![]()
好久沒寫微服務系列的文章了,這篇算是 Message Queue 的進階版本,如果你有越來越多的任務需要 Message Queue 後端的 Worker 來處理,後端 Worker 的架構其實是個很有意思的架構思考練習題。會想解決這個議題: Task Management, 需求有點類似 serverless, 我希望有個 pool 能很快的消化掉我丟進去的 task …。其實我需要的架構就類似 message queue + serverless 就能符合了,但是有些因素, 我得認真評估自行建置最關鍵的那一塊該怎麼做。不過這篇我沒打算把主題擴的那麼大,我就專注在 Process Pool 上面了。
本來打算先講我打算如何解決問題,再來講實作的,不過架構題的決策,往往就是需求、架構跟實作的平衡啊,不先交代一下基本的實作技術,有點講不下去 XDD,我決定先花點篇幅說明程式碼隔離機制 (Isolation) 的架構選擇,再來講應用考量,最後說明 Process Pool 的實作。我分三個段落來說明最終 Process Pool 這個構想是怎麼誕生的:
-
挑戰: Isolation 的機制研究:
了解與比較各種執行環境隔離的技術 (InProcess / AppDomain / Process), 以及如何橫跨隔離環境進行有效率的通訊 (IPC) -
為何需要建立隔離環境:
交代我工作場合面臨的需求與挑戰,Container + Orchestration / Serverless 無法滿足的需求 -
挑戰: Process Pool 的設計與開發
在技術與平台的選擇與平衡, 如何設計與開發 Process Pool
在這過程中,其時用了很多我過去文章個別提過的好幾種技巧,算是個終極的綜合應用篇吧! 最遠可以追溯到 10 年前那系列 Thread Pool 設計與實作的相關文章。只是這篇的應用,把 “Thread” Pool 的觀念,擴大到 “Process” Pool 了。現在的技術,Process 層級的隔離期時有更多的工具可以運用了,例如 Container 就是一例;所以過程中我也花了不少時間在拿捏,站在巨人的肩膀上 vs 重新發明輪子 的取捨;對這部分有興趣的讀者們,可以直接跳到第二段。
前言: 微服務架構 系列文章導讀
Microservices, 一個很龐大的主題,我分成四大部分陸續寫下去.. 預計至少會有10篇文章以上吧~ 目前擬定的大綱如下,再前面標示 (計畫) ,就代表這篇的內容還沒生出來… 請大家耐心等待的意思:
- 微服務架構(概念說明)
- 實做基礎技術: API & SDK Design
- API Design #1 資料分頁的處理方式; 2016/10/10
- API Design #2 設計專屬的 SDK; 2016/10/23
- API Design #3 API 的向前相容機制; 2016/10/31
- API Design #4 API 上線前的準備 - Swagger + Azure API Apps; 2016/11/27
- API Design #5 如何強化微服務的安全性? API Token / JWT 的應用; 2016/12/01
- API First Workshop: 設計概念與實做案例
- API First #1 架構師觀點 - API First 的開發策略 - 觀念篇; 2022/10/26
- API First #2 架構師觀點 - API First 的開發策略 - 設計實做篇; 2023/01/01
- (計畫) API First # 微服務架構 - API 的安全機制;
- 架構師觀點 - 轉移到微服務架構的經驗分享
- 基礎建設 - 建立微服務的執行環境
- 案例實作 - IP 查詢服務的開發與設計
- 容器化的微服務開發 #1 架構與開發範例; 2017/05/28
- 容器化的微服務開發 #2 IIS or Self Host ? 2018/05/12
- 建構微服務開發團隊
- 分散式系統的基礎知識
- 分散式系統 #1 如何保證 API 呼叫成功? 談 Idempotency Key 的原理與實作
挑戰: Isolation 的機制研究
進入應用之前,要先對一些基礎的隔離方式做些了解,就先來牛刀小試一下好了。有點手感 & 先了解每種技術的表現在哪個數量級,你才會知道後面要如何取捨以及設計。我有跨平台的需求 (需要跨越 windows / linux 這些作業系統, 同時開發技術也需要跨越 .net frameowkr / .net core / node js), 而且主力是 C#, 因此我還是以目前最大宗的 C# / .net framework 為起點好了,後面的選擇也至少要能兼顧這需求為前提。
根據隔離的層級不同,我大概區分這幾種可行的做法:
-
In-Process (Direct Call):
完全正常的呼叫方式,就只有語言層級的隔離機制而已 (例如: public / private, local variable … etc) 不多做說明。 -
Thread:
執行緒之間除了執行的順序各自獨立之外, 幾乎沒有任何隔離的措施了。從系統的角度來說,多個執行緒之間只有 call stack 是閣獨立的, 意思是只有 PC (program counter, 組語裡面指向目前執行位置的指標)、local variable 這類資料是被隔離的;但是除了平行處理之外,這個可當作完全沒有隔離機制的對照組。 -
GenericHost:
從 .net core 2.0 開始被引入的機制。每個 Host 控制背後的 BackgroundService 的生命週期, 每個 Host 也擁有自己獨立的 IoC container (Inversion of Control, 控制反轉)。在 .net core 的世界, Microsoft 大量運用 DI (Dependency Injection) 的技術, 因此 Host 你可以把他想像成有完全獨立的 DI 機制。不同 Host 之間注入的 Singleton 物件是彼此獨立的。
嚴格的來說這不算強制的隔離機制,但是在 DI 的技術越用越廣泛的今日, 這是個有潛力的技術。不過沒有透過 DI 處理的部分,隔離層級就跟 InProcess / Thread 沒兩樣了。不過現階段這技術還沒辦法解決我的需求 T_T, 因此僅止於介紹, 這次不參與評估。 -
AppDomain:
從 .NET Framework 時代就開始支援的技術,直接由 .NET CLR (Common Language Runtime) 提供,相較於 process 來說更為輕量化的隔離技術。AppDomain 提供了互相獨立不被干擾的 space, 透過 .NET API 的保證, .NET 的物件是無法跨越 AppDomain 的邊界的。只要是 “managed” 的部分都在管控的範圍內。除非你用了 unsafe 或是 unmanaged code, 否則所有你用 C# 寫的 code 都可以被 AppDomain 所保護。不過這些優點是有代價的,只支援 .NET CLR, 只有 .NET Framework 的程式才被支援,這項技術在 .NET core 的時代也正式被廢掉了。官方的替代技術嘛… 很抱歉沒有了, 官方文件直接說明未來用 Process 跟 Container (這邊指的是 Docker 這種容器化技術, 不是前面提到的 IoC container) 取代,可以做到同樣的需求。因此這篇主要就是要看看 Process 的能耐…。 -
Process:
直接由作業系統 (OS: operation system) 提供的機制。OS 在載入任何程式支前, 都會先在 OS 內建立一個新的處理程序 (process), 有獨立的啟動點,也有完全隔離的 memory space, 隨後才在這個 process 內載入及執行你指定的程式 (executable)。由於這是由 OS 提供的機制,因此只要被該 OS 支援的程式都可以支援,不限定開發技術或是開發語言。雖然使用的方式有點不同,但是基本上 container 也是屬於這個層級。不過這次探討的主要是以開發為主,我就不特別再介紹 container 的做法了。實作上有需要的朋友,你可以把 Docker Container 擺在這層級來考量即可。 -
Hypervisor:
由硬體虛擬化提供的機制。一套支援虛擬化的硬體設備,搭配 hypervisor 的抽象層,可以在這基礎之上模擬成獨立的多個硬體設備,分別在這上面載入 OS ,進一步執行程式。這比起 Process 來說有更安全的隔離層級。不過通常再開發的階段,我都把 Hypervisor 隔離的環境直接當作 VM (virtual machine) 看待了。對於大部分的開發者來說,實體機器跟虛擬機器在開發上沒有太多的不同,這技術一樣我也不特別討論了,我直接歸類在分散式的環境下討論。真的有需要這技術的朋友門,把你的 application 包裝成 container, 在 infrastructure 的選擇下,已經有特定平台,可以替你為每個 container 準備專屬的 hypervisor 虛擬化的環境了。Windows container 內建 Hypervisor Container (只要加上 –isolation hyperv 參數),Linux 也有對應的 (抱歉我記不得名字了) 可以使用。
基本觀念介紹完一輪後,後面的 POC 我就只針對 inprocess / threads , application domain, process 三者來比較就好了,可以透過 infrastructure 解決的架構我暫時略過,因為面對的對象是 developer, 不是 SRE, 因此我專注在 coding 上需要了解對應做法的技術為主。我會特別評比 coding 的做法與限制,測試則是物理效能的 benchmark 為主;請繼續看下去…
Benchmark: 隔離環境的啟動速率
真正開始測試執行速率前,我先準備了一個啥事都不做的 Main(), 來代表整個隔離環境對應到 code 的完整 life cycle. 這個 Main() 只要呼叫了就立馬 return, 用他來測試隔離環境 “空轉” 的效能 (這測試結果也代表該架構的效能天花板):
class Program
{
static void Main(string[] args)
{
}
}
接著,我用 .NET Framework 4.7.2 起了一個 Console App 的 project, 分別用了這五種方式,建立執行環境 (如果需要的話),然後呼叫這個 Main() 一次,離開。如此重複 100 次,計算每秒可以跑幾次。第一次先來看看每個測試的 code。
InProcess Mode
直接呼叫, 沒有任何隔離層級的設計;當作對照組來看待:
Stopwatch timer = new Stopwatch();
int total_domain_cycle_count = 100;
timer.Restart();
for (int i = 0; i < total_domain_cycle_count; i++)
{
HelloWorldTask.Program.Main(null);
}
Console.WriteLine($"Benchmark (InProcess Mode): { total_domain_cycle_count * 1000.0 / timer.ElapsedMilliseconds } run / sec");
跑出來的結果:
Benchmark (InProcess Mode): ∞ run / sec
由於跑的太快,C# 直接給我顯示無限大 XDDD, 其實真的去追究差異倍數意義也不大,我就不去追了。大家只要知道這個版本跑很快就好…
Thread Mode
這次每個 Main() 的呼叫,都用一個執行緒來包裝他。這麼做有些用意,後面再解釋,我先測試再說:
for (int i = 0; i < total_domain_cycle_count; i++)
{
Thread t = new Thread(() =>
{
HelloWorldTask.Program.Main(null);
});
t.Start();
t.Join();
}
這個版本跑出來的結果:
Benchmark (Thread Mode): ∞ run / sec
一樣是無限大,比較就沒什麼意義了,一樣略過。
AppDomain Mode
這版本特別一點,我直接用 .NET Framework 的特殊機制 AppDomain 來實作。先看 code:
for (int i = 0; i < total_domain_cycle_count; i++)
{
var d = AppDomain.CreateDomain("demo");
var r = d.ExecuteAssemblyByName(typeof(HelloWorld).Assembly.FullName);
AppDomain.Unload(d);
}
補充說明一下,你如果寫過 Console App 應該都知道, .NET 編譯器需要你指定進入點 (就是上面講的 Main(...) )。專案範本都會幫你產生一個 Program.cs 就是這用意:
class Program
{
static void Main(string[] args)
{
// ... 略
}
}
這進入點的資訊,其實會記載在 assembly 的 metadata 內,AppDomain 啟動時就會去找這資訊,因此在上述的 code 你沒有看到直接呼叫 HelloWorldTask.Program.Main(null); 的原因就在這邊。如果你有多個 Main() 的話就必須自己動點手腳了。
這版本跑出來的結果:
Benchmark (AppDomain Mode): 333.333333333333 run / sec
Process
這個版本,我直接把 Main() 編譯成獨立的 .exe (Console App), 然後透過 Process 物件來啟動獨立的程序,測試執行 .exe 的速度。這邊的結果頗令我意外,因為我用模一樣的 code, 甚至用一樣的 .NET Standard 編譯出來的 binary code 來寫關鍵部分, 只是最後用兩個不同的專案來編譯而已。結果編譯成 .NET Framework 跟 .NET Core 跑出來的結果有很大的落差。多跑幾次或是重新開機都會有些變化,受環境影響的因素不少。我跑了好幾次挑有代表性的貼結果就好。先來看 code (都一樣的 code, 只有執行檔的路徑不一樣):
for (int i = 0; i < total_domain_cycle_count; i++)
{
var p = Process.Start(new ProcessStartInfo()
{
FileName = @"C:\CodeWork\github.com\Andrew.ProcessPoolDemo\ProcessHostFx\bin\Debug\ProcessHostFx.exe", // .net fx 4.7.2
WindowStyle = ProcessWindowStyle.Hidden,
});
p.WaitForExit();
}
再來看看跑出來的結果:
Benchmark (.NET Fx Process Mode): 11.7647058823529 run / sec
Benchmark (.NET Core Process Mode): 12.6582278481013 run / sec
附註說明一下, .NET Fx 我使用的版本是 4.7.2, .NET Core 則是用 3.1
小結
把結果列在一起看一下吧! 上面測試的主程式是用 .NET Framework 開發的,因為不用 .NET Fx 我就無法使用 AppDomain 了。為了對比同樣的 code (主程式) 用 .NET Fx / Core 的差異,同樣的測試我也另外用 .NET Core 測了一次,測試結果我列在底下的表格:
.NET Fx:
Benchmark (InProcess Mode): ∞ run / sec
Benchmark (Thread Mode): ∞ run / sec
Benchmark (AppDomain Mode): 333.333333333333 run / sec
Benchmark (.NET Fx Process Mode): 11.7647058823529 run / sec
Benchmark (.NET Core Process Mode): 12.6582278481013 run / sec
.NET Core:
Benchmark (InProcess Mode): ∞ run / sec
Benchmark (Thread Mode): ∞ run / sec
Benchmark (AppDomain Mode): (Bypass)
Benchmark (.NET Fx Process Mode): 31.25 run / sec
Benchmark (.NET Core Process Mode): 23.25581395348837 run / sec
| 主程式 \ 隔離方式 | InProcess | Thread | AppDomain | Process (.NET Fx) | Process (.NET Core) |
|---|---|---|---|---|---|
| .NET Fx | ∞ | ∞ | 333.3333 | 11.7647 | 12.6582 |
| .NET Core | ∞ | ∞ | 無法測試 | 31.2500 | 23.2558 |
Benchmark: 不同環境的 Task 執行效率
前面第一個 Part 我測試了整個 “環境” 啟動的效率。接下來要測一下在這環境下,執行 task 的效率 (也包括 code 寫法的說明) 差異。我寫了一個很簡單的 HelloTask, 來做為比較的標準依據:
public class HelloTask : MarshalByRefObject
{
public static bool state_must_be_true = true;
#if NULL_LOAD
public string DoTask(int size) => null;
public string DoTask(byte[] buffer) => "";
#else
private static Random _rnd = new Random();
private static HashAlgorithm _ha = HashAlgorithm.Create("SHA512");
public string DoTask(int bufferSize)
{
byte[] buffer = new byte[bufferSize];
return this.DoTask(buffer);
}
public string DoTask(byte[] buffer)
{
if (state_must_be_true == false) throw new InvalidProgramException();
_rnd.NextBytes(buffer);
return Convert.ToBase64String(_ha.ComputeHash(buffer));
}
#endif
}
這段 code 唯一的目的,就是造成一些合理的負載而以,我挑了會占用 RAM 跟 CPU 的案例: 計算 SHA512 hash 來當作案例。用法很簡單,就是呼叫 DoTask(), 然後把 buffer 傳進去,計算完 hash 後用 base64 字串傳回來。我設計了兩套參數,一個是只傳 int bufferSize, 另一個是由 host 端直接準備好記憶體區塊內容,用 byte[] buffer 傳遞過來。兩者之間主要差異在傳遞參數的大小 ( 4 bytes vs 1M bytes )。因為,在跨越隔離環境下要呼叫另一端的 code, 通常參數的傳遞都是要花力氣處理的。
同樣的,為了觀察傳遞參數的影響,我用了條件式編譯,來切換空轉的版本。如果 compiler 定義了 #define NULL_LOAD 的話,就會啟動空轉的版本,所有 DoTask() 呼叫都是立刻 return, 可以觀察這些機制的效能天花板。這段 code 我直接用 .NET standard 2.0 的規範開發與編譯, 其他專案不論是 .NET framework 或是 .NET code, 都會共用同一個 binary code 來執行。接著,我也把Main() 的部分做了點調整。原本是立馬 return 的 code, 改成呼叫 100 次 HelloTask:
public static int Main(string[] args)
{
for (int i = 1; i < 100; i++)
{
new HelloWorld().DoTask();
}
return 0;
}
然後,測試的主程式就不再跑 100 次重新建立環境的 code 了,這次我只執行一次隔離環境的建立。我的目的是想觀察,這 HelloTask 在不同環境下的執行速率有沒有影響。為了這個目的,我把主程式調整了一下:
public static void WorkerMain(string mode, HelloWorkerBase[] workers)
{
Stopwatch _timer = new Stopwatch();
int count = 10000;
int buffer_size = 1 * 1024; // 1kb
Console.WriteLine($"Worker: {System.Reflection.Assembly.GetEntryAssembly().GetName().Name}, Mode: {mode}");
foreach (var worker in workers)
{
_timer.Restart();
for (int i = 0; i < count; i++)
{
HelloWorkerBase.HelloTaskResult result = null;
if (mode == "VALUE") result = worker.QueueTask(buffer_size);
if (mode == "BASE64") result = worker.QueueTask(new byte[buffer_size]);
}
worker.Stop();
Console.WriteLine($"{worker.GetType().Name.PadRight(30)}: {count * 1000.0 / _timer.ElapsedMilliseconds} tasks/sec");
}
}
簡單的用個架構圖來表示,我想做的就是這樣的機制:
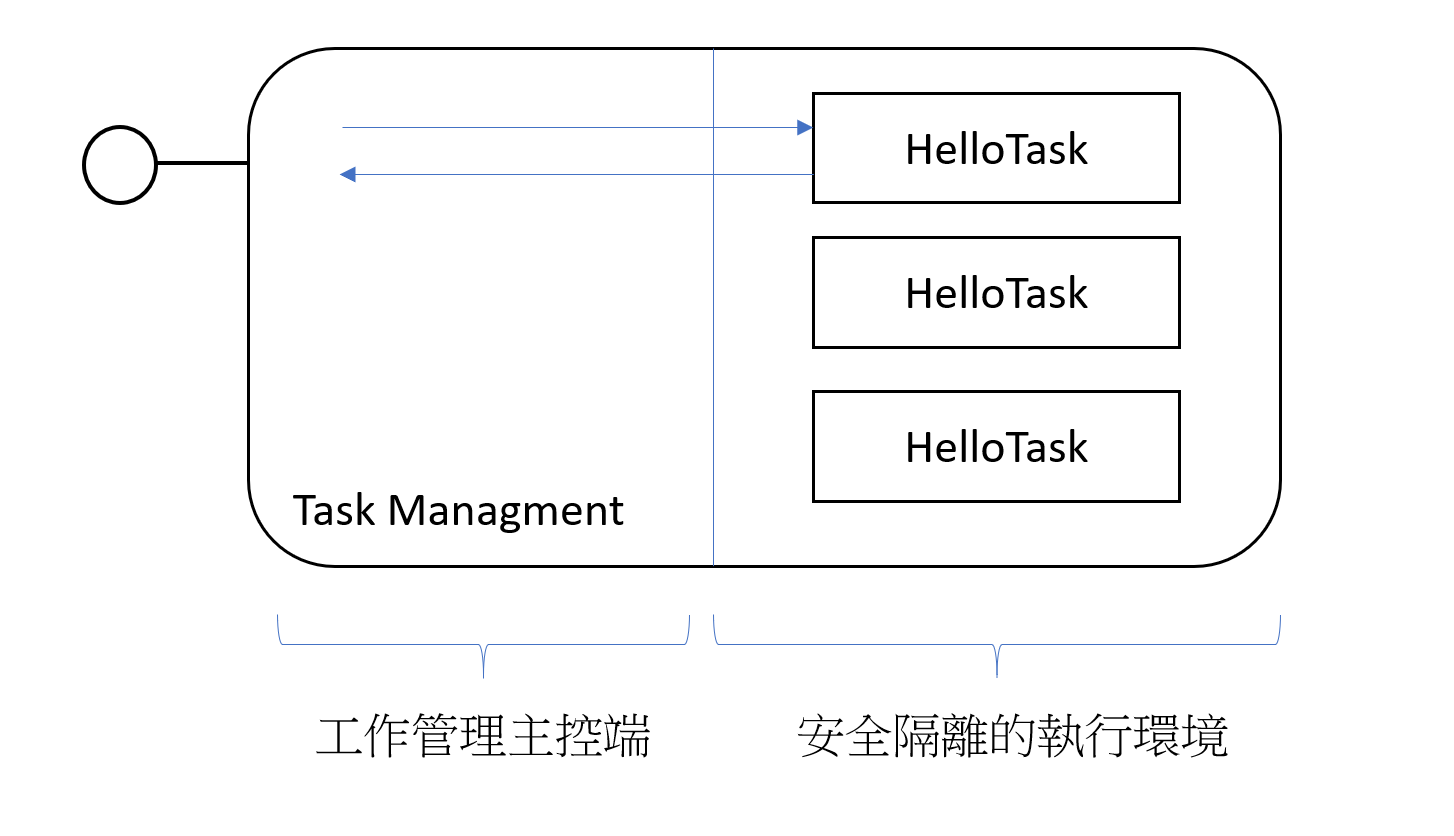
我需要有個隔離環境,來讓 HelloTask 安心的被執行,而主控端能夠適當的分配任務 (data) 給隔離環境下的 HelloTask 執行,並且傳回結果。
每種不同的隔離環境,都會有各自的 Worker 來實作。我定義了抽象類別來規範這個 Worker 的實作方式來方便測試。 HelloWorkerBase 以及每種隔離環境的實作方式,我在下個 Part 再各自說明。接下來開始的 code 就要認真面對了,我要開始模擬真正的執行狀況,我希望 Task 能夠如同本地端的 lib 一樣容易的呼叫,需要傳遞參數過去,也需要傳遞結果回來。我期望主控端建立好環境後,可以傳遞 task 需要的參數過去,然後等待執行結果回來。除了參數根結果的傳遞之外,我需要 task 所有執行過程都被限制在安全的隔離環境內。
不同的隔離方式,有不同的通訊技巧。我這邊把通訊的需求簡化成傳遞呼叫參數,跟傳回執行結果就好。基本上 InProcess / Thread 都在同一個 memory space 下,直接傳遞物件的 reference 就夠了。AppDomain 嚴格的說也是在同個 memory space (相同 process 的多個 AppDomain, 是共用 managed heap 的), 只是 heap 內的物件存取會被 AppDomain 管控。跨越 AppDomain 存取物件,必須透過 Marshal 的機制處理。至於 memory space 完全獨立的 process, 只能透過 OS 層級的機制了, 例如 pipe, network, share file / memory map file 等等都是可行的做法, 後面的 code 我就直接拿 standard I/O + pipe 來示範..
測試模式跟剛才差不多,不過因應這個測試需求,我改了一些 code …, 為了鋪梗後面的延伸範例, 我先把 POC 架構一次到位。我用以前寫過的 ThreadPool 當作範本,過去自己手動搞定 ManualResetEvent 的部分,我這邊直接用 BlockingCollection 簡化了。所有的 POC 都從 HelloWorkerBase 衍生出來:
public abstract class HelloWorkerBase
{
public HelloWorkerBase()
{
}
public abstract HelloTaskResult QueueTask(int size);
public abstract HelloTaskResult QueueTask(byte[] buffer);
public abstract void Stop();
public class HelloTaskResult
{
public HelloTaskResult(bool waitState = false)
{
this.Wait = new ManualResetEventSlim(waitState);
}
public string ReturnValue;
public readonly ManualResetEventSlim Wait;
}
}
與前面提到的 Thread Pool 相比,我抽象化了各種 Worker 的實作,也簡化了他的泛用度,因此這邊的 Worker 只限定處理 HelloTask, 但是我希望這些 HelloTask 將來能在各種不同隔離層級的要求下,有效率的處理 HelloTask…。因此 POC 公開的介面就是 QueueTask(), 我只傳遞執行 Task 必要的參數 (int size / byte[] buffer 二選一) 就夠了。為了精確控制 thread, 我選擇跳過 .NET 內建的 async / await 機制, 用簡單的 HelloTaskResult 來封裝執行結果。
如果資深一點的 developer, 應該會記得當年還沒有 async / await 時, .NET 怎麼處理這類問題的方法吧? IAsyncResult .. 我這邊就是做了一個簡化的版本: HelloTaskResult, 來當作 QueueTask() 的傳回值。這設計允許你先拿到 Result, 然後在需要的時候再呼叫 HelloTaskResult.Wait.Wait() 來等待結果。整個 Worker 設計上應該要允許平行處理,直到 Worker.Stop() 被呼叫為止。呼叫 Stop() 會停止接受新的 QueueTask() 需求,同時 Stop() 會等待 (blocking) 到所有 Task 都完成為止才會 return 。
舉例來說,如果你要呼叫三個 HelloTask, 並取得結果,正確的寫法應該是這樣:
var worker = new MyDemoWorker();
for (int i = 0; i < 3; i++)
{
var task = worker.QueueTask(1);
task.Wait.Wait();
Console.WriteLine(task.ReturnValue);
}
worker.Stop();
先從單純一點的測試開始吧。我先不去處理平行執行的部分,參數也先以最單純的 value 為主就好。我來測試看看,不重覆建立隔離環境的前提下,加上傳遞參數的效能測試。我啟用 NULL_LOAD 定義,把 HelloTask.DoTask() 的內容清空,我想先測試一下空轉時這個機制的效能極限:
不論你用哪一種 Worker 的實作來執行 HelloTask, 我都用前面提到改寫後的 WorkerMan() 來測試效能。我會測試四種組合,一個維度是空轉 / 實際負載,另一個維度是基本參數傳遞 (int) 及大型資料傳遞 (byte[]: ~ 1MB)。切換測試方式會有微小的 code 調整,這些我也略過, 我只說明一次主程式結構就好,其他直接看測試數據。接下來就逐一來看各種隔離層級的程式碼,以及測試結果:
InProcessWorker
接著先來看對照組 InProcessWorker: 完全沒有做任何隔離環境,直接執行 HelloTask …
public class InProcessWorker : HelloWorkerBase
{
public override HelloTaskResult QueueTask(int size)
{
return new HelloWorkerBase.HelloTaskResult(true)
{
ReturnValue = (new HelloTask()).DoTask(size)
};
}
public override void Stop()
{
return;
}
}
測試空轉 10000 次 HelloTask 呼叫的結果: InProcessWorker: ∞ tasks/sec
一如預期,一樣跑到破表…
SingleAppDomainWorker
接下來來看看 AppDomain 的部分。作法跟 InProcessWorker 雷同,主要的差異在於,跨越 AppDomain 的物件傳遞,必須透過 .NET Marshal 的機制來處理才行。所幸 Microsoft 幫我們把大部分的細節都處理掉了,我只需要讓 HelloTask 繼承 MarshalByRefObject, 基本上就搞定了:
public class HelloTask : MarshalByRefObject
{
// 略 ...
}
接著來看看 SingleAppDomainWorker 的實作:
public class SingleAppDomainWorker : HelloWorkerBase
{
private AppDomain _domain = null;
public SingleAppDomainWorker()
{
this._domain = AppDomain.CreateDomain("demo");
}
public override HelloTaskResult QueueTask(int size)
{
HelloTask ht = this._domain.CreateInstanceAndUnwrap(typeof(HelloTask).Assembly.FullName, typeof(HelloTask).FullName) as HelloTask;
return new HelloWorkerBase.HelloTaskResult(true)
{
ReturnValue = ht.DoTask(1),
};
}
public override void Stop()
{
AppDomain.Unload(this._domain);
this._domain = null;
return;
}
}
關鍵在於這段: CreateInstanceAndUnwrap(...), 透過 AppDomain 的這個方法,你要求指定的 AppDomain 替你建立物件,然後 Unwrap (背後需要經過 ObjectHandle 處理), 經過一連串的步驟把遠在另一個 AppDomain 的物件穿越回你現在的 AppDomain… 拿到 Unwrap 後的物件你就能直接呼叫他了,其他背後的細節,.NET 會通通替你處理掉…,除此之外,這段 code 其時跟 InProcessWorker 沒有什麼不同。有時這麼方便背後的代價是很可怕的啊,短短一行 code 背後包含這麼多系統面的知識, 搞不清楚狀況的工程師可能誤用了多年都還不知道自己錯過了什麼…
來看看執行結果: SingleAppDomainWorker: 26666.6666666667 tasks/sec
數字已經不如 InProcess 那樣破表的表現了…
SingleProcessWorker
最後來看一下 Process 隔離層級的做法。由於作業系統 (OS: Operating System) 對 Process 有先天的隔離與限制,因此跨越 Process 能使用的通訊方式,大部分都是繞到全系統通用的 I/O 的機制去處理了。不論是 pipe, stdio redir, network, share file 等等都算是 I/O 的領域。我這邊就用前面介紹過的 standard i/o redir 的機制來實作:
public class SingleProcessWorker : HelloWorkerBase
{
private Process _process = null;
private TextReader _reader = null;
private TextWriter _writer = null;
public SingleProcessWorker()
{
this._process = Process.Start(new ProcessStartInfo()
{
FileName = @"D:\CodeWork\github.com\Andrew.ProcessPoolDemo\NetFxProcess\bin\Debug\NetFxProcess.exe",
Arguments = "",
RedirectStandardInput = true,
RedirectStandardOutput = true,
UseShellExecute = false
});
this._reader = this._process.StandardOutput;
this._writer = this._process.StandardInput;
}
public override HelloTaskResult QueueTask(int size)
{
this._writer.WriteLine(size);
return new HelloTaskResult(true)
{
ReturnValue = this._reader.ReadLine()
};
}
public override void Stop()
{
this._writer.Close();
this._process.WaitForExit();
}
}
主要的通訊機制,就是在 Worker 內啟動 NetFxProcess.exe, 同時重新導向這個 process 的 STDIN / STDOUT, 我寫入一行數字到 STDIN 就代表傳遞參數過去;我從 STDOUT 讀取一行字串就代表傳回執行結果;我 close STDIN 就代表我不再需要這個 process 了,close STDIN 可以通知該 process 不會再有後面的參數了。中間的等待與協調,就靠 I/O 的 blocking 來達成。
同時來看看被啟動的 Process 另一端的 code :
class Program
{
static void Main(string[] args)
{
string line = null;
while((line = Console.ReadLine()) != null)
{
int size = int.Parse(line);
var result = (new HelloTask()).DoTask(size);
Console.WriteLine(result);
}
}
}
基本上就是把上面對於 STDIO 的傳輸定義,反過來寫而已。這邊就是讀取一行 STDIN 當作參數來呼叫 HelloTask, 然後把執行結果寫到 STDOUT 就結束了。不斷循環,直到 STDIN 被關閉為止。不過這是基本參數傳遞的版本,另外大量參數傳遞的版本大同小異,只是多用了序列化 / 轉換成 Base64 的方式處理參數傳遞而以,完整的版本:
public static void ProcessMain(string[] args)
{
string line = null;
string mode = "VALUE";
if (args != null & args.Length > 0) mode = args[0]; // transfer mode: VALUE | BASE64
switch (mode)
{
case "VALUE":
while ((line = Console.ReadLine()) != null)
{
int size = int.Parse(line);
Console.WriteLine((new HelloTask()).DoTask(size));
}
break;
//case "BINARY":
// break;
case "BASE64":
while ((line = Console.ReadLine()) != null)
{
byte[] buffer = Convert.FromBase64String(line);
Console.WriteLine((new HelloTask()).DoTask(buffer));
}
break;
}
}
這次來看看 Process 的版本執行效率: SingleProcessWorker: 41493.77593361 tasks/sec
結果有點令人意外,資料量不大的情況下,process 隔離層級的做法效能竟然還贏過 AppDomain … 當然這並不是絕對的結果,不過也證明其中的落差不如我們想像的巨大。這次測試傳遞的都是很簡單的資料 (int, string),接下來我們測試一下大型的物件看看…
Isolation 測試結果總評
接下來就是有點煩人的綜合測式了。程式碼跟做法前面都交代過,我就直接看結果。我測試了兩個維度,各兩種做法的組合。測試結果如下:
執行平台: .NET Framework 參數模式: VALUE (基本數值) 執行內容: 正常負載
Worker: NetFxWorker, Mode: VALUE
InProcessWorker : 19011.4068441065 tasks/sec
SingleAppDomainWorker : 10593.2203389831 tasks/sec
SingleProcessWorker : 13440.8602150538 tasks/sec
SingleProcessWorker : 27173.9130434783 tasks/sec
執行平台: .NET Core 參數模式: VALUE (基本數值) 執行內容: 正常負載
Worker: NetCoreWorker, Mode: VALUE
InProcessWorker : 84745.7627118644 tasks/sec
SingleProcessWorker : 12919.896640826873 tasks/sec
SingleProcessWorker : 29239.766081871345 tasks/sec
執行平台: .NET Framework 參數模式: BASE (大量資料) 執行內容: 正常負載
Worker: NetFxWorker, Mode: BLOB
InProcessWorker : 19120.4588910134 tasks/sec
SingleAppDomainWorker : 10822.5108225108 tasks/sec
SingleProcessWorker : 9285.05106778087 tasks/sec
SingleProcessWorker : 21321.9616204691 tasks/sec
執行平台: .NET Core 參數模式: BASE (大量資料) 執行內容: 正常負載
Worker: NetCoreWorker, Mode: BLOB
InProcessWorker : 85470.08547008547 tasks/sec
SingleProcessWorker : 9861.932938856016 tasks/sec
SingleProcessWorker : 25575.447570332482 tasks/sec
執行平台: .NET Framework 參數模式: VALUE (基本數值) 執行內容: 無負載
Worker: NetFxWorker, Mode: VALUE
InProcessWorker : ∞ tasks/sec
SingleAppDomainWorker : 26881.7204301075 tasks/sec
SingleProcessWorker : 51546.3917525773 tasks/sec
SingleProcessWorker : 57471.2643678161 tasks/sec
執行平台: .NET Core 參數模式: VALUE (基本數值) 執行內容: 無負載
Worker: NetCoreWorker, Mode: VALUE
InProcessWorker : 10000000 tasks/sec
SingleProcessWorker : 43668.12227074236 tasks/sec
SingleProcessWorker : 52631.57894736842 tasks/sec
執行平台: .NET Framework 參數模式: BASE (大量資料) 執行內容: 無負載
Worker: NetFxWorker, Mode: BLOB
InProcessWorker : 5000000 tasks/sec
SingleAppDomainWorker : 23419.2037470726 tasks/sec
SingleProcessWorker : 19193.8579654511 tasks/sec
SingleProcessWorker : 32051.2820512821 tasks/sec
執行平台: .NET Core 參數模式: BASE (大量資料) 執行內容: 無負載
Worker: NetCoreWorker, Mode: BLOB
InProcessWorker : 2500000 tasks/sec
SingleProcessWorker : 21739.130434782608 tasks/sec
SingleProcessWorker : 37037.03703703704 tasks/sec
這樣不大好看,我整理成表格;我把有無負載分成兩個獨立的表格來看:
無負載:
| 主程式 + 參數模式 \ 隔離方式 | InProcess | AppDomain | Process (.NET Fx) | Process .NET Core) |
|---|---|---|---|---|
| .NET Fx + VALUE | ∞ | 26881.7204 | 51546.3918 | 57471.2644 |
| .NET Core + VALUE | 10000000 | 無法測試 | 43668.1223 | 52631.5789 |
| .NET Fx + BLOB | 5000000 | 23419.2037 | 19193.8580 | 32051.2821 |
| .NET Core + BLOB | 2500000 | 無法測試 | 21739.1304 | 37037.0370 |
有負載 (buffer: 1KB):
| 主程式 + 參數模式 \ 隔離方式 | InProcess | AppDomain | Process (.NET Fx) | Process (.NET Core) |
|---|---|---|---|---|
| .NET Fx + VALUE | 19011.4068 | 10593.2203 | 13440.8602 | 27173.9130 |
| .NET Core + VALUE | 84745.7627 | 無法測試 | 12919.8966 | 29239.7661 |
| .NET Fx + BLOB | 19120.4589 | 10822.5108 | 9285.0511 | 21321.9616 |
| .NET Core + BLOB | 85470.0855 | 無法測試 | 9861.9329 | 25575.4476 |
這表格應該要這麼解讀,基本上無負載的部分,InProcess 的數據可以直接忽略了,你只要知道他很快就夠了。因為測式的精確度不夠高,測式的數量也不高 (太高我的電腦要跑完所有測式要等很久啊)。這是拿來當對照組的,我實際上不可能去用他,讓大家大約知道數量級上的差距即可。
這些測式有點難歸納結論啊,要考慮的變因 (維度) 太多,我試著從我想知道的幾個結論回頭說明我觀察的測試結果:
主程式 (管控端) 開發平台的選擇: 推薦 .NET Core
測試做完,老實說最令我跌破眼鏡的就是這組數據。我把上面的 32 項測試結果都匯到 Excel, 過濾出 .NET Fx 主程式;有負載;BASE64 傳輸模式的測試結果。令我傻眼的是: 透過 Process 層級隔離的,理論上應該是最慢的啊… 怎麼反過頭來超車,比 InProcess 還要快? 這其中一定有甚麼誤會…。
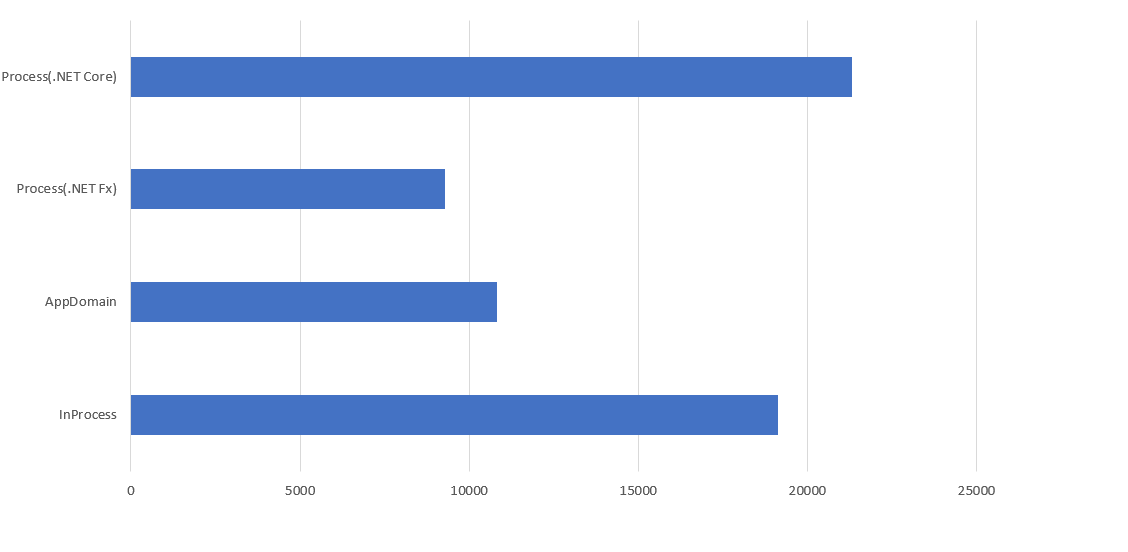
我還花了不少時間看我的 code 有沒有弄錯,最後真相大白,原因是:
.NET Core 的 SHA512 計算效能遠高於 .NET Fx 的版本...
我忽略了 Microsoft 的 .NET Fx BCL / Runtime 已經有好幾年沒有大幅改版了, 近幾年來的資源都投注在 .NET Core 身上。光是記憶體存取的優化 Span ,應該就有巨幅的影響了 (例如 .NET Core 3.1 的 Json 效能 就突飛猛進)。不相信? 從上圖的 Process(.NET Fx) 跟 Process(.NET Core) 兩條數據來對比就知道了,差了 230% 啊…
再來做個比較,通通一樣的條件,只是主程式換成 .NET Core, 來看看圖表:
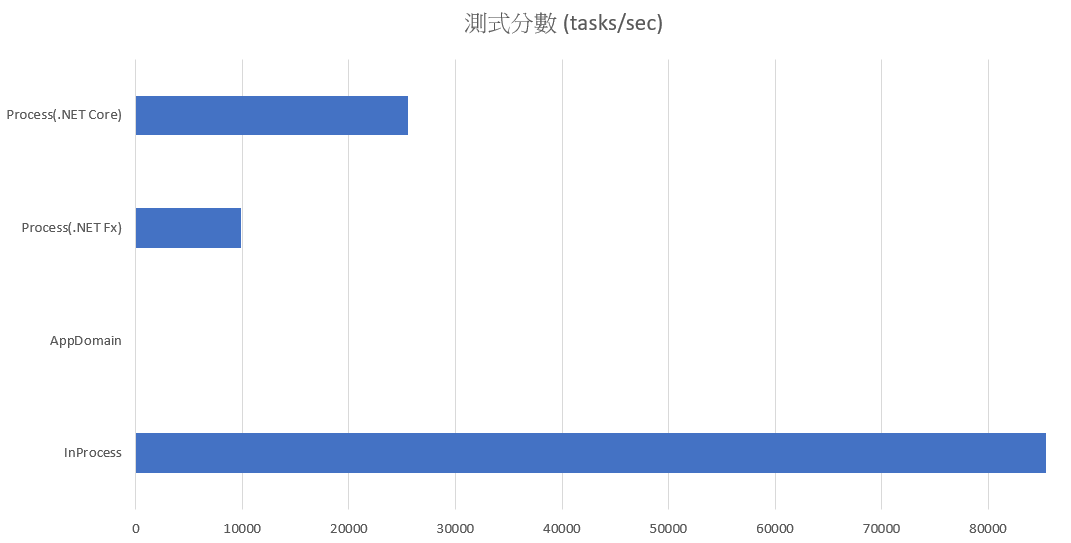
數字果然會說話,這次純粹通通都是 .NET Core 來較勁,數據就合理了。InProcess 的效能遙遙領先 Process(.NET Core) 達 330% .. 神奇的是,一模一樣的 Process (.NET Fx / Core ), 只是透過不同的主程式來啟動,竟然效能也有差異… Process(.NET Fx) 的版本因為主程式換成 .NET Core, 效能就提升了 6.2% … 而 Process(.NET Core) 表現更搶眼,提升了 19.95% …
這些我沒有再深入挖掘,不過根據經驗推論,主要改善應該來自 .NET Core 本身跟 OS 的最佳化做得更好吧,尤其在 I/O 層面 (例如新的 Async Stream, IAsyncEnumerable)..
記憶體的效率,加上 I/O 效率的改善,這次測試是我完全意料之外的結果。你還在猶豫要不要用 .NET Core 的話, 基本上可以不用考慮了。我現在終於可以理解,Microsoft 為何在 .NET Core 直接放棄 AppDomain 這樣的技術了。從數字上來看,”感覺” 架構上比較理想的 AppDomain, 完全被 Process + .NET Core 打趴在地上啊! 因為 AppDomain 必須綁定 .NET Fx, 因此選了他你就無法享用其他所有 .NET Core 帶來的效能優化, AppDomain 帶來的局部架構優化, 抵擋不了 .NET Core 全面效能優化帶來的改進。
負載 (工作端) 開發平台的選擇: 推薦 .NET Core
基本上這也沒什麼好選擇了,做完這次測試,你現在開發的 code, 毫無懸念直接轉往 .NET Core 吧! 如果你跟我一樣,還有些離不開 .NET Fx 的原因的話,至少把你的 code 改成 .NET Standard .. (這次範例 HelloTask 就是 .NET Standard 2.0), 如果再不行, 就做好準備轉移吧! 一個好方法是善用條件式編譯, 讓你能用 同一份 source code, 編譯出完整功能的 .NET Fx 版本, 同時也能編譯出只支援部分功能的 .NET Standard / Core 版本。有了這樣的規劃,剩下的交給 CI / CD, 你就開始有個基礎能夠逐步的升級轉移。
同樣這些資料,我再用不同角度來評斷一下:
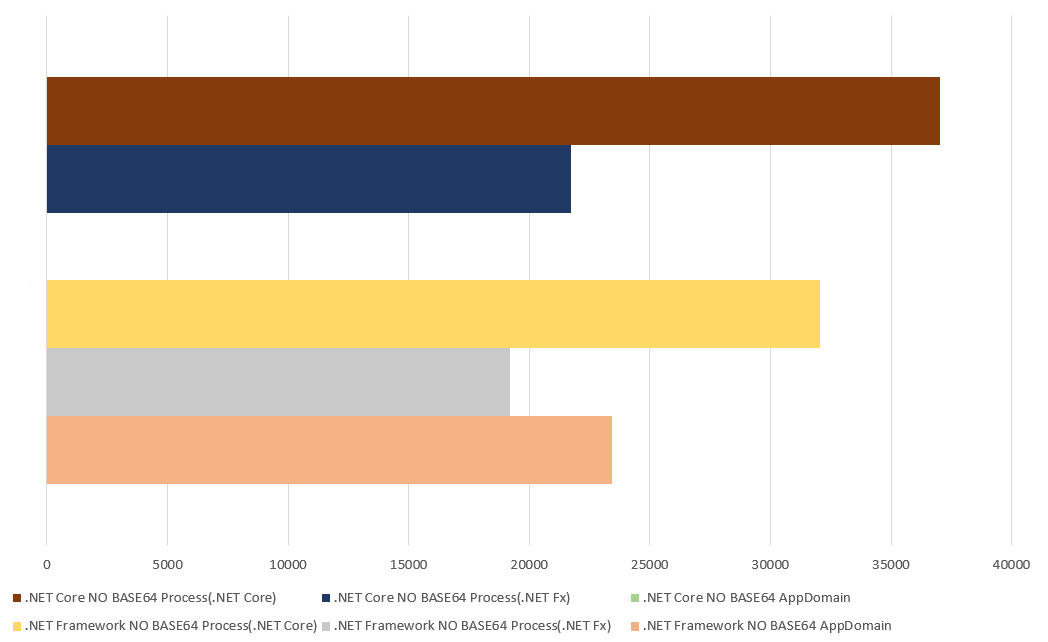
我列出所有無負載;BASE64 傳輸的數據出來看,我想知道空轉的情況下,到底整體的架構帶來的影響有多大。
同樣是 .NET Fx , 比起 Process, AppDomain 的效能好上 22.02 %, 不過這代價是你必須綁死在 .NET Fx 身上,因為他在 .NET Core 已經沒有替代品了。這代價不小,你同時得綁定主程式端跟工作端。丟掉 AppDomain, 你的選擇就更寬廣了,如同前一個評論一樣,當你有選擇機會時,優先挑選 .NET Core。如果你期望有最大的彈性,第一時間先把你的工作端 code 從 AppDomain 改成 Process 吧! 也許這樣你暫時會損失 22% 的效能,但是你開始有能力獨立改版主控端了。如果你轉移完成,主控端用 Core, 工作端用 Fx, 跟原本都用 Fx + AppDomain 相比, 效能一來一往, 只掉了 7.73 %, 但是你換來更好的架構,還有更寬闊的升級空間。拋開 AppDomain 你也開始有能力承擔更龐大的規模,Scalability 的上限也直接往上衝 (這個後半段再來討論)。
參數傳遞方式的選擇: 推薦 BLOB
這又是另一個有趣的題目,先來看看數據,這次我過濾了 無負載;只看 Process(.NET Core) 隔離方式:
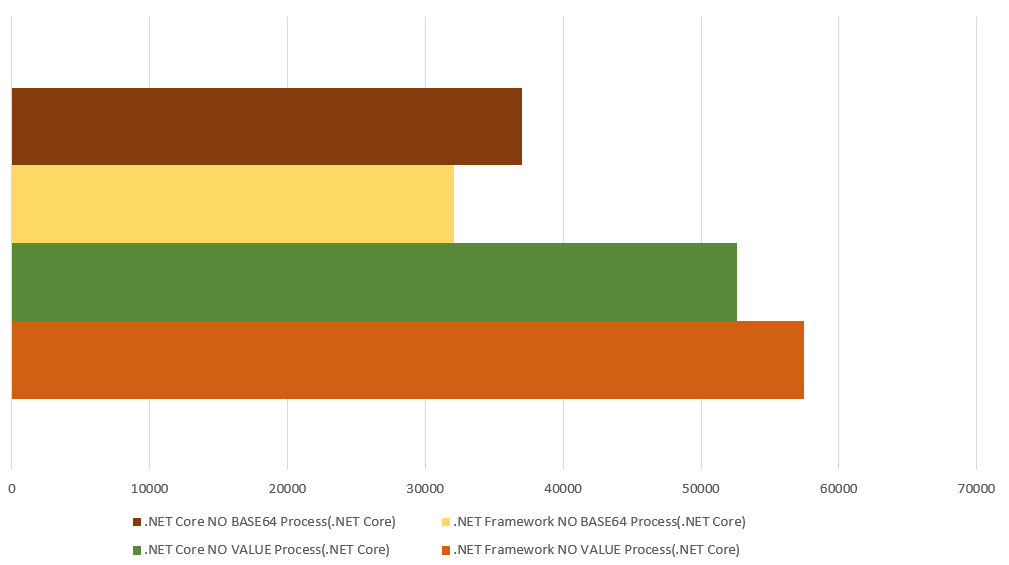
工作端基本上不用選了,我只看 Process(.NET Core) 這項就好。有 OS 的隔離,基本上我就把他當作同一回事了,我專注在前面一層主程式管控端的選擇。我唯一搞不清楚的是,最佳組合竟然是出現在 .NET Fx -> (VALUE) -> .NET Core, 比起 .NET Core -> (VALUE) -> .NET Core 好上 15.56 %… 我只能把他當作也許 .NET Fx 有些局部的最佳化做得比較好吧!
不過即使如此,整體考量我仍然會優先選擇 .NET Core 主控端 + BLOB .. 因為這次實測的參數我沒有弄得很大,才 1KB 而已,如果我傳輸的是 URL,有些較長的網址早就超過了… 這組合占優勢的地方,對我並不是那麼的關鍵。
具體來說,這兩種傳輸方式的差異可能會是什麼? 很多任務通常會搭配 DB,我做這測試的目的是想看看,透過 I/O 傳輸參數,跟透過早已存在的高效率 storage 來比的差異有多大。也許我的系統早就有備妥要傳遞的資訊了,也許存在 database, 也許存在 NoSQL 或是 Redis … 這時我也許有機會選擇只傳遞 Primary Key, 來取代傳輸完整的資料。
不過空轉的情況下,落差也沒有很大,即使落差最大的組合,差距也只有 79.31% 而已。負載再加上去差距就更小了。這時工作管理傳遞參數的選擇,我會選擇直接傳遞,即使需要序列化較大型的物件。
下一步: Process Pool
這邊我就先把這一段 Isolation 的研究告一段落。看了這麼多種組合 (.NET Fx / Core),傳遞參數的策略 (Value / BLOB), 隔離技術的選擇 (AppDomain / Process) 都做了一番測是,大體上都搞清楚每種組合的特性了。看起來最適合的隔離機制是 Process, 而主控端與工作端按照需求,盡可能的挑選效能最好的 .NET Core。中間跨越 Process 的通訊可以採用常見的 I/O (例如 STDIO, pipe 等)。
Process 跟 Thread 一樣,建立都是有很高昂的成本的,維護一個 Process 要比維護一個 Thread 代價還要更高,要花費更多的記憶體,啟動也需要花費更多時間。因此,下一步是我打算用 Process 來隔離主控端跟工作端,同時打造一個像 Thread Pool 這樣的機制,拿來管理跨越 Process 邊界執行 Task 用的 Process Pool。
回到主題: 為何你需要隔離環境?
前面把幾種我想的到的 .NET 隔離技術都試過一次,測試了環境的啟動速度,也測試了每個隔離環境內的 Task 執行速度 (包含跨越隔離環境傳遞參數)。其實,做這些測試,就是為了下一段做準備啊! 我趁這機會再重新說明一下我要解決的問題:
整套系統有很多環節,都需要非同步的任務處理。由於規模大到須要有獨立機器來負責,因此必須透過 Message Queue 把任務往後端送。不過這些非同步任務的 “種類” 也很多啊,為了確保多種任務的 code 不會彼此打架互相影響, 因此需要彼此隔離的環境來分別執行這些任務。不過隔離是需要代價的,包含隔離環境的啟動需要時間,跨越隔離環境通訊也是額外的成本。因此做好這些隔離環境的管理,取得可靠度、效能與成本的平衡便是這次要解決的問題了。
舉幾個現成的例子來說明一下 “隔離環境” 的重要性。如果我寫的 task 要跟其他人的 task 擺在一起執行, 試想這幾個情境對你有沒有影響? 有的話你就需要一個隔離環境了:
- 其他 task 把記憶體吃光了, 導致我的 code 出現 OutOfMemoryException ..
- 其他 task 吃太多 CPU 運算資源, 導致我的 code 無法分配足夠的 CPU time ..
- 其他 task 誤觸某些共用 library 的 static properties / fields 影響我的 code 執行 ..
- 其他 task 意外出現 Unhandled Exception, 導致整個 process 都被終止了, 影響我的 code 被中斷…
其實這些都是 “惡鄰居” 可能會帶來的影響。資源的分配跟問題的隔離,自然就是要挑選合適的隔離機制才能辦的到。前面介紹的 AppDomain 跟 Process 都能提供不同層級的保護機制來避免上述問題。我拿 AppDomain 做個很簡單的實驗, 我用兩種做法呼叫 AppDomainProgram.Main(), 一個是直接呼叫 (相同 AppDomain), 另一個是透過不同的 AppDomain 呼叫。在呼叫之前我先改變了 AppDomainProgram 的 static field: InitCount 的數值, 呼叫的結果就是單純列印出這變數內容而已:
Assembly: AppDomainIsolationDemo
class Program
{
static void Main(string[] args)
{
AppDomainProgram.InitCount = 543; // 模擬汙染 static fields 的狀況
AppDomainProgram.Main(null); // 不透過獨立的 AppDomain 執行 code
var iso = AppDomain.CreateDomain("demo");
iso.ExecuteAssemblyByName(typeof(AppDomainProgram).Assembly.FullName);
}
}
Assembly: AppDomainIsolationLib
public class AppDomainProgram
{
public static int InitCount = 0;
public static void Main(string[] args)
{
Console.WriteLine($"Init Count: {InitCount} (CurrentDomain: {AppDomain.CurrentDomain.FriendlyName})");
}
}
看看執行結果:
Init Count: 543 (CurrentDomain: AppDomainIsolationDemo.exe)
Init Count: 0 (CurrentDomain: demo)
Press any key to continue . . .
果然實驗證明, AppDomain 真的有達到隔離的效果。就這個例子而言,即使是 static field, 同一個 class 分隔在不同的 AppDomain 也會各自有一份 static field, 不會混在一起。因此我們能更確認不同的 AppDomain 內執行的 code 不會互相汙染各自的 code, 即使彼此都用了相同的 share library, 彼此都用了同樣的 static fields, 彼此都在同一個 process 範圍內運作。
前面介紹的只是 AppDomain 的示範而已,回過頭來,如果我需要 Process 層級的隔離呢? 因為這是作業系統提供的機制,我不一定需要完全自己寫 code 來實現啊! 我在寫這篇文章時,就已經嘗試過其他方案,透過 infrastructure 領域的工具或服務來達到目的,讓我可以在同一台 server 或是跨越多台 server 建立隔離的 Process 。不過由於應用的環節太廣泛,每種方案都有些不大適用的地方:
-
Serverless (例如 Azure Function, AWS Lambda, KNative 等等):
門檻在於冷啟動、以及直接存取 DB 的效能不佳 (database connection pool 的機制在 serverless 無法有效發揮), 缺乏 windows 平台或是 .net framework 的支援性, 在無法大規模改寫 legacy code 的情況下難以採用這解決方案。 -
Container + Orchestration:
同樣的面臨到 windows 平台的支援度就是落後 linux 一截, 能靠 kubernetes 調度的彈性有限; 由於有很多非同步任務的執行頻率很低,即使最少開啟一個 Pod 也是有很大量的閒置資源的浪費。
於是,最後只好走回老路了,這些難搞的部分拉回來自己解決,問題簡化後剩餘的部分 (單純的 scale out) 再交給成熟的 infrastructure 處理。我負責管控好單一 node 內,一個 controller + 多個 worker 的協調;而整組 (controller + multiple workers) 的 scale out 則可以交給 k8s 或是 cloud service 的 auto scaling 機制來解決。
因此我再度把腦筋動到以前寫的 Thread Pool 身上了。Thread Pool 最能發揮效益的場合,是有很多規模很小的 task, 但是數量很多, 需要平行處理。這些 task 小到為他啟動專屬的 thread 都嫌浪費的程度,因此需要適度的重複使用 threads 才符合經濟效益,因此 thread pool 的機制就這樣普及了起來。為了降低 thread 啟動跟維護的成本, 系統會先啟動幾個 threads 待命;如果 task 變多來不及處理, thread pool 會適度地多建立一些 threads 來支援, 直到達到 threads 數量上限,或是資源耗盡為止。相反的,若是 task 已經消化完畢,超過指定的閒置時間,thread pool 就會回收部分的 worker threads, 只保留最低限度的 worker threads 待命, 等待接下來的 tasks…
這不就是我需要的處理機制嗎? 只不過 thread pool 的 “thread”, 我必須按照我需要, 替換成前面一直討論的 “隔離環境” 而已,不論是 AppDomain Pool, 或是 Process Pool 都一樣。我可以用同樣的機制,盡我最大可能的削弱啟動慢的缺點;最大化批次執行的效率;同時還能保有良好的隔離性,別讓寫的不好的 code 影響到其他任務的進行。
看完這一大串說明,各為還記得前面做的各種評估跟效能測是嗎? 我把結果再貼一次,看看綜合比較 (我只取無負載,傳輸 BLOB 的部分):
各種隔離環境的啟動速度:
| 主程式 \ 隔離方式 | InProcess | Thread | AppDomain | Process (.NET Fx) | Process (.NET Core) |
|---|---|---|---|---|---|
| .NET Fx | ∞ | ∞ | 333.3333 | 11.7647 | 12.6582 |
| .NET Core | ∞ | ∞ | 無法測試 | 31.2500 | 23.2558 |
各種隔離環境的任務執行速度 (無負載):
| 主程式 + 參數模式 \ 隔離方式 | InProcess | AppDomain | Process (.NET Fx) | Process .NET Core) |
|---|---|---|---|---|
| .NET Fx + BLOB | 5000000 | 23419.2037 | 19193.8580 | 32051.2821 |
| .NET Core + BLOB | 2500000 | 無法測試 | 21739.1304 | 37037.0370 |
我就不再逐一比較了,我直接取最理想的組合: 主程式用 .NET Core, 採用 Process 隔離模式來執行 .NET Core 版本的 HelloTask 當做最後的技術選擇。在這情況下,每秒鐘可以啟動 23.2558 次 process, 而 process 每秒可以執行 37037 次 task, 兩者的速度相差近 1600 倍, 如果你沒好好利用這個 process 就回收掉他,那就太浪費了。
為了確認,在 .NET Core 的世界裡, 用 process 是不是最理想的做法,我特地花了時間 google 了各種可能的解決方案,直到找到這篇:
Porting to .NET Core, 我截錄其中一段:
App Domains Why was it discontinued? AppDomains require runtime support and are generally quite expensive. While still implemented by CoreCLR, it’s not available in .NET Native and we don’t plan on adding this capability there.
What should I use instead? AppDomains were used for different purposes. For code isolation, we recommend processes and/or containers. For dynamic loading of assemblies, we recommend the new AssemblyLoadContext class.
看到 Microsoft 官方的 devblogs 都這樣講了,我還有啥好擔心的? 接下來,下一段我就開始動手,把原本的 SingleProcessWorker, 改造成 ProcessPoolWorker 吧! 改造之後也來看看執行的效果。
自行建置 Process Pool 的編排機制
Process 有很好的隔離性,但是代價就是啟動 Process 的成本很高 (上面的測試: 一秒只能建立 23 個 process, 但是一秒中卻能執行 37037 個 task, 差距 1500 倍)。因此我需要一個聰明的調節機制來協助,常見的 “pool” 做法是個好選擇。這做法很常見,例如 thread pool, connection pool, storage pool 等等都是。這些 pool 的機制都有個共通的管理模式:
建立新的資源如果需要大量的成本 (時間),則最佳的管理方式是盡可能重複使用,透過 pool 來調度,使用完放回 pool, 需要就從 pool 拿走。不夠就多準備幾個放到 pool, 閒置過久就從 pool 裡回收。Pool 只要能維持資源的數量在依定範圍內 ( min ~ max ), 就能達到資源的使用效率最大化。
同樣的情境,套用到 process, 就是我一直在講的 process pool 了。理想情況下,只要有 task 進來, 我就要有 process 來處理他。因為 process 建立成本很高,因此我希望 process 盡量能重複使用,如果 task 處理完畢不要馬上結束,可以等待一段時間看看還有沒有其他 task 需要處理;相對的,有 task 進來就優先交給 idle 的 process, 如果都沒有再啟動新的 process 接手,直到 process 數量達到上限為止。
如果 process 超過 idle 時間還沒有 task 可以處理,為了節省資源,則這個 process 應該要自我了斷了。但是顧及 process 啟動時間可能很長,因此就算完全沒有 task 需要處理,我仍然能夠保留最少數量的 process 待命, 至少解決突然出現的 task 不至於延遲過久。
這整套處理的機制,其實就是 thread pool 的精神啊,擴大到 container, 就是 kubernetes 這類 container orchestration 機制運作原理啊, 範圍再擴大到 cloud service 的 auto scaling 機制也是類似的作法。很遺憾的是我的實際狀況無法很輕易的將這類管理任務,轉移到 container + kubernetes, 我最後決定自己來處理這樣的 process 管理機制。
實作: ProcessPoolWorker
既然都要自己挑戰 orchestration 的機制,那就做好心理準備,要對一些基本的 orchestration 做些了解吧。對 Thread Pool 的實作有興趣的朋友,可以先去看看我過去的文章;其中最關鍵的同步機制,就是生產者與消費者的控制了。透過 BlockingCollection<T> 已經可以大幅簡化很多複雜的同步細節,我就從這邊開始版吧。這個 ProcessPoolWorker 我就不分段貼程式碼了,直接貼完整的實作 (剛好 100 行搞定):
public class ProcessPoolWorker : HelloWorkerBase
{
// pool settings
private readonly int _min_pool_size = 0;
private readonly int _max_pool_size = 0;
private readonly TimeSpan _process_idle_timeout = TimeSpan.Zero;
// pool states
private readonly string _filename = null;
private BlockingCollection<(byte[] buffer, HelloTaskResult result)> _queue
= new BlockingCollection<(byte[] buffer, HelloTaskResult result)>(10); // buffer size
private List<Thread> _threads = new List<Thread>();
private object _syncroot = new object();
private int _total_working_process_count = 0;
private int _total_created_process_count = 0;
private AutoResetEvent _wait = new AutoResetEvent(false);
public ProcessPoolWorker(string filename, int processMin = 1, int processMax = 20, int processIdleTimeoutMilliseconds = 10000)
{
this._filename = filename;
this._min_pool_size = processMin;
this._max_pool_size = processMax;
this._process_idle_timeout = TimeSpan.FromMilliseconds(processIdleTimeoutMilliseconds);
}
private bool TryIncreaseProcess()
{
lock (this._syncroot)
{
if (this._total_created_process_count >= this._max_pool_size) return false;
if (this._total_created_process_count > this._total_working_process_count) return false;
if (this._queue.Count == 0) return false;
if (this._queue.IsCompleted) return false;
}
var t = new Thread(this.ProcessHandler);
this._threads.Add(t);
t.Start();
return true;
}
private bool ShouldDecreaseProcess()
{
lock (this._syncroot)
{
if (this._queue.Count > 0) return false;
if (this._total_created_process_count <= this._min_pool_size) return false;
}
return true;
}
private void ProcessHandler()
{
lock (this._syncroot) this._total_created_process_count++;
var _process = Process.Start(new ProcessStartInfo(this._filename, "BASE64")
{
RedirectStandardInput = true,
RedirectStandardOutput = true,
UseShellExecute = false,
});
_process.PriorityClass = ProcessPriorityClass.BelowNormal;
//_process.ProcessorAffinity = new IntPtr(14); // 0000 0000 0000 1110
var _reader = _process.StandardOutput;
var _writer = _process.StandardInput;
Console.WriteLine($"* {DateTime.Now} - Process [PID: {_process.Id}] Started.");
while (this._queue.IsCompleted == false)
{
if (this._queue.TryTake(out var item, this._process_idle_timeout) == false)
{
if (this.ShouldDecreaseProcess())
{
break;
}
else
{
Console.WriteLine($"* {DateTime.Now} - Process [PID: {_process.Id}] Keep alive for this process.");
continue;
}
}
this.TryIncreaseProcess();
lock (this._syncroot) this._total_working_process_count++;
_writer.WriteLine(Convert.ToBase64String(item.buffer));
item.result.ReturnValue = _reader.ReadLine();
item.result.Wait.Set();
lock (this._syncroot) this._total_working_process_count--;
}
lock (this._syncroot) this._total_created_process_count--;
Console.WriteLine($"* {DateTime.Now} - Process [PID: {_process.Id}] Stopped.");
_writer.Close();
_process.WaitForExit();
this._wait.Set();
}
public override HelloTaskResult QueueTask(int size)
{
throw new NotSupportedException();
}
public override HelloTaskResult QueueTask(byte[] buffer)
{
HelloTaskResult result = new HelloTaskResult();
this._queue.Add((buffer, result));
this.TryIncreaseProcess();
return result;
}
public override void Stop()
{
this._queue.CompleteAdding();
while (this._queue.IsCompleted == false) this._wait.WaitOne();
}
}
我這邊先定義好,管理 process pool 的幾個必要參數:
-
BlockingCollection<T> _queue的 collection size:
代表 ProcessPool 允許預先接收的 task 數量。如果後端 process 消化的速度不夠快, _queue 裡面等待的 task 超過這數量, 則 QueueTask() 會 blocked, 前端加入 Task 會被暫停。 -
int _min_pool_size:
代表 process pool 必須維持的 process 最低數量。低於這數量, 即使 idle timeout 時間到了,也不會終止這個 process .. -
int _max_pool_size:
代表 process pool 必須維持的 process 最大數量。高於這數量, 即使還有 task 未處理完, 也不會在增加新的 process .. -
TimeSpan _process_idle_timeout:
代表 process 等待 task 的最大時間。等待超過這時間還沒有 task 可以處理時,process 會自行終止。
這些定義,大概就足以描述我期望的 process pool 運作所有的必要設定了。接下來我們先看看怎麼 “管理” 好單獨的一個 process。請直接看前面完整程式碼的這個 method: ProcessHandler() …。這邊我結合了先前設計 ThreadPool 的經驗,跟這次 process 的隔離與通訊技巧。我替每個 process 準備了一個專屬的 thread 來照顧他,而 ProcessHandler() 就是這個 thread 要做的事情。一旦 process 終止,這個 thread 就會跟著結束。其實觀念上你就想像成這是個標準的 thread pool + IPC (Inter-Process Communication) 的設計就好了。不用成熟普遍的 thread pool 套件來用,原因很簡單,這些套件都只開放處理大量 task 的機制啊,thread 本身是被封裝起來的,如果我要做好 thread 跟 process 之間的對應,我就必須自己處理這部分的細節。
我用 ProcessHandler() 來代表一個 Process 的完整生命週期。其中的關鍵就在中間的 do - while loop 而已,前面只是建立 Process, 後面則是關閉 Process 的程序。我用了個 BlockingCollection 來接收前端 QueueTask() 收到的 task, 每個 ProcessHandler 就不斷地從 _queue 接收 task 來處理。TryTake() 如果已經沒有 task, 或是等待超過 timeout 時間的話,就會 return false, 這時外面 while() 就會判斷要不要再等下一輪? 如果 _queue 還沒結束,或是 process 總數已經小於等於 _min_pool_size 最小數量的話,那這個 process 就不會結束,繼續等下一輪。
關鍵的地方在於 Pool 的控制。如果這輪沒辦法從 _queue 收到 task, 要嘛 _queue 已經 Completed 了,或是超過 idle timeout 了。這時我會觸發 ShouldDecreaseProcess() 來判定目前的 process 是要直接終止,還是要 keep alive 繼續空等下去? 這背後判定的邏輯就是由 max / min pool size 來判定的。
如果順利從 _queue 取得 task, 則會觸發另一個檢查: TryIncreaseProcess(), 判定是否需要預先啟動另一個 process 起來待命。這邊一樣是由 max / min pool size 來判定,同時會檢查已經啟動的 process 是不是都在忙碌中? 若還有空閒的 process 則會略過這擴充的機制。
接下來,看看 task 被加進去 worker 的部分 QueueTask(byte[] buffer),我放棄另一個傳遞 value 的實作,只做 BLOB 這份。準備好 buffer 跟 result, 就用 Tuple 打包丟到 _queue 裡面了。加入時順便做 TryIncreaseProcess() 的判斷,然後就把 result 傳回去。這 result 就是前面介紹過的 HelloTaskResult, 裡面包含 WaitHandle 的設計,等背景任務完成後, 可以透過 WaitHandle 通知能夠讀取 ResultValue 的內容了。這算是個陽春的 Async Task 做法,實際開發時,你可以考慮把它改成 .NET 的 Task, 就能更充分的應用 async / await 機制了。
這三個流程的關鍵點,是我控制 Process Pool 數量的時間點。透過這三個控制點,我就能精準的調節 process 的數量, 用最洽當的 pool size 來處理負載。
最後是 Worker 的 Stop() 程序,當你通知 Worker 該結束時,第一件事是通知 _queue 不會再有 task 被加進去了,呼叫 BlockingCollection.CompleteAdding() 可以完成這個動作。
接著,我埋了一個 AutoResetEvent _wait, 這物件就像閘門一樣,另一端 Set(), 這邊的 WaitOne() 就可以通過一次。我讓每個 ProcessHandler 結束前都呼叫一次 this._wait.Set(), 這邊的 this._wait.WaitOne() 就會醒來一次。醒來後判斷是否 _queue 已經空了? 若還沒代表還有 ProcessHandler 沒結束。直到最後一個 ProcessHandler 離開,這邊就會跟著離開了。
這樣的設計,可以讓外面使用 Worker 的程式,能夠精準的等待,到所有任務都成功處理完畢為止。
實際測試 Benchmark
寫到這邊,剛剛好 100 行 XDD (我真的很計較行數)。你也許會懷疑只有 100 行真的能做完整個類似 kubernetes 對於 pod 進行的 orchestration 機制嗎? 別懷疑,來試看看就知道。接下來,我們寫一段 code 來測試看看 ProcessPoolWorker 的表現是不是如我們預期…
我把前面的 benchmark 重新拿出來用吧! 我只測式 有負載, BASE64 模式的那組, 版面關係我就跳過 .NET Fx 的測試了,加上 ProcessPoolWorker 一起測試:
有負載 (buffer: 1KB):
Worker: NetFxWorker, Mode: BASE64
InProcessWorker : 19120.4588910134 tasks/sec
SingleAppDomainWorker : 10845.9869848156 tasks/sec
SingleProcessWorker : 9596.92898272553 tasks/sec
SingleProcessWorker : 21598.2721382289 tasks/sec
ProcessPoolWorker : 51282.0512820513 tasks/sec
Worker: NetCoreWorker, Mode: BASE64
InProcessWorker : 84745.7627118644 tasks/sec
SingleProcessWorker : 10183.299389002037 tasks/sec
SingleProcessWorker : 26385.224274406333 tasks/sec
ProcessPoolWorker : 58823.529411764706 tasks/sec
有負載 (buffer: 1KB):
| 主程式 + 參數模式 \ 隔離方式 | InProcess | AppDomain | Process (.NET Core) | Process Pool (.NET Core) |
|---|---|---|---|---|
| .NET Fx + BLOB | 19120.4589 | 10845.9870 | 21598.2721 | 51282.0513 |
| .NET Core + BLOB | 84745.7627 | 無法測試 | 26385.2243 | 58823.5294 |
效能只多了兩倍,其實還沒完全榨出潛力。我加大運算負載,把計算 hash 的 buffer 從 1KB 加大到 1MB, 一次丟 10000 筆進去計算:
Worker: NetFxWorker, Mode: BASE64
InProcessWorker : 20.9336403600586 tasks/sec
SingleAppDomainWorker : 20.7092504079722 tasks/sec
SingleProcessWorker : 40.9785682088268 tasks/sec
ProcessPoolWorker : 168.878981321985 tasks/sec
Worker: NetCoreWorker, Mode: BASE64
InProcessWorker : 102.3059767151597 tasks/sec
SingleProcessWorker : 55.12983075141959 tasks/sec
ProcessPoolWorker : 183.8978998859833 tasks/sec
有負載 (buffer: 1MB):
| 主程式 + 參數模式 \ 隔離方式 | InProcess | AppDomain | Process (.NET Core) | Process Pool (.NET Core) |
|---|---|---|---|---|
| .NET Fx + BLOB | 20.9336 | 20.7093 | 40.9786 | 168.8790 |
| .NET Core + BLOB | 102.3060 | 無法測試 | 55.1298 | 183.8979 |
測試到這邊,已經看到 Process Pool 帶來的效益了。只要你的 VM 運算資源還足夠,多開啟幾個 process 是有助於提升整體運算力的。同樣是 .NET Core 的 Process, 啟用 Pool 機制就可以提升 333.57% 的效率, 對比效率差距最大的兩筆數據: .NET Fx + AppDomain = 20.7093, 及 .NET Core + Process Pool = 183.8979 來看,效能差距拉大到 887.997%, 差了近 9 倍…
進階資源控制: 指派 CPU, 調整 process 優先權
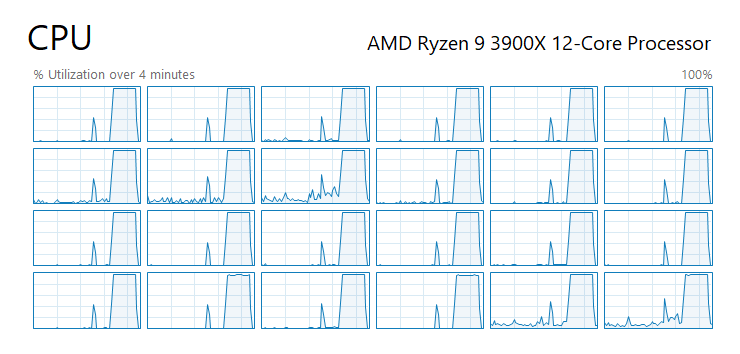
既然要做 orchestration, 那就應該做到位一點。上面的例子,我 pool size 開到 24 process(es), 跑測試時, 把我 12C/24T CPU 的運算能力都吃光了:
如果這台 server 還有其他任務要跑 (至少要讓主程式好好的執行啊),那有些地方應該要留意一下:
- CPU Affinity: 處理器相關性, 可以指定你只要用哪幾個核心
- Process Priority: 處理程序的優先權
有唸過作業系統的話,應該對於這些排程的原則不陌生。第一個 CPU Affinity, 你可以更精準的分配 CPU 核心該怎麼使用, 你可以調配指定的幾個核心來負責其他任務。另一個 Priority 則是我常用的,我會把 CPU Bound 的任務優先權調的略低 (BelowNormal), 這樣有個好處是, 當別人要忙的時候,因為優先權較低, OS 會優先把 CPU 分配給其他 process, 但是你的 process 還是繼續執行, 他會吃光所有剩下的 CPU。如此一來,其他任務都可以兼顧回應速度,而你也不會浪費任何一點 CPU 運算能力。
要指定這些參數,一點也不複雜,加這兩行就夠了。ProcessorAffinity 用的是二進位,給 1 的就是打開那顆 CPU:
_process.PriorityClass = ProcessPriorityClass.BelowNormal;
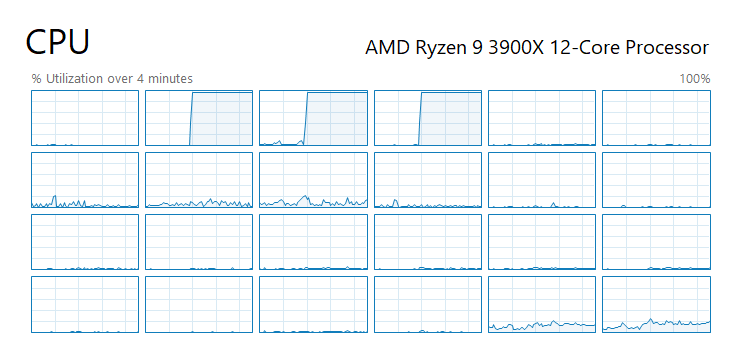
_process.ProcessorAffinity = new IntPtr(14); // 0000 0000 0000 1110
我將 ProcessorAffinity 設定成 14 (0b 0000 1110), 代表我只用第 1, 2, 3 這三個核心, 其他 0, 4 ~ 23 通通讓給其他人使用。同樣程式跑出來就像這樣,這 24 process 都只擠在我指定的那三個核心上面執行:
Auto Scaling 測試
進行到此,其實還有一些測試被我省略掉了,但是我在正式的專案是有進行的,就是當大量 process 同時運行時,記憶體使用量反而是個瓶頸了,這時 process pool 能夠適時的自動回收閒置的 process 發揮了很大的作用。過去沒有啟用回收機制時,我們配置 VM 時都卡在 RAM 不足,但是啟用適當的回收機制後,記憶體不再是瓶頸了,我們能夠開啟更多 “真正” 有在做事的 process, CPU 的使用率提高了。換來的好處是我們需要的 VM 更少了,這些效能調較優化的效益,直接反映在雲端的運算費用上。
本來想要模擬一下 allocate 大量記憶體的,不過我試了一下,我有 64GB RAM, 要塞滿到觀察的出來很花時間啊… Orz, 我換個方式表達好了。我就不直接觀察記憶體使用量,我直接觀察 process 的生命週期是否如我預期好了。原本上面的測試,只是很無腦的把 10000 個 task 交給 Worker 處理,這次我動點手腳:
var worker = new ProcessPoolWorker(
@"D:\CodeWork\github.com\Andrew.ProcessPoolDemo\NetFxProcess\bin\Debug\NetFxProcess.exe",
2, 5, 3000);
for (int i = 0; i < 100; i++) worker.QueueTask(new byte[1 * 1024 * 1024]);
Console.WriteLine("Take a rest (worker idle 10 sec)...");
Task.Delay(10 * 1000).Wait();
Console.WriteLine("Wake up, start work.");
for (int i = 0; i < 100; i++) worker.QueueTask(new byte[1024 * 1024]);
worker.Stop();
我建立一個 ProcessPoolWorker, pool 參數設定 2 ~ 5 之間, idle timeout 設定 3 sec… 程式一開始直接丟 100 個 1MB buffer 的 SHA512 計算需求 task 進去, 然後等待 10 sec 後繼續丟 100 個 task 進去, 最後離開。這次我在 ProcessHandler 的啟動與終止的地方印了訊息,來觀察一下執行結果:
* 2/19/2020 04:37:59 AM - Process [PID: 32628] Started.
* 2/19/2020 04:37:59 AM - Process [PID: 29776] Started.
* 2/19/2020 04:37:59 AM - Process [PID: 15200] Started.
* 2/19/2020 04:37:59 AM - Process [PID: 19060] Started.
* 2/19/2020 04:37:59 AM - Process [PID: 31692] Started.
Take a rest (worker idle 10 sec)...
* 2/19/2020 04:38:04 AM - Process [PID: 29776] Stopped.
* 2/19/2020 04:38:04 AM - Process [PID: 32628] Stopped.
* 2/19/2020 04:38:04 AM - Process [PID: 19060] Stopped.
* 2/19/2020 04:38:04 AM - Process [PID: 15200] Keep alive for this process.
* 2/19/2020 04:38:04 AM - Process [PID: 31692] Keep alive for this process.
* 2/19/2020 04:38:07 AM - Process [PID: 15200] Keep alive for this process.
* 2/19/2020 04:38:07 AM - Process [PID: 31692] Keep alive for this process.
* 2/19/2020 04:38:10 AM - Process [PID: 15200] Keep alive for this process.
* 2/19/2020 04:38:10 AM - Process [PID: 31692] Keep alive for this process.
Wake up, start work.
* 2/19/2020 04:38:11 AM - Process [PID: 21908] Started.
* 2/19/2020 04:38:11 AM - Process [PID: 32396] Started.
* 2/19/2020 04:38:11 AM - Process [PID: 27956] Started.
* 2/19/2020 04:38:12 AM - Process [PID: 31692] Stopped.
* 2/19/2020 04:38:12 AM - Process [PID: 15200] Stopped.
* 2/19/2020 04:38:12 AM - Process [PID: 32396] Stopped.
* 2/19/2020 04:38:12 AM - Process [PID: 27956] Stopped.
* 2/19/2020 04:38:12 AM - Process [PID: 21908] Stopped.
D:\CodeWork\github.com\Andrew.ProcessPoolDemo\NetCoreWorker\bin\Debug\netcoreapp3.1\NetCoreWorker.exe (process 31772) exited with code 0.
Press any key to close this window . . .
從時間序可以看到執行的過程,04:37:59 時啟動了 5 個 process, 主控端就去休息 10 sec 了。開始休息後過了 5 sec, 每個 process 差不多都超過 idle timeout 了,可以看到 04:38:04 時有 3 個 process 就自我終止了, 由於 min pool size 的限制, 另外有 2 個 process 持續 keep alive, 選擇繼續等待後面隨時會產生的 task. 這 keep alive 的動作每隔一次 timeout 時間就會再確認一次, 直到有新的 task 為止。
時間序到了 04:38:11, 主程式又有新的 100 task(s) 進來了。這瞬間保留待命的 2 process 又不夠了, 於是 Worker 繼續啟動新的 process 起來應付流量, 從訊息看到又啟動了 3 個新的 process 加入行列。留意一下 PID 跟先前的不同,代表這真的是重新建立的 process。這次不再是 idle, 而是主程式直接呼叫 Worker.Stop() 了,因此 process pool 進入 shutdown 的程序, 每個 process 結束工作後就退出,這次沒有保留任何 keep alive 的 process, 而是 5 個 process 全數終止,正常離開。
從這過程,看的出來簡單的 100 行 code (寫出來很簡單,要搞懂不簡單啊啊啊啊…) 就能達到這麼精準的資源調度, 果然平行處理是個很迷人的領域啊 (咦?
最後結論
終於完成這篇文章了,我也同時完成了 ProcessPool 的實作。感覺又回到十年前自己刻出 ThreadPool 的成就感。Process Pool 是很實用的技巧,不過太多框架與服務盛行,往往工程師都忽略掉這些隨手可得,只需要基礎的語言就能達成的做法。只要你願意打好基礎,好好的掌握這些基礎原理跟知識,這種問題 100 行的 code 就能搞定啊! 看過太多人迷信服務跟框架,一個小問題就相依過多外部服務,結果沒有帶來多大的效益,卻帶來了過多的相依性,造成維運的困難。
其實寫了這一大串下來,我的想法還是一樣。架構相關的技術是需要靈活運用的,當你沒把應用擺在第一位的話,你就很容易被細節牽著跑,手上拿著槌子就覺得什麼問題都像個釘子一樣了。這次我面對的問題,就是很典型是 application 本身的需求, 感覺起來好像可以靠 infrastructure 來解決, 偏偏就是有些關鍵的環節需要由 developer 來做好整合。這次的問題,各個團隊的成員都給了我很充分的技術評估,我才有足夠的資訊做出最終的架構決策。我相信經過這樣的過程,調整出來的方案才是最適合團隊需要的。
舉例來說,這次的情境,乍看之下 function as a service 應該是最適合的情境, 無奈 .net framework + database connection 先天就不適合, 跟這些方案絕緣; 這些 process pool 的管控,將他 containerize 後交由 kubernetes / docker swarm 管理也應該是最適合的機制, 無奈 windows container 的支援度有限, 而且這些 process 的調度又高度與 application 內的訊息相關, 調度的單位必須細緻到 job, 而非 service, 我如果硬要套用 kubernetes 的話,我可能會被迫搞出有幾百個 pod 的這種怪物出來… 這樣的架構決策,其實也會造成團隊分工的矛盾與困擾。
這時,當有必要,而且你有重新打造輪子的能力時,你的價值就表現出來了。重新打造輪子,不代表你必須從頭開始設計,你只需要處理最關鍵的部分,其他成熟的零件你還是可以使用的。例如這個案例,我其實不需要處理到跨越 server 的 process pool, 我只親自操刀單一 VM 內的 process pool management, 以 VM 為單位的 scale out 我還是可以交給成熟的 infrastructure 來管理,你可以把你的精力真正用在刀口上啊!
越往架構的角度鑽研,這樣的體認越深刻;資訊科學的基礎技能往往不大吃香 (因為平常工作老闆看不大出來這些技能的差異),但是他往往決定了你的能力天花板在哪邊,你能用多精準的手段來解決問題。這次是個很好的案例,特地把這些研究的過程跟最後的 POC 結果整理成這篇文章,希望能幫到有需要的朋友們 :)
這次的 POC / Sample Code 有點雜亂,我都整理在我的 GitHub 上了。如果你只是想了解我怎麼做的,其實 source code 我都貼在文章上了,看文章說明應該比較好懂。如果你想親自執行看看,可以直接 git clone 我的 repo . 任何意見都歡迎在 FB 留言給我 :)
