
原本 “服務量控制” 這是我要拿來寫 “架構面試題 #3” 的內容的,不過想想拿這個來考白板也太殘忍了吧! 同時這些基礎知識恰好是微服務架構裡面 “斷路器” (circuit breaker) 很重要的基礎,因此這篇就順理成章地接在 “服務發現” (service discovery) 的下一個主題了。
這篇文章我還不打算介紹 “斷路器” 該怎麼使用,取而代之的是使用斷路器的基礎知識: 流量控制。這裡指的流量不光是網路封包而已,而是泛指某個服務在一定時間內能夠處理的服務量。”服務量” 指的可能是訂單件數,可能是出貨量,也可能是發送的訊息數等等。先要能搞清楚如何掌握服務量,你才能預測系統何時會到達極限,何時該啟動斷路器保護整個系統。
微服務是個龐大的體系,你必須想盡辦法讓一整群的服務彼此能夠互相協調運作。這不是件容易的問題,因此我常常說 “微服務架構,考驗的是你治理眾多服務的能力” 一點都不誇張。這過程中必須涉及不少開發的課題,如演算法,或是各種開發技巧等等。同時運維與基礎建設的領域知識也同樣重要,沒好好掌握它的話就很容易事倍功半。這不就是橫跨 Dev(elopment) 跟 Op(eration)s 的整合嗎? 別再狹隘的認為做好 CI/CD 或是自動化,就是 DevOps 了,進入微服務的每個挑戰都在考驗團隊是否具備良好的 DevOps 能力。
所以,”服務量管控” 跟 “斷路器” 有什麼關聯? 再舉個例子,一般電器或是較好的延長線,都會有過載保護的機制,這就是最基本的 “斷路器” 了。一旦電流超過額定的大小,就會自動斷電,不但保護電器,也保護你的安全。在微服務架構內也是一樣,內部服務若有某部分服務量超過負荷了,其它服務還不斷地丟任務過來,那就像沒有過載保護的電器一樣,持續下去問題可能會不斷擴大,就像滾雪球一樣越來越大,造成 服務雪崩效應, 然後整個系統都崩潰無法運作…。
解決方式,當然不是簡單的裝上保險絲就解決了。裝上去之前,你必須先了解多大的電流是 “安全” 的? 對應到這篇要講的主題,就是所謂的 “服務量” 。服務量該如何控制? 該如何量化它? 這問題翻成白話就是: “若我要限制某 API 一分鐘最多可以呼叫 60 次” 的功能該如何設計? 如此而以。別小看這類問題,看似簡單,若你必須自己實作,那麼要解決的障礙還不少。我會想把這問題加入面試題庫內,自然不是要你馬上寫出 production code 給我看,重點是要看看你思考問題的方向有沒有概念? 有沒有善用抽象化思考的技巧,排除困難的實作部分,思考關鍵複雜的核心問題?
不過,大部分的 developer 也許會這樣想:
“流量管控是 infra 的事情啊! 我幹嘛自己寫 code 去處理這件事?”
API 呼叫次數的確是有現成的 solution 可以使用 (如: Kong - API Gateway, 或是 NGINX Rate Limiting),但是如果 developer 對這類問題完全沒概念的話,業務上的需求稍微變化一下就完蛋了。舉例來說,如果客戶要求 “下單時要限制某類商品每一小時最多能出貨 1000 件,超過的話就不接單”,或是高速公路的匝道管制系統要求 “快速道路只能乘載每小時通過 5000 人次,超過的話必須在匝道限制上快速到路”,這種需求你還能靠現成的 API Gateway 幫你搞定嗎?
這是個高度整合的時代,這世界什麼都在整合,developer 有這種能力的話在這個年代才會有價值。重新發明輪子也許是件蠢事,你可以不用自己發明所有的輪子。但是一旦有必要時,你一定要有能力做這件事。如果 Steven Jobs 當年不試著自己 “重新定義” 手機的使用方式,直接採用現成成熟的元件來組裝手機,那是不會有現在的 iPhone 問世的。Apple 逐步自己重新發明每個基礎元件 (CPU, OS, 周邊…), 為的就是更高度的整合,才能有更好的體驗。因此最好的方式是,碰到任何需求,即使有現成的解決方案可用,你都應該把握機會,先在腦袋裡 run 過一次。對 developer 來說,知道怎麼做是最重要的,剩下的只是時間跟資源的問題,即使有必要重新發明輪子你也知道該怎麼進行。
另一個角度來看,所有 infra 的 solution,都是過去的經驗與需求累積起來的,所以才會是個 “成熟” 的 solution (這些 solution 的 code 其實也是某個 developer 寫出來的啊 XDDD)。整個演進過程通常是用 “年” 為單位的;碰到棘手的問題你可以 “等待” 現成的方案,但是你可能錯失先機,就算等到那個時候,可能競爭對手也搞的定了。不試著去解決還沒有現成 solution 的問題,你可能就錯失掉成長的機會了。我會希望 developer 都該要知道這類問題怎麼處理才洽當。知道之後當然可以盡可能去找現有的 solution, 但是永遠要做好最壞的打算:
“就算沒有現成的 solution, 我也有能力自己創造輪子來解決它”
因此,我認為架構師的價值在於: 能夠替團隊找到解決問題的方案,包含選用現有的 solution, 或是要自行開發。評估的範圍橫跨 development team 及 operation / infra team, 因此拿這類問題來面試架構師候選人員,再適合不過了。如果你對架構師的職位有興趣,不彷自己測驗一下看看你能掌握多少細節? (你有興趣來找我面試也歡迎 XD)
所有微服務相關的文章,可以直接參考下列的導讀。
前言: 微服務架構 系列文章導讀
Microservices, 一個很龐大的主題,我分成四大部分陸續寫下去.. 預計至少會有10篇文章以上吧~ 目前擬定的大綱如下,再前面標示 (計畫) ,就代表這篇的內容還沒生出來… 請大家耐心等待的意思:
- 微服務架構(概念說明)
- 實做基礎技術: API & SDK Design
- API Design #1 資料分頁的處理方式; 2016/10/10
- API Design #2 設計專屬的 SDK; 2016/10/23
- API Design #3 API 的向前相容機制; 2016/10/31
- API Design #4 API 上線前的準備 - Swagger + Azure API Apps; 2016/11/27
- API Design #5 如何強化微服務的安全性? API Token / JWT 的應用; 2016/12/01
- API First Workshop: 設計概念與實做案例
- API First #1 架構師觀點 - API First 的開發策略 - 觀念篇; 2022/10/26
- API First #2 架構師觀點 - API First 的開發策略 - 設計實做篇; 2023/01/01
- (計畫) API First # 微服務架構 - API 的安全機制;
- 架構師觀點 - 轉移到微服務架構的經驗分享
- 基礎建設 - 建立微服務的執行環境
- 案例實作 - IP 查詢服務的開發與設計
- 容器化的微服務開發 #1 架構與開發範例; 2017/05/28
- 容器化的微服務開發 #2 IIS or Self Host ? 2018/05/12
- 建構微服務開發團隊
- 分散式系統的基礎知識
- 分散式系統 #1 如何保證 API 呼叫成功? 談 Idempotency Key 的原理與實作
微服務の斷路器
服務量管控這件事,在微服務架構上的意義,最直接的就是跟系統乘載能力直接相關。任何系統都有它服務量的上限,某個環節的服務量若沒有掌控好,開始無法正常回應時;這時呼叫端可能會不斷 retry, 讓原本已經很重的負擔更加沉重。這樣的模式拖垮了某個服務之後,可能會讓影響範圍持續擴大,讓其它原本正常的服務也跟著失效,雪崩效應會加速整個系統無法提供服務。
解決問題的方式就是服務量的管控,偵測到這個現象時 (錯誤率增高,或是服務量超過安全警戒),就打開斷路器,暫時隔絕新的 request 繼續丟給該服務處理,以求整體系統的可靠。這時就是斷路器 (circuit breaker) 的設計目的。不過這機制困難點不在於你要挑選什麼 framework 或是 service 來用,而是你是否有辦法精準的掌握你系統內的服務服務量數據,並且有能力做好整合,進一步做到自動化調節服務量的機制?
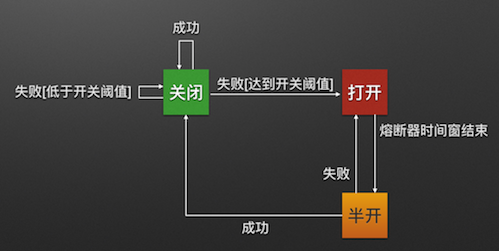
我這篇文章不是要大家自己搞斷路器,而是你要搞清楚服務量這件事,你才能夠正確的運用斷路器來解決問題。這跟高速公路逢年過節,就會啟用匝道管控,確保交通暢通是一樣的道理。這是我把這問題放到微服務架構系列文章的主要原因。不過做這件事情最大的門檻在於 developer 的應變能力與視野啊 (眼界短淺的就直接雙手一攤,讓系統掛掉了)。
如何定義 “服務量” ?
“服務量” 這件事很簡單明確,卻也很抽象。你要先讓 “服務量” 能夠量化,能被測量,後面才能依據這度量值做出反應,才能進一步 “控制” 服務量!
“服務量” 指的就是 “單位時間內的處理量” 而已。例如我家的光纖上網是 100Mbps, 意思就是每一秒鐘, HiNET 能夠提供我最大 100Mbits 的傳輸量。不過我們還是的明確的定義它才行。舉個例子說明,假設我家光纖實體的線路乘載能力遠高於 100Mbps, 那 HiNet 會用什麼機制來 “限制” 我的流量? 我隨便想幾種機制:
- 每秒統計累計傳輸量,在 1 sec 內只要不超過 100Mbits, 你能傳多快就傳多快。
- 平均下來每傳 1bits 要花費 0.01 ns.. 因此每傳完 1bits 後必須等到 0.01ns 過後才能再傳下個 bits
- (懶得算這麼精準了) 只要 60 sec 內傳輸不超過 60sec x 100Mbps = 6Gbits 就好 (average)
- …..
講到這邊,你就會發現真正要限制還沒那麼容易,這些規則會影響到你寫出什麼樣的 code… 如果我真的用 (2) 來處理,大概會搞死自己吧! 搞不好你更新統計資料就遠遠超過 0.01 ns … 因此,我重新定義一下題目,主要是該怎麼處理這兩個核心問題:
- 你要如何 “定義” 流量的計算方式 (如上所述)? 你會怎麼實作它? 你的方式能否運用到大型分散式的架構上?
- 超過流量後的處理方式? (就是斷路器要做的事)
這兩部份想清楚之後,剩下的部分就單純多了。系統的處理流程就很單純了,接到新的 request, 只要確認目前的服務量是否還有餘力受理新的 request ? 若無則直接回應 error, 若有則受理該 request, 用 sync 或是 async 的方式處理都可以。
主流程想通之後,接下來的挑戰則是實作。
題目: 抽象化的 ThrottleBase 類別
我就直接出題了,這次的目標是要繼承 ThrottleBase ,補上你的實作:
public abstract class ThrottleBase
{
/// <summary>
/// 每秒鐘處理量的上限 (平均值)
/// </summary>
protected double _rate_limit = 100;
/// <summary>
///
/// </summary>
/// <param name="rate">指定服務量上限</param>
protected ThrottleBase(double rate)
{
this._rate_limit = rate;
}
/// <summary>
///
/// </summary>
/// <param name="amount">Request 的處理量</param>
/// <param name="exec"></param>
/// <returns>傳回是否受理 request 的結果。
/// true: 受理, 會在一定時間內處理該 request;
/// false: 不受理該 request</returns>
public abstract bool ProcessRequest(int amount, Action exec = null);
}
唯一要實做的,只有 bool ProcessRequest(int amount, Action exec = null) 這個 method 了。如果你的 throttle 認為能夠受理這個 request, 就直接 return true, 若不能受理, 則 return false… 由於受理跟實際處理,可能還有時間差,因此真正要處理的時候,則呼叫 delegate: exec (如果有給的話)。
至於寫好的 Throttle 應該怎麼使用? 由於這些服務量掌控不是明確的 0 或 1, 有些許誤差存在,因此我沒有用先前的單元測試方式出題;我改用 test console, 預先產生來源資料餵給 Throttle, 透過 console output 輸出統計資料 (CSV),放進 EXCEL CHART 來看看處理的結果。這樣我不需要安裝複雜的監控工具就能視覺化程式的服務量處理結果。
先來解釋一下我怎麼測試,程式碼有點長,我分段說明,有需要看完整程式碼的可以直接參考我的 github …
程式主要分為兩部分,第一是產生模擬的服務量。我準備了三段服務量產生的程式碼:
- 持續產生平均約 600 RPS (request per second) 的服務量。這邊由 30 個 threads 負責,每個 thread 間隔 0 ~ 100 ms (隨機決定) 產生一個 request
- 每 17 sec 會有 2 sec, 產生約 500 RPS 的額外瞬間服務量,藉以測試 Throttle 對於 peek 的處理效果。
- 每 20 sec 會有 3 sec, 完全阻隔 (1) 與 (2) 的運作,在這段期間內不產生任何服務量。
第二部分比較簡單,就是固定每秒把統計資料輸出成 CSV 而已:
我先打造了一個很不負責的 DummyThrottle, 它完全不做服務量管控,因此輸出的數據就是產生的服務量:
public class DummyThrottle : ThrottleBase
{
public DummyThrottle(double rate) : base(rate)
{
}
public override bool ProcessRequest(int amount, Action exec = null)
{
//exec?.Invoke();
Task.Run(exec);
return true;
}
}
正好可以對照著看一下第一部份產生甚麼樣的 request:
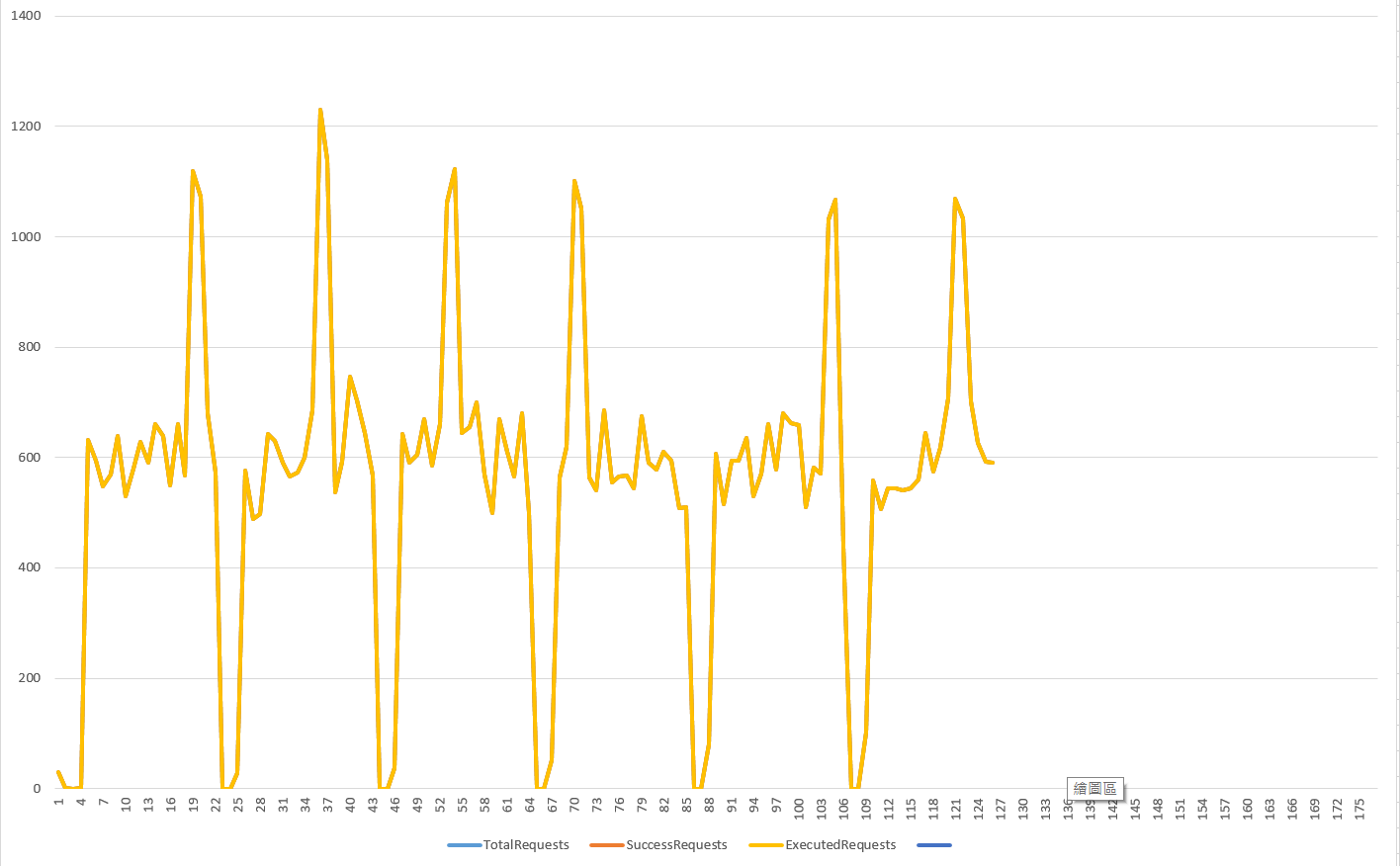
以上,各位可以驗證一下是否符合來源服務量的描述。接著我們就可以看看各種方式控制服務量後的成果了。輸出的 CSV 統計數據共有這五個欄位:
TotalRequest, 所有發出的 request 總數 => (1) + (2)SuccessRequest, 成功受理的 request 總數FailRequest, 拒絕受理的 request 總數 (被 Throttle 拒絕的 request 統計)ExecutedRequest, 已執行的 request 總數 (Success 後不一定會立即執行,不同演算法可能有不同的時間差)AverageExecuteTime, 所有已執行的 request, 從受理 (success) 到執行 (execute) 的平均等待時間
這些數據,在前面兩部分的 code 都會不斷的累加 counter, 在這段 code 則會每秒讀出數據之後,reset counter 歸零重新統計。CSV 的資料,只要複製貼上 EXCEL 就可以看到服務量統計表 (如下例):
寫到這邊,萬事俱備! 接下來就等著看面試者的發揮了。不過這題其實有點難度,你可以拿來用在內部的教育訓練,或是內部面試篩選能處理這些問題的人員,也可以拿來面試 senior engineer。搭配 EXCEL 很容易視覺化執行的結果,因此也很適合拿來做 POC 跟討論評估各種做法的優缺點。
這樣的討論方式,可以讓團隊在最短的時間內,花費最少的資源,就能評估做法是否適合。這段落的最後,我放一下完整的 test console 程式碼,有興趣的朋友們可以仔細瞧瞧:
static void Main(string[] args)
{
ThrottleBase t =
//new DummyThrottle(500);
//new CounterThrottle(500, TimeSpan.FromSeconds(5));
//new CounterThrottle(500, TimeSpan.FromSeconds(1));
//new StatisticEngineThrottle(500, TimeSpan.FromSeconds(5));
//new StatisticEngineThrottle(500, TimeSpan.FromSeconds(1));
//new LeakyBucketThrottle(500, TimeSpan.FromSeconds(5));
//new LeakyBucketThrottle(500, TimeSpan.FromSeconds(1));
//new TokenBucketThrottle(500, TimeSpan.FromSeconds(5));
new TokenBucketThrottle(500, TimeSpan.FromSeconds(1));
int statistic_success = 0;
int statistic_fail = 0;
int statistic_execute = 0;
long statistic_executeTime = 0;
//
// 製造 (平均) 200qps 穩定的流量
// 產生多個 threads, 用穩定的速度 (會加上亂數打散) 產生 request(s), 交給 throttle 處理。
//
List<Thread> threads = new List<Thread>();
bool stop = false;
bool idle = false;
for (int i = 0; i < 30; i++)
{
Thread thread = new Thread(() =>
{
Random rnd = new Random();
while (stop == false)
{
Stopwatch _timer = new Stopwatch();
_timer.Start();
if (idle)
{
}
else if (t.ProcessRequest(1, ()=> { Interlocked.Increment(ref statistic_execute); Interlocked.Add(ref statistic_executeTime, _timer.ElapsedMilliseconds); }))
{
Interlocked.Increment(ref statistic_success);
}
else
{
Interlocked.Increment(ref statistic_fail);
}
Thread.Sleep(rnd.Next(100));
}
});
thread.Start();
threads.Add(thread);
}
//
//
// 製造 peek 的流量 (約 700 ~ 100 qps)
// 產生1個 threads, 每隔 17 sec, 就有 2 sec 會產生大量 request 交給 throttle 處理。用以測試尖峰流量的處理效果。
//
{
Thread thread = new Thread(() =>
{
Stopwatch timer = new Stopwatch();
while (stop == false)
{
timer.Restart();
while (timer.ElapsedMilliseconds < 2000)
{
Stopwatch _timer = new Stopwatch();
_timer.Start();
if (idle)
{
}
else if (t.ProcessRequest(1, () => { Interlocked.Increment(ref statistic_execute); Interlocked.Add(ref statistic_executeTime, _timer.ElapsedMilliseconds); }))
{
Interlocked.Increment(ref statistic_success);
}
else
{
Interlocked.Increment(ref statistic_fail);
}
Thread.Sleep(1);
//SpinWait.SpinUntil(() => false, 5);
}
Task.Delay(15000).Wait();
}
});
thread.Start();
threads.Add(thread);
}
//
// 製造離峰的流量, 每 21 秒約 3 秒沒有任何流量
//
{
Thread thread = new Thread(() =>
{
Stopwatch timer = new Stopwatch();
while (stop == false)
{
idle = true;
timer.Restart();
SpinWait.SpinUntil(() => timer.ElapsedMilliseconds >= 3000);
idle = false;
Task.Delay(18000).Wait();
}
});
thread.Start();
threads.Add(thread);
}
//
// 產生一個 thread, 定期每秒分別統計:
// 0. 所有發出的 request 總數 => (1) + (2)
// 1. 成功受理的 request 總數
// 2. 拒絕受理的 request 總數
// 3. 已執行的 request 總數
//
{
Thread thread = new Thread(() =>
{
Console.WriteLine($"TotalRequests,SuccessRequests,FailRequests,ExecutedRequests,AverageExecuteTime");
while (stop == false)
{
//Console.WriteLine("{0} per sec", Interlocked.Exchange(ref statistic_success, 0));
int success = Interlocked.Exchange(ref statistic_success, 0);
int fail = Interlocked.Exchange(ref statistic_fail, 0);
int exec = Interlocked.Exchange(ref statistic_execute, 0);
long exectime = Interlocked.Exchange(ref statistic_executeTime, 0);
double avgExecTime = 0;
if (exec > 0) avgExecTime = 1.0D * exectime / exec;
Console.WriteLine($"{success+fail},{success},{fail},{exec},{avgExecTime}");
Task.Delay(1000).Wait();
}
});
thread.Start();
threads.Add(thread);
}
Thread.Sleep(1000 * 120);
Console.WriteLine("Shutdown...");
stop = true;
foreach(Thread thread in threads)
{
thread.Join();
}
}
解法 1, CounterThrottle
絕大部分的人,拿到這個題目,大概就是很直覺的分析題目的語意吧! 既然是限制單位時間內的總處理量,那我就設置一個 counter, 每隔固定時間就 reset 歸零。處理過程中只要 counter 不超過上限即可。於是就有第一版 CounterThrottle 出現了:
public class CounterThrottle : ThrottleBase
{
private TimeSpan _timeWindow = TimeSpan.Zero;
private double _counter = 0;
public CounterThrottle(double rate, TimeSpan timeWindow) : base(rate)
{
this._timeWindow = timeWindow;
Thread t = new Thread(() =>
{
Stopwatch timer = new Stopwatch();
while (true)
{
this._counter = 0;
timer.Restart();
SpinWait.SpinUntil(() => { return timer.Elapsed >= this._timeWindow; });
}
});
t.Start();
}
public override bool ProcessRequest(int amount, Action exec = null)
{
if (amount + this._counter > this._rate_limit * this._timeWindow.TotalSeconds) return false;
this._counter += amount;
Task.Run(exec);
return true;
}
}
執行結果
程式碼很短,我就不說明了。我設定了 rate: 500 rps, time window: 5 sec, 來看看執行的結果:
console output (csv):
TotalRequests,SuccessRequests,FailRequests,ExecutedRequests,AverageExecuteTime
30,30,0,30,4.76666666666667
0,0,0,0,0
0,0,0,0,0
0,0,0,0,0
547,547,0,547,0
582,582,0,582,0
545,545,0,545,0
664,664,0,664,0
552,552,0,552,0
483,483,0,483,0
581,343,238,343,0.00291545189504373
575,575,0,575,0
(以下略)
statistic (chart):
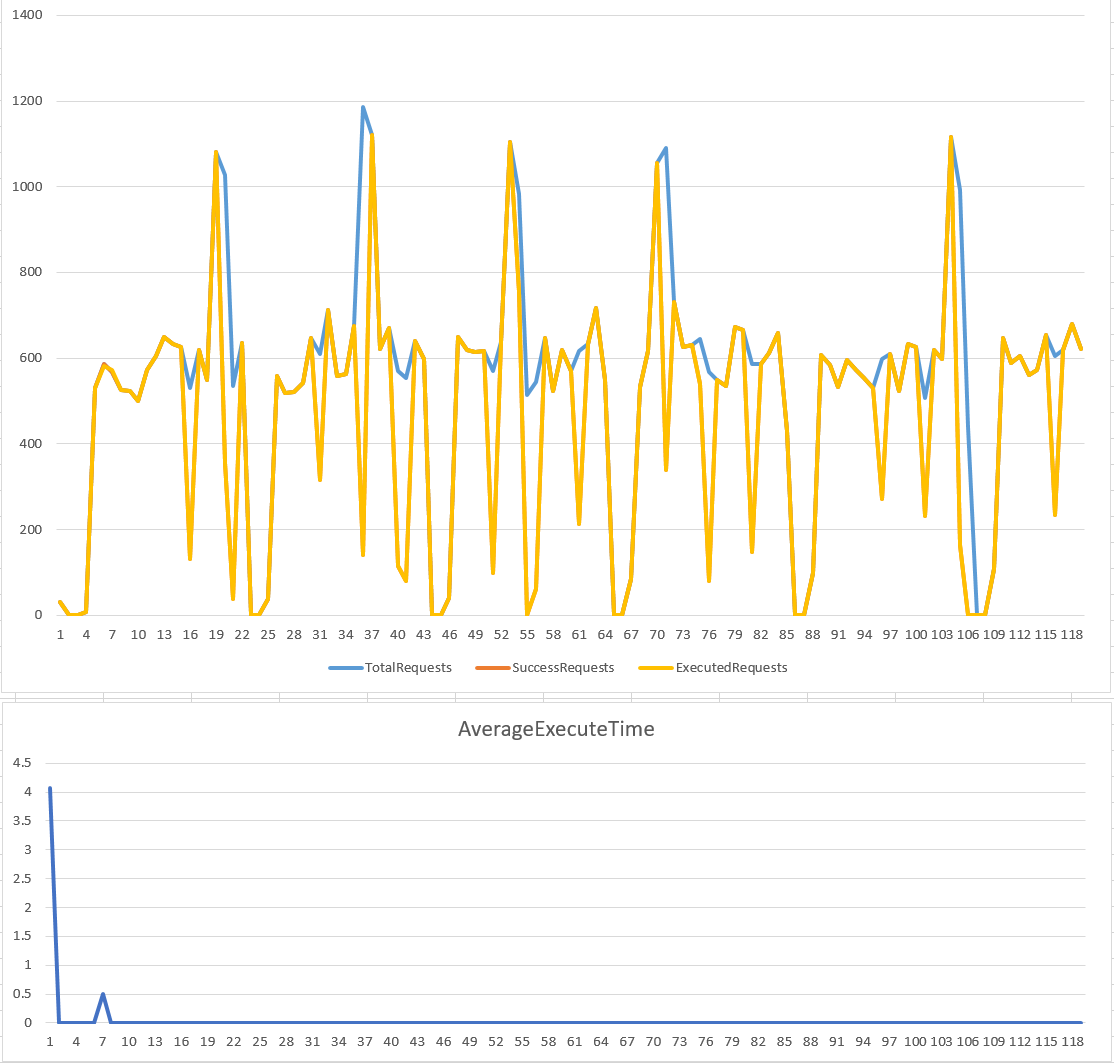
很明顯的可以看到,雖然我們的目的是服務量管控,但是從結果來看,最後通過執行的服務量表現很不穩定啊… 在 time window (5 sec) 的範圍內,可能碰到 peek 在一瞬間就把 time window (5 sec) 內的額度 (500 x 5 = 2500 requests) 通通用光了,導致後面一段時間內的服務量都被拒絕了。
CounterThrottle 額定的服務量限定在 500 RPS, 不過看跑出來的結果,很明顯的實際服務量在 0 ~ 1175 之間跳動啊,感覺沒有發揮太大的效用。這演算法的缺點就是: 你無法掌控 time window 範圍內的表現。設的過短,你會花很多運算能力在服務量控制這件事上。設的過長,就會有這案例的現象。服務量掌控的不夠精準,後果就是後端的服務可能在瞬間被打垮,而垮掉之後又有一段時間內沒有 request ..
我把設定範圍調整一下,改為 rate: 500, time window: 1 sec, 重新看一次執行結果:
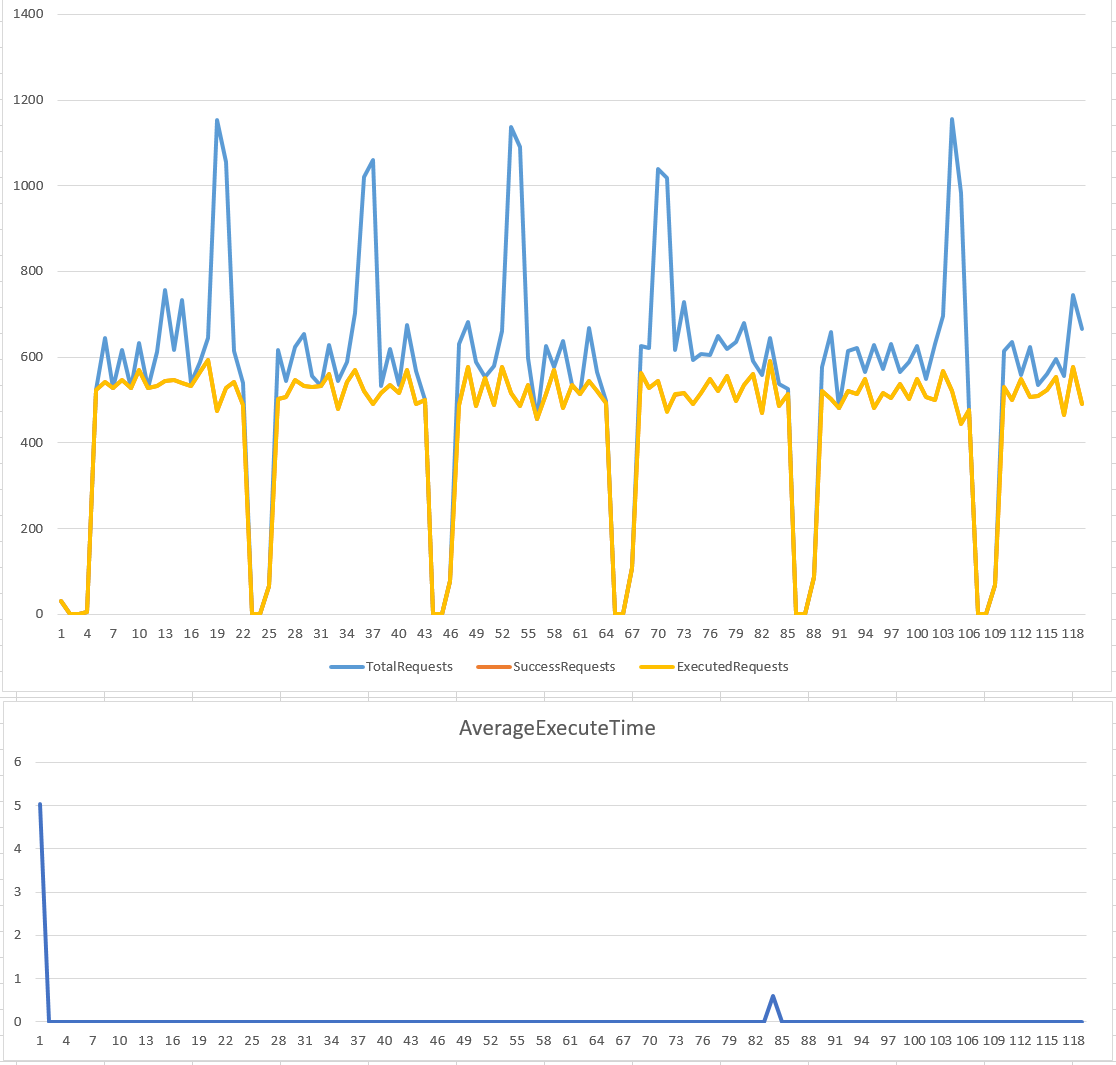
藉由縮小 time window, 得到的結果稍為平緩了一些。不過還是可以看到波動的幅度很大,難以預測跟控制。如果你有選購過 UPS 你就知道,這樣的凸波會害死後面的機器.. XD
小結
我下個簡單的結論: 這個演算法只能做到基本的限流。如果你的目的只是要限制 user 的用量,或是按照速度計費,這個方式就夠了。如果你的目的是預測或是限制服務量,要保護後端的服務平穩可靠的運行,這方是明顯的不足。
解法 1.5, StatisticEngineThrottle
這個解法是我額外插進來的,基本上只是 (1) CounterThrottle 的延伸,本質上還是依樣透過統計的方式來修正服務量的計算。
上個做法主要的缺點,在於每個 time window 之間有明顯的分界。例如 0 ~ 5 sec 之間是一個段落,6 ~ 10 sec 又是一個段落。每個段落是獨立統計的,因此很容易在兩個段落的交界處發生爆量的情況。很極端的狀況下,交界處可能在一瞬間 (ex: 0.1 sec) 把兩個段落的所有額度 ( 5 sec x 500 rps x 2 = 5000 requests ) 用光,造成瞬間巨量。這就違背了我們限制服務量的用意了。
還記得之前那篇 架構面試題 #2, 連續資料的統計方式 嗎? 這篇探討的就是如何讓這種時間區段能夠 “平滑” 的統計? 不是 0 ~ 5 sec, 6 ~ 10 sec 這樣,而是 5 sec 那瞬間可以統計 0 ~ 5 sec 之間的資料,而 5.1 sec 則可以統計 0.1 sec ~ 5.1 sec 之間的資料。這個版本就是拿那篇文章講到的 sample code (我就不再拿分散是版本了,我直接拿單機版本 InMemoryEngine 來使用)。這種方法改善了 CounterThrottle 不夠 “平滑” 的問題,我們可以更精準的統計長時間的累計資料。
直接看程式碼:
public class StaticEngineThrottle : ThrottleBase
{
//private EngineBase _peek_engine = null;// new InMemoryEngine(timeWindow: TimeSpan.FromSeconds(1));
private EngineBase _average_engine = null;// new InMemoryEngine(timeWindow: TimeSpan.FromSeconds(3));
//private double _peek_limit = 0;
public StaticEngineThrottle(double averageRate, TimeSpan averageTimeWindow) : base(averageRate)
{
//this._peek_limit = peekRate;
this._average_engine = new InMemoryEngine(timeWindow: averageTimeWindow);
//this._peek_engine = new InMemoryEngine(timeWindow: peekTimeWindow);
}
public override bool ProcessRequest(int amount, Action exec = null)
{
if (
//this._peek_engine.AverageResult < this._peek_limit &&
this._average_engine.AverageResult < this._rate_limit)
{
//this._peek_engine.CreateOrders(amount);
this._average_engine.CreateOrders(amount);
exec?.Invoke();
return true;
}
return false;
}
}
執行結果
我在 StaticEngineThrottle 裡面,藏了一個 InMemoryEngine: _average_engine, 用來取代上個例子單獨的 counter… 運作的原理是透過這個 InMemoryEngine, 統計過去 {time window} sec 內累計的處理量。修正過的做法,我一樣採用指定速率: rate = 500 rps, time window = 5 sec, 以下是跑出來的結果, 服務量控制的波動幅度穩定一些:
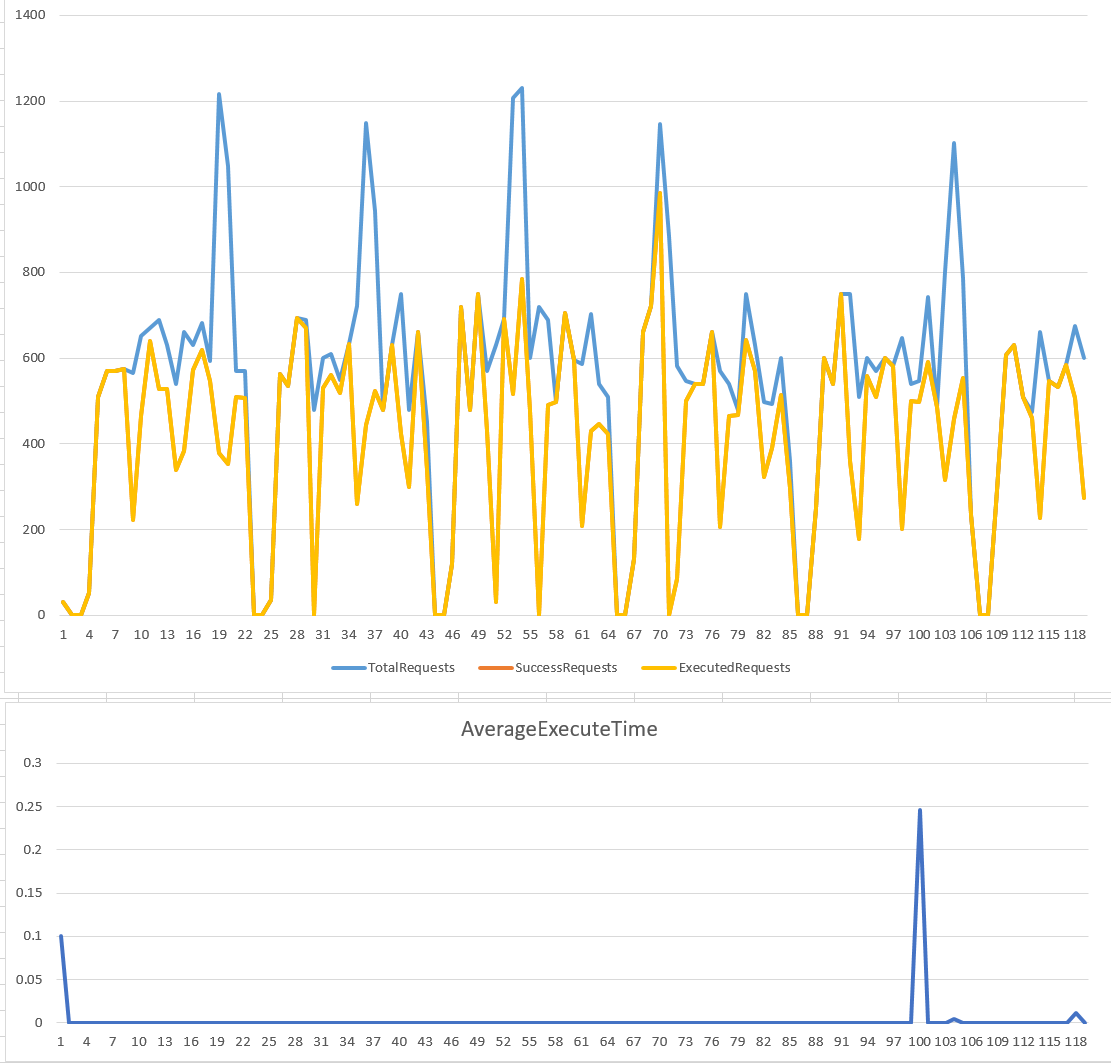
一樣做個對照組,改用 rate = 500 rps, time window = 1 sec:
小結
結論: 這個做法雖然較 (1) CounterThrottle 來的好一些,但是我認為只有做到 “改良” 的程度而已。基本上只靠 counter 的限制還是存在。我單純只是延續前一篇文章的內容,順便驗證一下改善的效果。這方法在技術使用上較為精進,不過還沒有很到位的解決這個需求,仍有改進的空間。
解法 2, Leaky Bucket
用 counter 的方式,最大的障礙在於存在 time window 的邊界會。在 time window 切換的瞬間,容易產生瞬間的大量請求造成 peek,無法穩定的控制服務量。我們需要尋求其他更理想的控制方式。
我順手 google 了業界較通用的演算法,其中一種就叫做漏桶演算法 (Leaky Bucket)。它的觀念很簡單,想像一個桶子,你的 request 就像是水一樣不斷的倒進去,只要桶子還沒滿你都可以繼續倒,能倒的進去就算 success, 倒不進去就算 fail。而桶子的底部有個小孔,可以用你指定的固定速率把水漏掉。漏掉的水就是會被處理的服務量 (exec)。
在 wiki 上也有詳細的介紹: Leaky bucket
The leaky bucket is an algorithm based on an analogy of how a bucket with a leak will overflow if either the average rate at which water is poured in exceeds the rate at which the bucket leaks or if more water than the capacity of the bucket is poured in all at once, and how the water leaks from the bucket at an (almost) constant rate. It can be used to determine whether some sequence of discrete events conforms to defined limits on their average and peak rates or frequencies, or to directly limit the actions associated to these events to these rates, and may be used to limit these actions to an average rate alone, i.e. remove any variation from the average.
我自己實做了一個簡單的版本: LeakyBucketThrottle
public class LeakyBucketThrottle : ThrottleBase
{
private double _max_bucket = 0;
private double _current_bucket = 0;
private object _syncroot = new object();
private int _interval = 100; // ms
private Queue<(int amount, Action exec)> _queue = new Queue<(int amount, Action exec)>();
public LeakyBucketThrottle(double rate, TimeSpan timeWindow) : base(rate)
{
this._max_bucket = rate * timeWindow.TotalSeconds;
Thread t = new Thread(() =>
{
Stopwatch timer = new Stopwatch();
timer.Restart();
while(true)
{
timer.Restart();
SpinWait.SpinUntil(() => { return timer.ElapsedMilliseconds >= _interval; });
double step = this._rate_limit * _interval / 1000;
double buffer = 0;
lock (this._syncroot)
{
if (this._current_bucket > 0)
{
buffer += Math.Min(step, this._current_bucket);
this._current_bucket -= buffer;
while (this._queue.Count > 0)
{
var i = this._queue.Peek();
if (i.amount > buffer) break;
this._queue.Dequeue();
buffer -= i.amount;
//i.exec?.Invoke();
Task.Run(i.exec);
}
}
}
}
});
t.Start();
}
public override bool ProcessRequest(int amount, Action exec = null)
{
lock (this._syncroot)
{
if (this._current_bucket + amount > this._max_bucket) return false;
this._current_bucket += amount;
this._queue.Enqueue((amount, exec));
return true;
}
}
}
執行結果
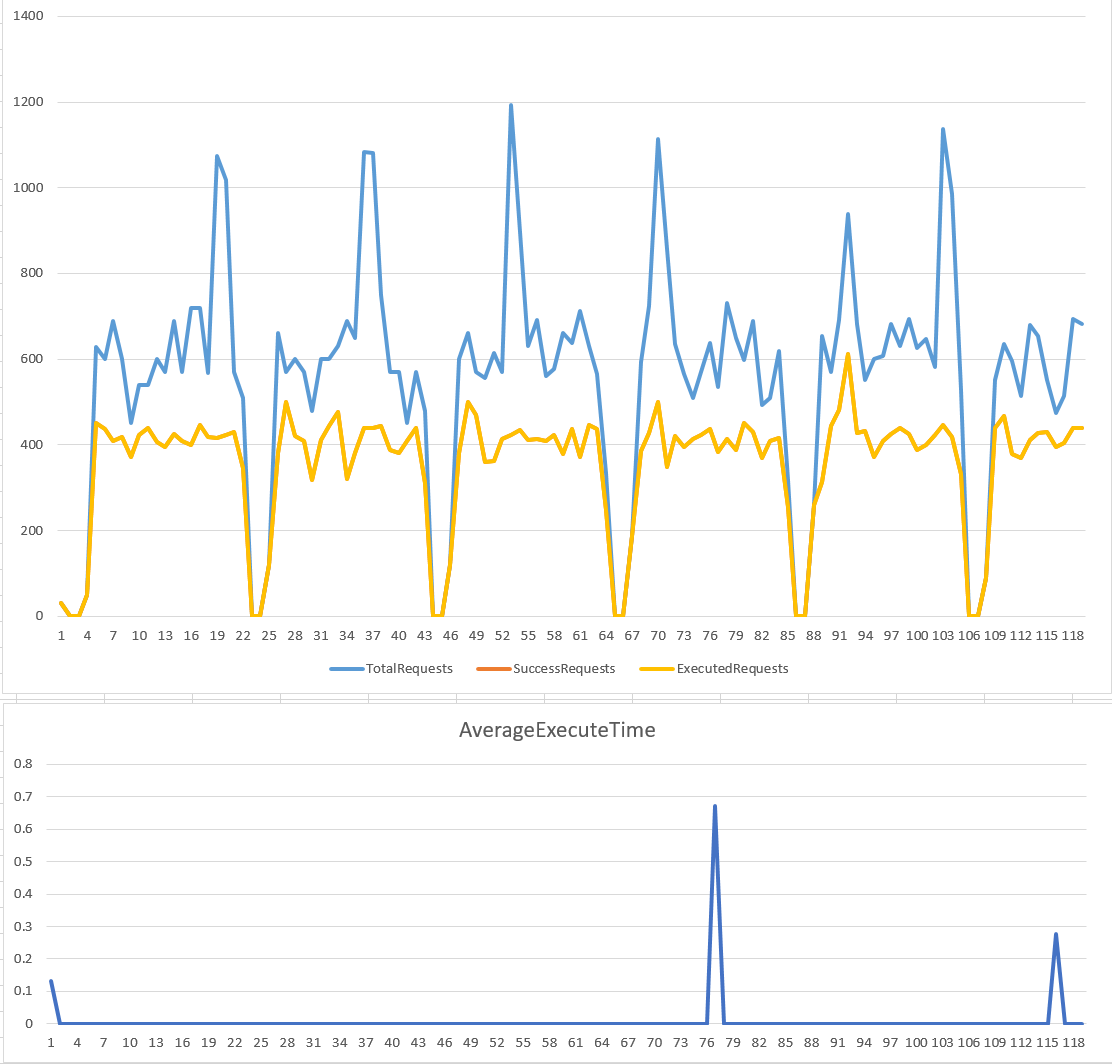
解釋 code 之前,先來看看執行結果。我用一樣的兩組設定來觀察…
rate: 500 rps, time window: 5 sec
rate: 500 rps, time window: 1 sec
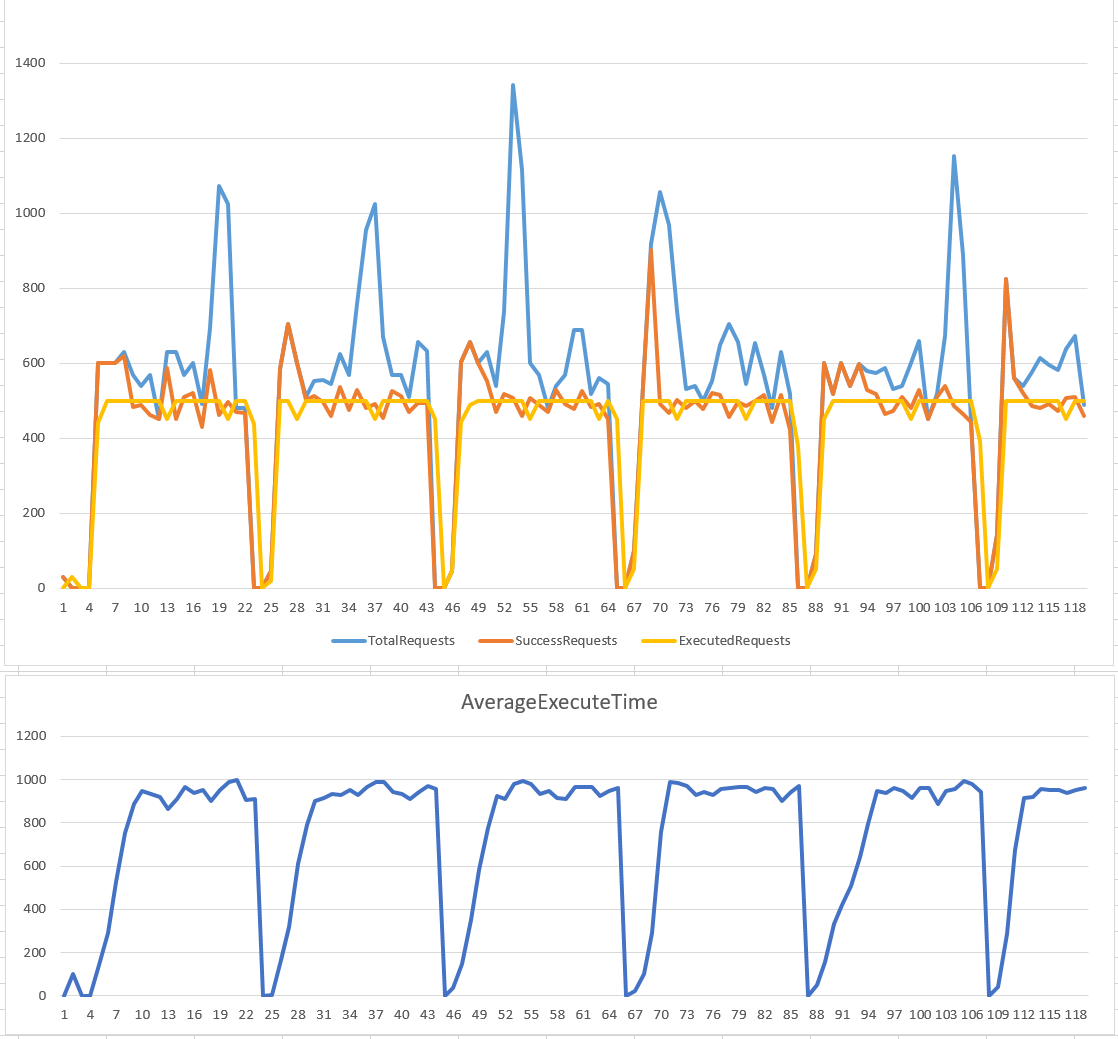
小結
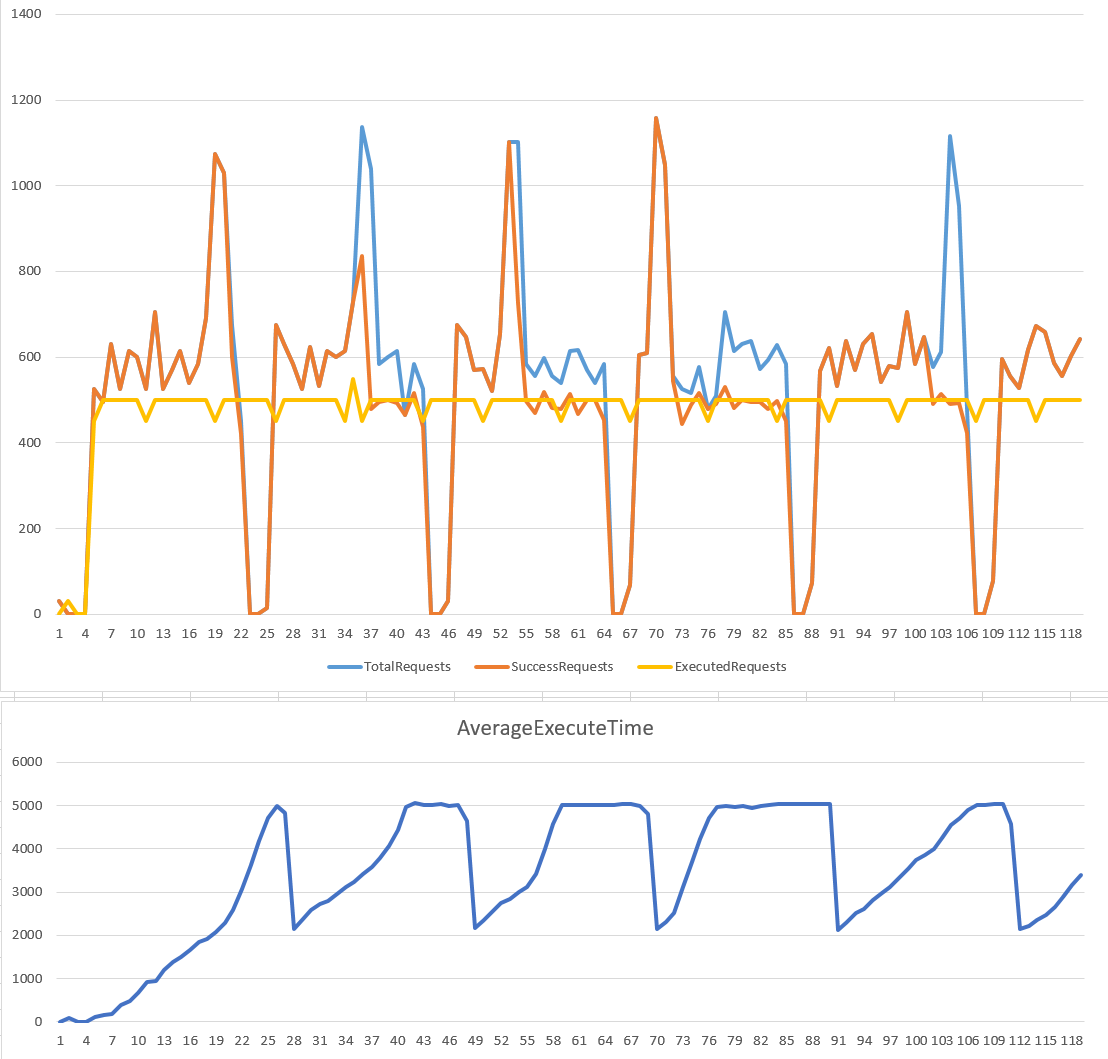
實際上,Leaky Bucket 的原理,就是中間設置一個 queue 當做緩衝,只是這個 queue 的大小是有限的 (就是桶子的大小)。能夠進的了 queue, 你的 request 就能保證在一定時間內能被處理 (time window)。由於處理 request 的部分被 queue 隔離保護得很好,因此幾乎可以用完美穩定的速率來處理 request。
其實這就是常見的 queue + worker 處理模式啊! 生產者跟消費者之間的平衡機制就是這個做法的精神。這個演算法的圖表,有很多有趣的細節,我逐一一個一個拿出來討論。我們以 5 sec time window 這張圖為例:
-
Executed Requests(黃線):
這個做法最大的優點,就是實際執行的速率是完美的水平線。中間的波動只是某個 request 只是統計的時間差而已,在 1 sec 統計的邊界,有些 request 被算在後面的區間而已。 -
Success Requests(橘線):
由於這個作法是有 buffer (queue) 的,因此它有能力受理一定程度內的 peek… 我們可以看到超過服務量的 request, 只要桶子還有空間,它都會被吸收進去,等後面慢慢消化。只有服務量超過的部分已經讓桶子都滿了裝不下,才會被丟棄,所以我們可以看到橘色的線在 peek 剛發生的時候都還跟的上,直到桶子滿了為止。 -
AverageExecuteTime(下圖藍線):
這個做法的缺點是,由於有桶子做緩衝,因此某些 request 可能會延遲一段時間才會流出桶子。這時 time window 就等同於最大的等待時間。我們可以看到 time window: 5 sec 那張圖,averaget execute time 爬到 5000 msec 就停止了 (因為再之後的 request 都灌不進來了)。另一張圖 time window: 1 sec, 也一樣,average execute time 爬到 1000 msec 就停止不再成長了。
這是這個演算法的優點,也是缺點。你可以按照你的情況做調整。用 time window 可以更具體化的告訴你的客戶 (產生 request 的那端) 你的服務水準 (最大等待時間) 有多長。過去如果你只是用 queue, 你只能告訴客戶 “此 request 已收到,等待處理中”,而你沒有辦法預估一個精準的處理時間。搭配 Leaky Bucket 你就能做到這點。
另一個好處是,這也是一個你 scale out 的評估標準。假設 queue 後面的 worker 每個能提供 100 RPS 的處理能力,後面有五個 worker 就能提供 100 x 5 = 500 RPS, 也就是這個範例設定的條件。當你觀察到 fail requests 的數量增加時,就可以擴充 worker 數量。當 worker 個數從 5 -> 6, time window 不變,改變的是你的處理速度,從 500 -> 600。這一切都能夠更直覺得量化,也更容易被度量,負責為運系統的 operation team 也能更直覺得按照需求條配系統組態。
唯一要留意的是,這些需求如果不是非同步的處理 (async), 這些 idle 的 request 可能都會佔住 http connection. time window 設的過大,有可能導致前端的 connection 被用光了,造成前端的服務垮掉的現象。
解法 3, Token Bucket
漏桶演算法,是控制桶子流出來的速率。另一種相對的演算法: 令牌桶 (Token Bucket) 則是剛好反過來,用一定速率把令牌放到桶子內,直到桶子滿了為止。當你接到 request, 只要你能從桶子裡拿到令牌,你的 request 就能被受理執行。
同樣的,可以看看 Wiki 上的介紹: Token bucket
The token bucket algorithm is based on an analogy of a fixed capacity bucket into which tokens, normally representing a unit of bytes or a single packet of predetermined size, are added at a fixed rate. When a packet is to be checked for conformance to the defined limits, the bucket is inspected to see if it contains sufficient tokens at that time. If so, the appropriate number of tokens, e.g. equivalent to the length of the packet in bytes, are removed (“cashed in”), and the packet is passed, e.g., for transmission. The packet does not conform if there are insufficient tokens in the bucket, and the contents of the bucket are not changed. Non-conformant packets can be treated in various ways:
- They may be dropped.
- They may be enqueued for subsequent transmission when sufficient tokens have accumulated in the bucket.
- They may be transmitted, but marked as being non-conformant, possibly to be dropped subsequently if the network is overloaded.
A conforming flow can thus contain traffic with an average rate up to the rate at which tokens are added to the bucket, and have a burstiness determined by the depth of the bucket. This burstiness may be expressed in terms of either a jitter tolerance, i.e. how much sooner a packet might conform (e.g. arrive or be transmitted) than would be expected from the limit on the average rate, or a burst tolerance or maximum burst size, i.e. how much more than the average level of traffic might conform in some finite period.
我自己也實作了一個簡單的版本: TokenBucketThrottle:
public class TokenBucketThrottle : ThrottleBase
{
private double _max_bucket = 0;
private double _current_bucket = 0;
private object _syncroot = new object();
private int _interval = 100;
public TokenBucketThrottle(double rate, TimeSpan timeWindow) : base(rate)
{
this._max_bucket = this._rate_limit * timeWindow.TotalSeconds;
Thread t = new Thread(() =>
{
//int _interval = 100;
Stopwatch timer = new Stopwatch();
timer.Restart();
while (true)
{
timer.Restart();
SpinWait.SpinUntil(() => { return timer.ElapsedMilliseconds >= _interval; });
double step = this._rate_limit * _interval / 1000;
lock (this._syncroot)
{
this._current_bucket = Math.Min(this._max_bucket, this._current_bucket + step);
}
}
});
t.Start();
}
public override bool ProcessRequest(int amount, Action exec = null)
{
lock (this._syncroot)
{
if (this._current_bucket > amount)
{
this._current_bucket -= amount;
//exec?.Invoke();
Task.Run(exec);
return true;
}
}
return false;
}
}
執行結果
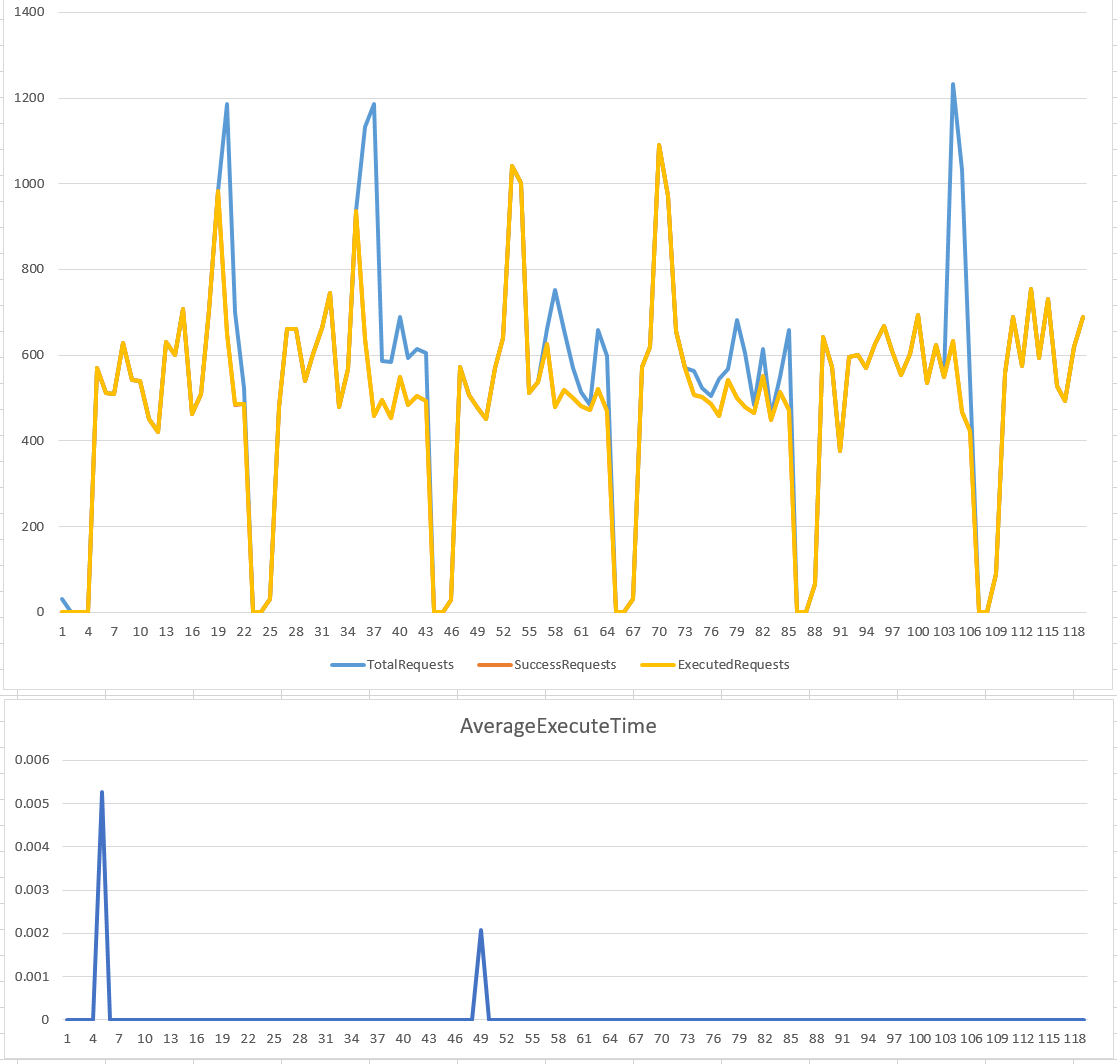
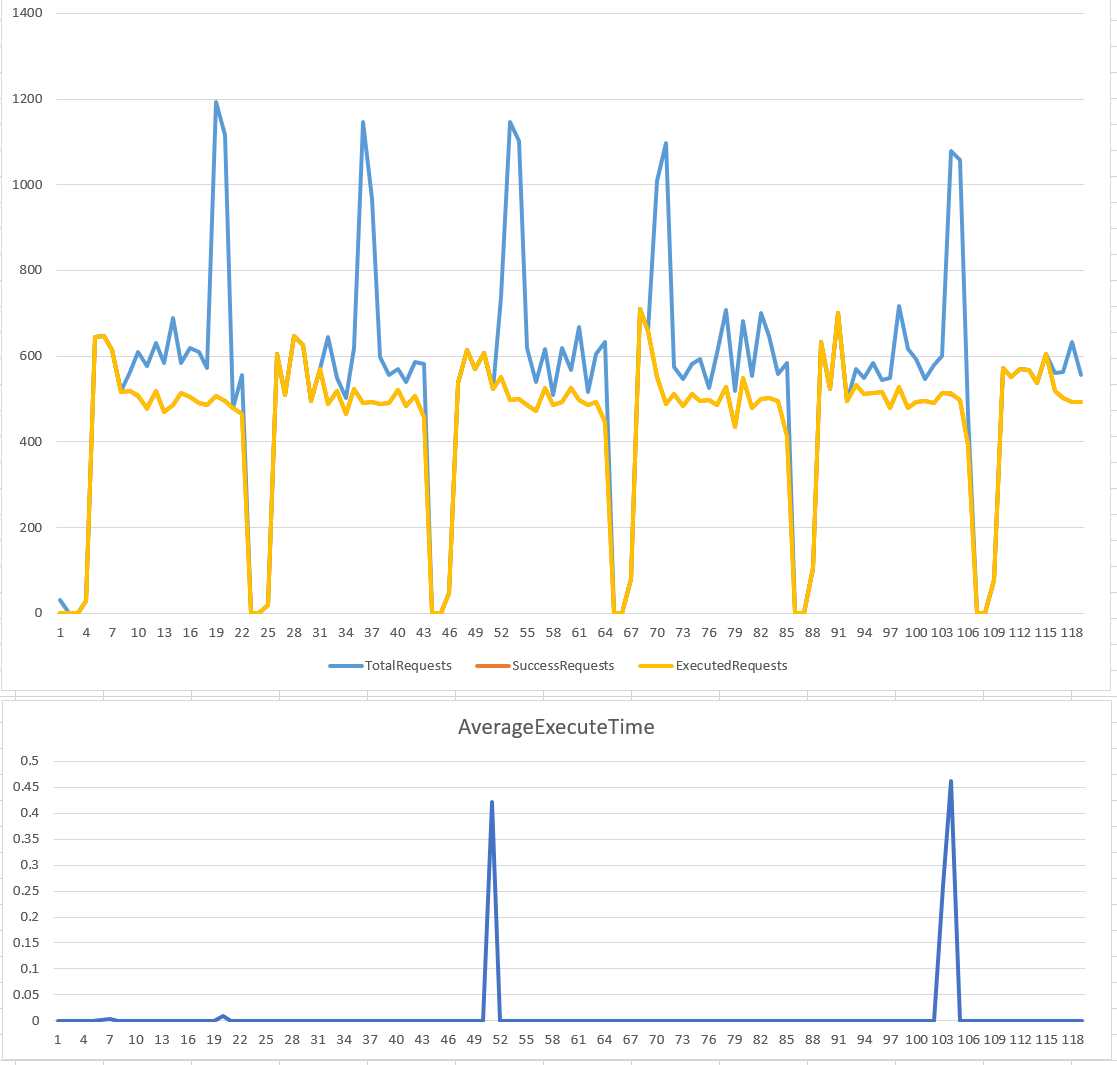
不多說,一樣先來看看兩種組態跑出來的成果:
rate: 500 rps, time window: 5 sec
rate: 500 rps, time window: 1 sec
小結
Leaky Bucket 跟 Token Bucket 只是分別管控 buffer 的前端 (來源) 跟後端 (處理) 的速率而已啊! 因此大致上兩者的 Success Requests 的曲線是差不多的,在 peek 發生的瞬間,都還有一定的 “吸收” 能力。差別在於 Leaky 會保護後端,吸收下來的 peek 會延遲執行,而 token 則是先預留處理能力 (把 token 放進 bucket), 有保留資源的才能執行。
相較於 Leaky Bucket 能夠保證最大的 idle time, Token Bucket 則是保證後端有一定的 peek 吸收能力的前題下,盡可能地接受 request 並且立刻處理它, 一旦 request 被接受了,不需要任何等待的時間就能開始進到處理程序階段。只是當系統剛消化完一部分 peek 之後,Token Bucket 需要等一段時間 (time window) 讓後端恢復足夠的處理能力 (讓桶子裡放滿令牌) 後才能繼續吸收下一次的 peek…
整體而言,Token Bucket 較 Leaky Bucket 來的有效,Leaky Bucket 不論後端的設備有無餘力,都只能用一定的速率消化 request, 對於較健全的系統來說服務的利用率較低,因為任何的 Peek 都會被擋下來。而 Token Bucket 則能夠有限度地允許後端設備接受 peek , 就好像戰鬥機有後燃器一樣,能夠瞬間加大推力,只要你有限度的使用它就不會有問題。這可以讓你更有效率地去適應外界的 request 變化。只是你必須事先掌握你的 token 填充速率以及 time window 的大小,找出適合你系統的組態才能達到最佳效率。
總結
終於寫到結論了 @@, 寫到這邊,我只能說… 服務量控制真的是很煩人的一件事啊! 之前有篇文章,就是要寫程式控制 CPU 的使用率,想辦法讓 CPU 的 utilization 劃出正弦波… 為了修飾波形,想辦法消除雜訊,就花掉不少心思… 有興趣的朋友們可以去體會一下:

Microsoft 面試考題: 用 CPU utilization 畫出正弦波
花了這麼多篇幅 (最近文章的長度越來越誇張了 @@),總算把服務量 (流量) 控制的做法交代完畢,告一段落。我會花這些篇幅說明這些演算法,是有原因的。我看過很多說明斷路器的文章,清一色都是說後端服務開始 “不正常” 之後就要啟動了… 不過這時才啟動應變措施,代表也已經有些災難發生了 (只是還沒擴大而已)。而我的想法是,如果我能夠更精準的掌握服務量 (流量) 這件事的話,也許我就有機會在快要發生災難時 (還沒發生) 就開始做好準備了。除了可以啟動斷路器之外,我也可以有更充裕的時間做 scale out, 或是優先調配資源,優先讓重要服務 (如交易) 通過。這些進階的控制技巧,都不是直接拿現成的 framework, 或是套用現成的 infra (如 load balancer, 或是 api gateway … 等等) 可以解決的。
我期望帶給讀者們的是個高度整合的 solution, 我不想綁定在特定的 infra / service 上,而是想帶給大家一個處理這類問題的 concept… 不說別的,光是能夠在 client side 透過你的 code 靈活操作 service discovery, throttle, circuit breaker, key-value store (configuration management), health check … 等機制,你就能用很少量的 code 做到很高的靈活程度。
舉個例子 QoS (quality of servics), 若你想讓特定客戶可以享用較高等級的服務, 但是這些背後的服務都是同樣一份 code.. 該怎麼做? 很簡單,你只要把這些 service instance 在註冊時先貼上標籤,標記那些是 VIP only, service discovery 時就能夠依照客戶身分別找到特定的 service group 了。不同 service group 你可以用不同的限流 (throttle) 標準來控制服務水準,讓你的 SLA 也是可控的。
開始能體會這些技巧帶來的效益了嗎? 掌握這些知識,才是微服務架構成功的途徑啊! 後續的文章我都會繼續用這角度介紹,實作的 labs 也會把這些應用的情境用實際的 code 表現出來。敬請期待, 也感謝各位長期支持 :)
