
來源: 動畫瘋, 不起眼女主角培育法 S1.EP2, 這動畫一定是在談 embedding space (咦?)..
LLM 應用開發,來到第三篇。這篇我想談談 LLM 應用程式處理資料的做法。在 LLM 帶來很好的語言理解能力後,這需求也延伸到資料處理 (資料庫) 的領域了。這些過程跟我過去理解的資料庫正規化等等技巧,完全是不同領域啊,為了補足這段空缺,前兩篇研究完 LLM 如何替你呼叫 API 完成任務後,這篇我想以同樣角度,研究讓 LLM 能幫你找出並應用你的 DATA 的作法了。在軟體開發的領域,行為跟資料同樣重要,一直都是開發人員關注的兩大主題。補完這篇,我覺的對整個 LLM 應用開發的版圖就完整了。
這次我拿我自己累積的文章為主的應用: “安德魯的部落格 GPTs” 來示範吧。我希望能藉著 AI 的力量,讓我的讀者們能更有效的運用 (我期待不只是閱讀) 我的文章,來解決各位開發設計上的問題。我的部落格,一直是我過去 20 年來不間斷持續維護的 side project, 我除了改善系統本身之外,也不斷地在累積文章內容,因此不論文件的質、量、儲存格式等等,我都有十足的掌控能力,拿來做這次的 PoC 再適合也不過。
0. 寫在前面
我寫文章時,我會圍繞在特定領域 ( microservices, parallel process, OOP 等) ,挑特定主題 (例如: 架構面試題) 分享我解題的過程,從定義問題,構思解法,設計 POC,開發,模擬驗證的過程交代一次。對我而言,是個很實用的顧問資料庫。不過,有很多人都嫌過我寫太長,消化吸收不容易 (沒辦法,這些題目真的很硬),不過我還是堅持這樣做,因為這是我個人特色,我寫短篇應該就沒人要看了吧…。事實證明,我這做法,就算是老文章,過了好幾年仍然有參考價值,不會因為技術的替代就被遺忘 (我十年前的文章都還有一定的流量)。而這座法的缺點: 不容易閱讀消化,藉著 GPTs 的發展,正好能替我補足這環節。
快速回顧一下我的部落格:
- 時間: 2004/12/14 寫了第一篇文章至今
- 數量: 這期間總共發表了 327 篇文章
- 字數: 文字內容部分 (包含程式碼,排除 HTML 等處理格式的部分) 共計 400 萬字
- 主題: 軟體開發,架構設計的領域為主。架構師觀點、架構面試題 (解題)、微服務架構、平行處理技巧、物件導向設計等
這次的 PoC, 我想拿 Chat GPT 當作介面,背後靠 Azure OpenAI 的力量,自己實做 RAG (Retrieval-Augmented Generation, 檢索增強生成) 的機制,結合 GPTs,我想體驗看看這件事能多容易解決。花了不少研就的時間,但是真正花在開發的時間其實很少,如果重做一次,大概不用一天就全部搞定了吧。這次成果,我設計的 “安德魯的部落格 GPTs“,一個擁有我所有文章當作知識庫的對談 AI 機器人。你可以找他詢問、查詢、解題,甚至用不同語言來導讀,GPTs 都能輕鬆應付。突然之間,我覺得過去花心思累積下來的文章是有價值的,AI 的進步非但沒有讓我被淘汰,反而讓我的部落格更有運用的價值了。
如果你也想看看相關的文章,我把 Gen AI 主題系列文章列在這:
前言: LLM 應用程式開發
2023 開始,生成式 AI 就把軟體開發產業翻了一輪了,我也開始花了空閒的時間,研究 LLM 的應用程式開發。這系列我寫了幾篇文章,包含我對未來 AI 發展的看法,AI 如何整合既有 API,以及 AI 如何善用知識庫的心得。
目前寫了三篇相關文章:
- 開發人員該如何看待 AI 帶來的改變?, 2024/01/15
- 替你的應用程式加上智慧! 談 LLM 的應用程式開發, 2024/02/10
- 替你的應用程式加上智慧! 談 RAG 的檢索與應用, 2024/03/15
體驗我開發的 GPTs:
除了文章之外,也有了一點點成果可以展示。我寫了兩個 GPTs,只要你有 Chat GPT Plus 訂閱的都能直接體驗看看:
- 安德魯小舖 GPTs: 體驗用對談的方式,完成整個購物的過程。背後串接我自己開發的線上商店 API
- 安德魯的部落格 GPTs: 我將我的部落格所有文章建立索引,透過 GPTs 你能有效率的查詢這些文章。你也可以直接問 GPTs 問題,他會運用我的文章內容來回覆你的問題
1. “安德魯的部落格” GPTs - Demo
趁這次研究,我才發現我的部落格開張就要 20 年了,從第一篇 技術文章 開始,我就養成只寫原創內容的文章。我很在意分享背後的想法,勝過單純說明步驟,或是單純介紹產品或技術類型的內容。以投入的時間,跟得到的效益 (點閱率,廣告收益等等) 來看,我的作法完全沒有效益,但是以知識的分享來看,我自認做得還不錯。這 20 年來,很多超過十年以上的老文章仍然都有人在看,代表當年寫的東西都還有存在的價值… 不過,文章的傳播型態,確實也帶來了我上面提的一些困擾…
2023 一整年,Chat GPT 的出現,把整個網路產業都翻了一輪,我也開始在想,我除了透過靜態部落格文章之外,是否也有其他對外輸送知識的方式? 除了讓大家免費閱讀,如果能用來提供對談的互動,用我文章內容來回答讀者的問題,不是很棒嗎? 於是,在我做完 “安德魯小舖 GPTs” 之後,AI 代替使用者執行動作 (購物) 的部分其實已經到位了,接下來我想換個角度,讓 AI 來協助使用者,有效率的運用知識,有效率的使用我部落格累積的知識庫內容。
1-1, 示範: 整理我的部落格發展史?
過去 20 年來,我也換過好幾次系統了,更換系統的同時,我都會寫幾篇文章交代我的想法,新系統的特色,內容如何轉移,以及我如何開發擴充套件,把系統改造成我想要的樣子? 回想起來,圍繞著這主題,有大大小小幾十個 side project 在裡面吧。不過,當我想要回顧我在我部落格上做的努力,我發現連我自己都很難很有效率的找出來啊,只能按照印象,自己一篇一篇慢慢翻,或是用 google search engine 輔助,分別查了幾個相關的 keyword,看看有沒有我漏掉的主題…,然後最後再手動整理彙整…
我想要的結果就如下所示,各位可以體會看看這些內容,主軸都是我自己對部落格做的調整,但是沒有一致的分類,也沒有通用的關鍵字。想像一下如果你是我,你會怎麼 “整理” 這些內容? 如果你是讀者,這樣的整理對你較好吸收? 還是 Google Search 更好用? 最後就是,這樣的整理只有我能做嗎? 還是能靠 AI 的力量讓大家自己都能做得到?
Blogging as code !!
摘要: 安德魯分享了他從2002年開始維護部落格至今的經歷,包括更換了多套部落格系統,從最早的自製asp.net 1.1 blog> 到WordPress等。最後決定採用最簡單的靜態檔案,並使用GitHub Pages作為Hosting方式。文章中還討論了靜態檔案帶來> 的好處以及使用markdown的方便性。 標籤: Jekyll, Liquid, Wordpress, Blogging, GitHub, VSCode 發布時間: 2016-09-16[BlogEngine.NET] 改造工程 - CS2007 資料匯入
摘要: 安德魯描述了他如何將舊有的CS2007資料成功匯入到BlogEngine.NET的過程,包括處理資料庫和檔案的轉移、解決中> 文網址問題和分類標籤的對應等技術挑戰。 標籤: .NET, ASP.NET, BlogEngine.NET, Community Server, 技術隨筆, 有的沒的 發布時間: 2008-06-21[架構師的修練] #1, 刻意練習 - 打好基礎
摘要: 安德魯談到了自己在維護部落格過程中,透過學習新技術並將其應用到部落格的每一次改版中,從中獲得刻意練習的機> 會。文章回顧了他從2002年使用自製的blog系統開始,到後來使用GitHub Pages的歷程。 標籤: 系列文章, 架構師的修練, 刻意練習 發布時間: 2021-03-01Case Study: BlogEngine -> WordPress 大量(舊)網址轉址問題處理
摘要: 文章中安德魯分享了從BlogEngine遷移到WordPress過程中遇到的大量舊網址轉址問題,以及如何使用Apache的> RewriteMap來解決這一問題的經驗。 標籤: 技術隨筆, 有的沒的 發布時間: 2015-11-06水電工日誌 #8. 家用網路設備整合, UniFi + NAS 升級之路
摘要: 安德魯在這篇文章中分享了他如何整合家用網路設備,包括使用UniFi產品和NAS進行升級的經驗。他講述了在這過程中> 學到的技術知識以及實際操作的心得。 標籤: 水電工, 有的沒有的, 敗家, UniFi 發布時間: 2022-06-10換到 BlogEngine.Net 了!
摘要: 安德魯分享了他從Community Server轉移到BlogEngine.NET的過程,包括轉移的動機和轉換過程中遇到的挑戰。 標籤: .NET, BlogEngine.NET, Community Server, 技術隨筆 發布時間: 2008-06-17BlogEngine Extension: Secure Post v1.0
摘要: 安德魯開發了一個BlogEngine的擴展,使得特定文章可以設置密碼保護,並分享了開發過程和思路。 標籤: .NET, ASP.NET, BlogEngine Extension, BlogEngine.NET, 作品集, 技術隨筆 發布時間: 2008-09-06[BlogEngine.NET] 改造工程 - 整合 FunP 推推王
摘要: 安德魯描述了如何將BlogEngine.NET和FunP推推王進行整合,以增強社交分享功能的過程。 標籤: .NET, ASP.NET, BlogEngine.NET, 有的沒的 發布時間: 2008-06-30CaseStudy: 網站重構, NGINX (REVERSE PROXY) + 文章連結轉址 (Map)
摘要: 這篇文章中,安德魯分享了他如何使用NGINX作為反向代理來重構他的網站架構,並處理大量文章連結的轉址問題。 標籤: BlogEngine.NET, Docker, Tips 發布時間: 2015-12-04FlickrProxy #1 - Overview
摘要: 安德魯介紹了他開發的FlickrProxy項目,該項目旨在解決部落格上圖片存儲和頻寬問題,通過將圖片自動上傳至> Flickr並在部落格中使用。 標籤: .NET, ASP.NET, 作品集 發布時間: 2008-05-16換新系統了!! CS 2.0 Beta 3
摘要: 安德魯分享了他將部落格系统从Community Server 1.0升级到CS 2.0 Beta 3的经验,包括遇到的问题和如何解决> 它们。 标签: 有的沒的 发布时间: 2006-02-03網站升級: CommunityServer 2007.1
摘要: 文章中,安德魯讨论了将他的网站从CommunityServer 2007升级到2007.1版本的过程,包括他采取的步骤和遇到的> 挑战。 标签: Community Server, 技術隨筆, 有的沒的, 水電工 发布时间: 2007-11-12升級到 BlogEngine.NET 1.4.5.0 了
摘要: 安德魯描述了他将部落格系统从旧版本升级到BlogEngine.NET 1.4.5.0的简便过程。 标签: BlogEngine.NET, 有的沒的 发布时间: 2008-08-29終於升級上來了…
摘要: 安德魯分享了他升级部落格系统到最新版本的经验,以及他自定义功能的重新实施。 标签: 有的沒的 发布时间: 2006-12-10搭配 CodeFormatter,網站須要配合的設定
摘要: 文章中,安德魯讨论了他如何为他的部落格集成CodeFormatter插件,并详细描述了需要进行的网站配置。 标签: .NET, 作品集, 技術隨筆 发布时间: 2008-04-04
當你有 300+ 篇文章, 涵蓋 20 年的記憶, 字數達 400 萬的內容時,整理這些資訊並不是件容易的工作,我想要快速掌握全貌,需要時我也想要深入了解特定主題的整篇文章內容。所以每當這種時候,我都在想..
“如果有 AI 幫我處理這些事就好了…”
“如果我的部落格聰明一點,可以直接跟他說我的目的,就幫我整理好內容就好了…”
“如果能替我的部落格加一點智慧…”
對,可以回收標題了 (很硬要),其實上面這段整理,就是來自 “安德魯部落格 GPTs” 整理出來的 (我才不要自打嘴巴,明明寫 RAG 的介紹,結果還自己土炮整理內容)。你可以親自試試看,或是繼續看我後面的示範。
1-2, 示範: 特定主題的彙整
換個主題,我同一個主題寫過最多篇的內容,大概就是微服務了吧。這主題涵蓋了大部分 cloud native 架構下都會碰到的問題,也有我的實做案例跟經驗分享。
於是,我再次找了 Chat GPT, 問了 安德魯的部落格 GPTs:
我要導入微服務,全面使用 api 讓我不能再像過去一樣在資料庫 join 不同資料表。有說明這主題的文章嗎?給我條列式的原則,並且列出相關文章的摘要跟連結給我。
我得到的回答:

看起來還不錯,回答的內容的確都是我文章提過的觀點沒錯,不過文字不是我寫的,是 AI 歸納整理出來的。 後面的參考連結也都正確,列的參考文章都符合我問的問題。
不過這樣還沒結束,我繼續追問:
如果都 api 化了,統計報表的問題該怎麼處理?一樣給我原則跟參考資料。參考資料請至少給我十篇

還不錯,這次我特地問了擦邊球,我沒有太多文章在聊分散式系統的報表做法,AI 就老實回答了,沒有硬是亂掰一些資訊出來塘塞…
後面接著還有幾個問答,我直接貼上對話內容了:
那麼有微服務之間維持資料一致性的作法嗎?

GPTs 回應了我摘要內容,這些內容沒錯,也是我文章內談過的沒錯。不過我留意到 GPTs 並沒有重新呼叫 API 查資料,也沒有列出相關文章連結,我就補問了一句:
有這些主題的相關文章?
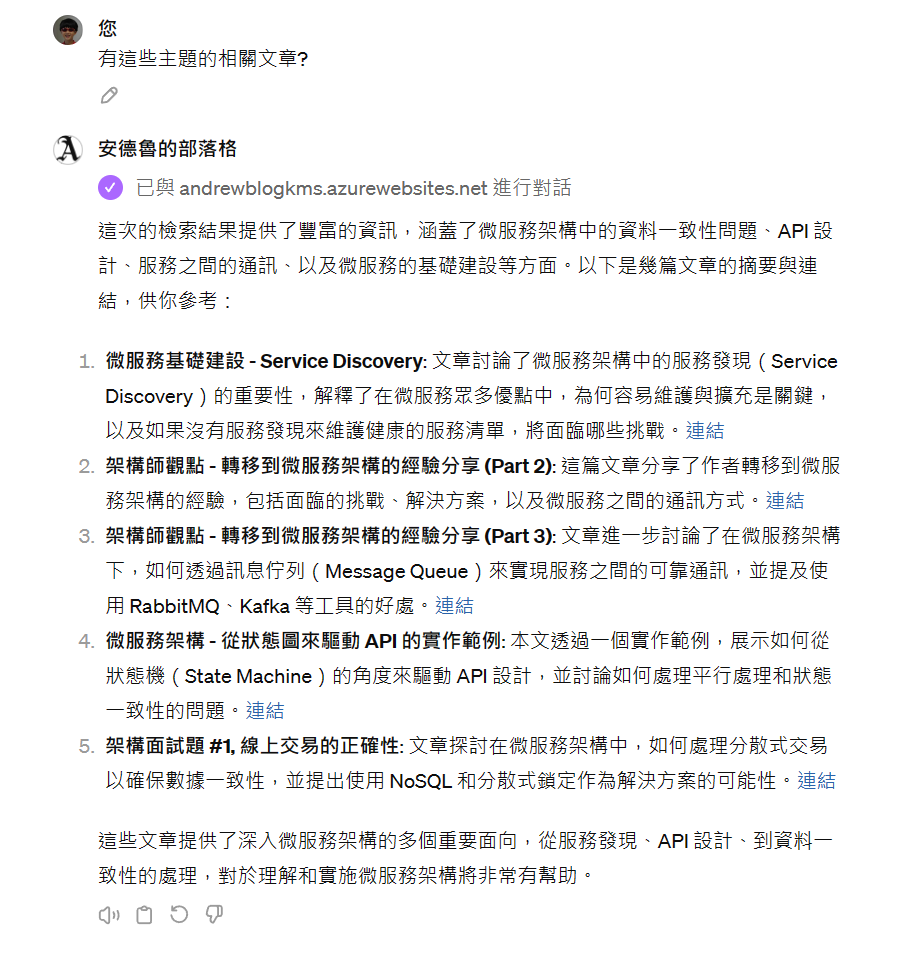
人家說的 AI 越來越懶惰了,果然是真的 XDD
接著繼續問,AI 一樣給我兩段式的回答,先給摘要,我追問後才整理文章連結給我。不夠貼心,但是內容正確。我想以後在 GPTs instruction 裡給更正確的 prompt 應該可以改善,這邊我先接受:
好,那我有多個微服務了,整合很麻煩,我想要像 azure 一樣有整套 sdk 可以簡化開發者的負擔。有微服務 api sdk 的主題說明與參考內容嗎
…
有這些主題的相關文章?


1-3, 示範: 特定經驗分享彙整
我在不少文章中分享過我的家用系統建置經驗,但是連我自己都會忘記我在哪一篇寫過什麼.. 於是,我也試試看這個案例吧,看看 GPTs 會怎麼回應我的詢問:
Home Network 下,NAS 有建議安裝那些 container / service ?

真的變懶了,追問才給文章列表:
有這些主題的相關文章?

繼續追問,把情境跟身分交代清楚,再問一次建議… 這次我學乖了,同時要求給我文章連結
家用網路環境,NAS 上架設的服務,有 web developer 用的建議方案嗎? 給我摘要說明,同時給我相關文章連結


這些查詢,還真的挖出一些我自己已經沒啥印象的文章 XDDD, 還蠻到位的,我在家裡的 labs 的確弄了這些服務,方便我測試跟開發使用。過去我是自己弄 PC,24hr 開著跑 windows server, 不過自從用了 NAS 之後就再也不自己維護了,部署方式也逐漸改成 NAS 內建,或是用 container 部署。
Demo 先到這邊,我先自己給個 comments. GPTs 要協助各位讀者快速瀏覽或是導讀我的部落格,的確做的很到位。他能精準的理解讀者的問題 (同前面幾篇聊的一樣,他有抓住語言背後的意圖),加上 RAG 也能比過去的關鍵字搜尋更精準的找出我要的內容,兩者的結合開始有不一樣的體驗了。剩下的就等使用門檻 (費用) 持續下降吧!
過程我有做些調整修正,因此沒有一開始就貼對話紀錄,而是用截圖的方式說明。這邊有來自 Chat GPT 的對談紀錄,有完整對話內容,也包含沒被我貼出來的嘗試過程。有需要的可以參考 封存對話紀錄
如果你好奇這樣的 GPTs 該怎麼設計出來,就繼續往下看,我後面的章節會說明。
破題用的 demo 就點到為止就好了。現在已經是 2024 年,Chat GPT 的威力我已經不需要多做說明,demo 到這邊大家應該已經能想像一個熟悉我 327 篇文章內容的 Chat GPT 能做多少事了。檢索、摘要彙整、問答、翻譯等應該都不是問題了。接著就直接進入主題: RAG, 以及我是怎麼實做過程。
2, 部落格檢索服務
AndrewBlogKMS
這算是我第二個自己打造的 GPTs 了,其實 GPTs 很容易就能做出來了。GPTs 允許你自訂 instructions, 同時允許你掛上能呼叫外部 API 的 Custom Action, 這麼一來就打通他的行為與外部操作的客製化能力,GPTs 就能展現出模型本身無法直接回答的問題。這次我的 PoC,最主要的環節,就是打造一個檢索服務讓 GPTs 使用,我選擇的是來自 Microsoft 的開源專案 - Kernel Memory …
其實,我用了一個很取巧的組合,我拿 GPTs 負責最終面對使用者的介面,同時讓他呼叫檢索服務,將檢索結果彙整回給我;而背後的檢索服務,則由我另外準備的 Azure App Service 來負責。而這服務背後的開發,則是以 Kernel Memory 這開源專案為基礎,把整個 RAG 的流程建立起來。
直接看怎麼整合,其實並不難,但是我還是想先聊一點 LLM 在處理資料檢索的標準做法: RAG。我刻意找了外部的課程當作參考,通常課程比較會交代背後的原理,而原廠的教材或是文件則會重視規格跟操作步驟,了解背後的原理,你才有能力做正確的選擇。
我找的是這份課程: Applied LLMs Mastery 2024
看完後你會對 LLM 的應用程式開發有正確的結構跟概念,然後再去找合適的技術,模型,框架來組合。而我只引用其中一段就好: Week 4 - Retrieval Augmented Generation,其中有張圖貫穿整個主題:
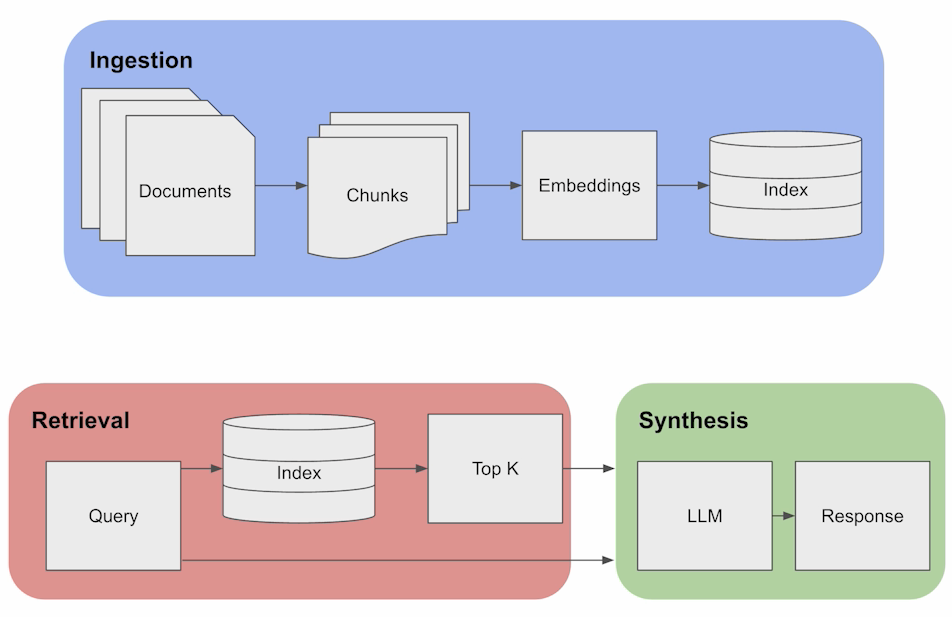
這圖講的就是 RAG 三個關鍵組件,其實也對應到我這次要做的三個部分:
The diagram above outlines the fundamental RAG pipeline, consisting of three key components:
- Ingestion:
- Documents undergo segmentation into chunks, and embeddings are generated from these > chunks, subsequently stored in an index.
- Chunks are essential for pinpointing the relevant information in response to a given > query, resembling a standard retrieval approach.
- Retrieval:
- Leveraging the index of embeddings, the system retrieves the top-k documents when a > query is received, based on the similarity of embeddings.
- Synthesis:
- Examining the chunks as contextual information, the LLM utilizes this knowledge to > formulate accurate responses.
💡Unlike previous methods for domain adaptation, it’s important to highlight that RAG > doesn’t necessitate any model training whatsoever. It can be readily applied without the > need for training when specific domain data is provided.
其實這三段,就對應到我在做的三件事,我照我說明的順序,對照這三個組件:
- Synthesis:
我用 GPTs (內建 GPT4 LLM) 來負責這段, 主要是調整 instruction 與設定 custom actions - Retrieval:
我用 Kernel Memory (Serevice) 來提供檢索的能力。雖然他也支援 Synthesis ( api: /ask ),但是這段我靠 GPTs 處理掉了,因此我只用到 Retrieval ( api: /search ) 的部分。這部分由於檢索的需要,必須依賴外部 text-embedding model - Ingestion:
我用 Kernel Memory (Serviceless) 來替我所有的文章向量化,並且建立 Index (向量資料庫),同樣是用 Kernel Memory,只是他是離線作業,並非線上運作的服務。
所以,這一章就來聊這三個主題吧,我換成好理解一點的標題,你可以把它當成:
- RAG 資料檢索的應用 (Synthesis)
- 語意的檢索 - 向量搜尋 (Retrieval)
- 建立文章向量化的資料庫 (Ingestion)
2-1, RAG 資料檢索的應用
Synthesis
回到這張圖,我把重點擺在綠色區塊 Synthesis 的部分。留意他有兩個 input: Retrieval 的結果 + Query。意思是拿著 Query 本身 (就是你問的問題),加上 Retrieval 用同樣 Query 查詢出來的結果 (先別管結果怎麼來的),讓 LLM 來加工,把它修飾成使用者能理解的回應內容。
至於實做過程,我一步一步來拆解: 不知各位在看前面的 demo 時,是否注意到這段訊息:
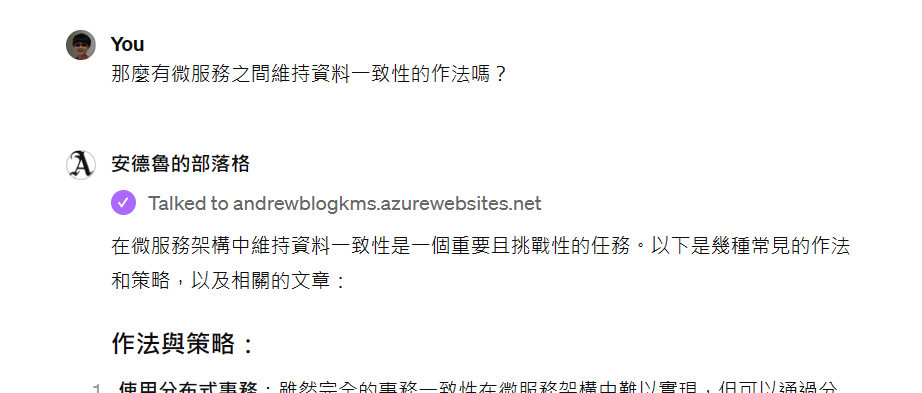
其中,看到這段 “Talked to andrewblogkms.azurewebsites.net“,就代表 GPTs 嘗試呼叫我設定好的 Custom Action ( API ), 來透過外部服務取得資訊了。點下去你可以大致看到,GPTs 帶了哪些資訊給外部 API:
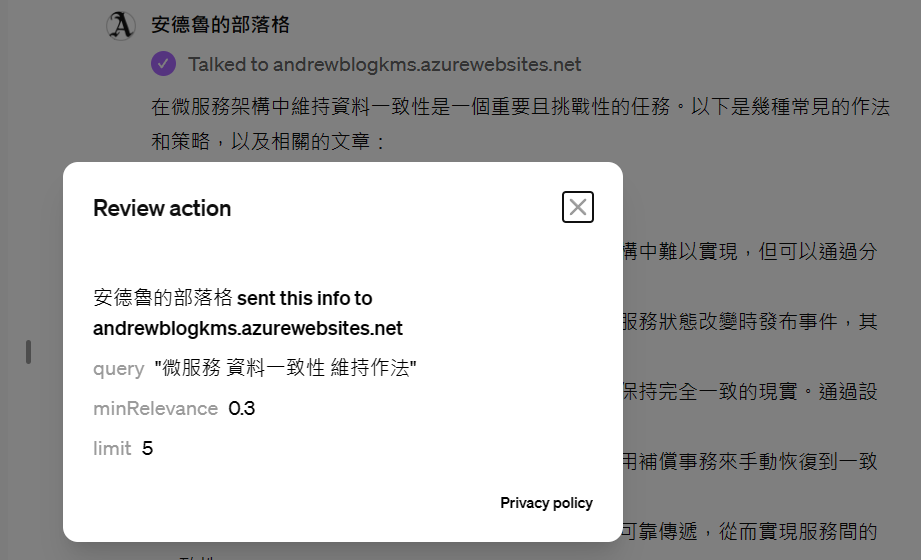
雖然這是被簡化過的內容,不是完整的 API call request payload, 但是大致能解讀出這些資訊:
- API endpoints: andrewblogkms.azurewebsites.net
- Parameters:
- query: “微服務 資料一致性 維持作法”
- minRelevance: 0.3
- limit: 5
GPTs 之所以知道這些資訊,是因為我在 GPTs 背後設置了這個 Custom Action:
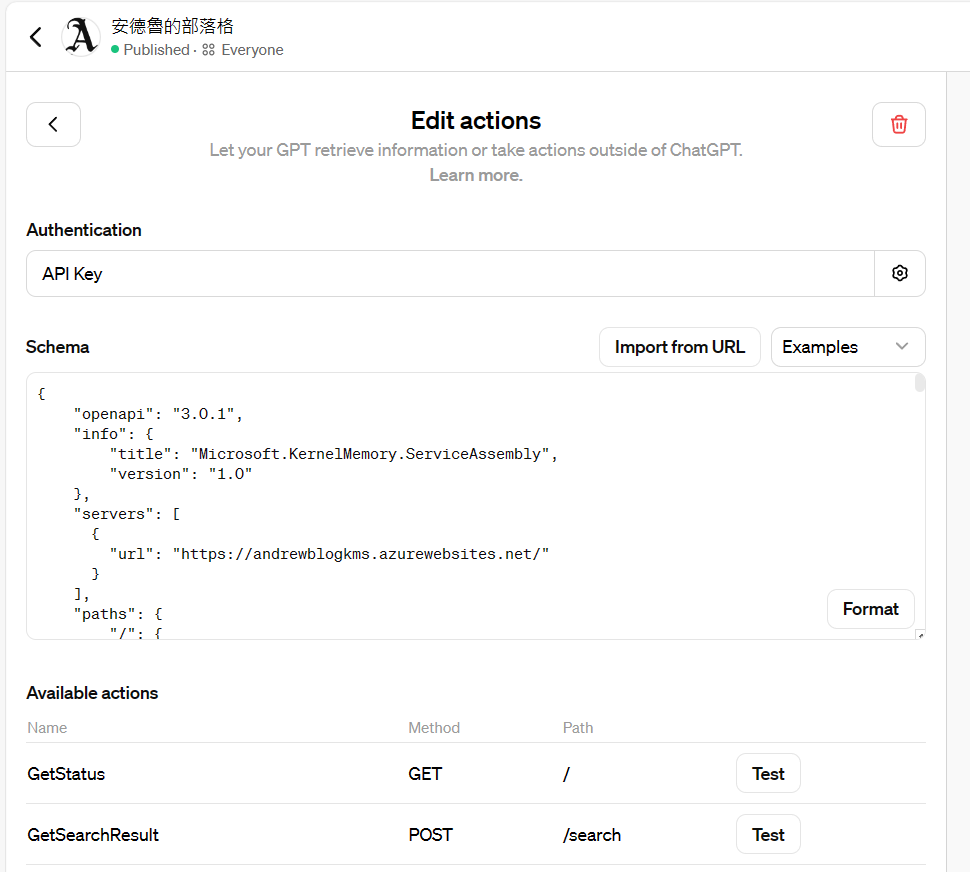
我在 Custom Action 設定畫面中,提供了 open api schema (swagger),只要你的 API 符合標準規範,就能掛進來。有了這些資訊,GPTs 就能理解呼叫你的 API 的格式了。另外,除了 spec 之外,標註在 path 與 parameters 上面的文字說明 (description) 是很重要的,因為那是 LLM 拿來判定上下文,跟理解你 API 語意很重要的資訊,你可以理解成 description 其實是說明 API spec 的 prompt ..。我用的檢索服務 swagger 長這樣:
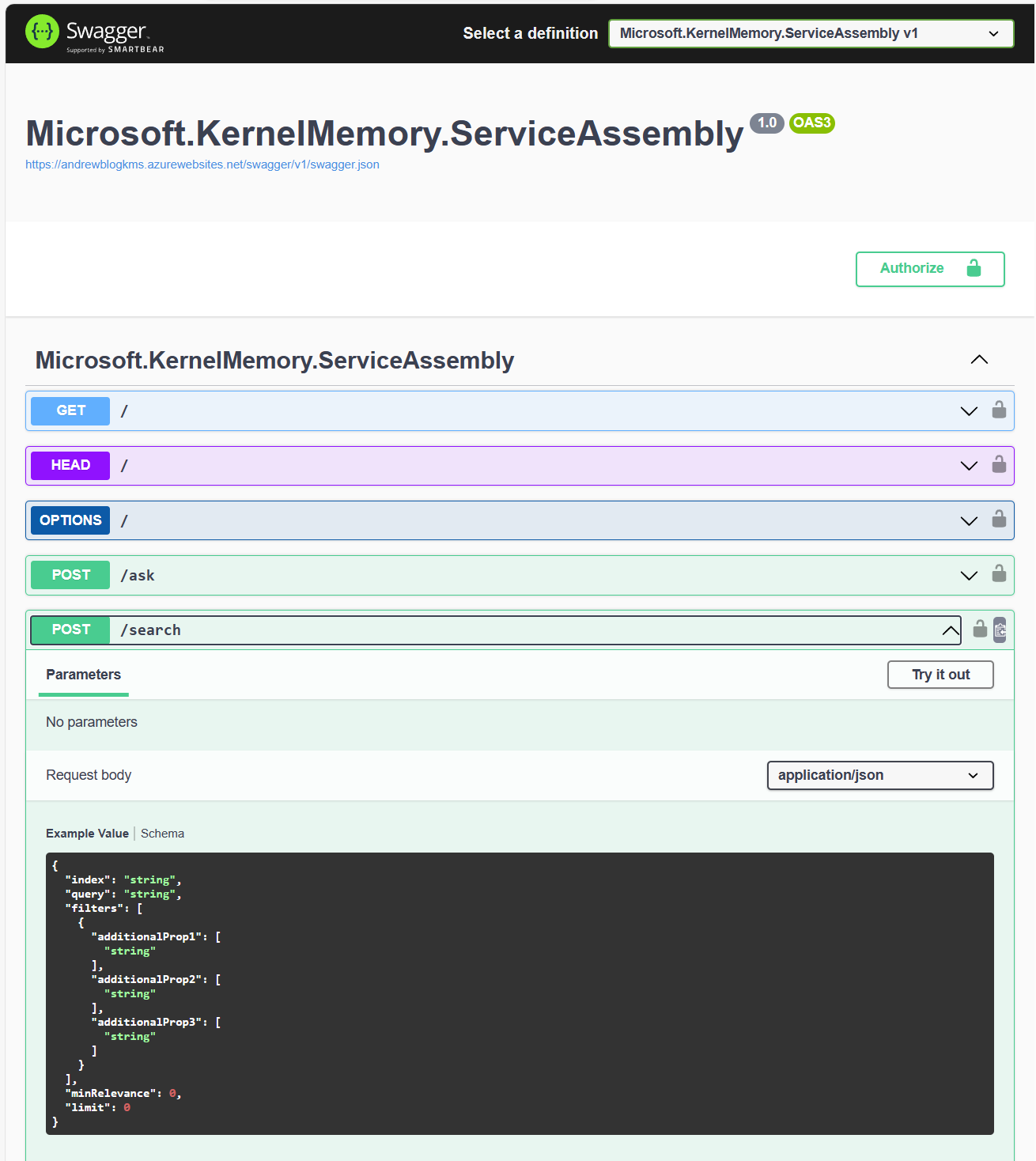
有了這些 swagger 的定義,加上 swagger 上面對每個 path, parameters 的說明,就成為告訴 GPTs 怎麼使用 API 的 prompt 了。在 GPTs 的 Function calling 機制下,AI 會自動從前後文,產生符合 API spec 的 request, 經過使用者同意後,就替使用者呼叫外部服務了。
我試著自己還原這個過程 (我無法 debug GPTs 做這些動作的過程,只能模擬),按照上面看到的資訊,我自己試著呼叫我的檢索服務:
Request: https://andrewblogkms.azurewebsites.net/search
{
"query": "微服務 資料一致性 維持作法",
"filters": [ ],
"minRelevance": 0.3,
"limit": 5
}
Response: (為了精簡,我刪除不必要的 json 片段)
{
"query": "微服務 資料一致性 維持作法",
"noResult": false,
"results": [
{
"link": "default/post-2022-04-25/0db8eaa31cb946e78d03ba825db0a624",
"index": "default",
"documentId": "post-2022-04-25",
"fileId": "0db8eaa31cb946e78d03ba825db0a624",
"sourceContentType": "text/plain",
"sourceName": "content.txt",
"partitions": [
{
"text": "微服務 API 的設計與實作,來到第二篇。\n圖片來源: https://www.freecodecamp.org/news/rest-api-best-practices-rest-endpoint-design-examples/\r\n會有這篇,其實是有感現在講架構的文章太多了, 但是每個人看了同樣的文章,\r\n最後實作出來的落差都很大啊。很多架構類的文章都是標竿大型系統的設計,不過還沒有對應經驗的人,看了這類文章是沒辦法從小規模的系統經驗,直接跨過那道鴻溝啊,所以往往有些看的多的人,在專案上拿捏不好設計的力道,不知不覺就做了過度的設計\r\n(過度可能是超出期待太多,或是超出能力範圍太多都算)\r\n。因此我在講完架構的設計概念後,我都會希望能搭配實作的驗證,PoC 也好,\r\nMVP 也好,總之能夠真正用能運作的方式,把要解決的情境用你想的架構實際推演一次。架構實作一定是複雜的,有很多工程問題要解決,因此能否在這階段盡可能的排除非必要的實作,又能達到驗證的目的,就是抽象化能力的考驗了。Do the\r\nright thing 比 do the things right 同樣重要,但是不先看清楚 right thing 的話會讓你後面的 do the thing right 功虧一簣,因此有了這篇文章,來驗證上一篇我介紹的方法: 用狀態機來驅動 API 設計。",
"relevance": 0.48848033,
"partitionNumber": 0,
"sectionNumber": 0,
"lastUpdate": "2024-02-29T15:37:06+00:00",
"tags": {
"user-tags": [
"系列文章",
"架構師的修練",
"microservices"
],
"categories": [
"系列文章: 微服務架構"
],
"post-url": [
"https://columns.chicken-house.net/2022/04/25/microservices16-api-implement/"
],
"post-date": [
"2022-04-25"
],
"post-title": [
"微服務架構 - 從狀態圖來驅動 API 的實作範例"
],
"post-content-type": []
}
},
{
"text": "然而,這同時間還得面對其他棘手的問題,例如平行處理一定會碰到的 racing condition, 如果同時有兩個 client 在同一瞬間要做狀態轉移,誰會成功? 總不能兩者都成功吧! 那麼這些機制該怎麼處理?\r\n這邊不管誰負責,DB 也好,AP 也好,或是 Core Library 負責也好,總是要有人負責擔任協調者,只能讓其中一個 client\r\n成功執行。其他要明確接受到錯誤訊息,並且阻擋他執行到一半。這部分沒做好,流量一大,你會發現有很多幽靈的資訊,狀態也許正確,但是關聯的資料錯誤,這些問題越晚越難追查,到最後就變成一個不夠可靠的系統.\r\n.. 這種程度的服務是無法架構出具規模的微服務架構的..\r\n一旦確定能執行該 action 並且執行成功後,後面的就單純一些了 (我沒說容易喔)。後面就剩下要 \"保證\" 後續的處理一定會被觸發就好,這邊最典型的就是觸發 \"狀態已改變\" 的事件通知。我這邊就用 C# 的 event 機制來代替了。C# 用 event handler 來代表,實際上如果你有分散式的需求,應該被改寫成發送訊息到 message queue,\r\n並且在 queue 的另一端安排對應的 worker 來接收並且處理訊息。 想到這些難題,頭就痛起來了 XDD, 不過越頭痛的問題,",
"relevance": 0.48434806,
"partitionNumber": 49,
"sectionNumber": 0,
"lastUpdate": "2024-02-29T15:37:06+00:00",
"tags": {
"user-tags": [
"系列文章",
"架構師的修練",
"microservices"
],
"categories": [
"系列文章: 微服務架構"
],
"post-url": [
"https://columns.chicken-house.net/2022/04/25/microservices16-api-implement/"
],
"post-date": [
"2022-04-25"
],
"post-title": [
"微服務架構 - 從狀態圖來驅動 API 的實作範例"
],
"post-content-type": []
}
}
]
},
{ ... } // 略過後面三筆
]
}
當我的檢索服務傳回這樣內容後,GPTs 一樣會依照 API schema 的描述,理解這堆 json 的意義後,再次消化這些內容,整理成我要的答案,回應在 Chat 的介面上給使用者。
根據過去使用 Chat GPT 的經驗,我自己腦補一下這段動作該怎麼下 prompt,首先我給了 Chat GPT 這段任務設定:
我會用下列結構整理我的問題跟參考資訊,請你彙整後給我回答,並且在回答的內容附上來源網址 (post-url, 請用 hyperlink 的方式呈現)。
理解後回我 OK,我會開始給你問題內容
接著,用一個簡單的樣板,把剛才 API 查到的資訊貼進去 (若效果不錯,以後就可以寫 code 來套了)。底下貼的這段是套了樣板之後的結果:
## ask
那麼有微服務之間維持資料一致性的作法嗎?
## facts
- relevance: 48.84%
- post-url: https://columns.chicken-house.net/2022/04/25/microservices16-api-implement/
微服務 API 的設計與實作,來到第二篇。\n圖片來源: https://www.freecodecamp.org/news/rest-api-best-practices-rest-endpoint-design-examples/\r\n會有這篇,其實是有感現在講架構的文章太多了, 但是每個人看了同樣的文章,\r\n最後實作出來的落差都很大啊。很多架構類的文章都是標竿大型系統的設計,不過還沒有對應經驗的人,看了這類文章是沒辦法從小規模的系統經驗,直接跨過那道鴻溝啊,所以往往有些看的多的人,在專案上拿捏不好設計的力道,不知不覺就做了過度的設計\r\n(過度可能是超出期待太多,或是超出能力範圍太多都算)\r\n。因此我在講完架構的設計概念後,我都會希望能搭配實作的驗證,PoC 也好,\r\nMVP 也好,總之能夠真正用能運作的方式,把要解決的情境用你想的架構實際推演一次。架構實作一定是複雜的,有很多工程問題要解決,因此能否在這階段盡可能的排除非必要的實作,又能達到驗證的目的,就是抽象化能力的考驗了。Do the\r\nright thing 比 do the things right 同樣重要,但是不先看清楚 right thing 的話會讓你後面的 do the thing right 功虧一簣,因此有了這篇文章,來驗證上一篇我介紹的方法: 用狀態機來驅動 API 設計。
## facts
- relevance: 48.43%
- post-url: https://columns.chicken-house.net/2022/04/25/microservices16-api-implement/
然而,這同時間還得面對其他棘手的問題,例如平行處理一定會碰到的 racing condition, 如果同時有兩個 client 在同一瞬間要做狀態轉移,誰會成功? 總不能兩者都成功吧! 那麼這些機制該怎麼處理?\r\n這邊不管誰負責,DB 也好,AP 也好,或是 Core Library 負責也好,總是要有人負責擔任協調者,只能讓其中一個 client\r\n成功執行。其他要明確接受到錯誤訊息,並且阻擋他執行到一半。這部分沒做好,流量一大,你會發現有很多幽靈的資訊,狀態也許正確,但是關聯的資料錯誤,這些問題越晚越難追查,到最後就變成一個不夠可靠的系統.\r\n.. 這種程度的服務是無法架構出具規模的微服務架構的..\r\n一旦確定能執行該 action 並且執行成功後,後面的就單純一些了 (我沒說容易喔)。後面就剩下要 \"保證\" 後續的處理一定會被觸發就好,這邊最典型的就是觸發 \"狀態已改變\" 的事件通知。我這邊就用 C# 的 event 機制來代替了。C# 用 event handler 來代表,實際上如果你有分散式的需求,應該被改寫成發送訊息到 message queue,\r\n並且在 queue 的另一端安排對應的 worker 來接收並且處理訊息。 想到這些難題,頭就痛起來了 XDD, 不過越頭痛的問題,
## answer
這樣的 prompt, 貼到 Chat GPT 後可以得到這樣的回應 (如下),基本上跟我前面示範的 GPTs demo 已經有 87% 像了:

到這邊,我盡力還原 GPTs 背後做的事情了。看了很多教學,都有講到 Synthesis 的做法,我這算是自己土炮,用手邊的工具,把分解動作嘗試了一次,做過一次這印象就會刻在你腦袋裡了。
我特地補充這段的目的,是希望大家知道 GPTs (或是: LLM) 是怎樣把這些內容產生出來的。這很重要,理解 AI 怎麼運用知識庫的過程,我後面的內容才聊得下去啊 XDD, 記好這些過程, 未來你的 AI 應用, 不一定會是在 Chat GPT 這平台上面開發,如果你了解這過程,那你就有能力透過 Semantic Kernel,自己完成相同的功能。
我知道 GPTs 絕對不會是唯一一個能完成 Synthesis 的工具,真正難以自己開發的其實是 LLM,但是 GPTs 並不是,有更多的機會是你需要自己開發應用的介面,清楚這些過程,你開發的時候會更得心應手。
最後補上課程的內容。在說明 RAG 的時候,其實有這麼一段:
Althought RAG seems to be a very straightforward way to integrate LLMs with knowledge, there are still the below mentioned open research and application challenges with RAG.
我想在這裡擺這段,目的是提醒各位開發者,往往我們在鑽研技術時,會過於執著 “how to”,但是忘了 “why”,這時中立一點的內容,課程,研究報告等,反而是個很好的平衡點,可以提醒我原廠或是工具的角度提供的文件或教學,是否有些偏頗或是遺漏? 架構師的任務往往都是做出正確的選擇,沒有平衡報導的話,面對不熟悉的領域很容易被廠商的官方教材牽著跑.. XDD
所以,我順完整個流程 ( 加上示範 ) 後,還是補一下這段,提醒看到這邊的朋友們,我的作法不是標準 100% 完美,使用時仍然要思考一下,是否有更合適的做法可以改善?
原文提了 RAG 有這幾點挑戰,我列項目就好,內文大家可以自己看:
RAG Challenges Although RAG seems to be a very straightforward way to integrate LLMs with knowledge, there are still the below mentioned open research and application challenges with RAG.
- Data Ingestion Complexity
- Efficient Embedding
- Vector Database Considerations
- Fine-Tuning and Generalization
- Hybrid Parametric and Non-Parametric Memory
- Knowledge Update Mechanisms
2-2, 語意的檢索 - 向量搜尋
Retrieval
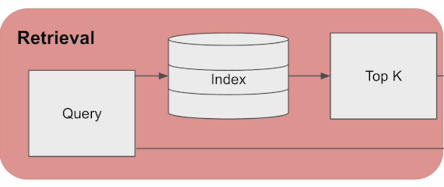
這張圖表達了 Retrieval, 若把他的步驟再分解:
- User Query: 由使用者提供給 LLM 的自然語言查詢
- Query Conversion: 將 (1) 轉為向量 (必須依靠 embedding model)
- Vector Comparison: 所有語意的操作都在向量空間內進行。拿著 (2) 在資料庫內找出相近的資料
- Top-K Retrieval: 除了向量比較之外,也附加其他過濾條件 (例如標籤,分類等等),最後收整出 Top-K 筆符合的資料
- Data Retrieval: 將 (4) 的清單,還原當初拿來向量化的原始內容
經過這一連串步驟得到的 (5), 才是圖上的 [Top-K] 檢索結果。這結果連同 Query 一起交給 LLM,就是前面那段 2-1, GPTs 怎麼使用我的 API 來完成部落格的檢索。
從這裡開始,就必須搞懂 embedding 這東西了。我真正對整個流程恍然大悟時,最關鍵的部分就是我搞懂 embedding 跟 vector 向量之間的關係。這邊我花點篇幅聊一下 embedding 在幹嘛。
2-2-1, Text Embedding
Embedding, 這是檢索的核心, 檢索的目的是先找到語意相近的片段資訊,而要怎麼明確的表達 “語意” 這種概念? 就是將各種領域變成維度,把每一段資料都在這些維度組成的空間,標示一個座標,來表達這段資料在各個領域上的相關性有多高。這座標就是所謂的 “向量”。而 Embedding, 是指把一段文字轉成向量的過程。為何稱作 “embedding” ? 要花點想像力。你就先想成一個 N 度空間,裡面所有的資訊都變成一個 “向量”,而文字轉成向量的過程,就好像把資訊 “embed” 到那個空間內,因此用這抽象的字,來形容這個過程。
“空間”,代表的就是語意,我先前參加 Microsoft 的活動,有一份簡報,裡面的說明是我看過最好理解的,我就借來用一下。原始出處在這邊…
Embedding, 簡單的說就是把所有資訊都轉成向量, 而這向量的意義,就是代表你這段資訊跟哪些領域相關。這張圖蠻有意思的,我貼上來:
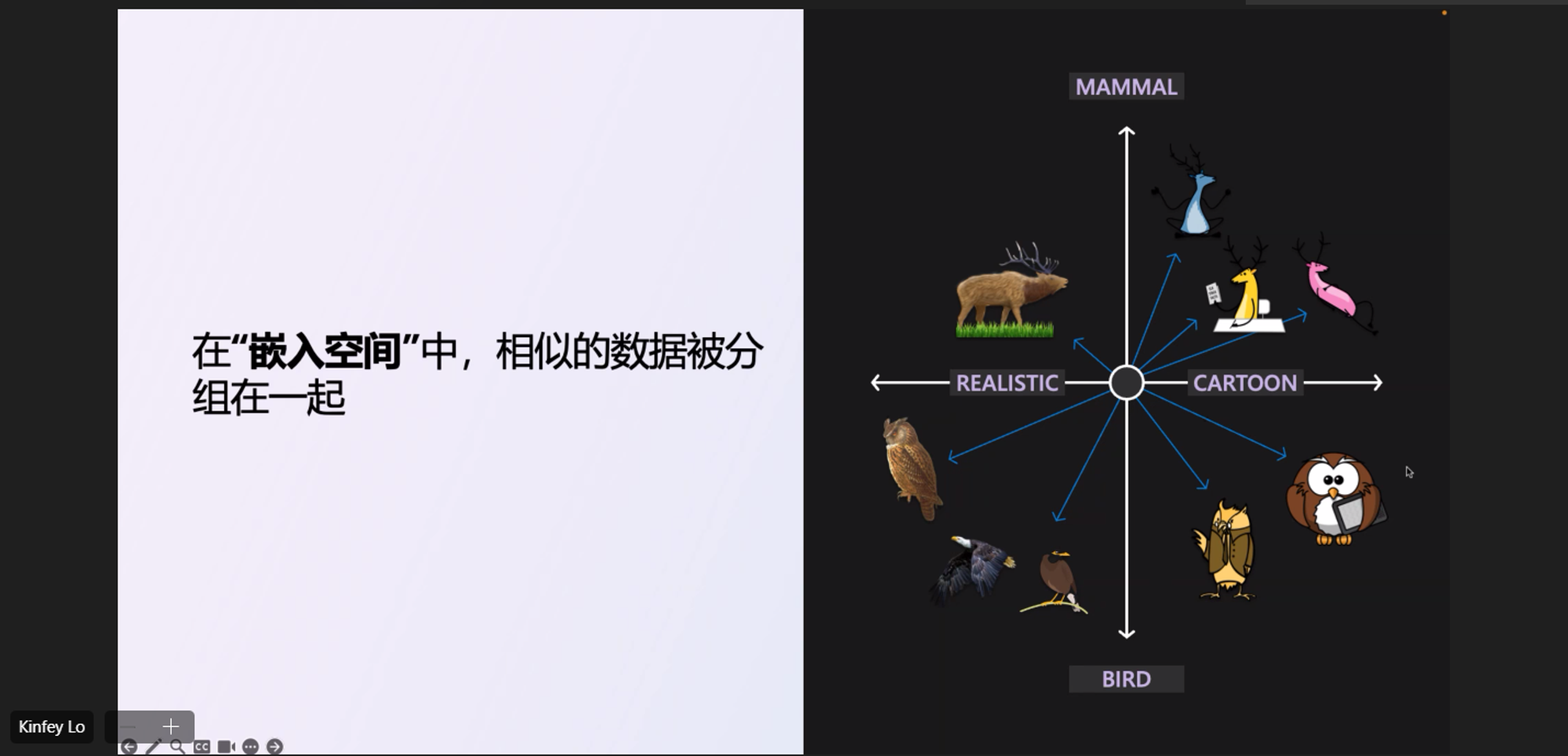
如果我用兩個維度,一個維度是 風格 (寫實 Realistic / 卡通 cartoon ),另一個維度是物種 (哺乳 mammal / 鳥類 bird), 這兩個維度就形成一個二度空間。而圖上的各種圖片,被向量化就是在這空間上用一個最能表達這圖片的向量來標記。
了解向量化的做法之後,接著就是工程的處理了。將你的內容分割成適當的段落,個別轉成向量:
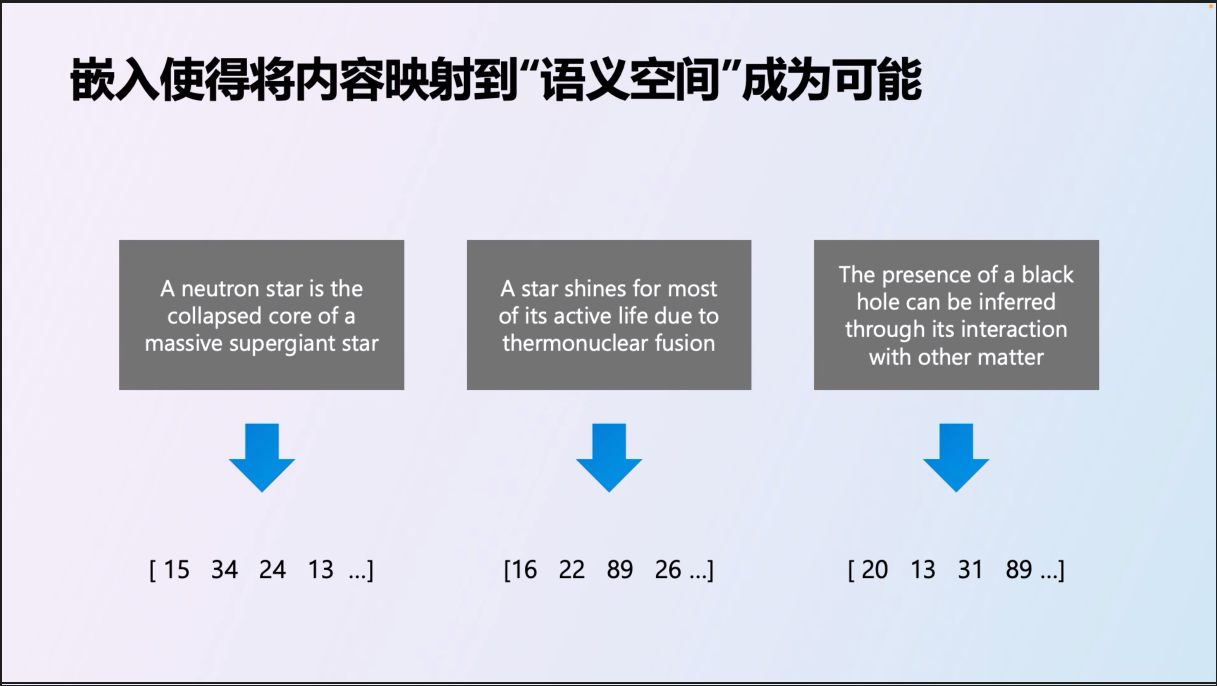
這些資料都向量化之後,如果你有支援的資料庫 (或是數量不大,自己 coding 處理也行, 這次的 GPTs 我走這條路),你只要把問題也轉成向量,挑出最相近的內容就很簡單了:
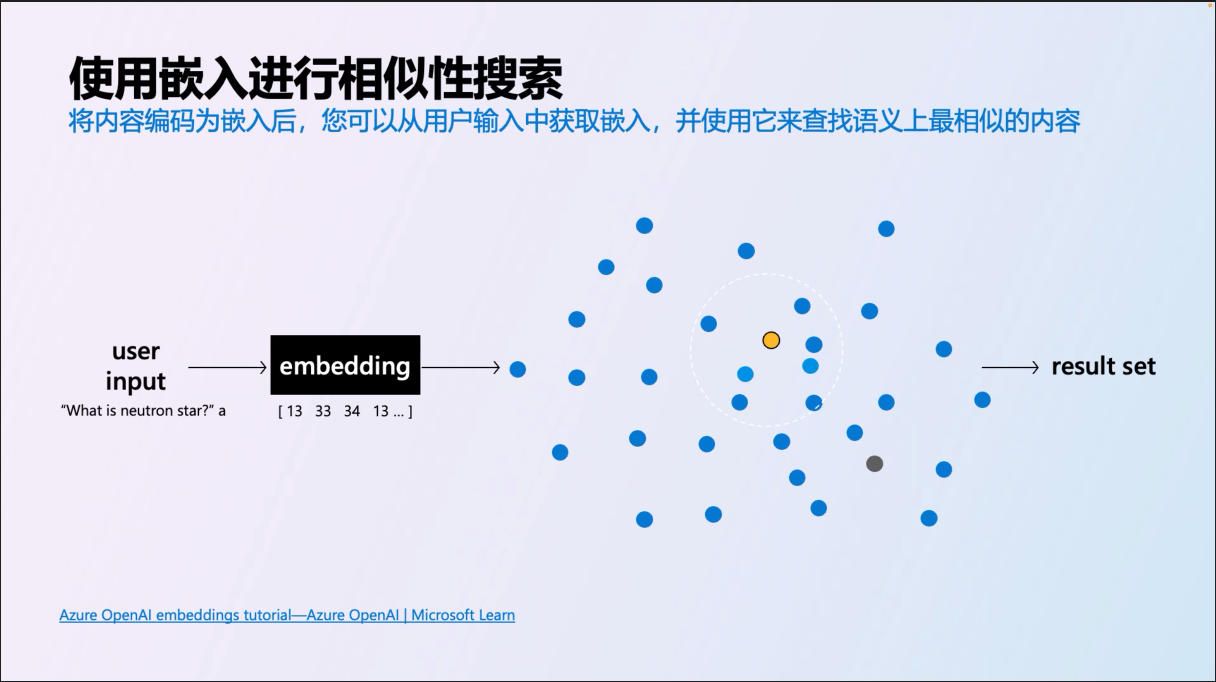
接著說明一下搜尋的原理:
當你標記完成後,所謂的 “相似度”,就是兩個向量之間有多接近,有幾種演算法,一種是座標之間的距離 (distance);一種是向量之間的夾角 (cosine similarity);一種是向量的內積 (product), 不過,聊這個又踩到我不擅長的領域了,我直接走捷徑,我用最常聽到的 cosine 來處理,三角函數的 cos 結果越接近 1.0 就代表夾角越小,所以需要做的就是不斷地計算向量之間的 cos 值就可以了。
我打算先把整個流程跑完,把架構定案下來;將來需要我再來個別抽換演算法就行。不過千萬別過度簡化了,夾角最大 (例如: 180 度) 不代表 “最不相關”,他們可能是同個維度上的反方向,應該是 “距離最遠” 才對。在向量上真正的 “不相關” 應該是垂直 (正交) 的向量才對,cosine 值是 0,這才是意義上的不相關,完全無法比較,不在同一個次元上的資訊。
講到這個,害我想到以前看過的一部動畫,某個阿宅有這麼一句名言 XDDD:
如果每一筆文字資料都能算出一個向量,把這些對應過程中的做法,用大量資料訓練而成的模型,簡化後面的轉換,這個模型就是 text-embedding model 了。標記語意的向量空間,不可能只有這種二維空間。稍後我示範的案例,我用 OpenAI 的 text-embedding-3-large model, 就可以支援到 3072 dimensions. 不過,每個維度代表什麼意義並沒有被定義,不同模型之間的維度也互不相容… 你必須全部都用一樣的 text-embedding model 才行。

2-2-2, Retrieval
了解了 embedding 是什麼,後面就簡單得多了。
在空間內已經有所有內容的向量了,那麼要找出你要的 “相近” 內容,很簡單,只要把你的問題 (query) 也轉成對應的向量,並且搜尋出與 query 最接近的 top-k 筆資料就行了,這就是 retrieval 的基本原理。
前面拆解過的五個步驟,我再貼一次:
- User Query: 由使用者提供給 LLM 的自然語言查詢
- Query Conversion: 將 (1) 轉為向量 (必須依靠 embedding model)
- Vector Comparison: 所有語意的操作都在向量空間內進行。拿著 (2) 在資料庫內找出相近的資料
- Top-K Retrieval: 除了向量比較之外,也附加其他過濾條件 (例如標籤,分類等等),最後收整出 Top-K 筆符合的資料
- Data Retrieval: 將 (4) 的清單,還原當初拿來向量化的原始內容
中間,牽扯了 Index 向量資料庫的操作,這我下一段再談,試想一下,如果這一切要被 API 化,其實很簡單啊,API 的 input 就只有 query 而已,output 就是 top-k result 而已。而這段我本來想要自己寫的 code, 也找了現成的 kernel-memory 開源專案來替代。我再列一次 kernel-memory 提供的 API spec (我已經刪掉我不需要的部分了,只留下 retrieval 的部分):
Swagger UI: https://andrewblogkms.azurewebsites.net/swagger/index.html
這 API spec 中的 “/search”, 代表的就是 Retrieval 的動作。對應流程上的 “query”, 不得不說 microsoft 的規格開的真不錯,理論跟實際都對應的很好,名詞一字都不差。雖然前面貼過了,我就再貼一次 /search 這 API 的範例 request / response:
我如果在 GPTs 用口語問它:
告訴我 microservice 架構下,多個服務之間如何維持資料一致性的作法?
GPTs 理解我的問題,與理解 Kernel Memory 提供的 API 規格後,會自己組出 /search API 需要的 query:
微服務 資料一致性 維持作法
然後你按下同意後,GPTs 就會發出這段 API request:
Request: https://andrewblogkms.azurewebsites.net/search
{
"query": "微服務 資料一致性 維持作法",
"filters": [ ],
"minRelevance": 0.3,
"limit": 5
}
Response: (為了精簡,我刪除不必要的 json 片段)
{
"query": "微服務 資料一致性 維持作法",
"noResult": false,
"results": [
{
"link": "default/post-2022-04-25/0db8eaa31cb946e78d03ba825db0a624",
"index": "default",
"documentId": "post-2022-04-25",
"fileId": "0db8eaa31cb946e78d03ba825db0a624",
"sourceContentType": "text/plain",
"sourceName": "content.txt",
"partitions": [
{
"text": "微服務 API 的設計與實作,來到第二篇。\n圖片來源: https://www.freecodecamp.org/news/rest-api-best-practices-rest-endpoint-design-examples/\r\n會有這篇,其實是有感現在講架構的文章太多了, 但是每個人看了同樣的文章,\r\n最後實作出來的落差都很大啊。很多架構類的文章都是標竿大型系統的設計,不過還沒有對應經驗的人,看了這類文章是沒辦法從小規模的系統經驗,直接跨過那道鴻溝啊,所以往往有些看的多的人,在專案上拿捏不好設計的力道,不知不覺就做了過度的設計\r\n(過度可能是超出期待太多,或是超出能力範圍太多都算)\r\n。因此我在講完架構的設計概念後,我都會希望能搭配實作的驗證,PoC 也好,\r\nMVP 也好,總之能夠真正用能運作的方式,把要解決的情境用你想的架構實際推演一次。架構實作一定是複雜的,有很多工程問題要解決,因此能否在這階段盡可能的排除非必要的實作,又能達到驗證的目的,就是抽象化能力的考驗了。Do the\r\nright thing 比 do the things right 同樣重要,但是不先看清楚 right thing 的話會讓你後面的 do the thing right 功虧一簣,因此有了這篇文章,來驗證上一篇我介紹的方法: 用狀態機來驅動 API 設計。",
"relevance": 0.48848033,
"partitionNumber": 0,
"sectionNumber": 0,
"lastUpdate": "2024-02-29T15:37:06+00:00",
"tags": {
"user-tags": [
"系列文章",
"架構師的修練",
"microservices"
],
"categories": [
"系列文章: 微服務架構"
],
"post-url": [
"https://columns.chicken-house.net/2022/04/25/microservices16-api-implement/"
],
"post-date": [
"2022-04-25"
],
"post-title": [
"微服務架構 - 從狀態圖來驅動 API 的實作範例"
],
"post-content-type": []
}
}
]
},
{ ... } // 我只留第一筆,後面略過
]
}
就結構上來說,這個 API ( /search ) 就很精準地完成了 retrieval 的要求,輸入 query 與附帶條件,輸出符合條件的結果。除了有用上 text-embedding model 來讓語意搜尋更精準之外,基本上這跟一般搜尋引擎提供的介面沒兩樣,就是條件跟符合結果而已。
雖然我這個 PoC 是靠 GPTs 來做最後結果彙整,但是其實 Kernel Memory 也內建了同樣的能力,我自己額外掛上了 GPT4 model, 改用 /ask 這個 API。中間不再需要 GPTs, 因此 request 也變精簡了, 直接是 “問題” (question) 而不是 “查詢” (query), 而期待的回應也是 answer, 而不是 result (雖然他還是會附上就是了)。
Request: https://andrewblogkms.azurewebsites.net/ask
{
"question": "告訴我 microservice 架構下,多個服務之間如何維持資料一致性的作法?",
"filters": [],
"minRelevance": 0.3
}
得到的 response:
{
"question": "告訴我 microservice 架構下,多個服務之間如何維持資料一致性的作法?",
"noResult": false,
"text": "在微服務架構下,多個服務之間維持資料一致性的作法可以有多種方式。以下是一些常見的作法:\n\n1. 使用分散式交易控制(Distributed Transaction Control):這是一種傳統的作法,可以使用兩階段提交(Two-Phase Commit)或是三階段提交(Three-Phase Commit)等協議來確保多個服務之間的交易一致性。這種作法需要一個協調者(Coordinator)來協調各個參與者(Participant)的操作,確保所有參與者都能成功執行或是回滾交易。\n\n2. 使用事件驅動架構(Event-Driven Architecture):這種作法將資料的變更以事件(Event)的形式發布出去,其他服務可以訂閱(Subscribe)這些事件並做出相應的處理。這樣可以確保多個服務之間的資料一",
"relevantSources": [
// 略, 結構同 search result, 會列出符合的 chunk 清單
]
}
我追查過背後的 source code, 基本上跟前面談的 RAG 流程都一樣。只不過我沒辦法看 GPTs 背後的做法,也許在 prompt 的調整上還有些差別,也許 GPTs 對於 chat 介面的上下文還有做額外的處理,這些無從比較。但是同樣的模型,看的出來 ask API 也能得到不錯的效果。你如果有些應用無法依賴 Chat GPT 介面的話,這倒是個好選擇。
只是,留意效能跟成本的問題。你用 GPTs 當作介面的話,LLM 部分的費用,實際上是訂閱 Chat GPT Plus 的用戶自己支付的,每個人都有固定的額度 (每 3 小時 40 句),而呼叫 /ask API 的話,是服務提供者 (這案例就是我) 要準備 Azure OpenAI 的 APIKEY, 費用是算在我頭上的。上面這樣的問答,大致上就花掉 15000 input tokens … (主要花在檢索結果要丟給 GPT4 產生回答)
如果用現在的價格計算,GPT4 的 input token 費用是 $10.00 / 1M tokens, 換算 15000 tokens 要花掉 $0.15 美金,相當台幣 $5 左右..
2-2-3, Start Coding
由於我原本真的有打算自己刻這段 code 的,因此除了列出 API spec 之外,我還是忍不住挖了 source code 出來看 ( Open Source 萬歲 ),畢竟這專案除了提供 service mode 讓你呼叫 Http API 之外,也提供 serverless mode 可以在你的 code 內直接呼叫。看一下 serverless mode 可以使用的介面怎麼定義的:
source: https://github.com/microsoft/kernel-memory/blob/main/service/Core/MemoryServerless.cs
namespace Microsoft.KernelMemory;
/// <summary>
/// Memory client to upload files and search for answers, without depending
/// on a web service. By design this class is hardcoded to use
/// <see cref="InProcessPipelineOrchestrator"/>, hence the name "Serverless".
/// The class accesses directly storage, vectors and AI.
/// </summary>
public class MemoryServerless : IKernelMemory
{
// 略過其他 methods
public Task<SearchResult> SearchAsync(
string query,
string? index = null,
MemoryFilter? filter = null,
ICollection<MemoryFilter>? filters = null,
double minRelevance = 0,
int limit = -1,
CancellationToken cancellationToken = default) { ... }
public Task<MemoryAnswer> AskAsync(
string question,
string? index = null,
MemoryFilter? filter = null,
ICollection<MemoryFilter>? filters = null,
double minRelevance = 0,
CancellationToken cancellationToken = default) { ... }
}
}
重要的 interface 我也列一下 (移除不必要的 comments, attribute, implementions, 只保留 public 的部分):
namespace Microsoft.KernelMemory;
public class SearchResult
{
public string Query { get; set; } = string.Empty;
public bool NoResult { get { ... }, private set; }
// List of the relevant sources used to produce the answer. Key = Document ID Value
// = List of partitions used from the document.
public List<Citation> Results { get; set; } = new List<Citation>();
}
public class MemoryAnswer
{
/// Client question.
public string Question { get; set; } = string.Empty;
public bool NoResult { get; set; } = true;
/// Content of the answer.
public string? NoResultReason { get; set; }
/// Content of the answer.
public string Result { get; set; } = string.Empty;
/// List of the relevant sources used to produce the answer.
/// Key = Document ID
/// Value = List of partitions used from the document.
public List<Citation> RelevantSources { get; set; } = new();
}
public class Citation
{
public string Link { get; set; } = string.Empty;
public string Index { get; set; } = string.Empty;
public string DocumentId { get; set; } = string.Empty;
public string FileId { get; set; } = string.Empty;
public string SourceContentType { get; set; } = string.Empty;
public string SourceName { get; set; } = string.Empty;
/// URL of the source, used for web pages and external data
public string? SourceUrl { get; set; } = null;
/// List of chunks/blocks of text used.
public List<Partition> Partitions { get; set; } = new();
public class Partition
{
/// Content of the document partition, aka chunk/block of text.
public string Text { get; set; } = string.Empty;
/// Relevance of this partition against the given query.
/// Value usually is between 0 and 1, when using cosine similarity.
public float Relevance { get; set; } = 0;
/// Partition number, zero based
public int PartitionNumber { get; set; } = 0;
/// Text page number / Audio segment number / Video scene number
public int SectionNumber { get; set; } = 0;
/// Timestamp about the file/text partition.
public DateTimeOffset LastUpdate { get; set; } = DateTimeOffset.MinValue;
/// List of document tags
public TagCollection Tags { get { ... } set { ... } }
}
}
public class MemoryFilter : TagCollection
{
public bool IsEmpty() { ... }
public MemoryFilter ByTag(string name, string value) { ... }
public MemoryFilter ByDocument(string docId) { ... }
public IEnumerable<KeyValuePair<string, string?>> GetFilters() { ... }
}
有興趣的可以一路往下追 source code, Kernel Memory 的 code 寫得很漂亮, code 讀起來很舒服的, 我直接講結論, 他背後的 code 完全就是使用 Microsoft Semantic Kernel 來寫的,並且都與我參考的課程: Applied LLMs Mastery 2024 介紹的 RAG 流程說明都一致。
背後用到 Semantic Kernel, 並且你必須在 configuration 的時候指定兩個語言模型:
- EmbeddingGeneration
- ChatCompletion
我自己在 Azure 部署了這兩個模型來使用:
- text-embedding-3-large
- GPT4
有趣的是 Kernel Memory 提供了很大的應用彈性。前面我花了不少篇幅在介紹 RAG, 課程中的流程圖也把 Retrieval / Synthesis 這兩大區塊區隔出來。而我的組合是拿 Chat GPT 當前端,因此我的組合是這樣:
- Chat GPT: 負責 Synthesis
- Kernel Memory: 負責 Retrieval ( API endpoint: /search )
不過,你願意的話,也可以讓 Kernel Memory 統包.. 只要你把 API 改成 /ask 就好了。他的背後會叫用 ChatCompletion 的服務來替你完成 Synthesis + Retrieval
官方的 github repo 也提供了十幾個 example code, 我貼一段示範 serverless 的 example code:
問: E = MC^2 是什麼意思?
Console.WriteLine("\n====================================\n");
// Question without filters
var question = "What's E = m*c^2?";
Console.WriteLine($"Question: {question}");
var answer = await memory.AskAsync(question, minRelevance: 0.50);
Console.WriteLine($"\nAnswer: {answer.Result}");
Console.WriteLine("\n====================================\n");
會問這問題,是因為這段 example code 前面已經先建立 (Ingestion) 了這段文字進去:
// Uploading some text, without using files. Hold a copy of the ID to delete it later.
Console.WriteLine("Uploading text about E=mc^2");
var docId = await memory.ImportTextAsync("""
In physics, mass–energy equivalence is the relationship between mass and energy
in a system's rest frame, where the two quantities differ only by a multiplicative
constant and the units of measurement. The principle is described by the physicist
Albert Einstein's formula: E = m*c^2
""");
這問題(Question) 與這段文字,用 text-embedding-003 large 模型來做向量比對,最後算出來的相關性是 64.1% (就是問題向量跟內容向量的 cos 值為 0.641),檢索出來符合的結果只有這一筆。
於是, 我繼續追 code, 最後 .AskAsync( ) 會由 retriveal 結果, 組出這段 prompt, 交給我指定的 LLM 模型 (我用的是 GPT4 preview 1106):
Facts:
==== [File:content.txt;Relevance:64.1%]:
In physics, mass–energy equivalence is the relationship between mass and energy in a system's rest frame, where the two quantities differ only by a multiplicative constant and the units of measurement. The principle is described by the physicist Albert Einstein's formula: E = m*c^2
======
Given only the facts above, provide a comprehensive/detailed answer.
You don't know where the knowledge comes from, just answer.
If you don't have sufficient information, reply with 'INFO NOT FOUND'.
Question: What's E = m*c^2?
Answer:
很標準的 prompt engineering 寫法。Facts 段落代表檢所的結果 (事實),中間是給 system 的指示 (instruction),告訴 LLM 回應問題的原則
後面附上了原始的問題 (Question),然後留了一個空白的 Answer 要讓 LLM 來回答..
這樣的內容,用我指定的 LLM 模型 (GPT4),得到了這樣的回應:
E = m*c^2 is the equation representing the principle of mass-energy equivalence, which was formulated by the physicist Albert Einstein. This equation states that energy (E) and mass (m) are interchangeable; they are different forms of the same thing. In this equation, c represents the speed of light in a vacuum, which is approximately 299,792,458 meters per second (m/s).
The equation implies that a small amount of mass can be converted into a very large amount of energy because the speed of light squared (c^2) is a very large number. This principle is fundamental to the field of physics and has important implications in various areas, including nuclear physics, where it explains the energy released in nuclear fission and fusion reactions, and in cosmology, where it helps in understanding the energy of the cosmos.
The mass-energy equivalence principle is a cornerstone of the theory of relativity and has been confirmed by many experiments. It has also led to the development of technologies such as nuclear power and has deepened our understanding of the universe.
蠻有意思的過程。看完了 free course 大概了解 LLM application 的運作方式,找到 open source 的 RAG 懶人包 Microsoft Kernel Memory,拿現成的 example code 跑看看,並且看一下 source code 研究人家怎麼寫的,動手印出 prompt 跟 answer 驗證一下結果,花一點點時間,搞清楚整個處理過程,其實還蠻值得的,突然之間所有的技術都串的起來了。如果你有興趣,建議你也試看看。
再強調一次,弄清楚流程很重要的,弄清楚之後,Chat GPT 對我而言,除了問問題之外,某些情況下他也變成我測試用的 Playground 了。有時我想到一些應用方式,只要打開 Chat GPT,把上面的 Prompt 貼進去就能看到結果了。(對不起我是懶人,有時真的很懶得打開 Azure OpenAI Studio 出來用.. )
我把同樣的 Prompt, 用 ChatGPT4, 貼上去看看, 我得到的回應:

雖然是同樣的模型,回答仍然有些出入。不過我看到英文,就手癢想調整一下 prompt. 我只在原本 instruction 的部分加了幾個字,用 traditional chinese 回答:
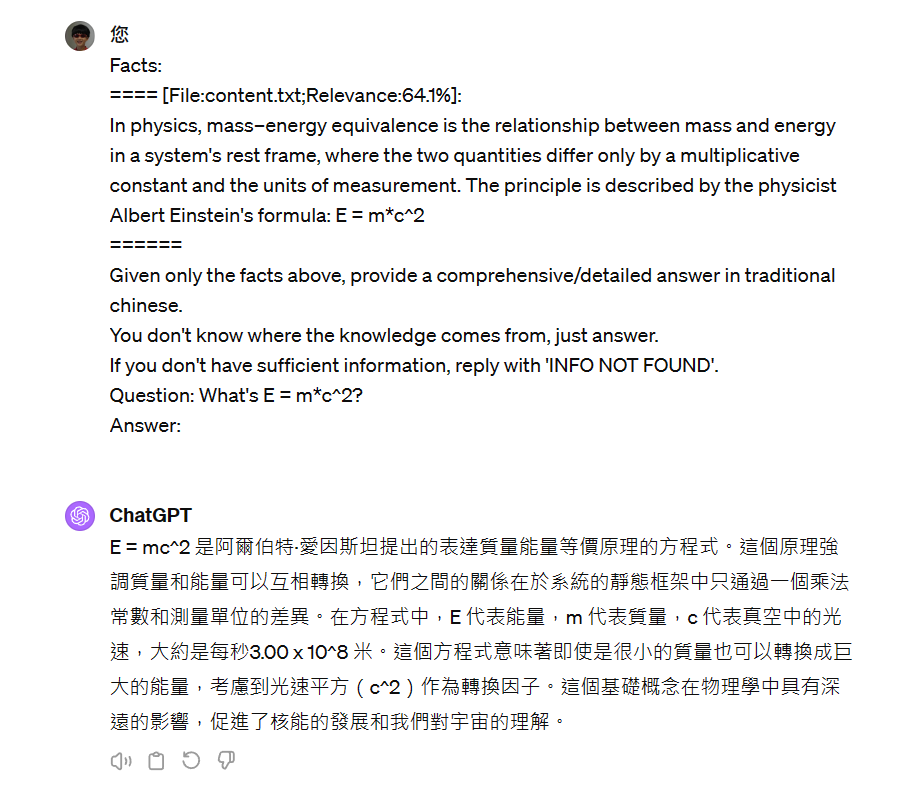
測滿意後,就可以回去改 code 了。不過我常常還不到改 code 的階段,只是有時靈光一閃,想知道什麼樣的系統化 prompt 可以得到什麼樣的答案,順手打開 Chat GPT 測試一下就知道了。不一定要寫成 code, 你也會更清楚掌握 prompt 的下法。
2-3, 建立文章向量化的資料庫
Ingestion
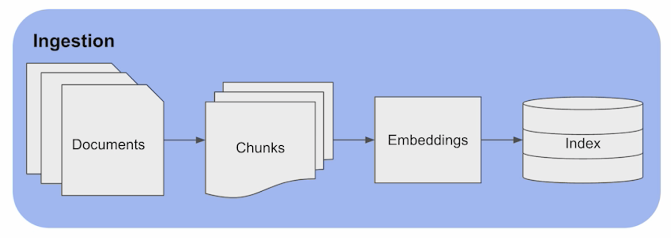
應該最先做的 Index, 我留到最後再講… 因為這邊很多準備動作,但是你不清楚哪裡要用的話,看了也是無感,到時還是要回頭來看.. 所以我直接調整順序,Ingestion 擺在最後..
要把內容向量化之後存進向量資料庫 (Index),主要有三件事要做:
- Chunking
- Embedding
- Indexing
先來看看我這次使用的 text-embedding 003 (large) 模型的規格:
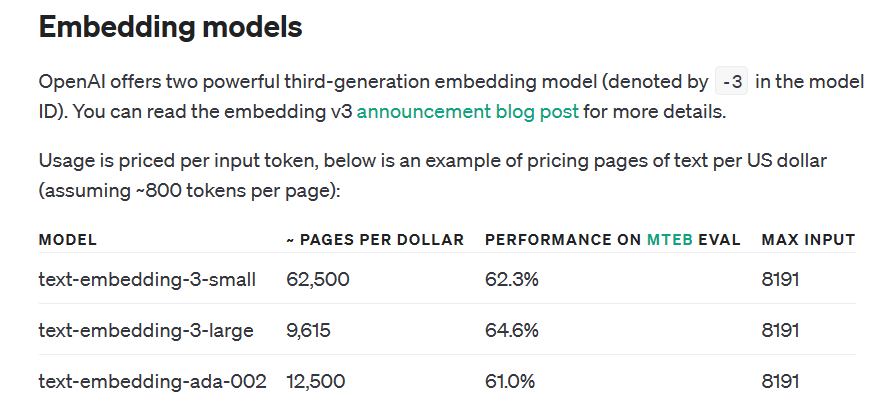
這個模型,最大能輸出 3072 維度的向量。模型在輸入規格上有個硬限制,就是 max input. 要向量化的原始內容不能超過 max input 限定的範圍 (單位是 token 數量),8191 tokens, 大約在 8kb 左右的範圍。就算他是 “詞” 不是 “byte” 好了,仍然是很容易就超過的數字,因此你必須面對內容怎麼 “切段” 的課題。因為跟語意搜尋有關,你不能切在中間,最適合的是段落之間,甚至是前後段都要有點重疊,甚至事先濃縮成摘要再處理等等,這邊有些處理策略需要考慮 (我當然還是略過 XDD),我為了 PoC, 這部分我就是留意,而 Kernel Memory 也內建了幾種 Chunking 的機制可以選擇,也能擴充 (我當然是先用預設值)
其他規格一起看一下,我挑選的模型分數最高 (MTEB 64.6%, 我也搞不懂差在哪 XDD),而價格也是最貴的,有多貴呢? 這張表可以看一下:
https://openai.com/pricing

每 100 萬個 token 需要花掉 $USD 0.13..
如果你有認真練習上面的步驟,你大概就能掌握哪邊需要花錢了,建立資料時,文章內容需要向量化要花錢 (一次性);查詢時,你的查詢條件須要向量化也需要花錢 (每次查詢)。因此問題先精簡再問,某種程度也有效果的,但是別走火入魔…
也許你會想: 如果我先用 LLM 來精簡問題再問呢? 看一下 GPT4 的費用:

GPT4- Turbo, 每 100 萬個 token 可是要花上 $USD 10 啊,這是 input, LLM 處理後的 output 也要花錢,更貴,要 $USD 30… 因此,別走火入魔,好好控制好不要無謂的浪費就好..
這些會跟你的 chunking 策略選擇有關,請記得規格的限制。
接著,直接來看實際範例吧! 我寫了一段小程式,我拿這系列文章第一篇: [架構師觀點] 開發人員該如何看待 AI 帶來的改變? 當作範例,用 Kernel Memory 向量化之後 Import 進資料庫。部落格自己掌控度高就是有這好處,要處理檔案直接就調的到。原始檔案是 .md (markdown),基本上已經是純文字了:
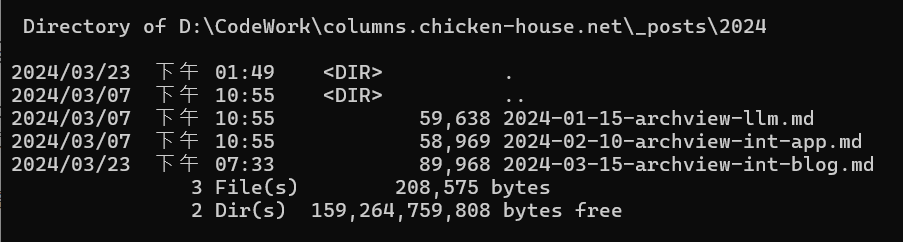
檔案名稱是: 2024-01-15-archview-llm.md 檔案的大小: 59,638 bytes (format: markdown)
我挑選的是最陽春的儲存方式 (沒有用任何向量資料庫,就是把每個 chunk 向量化後存成 json …
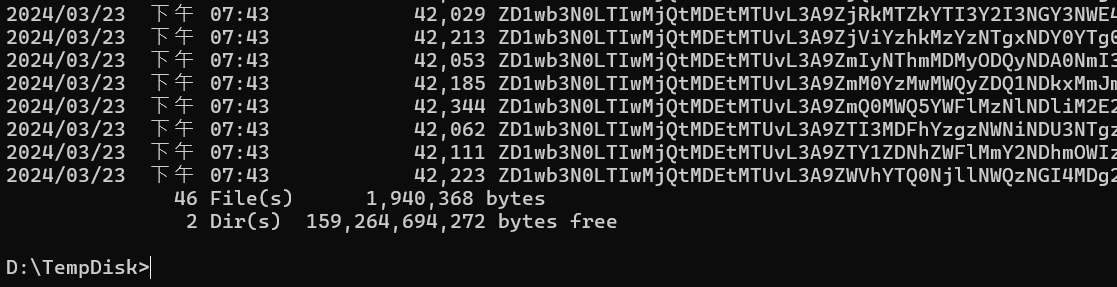
這樣的內容,總共被拆成 46 個 chunks, 總容量 1,940,368 bytes, 接近 2mb..
我貼第一個檔案內容,不過為了好處理,我刪除了一些不必要資訊,我也把 unicode 編碼轉成人演好讀的格式,另外 3072 個維度的向量都只是一堆數字,我只留前後各 5 個維度就好:
{
"id": "d=post-2024-01-15//p=ccc1cff5579640888ac346b9271a8b06",
"tags": {
"__document_id": [
"post-2024-01-15"
],
"__file_type": [
"text/plain"
],
"__file_id": [
"f6b3fd482292413698067f80d97fe98e"
],
"__file_part": [
"a0febecc6c334cdf9acc7305fddd68fd"
],
"__part_n": [
"1"
],
"__sect_n": [
"0"
],
"user-tags": [
"架構師觀點",
"技術隨筆"
],
"categories": [
"系列文章: 架構師觀點"
],
"post-url": [
"https://columns.chicken-house.net/2024/01/15/archview-llm/"
],
"post-date": [
"2024-01-15"
],
"post-title": [
"[架構師觀點] 開發人員該如何看待 AI 帶來的改變?"
]
},
"payload": {
"url": "",
"schema": "20231218A",
"file": "content.txt",
"text": "在 2023/11, Open AI 的開發者大會,發布了一個新的服務: GPTs, 我這次 demo 的主角, 就是想試試看, 搭配我自己的 API, GPTs 能替我把體驗做到什麼樣的程度?\r\nGPTs 是以 Chat GTP 為基礎, 他允許你在這基礎上, 預先設定好它的角色設定 (只管用自然語言說明就好), 背後的知識庫 (只管上傳檔案就好, 不用理會 RAG 什麼的細節), 你也可以把自己的 API 掛上去 ( Custom Action, 只要遵循 Open API spec 就好,\r\n寫好每個 path 的說明即可, 不用做特別設定, GPTs 會自己思考何時要呼叫你的 API)。完成之後,這個客製化的 GPTs, 就會按照你的設定, 來回應你的問題。而我這次的 demo, 就是客製了 安德魯小舖 GPTs, 他是個店長, 你只要跟他對話, 他可以在線上服務你, 並且替你呼叫 API 完成整個購物的流程。\r\n整個測試進行下來,說老實話,技術門檻很低,沒有太多新的 \"技術\" 要學。但是整合應用的門檻很高,困難的地方在於跟傳統的做法差異太大了,像我這種經驗充足的業界老人反而綁手綁腳的很不習慣. .",
"vector_provider": "AI.AzureOpenAI.AzureOpenAITextEmbeddingGenerator",
"vector_generator": "TODO",
"last_update": "2024-03-23T11:43:50"
},
"vector": [
-0.005305131,
0.009483802,
-0.0114965215,
-0.016640138,
0.02405324,
//
// 中間刪除 3062 個維度
//
-0.017427003,
-0.009384409,
-0.012846617,
-0.020044368,
0.015066407
]
}
這部分我想談兩件事,一個是底層資料庫的選擇,另一個是 tags 的應用。
向量資料庫的選擇:
Kernel Memory 有把底層的儲存機制 ( 區分 storage 與 vector database ) 都抽象化,所以底層用什麼技術說實在沒有那麼重要 (至少對於 coding 來說)。以我的 case, 雖說自認文章數量很多,但是對於資料庫而言,不過就是 300+ 筆紀錄,就算 chunk 分段,算一算也只有 2481 records, 共計 104 mb 大小的資料量。我這種實驗性的專案就選擇靜態的 file system 來處理就夠了。
目前,Kernel Memory 支援了這幾種向量儲存的底層技術: https://microsoft.github.io/kernel-memory/extensions/memory-db
- Azure AI Search
- Qdrant
- PostgreSQL
- Elastic Search
- Redis
- Simple Memory
除了 Azure AI Search 比較特別,額外支援圖片上傳 + OCR 轉成文字,做 text embedding 之外,其他就是單純費用、效能、維護等等考量而已。而 Simple 開頭的,都是單純由程式碼 (C#) 實做的而已,只是讓你可以動,方便開發與測試,並非給你用在 production 環境,不保證可靠度與效能的選擇。
不過,我的就是 PoC 驗證用途啊,所以我就選了 Simple Memory 這套。因為沒有資料庫,只需要靜態的檔案,因此我最後部署上 Azure 的 Kernel Memory Service, 是我刪減過的版本。我不打算開放任何管道,在雲端上來更新檔案,我只想要提共一個完全 Read Only 的檢索服務。還記得我 2016 年寫過一篇 Blogging as code 的文章嗎? 我完全把文章的發行也走 Git 版控 + CI / CD 流程了,既然文章已經都是用靜態網站的技術發布了,資料庫也比照辦理就好。目前我還是手動更新,等到弄好我就會讓他一氣呵成,修改文章就發 PR, merge 後就觸發 Build Web + Build 檢索服務,然後發行。
因此,我才想要刪減能匯入檔案的 API, 替代方案是我自己在 Local PC 先把文章匯入後,拿 memories 目錄 (就是一堆上面貼的 json files 的檔案) build docker image, 再部署到 Azure App Service 上面執行,我的 GPTs 就能透過 Custom Action 呼叫 API 提供使用者內容檢所的服務了。
我貼一段我自己用 Kernel Memory 寫的匯入部落格文章的程式碼,用的是 Serverless 模式 (不用架設服務,直接把 Kernel Memory 寄生在你的 code 內),資料儲存選擇 SimpleVectorDB,也不需要額外的 database service,一切都內建,一切都吃 Process 的運算能力,沒有任何外部相依性的要求,就能正常運作。
namespace AndrewDemo.BlogCopilot.PostIndexer
{
internal class Program
{
static void Main(string[] args)
{
var azureOpenAITextConfig = new AzureOpenAIConfig();
var azureOpenAIEmbeddingConfig = new AzureOpenAIConfig();
new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddJsonFile("appsettings.Development.json", optional: true)
.Build()
.BindSection("KernelMemory:Services:AzureOpenAIText", azureOpenAITextConfig)
.BindSection("KernelMemory:Services:AzureOpenAIEmbedding", azureOpenAIEmbeddingConfig);
var memory = new KernelMemoryBuilder()
.WithAzureOpenAITextGeneration(azureOpenAITextConfig, new DefaultGPTTokenizer())
.WithAzureOpenAITextEmbeddingGeneration(azureOpenAIEmbeddingConfig, new DefaultGPTTokenizer())
.WithSimpleVectorDb(@"d:\TempDisk\memories\")
.Build<MemoryServerless>();
int count = 0;
foreach(var post in GetBlogPosts(@"d:\CodeWork\columns.chicken-house.net\"))
{
count++;
Console.WriteLine($"import({count}): {post.PublishDate:yyyy-MM-dd} - {post.Title}");
var tags = new TagCollection();
if (post.Tags != null) tags.Add("user-tags", post.Tags.ToList<string>());
if (post.Categories != null) tags.Add("categories", post.Categories.ToList<string>());
tags.Add("post-url", post.URL.ToString());
tags.Add("post-date", post.PublishDate.ToString("yyyy-MM-dd"));
tags.Add("post-title", post.Title);
memory.ImportTextAsync(
post.Content,
$"post-{post.PublishDate:yyyy-MM-dd}",
tags,
null,
null).Wait();
}
}
static IEnumerable<BlogPost> GetBlogPosts(string blog_directory)
{
foreach(FileInfo postFile in new DirectoryInfo(Path.Combine(blog_directory, "_posts")).GetFiles("*", SearchOption.AllDirectories))
{
// 省略處理過程
yield return post;
}
}
}
public class BlogPost
{
public string FilePath { get; set; }
public DateTime PublishDate { get; set; }
public Uri URL { get; set; }
public string Title { get; set; }
public string Logo { get; set; }
public string[] Tags { get; set; }
public string[] Categories { get; set; }
public bool Published { get; set; }
public string ContentType { get; set; } // markdown | html
public string Content { get; set;}
}
}
這邊就是讓大家體驗一下 Kernel Memory 的用法而已。主要就是用 KernelMemoryBuilder 建立好 MemoryServerless 物件後,就可以直接拿來用了。Builder 可以指定幾乎整套系統的外掛模組,包含文章的處理 (可以 in-process, 也可以透過 message queue 讓其他獨立的 worker 分散式處理),包含使用的 AI service,包含使用的 AI model ( chat completion, text embedding generation ),包含要儲存的機制 ( storage , memory, vector database 選擇 ) 通通包含在內。而我的選擇,就是最單純單機版,最低外部服務相依的選擇而已。
真正關鍵匯入的,其實就這段 code:
foreach(var post in GetBlogPosts(@"d:\CodeWork\columns.chicken-house.net\"))
{
count++;
Console.WriteLine($"import({count}): {post.PublishDate:yyyy-MM-dd} - {post.Title}");
var tags = new TagCollection();
if (post.Tags != null) tags.Add("user-tags", post.Tags.ToList<string>());
if (post.Categories != null) tags.Add("categories", post.Categories.ToList<string>());
tags.Add("post-url", post.URL.ToString());
tags.Add("post-date", post.PublishDate.ToString("yyyy-MM-dd"));
tags.Add("post-title", post.Title);
memory.ImportTextAsync(
post.Content,
$"post-{post.PublishDate:yyyy-MM-dd}",
tags,
null,
null).Wait();
}
迴圈中的 post 是 BlogPost 的物件,是我用 Markdown / HTML 的套件,把文章內容去掉格式,轉成純文字,同時把 GitHub Pages 定義的文章摘要資訊 (這格式是有定義的, 處理方式可以參考黑暗執行緒的這篇: C# 解析 Markdown Front Matter) 解析出來,裡面有文章的分類,標籤等等資訊,解析出來後都放在 BlogPost 物件內。
而 Kernel Memory 支援的 Index 結構,也很簡單,就只有文字內容,基本的 document-id 等欄位,一個讓你自定使用的 TagCollection,以及文字內容向量化之後的浮點數陣列而已。
存進資料庫後,怎麼使用? 往前翻,前面我有提到 MemoryServerless 物件有 .AskAsync( ) 跟 .SearchAsync( ), 這就是了。
接下來,談一下 Filters 吧。也是前面我講的第二件事: Tags 的應用。
其實,看文件看到這部分,我還挺意外的,即使是個小專案,即使才 0.29 (離 GA 還很遠),但是他的規格卻定義的很完整,連 AI 應用的 security 都考量到了。這邊考量的,不是連線的安全,而是內容的安全。講白話一點,這機制可以讓你精準的控制,不論我下什麼 Query, 我都不會檢索到我沒有權限閱讀的內容。
本來我有要寫篇權限管控的設計,包含 RBAC (Role Based Access Control), PBAC (Policy Based Access Control), ABAC (Attribute Based Access Control) 的文章的 (會寫這句當然就是還沒寫 XDD),其中,適合用於大量資料的權限管控,最普遍的用法就是 ABAC 了。
這些授權管理機制,靠的都是認證 + 授權 + 規則 的組合,來簡化安全機制的開發。我就講 ABAC 就好,只要達成這幾個要求,資源的授權就很容易做到:
- 人 必須通過認證,並且把認證後的結果 (主要是: 是否通過認證? 被認可的角色清單) 放在 context 上。如果你熟悉 .NET 的 IIdentity / IPrincipal, 就是這東西。
- 資源 必須標記指定的 Attribute, 例如我常常舉的例子: 訂單。北區的業務只能查閱北區成交的訂單資料,南區也是,而總公司的人能查全部,這時每張訂單資料必須標記 “北區” or “南區” 的 attribute
- 透過 Policy, 或是其他靜態的設定,將 Role / Attribute 的關係做好對應。例如 Role(北區業務) -> Attribute(北區訂單),只要有這對應,就能授予權限。
這麼一來,當我登入那瞬間,我馬上就可以透過簡單的運算,列舉我被授權存取那些 Attribute 的資源。而這些 attribute, 我可以在下查詢的時候直接過濾。授權機制被 ABAC 標準化之後,剩下的就是設定了,連 SQL 查詢都能固定下來,不用改一種權限就要改一套查詢邏輯。
而在 NoSQL 體系,這種機制更容易實做,其實就是貼標籤就夠了。大部分的 NoSQL 都能很容易實做這樣的機制,一個 Json 的 string Array 就能簡單搞定。而 Kernel Memory 支援的,就是這套機制。
可以看一下他的文件說明 (雖然文件還缺很多,但是這段倒是寫得挺清楚):
https://microsoft.github.io/kernel-memory/security/filters#tags
Tags When designing for security, Kernel Memory recommends using Tags, applying to each document a User ID tag that your application can filter by.
Vector DBs like Azure AI Search, Qdrant, Pinecone, etc. don’t offer record-level permissions and search results can’t vary by user. Vector storages are optimized to store large quantity of documents indexed using embedding vectors, and to quickly find similar documents. Memory records stored in Vector DBs though can be decorated with metadata, and can be filtered when searching, applying some logical filters.
Kernel Memory leverages this capability, and uses specific native filters on all the supported Vector DBs (Azure AI Search, Qdrant, etc), removing the need to learn ad-hoc filtering syntax, allowing to tag every memory during the ingestion, and allowing to filter by tag when searching, during the retrieval process.
Tags are free and customizable. Multiple tags can be used and each tag can have multiple values. Tags can be used to filter by user, by type, etc. and in particular can be leveraged for your security scenarios.
文件在說明 tags 的應用就明說了,資料庫通常不會提供 record-level permissions 設定的,這也合理,通常這些都是 application 處理範圍。難道每個不同的 user 登入都要有不同的 connection string 嗎? 還沒登入的怎麼辦? 有各種原因,都無法在 database level 實做 application level 的 permission 機制的,因此 tags 的設計就幫了大忙,他定義了一個結構,讓資料庫能有效率且精準的過濾資料,也讓應用端能靈活的設計自己的 permission 規則。你需要的,就是學會如何善用 tags 來實做你的安全機制。
這些設計,若你有真的了解 ABAC 的原則的話,通常不需要 runtime 才做 join 的處理,你應該在資料寫入 ( ingestion step ) 就能確定該寫入那些 tags 了。Tags 應該標記 “意圖”,如果你發現你需要 tags 很動態 (已經寫入之後還要因為文件以外的原因 “自動” 改變 tags) 的操作時,十之八九你的設計可能需要調整..
針對安全的設計,後面也有一段在說明系統架構該如何配合:
https://microsoft.github.io/kernel-memory/security/filters#security-best-practices , Security Best Practices
Security best practices Summarizing, we recommend these best practices to secure Kernel Memory usage:
Use Kernel Memory as a private backend component, similar to a SQL Server, without granting direct access. When using Kernel Memory as a service, consider assigning the service a reserved IP, accessible only to your services, and using HTTPS only. Authenticate users in your backend using a secure solution like Azure Active Directory, extract the user ID from the signed credentials like JWT tokens or client certs, and tag every interaction with Kernel Memory with this User ID Use Kernel Memory Tags as Security Filters. Make sure every API call to Kernel Memory uses a User tag, both when reading and writing to memory.
AI 需要大量的處理語意相關的檢索,Embedding + Vector Search 基本上是跑不掉的,不過這不代表傳統的條件過濾機制就不需要。然而要做到像 RDBMS 那樣不斷的 Join 也過頭了,因此平衡的手段: Tagging 是很好的做法,我自己即使不是做 AI 相關的用,在其他地方也很常用這樣的技巧。留一個 Tagging 的機制,給將來的需求按照不同的意圖,貼上對應的標籤;檢索時就能很有效率地按照標籤來做簡單的二元運算 (有,沒有,AND,OR) 來達成過濾的要求。
Kernel Memory 實做的 TagCollection, 結構很單純,他是一個 TagKey, 搭配一組 TagValue 的陣列 ( 0 ~ N 筆 ) 的結構。其實我有預先把幾個我認為我以後會用的到的資訊,透過標籤標在 document 上了。我趁這機會說明一下:
匯入文件時,我寫了這樣的 code:
var tags = new TagCollection();
if (post.Tags != null) tags.Add("user-tags", post.Tags.ToList<string>());
if (post.Categories != null) tags.Add("categories", post.Categories.ToList<string>());
tags.Add("post-url", post.URL.ToString());
tags.Add("post-date", post.PublishDate.ToString("yyyy-MM-dd"));
tags.Add("post-title", post.Title);
memory.ImportTextAsync(
post.Content,
$"post-{post.PublishDate:yyyy-MM-dd}",
tags,
null,
null).Wait();
而在匯入後的資料片段 (就我上面貼的 json),會長出這樣的結構:
{
"id": "d=post-2024-01-15//p=ccc1cff5579640888ac346b9271a8b06",
"tags": {
// 我只保留我自己附加上去的 tags collection
"user-tags": [
"架構師觀點",
"技術隨筆"
],
"categories": [
"系列文章: 架構師觀點"
],
"post-url": [
"https://columns.chicken-house.net/2024/01/15/archview-llm/"
],
"post-date": [
"2024-01-15"
],
"post-title": [
"[架構師觀點] 開發人員該如何看待 AI 帶來的改變?"
]
},
"payload": {
// 略
},
"vector": [
-0.005305131,
// 中間刪除
0.015066407
]
}
這些 tags, 你可以在 Search / Ask 的時候,用基本的二元運算來決定你要怎麼過濾。其實 Kernel Memory 都準備好了 (只是文件還沒寫好而已.. Orz),我這次都還沒用上的 filters, 我就簡單的示範一下:
舉例來說,我呼叫 POST /search 時,如果我給這樣的 payload:
{
"query": "OOP",
"filters": [],
"minRelevance": 0.3,
"limit": 30
}
我會查到所有語意跟 OOP 有 30% 以上相關性的紀錄。我寫文章當下查到的資料有 30 筆。看來符合地遠超過這數字 (畢竟我一天到晚都在聊 OOP),只是被 limit: 30 限制住了。
接著,我把 payload 加上 filters,除了原有條件之外,外加 user-tags (我自己加上的 tags collection) 必須包含 “架構師觀點” :
{
"query": "OOP",
"filters": [
{ "user-tags": ["架構師觀點"] }
],
"minRelevance": 0.3,
"limit": 30
}
查詢結果就剩下一筆 (我就不列查詢結果了)
而 Kernel Memory 團隊,也用了我過去常用的技巧,提供 AND / OR 的表達方式。如果你要下 AND 的查詢,可以這樣下 (代表我要查詢同時有貼 “ASP.NET” 跟 “microservices” 標籤的文章):
{
"query": "OOP",
"filters": [
{ "user-tags": ["microservice", "ASP.NET"] }
],
"minRelevance": 0.3,
"limit": 30
}
如果你要表達 OR,就拆成兩行
{
"query": "OOP",
"filters": [
{ "user-tags": ["microservice"] },
{ "user-tags": ["ASP.NET"] }
],
"minRelevance": 0.3,
"limit": 30
}
如果你要再複雜一點: ( “microservice” AND “ASP.NET” ) OR ( “架構師觀點” ) ,可以這樣下:
{
"query": "OOP",
"filters": [
{ "user-tags": ["架構師觀點"] },
{ "user-tags": ["microservice", "ASP.NET"] }
],
"minRelevance": 0.3,
"limit": 30
}
Kernel Memory 把這機制保留下來了,而且在 SimpleVectorDB 裡面也實做出來了,同時在缺很大的文件裡也優先把它說明清楚了,可見開發團隊對他的重視。這篇篇幅有限,如果我將來有別的 PoC 或是 Project 有用到,再來好好介紹一下他的應用技巧。
3, AI 改變了內容搜尋方式
講這段之前,還是要再提醒一下,我是老一派的開發人員,從組合語言學起來的那一代。無法精確交代執行過程的技術,對我來說都很虛幻。在我對內容檢索的 know how 還停留在關鍵字搜尋,全文檢索的程度時,我是很難想像如何能 “精確” 的找出語意相近的內容,尤其是它們呈現的文字 (到 bytes 層級) 是完全不相干的前提下…。
將語意用個多維度的空間 (embedding space) 來表示,將每個內容都在這空間內標示對應的向量的作法,是 deep learning 發展下的產物。細節我沒辦法聊太多,只能聊聊怎麼應用了。只要能將內容轉成對應的向量,要找出 “語意相近” 的內容很容易,單 純在這空間內找出最接近的向量就是了。這是數學的運算,沒有 AI 那麼多難以理解的環節,而玄學的部分,則是將內容轉成向量的模型 ( text-embedding model )。
了解了這部分,應用就開始多元化了。過去的 “搜尋” 都很僵硬,就是要明確定義欄位,數值,條件等等,或是關鍵字,全文檢索等作法;而到了 embedding space,雖然轉成向量的部分仍然難以理解,但是就結果而言,向量搜尋是很簡單易懂的。只要能放上同一個 embedding space,你就能找出相近的內容 (或是物件)。
舉例來說,這整篇談的,都是從 “問題” ( question, 可能是個關鍵字,可能是一句話,也可能是一段描述 ) 找到對應 “內容” ( 文章的片段 ) 的過程。如果你也有對應的模型,能把圖片轉成向量 (或是圖片 -> 文字 -> 向量),那你就能從問題找圖片了。
先前看過一些有趣的應用,例如 Spotify, 他的課題都在如何推薦歌曲給使用者。他的做法就是以 user 為中心,收集了一堆資訊,包含歌單,播放次數等等,細節我無法理解,但是他有他的一套方法,定義個人的 profile, 並且向量化。另外,也以 playlist / song 為中心,一樣做了向量化…
所以,推薦該怎麼做? 到這邊就很容易了,把這些向量放到同一個 embedding space, 找出特定 user 跟他相近的 playlist 就好了。這是 two tower models 的作法
貼兩篇我看過的參考資訊:
spotify, 歌曲也能 embedding ..
來源: Git Repo - spotify_mpd_two_tower

另外這篇,講的就是電商的應用, 個人化的推薦系統, 也是 two tower 神經網路作法 Personalized Recommendation Systems using Two Tower Neural Nets
看了這些應用,我開始覺得,AI 的成熟跟普及 (不用等通用人工智慧了,現在改變就夠大了),會大大的改變資訊系統的運作方式。前兩篇我的重點都在 LLM 改變了 API 的使用方式 (現在: 開發人員決定怎麼呼叫;未來: AI 決定怎麼呼叫),光是這點就足以讓整個生態天翻地覆了…。
而這篇要談的也類似,只是從 API 的應用換成資料的應用了。AI ( Embedding, LLM ) 的成熟,也開始改變資料的應用方式了。資料不再只能靠只有開發人員才搞得懂的複雜 Query 才能使用,而可以進化成每個人都能理解的自然語言查詢。向量化可以讓系統架構便單純,而且通用;而複雜度則被切割到特定領域,特定格式的內容,要訓練出夠精確的模型來進行向量化。
所以,我也來推測一下,未來資料處理的方式,會有那些改變吧:
3-1, 從 “表格” 到 “空間” 的演進
我算是有幸經歷過三種資料庫演進的年代,我就從 RDB,NoSQL,到 VectorDB 的演進,來談一下資料搜尋的進化吧。每次的進化都代表技術的演進,背後都有不同的象徵意義,代表著資料的儲存與查詢的層次改變。
3-1-1, RDB: 表格為主
表格,是最有效率的資料儲存方式,出發點是 storage / data structure 的最佳化,為的是效率與精確度的工程考量
最典型的資料庫型態,就是能儲存多個巨大的 table 所組成的資料庫。表格的建立,必須先定義 schema,資料必須符合 schema 的規範才能寫入。而資料的操作都是以表格為主,大家耳熟能詳的 select, where, order-by, join 等等都是基本操作,這些操作發展出專屬的語言: SQL,我就不多做介紹。
table, 是最單純且有效率的結構。就如同程式語言最有效率的結構永遠都是 array 一樣,table 在資料庫就是同樣的存在。table 結構明確,容易做索引,也容易做各種 I/O 的優化。不過 table 結構離最終應用程式要使用的結構差距太遠 (為了把現實世界資料完美的放進 table, 做了過多的正規化,導致使用時必須做 join 來還原。許多 RDBMS 的限制都來自這裡)
3-1-2, NoSQL: 文件為主
物件/文件,是最理想的模型對應結構。應用程式都已 “物件” 的方式思考,而 “文件” 則是跟他一對一的存在。NoSQL 最大的改進就是讓工程師以模型來思考,而不是以怎麼拆解成 table 來思考的突破
進化到 nosql ,其實我在念書的時代,這類技術的前身是 object database。背後的觀念是你不再是在表格存資料,而是在一個一個的 collection 內儲存 object… 物件會有繼承,封裝,多型等等特性,拔除行為的部分,剩下的資料層面則是結構化資料。我在唸書時代正好念過這些,研究的都是物件導向資料庫 (OODB),出來工作後接觸的第一個類似理念的資料庫,是以 XML 為基礎的資料庫,資料用 XML 表示,Schema 用 XSD ( Xml Schema ) 表示,而查詢則用 XPath / XQuery 表示。不過發展至今,XML 已經快被 Json 完全取代了,因此目前的主流都是用 nosql, 存的是 json, 用的是 json schema 來定義。
entity, 對應到程式語言的 object 可說是完整的對應, 省去過多的 “ORM” 操作,同時 entity 也較貼近應用程式最終使用資料的樣貌,nosql 對 join 的需求降低很多,各種分散式的最佳化也得以發展,在 cloud native 世代逐漸變成顯學,雖沒有完全取代 RDBMS,但是也發展出他不可取代的應用領域。
3-1-3, VectorDB: 以向量為索引
物件為主的儲存,加上向量索引,就是個理想的資訊儲存方式了。每個物件都有它的狀態 (entity),而每個物件也在 embedding space 有它的意義 (vector) 存在,比起 RDBMS,NoSQL 更能完美的跟向量查詢搭配,一邊拿向量當作 AI 世界的索引,一邊拿 NoSQL 精確地描述物件的狀態
進化到 AI 的時代,語意變成最重要的環節,資料庫也跟著演進了。能描述資料的語意,是多維度的空間,每一筆資料,是這個空間內的向量,而查詢的方式,是向量的相似性比對。所有資料都應該先向量化 embedding 才能放進這空間。在這空間內就能很容易的按照語意來操作資料,解決語意的比對這難題後,再搭配成熟的 relation database 或是 nosql 的輔助,就能做好資料的語意搜尋與應用了。
這是很重要的結構改變,也因為這改變,對我來說,資料庫的發展應用也進化了,語意查詢已經被標準化為向量搜尋,不再是過去百家爭鳴的關鍵字搜尋或是全文檢索的獨門技術。
然而,向量代表的主要是來自原始資訊 ( text, image 等等 ) 轉換成多維度空間結果,並沒有辦法還原成原始資訊的,因此,這類應用還是得依靠 RDB 或是 NOSQL,來做原始資料的儲存,以及額外的過濾等等的輔助機制。因此,向量資料庫不是取代傳統的資料庫,而是強化資料庫在 AI 世界運作的能力。你會看到各種主流服務,都積極的替自己的服務加上向量檢索的能力。就我看來,NoSQL + Vector 較有優勢,因為他們都是對應主體 ( entity, document ) 而設計的儲存方式,而 “向量”,則是這些主體,在語意上最有效率的索引,讓其他系統能快速準確地找出 “語意相近” 的資料。這整篇談的 RAG,就是這樣的應用。
3-1-4, 資料庫世代的改變
對我來說,這三種世代的改變,不是新的取代舊的,而是新的資料儲存方式,提升了資料操作的層級。RDB 處理的就是一連串的 “欄位” 組合,基本上處理的單位就是程式碼的變數。而 NoSQL,處理的是一連串的 json document,基本上你可以把它看成程式碼的物件。而 VectorDB,處理的是 embedding space 內的 vector, 你可以把它看成處理他的語意,有能力判斷這段文章跟另一段文章是否相關這種層級的搜尋與操作。
因為有了 text-embedding model 與 vector database, 語意的搜尋已經
所以,拆解出 AI 時代,各位都應該掌握的幾個關鍵元件:
-
向量化 (embedding):
把資料轉成向量的關鍵。有各種技巧,包含 ML (machine learning) 等等,這些我沒有能力談,我只能用現成的模型來處理。後面範例我會用的是 Open AI 的 text-embedding-003 large model. 他的輸入是 text, 輸出是 vector, 主要的成本來自要處理的 input tokens 數。 -
向量資料庫:
用來儲存預先處理過的向量資料, 並且能有效率的查詢相近的向量 -
語言模型 (LLM):
有兩個用途,一個是將你的輸入 (詢問的自然語言) 的意圖抓出來,再把問題轉成向量 (這樣就能找出相近的其他向量);接著再把查詢的結果對應到原始內容,這時你已經從幾百萬筆資料,濃縮到只有幾筆相近的資料了,再次靠 LLM 把這些問題與檢索結果彙整歸納成你要的答案
這三者缺一不可,組合起來就能達到 “用嘴巴來找資料” 的期待。
突然間,我覺得這些組合都發展成熟了 (最關鍵的還是 LLM),然後相關的應用都被打開了… 我聊這段的用意,是告訴大家,因為 AI 的普及,在資料儲存上,向量的處理勢必會越來越重要。各位資深的工程師,架構師,SRE,DBA 等等,都應該關注這個趨勢,做好準備才是。
除了 “儲存” 的方式改變之外,”查詢” 的方式,以及查詢用的 “語言” 也都有不同。這我後面分兩段來聊聊
3-2, 從 “條件” 到 “語意” 的查詢
SQL, 專屬的查詢語言
既然儲存的方式都改變了,查詢的方式也不再相同。回想一下,不論你用哪一套資料庫,只要是 “關聯式” 資料庫,你大概離不開 SQL 的各種衍伸語法。
SQL ( Structure “Query” Language ) 的標準結構,大概是這樣,基本上都是表格為基礎的操作:
select ... // 指定要傳回的欄位
from ... // 指定要從哪個 table 查詢,若有 join 代表多個表格要用指定方式合併,也是在這層及處理
where ... // 指定表格要篩選那些資料列
order by ... // 指定查詢結果要照那些欄位排序
group by ... // 指定查詢結果要如何聚合 (aggregate)
having ... // 指定聚合結果要照那些欄位過濾
不管如何,這些都是表格的想法,你沒有 schema,沒有辦法寫得出來。而 schema 又需要經過正規化分析設計,基本上這就是專屬開發人員使用的工具…
Stream Pipeline, 串流的資料過濾與處理
到了 NoSQL,這狀況稍微好了一些,因為 Entity 的設計,已經避免了過度繁瑣的正規化,Entity 的種類大致上已經能對應到商業模型上的 Entity,Join 的需求還在,但是已經沒有那麼頻繁的被使用
這時,查詢已經簡化成:
projection (挑選你要的結構) filtering (過濾你要的 entity)
其他的進階處理,因系統而異,但是基本上都是 pipeline 的方式,一關接著一關一路往下串… 允許 stream process 的結構。看看那些 big data solution , 或是 no sql database, 大致上都支援這樣的查詢方式。
如果把 ORM 對應過之後的 LINQ 也算進去的話,IQueryable 可以一路一直串 .Where( ) 跟 .Select( ),也算是在語言內的記憶體內串流處理啊 (硬ㄠ..)
Embedding 與向量運算
若把向量當作 Entity 在特定空間 (Embedding Space) 的索引 (Vector),那一切就很單純了。向量搜尋只不過是 filtering 或是 sorting 的一個特殊選擇而已。困難的不在語法,而是往前挪到如何將內容 “精準” 的轉成向量,這是模型的議題,就讓 AI 的專家們來傷這個腦筋吧,資料建到資料庫內,做好向量化之後,才是開發人員要處理的範圍。只要模型夠強,資料庫搜尋向量的能力夠強,一切就沒問題了。
這時,已經不再需要 “專屬” 的查詢方式與 API 了。真正重要的,是你要把什麼東西轉成同樣空間的向量來比對? 這次 RAG 的範例,我用的是使用者輸入的問題,轉成向量比對;前面提到 Spotify 的推薦案例,則是把使用者個人 profile 轉成向量,來找出對應的推薦歌曲。領域的知識集中到模型本身,撇開模型的效率與微調,程式碼的結構跟流程是很明確的。
這時,查詢方式已經進化到自然語言,或是提示工程 (prompt),影響正確性的已經是模型的能力與訓練.. 你會發現這已經跨過開發的工程問題,真正已經轉移到語意的定義問題了,我覺得這真的是一大進步,開發人員終於要面對的是使用者的需求,而不再是替使用者跟電腦之間做溝通的橋樑。
3-3, 從 “APP” 到 “AGENT” 的操作
最後,聊一下我這次的選擇,我選用 GPTs,而沒有第一時間自己開發 “ASK” 的 UI … 仔細想想,這兩個選擇不是只有 “哪個比較好” 的差別而已,想通了我才發現這是不同的目標跟策略下的對應作法。我用幾點來對照:
- 我是否需要 “對談式” 的介面?
Chat GPT, 畢竟是個 “Chat”, 先天就有上下文的處理。如果我自己的部落格要提供檢索的功能,第一件事應該是想: 我要用對談的方式? 還是問答的方式 (有個搜尋框,讓使用者在裡面填問題,就列出答案;每次問答之間是獨立的,沒有上下文關係) ?
如果是 Chat, 那麼在 Chat GPT 的基礎上來實作會容易得多 (就是我這次的做法)。雖然會有其他的限制,例如最明顯的是只有 Chat GPT Plus 訂閱用戶才能使用,大大降低了能使用的人數。不過,如果你要少量測試,取得先期的回饋,這道是個不錯的方式。
即使你要提供 “對談” 的介面,我也建議不要第一時間嘗試自己開發,上下文關係的處理要做到精緻其實也是要花功夫的。過濾太多上下文,關聯性就掉了,保留太多,費用就上去了 ( token 很貴啊啊啊… )。如果要自己做,至少也要用對的 API,例如 Open AI 的 Chat Completion API, 或是 Assistant API, 避免自己處理太多 “chat” 的細節…
再者,Chat GPT 有基本的個人 profile, 這些細節也許都能協助讓你的回答更貼近 user 的期待,這些都屬於 prompt engineering 微調的範圍內。其實你收集好這些資訊,下對 prompt,用同樣的 LLM ( GPT4 ),應該都能做到對等的效果。但是就看你要不要 (有沒有辦法) 收集到這些資訊啊! 這是平台化的威力,依附在某個平台,這些好處就是現成的。以我來說,只是個單純的部落格搜尋,應該沒有人想在我這邊留下 user profiles 吧..
- 我要誰來付擔 AI 推理的運算費用?
接下來這是比較現實的問題,AI 的推論費用 ( token 費用 ) 很貴,由誰來支付? 你選擇的做法,背後就決定了這題 …
如果你用 GPTs, 那麼就是依附在 Chat GPT 的平台上了。要使用 GPTs 的人都必須先有 Chat GPT plus 的訂閱才能使用。而這些使用者在使用你的 GPTs 時,除了呼叫你的 API,在你 API 後端的運算之外,其他 LLM 端的處理,都是使用者的訂閱費用來支付的。
差距有多大? 我用前面舉過的案例,如果我問了這問題:
“告訴我 microservice 架構下,多個服務之間如何維持資料一致性的作法?”
這句話,用 text-embedding-003 (large) 模型來向量化搜尋,大約 30 tokens 以內,費用只要 $0.0000039 USD (價格: $0.13 / 1M tokens),還在合理範圍…
但是為了做到 RAG,要把向量搜尋檢索出來的 30 段文字都丟到 LLM 去彙整答案,大約要花掉 15000 input tokens, GPT4 的費用大約是 $0.15 USD … 而使用量的管控,Chat GPT 已經有做法了,每個人每 3hr 能問的額度是 40 次…
這一次查詢的費用,看看你想要哪一方負擔? 你的選擇就決定了費用的分攤方式…
如果時間再往後推三年,假設到時本地端的 LLM 已經成熟,你可以寫個 APP 直接用自身的運算能力時… 這時就演變成使用者要自己負擔設備的運算能力,以及電費了。這是第三個選項,由使用者端來決定 LLM 的模型,以及負擔 LLM 推論的算力。
- 我想要的是 APP 還是 AGENT 操作?
這題思考層面更大了,你想要的是網站的檢索功能? 還是獨立 APP? 還是是一個整合的 Agent ?
Chat GPT 目前還算是個 APP,不過我覺得他有在往 Agent 發展;Microsoft Copilot 目前跟 Chat GPT 差異不大,但是比起 Chat GPT,他更有本錢往 Agent 發展 ( Microsoft 掌握 Windows 的終端使用者,也掌握更多個資跟行為 )。
然而,大家別忘了最大宗的 Agent: Apple 的 Siri 與 Google 的 Assistant …, Microsoft 為了 AI PC,也端出了 AI Explorer, 看得出來他的野心,AI Agent 也開始要收所有個人資料跟行為了..
整合這些 Agent 的好處很明顯,如果他們都具備一樣的能力,由這些 Agent 來問問題,能做到更完善的個人化。就如同前面我舉例的 Chat GPT 可以設定 user profile 一樣。同樣的 user profile, 我猜 Apple / Google / Microsoft 應該能抓得比 Open AI 更精準吧?
Chat GPT 也在追趕這塊,光是你可以在正常的 Chat GPT 內用 @{GPTs} 的方式來叫你的 GPTs 回答,某種程度也在網整合方向靠攏了。未來的 roadmap 會做到甚麼地步我不清楚,不過現在沒人敢忽視 Open AI 的下一步吧? 請把它當成一個可敬的對手來看待..
不管從任何角度來看,都是提供檢索能力的 API,掛上某個成熟的平台,看來更為合理啊,目前我挑選的就是 GPTs, 只是因為需要訂閱,觸及人數大幅受限,我就把它當作個快速驗證的平台吧! 有餘力時我再來看看,如何更進一步的開放檢索能力,給更多的使用者使用…
4, 結論
前前後後聊了很多,這邊的總結,我就三篇的心得寫在一起吧。其實我做這些 PoC, 寫這些研究過程, 跟心得, 我背後的想法是:
AI 對我來說,已經是另一個世代了,而新的世代的資訊科學,基礎技能也應該往上翻一輪了。
我求學的那個年代,大家在談的是 “ 程式 = 資料結構 x 演算法 “;進階的抽象分析,大概就是物件導向分析 (OOP / OOA / OOD) 的層面。
後來加了很多部署環境跟維運的題目,CI / CD, Cloud Native, Public Cloud / SaaS / PaaS / IaaS 層面的知識。
現在,回歸到應用程式需要有智慧的話 (就是 LLM 應用程式開發),整個基礎就往上提升,你開始要掌握圍繞在 LLM 周圍的各種知識了,從 prompt engineering, function calling, embedding, vector search 等等,都變成是必要的技能,要懂這些才有辦法設計這些 “智慧化” 的應用程式。
要在未來十年繼續擔任架構師,就必須靈活運用這些 “基礎” 知識才行,所以我現在寫的這些內容,都是我自己在惡補這些技能的路上。比起速成,比起你多快能用 AI 寫出一段 code, 或是用 AI 產生一張圖,對我來說,搞清楚背後的運作模式,想清楚那些地方能用到它,該怎麼用,有哪些替代方案可以選擇等等…,這些在 AI 世代做出正確技術選擇,正確組合這些威力強大的武器,對資深人員來說更為重要。
因為你的角色不應該是跟 AI “競賽” (如果你心裡想著一直是不要被取代,那就是競賽了),因為時間不會站在你這邊,長期下來競賽結果一定是輸掉的 XDD,正確的站位,應該是你如果有了威力強大的武器 (AI) 或是部屬 (還是 AI),你要讓它做什麼才能讓你發揮更大的價值,那才是重點。我是個架構師,我該思考的就是如何善用 AI,才會花了時間研究這些題目,同時也寫了這三篇文章。
這三個月 (剛好一季),買了 Chat GPT plus 訂閱,用了 MVP 的一些資源,花了周末 & 下班時間,嘗試這些 PoC / Side Project,我覺得很值得。整理的這三篇文章,也希望對大家有幫助
最後再擺一次這三篇的連結,歡迎分享轉貼,也歡迎在底下留言給我回饋 :D
