
在今年 .NET Conf 2018, 我講了一個場次: Message Queue Based RPC, 內容就是這篇文章的前半段… Message Queue 本身的架構就容許部分服務掛掉也還能正常運作,是高可靠度 / 非同步通訊不可或缺的一環啊! 這個場次我說明了如何用 C# 把 Message Queue 封裝成 RPC, 同時支援 C# async / await 的整個過程跟細節。不過時間只有短短的 50 分鐘,要交代完整的來龍去脈實在有點困難啊,剩下的部分我就在這篇文章補完。
這類主題,拉得更高一點來看,目的其實是整合啊! “架構師” 在這幾年變成技術職的終極目標,不過軟體業的市場還很年輕,市場上有經驗的架構師也不多啊,很多文章都在談論架構師到底該做些什麼事? 其中有一點很多文章都有提到,就是 “技術選型”。架構師應該用他的專業及經驗,替團隊挑選一個符合現況及將來發展的技術。這句話並沒有錯,不過我看過幾個例子,都沒有做到位;因為選完之後,下一步就是要應用啊! 成熟的服務或是框架,在現在的時空背景下其實不是個大問題,但是每個團隊面臨的商業需求,歷史包袱,團隊組成狀況等等都不同,很難有哪一套服務或是框架可以適應所有情況的。因此你做完技術選型後,下一個難題是將這些技術 “整合” 起來給團隊使用。
這就是我這篇文章想要表達的;我們挑選了 RabbitMQ 當作我們服務背後的 Message Queue, Message Queue 掌控了可靠的通訊核心, 非同步的通訊,到 CQRS, 到 Event Driven 事件驅動, 訂閱 / 通知 等類型的通訊都需要靠他,我期望內部團隊能發展出一套體系,能將這些機制串在一起。這些機制整合的好,團隊的能力就能往上提升一個檔次。既然整個體系,是架構師規劃出來的,該如何 “整合”,自然是架構師最清楚其中的關鍵了。我一直期望我對團隊的貢獻不只是紙上的規劃而已,而是能真正融入開發,從 code 層面就能幫助團隊提升。因此這篇我就打算從 Message Queue 幾個應用場景切入,示範一下從架構的角度,該如何看待 Message Queue 的整合這件事?
這篇我會從封裝開始,只把我對於 Message Queue 想要解決的問題點出發,從這角度規畫出封裝後的介面該長什麼樣子,其餘的細節如何善用 C# / .NET 的機制藏到背後。背後需要進一步跟其他的基礎建設 (如: configuration, cloud / container infra, security, logging 等等) 整合,這整套的環境很難找到現成而且合用的,大部分團隊都需要自行建立。因此,我從 Message Queue 要解決的問題: 通訊 為出發點,整篇文章分幾個段落,先從封裝 “通訊” 這件事開始,帶到 Message Worker 這類長時間執行的背景服務開發,到非同步通訊如何跟 C# 的 async / await 整合,最後帶到如何跟 container orgistration 密切整合,不需要額外的管理工具就能做好 MessageWorker 的 scale managemnet。
雖然我不是果粉 (我沒有 mac / iphone … XD), 但是 Steve Jobs 的這段話我心裡非常認同,我特地把這段抓出來膜拜一下:
當然,當我在大學往前看時,把點連接起來是不可能的,但十年後往後看它是非常,非常清楚的。再提一次,往前看時你無法把點連起來。只有往後看時你才能連接它們,所以你必需相信點將在你的未來以某種方式連接。你必需相信某些事情 – 你的直覺、命運、人生、因緣、不管是什麼 – 因為相信點將在未來的路上連接起來將帶給你追隨內心聲音的信心,即便它引領你離開已被踏平的步道,而那將造就所有的不同。
出處: Steve Jobs’ Stanford Commencement Address 2005
會想寫這篇 (包含 .NET Conf 2018 那場演講),其實背後的原因很簡單,就是工作上要用啊 XD, 這些準備動作先做好,團隊才能有效率的把舊的系統逐步搬移到微服務架構。我常常講微服務架構,其實考驗的就是你治理大量服務的能力啊! 面對的範圍越廣,你越需要廣泛的知識與經驗。賈伯斯那段演講講得很對,你無法預期你將來會需要什麼能力,你只能不斷的累積,直到哪天你會突然發現這些事情都可以連在一起。
![]()
圖片出處: https://twitter.com/hughcards/status/423952995240648704
就像這張圖要表達的一樣,我寫這篇就是這種感覺;如果沒有剛開始工作時無意間聽了前輩上課教我們怎麼寫 thread pool (java), 沒有十年前因為工作需要研究了一堆平行處理的技巧,也寫了好幾篇文章 (還有投稿 RUN!PC),沒有三年前突然某根筋不對開始研究 docker 跟 linux, 現在我面對這些整合問題應該拿不出我滿意的解決方案。這內容其實是我準備要拿來內部訓練用的,只是現在回頭看,當年學了也沒機會用到的技巧 (台灣軟體業大部分都做 SI 啊,基礎科學沒有太多公司重視),現在回頭看才發現過去的努力沒有白費。台灣的軟體業很缺這樣的經驗跟案例,所以我想把這些經驗寫下來給需要的朋友參考。
回到主題吧,往下看下去,你可以學到幾件事:
- 如何善用 C# 的語法,將 Message Queue 封裝為 RPC
- 如何跟 environment 整合, 搭配 DI framework 解決環境耦合問題
- 想辦法讓你的 code 做到 design for operation, 達到 self management 的層次。
細節就直接往下看吧! 技術領域這條路,不見得要一直追趕最新的 framework, tools, language 啊,尤其是擔任架構師的角色,比起精通你更需要的是宏觀,你才能做出正確的判斷帶領團隊前進。
前言: 微服務架構 系列文章導讀
Microservices, 一個很龐大的主題,我分成四大部分陸續寫下去.. 預計至少會有10篇文章以上吧~ 目前擬定的大綱如下,再前面標示 (計畫) ,就代表這篇的內容還沒生出來… 請大家耐心等待的意思:
- 微服務架構(概念說明)
- 實做基礎技術: API & SDK Design
- API Design #1 資料分頁的處理方式; 2016/10/10
- API Design #2 設計專屬的 SDK; 2016/10/23
- API Design #3 API 的向前相容機制; 2016/10/31
- API Design #4 API 上線前的準備 - Swagger + Azure API Apps; 2016/11/27
- API Design #5 如何強化微服務的安全性? API Token / JWT 的應用; 2016/12/01
- API First Workshop: 設計概念與實做案例
- API First #1 架構師觀點 - API First 的開發策略 - 觀念篇; 2022/10/26
- API First #2 架構師觀點 - API First 的開發策略 - 設計實做篇; 2023/01/01
- (計畫) API First # 微服務架構 - API 的安全機制;
- 架構師觀點 - 轉移到微服務架構的經驗分享
- 基礎建設 - 建立微服務的執行環境
- 案例實作 - IP 查詢服務的開發與設計
- 容器化的微服務開發 #1 架構與開發範例; 2017/05/28
- 容器化的微服務開發 #2 IIS or Self Host ? 2018/05/12
- 建構微服務開發團隊
- 分散式系統的基礎知識
- 分散式系統 #1 如何保證 API 呼叫成功? 談 Idempotency Key 的原理與實作
團隊專屬 SDK: 通訊機制封裝
跨服務間的通訊永遠都是分散式系統的關鍵問題。跨服務間的通訊,絕對不會只有我 call 你的 API (HTTP REST) 這麼單純而已。不同的服務之間有很多通訊方式,從最無腦的共用資料庫: share database / stroage, 到非同步通訊: event driven (publish / subscribtion), event sourcing (stream data + cqrs), 到同步通訊: HTTP RESTFul / gRPC … 等都算。
如果你需要兼顧非同步,單向或雙向,甚至更複雜的情境,透過可靠的 Message Queue 已經是很基本的選項了。我們團隊挑選了 RabbitMQ + CloudAMQP 當作底層的通訊管道,而非直接選用特定 cloud provider 專屬的方案。由於有大量的商業邏輯需要仰賴 Message Queue 來簡化,因此靈活的 exchange / queue 的組合變成挑選的重點。
看了 RabbitMQ 的 sample code, 發現要駕馭他強大的彈性,要花上一些功夫啊,為了把訊息送出去,到另一端接收回來,就需要寫上幾十行 code。若是過程中還要經過團隊其他機制的處理 (EX: 例如透過集中的 configuration 取得連線資訊,或是訊息 header 必須傳遞認證授權機制等等),那就更複雜了。先對內部的需求進行抽象化及封裝的處理是有必要的,這也是我一直在講的: 先針對挑選的 tech stack 進行整合、封裝、抽象化之後,再交給團隊大量使用。
抽象化: Message Client / Worker
Message Queue 需要什麼樣的封裝? 撇開其他系統層面的需求 (例如上面提到,要整合 configuration 等等…), Message Queue 真正要面對的需求就是訊息傳遞而已啊,無法先替團隊決定的是 Message 的內容與格式,但是格式確認之後的傳輸處理 (send / receive) 卻可以事先準備好,同時也包含單向與雙向通訊的處理,於是這就成為第一版的設計目標了。
因此,我理想中,要交付給開發團隊的 SDK 應該長什麼樣子? 我以下用一段概念 code 代表:
傳送端我想提供這樣的 SDK (單向):
public class MessageClient<MessageBody>
{
// return: message id
public string Send(string routeKey, MessageBody message);
}
而接收端複雜了點,接收到訊息之後要接著處理,這段每個人都不一樣,因此我定義 delegate 讓使用的 developer 自行準備:
public class MessageWorker<MessageBody>
{
delegate void MessageWorkerProcess(MessageBody message);
public MessageWorkerProcess Process = null;
public async void StartAsync() {...}
public async void StopAsync() {...}
}
我宣告了個 delegate 說明 Message 收到後接手的處理程序的 function signature, 之後就等各位自行定義。用起來大概像這樣:
using(var worker = new MessageWorker<MyMessage>() {
Process = (message) => { ... }
})
{
await worker.StartAsync();
// ...
await worker.StopAsync();
}
上述的抽象定義,大概能表達出我想開放給團隊使用的介面應該長什麼樣子。其餘多餘的實作應該盡量的封裝起來才對。先從最單純的單向通訊開始,我們先來看看第一版的實作
單向傳遞: MessageClient 介面定義
實作的 code 包含太多細節,跟主題 (架構) 無關的細節我就略過了。有興趣的可以自行參考 source code, 也歡迎在 FB 留言討論相關細節。
MessageClient:
public abstract class MessageClientBase : IDisposable
{
// 略
}
public class MessageClient<TInputMessage> : MessageClientBase
{
public MessageClient(
MessageClientOptions options,
TrackContext track,
ILogger logger) : base(options, track, logger)
{
// 略, init rabbit mq connection
}
public string SendMessage(
string routing,
TInputMessage intput,
Dictionary<string, string> headers)
{
string correlationId = ...;
// 略, publish message to specified queue and return correlation id
return correlationId;
}
}
Demo Code:
// insert 5000 messages
long _message_max_count = 50000;
using (var client = new MessageClient<DemoMessage>(new MessageClientOptions()
{
ConnectionName = "benchmark-client",
BusType = MessageClientOptions.MessageBusTypeEnum.QUEUE,
QueueName = "benchmark-queue"
},
null,
null))
{
for (int i = 0; i < _message_max_count; i++)
{
client.SendMessage("", new DemoMessage(), null);
}
}
這版實作我把 configuration (MessageClientOptions) 都獨立出來了,如果你有慣用的 DI (Dependency Injection) framework 的話,可以直接用注入的方式整合進來。為了避免文章內容又爆版面,我只放介面與如何使用的 demo code。
基本的使用應該不用多說了吧,就是想辦法生出 MessageClient, 給他適當的 options 建立連線後就可以用了。封裝訊息的 DemoMessage 並沒有特別的規範,他的角色類似 WCF 的 Data Contract, 只要能正確的被 NewtonSoft.Json 進行序列化跟反序列化就可以了。
另外有個重要的參數: TrackContext, 先交代一下 (後面再詳細說明):
透過 Message Queue, 實體上已經是跨越兩個獨立服務的呼叫了。就如同一般的呼叫會有明確的參數跟傳回值, 但是背後可能會有其他追蹤或是共用的變數需要一併傳遞,解決其他 domain 的問題。如果通訊方式是 HTTP,那 Cookie 就是個典型的例子了;藉由每個 request 都附帶 cookie 能夠協助 browser / web server 處理其他環節的任務。如果你需要靠 middleware 處理認證,或是任何其他 AOP 的應用,大概就能理解了。
這邊我把 cookies 這樣的應用,抽象化成為 TrackContext。實作上你可以自己決定內容 (我們的應用就是個 request id), 這些內容理論上應該透過環境的注入取得 (scoped service, 或是 http context 這類), 傳輸的管道應該也要跟 Message Body 區隔開來。我這邊的實作是透過 Message Headers。
單向傳遞: MessageWorker 介面定義
看完 MessageClient, 接著來看看對應的 MessageWorker 的介面設計:
public abstract class MessageWorkerBase : BackgroundService, IDisposable
{
// 略
}
public class MessageWorker<TInputMessage> : MessageWorkerBase
{
public MessageWorker(
MessageWorkerOptions options,
ILogger logger,
IServiceProvider services) : base(options, logger, services)
{
// 略
}
public delegate void MessageWorkerProcess(
TInputMessage message,
string correlationId,
IServiceScope scope = null);
public MessageWorkerProcess Process = null;
}
看到這邊你可能會丈二金剛摸不著頭腦,怎麼介面設計上只定義了 MessageWorkerProcess 外就沒有了? 說好的 Start() / Stop() 跑哪去了? 我在前一個版本 (.NET Conf 2018 講的那一版) 還是自己實作 worker 啟動及停止的部分,不過這版已經直接按照 .NET core 2.x 的規範: IHostedService 來實作了。上面的 DEMO code 用到的 StartAsync() / StopAsync() 就是由這個介面而來的。這個介面的實作實在太通用了,因此也有個對應的 abstract class 提供大部分的實作: BackgroundService,沒有太特殊的應用的話,直接繼承會比較容易。
Microsoft 定義了這個介面來統一規範所有需要在背景長時間執行的服務介面 (跟 Windows Service 沒有直接對應關係)。你可以定義自己的 IHostedService, 這些服務通通都可以裝在 IHost 裡面執行。你只要正確的處理 Start / Stop 行為即可。這是越來越熱門的容器化應用需要的運作模式,我在去年 .NET Conf 2017 講容器驅動開發也有講到這概念。這我在後面的段落再說明。這邊我先點到為止,讓你看的懂這段 code :
int worker_threads = 5;
long _message_max_count = 50000;
using (var server = new MessageWorker<DemoMessage>(new MessageWorkerOptions()
{
ConnectionName = "benchmark-worker",
QueueName = "benchmark-queue",
WorkerThreadsCount = worker_threads,
PrefetchCount = 0
},
null,
null)
{
Process = (message, cid, scope) =>
{
Interlocked.Increment(ref _message_per_second);
Interlocked.Increment(ref _message_total);
return;
}
})
{
var start = server.StartAsync(CancellationToken.None);
Console.WriteLine("Press [ENTER] to exit...");
Console.ReadLine();
await server.StopAsync(CancellationToken.None);
}
由於 Worker 的執行不是那麼直線思考,這段 code 我稍微說明一下。 MessageWorker 啟動後就會對 rabbit mq 初始化必要的 connection, channel,同時就開始註冊 event handler, 只要 channel 收到 message, 就會觸發 event, 交給 MessageWorkerProcess 這型別的 delegate 接手處理。
這些動作,都會在 MessageWorker.StartAsync() 之後開始生效,直到 MessageWorker.StopAsync() 被呼叫之後為止。由於這些行為都在不同的 threads 之間直行,因此你會看到主執行緒只有幾行,啟動後就等著 user 按下 enter 然後就結束。
var start = server.StartAsync(CancellationToken.None);
Console.WriteLine("Press [ENTER] to exit...");
Console.ReadLine();
await server.StopAsync(CancellationToken.None);
MessageWorker: 多執行緒平行處理
MessageWorker 背後藏著不少難搞的細節,包含 MessageWorker 啟動之後,背後其實準備了多個 thread(s), 以便來應付同時有多個 message 湧入的狀況。也因為這樣,當你呼叫 Stop() 時,若還有 message 還在處理中,你也不能立刻就結束,需要經過正常的關閉程序 (你可以想像銀行同時有 5 個櫃台,每個瞬間最多都有五個客戶被服務,就算要關門也要等這五個櫃台都處理完畢才行)。在呼叫 StopAsync() 的那瞬間,MessageWorker 就不會再接收新的 message, 同時會等待所有的 worker thread(s) 把處理到一半的 message 都正常處理完畢後,回報給 MessageWorker, 全部完成之後 StopAsync() 才能取得 result (也就是 await 會 return),讓主程式知到 MessageWorker 已經完全關閉,能夠正常離開。
為何要做這段? 有很大的原因,是為了將來上線時的維運考量。細節我在後面的 Auto Scaling 段落再說明。這邊我先交代如何正常的結束 MessageWorker 的運作。
這段的實作,算是最多技術細節的段落了,需要用到的技巧與知識不少,你會需要精確的 thread(s) control 的知識與技巧才能搞的定。我在 .NET Conf 2018 那場就足足花了 50 min 在說明這機制,有興趣的可以看當日的錄影。如果想看這些背後的運作機制,過去我寫了幾篇相關的 (Orz, 有的竟然十年了) 文章可以參考看看:
- 系列文章: Thread Pool 實作
- 系列文章: 多執行緒的處理技巧
- 參考文章: 在 .NET Console Application 中處理 Shutdown 事件
- 參考文章: 容器化的微服務開發 #2, IIS or Self Host ?
啟動 MessageWorker 的程序
由於細節都有上述資源可以深入了解了,這邊我就把架構上的幾個關鍵點交代一下,讓大家有個全貌可以知道這段在解決什麼問題。這段邏輯的核心其實只有這幾十行 code:
protected int _subscriber_received_count = 0;
protected AutoResetEvent _subscriber_received_wait = new AutoResetEvent(false);
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
this.Init();
// init multiple (worker_count) channel(s)...
List<IModel> channels = new List<IModel>();
List<EventingBasicConsumer> consumers =
new List<EventingBasicConsumer>();
List<EventHandler<BasicDeliverEventArgs>> handlers =
new List<EventHandler<BasicDeliverEventArgs>>();
for (int index = 0; index < this._options.WorkerThreadsCount; index++)
{
var channel = this._connection.CreateModel();
if (index == 0)
{
// 只 declare 一次
channel.QueueDeclare(
queue: this._options.QueueName,
durable: this._options.QueueDurable,
exclusive: false,
autoDelete: false,
arguments: null);
}
var consumer = new EventingBasicConsumer(channel);
void process_message(object sender, BasicDeliverEventArgs e) =>
Subscriber_Received(sender, e, channel);
consumer.Received += process_message;
channel.BasicQos(0, this._options.PrefetchCount, true);
channel.BasicConsume(this._options.QueueName, false, consumer);
channels.Add(channel);
consumers.Add(consumer);
handlers.Add(process_message);
}
//
// 關鍵: 等待 Worker Stop 指令
//
await Task.Run(() => { stoppingToken.WaitHandle.WaitOne(); });
// stop receive new message
for (int index = 0; index < this._options.WorkerThreadsCount; index++)
{
consumers[index].Received -= handlers[index];
handlers[index] = null;
}
handlers = null;
// wait until all process finished.
while (this._subscriber_received_count > 0)
{
this._subscriber_received_wait.WaitOne();
}
// dispose multiple channel(s)...
for (int index = 0; index < this._options.WorkerThreadsCount; index++)
{
channels[index].Close();
}
this._connection.Close();
}
這段其實就是整個 MessageWorker 完整的生命週期會做的事情了。RabbitMQ 分為 connection, channel, consumer .. 分這三層有他的用意。每一層背後都代表有對應的系統資源:
- connection: 對應一個實體的 TCP connection。
- channel: virtual connection, 官方文件 建議別跨越 threads 共享 channel, 因為 channel 會強制 message 的處理是按照順序的, 多個 thread 的效能會受到影響。
- consumer: 每個 consumer 會有專屬的 event handler (根據實驗, rabbitmq .net client 會替每個 consumer 準備 thread 來執行 event handler)。
所以,其實你也可以只用一個 channel 就產生多個 consumer 來接收 message, 但是實際上每個 channel 會對 message 的處理序列化 (意思是會 lock, 同一時間只能處理一個 message), 多執行緒共用 channel 會有明顯的效能問題。我預期 developer 會清楚自己的 message 在多少 concurrent threads 情況下會有最佳效能,因此將 threads count 的控制權交給 developer, 在 MessageWorker 內部就按照 threads 數量來配置 channel 跟 consumer。
停止 MessageWorker 的程序
其實這段 code, 把 channel / consumer 都產生好之後就沒事了,直到 MessageWorker 必須關閉時,才會啟動後半段的 code… 中間有個關鍵的一段:
stoppingToken.WaitHandle.WaitOne();
這段會去等待 stoppingToken, 直到外面 (通常是 IHost) 對 BackgroundService 下達 StopAsync() 指令後,才會 return… 你可以把這行 code 當成分段點;前段是準備作業;後段則是關閉作業。
至於這段為何要脫褲子放屁,把 blocking call 還用 Task 多包一層:
await Task.Run(() => { stoppingToken.WaitHandle.WaitOne(); });
這又是另一段故事了。這是為了配合 C# async 的規格。BackgroundService 的 Start() 內部會 await ExecuteAsync(...) 的方式呼叫它,因此在這 method 內必須用 await 告訴 caller (其實我去 trace .NET core source code 才搞懂這段的), async call 可以在這個地方 return Task 了。這可以讓外面的 code 在 init MessageWorker 之後就能 async return 先去忙別的事情 (例如上例的等待 user 按下 ENTER …)。
後半段就是反過來的動作了。RabbitMQ 的文件找不到正常的終止程序該怎麼搞,這段是我自己 try & error 試出來的方案。MessageWorker 決定終止之後,我第一件事情先把 consumer 的 event handler 拔掉,這並不會阻止 consumer 接收新的 message (應該啦), 但是可以阻止接收到的 message 交給 process 去處理。不處理的話就不會 ack, 所有尚未 ack 的 message 都會在 connection close 後直接回歸回 queue 等待下個有緣的 worker ..
源頭斷掉之後,剩下的就是等待每個已經交給 process 處理的 message 完成即可。我搭配一個計數器,統計目前正在處理中的 message 有多少個 (我用 Interlocked 物件確保這數字,process 進入時 +1, 離開時 -1, threadsafe)。檢查的時機我不是傻傻地用無窮迴圈 + timer 不斷的去檢查,我用 WaitHandle 的機制,任何一個 process 處理完 message 時,就會 Set WaitHandle, 這回圈就會立刻被喚醒,確認這是否是最後一個 message? 不是的話就繼續等待,直到全部都完成為止。
由於這是 wait / notify 的設計,而非 pooling 的機制,因此反應時間幾乎是瞬間完成的。精確度取決於 OS 多快把 thread 喚醒,而不是取決於你 retry / pooling 的時間間隔設的多短。都處理完成之後才會繼續 close channel / connection。之前我踩過大地雷,太早 close connection, 導致 shutdown 之後的 message 都無法 ack …
這整段的程序,雖然不大好懂,但是他能讓你確保 message 都能精準地完成之後在關閉程式。除了你可以降低事情做一半要去收尾的麻煩事之外,後面可以進一步看到如何跟 container / cloud provider 的 auto scaling 機制完美搭配的用法。這是所有的 worker 類型應用程式很關鍵的一環,但是這麼複雜的事情也不是和每個團隊都要自己處理,因此抽象封裝起來讓大家大量使用才是正途。
雙向通訊: RPC
One Way Message 是 Message Queue 的強項, 訊息送出後就不用等待回應,發送端可以不用等待結果就繼續進行後續的任務,這是典型的 Async 模式。這能有效提高效率 (不用等待回應),也能提高可靠度 (Worker 身體健康才能從 Queue 拿走訊息,能確實處理好訊息)。不過有些任務就是必須等待結果才能繼續啊! 回想一下 C# 在語法就直接支援 async / await, 當你發出訊息後可以 “非同步” 的繼續後面的任務,同時你真的需要處理結果時,你還有 await 可以用啊!
在 RabbitMQ 官方文件的說明裡,也提到 RPC mode 的運用: Remote Procedure Call (RPC) - using the .NET client。其實這只是用兩組 Queue, 組合出雙向通訊的機制而已。
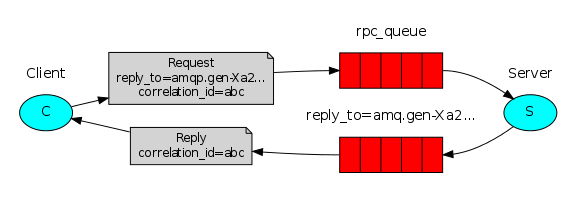
這張圖很直覺的表達這架構: Client 透過正常管道,從 Exchange -> Queue (rpc_queue) 傳送 Message 給 Server;為了識別,Client 會在每個 Message 上標示不重複的關聯 ID (correlation id),同時也會預先標示好回傳結果訊息要透過哪一個 Queue (reply_to)。
Server 接到訊息,處理完畢後,只要按照 Message 上的標示 (就像回郵信封,寄信給你的人把地址郵票都幫你弄好了,你只管把結果裝進信封寄回來) 回傳訊息即可。Client 端會預期在 Reply Queue 會收到處理結果,因此訊息送出之後就會開始監聽 Reply Queue 等待結果。簡單的說 Client / Server 都各自扮演了 Producer / Consumer 的角色。
這部分開始有趣了,按照這篇文章附上的 sample code, 其實做起來也不難,各自都數十行 code 就可以搞定了。不過這真的就是 sample code 啊! 沒啥結構可言,你很難直接拿這段 code 去重複運用在可能會有上百種不同的 message 上。這時這邊的抽象化與效能最佳化變成主要的挑戰了。
有效率的 RPC 封裝: async / await
先許願,我期望這樣的機制能被封裝成什麼樣子? 前面單向的例子我覺得很 OK,對訊息的傳輸處理,能否讓 Message 的泛型參數擴充為 InputMessage 跟 OutputMessage 就好? 原本 SendMessage() 只單向傳送 (底下是宣告) 的設計:
public string SendMessage(
string routing,
TInputMessage intput,
Dictionary<string, string> headers)
{
// 略
}
如果能配合雙向 RPC 的設計,改成這樣就太好了 (期望的設計):
public TOutputMessage SendMessage(
string routing,
TInputMessage intput,
Dictionary<string, string> headers)
{
// 略
}
為了支援雙向的訊息,因此原本 generic type 只需要一個參數的 MessageClass,現在也該擴充了:
public class MessageClient<TInputMessage, TOutputMessage> : MessageClientBase
{
// 略
}
只是,RPC 透過網路,通常回應時間都遠低於正常的本地呼叫,再加上這訊息是透過 message queue 傳遞,延遲的時間可能會更久,如果這邊的封裝機制能搭配 C# async / await 的方式來使用就更好了。再貪心一點,如果設計能追加成這樣就完美了:
public async Task<TOutputMessage> SendMessageAsync(
string routing,
TInputMessage input,
Dictionary<string, string> headers)
{
// 略
}
既然 MessageClient 這端的願望都許完了,那 MessageWorker 是否也需要改變? 當然要,不過同樣的也只要改一點點就好:
public class MessageWorker<TInputMessage, TOutputMessage> : MessageWorkerBase
{
public delegate TOutputMessage MessageWorkerProcess(
TInputMessage message,
string correlationId,
IServiceScope scope = null);
public MessageWorkerProcess Process = null;
}
一樣,既然是雙向的,我希望整體結構都跟單向的一致,只要泛型的型別多宣告一個 return value 的型別 TOutputMessage 就好。同時,為了妥善處理傳回值,給 developer 自己指派的 delegate 型別也稍作調整,從原本的:
public delegate string MessageWorkerProcess(
TInputMessage message,
string correlationId,
IServiceScope scope = null);
改成:
public delegate TOutputMessage MessageWorkerProcess(
TInputMessage message,
string correlationId,
IServiceScope scope = null);
如果這些都做完了,那用起來會是什麼樣的感覺? 我貼一段 “樣品屋” 給大家看看,體驗一下封裝後寫 code 的 fu ..。下面這段 sample code 是 client 的部分。我定義了 DemoInputMessage 跟 DemoOutputMessage 分別代表 RPC 的參數跟傳回值。程式中的 for loop, 我只不斷重複地做同一件事:
- 送 “start” 的 message, 並且 等待 結果
- 接著連續送 10 個 message, 一口氣送完 (不等結果) 後,再一次等待 10 個結果回來
- 接著送 “end” 的 message, 並且 等待 結果
這邊如果你熟悉 C# 的 async / await, 那麼這件事就相當容易了,用 await 跟 Task.WaitAll() 就可以搞定。來看 code:
using (var client = new MessageClient<DemoInputMessage, DemoOutputMessage>(new MessageClientOptions()
{
ConnectionName = "demo-client",
BusType = MessageClientOptions.MessageBusTypeEnum.QUEUE,
QueueName = "demo",
ConnectionURL = "amqp://guest:guest@localhost:5672/",
},
null, null))
{
DemoOutputMessage output = null;
for (int index = 1; index <= 100; index++)
{
output = await client.SendMessageAsync("", new DemoInputMessage()
{
MessageBody = $"[C:{pid}]/[{index:000}] start..."
}, null);
Console.WriteLine($"- [{DateTime.Now:HH:mm:ss}] {output.ReturnCode}, {output.ReturnBody}");
Console.WriteLine($"- [{DateTime.Now:HH:mm:ss}] - sending 10 jobs to worker queue at the same time...");
Task.WaitAll(
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 01..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 02..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 03..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 04..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 05..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 06..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 07..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 08..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 09..." }, null),
client.SendMessageAsync("", new DemoInputMessage() { MessageBody = $"[C:{pid}]/[{index:000}] - job 10..." }, null));
Console.WriteLine($"- [{DateTime.Now:HH:mm:ss}] - all jobs (01 ~ 10) execute complete and return.");
output = await client.SendMessageAsync("", new DemoInputMessage()
{
MessageBody = $"[C:{pid}]/[{index:000}] end..."
}, null);
Console.WriteLine($"- [{DateTime.Now:HH:mm:ss}] {output.ReturnCode}, {output.ReturnBody}");
Console.WriteLine();
}
}
MessageClient RPC 實作
好,許完願,算是開完需求規格了,這是否有打到 developer 的需求我就先不驗證了 (應該寫 C# 的人都會喜歡吧),接下來是怎麼達成願望的問題。雖然前面很簡單的說,就是單向的作法,往返都做一次就好;但是實際上還是有不少差別啊! 我把雙向跟兩個單向的差別列一下:
- 每個 rpc call 的傳回值不需要排隊。只要處理完畢最好立刻回傳,不應該被其他的 message 擋住。最好每個 client 能有專屬的 reply queue。
- 如果 client 已經離線, 這個訊息就可以丟掉了,整個 reply queue 的資源也可以放掉。
- client 端等待回傳訊息應該只有一個,不需要多執行緒 (多個 rabbitmq connection / channel), 也不需要處理 graceful shutdown 的問題。
- 如果單一個 client 發出多個 rpc call, 則可以共用一個 reply queue 降低系統負擔
接下來,一樣就看本事了。這裡考驗你幾個基本功夫:
- 平行處理的技巧 (event, threads, wait / notify)
- 對 RabbitMQ 的掌握能力
- C# 的掌握能力 (async / await)
這些個別都很容易精通,但是你必須同時精通這幾件事,才有能力做好整合。 MessageWorker 在這邊的處理很單純,就是按照 Message 上面標記的 ReplyTo / CorrelationId, 把要回傳的 Message 傳回去而已。留意一下 Ack 等等的細節別弄錯就沒事了。這邊我就不特地貼 source code, 一樣有興趣可以直接翻 source code。
要處理 RPC 的封裝,比較難搞的部分都在 MessageClient ,我多花點心思交代。原本想說既然是雙向,那我再 MessageClient 裡面包一個 MessageWorker 專心處理 return message 的部分就可以了。我也真的這樣實作出第一版,還真的能順利的 work。不過就如同上面說的一樣,使用情境落差太大,最主要是 MessageClient 沒有像 MessageWorker 那樣高可靠度的要求,跑起來太肥大了一點。於是我決定重新打造 MessageClient 接收訊息的部分,直接用 RabbitMQ 的 .NET client, 針對這種情境另外寫一套適合的機制 (其實也還好,幾十行 code 而已)。如果沒有看清楚需求跟目的,而過度強調要 reuse code 反而會畫地自限。
我決定的架構是: 替每個 MessageClient Reply 用途準備一個專屬的 Queue,至於 Connection / Channel 則跟 Send 共用。因為在單一個 Client 的情況下,我不大需要處理瞬間有大量 RPC call 同時運作的需求,適度的控制資源比較明智。
因此,看一下調整過的 MessageClient (我先略過 SendMessageAsync() 的部分):
public class MessageClient<TInputMessage, TOutputMessage> : MessageClientBase
where TInputMessage : MessageBase
where TOutputMessage : MessageBase
{
public MessageClient(
MessageClientOptions options,
TrackContext track,
ILogger logger) : base(options, track, logger)
{
this.ReplyQueueName = this.channel.QueueDeclare().QueueName;
this.ReplyQueueConsumer = new EventingBasicConsumer(channel);
this.ReplyQueueConsumer.Received += this.ReplyQueue_Received;
this.channel.BasicConsume(this.ReplyQueueName, false, this.ReplyQueueConsumer);
}
public override void Dispose()
{
this.ReplyQueueConsumer.Received -= this.ReplyQueue_Received;
this.channel.QueueDelete(ReplyQueueName);
base.Dispose();
}
private string ReplyQueueName = null;
private EventingBasicConsumer ReplyQueueConsumer = null;
protected override void SetupMessageProperties(IBasicProperties props)
{
base.SetupMessageProperties(props);
props.ReplyTo = this.ReplyQueueName;
}
private void ReplyQueue_Received(object sender, BasicDeliverEventArgs e)
{
var body = e.Body;
var props = e.BasicProperties;
TOutputMessage output = JsonConvert.DeserializeObject<TOutputMessage>(
Encoding.UTF8.GetString(body));
lock (this._sync)
{
this.buffer[props.CorrelationId] = output;
this.waitlist[props.CorrelationId].Set();
}
channel.BasicAck(
deliveryTag: e.DeliveryTag,
multiple: false);
}
private object _sync = new object();
private Dictionary<string, TOutputMessage> buffer =
new Dictionary<string, TOutputMessage>();
private Dictionary<string, AutoResetEvent> waitlist =
new Dictionary<string, AutoResetEvent>();
// 以下略
}
這段處理了 MessageClient Init (constructor) 跟 Dispose 的部分。因為 MessageClient 跟 ReplyQueue 是一對一的關係,因此我直接在 constructor 階段就先準備好 ReplyQueue 的準備動作了,也把 receive message 的 event handler 準備好。要處理 async / await 的機制,關鍵在於執行緒的同步。這邊我採用 AutoResetEvent 這個物件來協調。
不熟悉 AutoResetEvent 該怎麼用的朋友們,可以參考我以前的文章: ThreadPool 實作 #3. AutoResetEvent / ManualResetEvent。這邊簡單的說, AutoResetEvent 物件就像捷運的進出閘門一樣,平常是關閉的,如果有人想要通過就必須排隊。閘門何時會打開? 直到有人刷卡為止。不同的是通常我們會自己刷卡,在這邊刷卡跟通關的人是分開的。既然有 AutoResetEvent, 那就會有對應的 ManualResetEvent 。兩者最大的差異,在於 AutoResetEvent 會 “Auto” Reset … 意思是刷卡 (Set) 之後,閘門會打開放一個人過去,不管後面還有多少人在排隊,第一個人通過之後就會自動關起來 (Auto Reset),除非有人再刷一次卡 (Set)。而 ManualResetEvent 就反過來,刷卡 (Set) 之後閘門會維持開啟的狀態,除非有人把他關起來 (Reset)。
這邊我埋了個暗樁,在 ReplyQueue_Received 被觸發時,會用 correlationId 當作 key, 找到對應的 AutoResetEvent: this.waitlist[props.CorrelationId], 呼叫 .Set() 通知當初送出對應的 DemoInputMessage 的 SendMessageAsync(),對應的 DemoOutputMessage 已經收到了。SendMessageAsync() 可以藉由 Wait AutoResetEvent, 直到被通知醒來之後,就可以到 this.buffer[props.CorrelationId] 取得 DemoOutputMessage 物件。
這樣看有點抽象,對照著看一下 SendMessageAsync() 的部分 code (上面的程式碼我略過這段,分兩段看會比較清楚):
public class MessageClient<TInputMessage, TOutputMessage> : MessageClientBase
{
// 以上略,請參考上一段
public TOutputMessage SendMessage(
string routing,
TInputMessage input,
Dictionary<string, string> headers)
{
return this.SendMessageAsync(routing, input, headers).Result;
}
public async Task<TOutputMessage> SendMessageAsync(
string routing,
TInputMessage input,
Dictionary<string, string> headers)
{
string correlationId = this.PublishMessage(
routing,
Encoding.UTF8.GetBytes(JsonConvert.SerializeObject(input)),
headers);
AutoResetEvent wait = new AutoResetEvent(false);
lock (this._sync)
{
this.waitlist[correlationId] = wait;
}
//
// 關鍵: 等待接收 return message; 收到後會喚醒這行
//
await Task.Run(() => wait.WaitOne());
lock (this._sync)
{
var output = this.buffer[correlationId];
this.buffer.Remove(correlationId);
this.waitlist.Remove(correlationId);
return output;
}
}
}
整個 SendMessageAsync 就靠 wait.WaitOne() 這行,切割為上上兩個部分。前段就是準備送出 message, 而這行就是關鍵的等待 (會被 ReplyQueue_Received 喚醒)。喚醒之後就可以去 buffer 取回對應的 DemoOutputMessage 傳回。
至於 C# 的 async / await 如何封裝? 我只要把 AutoResetEvent.WaitOne() 包裝成 Task, 讓我可以用 await 去等待他的傳回結果;C# 編譯器就會幫我搞定這整段機制了:
await Task.Run(() => wait.WaitOne());
這整段非同步的處理需要花點腦筋,我在 .NET Conf 2018 那場演講中,就都是在交代中間的細節。需要更詳細的說明,可以看當天的錄影。我擷取當天的 PPT ,其中有畫了 UML sequency diagram, 搭配著看會更容易了解其中的奧秘:
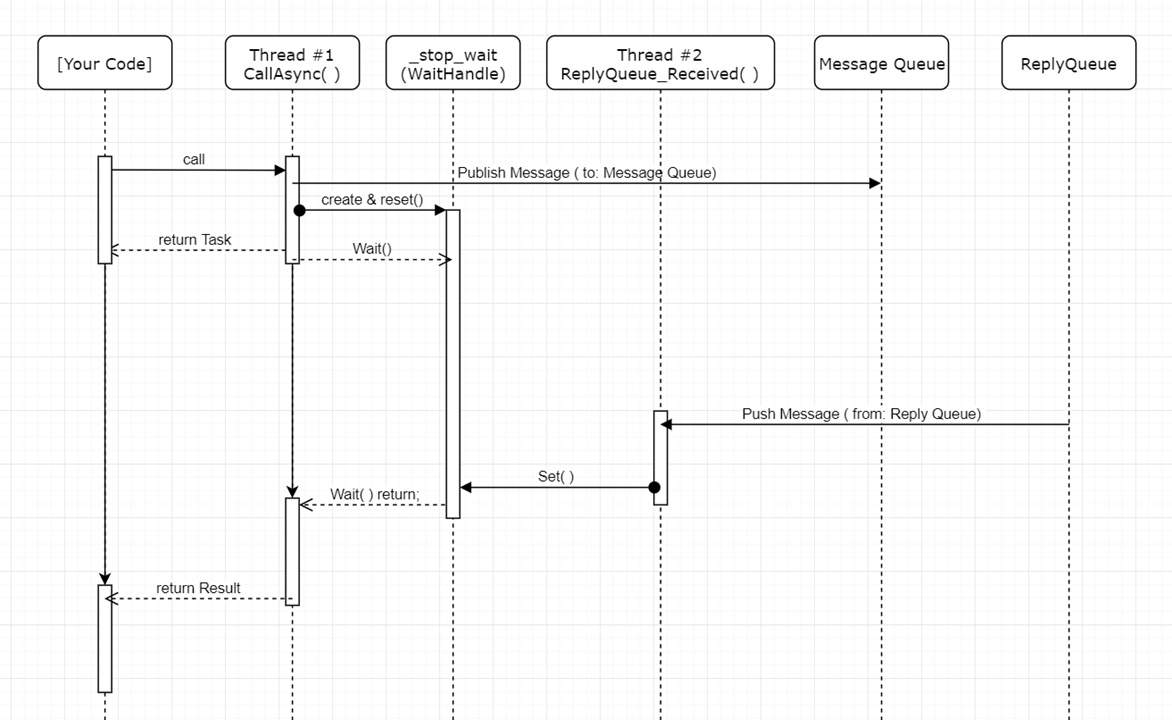
跨服務的 (Track)Context 轉移
其實到九月底,我開發的進度就搞定這些封裝的細節了。不過我卻遲遲還沒推送給團隊使用。因為還有個大問題沒解決掉;就是跟環境整合的部分。
微服務架構下,很多 user 眼中的一個動作,背後可能是分散在好幾個服務之間協力完成的,這帶來很多彈性跟優勢,也帶來很多問題。最明顯的一點就是很難追查問題。試想這個情境:
每個服務每秒都有數千個 request(s) 被執行。我如果要追查某一筆交易,我如何在多個分散服務之間,各自數十萬筆 logs ,挑出屬於我這筆交易的 log?
這狀況不只出現在 message queue (async) 會碰到,就算你用 HTTP RESTful API 一樣也會碰到。最常見的方式就是在系統邊界 (通常是外面打進來的 endpoints, 如 reverse proxy or API gateway) 先在 http header 藏一筆 request-id, 之後靠這個 request-id 來追蹤。
用這個方法的前提是,你必須把這個 request-id 傳到下一關,如果你必須仰賴其他服務的功能的話…。不論你用 HTTP 或是 Message Queue 都一樣。這個 ID 順利傳遞下去的話,你就能追蹤這個 Request 跨服務的處理細節了。既然傳輸的管道已經被抽象化了,那麼最好這樣的追蹤資訊也能一起被抽象化處理,才不會有人在哪一官漏掉這個動作,導致這些訊息之後就斷了。
我的作法是: 把這些資訊,封裝成 TrackContext, 如這個例子你可以只放 RequestId, 或是有其他更多的資訊 (如果你需要) 也可以。只是這會增加每次呼叫的通訊成本,請斟酌使用,切勿想到什麼通通都一股腦塞進去。這類機制的處理,通常都是配對的;例如以這個例子來說, MessageClient 會打包放進去, MessageWorker 就會拆包裹拿出來;如果 Http 通訊,我們可能就會在 HttpClientHandler 裡打包,在 ASP.NET WebAPI 的 ActionFilter, 或是 ASP.NET Core 的 Middleware 裡面拆開。
這邊為何多花了段時間處理? 主要是花在跟 Dependency Injection Framework 的機制整合。剛才說明的只有 TrackContext 怎麼傳遞的機制來討論而已。但是這類資訊通常都是全域的,無所不在。你也很少有機會在 local function call 過程中一路都拿著 TrackContext 到處傳遞 (這樣看起來很煩)。典型的作法是,在適當的 Scope 內注入 (Injection) 這個資訊,需要的人只要透過 IoC 解析 (Resolve) 這個資訊出來,剩下的問題 IoC container 會幫你搞定。
因此,我這邊的設計機制就為了配合 DI framework 做了點調整:
MessageClient constructor:
public MessageClient(
MessageClientOptions options,
TrackContext track,
ILogger logger) : base(options, track, logger)
{
// 略
}
如果你是透過 DI 取得 MessageClient, 那麼在解析的過程中,DI 自然會幫你取得正確的 TrackContext … (這物件通常都會被注入 Scoped 的領域內)。拿到 TrackContext 之後,剩下的就是在每次 SendMessage() 時把資訊放在 Message Headers 就好了。也因為這個原因,請避免把 MessageClient 用 Signletion 的領域注入,這樣會讓這個機制錯亂。如果你不打算搭配任何的 DI framework 也無訪,建立 MessageClient 時請自己準備好這些物件即可。
接著,這個問題複雜的部份又回到 MessageWorker 了。MessageWorker 會不斷接到不同的 message, 他們可能來自完全不同的 service or instance, 因此你必須替每個 MessageWorkerProcess 執行前後,準備一個獨立的 Scope, 並且在 Process 執行之前,先在這個 Scope 內注入正確的 TrackContext 資訊。聽起來有點抽象,沒辦法,Dependency Injection 本來就有點抽象… 簡單的說,這配對的機制,能創造一個環境,把 MessageClient 內的 TrackContext 複製到 MessageWorker 這端,讓同一個 Message, 在 MessageClient / MessageWorker 兩端都能拿到同樣的 TrackContext 。這個轉移機制如果能夠透明化,就能大大降低處理錯誤的狀況。
這邊我搭配 .NET Core 內建的 DI (namespace: Microsoft.Extensions.DependencyInjection), 來處理這問題。來看 MessageWorker 的片段 code:
protected override void Subscriber_Received(object sender, BasicDeliverEventArgs e, IModel channel)
{
// 略
TInputMessage request = JsonConvert.DeserializeObject<TInputMessage>(Encoding.UTF8.GetString(body));
using (var scope = this._services.CreateScope())
{
TrackContext.InitScope(scope, this.GetHeaders(props));
this.Process(request, props.CorrelationId, scope);
}
channel.BasicAck(
deliveryTag: e.DeliveryTag,
multiple: false);
// 略
}
這段是 MessageWorker 在每個 channel 收到 message 的對應 event handler, 我拿掉大部分不相關的 code, 只保留關鍵的部分;整個的流程:
- 反序列化,從 message body 還原成
TInputMessage物件 - 先取得
IServiceProvider, 建立專用的 Scope 物件 - 從 message headers 還原
TrackContext, 注入 Scope - 讓處理訊息的 delegate:
Process在這個 Scope 內運行。 - 完成之後,回報 Ack, 告知 RabbitMQ 訊息處理完畢。 (若雙向的話還需要回傳 message)
Auto Scaling
終於來到最後一關了。你 code 寫的再漂亮,總是要部署上線的吧,醜媳婦總是要見公婆的。現在很多人都在倡導 DevOps, 但是往往都擺錯重點,以為 DevOps 就是部署自動化而已。其實自動化的確是 DevOps 很重要的一環沒錯,但是別忘了他的精神啊! 這篇文章設計概念最後一段,就來談談 DevOps 其中一個重要觀念: Design for operation.
DevOps Concepts
DevOps 強調的是 Dev / Ops 的流程是緊緊扣在一起的,DevOps 團隊應該從 Ops 的過程中取得 feedback, 直接在 Dev 改善,然後再從 Ops 取得 feedback, 不斷循環持續改善,這才是 DevOps 的核心概念。
我為何要講這段? 因為我看過太多 Dev 只顧著功能需求,而忘掉 Ops 需求的開發團隊了。這樣的團隊其實還不夠格自稱 DevOps … 理想的 DevOps 團隊,開發出來的系統不只要滿足 user 的需求,也該要滿足 Ops 的需求啊,所謂要開發出能被維運的系統,就是這個意思。另一種說法 “Design for Operaion” 講的也是同一件事,你在開發階段,設計階段就已經考慮好這系統將來該如何被維運,將來上線才有可能讓 Developer 來參與 Operation。
MessageWorker 必須確實做好 Graceful Shutdown, 背後最主要的原因就是要密切配合 DevOps… 從維運的觀點來看, “auto scaling” 是一個很重要的功能, 他能讓 operation 人員只要設定明確的規則,就能自動 (或是手動敲一個數字) 把服務 scaling 到理想的規模。Scaling 的過程中,可能會 “啟動” 新的 Worker, 或是 “關掉” 多餘的 Worker 來達成目的。在 Message Queue 的架構下,新增 Worker 非常容易,連線到同一個 Message Queue 就結束了,而能否自動 “關掉” 多餘的 Worker, 這時 Graceful Shutdown 就是個關鍵。
你可以用這幾個問題自我檢視你們的服務的成熟度? 如果你的團隊,或是你管理的系統,在 Scaling (調整機器數量) 時是否需要:
- 必須依賴 Dev Team 來進行 (例如 VM 開起來或是準備關閉時,還得到 application 做 setting or update configuration)
- 調整過程中你接觸的介面,是 cloud provider (如 Azure Portal, AWS Console … ) 提供的原生工具,還是自行開發的 management portal ?
- 過程是全自動還是手動? 是否需要人力同時對 infrastructure / application 進行變更?
- 能否在一定的時間內完成? (例如 1 min)
我常常跟 developer 講這個 scenario, 如果你的 application 能夠顧好自己啟動 (例如註冊服務, 通知 load balancer 加入服務清單等等) / 關閉 (正確的終止未完成的任務, 移除服務註冊等等) 時的行為,同時 configuration 能夠集中管理,那麼大部分 scaling 的事情就完全不用靠 developer 來處理了。當開發團隊沒看清楚這一點時,上頭壓下來說要導入 DevOps 要推行各種自動化時,這類 scaling 的自動化就會搞死一大堆開發團隊,因為你要搞定的都是 application 本身的組態問題,不是只有 infrastructure, 除了自己開發你一定找不到現成的工具, 半夜出問題了你也只能自己起床處理…。
完整支援 infrastructure 對於 auto scaling 的各個環節,這是我會在設計階段就強調 graceful shutdown 的重要原因。唯有把這些環節掌握好,才能簡化維運的工作。所謂的 “design for operation”, 就是要顧及這些層次的需求。
Design For Operation
不過反觀開發階段,有多少 Developer 會留意這些細節? 沒注意這些,將來上線就會花費一些人力在維運上面。根本的解決之道就是一開始就把這件事情處理好。我的核心概念是: 讓 Ops 能用最單純的 cloud provider / container orchestration 管理機制,單純的決定你要幾個 worker(s), 其他都應該 “被” 自動處理妥當。
我知道中間有不少障礙需要克服 (尤其是你過去從來都沒思考過這問題)。因此我才會特地花一段篇幅來說明這件事。前面有提到, MessageWorker 必須要在收到關機指令時,能正常的停掉手上處理一半的工作,才能讓自己被關掉。上面的案例是按下 ENTER 後進入關機程序,現在要想辦法跟 infra 的 auto scaling 機制整合,這段做好上線後才能真正做到 “Auto” scaling…
其實,為了這個問題,我過去也吃過不少苦頭,Microsoft 會在雲端時代,Server Side OS 居於弱勢其實是有原因的,這部分的處理遠比 Linux 麻煩的多。有看過我之前幾篇抱怨踩雷文的朋友應該有印象。可以參考這幾篇:
Windows app 用 container 部署的相關主題:
- Azure Labs: Windows Container Swarm Mode
- Azure Labs: Mixed-OS Docker Swarm
- LCOW Labs: Linux Container On Windows
Windows Container 踩雷紀錄:
這段最後碎碎念一下, 趁機偷渡一下我對 “Design for Operation” 的看法:
其實要做到 design for operation, developer 該做的遠遠不只 graceful shutdown 而已。這邊舉的 auto scaling 是 operation 期望的結果,要做好這件事, 就要想辦法讓 infra / developer 兩個團隊要協調好如何 增加 / 減少 service instance 的程序。前面花很多篇幅說明的 graceful shutdown, 其實只是讓 developer 想辦法配合 infrastructure 做好關閉的動作而已。那麼啟動呢?
你千萬別很直覺的想:
那就把現在 setup 的程序寫 script 自動化就好了啊…
如果你原本的 setup 程序沒有貼近 infra team 的做法 (通常 infra team 的做法比較能應付各種狀況,比較有參考價值),那你貿然寫 script 只是把複雜的事情自動化而已。我從結果往回推,developer 可以思考這幾點:
- configuration 是否已經集中管理? config 異動是否需要重新 deploy application? (不需要是最理想的)
- multiple deployment 時是否需要準備多份 artifacts ? (不需要是最理想的) 能否只透過同一個 artifact repository 取得?
- code build process (CI/CD pipeline) 是否正確的整合到 artifacts managment?
上面這些,我認為是 developer 面對自動化部署的正確觀念。developer 該做的不是自己硬幹 automation script, 而是盡可能的配合 infra team 運用成熟的管理工具才是正途。檢視自身的 application 還不夠標準化導致無法接上 infra 的流程,改善這個環節才是一勞永逸的捷徑。
回頭來看看我們的 code, 封裝後的 MessageWorker 到底算不算是 “design for operation” ? 我驗證的方式,就是真的把他丟到 VM / container, 然後看看從 infra 的角度來做 scaling, 我們的機制是否能正常運作? 不論你用 VM 或是 container, 由於 OS 這層都已經被虛擬化了,因此 infra 跟 application 通知關閉的管道,都一律從 OS shutdown signal 來進行。你的程式只要偵測 OS 是不是要關機了? 如果是,在關機前做好事當的處理,在回報 OS 處理完畢即可。
Labs: Handling OS Shutdown
不過事情沒有這麼順利啊… 尤其是我用的環境是 .NET Framework + Windows … 在我寫這篇文章 Tips: 在 .NET Console Application 中處理 Shutdown 事件 時,為了在 .NET Framework 的 Console Application 內偵測 windows OS shutdown 的事件,吃了不少苦頭。當時我必須搞到建立一個看不到的視窗,藉由視窗監聽 Win Message 事件,才能攔截到 OS shutdown event… WTF? 都已經快要 2020 年代了,我還得依靠 1990 年代的 API …
不過,接下來的這幾個月,這件事有幾個轉機了…
- windows kernel 更新: 1809, 改善了需要 create windows 才能攔到 shutdown event 的毛病
- .NET Core 開始支援 Generic Host (IHost, IHostedService 介面)
看到我自己土炮的機制有官方的支援,當然沒有繼續自己搞下去的道理啊,於是我改了一版,符合 IHostedService 規範的 MessageWorker (對,就是這篇看到的版本)。實驗的過程我就略過了 (再寫就寫不完了),結果實在令人有點沮喪…
我的 code 是用 .NET Standard 2.0 來開發的 SDK, 我用這版 SDK 寫了兩個版本的 Console App, 分別是 .NET Framework (4.6.1) 版本,以及 .NET Core 版本。.NET Core 又有兩種 runtime 可以用 (我沒 Mac, 只能測 windows 跟 linux)。我測試的環境是 container, 結果 Microsoft 又提供了 LCOW (Linux Container On Windows), 還有 Linux 原生的 docker engine …
這麼多種組合,我每種都測了一次。我測試的方法很簡單,Code 偵測到 shutdown event 就印出 message, 我封裝成 container, 試看看 docker run 之後,透過 docker stop 關掉這個 container, 我在裡面執行的 console app 能否真測的到這個事件?
結果挺慘烈的 XDD, 請看下表:
| HOST | ENV \ CODE | .NET Framework | .NET Core (windows runtime) | .NET Core (linux runtime) |
|---|---|---|---|---|
| WIN10-1809 | Windows Container | FAIL | FAIL | – |
| WIN10-1809 | LCOW | – | – | SUCCESS (註一) |
| MobyLinux | Docker Engine | – | – | SUCCESS |
註一: 測試結果能成功偵測到 shutdown event, 但是最終 container 無法正常結束,docker engine 也無法砍掉這個 container, 最終 restart docker engine 解決。這看來是特定版本 windows container 的問題, 願意等的話應該會修正。
看來結果有點慘烈啊,搞半天跟 Microsoft OS 沾到一點邊的就不大正常 T_T … 唯一正常的是 linux host + linux container … 不過,按照過去的經驗,這一定是暫時的,下一版一定會修正的 XDD,我繼續等..
回到我們的 MessageWorker 來。我自己公司團隊的狀況,短時間還無法脫離 .NET Framework, 不過如果還想繼續寫 C#,那麼轉移到 .NET Core 是無庸置疑的,因此方向上我仍然會朝 IHostedServices 的方向走,只是我還是必須有 for Windows Server 的解決方式。從現在開始,這類為團隊打造的 SDK 一律以 .NET Standard 2.0 為最低要求。
我重新把過去直接叫用 win32 api 的那作法搬出來,把他封裝成 IHost 的 extension, 試圖在不改變整體結構的前提下,先自己做一組 for windows 的 workround, 盡可能地讓將來 .NET core 真正解決這問題後 (.NET Core 3.0?) 能夠無痛的轉移。於是,原本的 MessageWorker 是這樣啟動的:
var host = new HostBuilder()
.ConfigureServices((context, services) =>
{
// 略, 注入 MessageWorker 為 IHostedServices
})
.Build();
using (host)
{
host.Start();
host.WaitForShutdown();
}
我自己補了一段 WindowsHostExtensions.cs, 在原本的 IHost 補上這組 method:
public static class WindowsHostExtensions
{
public static void WinStart(this IHost host)
{
SetConsoleCtrlHandler(ShutdownHandler, true);
host.StartAsync().GetAwaiter().GetResult();
}
public static void WaitForWinShutdown(this IHost host)
{
host.WaitForWinShutdownAsync().GetAwaiter().GetResult();
}
public static async Task WaitForWinShutdownAsync(this IHost host, CancellationToken token = default)
{
int index = Task.WaitAny(
host.WaitForShutdownAsync(),
Task.Run(() => { close.WaitOne(); }));
switch (index)
{
case 0:
// IHostedServices
break;
case 1:
// Kernel32: SetConsoleCtrlHandler
await host.StopAsync();
close_ack.Set();
SetConsoleCtrlHandler(ShutdownHandler, false);
break;
}
}
private static ManualResetEvent close = new ManualResetEvent(false);
private static ManualResetEvent close_ack = new ManualResetEvent(false);
[DllImport("Kernel32")]
static extern bool SetConsoleCtrlHandler(EventHandler handler, bool add);
delegate bool EventHandler(CtrlType sig);
// reference: https://docs.microsoft.com/en-us/windows/console/handlerroutine
enum CtrlType
{
CTRL_C_EVENT = 0,
CTRL_BREAK_EVENT = 1,
CTRL_CLOSE_EVENT = 2,
CTRL_LOGOFF_EVENT = 5,
CTRL_SHUTDOWN_EVENT = 6
}
private static bool ShutdownHandler(CtrlType sig)
{
Console.WriteLine($"EVENT: ShutdownHandler({sig}) - RECEIVED");
close.Set();
close_ack.WaitOne();
Console.WriteLine($"EVENT: ShutdownHandler({sig}) - DONE");
return true;
}
}
Labs: MessageWorker Auto Scaling
加上這個 Extension 後,原本的程式稍微改個 method 名字就可以動了 (Start 改成 WinStart, WaitForShutdown 改成 WaitForWinShutdown)。其實原本的這兩個 method 也是 extension, 我不想搶他的 method name, 只好妥協一下了。Microsoft 也把原本的 source code 開源出來了,有興趣的可以直接到 GitHub 看: Microsoft.Extensions.Hosting.Abstractions.HostingAbstractionsHostExtensions
以下是套上我自己寫的 extension 後的 code:
var host = new HostBuilder()
.ConfigureServices((context, services) =>
{
// 略, 注入 MessageWorker 為 IHostedServices
})
.Build();
using (host)
{
host.WinStart();
host.WaitForWinShutdown();
}
如果你只鎖定在 windows container + 1809 / ltsc2019 + .net framework 的環境下,那這個 extension 應該能解決你的問題。最後附上我的實驗環境 dockerfile / docker-compose , 體會一下 design for operation 能做到位的話,對於 operation 團隊的成員有多大的幫助
我把 DemoRPC_Client / DemoRPC_Server 都寫了對應的 dockerfile:
Dockerfile for DemoRPC_Client:
FROM mcr.microsoft.com/windows/servercore:ltsc2019
WORKDIR c:/demorpc_client
COPY . .
ENV MQURL=amqp://guest:guest@rabbitmq:5672/
CMD demorpc_client.exe %MQURL%
Dockerfile for DemoRPC_Server:
FROM mcr.microsoft.com/windows/servercore:ltsc2019
WORKDIR c:/demorpc_server
COPY . .
ENV MQURL=amqp://guest:guest@rabbitmq:5672/
CMD demorpc_server.exe %MQURL%
Docker-Compose (我找了個 for windows 的 rabbitmq image, 避免部署時還要透過 LCOW 轉一手):
version: '2.1'
services:
rabbitmq:
image: micdenny/rabbitmq-windows
producer:
image: demorpc_client
environment:
- MQURL="amqp://guest:guest@rabbitmq:5672/"
depends_on:
- rabbitmq
consumer:
image: demorpc_server
environment:
- MQURL="amqp://guest:guest@rabbitmq:5672/"
depends_on:
- rabbitmq
networks:
default:
external:
name: nat
展示一下錄影的過程, 整個過程都在 Azure 上面運行, 我用的 VM image 是 “Windows Server 2019 Data Container with Containers” :
00:00 ~ 01:00 啟動 rabbitmq service, 等待啟動完成
docker-compose up -d rabbitmq
01:00 ~ 01:20 啟動 consumer (1 instance) / producere (5 instances)
docker-compose up -d --scale consumer=1 --scale producer=5
01:20 ~ 01:35 用 logs 指令觀察 consumer 的 console output, 可以看到 consumer 不斷地接收到 message 處理
docker-compose logs -t -f consumer
01:35 ~ 02:00 scale out, 將 consumer 的執行數量從 1 -> 2, 單純從 infra 角度就能讓新的 worker 加入工作叢集
docker-compose up -d --scale consumer=2 --scale producer=5
02:00 ~ 02:10 將 consumer 的執行數量從 2 -> 1, 可以從 message 看到其中一個 worker 接到關機指令,正常終止 (持續數秒)
docker-compose up -d --scale consumer=2 --scale producer=5
02:10 ~ 02:31 將 consumer 的執行數量從 1 -> 0, 再關閉一個 worker, 訊息中依樣看到正常終止的程序
docker-compose up -d --scale consumer=2 --scale producer=5
過程中可以看到,我只單純的對 docker-compose 下 --scale consumer=xxx 的指令,調整 service instance 的數量。從 console output 可以觀察到 MessageWorker 接到通知之後,不再有新的 message start, 只看到 end 的訊息;同時當處理中的訊息都完成後就跳出終止的訊息,MessageWorker 就離線了。這證明了我們可以透過 docker-compose, k8s 或是 docker swarm 這類管理工具直接來管理 MessageWorker, 而不需要再自己開發一堆 tools or script 做一樣的事情 (除非你有信心你自己開發的工具會比 K8S 好,而且你們的 operation 團隊不用學就會操作)。
因為觸發 application 準備關閉的通知管道,都是 OS 的 shutdown signal, 因此這個機制的通用性很高,不論你是用下列哪種方式 hosting 你的 application 都可以支援:
- 安裝在 physical server 上
- 安裝在 virtual machine 上
- 透過 container 部署到單機 (docker, docker-compose)
- 透過 container 部署到 orchestration 上 (kubernetes, docker swarm, azure / aws container services… etc)
我實際上也成功的在 Azure 上架設 docker swarm, 執行同樣的測試也成功了, 不過礙於篇幅我這邊就點到為止,用單機的 docker-compose 進行示範,讓大家體會一下用這種方式來配合 infrastructure 進行 automation 的威力。
後記
(為什麼現在的題目越寫越長了啊啊啊啊… 這篇文章的長度又破記錄了… Orz)
要導入微服務,對團隊而言真的是個高裝檢啊… 從流程,團隊成員的技能,規劃,架構等等,每一個環節都是要配合的。通訊的部分,是直接面對跨越多個服務的環節,會面臨最多的整合環節,也因此我在這邊花費最多的功夫。我就在總結這邊,再重複一次我這篇文章想告訴大家的觀念:
為團隊整合基礎服務
微服務最不缺的就是各式各樣的基礎建設與框架了 (雖然 .NET + Windows 的選擇仍然是少數 T_T),不過我還是強調,整合的重要性比選擇框架跟服務還重要啊!
其實只要是分散式系統,或是 cloud native 的架構,你都會面臨大大小小的其他服務 (自建的 OSS, 或是 cloud provider 提供的 PaaS)。這些服務都會有對應的 SDK,不過要讓每個 developer 都去熟悉所有的 SDK 如何運作與搭配,這對團隊而言是個很大的負擔。因此我這篇背後的設計概念就是: 團隊應該先派出一個先遣部隊 (人不用多,一兩個就夠),先去嘗試這些基礎服務,替團隊找出最佳的運用與組合方式,再替大家先整合 (封裝) 好,替團隊打造專屬的 SDK。這麼做的目的,不是用自建的 SDK “取代” 原生的 SDK (例如本文的 MessageWorker vs RabbitMQ .NET Client),而是簡化取用 RabbitMQ SDK 的一連串準備動作的過程 (如透過 configuration 取得 RabbitMQ ConnectionURL, 檢查權限與配置等等程序)。
也因為這個概念 (我們團隊是以 .NET / C# 為主要的 programming language), 我捨棄讓團隊直接面對 RabbitMQ SDK (實際應用還需要搭配 Consul, AWS, …. 等等 SDK),改為由先遣部隊提供整合好的套件。抽象化必須做到恰到好處才行,太過可能會隱藏必要的細節,太少則失去了整合的目的,會讓開發出來的服務與這些基礎建設過度耦合。
這概念,其實在這篇 一窩蜂驅動開發 也有提到;面對新技術正確的作法,是找對的人,作先行的研究,快速的測試 (Spikes), 就算失敗了, 你也是很快就知道結果。文內提到:
好的團隊,有扎實技術背景的人,有越好的工程素養的人,越能正確的評斷技術的好壞與否,也能正確地找出團隊使用的最佳做法。
這篇文章就是我對 Message Queue 做這樣的嘗試。
設計出能被維運的服務
另一個觀念,就是你要讓你設計出來的服務是可以被維運的啊 (design for operation)。維運是服務開發團隊的另一個痛,痛在於開發團隊通常都沒有充足的維運經驗;不懂得如何有效率大規模的維運,你就不會知道該怎麼設計出易於維運的系統。開發團隊善於創造,因此這情況下很多團隊就容易在不知情的狀況下走偏了,自行開發一堆服務來維運自己的服務…
我常常舉一個範例: 如果我要架設 wordpress (或是其他知名的 OSS), 我應該是 docker-compose 寫好, 各個服務的 image pull 回來後就搞定了。這些 service instance 要 scale out, 要調整 instance count, 應該只要從 docker-compose 調整 scale 就夠了…
反思自己開發的系統,如果無法這麼簡單地透過 infra 的手段完成 scale 調整,那代表背後還有些環節可以優化;這篇文章強調的 Graceful Shutdown 就是一例,這件事做好之後,scale 就能搭上 infra 手段的順風車, 這就是個對維運友善的設計。我看過太多開發者,因為不懂這些過程,往往自己寫了些很特殊或是專屬的工具來解決,不過換位思考,如果 Google 的每個服務都這樣搞,Google SRE 哪有辦法維運全球那麼多套服務啊!! 這些問題如果在開發階段就去考慮妥當,剩下的就交給專業的 SRE 就好。
該如何做到這點? 讓每個團隊試著去維運自己開發的服務,你就會知道 design for operation 的重要性了。好的團隊,採到這地雷之後,自然會去找方法來對應;團隊裡要是有優秀的 tech leader, 或是有 architect 的角色, 就能夠避免團隊走冤枉路。
觀念一轉之後,你會發現要做的事情完全不同了;你也會發現你的服務也能更容易地搭上主流技術了 (如 K8S, Azure, AWS 等等 cloud paas)。走向這條路,才有機會踩在巨人的肩膀上。
最後,希望我的經驗、想法、實作的案例能對大家有幫助;也感謝大家花時間看完這落落長的一大篇文章 :)