-
Docker 初體驗 - Synology DSM 上面架設 WordPress / Redmine / Reverse Proxy

前言: 先讓我講一點前情提要 XD,想看安裝步驟的請自己跳到後面…
在買這台 NAS 之前 (Synology DS-412+), 我是自己在家裡弄了台 PC, 裝了一堆硬碟充當個人用 file server, 同時順便在裡面架了自己常用的網站,包含這部落格的前身 (BlogEngine),還有自己用的 Visual SVN, 另外也架了 Linux VM 裝 Redmine 等等其他的東西..
後來 PC 開始不聽話了,開始三不五時當機,心一橫,兩年多前就買了台 4Bays NAS 把 Server 換掉,頓時輕鬆許多… 只是 NAS 不比 Server, 慣用 Windows Server 的我一時找不到替代品,這些服務就一個一個搬家了。其中最重要的 BLOG,就搬到 GoDaddy 的免費 web hosting (有 IIS),繼續在上面掛著..
用過 Synology NAS 的大概都知道,它的特色就是 DSM 很好用,也有提供很多 Package, 讓 NAS 加裝軟體就像手機逛 App Store 一樣簡單… 不過,DSM 的裝機量不比手機,很多套件要是沒有經過 Synology 包裝,要安裝就是件麻煩事了。就算有 Synology 官方的打包套件,更新或是維護也不比這些軟體的官方來的快。尤其是從小到大都是抱著 Microsoft 大腿的我更是不適應 @@
直到幾個月前 Synology Release DSM 5.2, 正式在裡面搭載了 Docker! 這真是天大的好消息.. :D
Docker 是個好物,沒用過或沒聽過的可以參考這裡: What is docker ?
簡單的說,是另一種虛擬化的應用。他不像 VM 是將硬體虛擬化,所以不用在上面安裝 OS,只虛擬化執行環境… 啟動速度很快,兩三秒就可以啟動了,少掉 OS 這層,整個就很輕量化,架在 Docker 裡,跟原生地執行環境速度,CPU / RAM 資源的使用沒甚麼明顯差別… 我覺得 DSM 加入 Docker 真的是 Synology 最聰明的決定了,比 Q 牌直接導入正統的虛擬化技術還實用… 畢竟個人用的 NAS 都不會有太強大的運算資源,為了這樣去拚硬體配備就有點本末倒置了。Docker 這種輕量化的虛擬化技術,正好補足了這需求
講這麼多幹嘛? 因為 Docker 實在太熱門了,所以在 Docker Hub 上大概所有熱門的應用都有人包好了,煩惱的是同樣的東西太多人包了,有時還真不知該怎麼選 @@.. 我是有官方版的就盡量挑官方的來用。因為社群的差異太大了,因此從 Docker 上可以找到的選擇,遠比從 Synology Package Center 找到的又多又廣泛,我就開始一個一個替換的計畫…
計畫要安裝的有好幾個,包括 WordPress, Redmine, MYSQL, WebSVN, 還有為了方便發布這些服務,還想裝個 Reverse Proxy… 不過流水帳我就省了,這次的範例我就拿 WordPress 跟 Reverse Proxy 當案例,給有需要的人參考步驟就好。
正文開始
這次打算把在 GoDaddy 流浪兩年多的 Blog Engine 搬回家,於是花了點時間把資料從 BlogEngine 匯出,轉到 WordPress, 這邊很多文章有教你一步一步處理,我就跳過了。
在 Docker 上安裝 WordPress + MySQL, 也是小事一件,最花時間的就是… 就是下載 image … 這我也跳過。比較特別的是,不知是 Synology 搭配的 Docker 套件問題,還是別的的問題 @@,WordPress 官方版的 image 開 DSM Docker 管理員的 terminal 就很容易會整個 container crash .. @@,不過因禍得福,意外發現有人用 Nginx 這個新興的 web server 架設的 WP image.
NGINX 是啥? 是個俄國人寫的 web server, 世界上的佔有率大概 1x % 吧~ 它的特色就是又小又快.. Apache 走的是可以外掛很多 module 的模式,NGINX 則是走把你要的東西編譯進去的模式,跑起來又快又省記憶體,正適合我的需要。換了這個 image, 前面講的 crash 怪問題就不藥而癒.. 算是因禍得福 :D
做個筆記,我用的 image 分別是這兩個:
wordpress image with php-fpm + nginx
架好後當然快樂的使用了。這時問題開始來了… 畢竟我用的是 NAS 內建的套件,我又不熟 Linux, 有很多東西就算我找到文章可以進去大改特改,我也不大敢動手,NAS 終究是拿來讓我日子過快樂一點的,不是要重回當黑手的日子… 因此太過古怪的技巧我就不想用了,我想盡量用正常一點的方式來設定,免得以後換個版本我就搞不定…
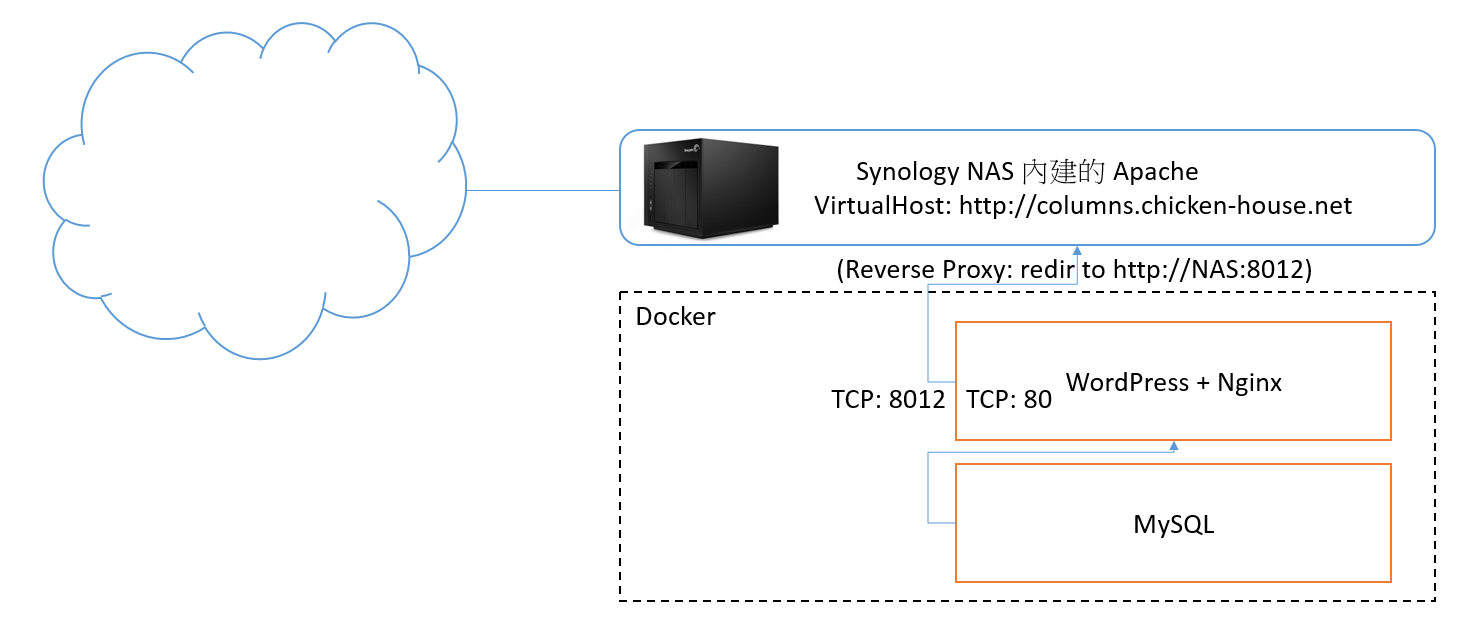
上圖是我現在家裡的網路架構,這時碰到的問題在於,PORT 80 早就被 NAS 內建的 apache 搶去用了。WordPress 若要用 80 PORT 就沒辦法了。DSM 也沒地方讓你把 PORT 80 放出來,二來就算放出來,我也沒辦法讓兩個以上的 container 都 mapping 到 80 PORT… 這樣要開放對外網站就顯得很棘手… 最終 WordPress 分配給他 8012 這個 port, 總不能叫所有的網友,以後要看我的文章要連這 PORT 吧? @@
一般業界最常處理這種問題的方式,就是用 Reverse Proxy 了。顧名思義,Reverse Proxy 就是反向的 Proxy, 他是替 “外面” 的 User 到你家裏面的網站抓資料後,再丟給外面的 User, 用這樣的技巧將內部的網站發布出去。其實他的機制跟一般的 Web Proxy 是一模一樣的,只不過他服務的是外面的 User 抓內部的網站,跟正常的應用情境相反,所以叫 Reverse Proxy.
Reverse Proxy 其實很多種應用,進階一點的 Load Balancer, Cache, HTTPS 發行 (在 Reverse Proxy 上加掛 SSL) 等等用途。在 Windows Server 上有 ARR (Application Request Routing) 這個 IIS 外掛可以用,也是另一種常用的 Reverse Proxy。回到我的狀況,由於唯一的 80 PORT 已經被 DSM 佔住了,所以沒得選擇,我開始尋找 DSM 內建的 Apache 上可以加掛的 proxy module… 結果得來完全不費工夫,內建就有 :D
架構跟方向都想好之後,就開始動手了… 各位現在看的到我翻新的 BLOG,可見是成功了! 以下是我的操作步驟:
-
Synology DSM 的控制台,底下有 Web Station, 先用正常的介面,建立 virtual host, 綁到 columns.chicken-house.net 這個 hostname (80)
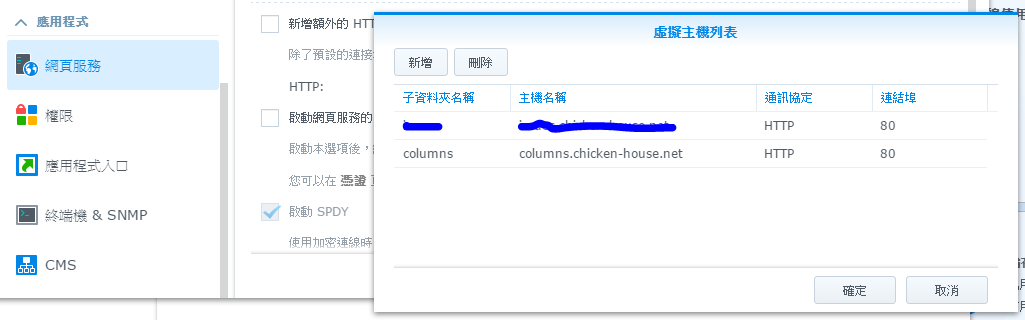
當然,其他 DNS 的設定你要自己搞定。我自己家裡用的 ROUTER 有內建個小型 DNS,加個 static record 就可以把 columns.chicken-house.net 對應到 NAS 的內部 IP,我自己要看我的 BLOG 不用繞到外面出國比賽再繞回來… 外面的 DNS 也要改一改,對到 router 的對外 IP,有固定 IP 的可以設 A record, 有 DDNS 的可以用 cname record. 改完可以測看看,這時應該會看到 Synology 自己準備的 404 page:

-
接下來,就是要設定這個 virtual host 要扮演 reverse proxy, 轉向內部的 word press 網站了。其實整篇廢話這麼多,重點就這一段而已 @@用 SSH 登入 NAS,修改這個檔案: /etc/httpd/httpd-vhost.conf-user , 其中 line 15 ~ 25, 就是我加進去的指令,告訴 apache 在這個 virtual host 內,位於 / 以下的 http request, 都轉給 http://nas:8012 這個內部的 URL,也就是安裝 WordPress 的 container 的發行端點
NameVirtualHost *:80 <VirtualHost *:80> ServerName * DocumentRoot /var/services/web </VirtualHost> <VirtualHost *:80> ServerName columns.chicken-house.net DocumentRoot "/var/services/web/columns" ErrorDocument 403 "/webdefault/error.html" ErrorDocument 404 "/webdefault/error.html" ErrorDocument 500 "/webdefault/error.html" # start of (reverse proxy settings) ProxyPreserveHost On ProxyRequests Off <Location / > ProxyPass http://nas:8012/ ProxyPassReverse http://columns.chicken-house.net/ Order allow,deny Allow from all </Location> # end of (reverse proxy settings) </VirtualHost>完成後,用這個指令 restart apache (httpd), 讓設定生效:
httpd -k restart再用瀏覽器測試一下網址 http://columns.chicken-house.net, 應該就可以看到 wordpress 的內容了 !
拿手機測試一下,關掉 wifi, 用 4G 連看看我自己的網站… 果然可以用正常的 URL 看到內容:

-
其實到這邊就大功告成了。不過… 請務必備份這個檔案 !! DSM 的介面設計得太簡單好用了,所以當你回到 (1) 重新調整後,或是有第二個 docker container 也要依樣畫葫蘆發布的話,DSM 會把這個設定擋蓋掉 T_T,我就是因為這樣全部重來一次…
OK,大功告成! 繞了一大圈,總算把我的 NAS 調教成可以擔負重要任務的 Personal Server 了,以前不覺得 NAS 跑的慢,現在開始覺得 RAM 好像值得加大一點了 :D,也許有人會問,這樣其實用 Synology 套件中心的 WordPress 好像也一樣不是嗎? 不不不,處女座的人是忍受不了這幾個問題的:
-
套件中心的 WordPress, 網址會多一段… 像這樣… http://columns.chicken-house.net/wordpress/…… 這我看了就很礙眼,更重要的是其他人透過 search engine 找到的連結,會點不進來… 身為點閱率破百萬的知名部落格 (並沒有) 怎麼能忍受這種現象…
-
套件中心的 WordPress 只能裝 “一份”,我想架兩個 wordpress 就沒辦法分開管理了
-
docker 將來要搬出去非常容易,匯出 container, 之後搬到別的地方,如 Azure / Amazon 都有提供 docker 執行環境了… synology 的套件就沒這優勢了…
-
docker 的選擇多太多了,到 docker hub 裡找找,甚麼都有… 能選擇的數量遠遠高於 synology package center
-
有統一的 container 管理工具,mount storage, port mapping, cpu / ram resource management 等等都有現成的, 套件中心提供的就沒這樣的管理彈性:
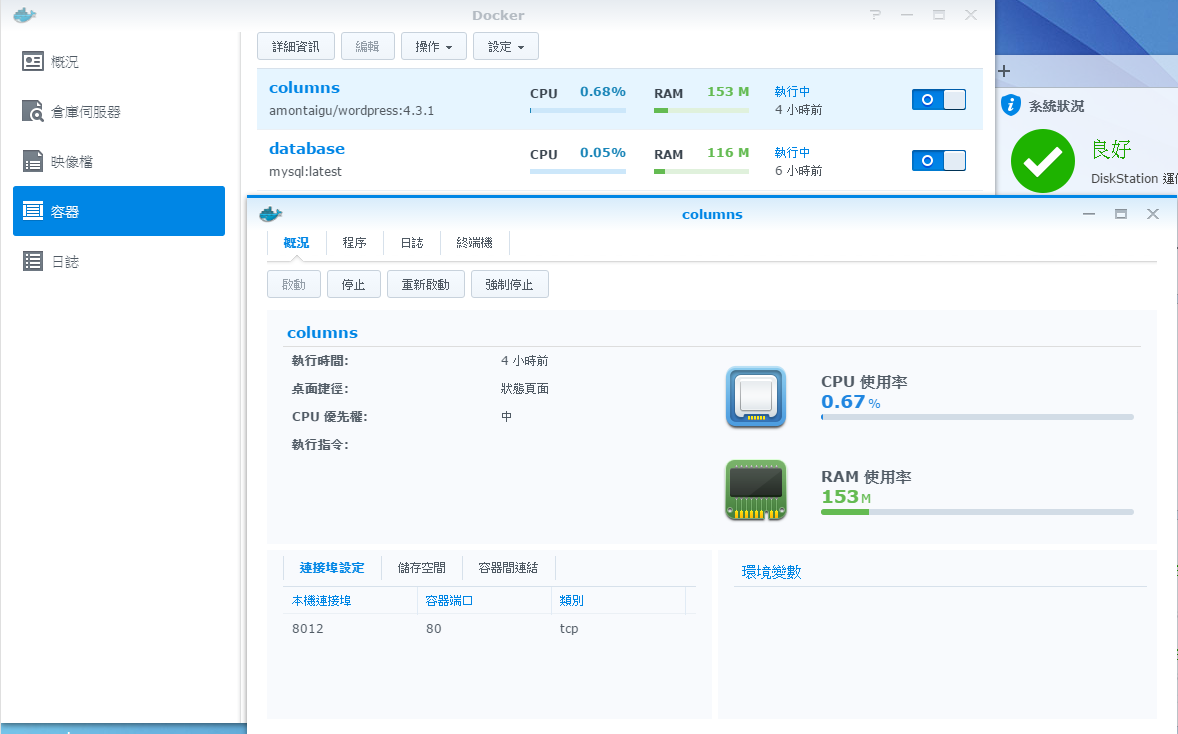
好,流水帳就記到這裡,當你還想再加上其他 container, 就依樣畫葫蘆就好。這篇其實沒甚麼重點,主要就是為了滿足 Synology NAS 用戶,能用 Docker 套件來做些正是用途的小技巧而已,歡迎分享 :D
-
-
處理大型資料的技巧 – Async / Await
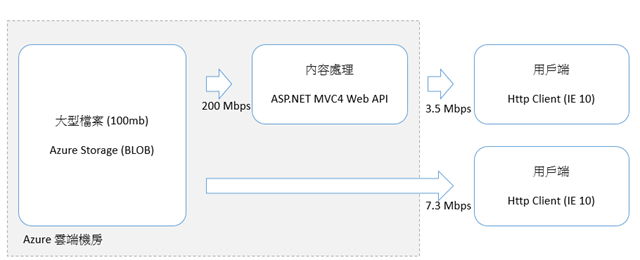
原本只是很單純的把大型檔案 (100mb 左右的 video) 放到 Azure Storage 的 BLOB 而已,結果效能一直不如預期般的理想。才又把過去的 thread 技巧搬出來用,結果又花了點時間改寫,用 async / await 的效果還更漂亮一點,於是就多了這篇文章 :D
其實這次要處理的問題很單純,就是 WEB 要從 Azure Storage Blob 讀取大型檔案,處理前端的認證授權之後,將檔案做編碼處理後直接從 Response 輸出。主要要解決的問題是效能過於糟糕… 透過層層的處理,效能 (3.5 Mbps) 跟直接從 Azure Storage 取得檔案 (7.3 Mbps) 相比只剩一半左右.. 過程中監控過 SERVER 的 CPU,頻寬等等,看來這些都不是效能的瓶頸。
為了簡化問題,我另外寫了個簡單的 Sample Code, 來呈現這問題。最後找出來的原因是,程式碼就是單純的跑 while loop, 不斷的把檔案內容讀進 buffer 並處理後,將 buffer 輸出。結果因為程式完全是 single thread 的處理方式,也沒有使用任何非同步的處理技巧,導致程式在讀取及處理時,輸出就暫停了,而在輸出時,讀取及處理的部份就暫停了,讓輸入及輸出的 I/O, 還有 CPU 都沒有達到滿載… 於是效能就打對折了。用時間軸表達,過程就如下圖:
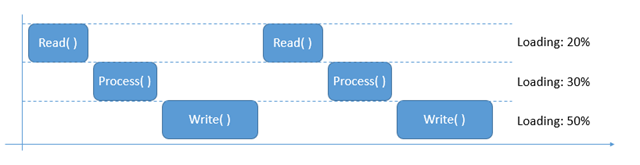
這樣的設計方式,同一時間只能做一件事。若把上圖換成各種資源的使用率,會發現不論是 DISK、NETWORK、CPU等等資源,都沒有同時間保持忙碌。換句話說好像公司請了三個員工,可是同時間只有一個人在做事一樣,這樣的工作安排是很沒效率的。要改善的方法就是讓三個員工都保持忙碌,同時還能亂中有序,能彼此協調共同完成任務。
同樣的狀況應該很普遍吧? 不要說別人了,就連我自己都寫過很多這樣的 CODE … 光是 COPY 大型檔案,大家一定都是這樣寫的: 用個 while loop, 把來源檔讀進 buffer, buffer 滿了寫到目地檔,然後不斷重複這動作,直到整個檔案複製完成為止。這不是一模一樣的情況嗎? 只是大部份的人不會去考量如何加速這樣的動作而已…
我先把目前的CODE簡化一下,拿掉一些不相關的部份,單純的用
Read()/Process()/Write()三個空的 method 代表執行這三部份的工作,執行過程需要的時間,就用 Task.Delay( 100 ) 來取代。經簡過後的 Code 如下:經簡後的示意程式碼:
public class Program { static Stopwatch read_timer = new Stopwatch(); static Stopwatch proc_timer = new Stopwatch(); static Stopwatch write_timer = new Stopwatch(); static Stopwatch overall_timer = new Stopwatch(); public static void Main(string[] args) { overall_timer.Start(); for (int count = 0; count < 10; count++) { Read(); Process(); Write(); } overall_timer.Stop(); Console.WriteLine("Total Time (over all): {0} ms", overall_timer.ElapsedMilliseconds); Console.WriteLine("Total Read Time: {0} ms", read_timer.ElapsedMilliseconds); Console.WriteLine("Total Process Time: {0} ms", proc_timer.ElapsedMilliseconds); Console.WriteLine("Total Write Time: {0} ms", write_timer.ElapsedMilliseconds); } public static void Read() { read_timer.Start(); Task.Delay(200).Wait(); read_timer.Stop(); } public static void Process() { proc_timer.Start(); Task.Delay(300).Wait(); proc_timer.Stop(); } public static void Write() { write_timer.Start(); Task.Delay(500).Wait(); write_timer.Stop(); } }程式執行結果:
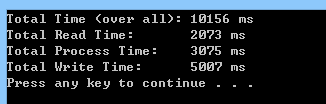
程式總共要花掉 10 秒鐘才執行完畢,由於完全沒有任何並行的處理,因此就是很簡單的 Read 花掉 2 秒,Process 花掉 3 秒,Write 則花掉 5 秒,加起來剛好就是總執行時間 10 秒。
回顧一下,過去寫過幾篇如何善用多執行緒來解決各種效能問題的文章,其中兩篇跟這次的案例有關:
- MSDN Magazine 閱讀心得: Stream Pipeline, (2008/01/19)
- 生產者 vs 消費者 - BlockQueue 實作, (2008/10/18)
- 生產線模式的多執行緒應用, ([RUN! PC] 2008 十一月號, 2008/11/04)
- RUN!PC 精選文章 - 生產線模式的多執行緒應用, (2009/01/16)
其實這些方法的目的都一樣,都是透過各種執行緒的操作技巧,讓一件大型工作的不同部份,能夠重疊在一起。這樣的話,整體完成的時間就能縮短。不過,隨著 .NET Framework 一直發展,C# 5.0 提供的 Syntax Sugar 也越來越精彩,到了 .NET Framework 4.5 開始提供了 Async / Await 的語法,能夠大幅簡化非同步模式的設計工作。
非同步的程式設計,其實也是 multi-threading 的一種運用。簡單的說,它就是把要非同步執行的任務丟到另一條執行緒去執行,等到它執行結束後再回過頭來找它拿結果。只是為了這樣的一個動作,往往得寫上數十行程式碼,加上原本程式的結構被迫切的亂七八糟,過去往往非絕對必要,否則不會用這樣的模式。
這次我的目的,其實用前面那幾篇的技巧就能解決了。不過這次實作我想換個方法,都已經 2013 了,有 Async / Await 為何要丟著不用? 這次就用新方法來試看看。先用上面的時間軸那張圖,來看看改進後的程式執行狀況,應該是什麼樣子:
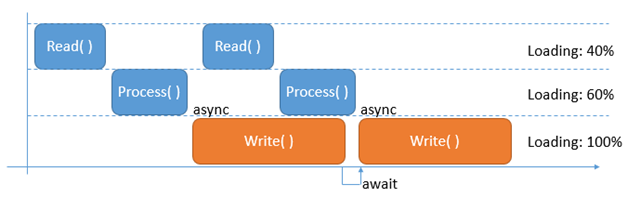
解釋一下這張圖: 橘色的部份代表是用非同步的方式呼叫的,呼叫後不會 BLOCK 原呼叫者,而是會立即 RETURN,兩邊同時進行。而圖中有個箭頭 +
await, 則代表第二個非同步呼叫Write()的動作,會等待前一個Write()完成後才會繼續。Write()跟下一次的Read()其實並無相依性,因此在開始Write()時,其實可以同時開始下一回的Read(), 因此時間軸上標計的執行順序就可以被壓縮,調整一下執行的順序,馬上得到大幅的效能改進。這次要改善的,就是把Read() + Process()跟Write()重疊在一起,預期會有一倍的效能提升。想要瞭解 C# 的 async / await 該怎麼用,網路上的資源有很多,我習慣看官方的文件,有需要參考的可以看這幾篇:
Async / Await 的細節我就不多說了,簡單的說在 method 宣告加上 async 的話,代表它的傳回值會被改成
Task<>, 而呼叫這個 method 會變成非同步的,一旦呼叫就會立刻 Return, 若需要這個 method 的執行結果,可用 await 等待,直到 method 已經執行完畢才會繼續…廢話不多說,過程就沒啥好說的了,直接來看改好的程式碼跟執行結果:
改寫為非同步模式的 CODE:
public class Program { static Stopwatch read_timer = new Stopwatch(); static Stopwatch proc_timer = new Stopwatch(); static Stopwatch write_timer = new Stopwatch(); static Stopwatch overall_timer = new Stopwatch(); public static void Main(string[] args) { overall_timer.Start(); DoWork().Wait(); overall_timer.Stop(); Console.WriteLine("Total Time (over all): {0} ms", overall_timer.ElapsedMilliseconds); Console.WriteLine("Total Read Time: {0} ms", read_timer.ElapsedMilliseconds); Console.WriteLine("Total Process Time: {0} ms", proc_timer.ElapsedMilliseconds); Console.WriteLine("Total Write Time: {0} ms", write_timer.ElapsedMilliseconds); } public static void Read() { read_timer.Start(); Task.Delay(200).Wait(); read_timer.Stop(); } public static void Process() { proc_timer.Start(); Task.Delay(300).Wait(); proc_timer.Stop(); } public static async Task Write() { write_timer.Start(); await Task.Delay(500); write_timer.Stop(); } private static async Task DoWork() { Task write_result = null; for (int count = 0; count < 10; count++) { Read(); Process(); if (write_result != null) await write_result; write_result = Write(); } await write_result; } }程式碼幾乎都沒有動,不過就是把
Write()改寫為 Async 版本,同時在主程式DoWork()用 Task 形別,把Write()傳回的Task物件,保留到下一次呼叫Write()前,用 await 來確保上一個Write()已經完成。改寫過的版本,程式碼很簡單易懂,90% 以上的程式碼結構,都跟原本同步的版本是一樣的,大幅維持了程式碼的可讀性,完全不像過去用了多執行緒或是非同步的版本,整個結構都被切的亂七八糟。看看程式的執行結果,果然跟預期的一樣,整體執行時間大約為 5 秒。多出來的 660 ms, 就是第一次的
Read() + Process(), 跟最後一次的Write()是沒有重疊的,因此會多出 500 ms, 再加上一些執行的誤差及額外負擔,就是這 660ms 的來源了。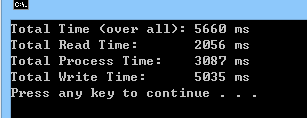
最後,來看一下效能的改善。在我實際的案例裡,Read 是受限於 VM 與 Storage 之間的頻寬,固定為 200Mbps, 而 Process 是受限於 VM 的 CPU 效能,也是固定可控制的, 最後 Write 則是受限於 client 到 VM 之間的頻寬,可能從 2Mbps ~ 20Mbps 不等,這會直接影響到到 Write 需要的時間。
不管是用 thread 或是 async ,都不是萬靈丹,主要還是看你的狀況適不適合用這方法解決。這次我的案例是用 async 的方式,將 Read / Write 閒置的時間重疊在一起,節省的時間就反應在整個工作完成的時間縮短了。因此兩者花費的時間差距如果過大,則就沒有效果了。
我簡單列了一張表,來表達這個關係。分別針對 client 端的頻寬,從 2Mbps ~ 200Mbps, 列出使用 async 改善前後的花費時間,及效能改善的幅度:
*200M 100M 80M 50M 20M 10M 5M 2M 原花費時間(ms) 7000 9000 10000 13000 25000 45000 85000 205000 ASYNC花費時間(ms) 5500 5500 5500 8500 20500 40500 80500 200500 效能改善% 127.27% 163.64% 181.82% 152.94% 121.95% 111.11% 105.59% 102.24% 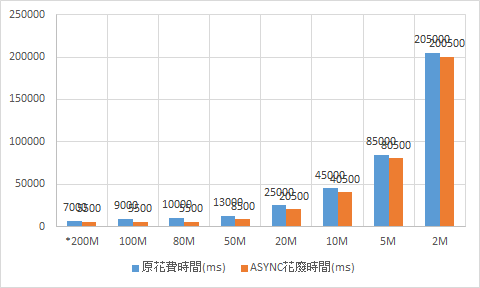
以執行時間來看,頻寬低於 80M 之後,改善的程度就固定下來了,隨著頻寬越來越低,WRITE 需要花費的時間越來越長,改善的幅度就越來越不明顯。同樣這些數據,換成改善的百分比,換成下一張圖:
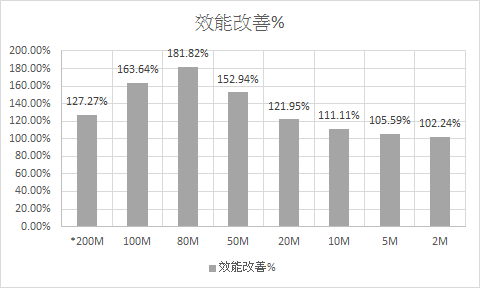
改善幅度最好的地方,發生在 80Mbps, 這時正好是
Read() + Process()的時間,正好跟Write()花費的時間一樣的地方。頻寬高於或低於這個地方,效果就開始打折扣了。通常改善幅度若低於 10%, 那就屬於 “無感” 的改善了。簡單的下個結論,其實任何效能問題都很類似,能用 async 改善的效能問題,一定有這種模式存在: 整個程式執行過程中,有太多等待的狀況發生。不論是 IO 等待 CPU,或是 DISK IO 等待 NETWORK IO 等等,都屬此類。從外界能觀察到的狀況,就是幾個主要的硬體資源,如 Network, CPU, DISK, Memory 等等,都沒有明顯的負載過重,但是整體效能就是無法提升,大概就屬於這種模式了。找出流程能夠重新安排的地方後,剩下的就是如何善用這些技巧 (async),把它實作出來就結束了。
而 async / await, 處理這類問題,遠比 thread 來的有效率。就我看來,若需要大規模的平行處理,還是 thread 合適。但是像這次的案例,只是希望將片段的任務以非同步的模式進行,重點在精確的切割任務,同時要在特定的 timing 等待先前的任務完成,這時 async / await 會合適的多。
-
[Azure] Multi-Tenancy Application #3, (資料層)實作案例
上篇花了一堆口水,說明各種 data layer 的設計方式,這回不噴口水了,直接來實作…。
開始前先說明一下我的期望,我先假設各位都用過 Entity Framework 或是這類的 solution, 我希望在 data context 這層,就能處理掉所有隔離 tenancy data 的問題,也就是我可以用一般 application 的開發概念來開發 multi-tenancy 的 application。換另一個說法,我希望在一個 storage 內,模擬出讓每個 tenancy 都有獨立的 storage 可運用的介面。
Web 的這部份也是一樣的概念,我希望在網址這層,邏輯上就讓每個 tenancy 有獨立的 URL (虛擬目錄)。有這種網址上自行客製的需求,當然是非 MVC 不可,因此這次會在 MVC 的 Routing 上動手腳,除了 controller 及 action 之外,能夠再切出一層 client 出來,讓 application 也像是能夠虛擬化一樣,每個用戶可擁有自己的 partition。
最後當然也希望 WEB 這邊的架構,能緊密的跟 DATA 這邊結合。讓開發人員就照一般的方法就能快速開發出Multi-Tenancy Applicaiotn。寫這種系統,若規模不夠大就沒意思了,因此我初期就把目標鎖定在 Windows Azure Storage + MVC4, 而應用程式就以常見的 “訂便當系統” 為案例。
訂便當系統,是個很適合開發成 Multi-Tenancy 模式的主題。原因有幾個:
-
這系統一定是一個團體才會需要用的,如果你只有兩三個人,用講的比較快… 通常是部門、辦公室、或是規模不大,可以一起訂便當的團體會需要使用。這需要基本的每日訂單管理,還有簡單的會員管理功能。
-
既然是 Multi-Tenancy Application, 那麼用 SaaS (Service as a Service) 的方式營運也是很理所當然的。所有客戶通用的內容,就可以由營運單位來負責整理及規劃。
-
除了切割很多獨立的 “分割區” 各自運作之外,Hosting 的一方其實也有很多商機,像是合作的餐聽或是便當店,這些資料就可以共用。甚至是可以主動匯入,讓客戶訂購起來更方便。若這樣能為便當店帶來生意,Hosting 的一方抽點庸金也是很合理的 XD
-
後台 BI 也是很有商機的一環。Service Hosting 的一方,就可以看看各種統計報表,看跟那家餐廳合作的機會較大,另外也可以設計客戶 share 他們自己開發的便當店資訊,給其它客戶使用。若越多客戶採用,可以給些系統租金的回饋等等….
越想越多,再想下去這個 POC 用的 prototype 就寫不完了,需求給各位讀者再去延伸,我這邊作 POC 就把需求收殮一下…。偷學一下 SCRUM 的 story 撰寫技巧,以下是我這次 POC 要實作的 stories:
好,看來一個設計良好的 DataContext, 可以省掉不少工夫。大部份的 coding logic, 都是在客戶的專區內運作的。我把整套系統稱作 “Hub”, 而每個客戶專區內的資料,就通稱為 “HubData”, 如會員資料,或是訂單等等。而其它非 HubData, 就是整個系統通用的資料。因此,我希望 Hub 用的 Data Context 能有這些功能:
- 取得 HubDataContext 時,就已經能確定目前是在那個 Client 的使用範圍。
- HubDataContext 能直接提供該 Client 才能用的 Data Collection, 我只要拿來再用 Linq 過濾即可,即使我沒控制好,也不會拿到別的 Client 專區內的 HubData。
- 全域 (共用) 的資料則不在此限。每個 Client 都能完整存取這些資料內容。
OK,噴了三篇的口水,終於看到第一段程式碼了 Q_Q,HubDataContext 的 interface 看起來要像這樣:
使用它的 Code 要像這樣 (這段我就寫在 unit test 內…):
花了一點時間,總算把實作都寫出來,成功通過單元測試了。套句 Luddy Lee 前輩常說的話,寫雲端的程式測試跟佈署都比以前麻煩,因此做好完整的規劃跟測試就變的更重要了,單元測試是少不了的,請各位切記。過去吃了很多苦頭,更加證明 Luddy Lee 前輩講的話一點都沒錯….
最終的 HubDataContext 實作如下… 其實也沒幾行:
OK,第一步通過了,接下來我們開始來規劃一下 Data Schema …. Azure Table Storage 已經沒有所謂的 “schema” 這回事了,它完全就像 EF5 裡面的 code first 一樣,你的 Data Entity class 定義好,就可以跑了… 這些細節就不在這篇裡多做說明,各位有興趣可以參考其它的資料。既然都是 Code First 開發模式了,我就直接用 class diagram 來描述這些資料 (Entity) 之間的關係:
-
-
[Azure] Multi-Tenancy Application #2, 資料層的選擇
其實上一篇設計概念還沒寫完,只不過很晚了想睡覺就先貼了,本篇繼續..
之前介紹 MSDN 的那篇文章,作者很精確的分析了資料層面的三種設計方式。不過仔細研究之後,真正能搬上台面的,也只有最後一種 “Shared Schema” 而已。我從系統實際運作的角度,來分別考量這三種方式的可行性,各位就知道我為何這樣說了..。上篇介紹了各種可行的方案,這篇則會說明我認為的最佳方案。
我的看法很簡單,除非你的 Multi-Tenancy 的 “Tenancy” 規模只有幾十個的數量,否則 Separated DB / Separated Schema 都不適用,因為這兩種方式都是依賴把資料放在不同的 DB 或是 TABLE,來達到隔離的目的。並不是說這樣不好,而是這些都是 “過渡” 的作法,讓傳統的 application 不需要大符修改就能化身變為 Multi-Tenancy 的應用系統。而且 database / table 的數量都是有限制的,無法無限制的擴張。同時,以系統設計的角度來看,在系統執行的過程中,動態去建立 DB 或是建立 TABLE 也不是個很好的作法,在我眼裡都會覺的這是禁忌 XD。
當你辛辛苦苦建立了 SaaS 服務,總不可能只服務兩三隻小貓吧? 因此下列的分析會用使用量及 DB 各種功能的理論上限來做簡單的評估。Multi-Tenancy 的用戶數量,就抓個 50000 好了,至於每個用戶的 profile 我也依過去的經驗大致預估看看。依這些假設,就可以來評估各種資料層的處理方式,會有啥問題。
以下是一般的應用,每個用戶需要的資料規模 (假設):
平均數量 資料表 (table) 500 物件 (Sql obj, 如 table, view, trigger, function… etc) 5000 資料筆數 (rows per table) 100000 總容量 (data size) 5GB 1. 能容納的用戶量限制
以 SalesForce.com 為例,它會為每個 “公司” 開設一個專區,接著看該公司買了多少帳號,就開幾個 User Account。這裡的 “公司” 就是一個用戶,也就是 Multi-Tenancy 裡指的 “Tenancy”。這用戶的數量合理的數量應該是多少? 而系統的理論上限又是多少?
實際運作當然還有軟硬體搭配跟效能問題,這理就先就 “理論上限” 來探討。理論上限值,應該要在任何情況都足夠使用才合理。我特地去挖了 Microsoft SQL Server 的各種物件的數量上限,下表是從官方資料 整理出來的,以目前最新的 SQL 2012 為準,單一一套 SQL SERVER 可以:
數值名稱 最大上限 Database size 524272 TB Databases per instance 32767 Instance per computer 50 Tables per database 2147483647 (所有database objects總數上限) User connections 32767 看起來,最需要注意的就是 database 數量了。一套 SQL SERVER 最多只能開設3萬個database, 如果你採用 Separated DB 的作法,不論使用量為何,連同試用用戶,或是測試用戶在內,只能給三萬個用戶使用… 雖然不見得每個系統都會有這麼多用戶,不過一定會有不少熱門的應用會超出這樣的限制。
那第二種切割作法 (Separated Schema) 情況如何? SQL server 是以 database objects 的總數來計算的,包含 table, view, function, trigger 等等都算是 database object. 一個資料庫能容納 2G (20億) 個 database objects, 相當於能容納 400K (40萬) 個用戶。這數值比 Separated DB 的 3 萬好上一些… 在台灣,以公司為單位的服務,應該還沒有問題。若是以部門、團隊、或是家庭、社團設計的 application, 這樣的容量上限就需要耽心了。
Share Schema 則完全沒這些問題,只要儲存空間足夠,系統的效能能夠負耽,就沒有這種物理的上限限制了。
2. 效能擴充 (scale out) 的限制
如果考量到大型一點的規模,其實這三種方式都有困難。Separated DB 本身就已經是獨立DB,SQL server 本身執行的負擔就大很多,對於數量很多的用戶,但是每個用戶的人數都不多時,會浪費太多系統資源在執行這堆 DB 上面。不過相對的,這種架構很容易做 Scale Out 的擴充。
另一個要考量的是,雖然稱做 Multi-Tenancy, 但是總有些資料是要讓全部的用互共用吧? 這時這類資料就會變的很難處理,一個不小心就會動用到橫跨上千個 database 的 sql query ..
另一個極端的 Share Schema 做法就完全相反,沒有執行多個 DB 的負擔,執行起來效能是最好的。但是因為所有資料都塞在一起,很容易就面臨到單一 table 的資料筆數過大的問題。以這次的例子,一個用戶有10萬筆資料的話,隨便 1000 個用戶就有 1 億筆資料了… insert / delete / update 資料時,更新 index 的成本會變的很高。一般的查詢就會很吃力了,若是碰到沒寫好的 table join 會更想哭… 換句話說,這樣的架構規劃下,資料庫的最佳化非常的重要。因為你面臨到的就是大型資料庫效能調校問題..
再者,資料庫相對於 WEB 來說,是很不容易 Scale Out 的… 比較合適的作法是對資料庫做 Partition. 不過,這也不是件容易的事,已超出我的理解範圍了 XD,我只能說,要是老闆決定這樣做,那 $$ 決對是省不了的…
3. RDBMS 之外的選擇: Azure Table Store
前面講的,其實都是幾年前我在傷腦筋的問題。傳統的資料庫是為了資料的正確性及一致性而打造的儲存技術,過多的限制 (schema, constraint, relation…) 也限制了它無法有效 scale / partition 的特性。要徹底解決這些問題,不砍掉重練的話就只能花大錢及人力,來追上雲端服務的使用量了…。
不論是 Google, 或是 Microsoft Azure, 或是依據 Google 提出 MapReduce 而發展出來的 Hadoop, 都有處理巨量資料的能力。我就挑我最熟的 Azure 來說明。近幾年資料庫相關的技術,開始有了不一樣的變化。開始出現 “NO SQL” 的資料儲存方式。這種儲存方式有著跟 RDBMS 完全不一樣的特性,它比較簡單,主要是以 Key-Value 的型式來存取。因為 NO SQL 的結構比 RDBMS 簡單,因此能夠很容易的做到 scale out, 將單一資料庫,擴充到上千台 server 的規模。而 Azure 提供的 Table Storage, 則是將這種 NO SQL 的資料,跟 RDBMS 表格式的資料,做了一個很好的串接。
想瞭解 Azure 的細節,這輪不到我來說,市面上有幾本書很不錯,像是 MVC 小朱的新書,或是大師 Lee Ruddy 的大作都很值得參考,若不介意看英文書,那選擇就更多了~,我就不在這多說太多了。但是 Azure Table Storage 有兩個很重要的特色,一定要講一下:
1. PartitionKey / RowKey:
老實說,這對 Multi-Tenancy 來說,是最完美的設計了。這篇文章講的很精闢,你要用 Azure Table Storage 的話一定要好好的研究 PartitionKey / RowKey, 因為我看過太多可笑的用法,實在糟蹋了這樣好的設計…。這篇文章前面講的都是howto, 最後一章是 “Why using Windows Azure Table Storage”, 我截錄一段:
The storage system achieves good scalability by distributing the partitions across many storage nodes.
The system monitors the usage patterns of the partitions, and automatically balances these partitions across all the storage nodes. This allows the system and your application to scale to meet the traffic needs of your table. That is, if there is a lot of traffic to some of your partitions, the system will automatically spread them out to many storage nodes, so that the traffic load will be spread across many servers. However, a partition i.e. all entities with same partition key, will be served by a single node. Even so, the amount of data stored within a partition is not limited by the storage capacity of one storage node.
The entities within the same partition are stored together. This allows efficient querying within a partition. Furthermore, your application can benefit from efficient caching and other performance optimizations that are provided by data locality within a partition. Choosing a partition key is important for an application to be able to scale well. There is a tradeoff here between trying to benefit from entity locality, where you get efficient queries over entities in the same partition, and the scalability of your table, where the more partitions your table has the easier it is for Windows Azure Table to spread the load out over many servers.
翻成白話,意思就是,開發人員只要慎選 partition key, 則 Azure 就會把同一個 partition 的資料放在同一個 node (不限於同一個 table 的 entities)。因此查詢會受惠於各種 cache 及 optimiaztion 機制,得到最佳效能。同時 Azure 也會自動依照 partition key 來分散到多個 node, 達到最佳的 scalability。
2. Scalability Issues, and Query optimization issues
另外,MSDN magazine 也有一篇值得一讀的文章… “Windows Azure Table Storage – Not Your Father’s Database” (中譯: 不是令北的資料庫… Orz), 一樣切重點出來:
PartitionKeys and RowKeys Drive Performance and Scalability
Many developers are used to a system of primary keys, foreign keys and constraints between the two. With Windows Azure Table storage, you have to let go of these concepts or you’ll have difficulty grasping its system of keys.
In Windows Azure Tables, the string PartitionKey and RowKey properties work together as an index for your table, so when defining them, you must consider how your data is queried. Together, the properties also provide for uniqueness, acting as a primary key for the row. Each entity in a table must have a unique PartitionKey/RowKey combination.
這篇就實際一點了,講到很多 Azure Table Storage 的特性,也帶出了設計時必需考慮的要點。因為設計理念不同,連帶的查詢時的限制 & 表現,跟傳統的 RDBMS 完全不同… 有沒有仔細規劃 partition key / row key, 決定了你的 query 效能的好壞。
除了內定的 partition key / row key 之外,其它 “欄位” 完全沒有任何的索引機制。這就是最需要顧慮的地方。實際上,Azure Table Storage 跟本就沒有 Schema 的設計,當然也沒有像 RDBMS 那樣的表格,反而是個典型的 Key-Value Pair 的 storage 而已。至於這些看起來像欄位的東西,完全是用 Code (TableEntity) 跟實際儲存的 Data (應該是 XML,或是類似的結構化 data) 變出來的東西。也因此,Query 完全需要良好的規劃才能有好的表現。
若各位對 Azure Table Storage 的 Query 技巧有興趣,這段 VIDEO 很值得一看。這是 2009 PDC 的一個場次: “Windows Azure Tables and Queues Deep Dive”, 講到很多 Query 的技巧..
再回到前面那篇參考文章,最後作者也列了一些缺點及建議,強烈建議各位在決定採用 Azure Table Storage 前要認真閱讀:
Windows Azure table storage is designed for high scalability, but there are some drawbacks to it though:
- There is no possibility to sort the data through your query. The data is being sorted by default by the partition and row key and that’s the only order you can retrieve the information from the table storage. This can often be a painful issue when using table storage. Sorting is apparently an expensive operation, so for scalability this is not supported.
- Each entity will have a primary key based on the partition key and row key
- The only clustered index is on the PartitionKey and the RowKey. That means if you need to build a query that searches on another property then these, performance will go down. If you need to query for data that doesn’t search on the partition key, performance will go down drastically. With the relational database we are used to make filters on about any column when needed. With table storage this is not a good idea or you might end up with slow data retrieval.
- Joining related data is not possible by default. You need to read from seperate tables and doing the stitching yourself
- There is no possibility to execute a count on your table, except for looping over all your entities, which is a very expensive query
- Paging with table storage can be of more of a challenge then it was with the relational database
- Generating reports from table storage is nearly impossible as it’s non-relational
If you can not manage with these restrictions, then Windows Azure table storage might not be the ideal storage solution. The use of Windows Azure table storage is depending on the needs and priorities of your application. But if you have a look at how large companies like Twitter, Facebook, Bing, Google and so forth work with data, you’ll see they are moving away from the traditional relational data model. It’s trading some features like filtering, sorting and joining for scalability and performance. The larger your data volume is growing, the more the latter will be impacted.
看起來蠻恐佈的,由於架構的不同,Azure Table Storage 無法題供像 RDBMS 那樣多樣化的查詢能力,除了 partition key / row key 之外,甚至連 RDBMS 最基本的 index 都沒有,這也導至這篇的作者連這點也列入缺點 “Generating reports from table storage is nearly impossible as it’s non-relational” …
不過,實際的狀況其實沒這麼嚴重。Azure Table Storage 極為強大的 scalability 可以彌補查詢上的不足,平行的查詢,及針對巨量資料的設計,都是你在處理巨量資料的武器,而這些是 RDBMS 所無法提供的。
寫到這裡,我簡單下個結論。Azure Table Storage, 是個很棒的 “storage”, 有絕佳的延申及擴充能力。能夠輕易的儲存及處理巨量資料,不論是資料大小或是資料筆數都一樣。不過它畢竟不是 “R”DBMS,而是 NO SQL這一類的 storage, 因此在執行覆雜的 QUERY 上不是 RDBMS 的對手。一些統計方面的功能 (如 SUM, COUNT, AVERAGE …. 等等) 就更不用說了。這部份得靠 ORM、Linq 及你的程式來補足。
而 Azure Table Storage 的規劃就將 partition 的機制放進去了,拿來做 Multi-Tenancy 的資料切割機制真是絕配! 跟本就是為了這樣的應用而設計的… 下一篇我會示範實際的程式碼,用 Azure Table Storage 來實作 Multi-Tenancy Applicaion 的 Data Layer ..
-
[Azure] Multi-Tenancy Application #1, 設計概念
對,各位你沒看錯,我的部落格在隔了一年半之後又有新文章了 XD
好久沒寫了,這年頭什麼東西都流行加個 “微” … BLOG 有微博,Messenger 有微信… MV有微電影… 連我們在做的數位學習也出現 “微型課件” … 什麼都微型化的後果,就是越來越懶的 POST 這種 “大型” 的文章在 BLOG 上了.. 常常想到一些東西,還沒成熟到一個完整概念,就貼到 FB 上,越來越速食的結果就越來越沒顧到 BLOG… Orz…
不過,世界果然是在往M型的方向發展,雲端到現在已經是個成熟的技術 & 概念了,WEB APP的開發也越來越大型化,用了 Azure 當 PaaS (Platform as a Service) 後,要開發大型的 Web Application 門檻也不像過去那麼高。這次要寫的,就是 SaaS (Software as a Service) 被廣為流傳的設計概念: 多租戶 (Multi-Tenancy) 的設計方式。
其實說明 SaaS 或是 Multi-Tenancy 的文章一大堆,完全輪不到我這種文筆程度的人來寫 XD,一樣,我只針對特別的地方下筆。Multi-Tenancy 顧名思義,就是讓一個 Application 能做適當的切割,”分租” 給多個客戶使用。跟過去一個 Application 就服務一個客戶不一樣,Multi-Tenancy 先天就是設計來服務多個客戶用的,也因為當年 SalesForce 的成功而聲名大噪。
回到系統的角度來思考,要設計一個漂亮的 Multi-Tenancy (Web) Application, 還真的是個不小的挑戰… 沒錯,我就吃過這種苦頭 XD,大概六年前因為工作上的關係,就已經有這樣的設計架構了,不過當年一切都要自己來,因此什麼釘子都碰過了。用現在的技術,有太多簡潔的作法,不過確看不到有太多的人在討論 (至少中文的沒有),就動起這念頭,想來寫幾篇.. 內容就定位在用當紅技術: Microsoft Azure + ASP.NET MVC4 當作底層開始吧~~
先來探討一下幾種常見的 Multi-Tenancy 的設計方式。MSDN 有篇文章寫的很精闢,快七年前的文章了,當年靠著這篇給我不少靈感… 我就先來導讀一下,標一下幾個架構設計的重點 (底下圖片皆引用 MSDN 該篇文章):
三種架構: Separated DB / Separate Schema / Shared Schema 比較:

要把多個客戶塞進同一套系統內,最直接的問題就是資料隔離的 issue 了。暫時不管 application, 只管 data, 若對隔離及安全性要求越高,就要在越底層就做到隔離的機制。
-
Separated DB

最高隔離等級,就是每個客戶一個 database (Separated DB)。用這種模式,再怎麼粗心的工程師,也不會不小心把別的客戶的資料給秀出來。舉個例,系統內的A客戶,就會連到A資料庫,B客戶就用B資料庫。每個客戶的資料庫各自獨立,不會互相打架。
-
Separate Schemas (Shared Database)

這種作法比第一種 Separated DB 好一點,它共用同一個 DB,但是替每一個客戶建立一組 Tables。這種作法不需要那麼高的成本 (看過 $$ 就知道,資料庫很貴的….),多個客戶可以共用資料庫,不過因為 Schema 的層級隔離了,簡單的說不同客戶的 Table Name 是不一樣的,因此粗心的工程師造成客戶資料混在一起的機率也不算高,還有不錯的隔離機制。
這方式實作有點辛苦,不過 SQL 2005 之後開始支援 Schema 這機制,實作上可以簡單的多。
-
Shared Schema (Shared Database & Shared Schema)

這作法最極端了,所有資料都放在同一個資料庫,同一組資料表… 靠的是一個客戶ID的欄位來區別。這種方式成本最低,設計也最簡易直覺,不過… 整個系統只要有一道 SQL query 寫錯 (漏掉 where TenantID = ‘MyAccount’),一切就完了,A客戶的資料就會出現在B客戶的報表裡…
當然,這篇是 MSDN 的文章,自然也提到了 Microsoft 的技術 (SQL server) 如何因應這三種不同的需求。這張表格是整篇文章的精華了,很清楚的講到三種模式,對各種問題的最佳處理方式。表格貼不過來 @@,我直接用截圖來說明:
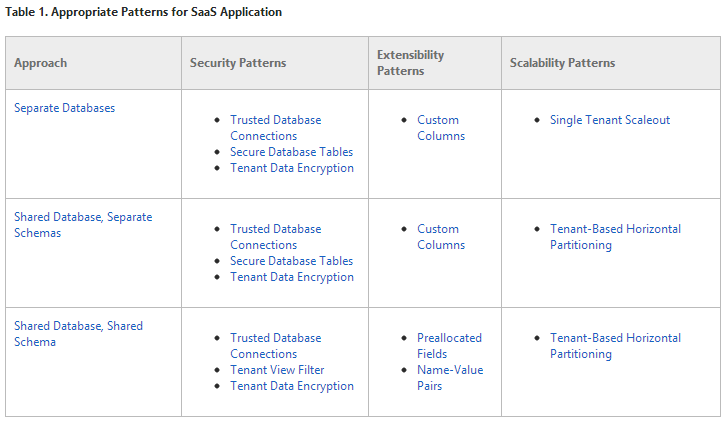
簡單舉個例子,Extensibility Patterns 這欄說明的是如何擴充你的資料? 這裡指的擴充不是指效能,是只你要如何增加新的資料型態?
Separate DB or Shared DB 最簡單,就照一般的方法,開新的欄位就好。對於 Shared Schema 的系統來說就沒這麼容易了,只能預先開幾個備用欄位 (如每個 table 都開: column1, column2, column3 …. etc),不然就只能弄出像 NO SQL 那種 Name-Values 的方式來處理。不過,有經驗的開發者都知道,這樣搞下去,QUERY 實在很難寫…
其實這篇文章講的很務實,從設計架構、開發、到系統上線的維護及調校都講的很清楚,若各位有在企業內部 (INTRANET) 的環境建立 Multi-Tenancy Application 的需求,只能用 Windows Server + SQL Server 的話,這篇文章很值得參考。不過,這篇文章的時空被景是 2006 年,當年沒有 Azure 這種東西… MVC 也沒今天那麼成熟… 現在要做同樣的事,你有更厲害的武器可以用…
現在該怎麼做? 當然是等下一篇 XD
-
