要動筆寫這個主題 (service discovery) 之前,我想了很久該怎麼講這個主題… 如果講他怎麼做,那是很乏味的 process 而已。介紹產品或 step by step 的操作,那又不是我的 style. 想了半天,還是從架構的角度,切入 service discovery 想要解決什麼問題,搭配幾種常見的處理模式,再介紹一下有哪些成熟的服務是用這種模式設計的,正好一次把這幾個目的解決掉…
Microservices 先天就是個分散式系統,在開發領域上的門檻,主要就是各種呼叫遠端服務 RPC - remote procedure call 的相關技術了。然而在架構上最重要的一環,就屬 “服務發現” service discovery 這技術了。說他是微服務架構的靈魂也當之無愧,試想一下就不難理解: 當一個應用系統被拆分成多個服務,且被大量部署時,還有什麼比 “找到” 我想要呼叫的服務在哪裡,以及是否能正常提供服務還重要? 同樣的有新服務被啟動時,如何讓其他服務知道我在哪? 人家說微服務考驗的就是你治理大量服務的能力,包含多種服務, 也包含多個 instances。要做到這件事,service discovery 就是你要挑戰的第一關。
說到治理大量服務的能力,Nginx 官網有篇 文章 講得不錯,我就借他的圖用一用。裡面提到 Modern Apps 演進過程,從 1980 的 client / server, 到 2000+ 的 3-tiers, 到現在的 microservices …
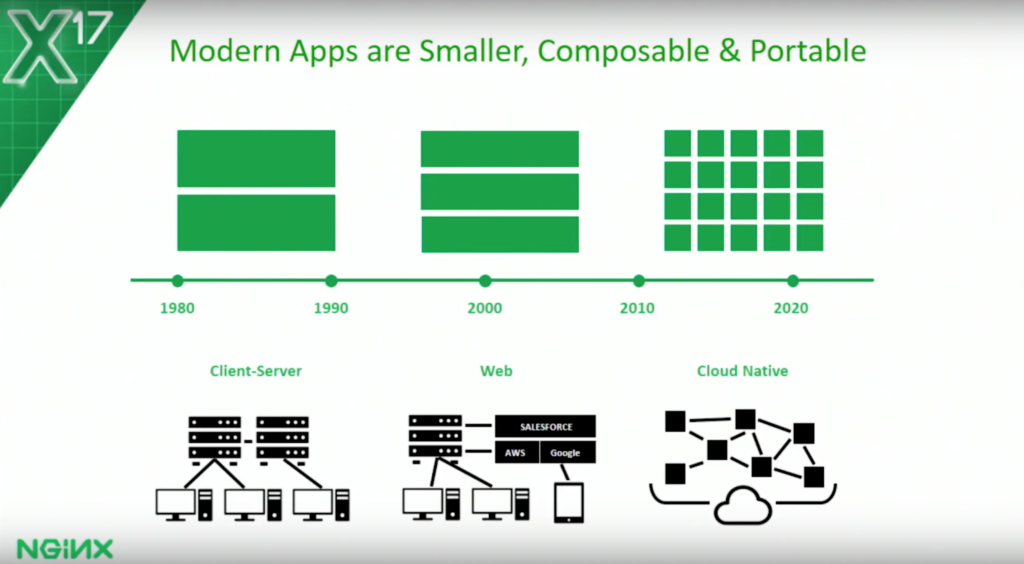
從這張圖可以理解到, 走向微服務架構,有沒有能力管理好這麼多數量的 instance, 是你的 apps 能否成功的上線運作的關鍵因素之一。如果以 container 來看,服務的數量從小規模 (100+) 到中大規模 (1000+),到你在書上看到的各種微服務大型成功案例 (10000+) 就知道,這種數量不大可能靠 IT 人員逐一設置固定 IP + PORT, 然後由 developer 逐一設置 configuration file, 這時善用 service discovery 就是解決這個問題的方法。
前言: 微服務架構 系列文章導讀
Microservices, 一個很龐大的主題,我分成四大部分陸續寫下去.. 預計至少會有10篇文章以上吧~ 目前擬定的大綱如下,再前面標示 (計畫) ,就代表這篇的內容還沒生出來… 請大家耐心等待的意思:
- 微服務架構(概念說明)
- 實做基礎技術: API & SDK Design
- API Design #1 資料分頁的處理方式; 2016/10/10
- API Design #2 設計專屬的 SDK; 2016/10/23
- API Design #3 API 的向前相容機制; 2016/10/31
- API Design #4 API 上線前的準備 - Swagger + Azure API Apps; 2016/11/27
- API Design #5 如何強化微服務的安全性? API Token / JWT 的應用; 2016/12/01
- API First Workshop: 設計概念與實做案例
- API First #1 架構師觀點 - API First 的開發策略 - 觀念篇; 2022/10/26
- API First #2 架構師觀點 - API First 的開發策略 - 設計實做篇; 2023/01/01
- (計畫) API First # 微服務架構 - API 的安全機制;
- 架構師觀點 - 轉移到微服務架構的經驗分享
- 基礎建設 - 建立微服務的執行環境
- 案例實作 - IP 查詢服務的開發與設計
- 容器化的微服務開發 #1 架構與開發範例; 2017/05/28
- 容器化的微服務開發 #2 IIS or Self Host ? 2018/05/12
- 建構微服務開發團隊
- 分散式系統的基礎知識
- 分散式系統 #1 如何保證 API 呼叫成功? 談 Idempotency Key 的原理與實作
Service Discovery Concepts
Service discovery 之所以重要,是因為它解決了 microservices 最關鍵的問題: 如何精準的定位你要呼叫的服務在哪裡。不論你用哪一套服務來提供 service discovery, 大致上都包含這三個動作組合成這個機制,分別是:
- Register, 服務啟動時的註冊機制 (如前面所述)
- Query, 查詢已註冊服務資訊的機制
- Healthy Check, 確認服務健康狀態的機制
過程很簡單,大致上就是服務啟動時,自身就先去 registry 註冊本身的存在,並且定時回報 (或是定時被偵測) 服務是否正常運作。由 service discovery 的機制統一負責維護一份正確 (可用) 的服務清單。因此這服務就能隨時接受查詢,回報符合其他服務期望的資訊。只要彼此搭配的好,所有要跨越服務呼叫的狀況下,就不用再擔心對方的服務再哪邊,或是服務是否還能正常運作等等議題了。要呼叫時,只管去 service discovery 查詢,然後呼叫就好。
觀念講起來非常簡單,我就直接拿一個大家都熟知,而且已經用了很久的例子: DNS + DHCP。現在的人上網,大概就是設備接上網路就可以使用了。背後用的機制就是 DHCP + DNS, 這套已經默默運作幾十年,最老資格的 service discovery 機制。
就從你的 PC 接上網路那一刻開始說明吧! 接上網路那瞬間會發生這幾件事:
-
DHCP 配發 IP:
首先,你的 PC 會對 LAN 廣播,詢問有誰能給它指派個可用的 IP address? 這時 LAN 若有 DHCP Server,就會回應可用 IP 給 PC,雙方溝通完成就順利取得 IP 並且可以開始上網了。DHCP server 會記得在何時分配哪個 IP 給哪個設備 (根據 MAC address)。 -
對 DNS 註冊 HOST / IP:
此時 DHCP server / PC client 也沒閒著,DHCP 順利的讓 PC 動態的取得 IP 之後,接下來就會跟 DNS 註冊這 PC 的 host name 以及對應的 IP (就是剛才 DHCP 分配的 IP)。有些組態,PC 可以自行跟 DNS 註冊;有些情況下 IT 人員不允許這功能,這時就會改由 DHCP server 配發 IP 後由 DHCP server 來負責對 DNS 註冊。不論如何,註冊之後 DNS 就認得該 PC 的 host name 跟 IP 的對應關係了。這就已經完成上面講的第一個動作: register。 -
對 DNS 查詢:
接著,網路上其他人怎麼找到這台 PC ? 很簡單,只要你知道這 PC 的名字 (host name) 就夠了。拿著 host name 到 DNS 去詢問,若登記有案的話,DNS 就會回應正確的 IP address。若還要查詢服務的附加資訊,如其它註記,或是對應的 PORT 等等,DNS 也有 SRV 及 TXT record 可以對應。在這階段就是前面提到的第二個動作: query。 -
確認 HOST 是否存在: 當你要開始連線時,你可能會想先確認一下連線目標是否正常連線中? 最常用的方式,就是用 ping 這個指令來測試看看。ping 會送出封包,若 PC 有開啟 ICMP ECHO 的話,就會回應收到的封包。送出 ping 封包的一端收到回應 (echo), 就知道測試 PC 網路功能是正常的。這階段就是前面提到的第三個動作: healthy check。
雖然講到微服務,沒多少人會舉這個古董的 DHCP + DNS 例子來說明吧,不過這是最簡單易懂的案例,微服務的 service discovery 其實也是一樣的原理,只不過不斷有新的做法來彌補 DNS 的不足。了解到這邊之後,接下來就來看看,常見的幾種 service discovery 機制是怎麼做的。我推薦之前介紹過的 Nginx ebook: Service Discovery in a Microservices Architecture, 介紹一系列的 microservices 的參考架構與做法,其中一個章節就是講到 service discovery patterns. 我截錄其中一段出來…
不論你用什麼方法,service discovery 想解決的問題情境,都可以用這張圖來表達:
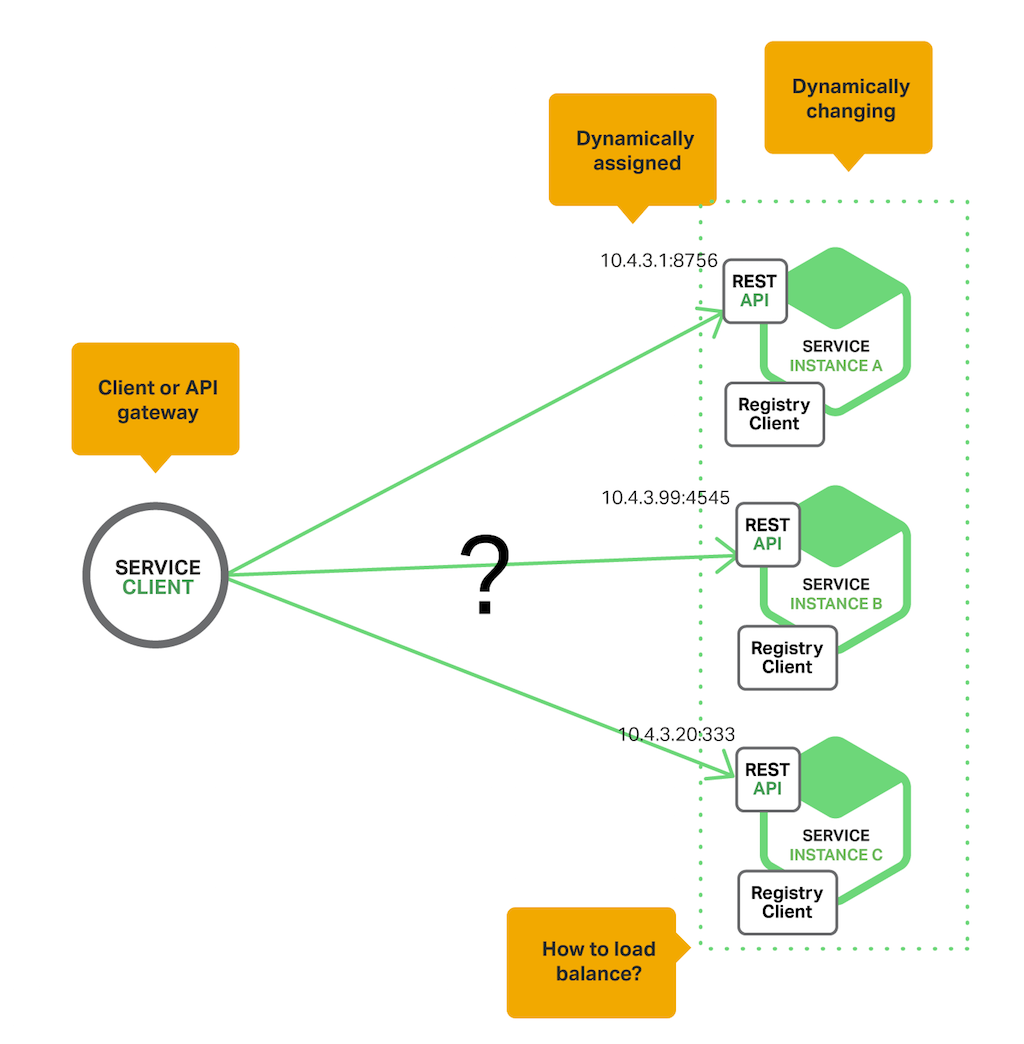
來回顧一下,已經運行數十年的 DNS 有哪些不足的地方? 在微服務架構下,我們預期內部的各個服務,都採取高度動態的前提進行部署。也許隨著流量的變化,幾秒鐘之內就會有新的 instance 被啟動或是關閉,instance 的數量也可能從數十個到數千個不等。這種狀況下,DNS 無法有效的解決這幾個問題:
- 服務清單精確度問題 (DNS TTL 通常只到 hours / minutes 的等級, 也缺乏服務資訊的描述, 如 domain name, ports, service tags or metadata 等等)
- 無法判定服務的健康狀況 (DNS 無法自動踢除當掉的 nodes, 沒有標準化的 healthy check 機制, 例如自動 ping each nodes)
- 無法精準的按照 loading 來分配 request (DNS round robin 無法偵測 server loading)
- 只能靠 client 端自行挑選 service node (DNS 無法代替客戶端進行 request forwarding, 必要時須搭配 load balancer or reverse proxy)
其實要做到上述的需求,只靠 DNS 也太過苛求了。搭配其它對應的服務也許也能辦的到,但是你也必須額外花時間建設,或是開發專屬的功能才能解決。Service discovery 為了解決這些問題, 發展出了幾種常見的模式,我就按照文章介紹的順序來說明這幾種 service discovery patterns:
Service Registration Pattern(s)
先從單純的開始。整套 service discovery 機制要能順利運作,第一步就是先能維護一份可用的服務清單。包含負責處理 service 加入與移除動作的 registry, 以及負責確認這些服務健康狀態的 healthy check 機制。服務本身要如何對 registry “宣告” 自身的存在呢? healthy check 該如何 確認這些服務都維持在可用的狀態下? 作法大致上分兩大類:
-
The Self‑Registration Pattern
自我註冊,顧名思義,上述這些動作,都由服務本身 (client) 自行負責。每個服務本身啟動之後,只要到統一的服務註冊中心 (service registry) 去登記即可。服務正常終止後也可以到 registry 去移除自身的註冊紀錄。服務執行過程中,可以不斷的傳送 heartbeats 訊息,告知 registry 這個服務一直都在正常的運作中。registry 只要超過一定的時間沒有收到 heartbeats 就可以將這個服務判定為離線。 -
The Third‑Party Registration Pattern
這個 pattern 採取另一種做法,healthy check 的動作不由服務本身 (client) 負責,改由其它第三方服務來確認。有時服務自身傳送 heartbeat 的方式並不夠精確,服務本身已經故障,卻還不斷的送出 heartbeats 訊息,或是內部網路正常,heartbeats 可以正確的送達 registry, 但是對外網路已經故障,而 service register 卻還能不斷的收到 heartbeats 訊息,導致 registry 都一直沒察覺到某些服務實際上已經對外離線的窘境。
這時要確認服務是否正常運作的 healthy check 機制,就不能只依靠 heartbeats, 你必須依賴其他第三方的驗證 (ping) 不斷的從外部來確認服務的健康狀態。
這些都是有助於協助 registry 提高服務清單準確度的作法。能越精準的提高手上服務清單的正確性與品質 (清單上每個服務 end points 都是可用的), 你的整套微服務架構的可靠度就會更高。這些方法不是互斥的,有必要的話可以搭配使用。
The Client‑Side Discovery Pattern
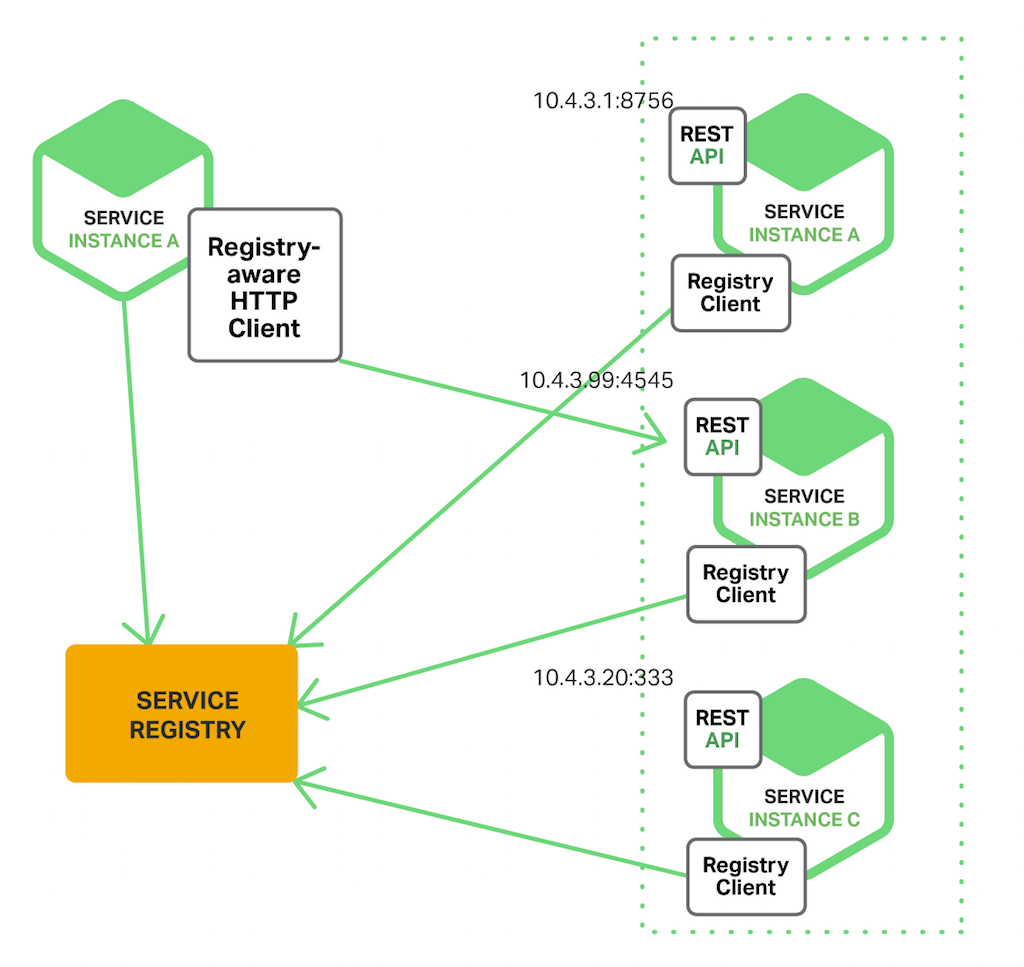
這種模式 (Client-Side Discovery Pattern) 的作法,主要是 client side 使用能跟 service registry 搭配運作的 http client (就是圖中的 Registry-aware HTTP Client) ,在呼叫前先查詢好相關資訊,之後就可用來呼叫該服務的 REST API。Registry 會回報可用的服務 end ponts 清單資訊,由 http client 自己決定要選擇哪一個 end point.
優點:
那麼這種模式下,Load Balancing 通常是 Http Client 查詢服務的 end points 清單後,自己用自身的演算法,來從中挑選一個。好處是呼叫端可以用最大的彈性來自訂負載平衡的機制,包含如何挑選最適當的 end point 等等。有時對服務等級要求很高的時候 (比如 VIP 要求有專屬的服務集群,或是要有更精準的查詢方式等),這個模式會更容易實作。
透過這種做法,才有機會實作點對點的網狀通訊 (例如 service mesh 那樣的機制)。去中心化的通訊,可以避開單點 (API Gateway or Load Balancer) 造成的效能瓶頸,或是單點失敗造成可靠度下降等等的問題。
容易自訂化是這個方式的優點,另外 http client 通常也會做成 library 或是 SDK 的型態,直接引用到你的開發專案內,實際執行時這部分是 in-process 的方式進行,語言間的整合程度最佳,執行效能也最佳,開發集除錯也容易,初期導入 service discovery 的團隊可以認真考慮這種模式。有很多輕量化的 service discovery 也都採用這種模式。
缺點:
然而這也是這模式下的缺點。當這些調度的機制被控制在 client side, 往往也會有對應的風險。當這些機制要更新時,難以在短時間內同步更新,造成有新舊的規則混雜在一起。因為這類 Registry-aware HTTP Client, 多半是以 runtime library 的形態存在,是用侵入式 (邏輯必須注入你的應用程式中) 的方式存在於所有的 client 之間。要替換掉它,通常得重新編譯,重新部署服務才行。也因為它屬侵入式的解決方案,你也要確保你的專案開發的技術或框架,有原生的 SDK or library 可以使用 (當然也得顧及到社群的生態,更新是否快速等等)。只是,對於服務調度邏輯這方面的隔離層級還不夠,解耦也做的不夠,當你很在意這個部分時就得多加考慮。
另一個主要的缺點是, 這樣的設計,也導致你的 application 會跟特定的 registry 綁在一起了,將來換成別套 registry 則需要改寫 code, 你服務的規模越大就越困難。這某種程度其實違背了微服務架構倡導的技術獨立性。
侵入式: 代表這部分的邏輯,會以 source code, library 或是 component 等等的形式,”侵入” 到你的服務程式碼內。這種型態的置入,通常能提供最佳的效能及功能性,也能提供最大的自訂化彈性。不過這也是缺點;意思是這置入的部分一但有任何修正,你的服務是必須經過 更新 > 重新編譯 > 重新部署 這幾個步驟的,往往越通用的套件,要更新都是件麻煩事。採用侵入式的解決方案時,請務必考量到更新與重新部署時的挑戰。
案例: Netflix Eureka
Netflix 將自己的微服務基礎建設跟框架都開源了,就是 Netflix OSS (Netflix Open Source Software center), Netflix 很佛心的把他們微服務化的經驗跟 source code 都開放出來。其實這是個很高明的策略,只要他們有實力,開源反而是讓競爭對手更難追上。之前看過一篇文章: 技术顶牛的公司为啥没有CTO?,說的是網路公司的經營策略,Netflix 這樣做可以建立大眾對他的技術能力是最佳的印象,也因此才能吸引到最好的人才… 這篇值得經營者看一看,作者楊波也是位高手,上個月去北京參加架構師峰會也有幸聽他的課程,值回票價。
在 Netflix OSS 的框架底下,負責 service discovery 的部分,就是 Netflix Eureka , 而對應到這模式的 client, 則是 Netflix Ribbon, 專門設計跟 Eureka 搭配的 IPC client, 允許你直接在 application 裡面自訂專屬的 load balance logic.
截錄這幾個 software 的介紹,有興趣的朋友們可以自行研究:
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers.
At Netflix, Eureka is used for the following purposes apart from playing a critical part in mid-tier load balancing.
- For aiding Netflix Asgard - an open source service which makes cloud deployments easier, in
- Fast rollback of versions in case of problems avoiding the re-launch of 100’s of instances which could take a long time.
- In rolling pushes, for avoiding propagation of a new version to all instances in case of problems.
-
For our cassandra deployments to take instances out of traffic for maintenance.
-
For our memcached caching services to identify the list of nodes in the ring.
- For carrying other additional application specific metadata about services for various other reasons.
Ribbon is a client side IPC library that is battle-tested in cloud. It provides the following features
- Load balancing
- Fault tolerance
- Multiple protocol (HTTP, TCP, UDP) support in an asynchronous and reactive model
- Caching and batching
案例: Consul
Consul 是另一套 service discovery solution, 也是我個人偏愛的 solution. 這是源自 HashiCorp 的產品, 相較 Eureka 是個較新的解決方案。整合度較高,部署與使用簡單使用是吸引我的地方。直接把上述的 service discovery, healthy check, 甚至連舊系統的整合 (透過提供 DNS 的介面) 以及內建 KV store, 用來處理集中式的 configuration management 都包含進去了,降低了進入門檻。
官網就直接清楚說明了他的四大特色,我就順著介紹一下就好。後面我打算另外再寫一篇 service discovery labs 的實作文章,會直接採用 Consul + .NET application + Windows Container, 到時再來詳細介紹這些內容。直接看看官網提供的四個主要特色說明:
Service Discovery:
Consul makes it simple for services to register themselves and to discover other services via a DNS or HTTP interface. Register external services such as SaaS providers as well.
就是前面介紹半天的 registry 的部分。特別之處是除了提供 HTTP interface 之外,也額外提供了 DNS 的 interface. 意思是如果你有些老舊的系統沒辦法改寫,你還可以從 IT 的角度來跟 Consul 整合,只要在 TCP/IP 設定上將 DNS server 指向 Consul 就搞定了,這對於遷移既有系統是很重要的一點,想想看前面提到 DNS + DHCP 例子的缺點,透過這樣的整合模式可以兼顧..
Failure Detection
Pairing service discovery with health checking prevents routing requests to unhealthy hosts and enables services to easily provide circuit breakers.
就是前面介紹不斷提到的 healthy check 的機制。Consul 內建這功能,只要你的服務在註冊時有提供該如何檢測自身的健康狀況,Consul 就能夠自主的維護服務清單與健康狀況等資訊。檢測的方式包含 HTTP, TCP port, 或是透過自訂的 shell script 都可。我們自己的使用狀況,甚至可以拿來檢測外部服務的健康狀況… (這有點撈過界了,不過還不錯用)
KV Store
Flexible key/value store for dynamic configuration, feature flagging, coordination, leader election and more. Long poll for near-instant notification of configuration changes.
整合 KV store 也是我選擇 Consul 的主要原因之一,微服務最難的就是要讓眾多服務能有條理的協同運作;service discovery 只是起點,還有其他環節都需要互相搭配才行。集中式的 configuration management 也是另一個頭痛的問題,雖然他跟 service discovery 並沒有直接的關聯…。
KV store, 就是類似 Redis 這類服務提供的一樣,讓眾多服務有個 key-value share storage 分享資訊而已,通常會拿他來儲存 configuration 組態資訊,服務啟動時的第一件事,就是到 Consul 註冊,第二件事就是透過 Consul 取得組態資訊 (取代 local configuration file),Consul 通通都包了,省了很多事情。其實很多其它套的 service discovery 的底層也是依賴 share storage 來進行的,或是就直接拿 share storage 來使用。例如 ZooKeeper / Etcd 就是。這部分我也不算熟,我只能列一下參考資訊給各位自行研究了。列一篇比較的文章: 服务发现比较:Consul vs Zookeeper vs Etcd vs Eureka
Multiple Datacenter
Consul scales to multiple datacenters out of the box with no complicated configuration. Look up services in other datacenters, or keep the request local.
Consul 架構上允許跨資料中心運作,不過我還沒玩這麼大… 這部分只能理解到 “有” 這個功能,還無法針對使用經驗做任何評論.. T_T
The Server-Side Discovery Pattern
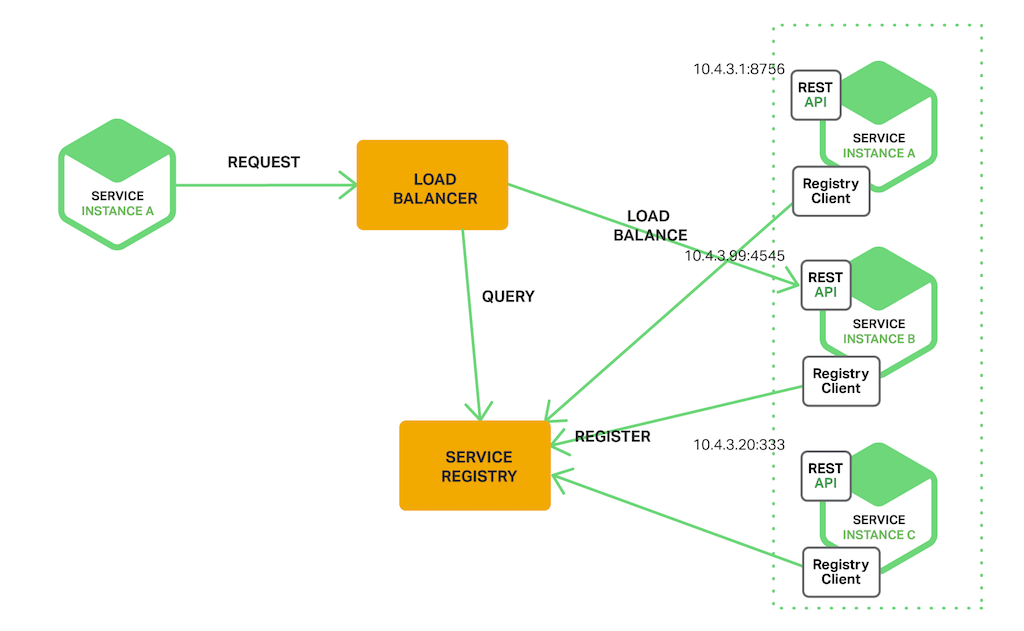
既然有前面講到的 “Client-Side” discovery pattern 的存在,自然也有對應的 “Server-Side” discovery pattern… 就是把原本 client side 執行的 registry-aware http client 這部分拆出來,變成一個專屬的服務;就是圖上標示的 “LOAD BALANCER”。
跟一般的 Load Balancer 不大一樣的地方是: 這個 load balancer 會跟 registry 密切的配合 (registry aware)。Load balancer 會即時的按照 registry 提供的資訊,扮演 reverse proxy 的角色,來將 request 導引到合適的 end point. 相較於 registry aware client 的做法而言,server-side discovery pattern 對 application 而言是透明的, service discovery 的邏輯, 都集中在 load balancer 身上。
優點:
相較於 client-side discovery pattern, 優點很明確, 就是 registry 對於 client side 來說是透明的,所有細節都被隔離在 load balancer 跟 service registry 之間了。不需要侵入式的 code 存在 client side, 因此也沒有前述的 language, library maintainess 等相關問題, 更新也 只要統一部署 load balancer & service registry 就足夠了。
缺點:
這樣一來,服務的架構等於多了一層轉送了。延遲時間會增加;整個系統也多了一個故障點,整體系統的維運難度會提高;另外最關鍵的,load balancer 可能也會變成效能的瓶頸。想像一下,如果整套 application 存在 N 種不同的服務,彼此都會互相呼叫對方的服務,那麼所有的流量都會集中在 load balancer 身上。
同時,這樣的角色,也很容易跟微服務架構下其他的基礎建設混在一起。例如 service registry 跟 load balancer 的整合, 可能導致兩者必須採用同一套服務了;再者, 轉送 (forward) 前端的服務請求 (request),這角色要做的事情又跟 API gateway 高度的重疊,然而 API gateway 還有其他它要解決的問題啊,最終可能會演變到這些服務,重複出現好幾次 (前端有 API gateway, 後端有另一套 load balancer, 或是每組服務都有自己的 load balancer 等等)。如果你的規模不夠大,可能你還沒享受到它帶來的好處,你就先被它的複雜度與維運成本給搞垮了…。
回想一下,微服務化的最初用意,有這麼一項: 故障隔離,將整個系統切割為多個服務共同運作,若有某個服務無法正常運行,那麼整個應用系統只需停用部分功能,其他功能要能正常運作。這樣做的方向就是要去中心化,不過 server side discovery pattern 就是集中式的做法啊.. 不過這並沒有絕對的好壞之分,主要還是要自己評斷你的狀況適合用哪一種模式。非侵入式的解決方案,就是部署與更新非常容易,雖然有些效能上的折損,但是高度彈性的應用方式越來越受歡迎,我在下一篇講 Service Mesh 時會進一步說明…。
案例: Azure Load Balancer / AWS Elastic Load Balancer
Nginx 原文提到的案例是 AWS Elastic Load Balancer, 不過我比較熟 Azure 啊,所以我就拿 Azure Load Balancer 來當例子了。兩者都是 cloud service 業者提供的 Load Balancer 服務,用來將來自 internet 的 request, 平均的分散在內部的 service 身上用的服務。
其實這類機制,雲端廠商早就都已經準備好了。當你啟動一台 VM 或是其它具備 end points 的服務時,早就在內部的 registry (或是對應角色的服務) 裡有記載了。只是你啟動的對象,是廠商準備好的 VM,因此 registry 紀載與偵測的對象也是這個 VM 為主。當你啟用 load balancer 服務後,他判定的來源就是內部的 registry 啊,接到來自 internet 的 request, 自然的就按照 registry 的內容來 forward request.
案例: Docker Container Network
這個案例是我自己補的。前幾篇文章,各位朋友有留意的話,大概也有發現我談過 DNS 這件事情。實際上 docker compose / docker swarm 內部就是用同樣的機制。Container 做的是 OS 的虛擬化,每個 container 都會認為他擁有整個 OS 的使用權。每個 container 能對外溝通的幾個管道也都被虛擬化統一管理了,這些虛擬化的管道包括: volume / environment variables / networking.. containers 之間想要互相溝通,就只有這幾種方式而已。
因此, docker 直接透過 networking 的管理, 很巧妙的利用上述的 DNS / DHCP 達成這件事。雖然是老技術,但是運用的非常巧妙,這是我很佩服的地方。我舉個實際的例子,在這篇文章裡提到的 IP 查詢服務, 我在 docker compose 定義了這幾個 service(s):
- webapi
- worker
- proxy
- console
每個服務都可能有 1 ~ N 多個 containers 同時運行,這時 docker 本身當然能精準的掌控這些資訊,但是他如何讓 container 內部也得知這些資訊? (重點是還要確保傳統應用程式不需要為 docker 重新改寫),docker 的做法,就是提供內建的 DNS (127.0.0.11), 並且把每個 service name 當作 host name, 只要 container start 後,就把他被分配到的 ip address 註冊到 docker internal DNS 內,每個 container 只要去 DNS query service name, 就可以精準的得到其它 containers 的 IP 了。
由於這些 container 的啟動與結束,都受到 docker 的控制,若上面的服務掛了,這個 container 也會直接被終止,因此 docker engine 本身對於 container 的掌握程度是很高的 (至少比 hyper-v 對於 VM 內的 application 掌握程度高多了)。透過這樣的封裝,在 docker 內使用 DNS 來做 service discovery 是很容易且精準的。
到目前為止,服務之間要找到彼此都還是靠 DNS,原則上還是歸類在 client-side patterns 啊,為何我把這機制歸類在 server-side patterns ?
主要有兩個原因,一來這個案例內,我用了 Nginx 扮演 reverse proxy, 目的是讓 docker-compose 以外的服務,能有單一入口來存取裡面的 webapi service, 這裡的 nginx, 就是透過 docker 內部維護的 DNS, 動態的去做 reverse proxy / load balancing. 這不就完全符合 server side patterns 的架構嗎? 若範圍在擴大一點,從單機版陽春的 docker compose, 放大到 docker swarm / kubernetes 等等這些 container orchestration 的機制,我這範例裡提到的 Nginx 這種角色的服務就通通內建了。
舉例來說,幾個月前我 這篇 文章,提到 docker swarm 的 routing mesh 機制, 就屬於其中一個例子, docker 幫你把整個 service discovery 的機制通通都包起來了,你的 container 從一 “出生” 就被監控了,誰能跟你的 container 聯繫也都在 docker swarm 的掌控之下 (像不像駭客任務裏面的 Matrix ?) 。因此當你透過 docker 來部署你的服務時,其實你已經在用 docker 替你準備的 internal service discovery 機制。除非你有進一步的需求,例如額外更精準的 failure detection, 或是要更精準的查詢服務的健康狀況,還有服務資訊 (service ip / port / tags / descriptions),你才需要自己另外建置專屬的 service discovery。
效益 & 結論
介紹了這麼多,還都只是 microservices application 最基本的基礎建設而已。我會花這篇幅介紹,因為他是讓你的系統 “微服務化” 後能順利運作的關鍵啊! 微服務帶來的眾多優點都需要依靠 service discovery, 想想看微服務最大的優點: 容易維護的小型服務 + 容易擴充 (scale out) 這兩點就好。相較於單體式的 application, 兩種架構下的 instance 數量可能會從 10 個以內 (monolithic), 擴張到 100 個左右 (microservices).
若沒有 service discovery 在背後協助,維護健康的服務清單,協調全部服務的通訊的話… 你會發現你的 application 可靠度會變的很糟糕。一來你很難正確的維護每個 service 的 end points, 再者你也很難確保每個服務都是健康的,碰到故障的服務你無法在第一時間剔除他…
要量化這件事很容易,我們只要簡單的計算一下 SLA:
假設每個服務 instance 故障的機率是 p%, 在沒有妥善管理機制下,任何一個 instance 故障都會造成整個 application 不穩定。那麼:
- 單體式的故障率:
1 - (1 - p) ^ 10 - 微服務的故障率:
1 - (1 - p) ^ 100
再來,看看在有 service discovery 協助的狀況下,假設先不考慮效能,那麼只有所有的 instance 故障,整個 application 才會故障 (因為故障的服務會自動被排除),那麼:
- 單體式的故障率:
p ^ 10 - 微服務的故障率:
p ^ 100
簡單的用 P = 1% 來計算的話:
| 架構\組態 | 基本(對照組) | 服務發現 |
|---|---|---|
| 單體式APP | 9.562% | 1E-20 |
| 微服務APP | 63.397% | 1E-200 |
當然這個計算方式有點誇大,跟過度簡化,但是他能表達出為什麼你需要注意 service discovery 這件事。我一直在提醒自己,微服務背後是需要高度累積各種架構與經驗的策略,典型的表面看起來很棒的技術,但是實際做起來到處都是地雷會炸斷你的手腳的…,初次導入這項技術的朋友們,千萬不要過度輕敵啊.. 跨入微服務,等於是對你的團隊做一次軟體工程的健康檢查,從 DevOps 到 CI / CD, 從 source code control, 到 release management, 到 TDD / unit testing 到各種開發的規範,到各種日誌、例外與錯誤的管理等等,都是個考驗。因此我都用這種態度來面對微服務的挑戰,每個基礎建設都有它存在的目的,你要嘛老老實實地照著實作,若想省掉他就一定要花精力徹底了解為何要這樣做之後,在經過你的經驗判斷確實可以省掉後才省掉。否則這些欠下的技術債總有一天會回來的。
寫到這邊,總算把 service discovery 的目的與用途交代清楚了。後面計畫還有兩篇相關的文章,一篇是 Consul + .NET 的開發範例說明,另一篇則是進階的變種: service mesh。敬請期待續集 :D
