
圖片來源: DALL-E, 這篇都是過年期間的研究心得, 就用龍(年) + 未來都市當主題吧
上一篇文章 架構師觀點 - 開發人員該如何看待 AI 帶來的改變?,展示了我嘗試的 安德魯小舖 GPTs 整合應用,實現了讓 AI 助理的嘗試,我開始真的可以用自然語言就完成整個購買流程的操作了。過程中,AI 也幫我 “腦補” 了部分我 API 沒有提供的功能 (指定預算跟購買條件,AI 自動幫我思考購買組合)。這結果其實比我預期的還理想,完成之後,我開始探索接下來的這兩個問題:
- 未來的應用程式,會怎麼運用 “AI” ?
- 未來軟體開發的流程與角色,會變成甚麼樣貌?
因此,這篇我就要面向應用程式的開發面,來探討該怎樣把 “智慧” (我暫時把 “智慧” 解讀為能理解語意的能力,拿 LLM / Large Language Model / 大型語言模型 當作代表) 加到你的應用程式內。雖然目前 LLM 還有很多缺點,但是應該開始把 LLM 當作 “人” 來看待了,溝通的方式都要把它當作 “人” 的方式溝通 (因此要善用 prompt, 而不是 function + parameters)。這其實跟傳統的軟體開發結構完全不同,也是我這篇想繼續往下挖的主題。
上面我列的兩個問題,一個是未來的軟體執行方式,改變的是使用者使用軟體服務的習慣;另一個是未來軟體開發的架構,流程與分工,改變的是軟體開發領域的生態,包含服務,結構,開發框架,流程,工具等等,預期都會被 AI 翻了一輪。改變是必然的,不確定的是會怎麼變? 因此,我決定延續 “安德魯小舖” 這 PoC, 假設這是五年後的服務呈現的樣貌,那麼這過渡期間會如何發展? 如果五年後是這樣,那麼現在大家使用的工具與知識會有什麼變化?
這篇文章會分兩段,第一段我會以我用 Azure OpenAI + Semantic Kernel 重寫一次 “安德魯小舖”,並且從典型的應用程式,逐步加上 LLM 的應用的開發過程。
第二段則是想深入聊一下,LLM 應用的幾個重大架構設計上的改變。這點尤其重要,越資深的人 (例如我) 越容易陷入過去的經驗與慣性,碰到這樣的重大轉折點反而不容易反應過來。這段我想談談的就是我觀察到軟體設計架構,會因為 LLM 的引進,有那些變化。
我目前仍然是個 AI 的門外漢,這篇是野人獻曝的分享內容,單純分享我自己摸索過程而已。我習慣盡可能搞清楚全貌,再來學習會比較精準有效率。因此過年期間 K 了很多文章,總算搞清楚 Open AI / Semantic Kernel 在幹嘛。文內的敘述有錯的話歡迎留言通知我,感謝~
這篇文章會用到的相關資源:
- 安德魯小舖 GPTs
- Microsoft Semantic Kernel
- Azure OpenAI
- Open AI: Function calling
- Open AI: Assistants API
- Source Code: AndrewDemo.NetConf2023
- The architecture of today’s LLM applications
- Large Language Models and The End of Programming - CS50 Tech Talk with Dr. Matt Welsh
1, “安德魯小舖” 的進化
先前,雖然完成了 “安德魯小舖 GPTs” 的 POC, 但是我仍然這不會是短期內 ( 1 ~ 3 年內 ) 大量運用 AI 的應用程式樣貌。把應用程式 Host 在 Chat GPT 上,還有很多不夠成熟的地方:
- 很容就踩到使用量的限制
- 並非每個消費者都有 Chat GPT plus 訂閱
- Chat GPT 回應的速度跟可靠度都還不及
這些對線上交易而言都不是個很好的選擇,我相信 Open AI 會持續改善這些問題,不過算力珍貴 (現在是各大廠的必爭之地),也不可能一夜之間改善,我覺得漸進式的在現有應用程式內加入 “智慧”,先從最需要 “智慧” 的環節改變,才是合理的發展路線。
於是,既然可行性已經確認,接下來就往產品發展的方向來思考了。我拆解了 “將應用程式加入智慧” 這願景,拆成這四個階段,重作了一次這題目,作為這篇 PoC 的主軸。開發細節跟程式碼,這篇實在寫不下,我就先截圖給大家體會,同時先提供 github repo, 有興趣的可以先看, 或是告訴我你想了解哪個部分,我看看是否整理成另一篇文章…
我想像中,安德魯小舖從典型的 APP 到智慧化的演進過程,應該有這幾個階段:
- 尚無智慧, 只提供 標準的操作模式
- 在關鍵環節使用 AI, 從操作意圖評估風險
- 操作過程使用 AI 輔助提示: 從操作歷程,即時提供操作建議
- AI 能自主代替使用者操作: 全對話式的操作
在這個 PoC 的每個階段, 我都試著寫了一點 code 來試做可行性, 而我另一個目的也是想要掌握這類應用程式的開發結構,跟過去有多少差別? 對我而言,架構師要判斷 “該不該” 使用某些技術,比 “會不會” 使用,或 “專不專精” 這些技術還重要。我也期待在這次試作的過程中,掌握一些這類應用程式設計的手感。
雖然客觀的來看,要發展到 (4) 普及的階段還要好一段時間,至少要 3 ~ 5 年以上才會成熟吧。但是看看現在 Micosoft Copilot 跟 Open AI 的發展,我覺得技術發展應該都快要到位了,在等待的是廣大的軟體開發人員跟上,以及這些應用的關鍵資源門檻下降。
這個段落,我就摘要的說明一下我的 PoC, 並且聊一下我設計上的想法。
1-1, 標準的操作模式 (對照組)
(這邊我用了 console app + 選單的操作, 模擬上古時代功能型手機的那種操作體驗。如同那些不友善的 chetbot 應用一樣,你只是透過 IM 的外殼,來執行選單的操作而已。我拿這當作對照組,各位可以自行替換成 MVC 或是其他操作介面。
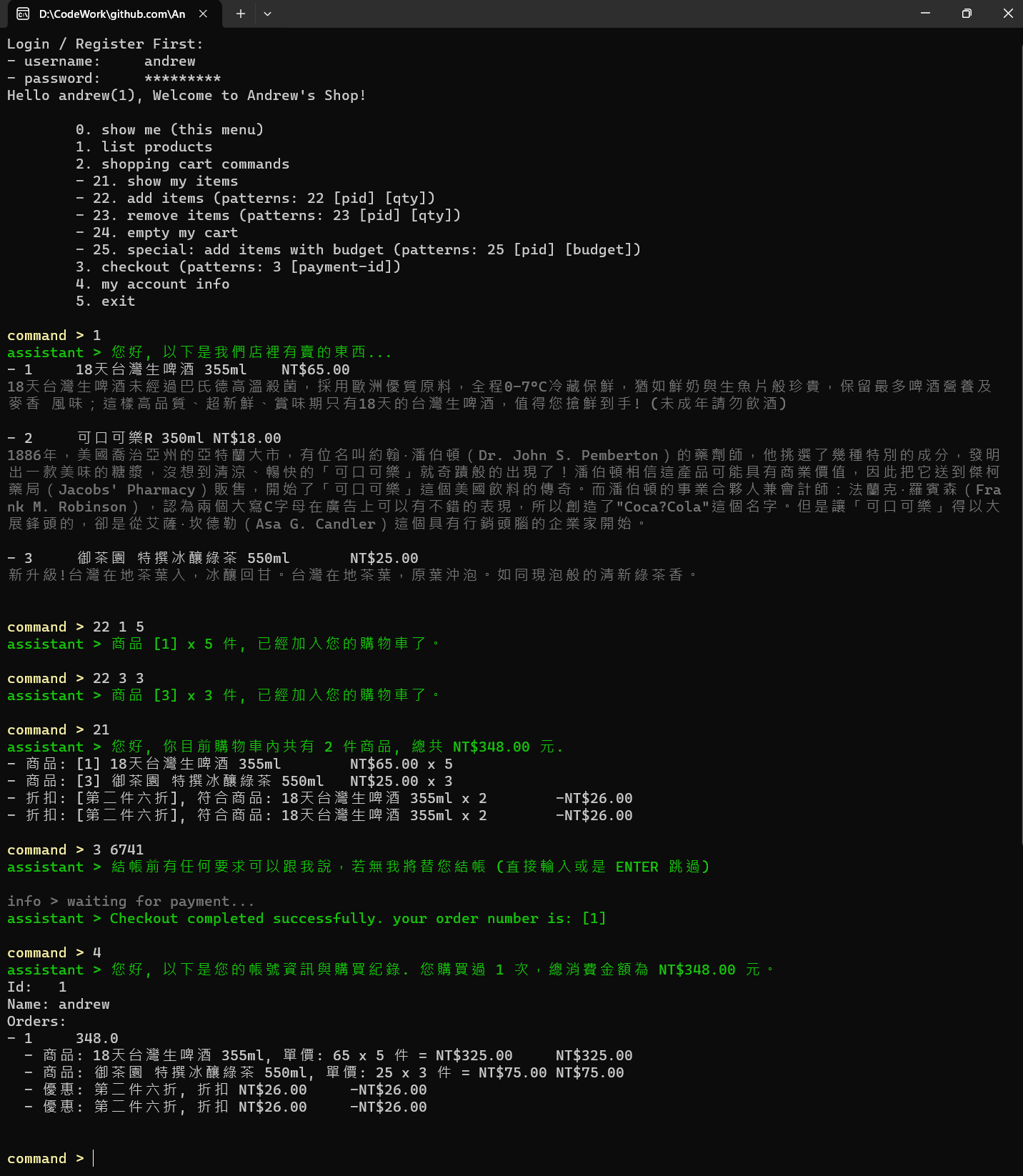
圖 1, 標準 console app 操作範例 (點擊可以看大圖)
我簡單的操作,基本上就是用數字選指令,有些指令有附加參數,就這樣而已。我示範的操作依序是:
- 列出商品清單
- 將啤酒 (id: 1) x 5 放入購物車
- 將綠茶 (id: 3) x 3 放入購物車
- 結帳 (支付代碼: 6741)
- 列出交易紀錄
這邊體驗一下就好,重點在後面延伸加入 LLM 處理的部分。
1-2, 從操作意圖評估風險
在關鍵功能 (我的定義: 結帳) 執行時,能靠 LLM 歸納與推理的能力提供個人化的建議,找出各種不是和交易執行的問題或是風險。除了 rule based 的規則檢查,應該有一個關卡是由 LLM 來進行前後文的邏輯推演,找出 “常識” 裡不合理的地方,提醒使用者。
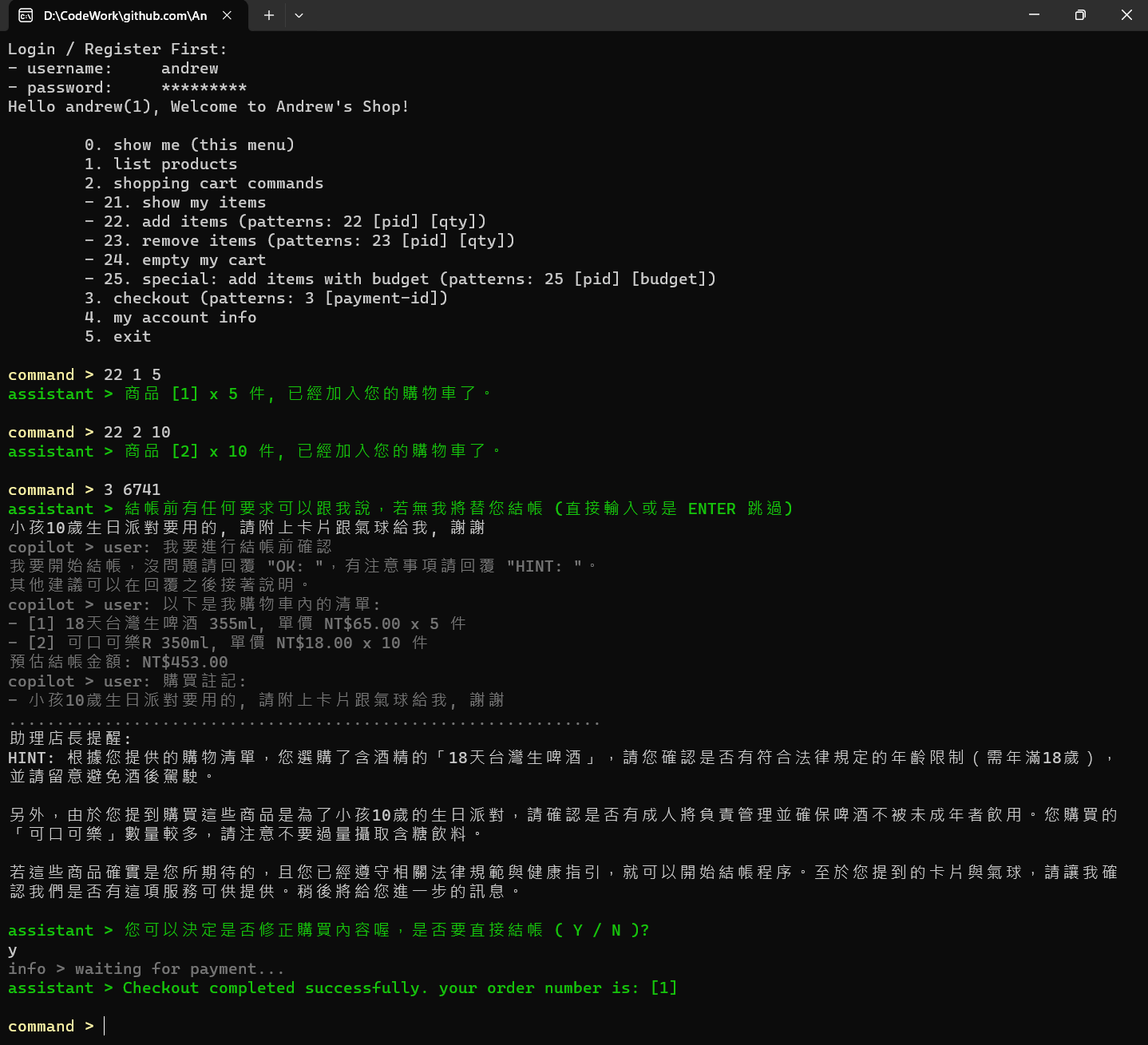
圖 2, 結帳時 AI 會提示注意事項 (點擊可以看大圖)
這邊我說明一下背後發生什麼事情,重點摘要一下流程,並且把我下的提示 (prompt) 也列出來。下正確的提示是需要技巧的,既然都包裝成應用程式了,使用者不再是直接操作 Chat GPT, 因此 prompt 應該是由開發人員決定,在背後準備好呼叫 AI 來操作才對,使用者應該無感才合理。
因此我準備了兩段 prompt, 一個是 system prompt, 定義 “店長” 的人物設定,同時我也把店長任務的 SOP 一起寫進去了 (這部分應該變成知識庫,用 RAG 來處理才對,這邊省略)。
System Prompt 的內容如下:
你是 "安德魯小舖" 的助理店長, 負責協助引導每個來商店購買的客人順利結帳。
主要任務有三類:
1. 結帳前的確認
2. 選購過程的操作過程關注
3. 回應客人的問題或是操作要求 (可呼叫 function call)
以下是這三類任務的流程說明:
結帳前請檢查下列項目:
1. 客人購買的東西是否適合他的期待? 請協助客人確認購買清單。
2. 客人的購買行為是否安全? 請協助客人確認購買行為。有些商品有法律限制,或是有可能對客人
造成危險。
3. 客人的購買行為是否合理? 請協助客人確認購買行為。有些商品可能有更好的選擇,或是有更好的折扣。
4. 檢查 FAQ 清單
5. 確認方式: 客人提示訊息會用 "我要進行結帳確認: XXX" 開頭,並且附上購物內容資訊。
沒問題就回覆 OK, 有注意事項就回覆 HINT
以下是 FAQ 清單:
1. 若購物車已經是空的,客人又嘗試清除購物車,可能碰到操作異常。請直接詢問是否需要幫助。
2. 若購物車是空的,客人嘗試結帳,可能漏掉部分操作。請直接提醒客人留意,並在結帳前主動列出
購物車內容再次確認。
3. 購買含酒精飲料請提醒客人年齡限制,法律限制,避免酒駕。
4. 購買含糖飲料請提醒客人注意醣類攝取。
5. 購買含咖啡因飲料請提醒客人注意咖啡因攝取。
6. 有預算要求,請留意折扣規則。部分優惠折扣可能導致買越多越便宜,請代替客人確認是否多買一件
真的會超過預算。
另一個 prompt 是結帳時要詢問 AI 是否有注意事項的 prompt:
我要進行結帳前確認
我要開始結帳,沒問題請回覆 "OK: ",有注意事項請回覆 "HINT: "。
其他建議可以在回覆之後接著說明。
以下是我購物車內的清單:{items}
預估結帳金額: {Cart.Get(_cartId).EstimatePrice():C}
購買註記:
- {prompt}
這段 prompt 會包含:
- 回應規則 (沒問題回 OK,有注意事項回 HINT)
- 購物車資訊,包含購物清單,結帳金額
- 購買註記,客人在結帳時留的 “購買註記”
我加了這段,目的是要善用 LLM 對語意的理解,還有常識的判斷。這些若沒有 LLM 輔助,大概很難做的好吧。自然語言處理在這邊就派上用場了。我截圖上的案例,整個 prompt 長這樣:
我要進行結帳前確認
我要開始結帳,沒問題請回覆 "OK: ",有注意事項請回覆 "HINT: "。
其他建議可以在回覆之後接著說明。
以下是我購物車內的清單:
- [1] 18天台灣生啤酒 355ml, 單價 NT$65.00 x 5 件
- [2] 可口可樂R 350ml, 單價 NT$18.00 x 10 件
預估結帳金額: NT$453.00
購買註記:
- 小孩10歲生日派對要用的, 請附上卡片跟氣球給我, 謝謝
我故意要求其他的東西 (卡片 + 氣球),無意間提到小孩。具備 “一般人” 的常識,加上 FAQ 的提醒,LLM 聯想到未成年不能喝酒的關聯,於是就給我下面這段提醒:
HINT: 根據您提供的購物清單,您選購了含酒精的「18天台灣生啤酒」,請您確認是否有符合
法律規定的年齡限制(需年滿18歲),並請留意避免酒後駕駛。
另外,由於您提到購買這些商品是為了小孩10歲的生日派對,請確認是否有成人將負責管理並
確保啤酒不被未成年者飲用。您購買的「可口可樂」數量較多,請注意不要過量攝取含糖飲料。
若這些商品確實是您所期待的,且您已經遵守相關法律規範與健康指引,就可以開始結帳程序。
至於您提到的卡片與氣球,請讓我確認我們是否有這項服務可供提供。稍後將給您進一步的訊息。
這是我第一個嘗試,我不再是整個購物流程都靠 AI 來進行了,而是在正常的操作流程中,靠 LLM 來處理關鍵需要 AI 判定的任務。而 prompt 的決定,也改為 developer 事先準備好。這樣的操作,你需要的不再是 Chat GPT, 而是需要在應用程式內使用 Open AI API, 搭配 AI 的開發框架 ( 我用 Semantic Kernel ) 來達成。
1-3, 操作過程中全程輔助
接下來,這段就是我為何要在 2024 年這時代,還搞一個 30 年前的操作介面的原因了 XDD
在思考怎麼讓現有的 APP 智慧化,我第一個想到的就是 GitHub Copilot, 相信大家都用過了吧? 我才打完一行 code, 他就猜出我想幹嘛, 然後提示一串 code, 而且命中率高的可怕, 不只語法正確, 連我的意圖都很準 (對我而言,大概有 90% 都被猜中了吧,省了我不少時間)。
除了建議很有用之外,另一個是他幾乎不需要學習 (我只有怎麼安裝跟啟用有看一下文件),因為它完全沒有改變你的操作方式,你只要如往常的寫 code, 他會躲在 IDE 背後默默觀察, 等你有需要時他自己會跳出來給你提示,你只要看到提示時決定要不要接受就好 (就按下 tab)
所以,我也在想,如果我要做 “安德魯小舖 Shop Copilot”, 程式的結構該怎麼調整? 我找了很多文章,想參考看看別人的 Copilot 怎麼寫的,程式碼架構怎麼規劃的,不過這方面的資訊少的可憐啊… 於是我就自己腦補了,有點雛型出來,我也不知道是否有更好的做法。不過至少達成我的目的了,我的 “安德魯小舖” console-ui 也開始有基本的 copilot 功能.., 就是這個段落的展示:
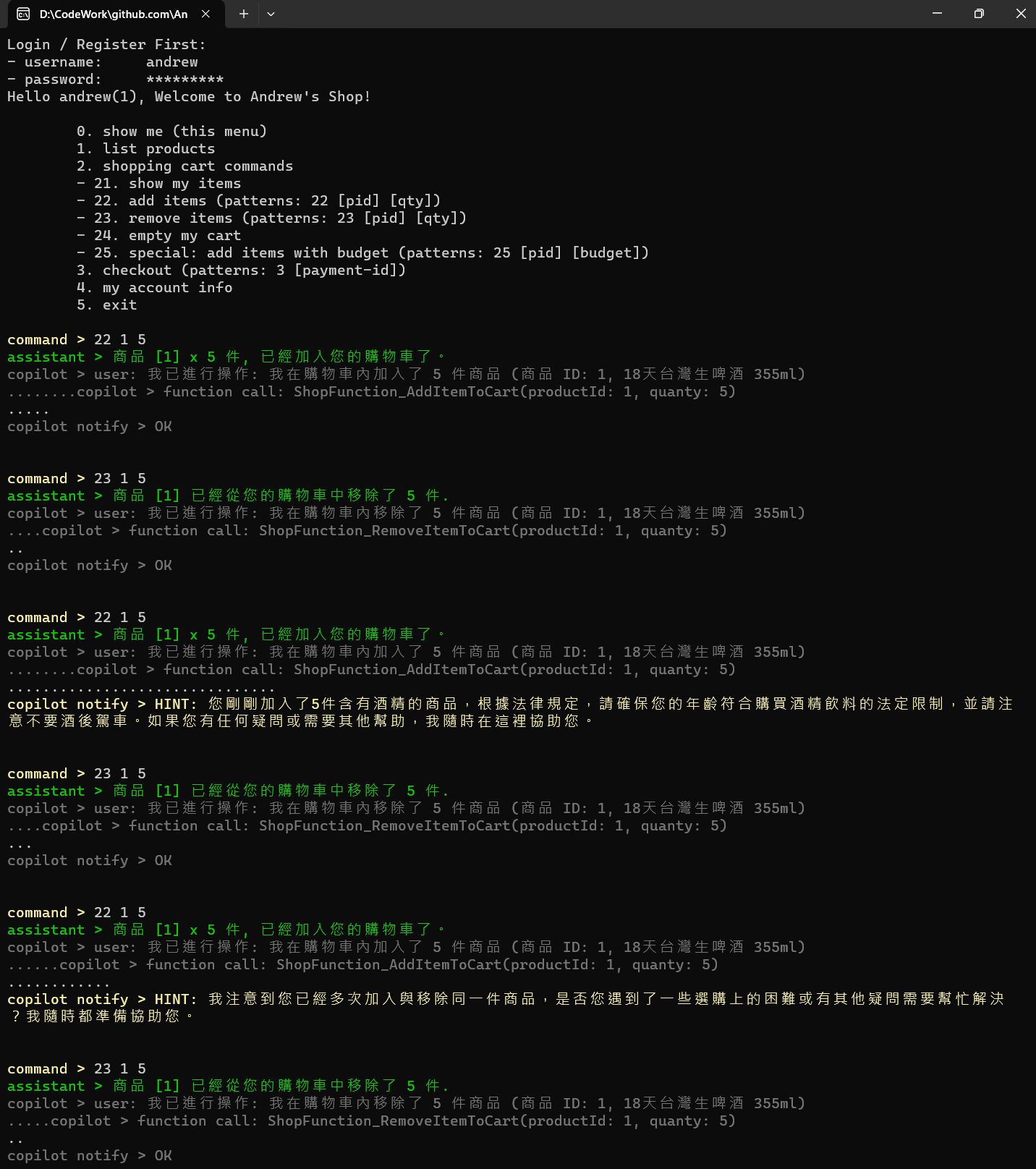
圖 3, copilot 輔助, 每一次操作都有 AI 在背後協助, 適時提醒你是否有更好的做法
我的想法是: 把客人的操作過程,都一五一十的用白話文 ( user prompt ) 跟 LLM 報告。要求 LLM 沒事就回 OK (這時 UI 就不做任何顯示),有需要注意 UI 才用醒目的提醒。
我調整了 system prompt, 加上這段規則:
選購過程的操作過程關注:
1. 如果購物車是空的,就進行結帳,代表客人可能遺漏操作步驟。請提醒客人留意,並在結帳前
主動列出購物車內容再次確認。
2. 如果客人連續加入/移除商品超過 5 次,可能是系統異常,或是需要諮詢才能決定。請直接詢問
是否需要幫助。
3. 如果客人加入購物車的商品數量超過 10 件,可能是操作異常,或是需要諮詢。請直接詢問是否
需要幫助。
4. 如果客人連續顯示操作指令清單 3 次,可能是不熟悉操作,或是找不到他要的功能。請直接詢問
是否需要幫助。
4. 確認方式: 客人提示訊息會用 "我已進行操作: XXX" 開頭,並附上操作內容。沒問題就回覆 OK,
有注意事項就回覆 HINT
UI 上客人每下一道指令,我就會送出這樣的 user prompt:
我已進行操作: {message}
而 message 內容,則是每個功能自己產生的。我就拿截圖的案例來說明。我故意重複將啤酒加入購物車,又把他移除。多做幾次 copilot 就察覺不對勁了,我略過 UI 的訊息,只留下 user prompt 跟 assistant message:
user: 我已進行操作: 我在購物車內加入了 5 件商品 (商品 ID: 1, 18天台灣生啤酒 355ml)
assistant: OK
user: 我已進行操作: 我在購物車內移除了 5 件商品 (商品 ID: 1, 18天台灣生啤酒 355ml)
assistant: OK
user: 我已進行操作: 我在購物車內加入了 5 件商品 (商品 ID: 1, 18天台灣生啤酒 355ml)
assistant: HINT: 您剛剛加入了5件含有酒精的商品,根據法律規定,請確保您的年齡符合購買
酒精飲料的法定限制,並請注意不要酒後駕車。如果您有任何疑問或需要其他幫助,我隨時
在這裡協助您。
user: 我已進行操作: 我在購物車內移除了 5 件商品 (商品 ID: 1, 18天台灣生啤酒 355ml)
assistant: OK
user: 我已進行操作: 我在購物車內加入了 5 件商品 (商品 ID: 1, 18天台灣生啤酒 355ml)
assistant: HINT: 我注意到您已經多次加入與移除同一件商品,是否您遇到了一些選購上的困難
或有其他疑問需要幫忙解決 ?我隨時都準備協助您。
效果還可以,該提醒的都有提醒,只是不知道為何第一次沒提醒我買酒的規矩,第二次就跳出來了 (這就是 LLM 不可預測性),不過我自己幻想的很美好… 如果我的 prompt 挑的再好一點, knowledge 收集的再好一點 (不一定要開發團隊來做,我也許可以整併客服資料庫,用 RAG 檢索), 如果 AI 已經是由 OS 廠商提供 ( windows / android / iOS 這些 ),而在本地端也有我的個人資訊 ( 聯絡人,行事曆,Email,筆記等等 ) 的檢索, 這些 “提醒” 可能就更個人化了。
同樣的,我自己檢視,沒有 LLM 的話,我大概做不出這些功能..
不過,做到這邊,終究也只是 “提示” 而已。接下來我嘗試讓 AI 可以幫我執行指令…
1-4, 允許透過對話,由 AI 代為操作
最理想的方案,才是像我在 “安德魯小舖” GPTs 展示的一樣,完全都透過 Agent 的介面,用自然語言溝通 (包含語音等等媒介) 來驅動的應用程式。不過,這個 Agent 不一定要是掛在 Chat GPT 這平台上的 GPTs,有更多適合 Hosting 這個 Agent 的方式。我認為較有可能能的發展,是在主流的使用者端作業系統 (目前局勢看來,就三大終端系統: windows / android / iOS ) 提供相關服務,讓應用程式 “掛” 上去,並且由 OS 提供 Agent 的存取介面。
雖然已經做過 “安德魯小舖 GPTs” 了,我還是在這個 console ui 的專案重寫了一次,讓這個版本也能接受用對話完成交易。而這些過程整合在應用程式內,好處很多,分工能更明確 (不是所有任務都適合由 AI 處理的,有些需要精準效率的仍然適合直接寫 code 處理),流程也能控制得更精準 (例如登入是必備的,我可以在一啟動就先完成登入程序),而我也可以混合手動跟自動的流程,用我期待的方式完成購物。
一樣,我貼一段示範案例:
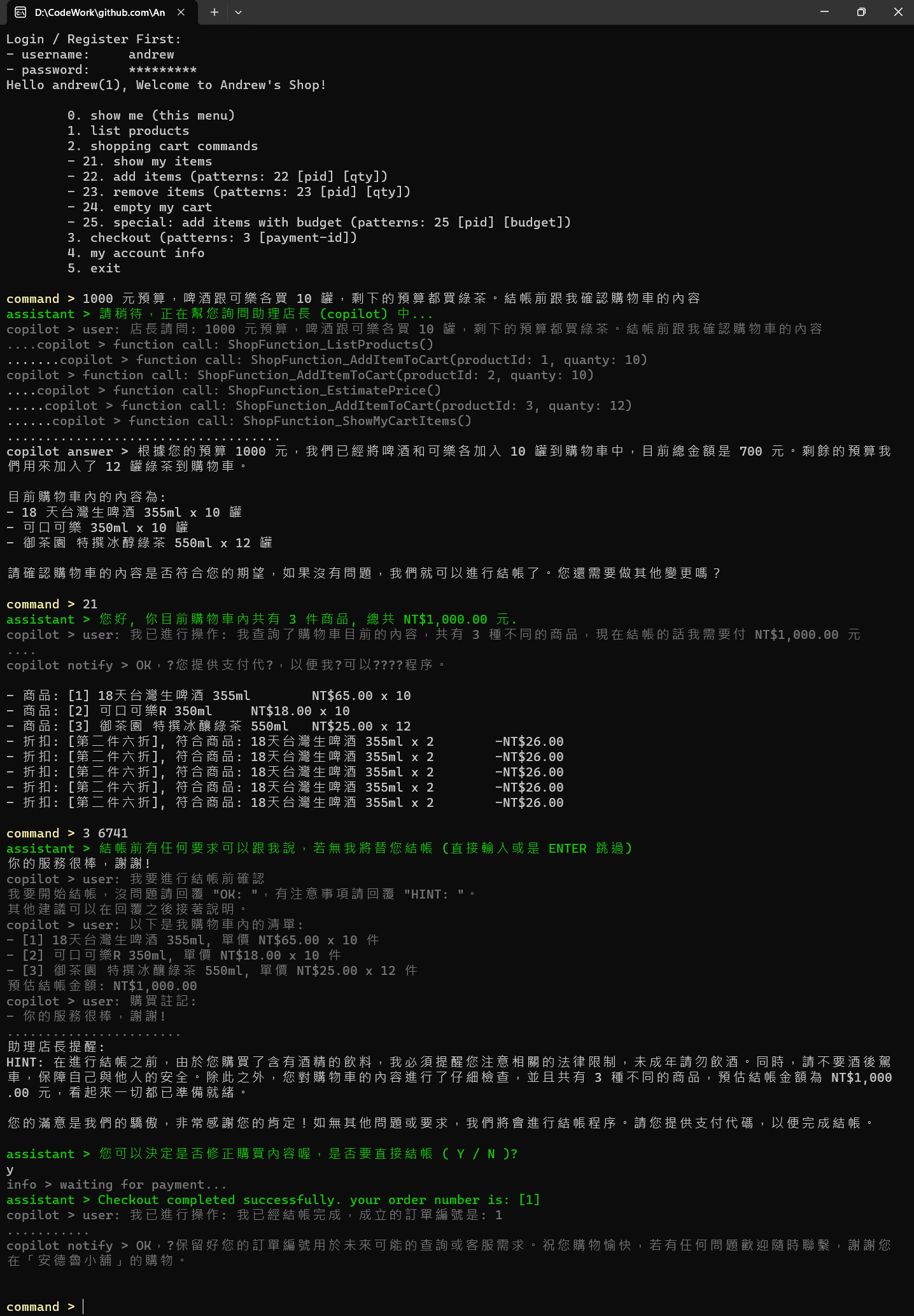
圖 4, 同樣介面也可以達成手動的效率 + AI 輔助的彈性
這段流程是這樣:
- 我直接用對話方式問: “1000 元預算,啤酒跟可樂各買 10 罐,剩下的預算都買綠茶。結帳前跟我確認購物車的內容”
- LLM 解讀我的需求後, 自行呼叫對應的 Function
- 手動下指令確認內容無誤,手動進行結帳,並且輸入感謝訊息
- 結帳過程 AI 仍然提醒購買酒類的法律限制,並且感謝我對他服務的肯定
這邊,我特別聊一下這段過程:
command > 1000 元預算,啤酒跟可樂各買 10 罐,剩下的預算都買綠茶。
結帳前跟我確認購物車的內容
assistant > 請稍待,正在幫您詢問助理店長 (copilot) 中...
copilot > user: 店長請問: 1000 元預算,啤酒跟可樂各買 10 罐,剩下的預算都買綠茶。
結帳前跟我確認購物車的內容
copilot > function call: ShopFunction_ListProducts()
copilot > function call: ShopFunction_AddItemToCart(productId: 1, quanty: 10)
copilot > function call: ShopFunction_AddItemToCart(productId: 2, quanty: 10)
copilot > function call: ShopFunction_EstimatePrice()
copilot > function call: ShopFunction_AddItemToCart(productId: 3, quanty: 12)
copilot > function call: ShopFunction_ShowMyCartItems()
copilot answer > 根據您的預算 1000 元,我們已經將啤酒和可樂各加入 10 罐到購物車中,
目前總金額是 700 元。剩餘的預算我們用來加入了 12 罐綠茶到購物車。
目前購物車內的內容為:
- 18 天台灣生啤酒 355ml x 10 罐
- 可口可樂 350ml x 10 罐
- 御茶園 特撰冰醇綠茶 550ml x 12 罐
請確認購物車的內容是否符合您的期望,如果沒有問題,我們就可以進行結帳了。
您還需要做其他變更嗎?
中間,我用深灰色,印出系統的訊息。可以看到我說了一句話之後,AI 背後就自己理解,拆解成數個步驟執行。從系統資訊看的出來 AI 理解我的意圖後,背後在嘗試替我找答案:
ShopFunction_ListProducts( )
列出所有商品,AI 可以從這邊得知品名跟商品 ID 對應關係。我並沒有給 exact match 的商品名稱,中間他有自己對應ShopFunction_AddItemToCart(productId: 1, quanty: 10)
按照我的指示,購物車加入啤酒 (id:1) x 10ShopFunction_AddItemToCart(productId: 2, quanty: 10)
按照我的指示,購物車加入可樂 (id:2) x 10ShopFunction_EstimatePrice( )
試算目前的結帳金額,我猜背後 AI 拿金額跟 1000 的差額,默默計算了剩下的錢還能買多少罐綠茶ShopFunction_AddItemToCart(productId: 3, quanty: 12)
按照我的指示,剩下的預算都拿來買綠茶,在購物車加入綠茶 (id: 3) x 12ShopFunction_ShowMyCartItems( )
按照我的指示,列出購物車清單讓我確認
其實,AI 有正確的理解語言,並且解讀意圖,對應到正確的 API + 參數,才是過去這一個月以來最令我驚訝的環節。先前用 Chat GPT 完成這驗證,這次我自己寫 code, 靠 Semantic Kernel 完成同樣的動作。中間過程的細節推演,我就留到下一章節再聊,這邊先讓各位體會這個階段的 “智慧化” 能做到什麼地步。
如果你也想了解完全在 Chat GPTs 處理這些任務,我上一篇也有同樣的案例,我把懶人包貼到這裡:
這段,就是我上一篇 “安德魯小舖 GPTs”, 我就不再重複了,你有幾種方式可以體驗 安德魯小舖 GPTs:
- 懶人包, 可以直接看完整 對談紀錄。
- 技術細節,可以直接看我這次開出來的 購物網站 API 規格
- 實際體驗 安德魯小舖 GPTs, 只要你有 Chat GPT Plus 訂閱,點這個連結就可以體驗了。我只是實驗性質,API 目前架設在 Azure App Service 下,沒有 HA,隨時會關掉。資料都是存在記憶體內,服務重啟就會清空。帳號註冊登入只是個流程,只看 username,密碼亂打都可以過。
2, 探索 LLM 應用的系統架構與開發框架
其實,這些發展的脈絡,是我自己先有個構想,嘗試與驗證的過程中,看到這篇文章,才發現我想的發展脈絡,其實 Microsoft 已經整理好並且寫成 Guideline 了 (不過 Microsoft 跳太快,直接接到 Semantic Kernel 了,我想要多補充中間的結構),我就借用一下:
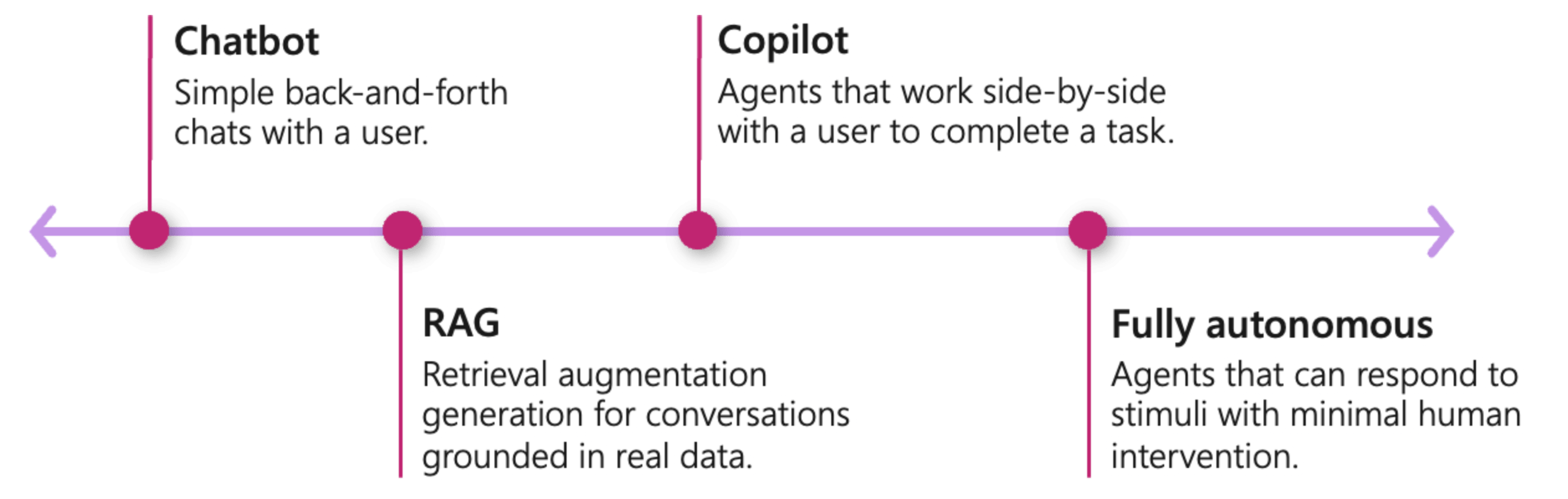
圖片出處: Microsoft Semantic Kernel / What is an agent?
文中這張圖表,對應 Agent 發展的幾個階段,正好可以跟我想像的智慧化發展階段對上:
-
Chatbot:
這階段訴求是 “對談”,透過 IM 來與 Agent 互動的形式是重點。不過這階段只有單純的對答,Chatbot 在過去幾年有很多討論,不過都在強調跟各個 IM 平台的整合與開發。我就當作對應到我的第一階段 (文字介面: 最基本的選單式的操作)。 -
RAG:
RAG 是個檢索的方式,可以讓 LLM 擴充他的 “知識庫” 的做法。不需要重新訓練語言模型,也不需要把所有的 “知識” 都塞進 prompt 內就能達到對等的效果。RAG 能將 LLM 能檢索的範圍擴大到資料庫層級。詳細的過程我下一段再說,在這階段,透過 Agent 用對話來檢索正確的知識,是主要的應用 (對應: 在關鍵環節使用 AI, 從操作意圖評估風險 )。 -
Copilot:
這個階段, Agent 應該要能 side-by-side 協助 user 完成任務,其實就是對應到我想的安德魯小舖第三階段 (從操作歷程判定使用者的狀況,即時提供操作建議),跟著使用者一步一步的操作,隨時給出適當的操作建議。Agent 應該要掌握使用者操作的過程 (APP 要在背後送操作資訊給 Agent),適時的從旁跟著使用者,引導他正確完成任務。在這階段,操作還是都靠使用者自己完成,只是有了正確的提示,再搭配 UI 操作的整合 (如果有的話),使用的體驗就會大幅提升。 -
Fully autonomous:
這個階段,Agent 應該要有 “自主運作” 的能力了。而所謂的自主運作,就如同我上一篇文章第一段,示範的 “安德魯小舖 GPTs” 一般,你只要用自然語言跟他對談就夠了,Agent 會幫你完成你想要做的事情。這背後,最主要的突破,是要讓 LLM 有能力呼叫你的 API 完成任務的相關機制。這就是對應到我講的第四階段 (全對話式的操作)。
正好,這四個階段,我的 POC 都有點到了,範例程式可以體驗一下。我的目的是概念驗證,因此為了降低我腦袋的負荷,我不擔心的工程細節我都跳過了。我在 .NET Conf 2023 那個場次講的 “降級” 思考,就是這麼一回事。
對我而言,很多工程細節,是開發過程中一定要克服的,那些事情是 “把事做對”,但是 POC 階段,更重要的是弄清楚該不該做? 關鍵是 “做對的事”。這是我選擇降級,忽略掉我不擔心的環節,把心力放在探索上面的原因。
因此,這 PoC 我用到的技術或是平台,有這些:
- 開發框架: .NET 8, C#, Microsoft Semantic Kernel (我用 1.3.0)
- API 我採用 Azure Open AI, 用的是 GPT4 model (我用 1106 preview)
- Chat GPT plus ( GPTs + Custom Actions )
而實做過程中,有些我認為該用,但是我沒往下挖的部分:
- Microsoft Semantic Kernel 的細部應用
(PromptTemplate, Planner, Memory) - Open AI - Assistant API
- Local 運行的 LLM ( LLaMa 2 chat 70B )
2-1, 加上 “智慧” 的設計框架
我是 AI 大外行,資料分析、深度學習也不是我的專長,因此我也沒辦法討論模型訓練等等很深入的 AI 議題;不過我擅長的是軟體開發,我擅長用程式碼正確的實現領域模型,因此我在過去一年都在想的是: 如果 LLM 越來越成熟,那我該如何好好運用他? 因此,我假定已知 LLM 的這些問題 (例如幻覺、黑箱、不可預測、運算資源… etc) 三年後都會被解決,那三年後我準備好擔任那個世代的架構師了嗎?
所以,這個段落,我特別想花點篇幅聊一下,我覺得現在是改變想法的轉折點,是該投入時間好好研究了。在過去 (尤其像我這類) 在軟體開發領域的資深人員,往往所有事情背後都會被拆解成明確的規則,流程,演算法,資料結構等等,然後試圖在所有問題背後都能理出一個脈絡,所有的 input 跟 output 都應該是明確的可被預測的… 但是 AI 出現後 (尤其是生成式 AI),這一切開始沒有這麼 “明確” 了。連很多 AI 的專家其實也猜不透 LLM 背後運行的邏輯是什麼,只知道餵給他足夠的訓練資料,產出的模型能回答出理想的答案而已。資料的複雜度,已經被轉移到模型的複雜度,然而 AI 專家們自己也無法掌握模型背後的運作方式..
在這基礎的觀念被打破的時候,你的 “傳統” 應用程式,該如何加入這些 “不可預測” (你無法預期使用者會問你什麼怪問題),卻又要精準執行 (你要解讀使用者的需求後,呼叫對應的 API,給對應的參數) 系統功能之間的矛盾,就變成這些資深人員需要思考的事情了。我也無法搞清楚模型背後在幹嘛,不過我至少得弄清楚它的特性,才能決定應用程式架構該怎麼設計。
我參考了 Semantic Kernel 的框架設計,也參考了 Open AI 的 Assistant API,實在很佩服訂出這些介面規格的人。它們把背後 AI 如何運作這件事,抽象化的非常清楚明確。起初我看了一堆 SK 的文章,看的一頭霧水,我決定暫停看 code,趁著過年好好地看完一些文章,了解流程後再回頭看 code 就恍然大悟了。
我強烈建議各位也花點時間理解這背後的知識,會很有幫助的。這段我花一點篇幅解讀一下它們背後的想法,你會清楚你該如何把它 (人工 “智慧”) 放到你的應用程式內。
2-2, LLM + 短期記憶 (聰明)
開始之前,先來看看對照組 (完全跟 AI 無關的應用)。典型的傳統應用程式,不外乎分成 UI / Domain / Data 三層.. 我就簡單的畫就好了:

圖 1, 標準的應用程式
再來看看最基本的 LLM, 這邊指的 LLM,只是純語言模型,沒有任何狀態。基本上就是餵給他一段提示 (prompt), 他就會給你一個回應。你給第二段提示, 他是不會記得上一次你問了什麼的,除非你拿著第一次的提示 + 第一次的回答給他,他回答就會比第一次理解你的意圖了。
這邊關鍵是 LLM 有足夠的語言理解能力,我就當作他他真的聽懂我的意思了。基本上你可把它當作正常人來對談,只是他有的只是通識,或是訓練資料內的公開知識。他的記憶力也不好,講完就忘了 (無狀態),除非你每次都要重複前面的對話內容;同時他也不見得有你需要的特定領域,或是公司內部的知識,這些都需要額外處理。
最關鍵的還是他的理解能力夠不夠強,他的記憶力差這件事很好解決,就是每次都給他完整 (或是篩選過的) 對談的紀錄 ( Chat History ), 這時, chat history, 對 LLM 而言就是維持短期記憶的機制
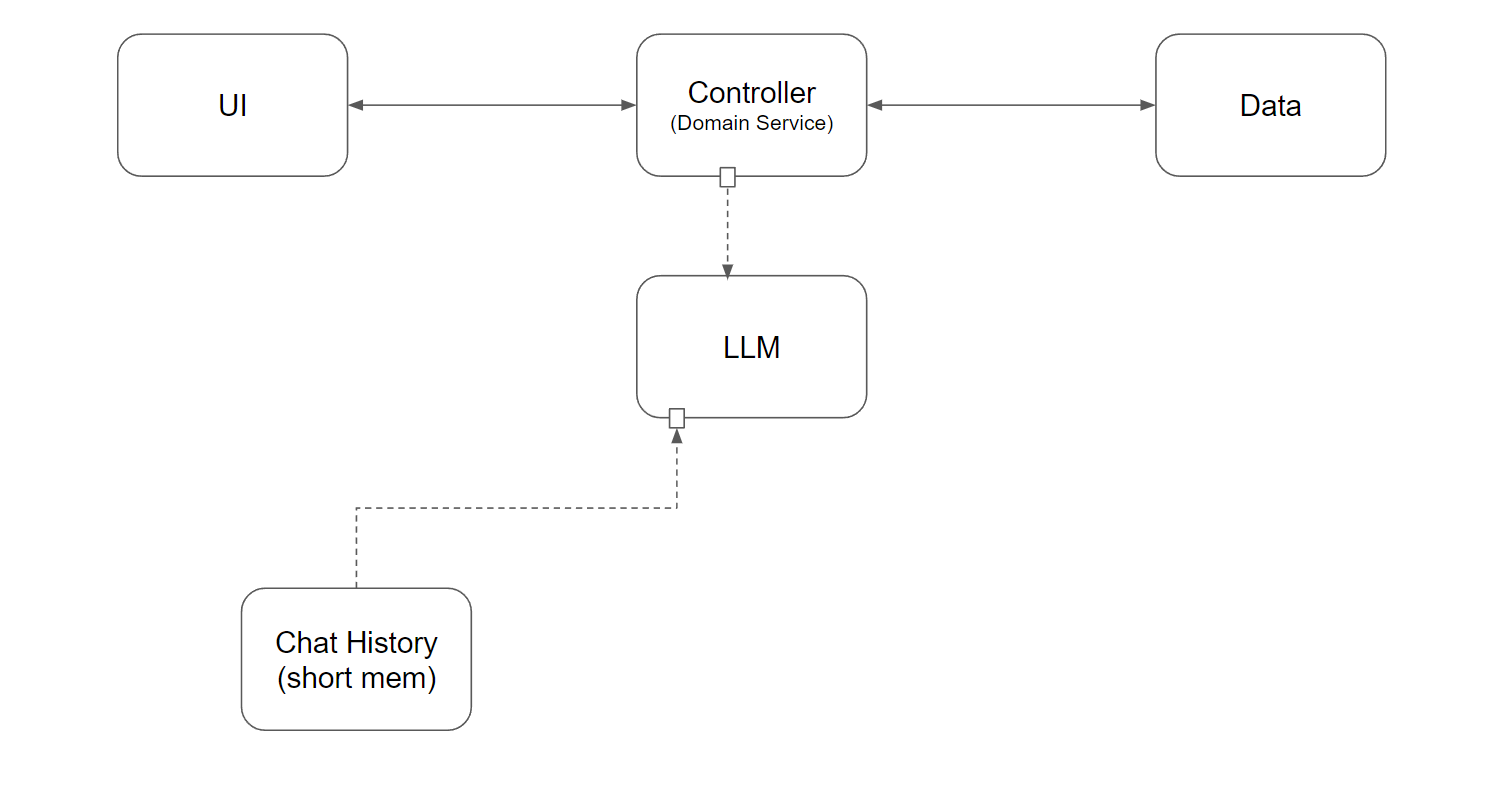
圖 2, LLM + Chat History, 有短期記憶能力的 AI
應用到安德魯小舖,短期記憶就是客人進商店後到結帳這段過程中的資訊..
2-3, RAG, 長期記憶 (智慧)
當累積的知識變多,不再能每次起始對談都把那堆知識塞進 prompt ( token 很貴的… ), 你就需要更有效率的做法了。人類在求學階段念了很多書,往後的日子會不斷的把過去學習的 “知識” 拿出來應用,這就是 knowledge。這些 knowledge 可不是原封不動一字不漏的存在腦袋,然後在腦袋裡做全文檢索… 而是你會把知識分類 & 消化,需要時你會去 “聯想” 找出關聯的知識出來用。
這過程,就是 text embedding, vector storage 以及 RAG 的運作過程。讀書的過程就是理解,對應到 AI 的處理機制,就是靠 Text Embedding Model 來把知識 (一段文字) 向量化,靠 Text Embedding Model 解讀後,將這段文字在幾千個維度的空間內標示一個向量來代表,儲存在 vector storage。每個維度代表一個知識領域,這維度的投影就代表這段知識在這個領域的關聯度有多高。
事後你問 LLM 問題之前,先把問題同樣丟給 Text Embedding Model 解讀成向量,這時只要拿著 input 的向量,到向量資料庫內做基本的過濾,加上搜尋相近的片段 (就是兩個向量之間的 cos 值,越相近數字越接近 1.0 ), 檢索出來的結果當作上下文,再交由 LLM 彙整後回傳,這就是 AI 如何在大量知識庫內快速檢索的過程,也就是 RAG (Retrieval Augmented Generation,擷取增強生成) 的運作原理。
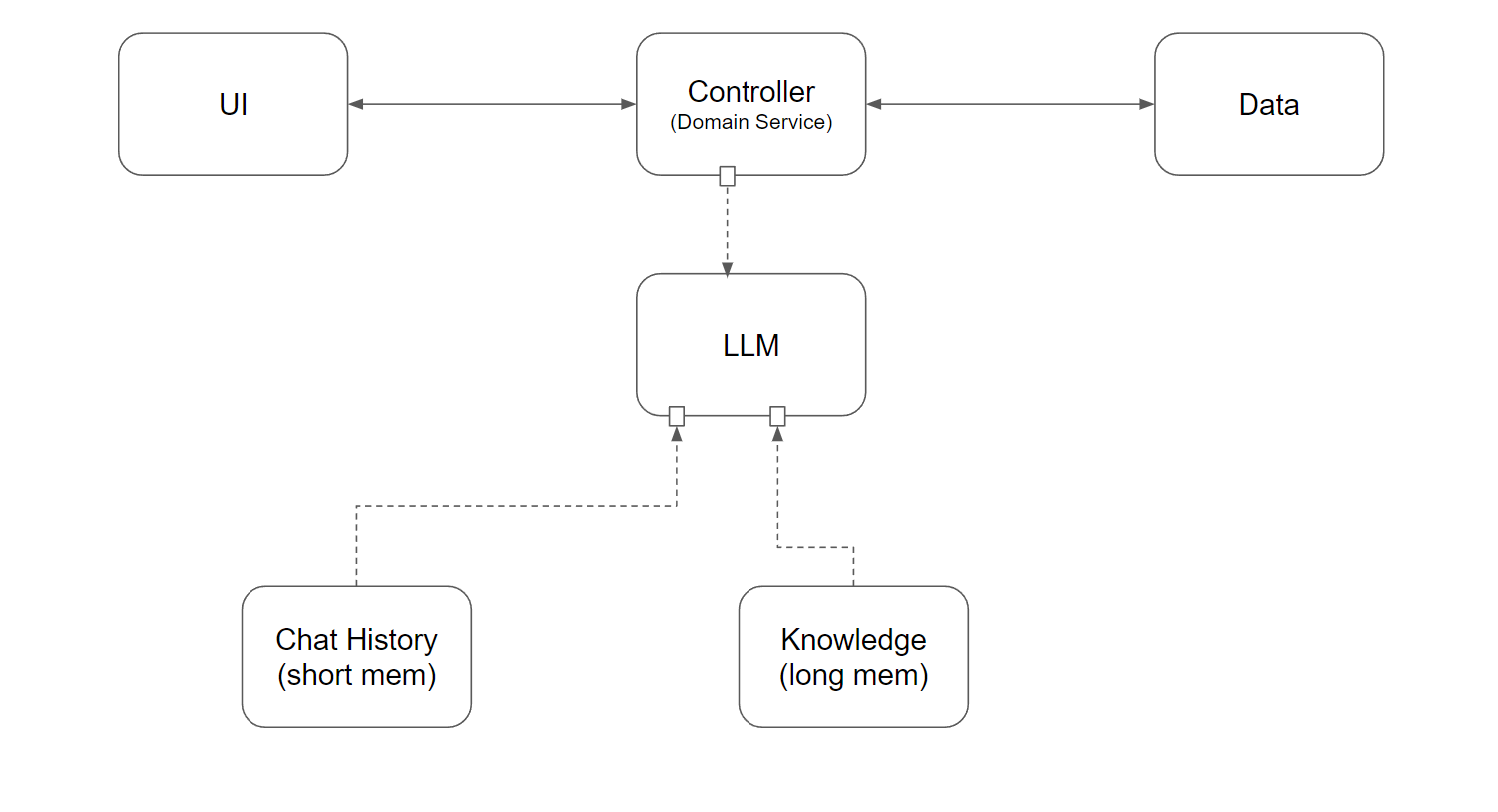
圖 3, 加上 Knowledge 知識庫, LLM 開始擁有長期記憶
其實這很符合人腦在運作的流程啊,講白了就是 “聯想” 並且從記憶內找出知識的能力。這些東西被系統化的結果,就是 AI 的長期記憶。應用到安德魯小舖,就是店長的 SOP 標準流程, 知識庫, FAQ, 或是服務紀錄等等。能力表現好的店長,可以在腦袋裡快速地檢索,立刻聯想到相關案例,當下回答客人問題或是給出理想的建議。這過程做得越到位,表現的結果就是越稱職。
參考: Retrieval Augmented Generation using Azure Machine Learning prompt flow
2-4, Skills (才能)
AI 終究不能只出一張嘴,也要會做事才行,這樣才能真正替你分攤任務。這是 Agent 很重要的關鍵,也是 LLM 開始跨入實用階段的重要突破。我就是想通這段,才搞定 “安德魯小舖 GPTs” 的。在搞懂 LLM 怎麼呼叫外部 API 前,先回想一下 “人” 是怎麼學會使用技能的..
人經過學習,練習,最終會掌握一些技巧 (Skill);而當有人對你做出請求的時候,他是用自然語言告訴你的… 你必須 “聯想” 要完成請求的話,需要用那些你學過的技能? 這過程其實跟 RAG 有點類似,但是 RAG 只讓你 “找到” 符合的知識,這邊還要正確的 “執行”。
因此 Skill 還有後面這段,當 LLM 已經決定哪個 “Skill” 能解決問題後,接著就有其他步驟要進行了。例如做衣服,當你學過裁縫後,別人請你做衣服,你就會根據你學到的技巧,你知道你需要有對方的身材尺寸才能做好衣服。於是你會去想辦法得到這些資訊 (直接丈量,或是查顧客紀錄等等),也許這過程又是另一個 Skill。不斷重複這過程,你終究可以準備妥所有必要資訊。
這時,Skill 的執行,就像是 API 呼叫一樣了,LLM 根據 input, 推測了該使出哪個 Skill (API),需要那些附加資訊 (Parameters),最後只要施展技能 ( Function Call ) 就完成了。如果技能施展後有些成果 (API return value),LLM 會把它當作上下文,彙總成白話文回答給你,這就是 LLM 幫你做事的過程。
對應到大家熟悉的 Chat GPT, GPT4 現身後,他能搜尋 internet, 他能執行 plugins, 都是靠 function calling 的能力。我上一篇文章介紹的 “安德魯小舖 GPTs”, 就是我把線上購物的 API,掛上 GPTs Custom Action, 賦予 GPTs 代替我操作購物車跟瀏覽商品的能力,最後我就能只靠一張嘴就要求他幫我完成整個購物過程,同時也完成我各種刁難的訂單內容安排的要求。
這過程很重要,這也是 LLM 開始有 “執行任務” 能力的關鍵。過去語言理解能力不足的時候,要講人話都很困難了,哪有辦法還能理解出這段話該呼叫哪個 API,該如何長出必要參數? 而在語言能力到達某個水準時 ( GPT4 達到這水準了 ),這門檻跨過了,就開始有透過對話執行任務的能力。
有興趣的話,可以看一下 Open AI 這篇,很有條理地說明了 Function calling 的過程。
因此,學習到的 Skill, 應該要能像 Knowledge 一樣,學過就被註冊記錄下來。每個 Skill 也有白話描述他是做什麼用的 (說明書?),也有參數定義跟說明,以及傳回值的定義跟說明。而組成這一切,就是靠 LLM 的語言理解能力,以及自然語言與結構化資訊轉換的能力。
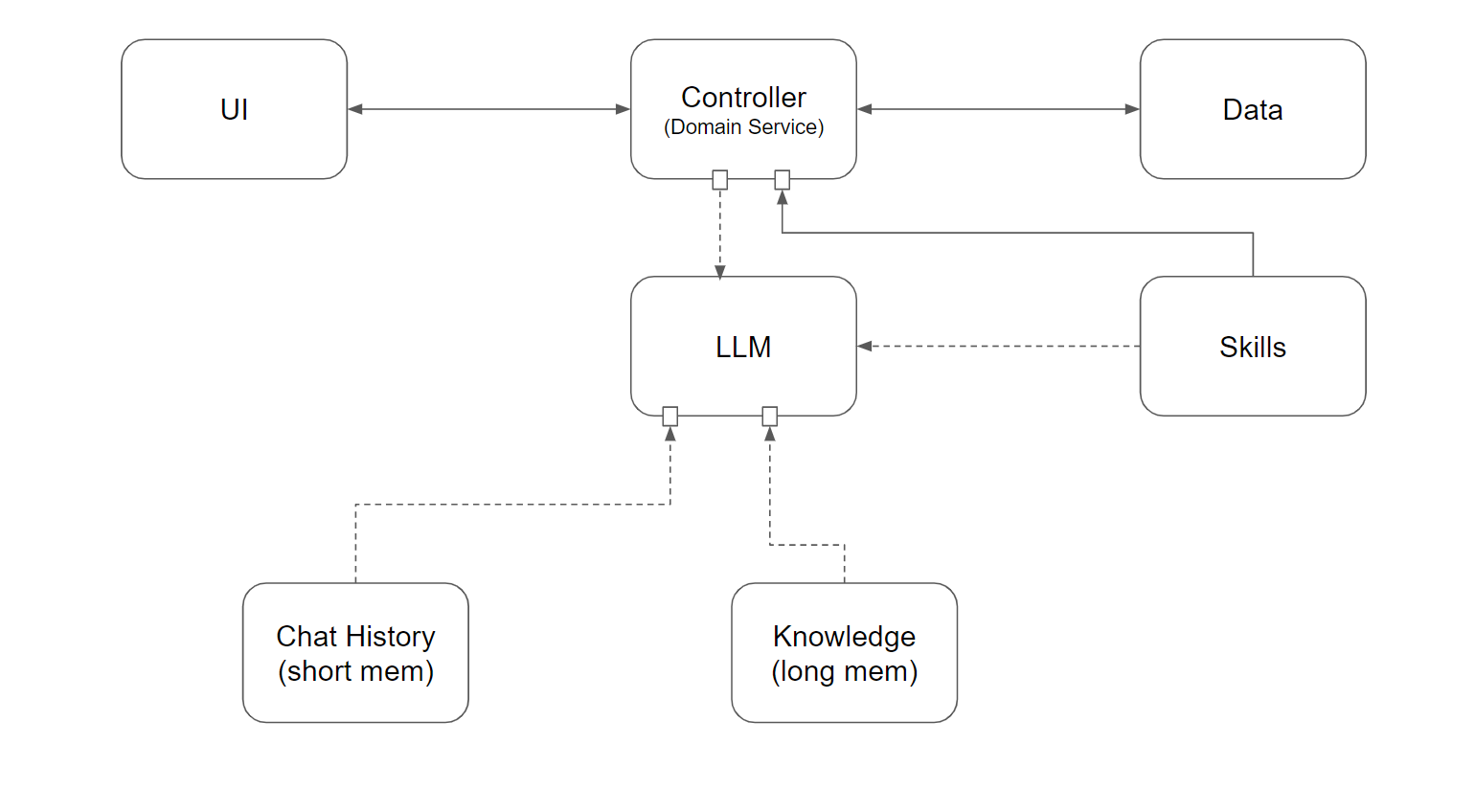
挖到這邊,LLM (大腦) + Chat History (短期記憶) + Knowledge (長期記憶、知識) + Skill (技能),整個整合好之後,這整組服務就能對自然語言的輸入,做出正確的回應,或是執行正確的動作了。
2-5, Persona (人格)
最後,我把沒提到的環節補完吧。Prompt Engineer 都會提到的技巧 - Persona, 角色設定,我把他補上去了:
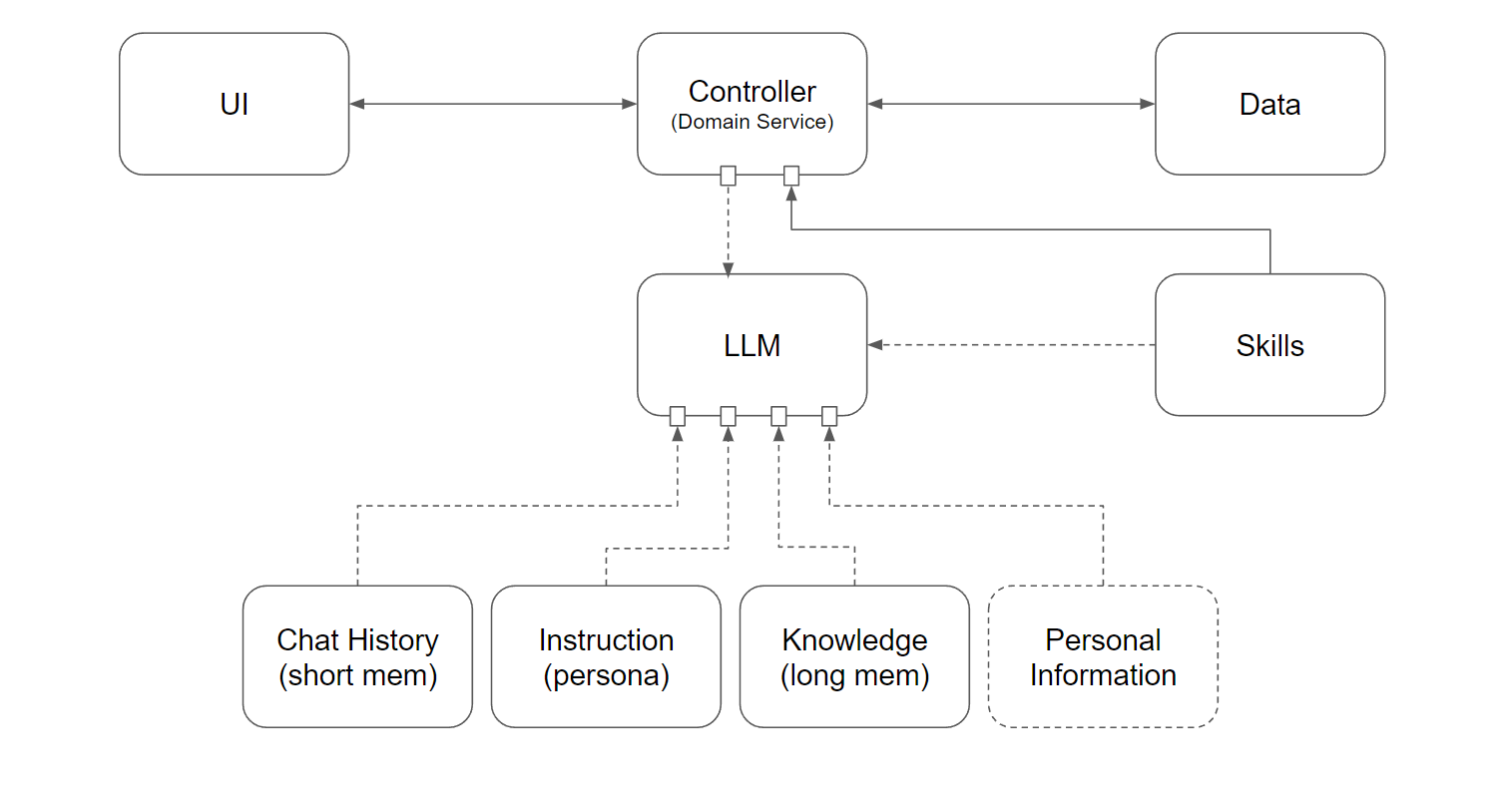
不知道有沒有人記得這部電影? MIB… Will Smith 把人的記憶消除後 ( reset 記憶 ),會掰一段人物設定,跟時空背景。被消除記憶的人聽完就會認為他是那樣的人… 於是就乖乖地扮演這角色了。LLM 先天就沒有狀態 (記憶),所以這些人格設定,反而是你 “必須” 給他的。
通常會有兩個部分,一個是你要告訴 LLM,Agent 是什麼角色,該做什麼,不該做什麼,稱作 Persona, 或是 GPTs 的設定內的 Instruction。而另一段是告訴 LLM 你自己是誰,想要聽什麼樣的資訊,GPTs 會盡量講你想聽的話,這在 Chat GPT 內是擺在 “Customize ChatGPT” 這功能內。
我的想像,如果以後主要的 LLM 是由作業系統來提供 (就前面提到, windows / android / iOS 這些廠商), 而這些個人化的設置, 就有更多的可能性了。你的瀏覽紀錄,行事曆,聯絡人等等,可能都會是本地端 RAG 檢索的來源,這邊就是廣義的 “個人化” 了。在圖上我用 Personal Information 表示。
不過,這些都還不是我這次要探索的範圍,因此我的 demo 都略過了,只是簡單地把這些資訊,用有限的文字描述,直接放在 prompt 裡面。你可以想像我把這些都簡化成你跟陌生人聊天,前幾句話都是 “自我介紹” 那樣而已,就足以應付我目前的情境了。
2-6, 開發框架全貌
寫到這邊,不知道你有無看到重點? 這邊我都在理解怎樣在軟體架構設計內,合理的把 AI 也放進去的思路。除了 LLM 最核心,最難理解 LLM 怎麼能搞的懂自然語言之外,其他都是基於這核心,用很單純的系統化做法把外圍的資訊都串起來。你會發現沒有 LLM,這一切都沒有用了。
從 LLM 往外延伸,有志往這領域鑽研的朋友們,一定要掌握的關鍵技巧,我認為有這兩個:
- 提示工程 (Prompt Engineering),這是你操控 LLM 的關鍵能力
- Skill / Plugins 的設計與開發能力,這是你能賦予 LLM 多少招式的另一個關鍵能力
如果 LLM 是核心,圍繞著 LLM 最原始的 input, 就是自然語言。回頭看看 1-2, 1-3 兩個案,這兩個案例的關鍵都不是程式碼 (程式碼單純的是把 message 丟給 LLM, 拿回傳值判斷是不是 OK 而已),而是你對 LLM 下了什麼樣的提示? 需要包含哪些資訊? 這些資訊給太多會很慢,也很貴 ( token 直接影響到速度與費用 ),甚至會影響到 LLM 回應的品質。Prompt Engineering 會是你要好好運用 LLM 的必修科目。
我在寫這段的時候,我刻意避開了不必要的實做細節,大致都只談到結構上該怎麼做而已。實做上大致就分兩派,一種是在 cloud 通通都幫你做好,你只管拿 APIKEY 呼叫 API 就好的方式 (PaaS), 例如 Azure Open AI 就屬於這種。另一種是把上述的處理結構都抽象化,變成一個開發框架,讓你自己去組合你要的元件 (你要哪種 LLM,哪種向量資料庫 … 等等),我多次提到的 Microsoft Semantic Kernel, 或是 Lang Chain 就屬於這種。
當初我就是沒先想通這一段聊的內容,就直接看 SK 的開發文件,最後搞得一頭霧水.. 現在再回過頭來看這張圖,突然之間都清楚了:
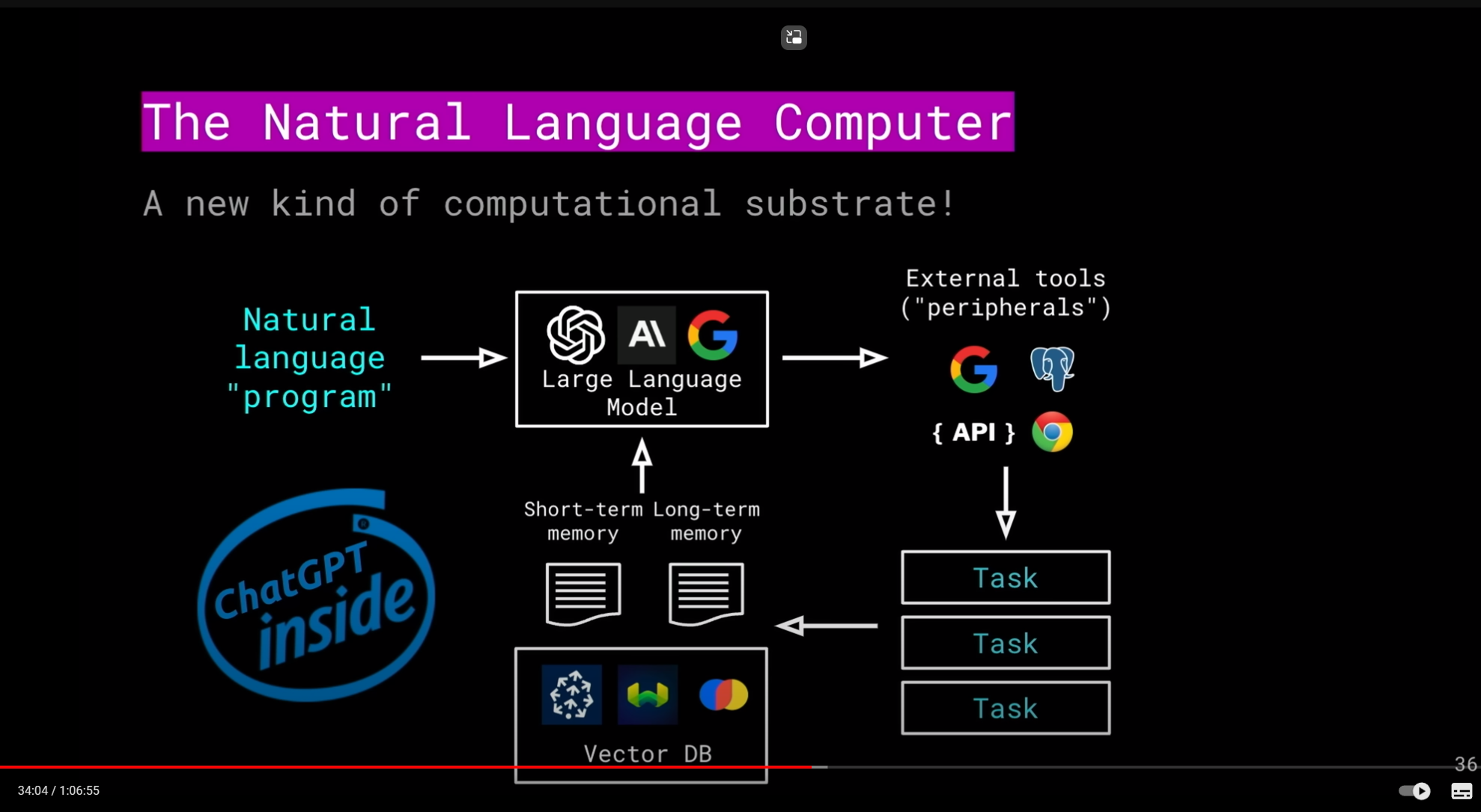
來源: Large Language Models and The End of Programming - CS50 Tech Talk with Dr. Matt Welsh
這邊的關鍵是: 自然語言 (prompt), LLM, API, Task (Orchestration), Vector DB, 其實講的就是前面列的幾個主要元件的組合啊。再看看 Semantic Kernel 相關的介紹 ( 我找到一篇 Build 2023 的場次 ) 就更貼切了:
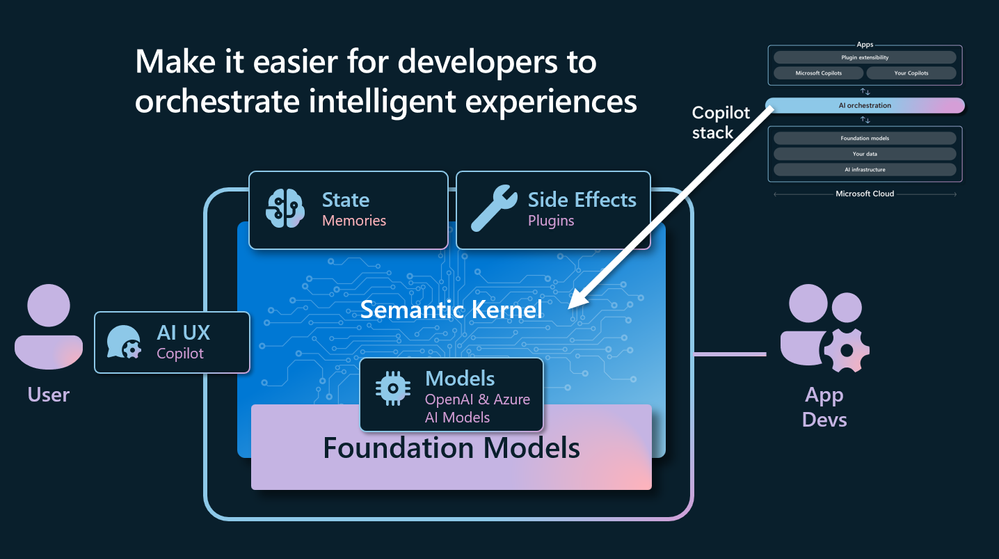
來源: Want to build a Copilot for your app? Semantic Kernel & Prompt Flow for Beginners
Microsoft Semantic Kernel 的這張圖, 就把我這次的 POC 都涵蓋進去了。從左到右來看:
-
AU UX: Copilot
其實就是對應到我重新改寫的 console-ui, AI 呈現到眾人面前的, 不會只有 “Chat” GPT, 而是可能隱藏在各種大家熟悉的 APP 內,這才是 AI UX。而 Copilot, 則是在 APP 智慧化的進化過程中會出現的一種樣貌,也是 Microsoft 接下來這幾年各大主要產品線的重頭戲。 -
Semantic Kernel
不意外,就是整合所有 AI 必要元件的開發框架。整個 SK 涵蓋了整個 APP 的開發 ,包含了幾個關鍵元件: Model, State, Side Effects.. 上面的那段話就貫穿了全貌,SK 就是讓開發者能夠整合這些智慧應用的利器 -
Models
講更具體一點,LLM (大型語言模型),或是文字轉圖形、聲音等等模型都算。SK 提供了各種 connector 來抽象化這些模型的應用,可以連接多種模型,包含本地端運行,也包含透過 API 開 放的模型。你不必遷就特定的模型,就必須使用特定框架或是 API。 -
State / Memories
前面提到 RAG, 以及向量資料庫。向量資料庫就是 AI 儲存 “知識” 的地方,在 SK 內就是把它抽象化成 “記憶” ( Memory ),同樣的提供多種選擇與實做。你不必因為使用了某種向量資料庫,就要改變整個應用程式的寫法。 -
Side Effects / Plugins
就是我前面提到的 Skills, SK 在 1.0 之前,就是使用 “Skill” 這名詞,來描述你的應用程式,賦予了 AI 那些 “技能”。在 1.0 release 後改成 Plugins 這個比較工程味道的用語了。不過我個人比較喜歡 “Skill”, 在描述 AI 時,各方面來看把 AI 當作 “人” 來溝通會更容易理解,這時 Skill 比 Plugins 貼切多了。我一直覺得 Model 跟 Plugins 是相輔相成,Model 不夠成熟我根本不敢給他任何 Skill … 而有了 Skill 的 Model 才是個有才能的 AI,而不是只能出一張嘴的半殘角色。
其他都相對好理解,我真正想談的就是 Plugins, 我把前面 1-4 示範案例中,提到的 functions 片段程式碼貼出來 (這篇唯一的 source code 解說就這段了):
[KernelFunction, Description("清空購物車。購物車內的代結帳商品清單會完全歸零回復原狀")]
public static void ShopFunction_EmptyCart( ) { ... }
// Cart_AddItem
[KernelFunction, Description("將指定的商品與指定的數量加入購物車。加入成功會傳回 TRUE,若加入失敗會傳回 FALSE,購物車內容會維持原狀不會改變")]
public static bool ShopFunction_AddItemToCart(
[Description("指定加入購物車的商品ID")] int productId,
[Description("指定加入購物車的商品數量")] int quanty) { ... }
// Cart_RemoveItem
[KernelFunction, Description("將指定的商品與指定的數量從購物車移除。移除成功會傳回 TRUE,若移除失敗會傳回 FALSE,購物車內容會維持原狀不會改變")]
public static bool ShopFunction_RemoveItemToCart(
[Description("指定要從購物車移除的商品ID")] int productId,
[Description("指定要從購物車移除的商品數量")] int quanty) { ... }
// Cart_EstimatePrice
[KernelFunction, Description("試算目前購物車的結帳金額 (包含可能發生的折扣)")]
public static decimal ShopFunction_EstimatePrice( ) { ... }
[KernelFunction, Description("傳回目前購物車的內容狀態")]
public static Cart.CartLineItem[] ShopFunction_ShowMyCartItems( ) { ... }
// Cart_Checkout
[KernelFunction, Description("購買目前購物車內的商品清單,提供支付代碼,完成結帳程序,傳回訂單內容")]
public static Order ShopFunction_Checkout(
[Description("支付代碼,此代碼代表客戶已經在外部系統完成付款")] int paymentId) { ... }
// Product_List
[KernelFunction, Description("傳回店內所有出售的商品品項資訊")]
public static Product[] ShopFunction_ListProducts( ) { ... }
// Product_Get
[KernelFunction, Description("傳回指定商品 ID 的商品內容")]
public static Product ShopFunction_GetProduct(
[Description("指定查詢的商品 ID")] int productId) { ... }
// Member_Get
[KernelFunction, Description("傳回我 (目前登入) 的個人資訊")]
public static Member ShopFunction_GetMyInfo( ) { ... }
// Member_GetOrders
[KernelFunction, Description("傳回我 (目前登入) 的過去訂購紀錄")]
public static Order[] ShopFunction_GetMyOrders( ) { ... }
這些,是我在這個專案內,所有的 Skills 清單。我只保留了 method 的簽章, 實作我拿掉了, 那個不重要。C# 的語言提供的 attribute 機制非常適合來應付這種場合,而 SK 也的確把它運用的很到位。這些 method 都被標上了 [KernelFunction], 而包含這些 method 的 class 或是 instance 被註冊到 kernel 後,就正式變成能讓 Model 支配的 “技能” 了。
怎麼註冊? 很簡單,在 init 的階段,把這個 type 掛上 SK 的 kernel plugins 就行了:
var builder = Kernel.CreateBuilder()
.AddAzureOpenAIChatCompletion("SKDemo_GPT4_Preview", "https://andrewskdemo.openai.azure.com/", config["azure-openai:apikey"]);
// 上述這些 ShopFunction, 都放在 Program 這個類別內。只要註冊這個類別就可以把所有標示 KernelFunction 的 method 都掛上去
builder.Plugins.AddFromType<Program>();
_kernel = builder.Build();
你可能會問,LLM 怎麼會 “理解” 這些 Skill 怎麼使用? 是拿來幹嘛用的? 別忘了 LLM 的專長就是 “理解自然語言”,不論這自然語言是使用者提供的,或是開發者預先準備好的 prompt,只要是自然語言都在它處理範圍內。SK 就是靠這些 method 與 parameters 上面的 [Description(...)] 描述,當作他的 prompt.
而 LLM 解讀後若需要呼叫,SK 就會有一連串的機制 (這就是開發框架的威力) 來幫你呼叫這個 method。因此,這部分的說明請認真的寫,並且要經過測試與調整。文字敘述 (prompt) 寫得好不好,完全影響了 AI 解讀能力是否正確。
回頭想想,LLM 怎麼 “找到” Skills? Skills 越多就越好嗎? 不是這樣的。Skill 貴不再多,而在精。就如同我前面幾篇都在聊 API 設計,跟 領域模型的對應一樣,Skills 廣義的說就是讓 LLM 呼叫的 API 啊。LLM 擅長的是自然語言,還有通識知識,你弄了大雜燴的 API 給 LLM,給得越多只是讓 LLM 有越多機會搞錯而已。這邊不下功夫,你會發現掛上越多 Skill, 你的 “智慧” 應用程式會越來沒有智慧,因為它會一直放錯招…
這部分的探討,我在上一篇其實已經提過,有興趣的朋友可以回頭看看這一段:
在 ChatGPT 設計 GPTs, 其實也有類似的設計,只是 GPTs 的對象是 API, 而不是 code 內的 function, 因此他採用 swagger 的描述檔案來做同樣的事情。Swagger 描述已經包含了所有 API 規格清單,裡面的 “description” 也會被拿來當作 LLM 理解的內容。標記與運作方式雖然有差異,但是精神跟結構關係都是相同的。
當這些都準備就緒,也都 init 完成後,把這一切串再一起,很神奇的,這一切就動起來了。上面的 PoC, 就是這樣做出來的。搞定這一步,SK 的主要功能就算踩過一次了,腦袋裡開始能掌握 SK 整個開發框架的樣貌了,接下來才是開始看規格,說明文件,與嘗試各種擴充元件的使用方式。如果你還沒想通,可以回頭再看一次,同時參考我的 source 對照著解讀看看。
最後,視角再拉大一點,整個應用程式的架構全貌,這篇文章說明的不錯,視角不大一樣,但是就是把上述的流程與架構勾勒的更具體。不習慣的是這張圖是從右 ( user ) 到左,我上面的圖都是從左到右..
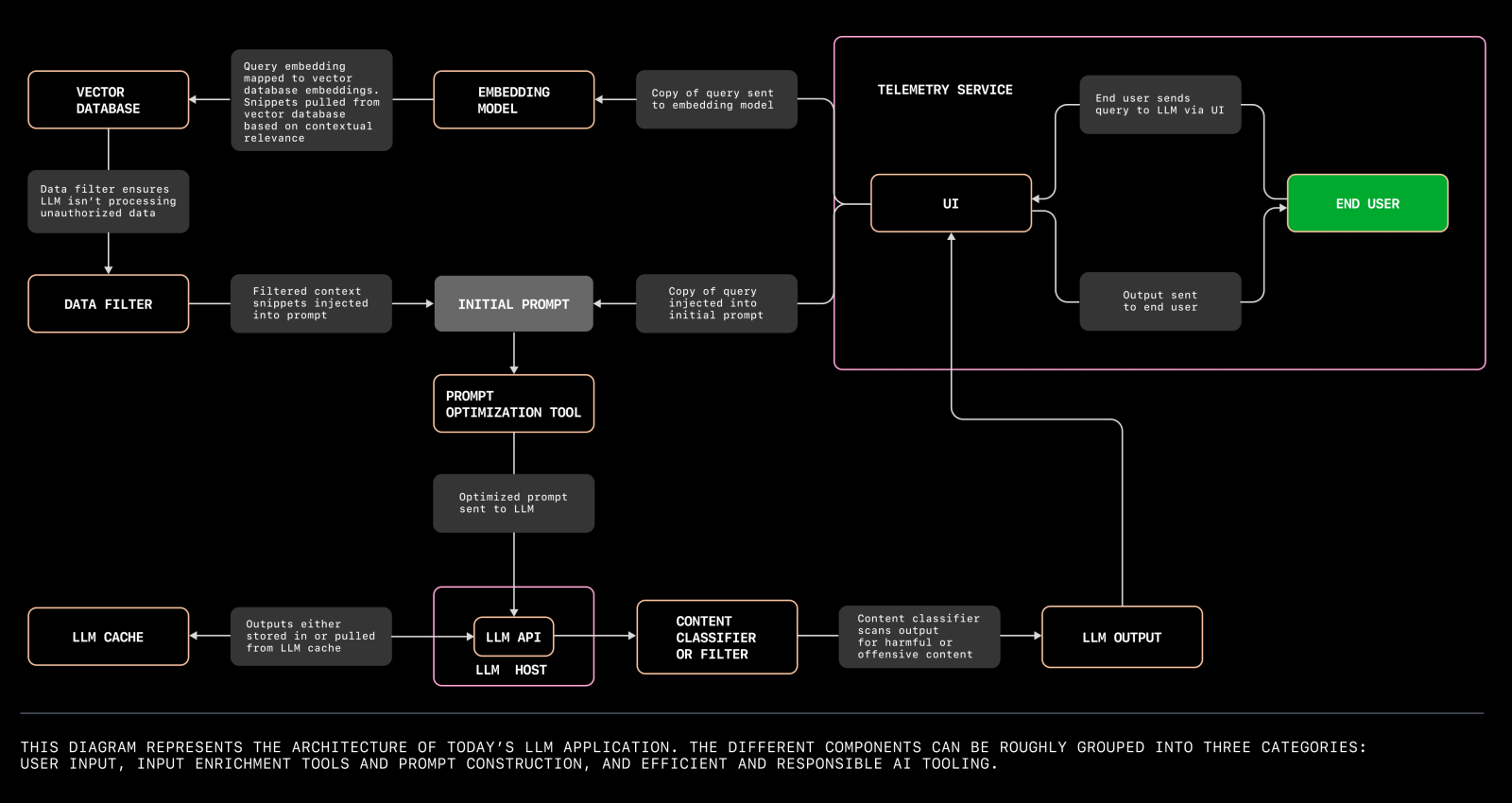
3, 未來的發展 (個人觀點)
這一段就單純心得感想,聊聊我自己個人,對未來 AI 帶來的影響的看法吧。
首先,其實去年底,2023 最後一個小時,我 PO 了 這篇 時,我就在想一件事:
- 過去,大家都靠 stackoverflow 找 code 來用.. ( copy & paste )
- 現在,大家開始靠 Chat GPT 產生 code 來用.. ( copy & paste )
- 現在,大家開始靠 GitHub Copilot 來幫加速 code .. ( tab & accept suggestion )
其實,AI 已經有能力 “產生” 夠水準的 code 了, 如果再多一步, 還能自動 build & deploy 呢? 如果 AI 還能自動執行 code 呢?
想到這邊,我不禁繼續往下想:
-
如果 AI 已經能正確地幫你 (產生 code) 呼叫正確的 API, 以後的程式開發,還需要 developer 明確的呼叫 method ( 附帶正確的 parameters ) 嗎?
-
如果不是明確的由 developer 呼叫 method, 那會變成什麼? 丟正確的 Prompt 嗎? 如果…
補充: 後來才發現,其實現在 Chat GPT 已經有部分功能是這樣做的了,有訂閱的用戶可能會看到有個功能叫 “code intepreter”, 當你問的問題需要的時候, Chat GPT 會在背後按照你的需求寫一段 python code, 然後若你有啟用 code interpreter, 就會啟動一塊安全的 sandbox 環境, 來跑這段 code 替你下載、分析資料等等其他用途。
補充: 某種程度上,Semantic Kernel 的 Planner, 也踩到了一部分的功能,他能將 prompt 拆解出來的多個任務 (可能是呼叫多個 kerenel function) 安排執行,角色上像 kernel function(s) 之間的 orchestration。我在這邊提他,跟 AI 寫 code + 執行無關,但是它包裝了部分 AI 解析 prompt, 判定呼叫 kernel function 的整個流程 (如果有多個步驟的話)
想到這邊我就沒有再繼續想下去了,我知道到這個階段的時候,就真的變成 “完全” 用嘴巴寫程式了。也許未來的程式語言,已經是自然語言了 (其他語言可能還會存在,但是比例應該會逐步降低);對比 C#, 未來的自然語言的 CLR ( Common Language Runtime ) 也許就是 LLM 了;未來的程式開發技巧,軟體工程,就是提示工程 ( Prompt Engineering )…
在做這次的 PoC, 其實已經隱約感受到了,搭配 Semantic Kernel, Code 寫起來的模式已經很固定了, 都是由各種管道取得 prompt / message, 包好後送給 chat completion service, 然後解析傳回來的資訊而已。這些 code 未來應該越寫越少了,可能都內建。反倒是開發過程,有幾個關鍵的功能都是靠 prompt 做出來的 (例如我給店長的 instructions, 結帳前的檢驗 prompt, 或是 copilot 檢驗使用者操作步驟的 prompt…)。要到完全用自然語言寫 code, 還要很久吧 ( 10 ~ 20 年,我猜 ),不過這趨勢應該不可逆了,年輕的朋友應該先做好準備。Developer 未來主要的任務也許不再是 coding 了,但是 developer 還是 developer,終究有人要替應用程式定義 prompt,所以我不擔心 developer 會消失,但是使用的工具一定會改變,背後需要的技能也會改變,如此而已。
回到主題,用 prompt 寫 code;因為我把過程串起來了,因此我更相信這是可行的,只是差在人類的硬體製造工藝能力還沒到位。目前 method invoke 速度很快,不需要 1 ns 就能執行完畢了吧? 一秒鐘呼叫個 1000 萬次不是問題。而 LLM ? 現在一秒鐘能消化 100 個 token 就很了不起了,運算成本天差地遠 (有在用雲端就會很有感)
我還在念書的年代,當時學的組合語言,當時想說 640kb 有限的記憶體只能用組合語言才能充分運用 blah blah.. 直譯式的語言在那個年代被當成玩具看待 ( Basic, 4GL, 那年代的直譯式語言只能處理資料,上不了正規應用程式開發的檯面的。主流是 C / C++).. 到了現代就完全不是這麼一回事了啊 XDD, 會不會未來的發展,過了 20 年,用自然語言寫 code 已經變成再自然不過的事情?
念書的時候,指導教授教我們物件導向設計 ( OOP, Object Oriented Programming ), 用的語言是 Small Talk… 當時一段話我印象深刻 (找不到原文了,只能憑印象):
物件之間的溝通,是靠 message passing
但是,當時所有的主流 OOP 程式語言,都是 object.method( ) 這樣,用 function call 的做法來實做物件之間的溝通,只有 Small Talk 真的丟一個 message 過去,由另一個物件接收到後 “自己” 決定怎麼回應。非常有彈性,彈性到同一個類別的不同 instance,都可以有完全不同的行為 (某種程度的不可預測)… 彈性到這個語言只拿來被學術應用,彈性大到能適應各種狀況,但是執行效能慘不忍睹…,導致不適合被用在生產環境上… 不過也因為這些學術研究,才有後來的 Java, C# 等這類兼顧各種特性,集各種優點於一身的新語言與新 runtime .. 我們現在不就大量的使用這樣強大威力的語言在開發各種系統嗎?
這段印象,現在看來,不就是 Prompt 跟 LLM 之間的關係嗎? 因此,我無法預測這些 LLM 的問題會被什麼樣的方式解決,但是我猜他應該是會被解決的,而且會成熟到能大量應用在關鍵的運算上。照這樣發展,我覺得這次應該不需要 20 年了,10 年差不多,到時 AI 的運算能力,語言模型的優化,等等問題應該都被解決掉了,成本跟效率優化到某個程度,應該這條路就被開啟了。
前陣子看了一段文章 影片,有人問到 speaker: LLM 的不可確定性 blah blah .. (這已經是 FAQ 了,以下省略),我覺得那位 speaker 回答的還蠻妙的:
企業在面試工程師,沒有人能保證你短短幾小時面試過程中,挑選出來的人,每件事情都能做的很到位,寫 code 沒有 bug, 部署不會出錯等等,但是我們錄用他了。因為我們覺得他有潛力,能把事情做好,我們可以容忍他有一定的犯錯空間。
人類所有企業都這樣用人,人類沒有因此而毀滅,人類的社會文明也這樣持續的進步。
LLM 會犯錯,行為不保證一致,但是我們認為他有潛力,能把事情做得更好。同樣的事情發生在 AI 上面,組織 & 系統的運作能夠承擔這樣的差異,世界會持續的進步。因為過去幾百年來人類就是這樣發展起來的,AI 也可以
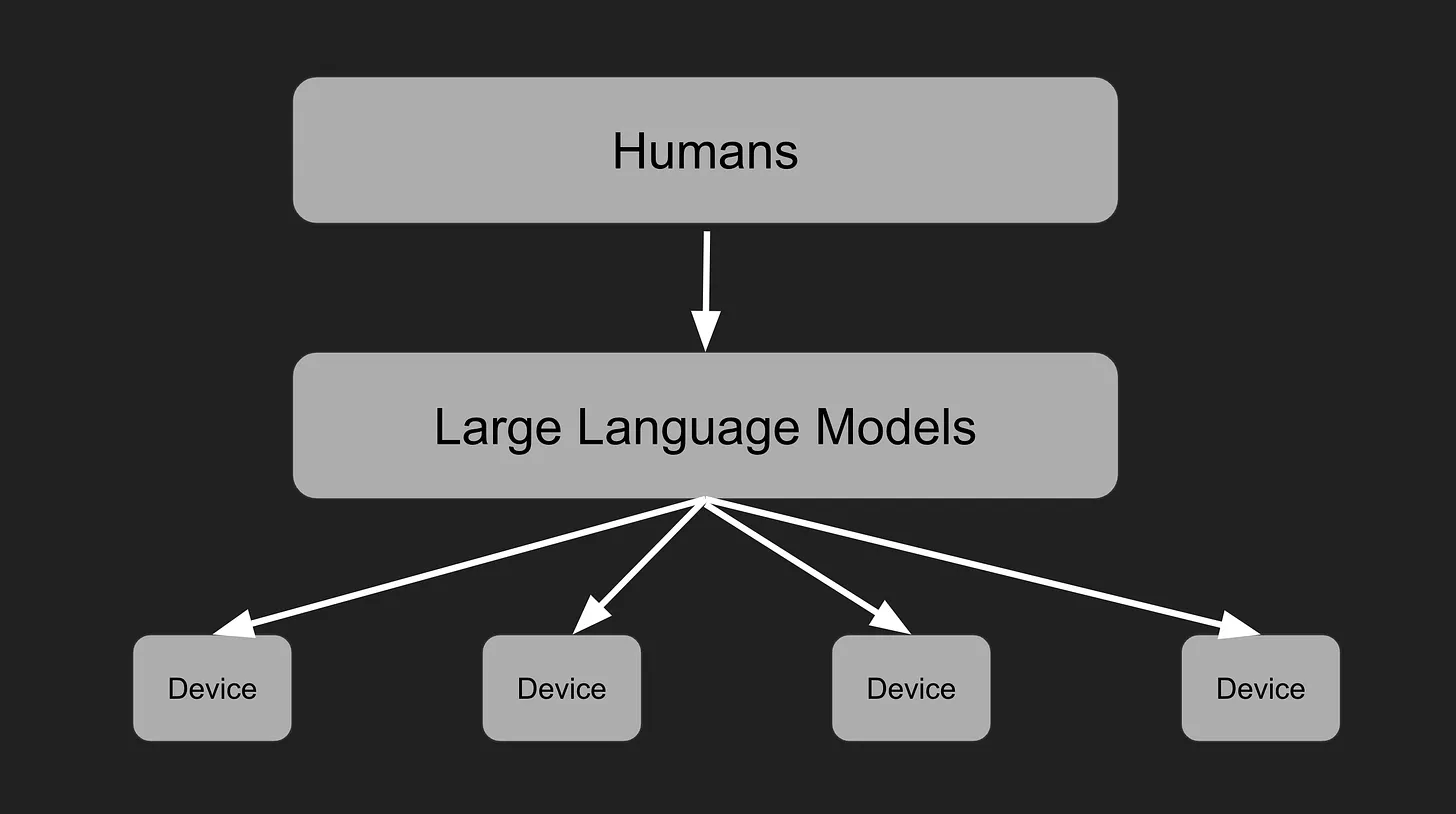
來源: Large Language Models and The End of Programming - CS50 Tech Talk with Dr. Matt Welsh
另外,這篇文章也有類似的觀點,蠻有意思的,可以花點時間讀一下:
“The End of Programming” 這篇我覺得講得很對啊 (有說服我)。某些角度,我們被現有很精準運作的系統刻板印象框住了,在要求 AI 解決過去精準執行體系無法處理的問題的同時,也要他有精準的結果 (其實這本質上就是矛盾的啊)。我們該做的,是要先區分出哪些該用精準的手段來處理,那些要用有智慧的手段來處理,然後才能對症下藥。
這就是我說的,看清楚全貌跟格局之後,你才會用對技術,才會把它用在對的地方。面對 AI 的進步,我想未來幾年,有太多這類問題需要思考了。我們都在這個變革內,無法閃開,只能面對。
最後這段寫了一堆,看看就好。我很歡迎大家跟我討論聊聊不同的看法,歡迎在下方留言回應 :D
