_=

這張照片可以看到,螢幕已經被我用暴力拆掉了 XD。 這次用 Microsoft 的隨身碟來裝 Linux … 裝起來的 Linux 又要跑 Microsoft 的 ASP.NET 5 … 你搞得我好亂啊..
至於 ASP.NET 5 … 哈哈,再過幾個禮拜再說 XD
