
這篇的內容,是我在今年 DevOpsDays Taipei 2024 擔任 Keynoye 演講 + 時間不夠被我略過的部分寫下來的文章。延續 2022, 2023 談的 “API First”, 延伸到 AI 應用程式開發,正好銜接到我半年前在研究的 LLM App 時寫的三篇文章內容, 這次投稿就用了這標題 “從 API First 到 AI First” 來聊聊這內容。
各行各業的每個環節, 大家都在想怎麼善用 AI 與相關工具了, 不過開發人員把它當作服務或元件,用在自家的產品上的案例就少得多。我自己是軟體開發產業的人,我的角色是架構師,我看到的是: AI 是個強而有力的元件,只要掌握清楚它的特性,就有機會在你的應用程式好好的利用他,而這也是這半年間,我下班時間都在摸索的事情。我驗證過好幾種想法,在那段時間我的 ChatGPT plus 的額度每天都被我用光了,到現在也算是有點心得,於是就有了這個主題,也有了這場演講 & 這篇文章。
這整篇的心得,其實摘要起來只有一段話,就是:
未來 AI 充分運用在各個領域的年代,你現在的軟體開發基礎只會越來越重要。
要確保未來 AI 盛行的世代還保有競爭力,請把基礎的功夫做好。
現在的生成式 AI 可以補足很多瑣碎的事務,我身邊的人都是 developer,對我最有感的就是 AI 可以大幅縮短 coding 的時間。不過縮短的是 “寫那些我覺得很無趣的 code” 的時間,真正有趣,真正需要思考或設計的地方,目前 AI 還幫不上忙。對我而言,我倒是省掉了很多處理這些瑣事的精神,可以更專注在架構跟技術決策上。
這些體驗,我更確定了這篇文章我想傳達的兩個觀點:
- 當 coding 可以量產的時候, 會決勝的是抽象化設計的品質
(能否被高效率 reuse 才是關鍵, 一次性 / 客製化的 code, AI 會寫得比你快,比你好) - 當 coding 速度不再是瓶頸的時候, 基礎建設與架構的設計決策會是關鍵
(你是否能有系統有效率的管控 AI 相關的基礎元件? 包含 CI / CD 的 pipeline? 對於 AI 最重要的數據與模型, 你知道該如何 DevOps 嗎?)
在我寫這篇文章的時候,正好看到這篇 貼文,驗證了我的觀點。感謝好心人給了中文的註釋,留言的討論也都是中文的, 我直接附上 連結
整串討論下來,我摘要我最有感的部分:
…
我認為一件非常重要的事是,你需要對你的應用程式架構有非常好的掌握,不僅是大局,還包括更具體的程式碼相關事項,如你處理數據獲取的設計模式等。如果你在這方面缺乏經驗(這是透過成為一個優秀的程式開發者獲得的),而只是使用 Claude,我認為程式庫通常會變得過於雜亂和複雜,導致日後難以進行修改。
… (略) …
首先,我有一個 Claude 專案,我會在其中上傳相關文件。最重要的文件是我稱之為「主要脈絡」的文件,我在這裡非常清楚地說明應用程式目前的功能以及下一個版本應該做什麼。我還指定了所有技術決策,以及為什麼選擇它們。我還解釋了我希望 Claude 遵循的更具體的程式碼設計模式(例如,如何保持伺服器狀態和客戶端狀態同步,有許多不同的方法可以做到這一點,但你肯定希望在整個應用程式中保持一致性)。我還在這裡有一個完整的數據庫架構文件,以及一些範例 API 端點。這些文件基本上總結了該專案到目前為止的所有內容。
… (略) …
我同意你的看法,你仍然需要做出架構決策。只是現在實際的實施部分變得如此快速。
…
看到這裡,認同我的觀點,那就繼續往下看吧! 本文正式開始 : )
1. 寫在前面

前情提要的部分我就直接略過了 (演講當下不是每個人都聽過我過去的場次,我還是花了點時間交代關聯),我直接給參考資料,有興趣的朋友自己看。前情提要主要包含 2021 ~ 2023, 連同今年 2024 的內容我一起放在下方:
- 2024: 從 API First 到 AI First
- 2023: 架構師也要 DevOps - 談服務模型的持續交付
- 2022: DevOps 潮流下的 API First 開發策略
- 2021: 大型團隊落實 CI/CD 的挑戰
跟本文相關的四篇文章 (文內有引用到),我也一起放在這邊:
- 2023/01, 架構師觀點 - API Design Workshop
- 2024/01, 架構師觀點 - 開發人員該如何看待 AI 帶來的改變?
- 2024/02, 替你的應用程式加上智慧! 談 LLM 的應用程式開發
- 2024/03, 替你的知識庫加上智慧! 談 RAG 的檢索與應用
另外,為了這篇我準備了幾個 DEMO (主要是 GPTs 的形式) 來帶出我想談的幾個議題:
- DEMO #1, 由自然語言處理能力的進步,所帶來的 UX 改變
- DEMO #2, 由自然語言處理能力, 掌握使用者的滿意度; 精準地做到個人化
- DEMO #3, AI 作為輔助的角色 ( copilot ) 的應用情境, 說明應用程式架構該如何整合 LLM,以及開發人員該具備的基本設計技巧
- DEMO #4, AI 處理資料的基本技巧
DEMO 的過程,我會穿插說明背後用到的技術與觀念的改變。文章第四段,會提到我老闆 Happy 在 Generative AI 年會 ( 2024 / 05 ) 談的題目: “零售業的 AI 產業應用 - AI 可以幫助做銷售嗎?“。這題目正好是我這場的最佳應用。兩者一起看,你會發現,原來活生生的應用案例,就是這樣跟基礎的技術發展搭配起來的。
演講當下我覺得很可惜,這段實際應用案例的串聯因為時間關係沒有講到,其實這關聯才是關鍵。部落格文章的部分,我就把這段補回來了。就算你當下有在台下聽我 DevOpsDaysTaipei 的這場 Keynote 演講,我也建議你再看一次這篇文章,我相信你會多看到 (體會) 到不一樣的內容。

// 簡報 P5, AI 話題已經燒了整整一年以上了,我看到的內容大部份是…
Generative AI 對大部分的軟體開發人員 (除了本來就在鑽研 AI 相關領域的之外) 而言,都算是新東西。面對新東西,社群與新聞媒體的討論自然也很熱烈。不過我很在意其中一點,就是在社群與媒體上,大家討論的熱度都集中在:
- 模型的進步: 各種主流 AI 模型的評比與介紹
- 算力的進步: 各硬體大廠 AI 算力的提升 (GPU / NPU 等) 的進步,AI 晶片的發展,以及各雲端服務商費用比較
- 工具的進步: 各種 GenAI 工具的介紹,使用技巧 ( ChatGPT, Stable Diffusion 等 )
這些的確都是 AI 的熱門話題,不過這些都還不是最終的應用啊! 我想像的最終應用,不是大家都拿 GenAI 的工具 (例如 ChatGPT) 處理生活大小事,而是你目前用的各種服務都已經內建 AI,並且由開發人員妥善幫你安排好 AI 該替你做甚麼才對。很多人拿挖金礦當比喻 AI 產業,在我看來,(1) (2) 其實都是在賣鏟子,而 (3) 則是告訴你挖到金礦後有多美好… 不過仔細想想,真正有產值的是 “怎麼挖出金礦”,這還沒變成大家討論的主軸啊;這環節,才是所有軟體開發人員該思考 & 面對的題目 (“當 AI 真正變成軟體開發的重要元件,成為軟體開發中的重要一環”)。
業界在 AI 投入了那麼多資金在建立算力,在訓練模型,不過創造出來的運算能力卻還沒有足夠多的應用程式來善用他,需要大量的軟體開發人員投入研究,如何有效的把 AI 應用在你自己的產品服務上。為了想通這些問題,我逐一問自己:
- 當模型 (LLM) 越來越強:
我有需要從頭訓練自己的模型嗎? 如果業界的模型成熟到某一個程度,我會知道我該拿它來幹嘛嗎? - 當 GPU / NPU / CPU 的運算能力越來越強:
等到 AI 算力普及了 ( 雲端的 token 夠便宜、雲端的 GPU 算力夠便宜、終端的 NPU 夠普及 ),我想好我的產品或服務該如何運用它了嗎? - 當 AI 相關工具的成熟:
現在的 AI 相關工具,都在強化 “你” 自身的能力;當模型跟算力都不再是問題時,你準備拿 AI 如何強化別人的能力? 如果要讓你自己的服務也能被 AI 強化,你現在該準備 / 學習什麼?
這些問題還沒有標準答案,不過我有自己的想像,我都寫在這篇文章內了。
2. 示範案例: 安德魯小舖 GPTs

// 簡報 P12, 安德魯小舖 GPTs
首先登場的,是先前我已經發表過的 GPTs, 安德魯小舖。這是我半年前嘗試的一個實驗性專案,我拿購物網站的後端 API 作為基礎,一般而言是拿這 API 就能做出一個購物平台,而我捨棄 WebAPP 的作法,將這 API 拿來給 ChatGPT 使用,讓 ChatGPT 在跟我對話的過程中,除了正常回應我的問題之外,他也能呼叫我給他的 API 取得資訊後給我回應 (例如: 查詢商品資訊 API 後彙整我的需求,給我推薦商品),也能按照我的要求完成操作 (例如: 按照我的對話要求,替我呼叫 API 將指定商品加入購物車結帳)。
“安德魯小舖 GPTs” 已經上架到 ChatGPT 的 GPT Store , 如果你看了我的介紹跟 DEMO 感興趣也可以親自體驗看看。不需要 GPT plus 訂閱就可以使用 (只是有額度限制),操作過程中會需要帳號,你只需要在登入畫面上輸入 ID 就好 (ID 隨意),單純作為系統運作識別消費者使用。
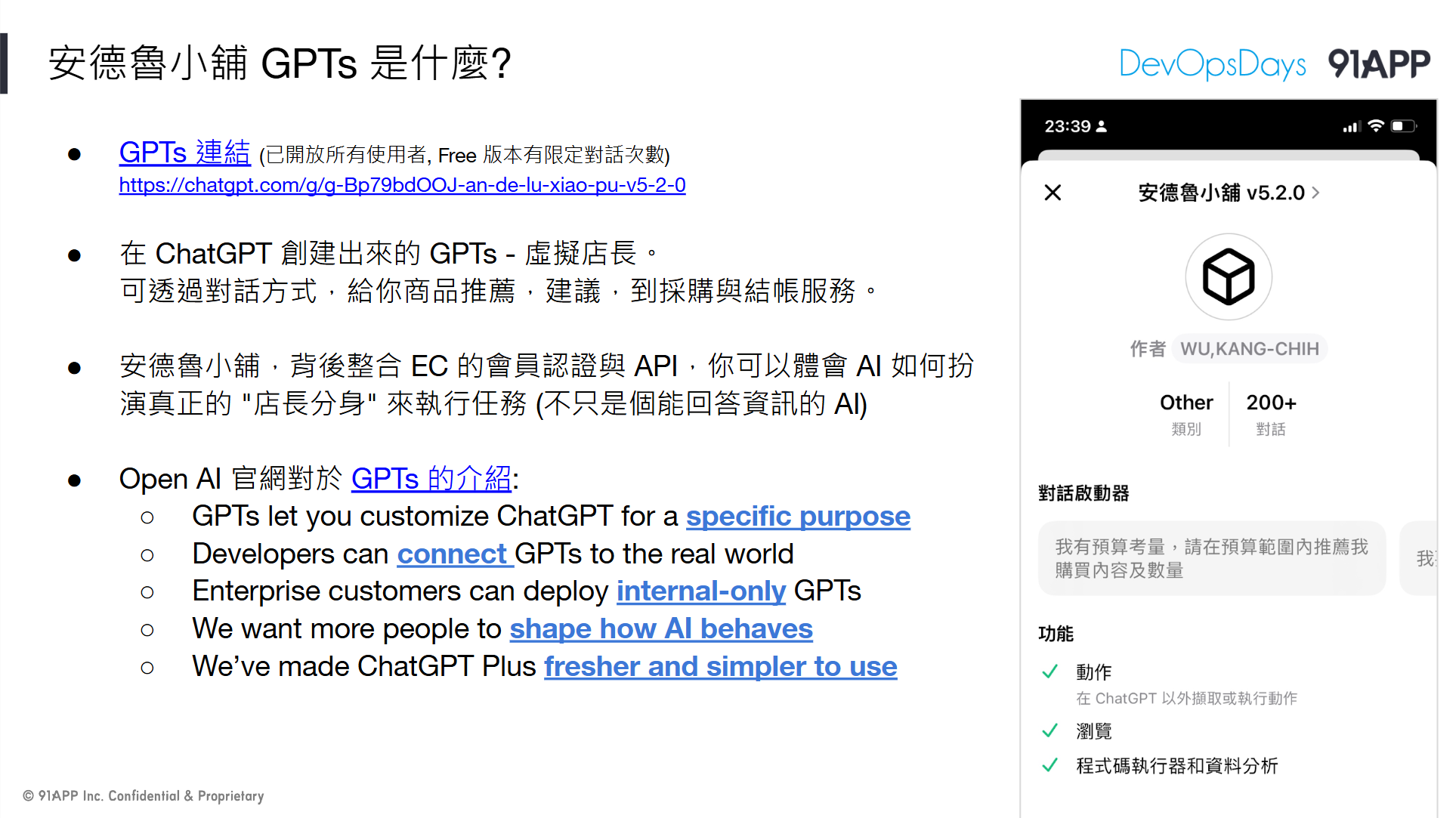
// 簡報 P13, 安德魯小舖 GPTs 是什麼?
從半年前第一次發表至今,這 GPTs 基本結構沒有太大改變,但是我多嘗試了幾種應用方式。基本能力介紹我就不再多說,有興趣的可以參考這一篇,第一段我都在介紹這個應用:

#安德魯的部落格, 架構師觀點 - 開發人員該如何看待 AI 帶來的改變?
2-1, 出一張嘴就能買東西的魔法

// 簡報 P14, Demo #1, 出一張嘴就能買東西的魔法
不過,DEMO 的腳本我還是有重新設計。為了方便在 Keynote 當下展示,我預先錄好了影片,也做了案例說明簡報,大家可以對照看。簡報左邊我標上影片的時間跟對應的案例情境,右邊則是實際的影片播放。

// 簡報 P15, Demo #1, 出一張嘴就可以買東西…
我直接把 DEMO 影片拿出來放這邊:
這個 DEMO 我示範了三個情境:
- (00:00 開始) 使用者詢問推薦商品,限定預算,指定商品。店長能協助加入購物車,並且結帳
- (00:40 開始) 使用者查詢購買紀錄,並且按照期待調整呈現方式。將表格改成條列 (適合手機),從訂購紀錄統計商品數量
- (01:10 開始) 使用者直接跟店長說明情境,由店長判定並且推薦適合商品,並且協助完成結帳
這些情境 DEMO,我背後的想法只有一個,就是 GPTs 已能用對話 (自然語言) 的介面,讓使用者能用口語的方式真正的 “要求” AI 處理購物需求了。我想像中的 “提出要求” 跟 “下指令” 是不同的兩種概念,如果你看完這段影片,你應該會理解我的差別。
所謂的 “提出要求”,就是在對談中我說我想要幹嘛 (我的意圖),而 AI 聽完後替我設想,並且找出對應的動作 (就是 API call),自動替我完成目的。影片的案例中我講了預算跟目的,GPTs 替我推論出我應該買什麼商品,並且按照預算要求來試算後將商品加入購物車並結帳;交易後也能按照我的要求,當下就改變資訊呈列方式來配合我;同時也能替我用我希望的方式整理資訊 (例如不照訂單排列,而是要按照商品來統計) 後呈現等等都算。
而所謂的 “下指令”,則少了 “了解意圖後找出對應動作” 這層解析,我得自己清楚我要要求 AI 執行甚麼指令,AI 頂多做到辨識指令,精準執行而已。例如前幾年很流行的語音助理,大概就是這個層級,你說一動他做一動,你換個方式下令他也許還聽得懂,但是需要邏輯推論的 (例如用預算反推) 大概就辦不到了。
多了這層 “意圖” 的轉譯,我覺得是個很大的變革了。這背後主要的機制都是 LLM 帶來的改變,如何從對話解析出意圖,然後呼叫對應 API 的一連串機制。簡報的 P15 ~ P18 主要是說明我做了哪些準備,才完成這個 GPTs 的。這些細節其實在上面那篇文章說明過了,這裡就先跳過。
在後面 第三章 的部分,我會有一段說明 AI 開發的基礎技能,那邊會再談談 LLM 是如何從單純的對話解析,逐步演進到有能力進行 function calling ( OpenAI 稱為 function calling, Anthropic 稱為: tool use,講白話就是讓 AI 自己判斷他該呼叫那些 API 來完成任務 )。
2-2, 透過 AI 來提升使用者體驗

// 簡報 P19, 降維打擊: 透過 AI 來提升使用者體驗
從結果來看,安德魯小舖 GPTs 比一般的購物網站做得好的地方,就是 “精確的對話回應” 吧。由於能理解意圖並且代替客戶操作網站就能完成下訂單的過程,我暫且把這結果當作 “更好的使用者體驗” 吧。這時,我回頭想:
那麼過去購物網站,都是怎麼提升使用者體驗的?
問了自己這個問題,就帶出這一連串的想法跟結論了。我想完後第一個感想就是:
用 LLM 來處理使用者體驗,跟 UI 對比根本就是 “降維打擊” 啊,完全是不同維度的做法
的確,用 AI 來提升使用者體驗 (UX),我覺得跟傳統提升 UX 的方法完全是從不同角度切入。我並不是說 UX 以後都要靠 AI 了,而是藉由這個案例,我看到了在 “猜測” 使用者意圖這範圍內,用 LLM 來處理,比起大量的訪談,流程設計,介面設計等手法,來的更準確更有效。如果你有能力辨識出那些情境該用傳統手法,那些情境該善用 AI 來解決,你就能得到兩者加乘的效果。
而介面或流程的改善,則是在降低使用者完成 “操作” 的障礙。基本上是使用者已經知道自己想要幹嘛了 (清楚意圖後的行動),良好的 UI 設計可以降低操作障礙,讓使用者很容易就完成 ( one click, 簡化身分認證, … 等等 ),而協助客戶理解意圖代為行動,則是另一個領域的事情。因此我說, AI 不會取代 UI / UX 的作法,兩者相輔相成;但是 AI 開創另一條路線,有機會用大模型解決以前碰不到的操作障礙。
我用兩頁簡報來總結這些想法:

// 簡報 P20, THINK: 你覺得 “安德魯小舖 GPTs” 的 UX 好嗎?

// 簡報 P21, THINK: 你覺得 “安德魯小舖 GPTs” 的 UX 好嗎? (續)
除了前面聊到的,還有一些較瑣碎的觀點,我一起列在這邊:
-
以 LLM 改善 UX 的路線:
這方式靠的是 LLM 理解對話上下文的能力,邏輯推論的能力,再搭配呼叫 API 執行動作的能力組合而成的。這些能力組合起來,你會開始有種錯覺,GPTs 聽得懂你 “想” 幹嘛,同時還能 “替你” 代勞操作系統 (挑選商品,加入購物車,結帳)。 -
“真正” 去 “理解” 使用者的意圖:
現有系統靠的都是大量的流程與介面 “引導”,搭配統計數據去推測使用者意圖而設計的。一來不夠直接,驗證很花時間;二來小眾的想法容易被忽略,因為這些小眾的需求不容易在統計數據與行為追蹤被凸顯出來,自然就不會被設計在 UI 內解決。透過 LLM 直接解析個別對話的做法,恰巧避開了這些盲點,因此這也是我所謂 “不同維度” 就是這個意思。 -
現在開始評估用新的做法 (AI):
目前 AI 還不夠成熟,速度也慢,費用也高。不過這些問題會在未來被解決掉。到我寫這篇文章為止 (2024/07),產業大老說 AI 運算能力每 2 年會提升 10 倍,OpenAI 每隔幾個月都會很有感的調降模型的費用;而 CPU + NPU 廠商也不斷地在提升終端設備 AI 的推論能力,這些 LLM 的推論可能都不再需要支付雲端費用… 單靠本機的小模型與算力就足以支持。
2-3, 偵測購買滿意度的魔法
接著繼續往 AI 改善 UX 這方向嘗試,這次的情境是:
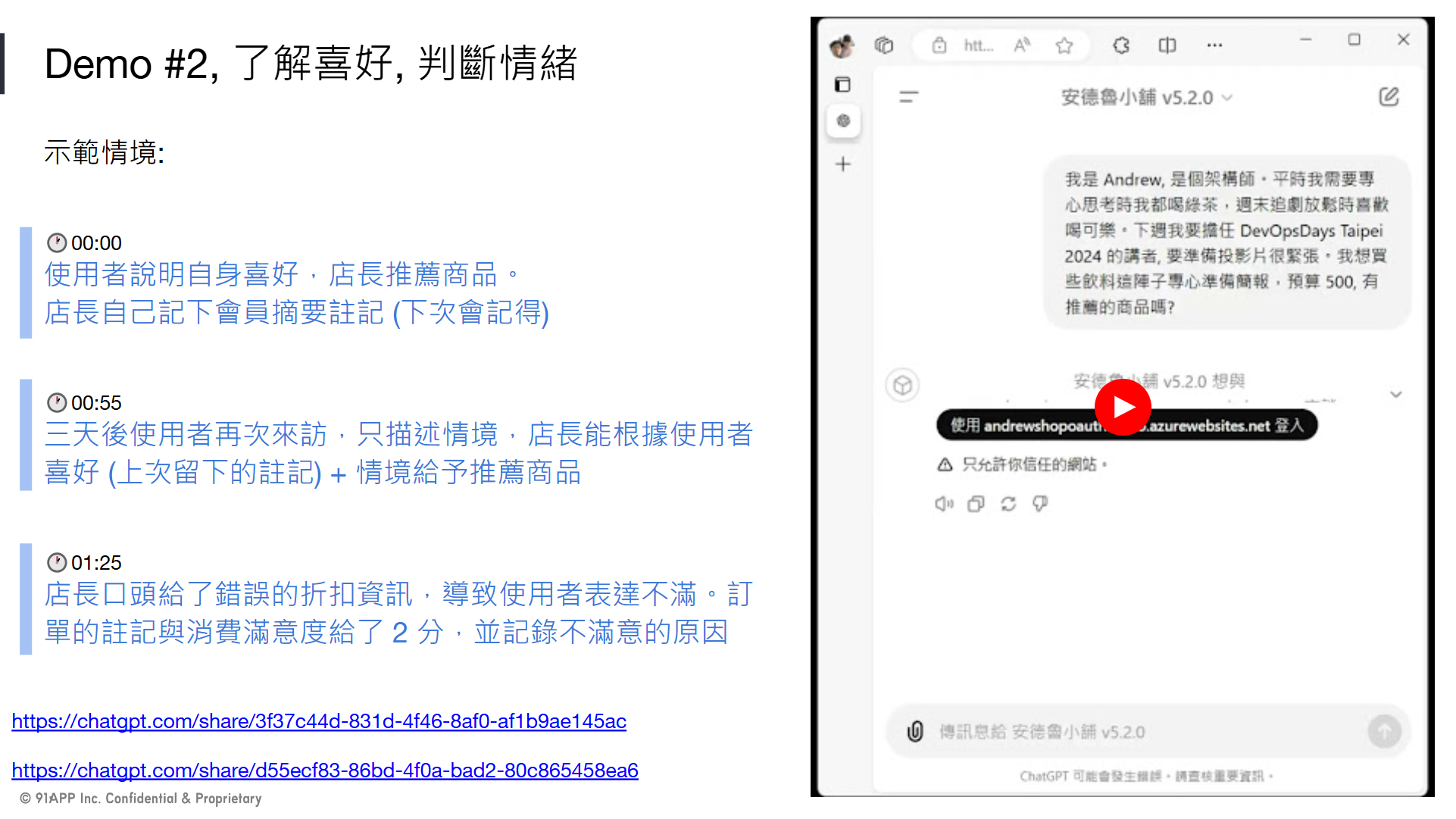
// 簡報 P23, DEMO #2, 了解喜好, 判斷情緒
DEMO 的影片我放在這裡:
這次我想挑戰兩個期待:
- 一個是 GPTs 能否掌握我的習性 (從對話中捕捉我的喜好並且記錄下來),並且在我提出需求時能按照我的習性給我量身訂製的回應
- 另一個是已經完成的交易,我希望 GPTs 能從過程中 (從整個交易的過程中捕捉) 記錄下使用者在這次交易中的感受 (包含量化的評分: 滿意度)
同樣的,各位對比一下,想要做到個人化 & 滿意度回饋,現在是怎麼做的?
- 收集數據:
包含: 購買內容,操作行為,跨站的追蹤,廣告喜好等等,善用各種大數據或是機器學習的技巧來替使用者貼標分類 - 指標監控:
監控: 跳出率,轉換率等。用各種監控指標,來看看某些特定商品,或是某些介面或功能設計,是否更獲得使用者喜好? - 滿意度問券:
設計問券,並且搭配各種誘因 (例如給五星好評送小菜,填問券送贈品或是累計點數) 讓使用者願意回饋評分或是評價
不過,經過前面 UX 的思考,我開始也有同樣的感覺:
這也是透過大量事前的布置,或是事後的統計,試圖在外圍累計的數字上來 “猜測” 使用者真正的想法。而在這樣的量化指標下,也開始有偏差的做法 (例如餐廳要你給五星好評才送你小菜,這樣的評價還是真的評價嗎?)。然而是否有機會跟前面案例一樣,如果有了成熟的 LLM,能否直接從赤裸裸的上下文紀錄,捕捉到使用者背後的情緒,喜好,感受?
現在的 LLM “可以” 做得到,但是做的還不夠好,不過我還是做了嘗試。我賭的是: 好不好的問題,時間會解決 (對,我就相信還沒踩到理論極限,就交給訓練大模型的 AI 大廠吧),然而可不可行這件事,程式該怎麼寫,系統該怎麼設計,我覺得現在就能開始嘗試了。嘗試的結果,我發現事情遠比我想像的簡單得多… (作法很簡單,但是正確性還有待提升)。
同樣的,我覺得這又是另一個 “降維打擊” 了。我一樣看到另一個不同的 “新路線” 出現了,發展下去必定能做到目前方法遠遠不可及的成效。這邊的案例,我特地花點時間,用文字來描述一下我看到的改變。先來看第一個案例:
情境: 使用者說明自身喜好,店長推薦商品。店長自己記下會員摘要註記 (下次會記得)
驗證結果: GPTs 從對話過程中,擷取並摘要我的喜好描述 “架構師,喜歡在專心思考時喝綠茶,週末放鬆時喝可樂。”,並且呼叫 API 記錄在我的客戶註記欄位
三天後使用者再次來訪,只描述情境,店長能根據使用者喜好 (上次留下的註記) + 情境給予推薦商品
AI 在我詢問內容,要回答我之前,先嘗試透過 API 讀取我的客戶註記資訊,並且把它併入上下文,綜合之後給我推薦建議,並且代替我執行對應的 API
店長口頭給了錯誤的折扣資訊,導致使用者表達不滿。訂單的註記與消費滿意度給了 2 分,並記錄不滿意的原因
結帳完成後,AI 總結這次購物過程的對話歷程,擷取並且摘要跟 “滿意度” 相關的註記,並且給了一個主觀的分數,呼叫 API 註記在訂單身上
2-4, 再來一次, 你覺得 UX 夠好嗎?
從這個案例,我看到幾個地方:
-
從數據統計,到 LLM 判斷使用者體驗:
同樣的,這是事前 / 事後,靠統計 / 靠當下情境判斷 + AI 的差別。我認為這也是不同維度的做法了,不是取不取代的差別。你沒有必要捨棄目前已經運作得很好的做法,而是做好準備,用新方法來面對既有作法改善不到的環節。 -
從數據推薦,到 LLM 判斷喜好後量身訂做推薦:
同樣的模式,只是都把資訊轉成自然語言,一切交給 LLM 來判斷 (這邊應該要善用 Embedding, 類似 RAG 的做法, 但是我 PoC 沒有處理這段)
這實驗結果,給我的感覺就像是老練的業務員,他會有先天敏銳的直覺,就能察覺客人背後的想法,同樣的客戶給他服務,業績就是會比較好 (完全無關數據統計)。回到頭來,其實業務員的經驗也是需要數據 (經驗) 的累積,只是收集的數據是這業務員一輩子的經歷訓練出來的模型 (存在業務員的腦袋內),而不是在這個系統內的大數據。現在 LLM 發展的路線,就是用全世界規模的資料來訓練 (而不是為了你的系統滿意度來訓練),這規模的大模型開始會有機會跟上資深業務員的判斷能力,而我只是撿現成,拿這樣規模的模型來解這問題而已。
我看到的改變,也是不同 “維度” 的做法。維度的差距也出現在模型的規模。從單一系統累積的數據用機器學習訓練 (ML,自己收集資料,自己訓練模型,自己預測解讀結果),改為用世界級的資料訓練的大模型 LLM 來解析 (LLM,AI 廠商收集資料,訓練出通用的大模型,軟體開發商拿來解讀單次歷程背後隱藏的訊息)。AI 模型訓練更往前了,模型訓練規模更大了,而模型的效益也更通用了,後面的應用就直接拿案例 + 自訂的 Prompt 就能得到結果了,這就是不同規模的競賽。比起來應用的層次不同了,解讀資訊的層級也不同了,才會造成這樣的落差。
也因為想通了這背後的差異,我開始理解 “降維打擊” 這句話背後要講的差別了。三次元的生物 (例如: 人),看待二次元的生物 (例如: 螞蟻),當人要從上面踩死螞蟻的時候,螞蟻其實完全沒有反抗能力的,甚至不知道發生什麼事情,這就是維度的差距。這差距大到不可能被突破,再多的努力跟改善都不會改變這現實。因此認清各自擅長的領域,”正確” 的使用這些技術是很重要的。
2-5, 小結

// 簡報 P25, 小結
還是要強調一次, 我寫的 DEMO 只是 “概念驗證” (PoC) 的程度而已,要搬上正式環境還遠遠不及格。不是要你現在就用這方法改掉你既有的 code … LLM 的成熟會帶來很多本質上的做法改變,這會發生在各個環節上,不只軟體開發。我只是把它拿來應用在我的服務本身而已。我嘗試將 LLM 納入服務內,試試用 LLM 來解決過去別的方式解決的 UX 問題。
我的目的是點出 “變革” 的可能性,你留意到哪些地方可能在未來發生變革嗎?
我看到的是:
LLM 開始有能力 “自主判斷” 該呼叫那些 API 了,這會串起 “對話” 跟 “任務” 中間的關聯,也是你開始可以用 “對話” 來執行 “任務” 的關鍵環節。而現在的 LLM 已經足以勝任這任務,這很快會變成所有開發人員必須具備的技能 (門檻很低啊,你不用嗎?)
過去 API 設計好壞,談的是 DX (Developer Experience)。想想看,你過去設計 API 在意的是什麼? 可讀性? 一致性等等。現在,會有越來越多來自 AI 呼叫你的 API 的場景了 (而且我預期會快速增加,尤其是越靠近使用者端的 API 越是如此),你設計的 API 該考量什麼?
我暫且將這個稱作 AI DX 吧 (好繞舌… 實際上沒這名詞, 我自創的),你該開始重視這件事了。正如同越精準的 prompt 你越能得到可靠的回應一樣,越好的 AI DX 你越能避開 AI 的不確定性。我示範的所有案例,在 API 開發本身,完全沒有引入新的工具或技術,完全就是典型的 ASP.NET Core WebAPI + OpenAPI Spec 而已.. 我甚至第一版還是用 .NET Core 3.1 寫的…, 我唯一有做的事情,就是調整設計規格,讓 ChatGPT 能順利地使用它而已 (寫 swagger 的描述, 加上 oauth2 的支援),在 API 本身的 domain spec 完全沿用, 甚至還更精簡, 例如我連預算處理, 折扣處理的 API 都沒有提供, AI 可以自己組合的出來。
除了工程面的 AI DX 之外,往應用與設計面來看,同樣的目的,引入了 AI 你也開始有機會有不同以往的工程做法可以選擇了 (例如我示範的個人化 & 滿意度的回饋機制)。AI 帶來了不同層級的抽象層,能打破過去作法無法突破的障礙。過去靠實體店員的 “直覺” 能辦到的事情,往往是生硬的軟體系統遠遠無法觸及的…。而你若能善用 LLM 的語言處理能力,你就有機會搭配既有的數據與個人化資訊的掌握,加成兩者的效果。
不同層次的作法,對我來說就是不同的維度。多一個維度所有的效益都是 “乘法”,而不是 “加法”。用的好的話,你的效益會加成;用的不好,會加成的是複雜度或是成本… 該如何選擇,我後面再聊。
最後一句話總結,也是我在 DevOpsDays Taipei 台上講的結論:
別小看跨維度的差距。多一個維度帶來的差距就是這麼大,站在三次元的視角是可以完全輾壓二次元的生物的
(這就是所謂的: 降維打擊)
// 不對,夠宅的話就會有人說: 2 次元的老婆可以輾壓 3 次元的老婆 XDDD
3. 軟體開發還是你想像的樣貌嗎?
看完兩個 DEMO, 歸納一下想法,然後帶出我認為的軟體開發樣貌會如何改變:

// 簡報 P27, 感想: AI “已知用火”
感想只有一個,就是現在 AI 的發展已經到 “已知用火” 的階段。你給他合適的工具,告訴他你的需要,然後他就開始懂得如何使用工具來為你做事了。不過我覺得現在的 LLM 做這些事還在幼兒階段,做的還不夠好,因此你有這些地方要留意:
- AI 已有能力理解對話的 “意圖”,也能嘗試使用 “工具” 了,但是正確性還不夠可靠。
- 傳統的資訊工程都講求 “精確” 的計算;模糊的需求 (例如語言) 其實都不大擅長。
- AI 的不確定性,是優點也是缺點,你必須把它放對地方,放大優點,防範缺點。
(1) 其實早就不是新聞了,十年前的 Siri 就已經能透過對話來啟用工具了,只是當時的語言模型很糟糕而已,對於使用者的 “意圖” 還不到位。而現在 LLM 理解能力提升,搭配工具的使用,開始跨過基本門檻,有 Agent 的樣子了。
這時,(2) 跟 (3) 我覺得就是個重要的分野了。計算機最強大的就是 “計算”,尤其是精確地計算或是演算法,完全不是人腦能追上的。如果你把 AI 類比為人腦,這差異仍然適用。30年前的電腦都能做好的四則運算,現在最先進的 LLM 可能都還會答錯。來看看這個例子:

// 來源: T客邦, 9.11與9.9哪一個數字比較大,為什麼這麼簡單的問題連ChatGPT、Claude都答錯?
短時間內,就算 AI 推論能力能追上了,運算成本也完全不符合比例。你需要的是在設計階段,就精準的切割,到底什麼任務你要用傳統資訊科學的做法來處理? 那些你該善用 AI 的推理能力來解決? 你給一個小學生一台便宜的計算機,你就能大幅提高它的計算能力… 你當然也可以讓他去學心算,但是成本完全不能跟計算機對比…
用 “計算” 的方式,跟用 “AI 推論” 的方式來解決問題,是有巨大的差異的,你想用 AI 來解決問題,第一課就是要先篩選問題。當你把不適合的問題交給 AI 處理時,產生的差異就是這麼巨大。
該用 (2) 的,乖乖地提供正確的 API,顧好 AI DX 吧;然後把麻煩事,用正確的 prompt,挑選正確的模型,就交給 AI 處理吧。
3-1, 從 API First (設計品質) 開始
因此,擴大這個主題,也就是這篇文章的標題,開始來看看 “如何” 從 API First 到 AI First.

// 簡報 P28, 標題回收: “從 API First 到 AI First”
先從你如何看待 API,以及你該改掉的一些壞習慣開始。投影片其實都有寫摘要了,所以我直接講我的想法:
第一個壞習慣, “檯面下的溝通”:
尤其是內部的 API,或是非 100% 公開的 API 更是如此,因為要呼叫你 API 的是其他 “人”,只要這些 “人” 的數量是可控的,例如限定內部使用的 API,使用的人就是你隔壁部門的幾個 RD;或是限定合作夥伴的 API,會呼叫的就是它們的 RD (如果兩邊地位不平等就更明顯了,我有 BUG 的地方你給我繞過去 blah blah blah …)
再來,“API 設計過度向目前的使用案例偏斜”:
典型的就是 UI 跟 API 的戰爭。這也是去年、前年那兩場我在聊的主軸,API 該做的是把你的 domain service 用 API 型態開放出來,而不是把你現在的 Application UI 能做的事情開放出來。兩者不完全重疊,但是沒分清楚就足以讓你的 API 完全沒達到他該發揮的效益。
我最常看到的狀況,就是 API 過度為了配合 UI 的用法,多了一些 “捷徑”。例如 UI 需要一次取得三個服務的資訊,UI team 覺得呼叫三次太麻煩,就要其中一個服務先整好再給他…。
這不是不行,但是當時程壓力下,做了這個,往往代表原本該開出來 “正確” 的 API 就被省略了。合理的做法應該是先按照 domain 把合理的 API 都做出來之後,按照 UI 特殊需求,額外提供 “方便使用” 的版本,而不是只提供 “方便使用” 的版本,就省掉了真正重要的 domain API。
接著如果其他不同情境的應用來了,老闆就會說:
“啊,我們 XXX 服務都有 API,我開給你用就好了”
然後,真的要用 API 的時候才發現,這 API 只能用在 UI 上,換個情境就不適用了,於是在改版的時候就整個翻掉重寫。啊 API 不就是為了能 “Reuse” 的目的才開發出來的嗎? Reuse 到哪了?
因此,這些壞習慣,其實都建立在用 “檯面下的溝通” 來迴避設計或架構問題。我要很直接地告訴各位,這些做法在 AI 都行不通。不是不能跟 AI 溝通,而是本末倒置,效果大打折扣,不如不做。如果你要認真為了下個世代的基礎做準備,請好好看待你的 API。有兩個面向一定要注意:
-
做到合情合理:
做到你的 API 規格讓 AI 一看就懂 ( LLM 都是由一堆 “常理” 訓練出來的,你設計邏輯越符合 “常理” 越不會出錯)。 -
做到足夠 “可靠”:
做到 API 即使被胡亂呼叫,該守住的邊界一定要守住,要做到不容許有任何例外的狀況 (難保你不會被 AI 找到漏洞)。例如你 APIKEY 明明沒給的權限,不要被找到奇怪的呼叫順序,就能做到不該做的操作;或是有限的 API 不正常的呼叫就會導致資料損毀 (必須去後台修理之類的狀況)。
如果你沒看過我之前談的 API First Workshop, 投影片的 P30 ~ P36, 或是參考我這篇文章都可以:

#安德魯的部落格: 架構師觀點 - API Design Workshop
我花了不少篇幅在闡述如何設計,你的 API 的介面才會夠可靠。簡單的說就是從狀態機出發,因為:
- 狀態轉移是被定義的,轉移的箭頭就是你必要的 “基本” API。
- 狀態轉移應該是 atom 操作,同一筆資料同一時間只能執行一個轉移的操作,完成了才下一個。沒做好就會產生損毀的資料。狀態機有助於協助你明確規範這些規格
- 轉移的對象 (誰能觸發這些轉移),就是 API 的認證 (APIKEY) 與授權 (SCOPE) 的基礎,這弄清楚你就能非常明確知道你該授權甚麼 API 給什麼人
- 確保所有 API 都是由符合規範的基本 API 組合。其他各種好用的延伸 API 隨便你做,只要你確保所有的行為都不會違背狀態機的規矩就好
其實,這些就是呼應到我在談 API First 時的幾個原則: 狀態機,SCOPE 設計,APIKEY 的設計原則,還有分散式交易等等的實做議題。API 的品質,DX 是否良好,談的就是這些面向。從這角度來看,API 能動只是最基本的要求,連及格都還不算,做得越好,你的 API 在 AI 時代越有利用價值。
試想一下,如果你不顧好 API 的設計品質,交給 AI 使用會發生什麼狀況?
-
你得寫一堆 prompt 額外告訴 AI 要閃開哪些行為…
不過,這些你原本會乖乖地寫在 API documentation 上嗎? 會的話直接餵給 AI 倒是還好 (就是多花 token 費用而已),不會的話你終究還是要寫 prompt ( instructions ), 也就是你還是得寫文件。 -
設計不佳的 API,你要更多的引導才能讓 AI 正確使用…
例如我曾經嘗試過一個版本的 CRUD API (我定義 訂單 的 schema,然後 EF core + ASP.NET 自動幫我產生 CRUD API … ),慘不忍睹,我寫了一堆文件告訴 AI,甚麼情況下該更新訂單的哪個欄位,整個商業邏輯通通曝光在 CRUD API 規格內了。更慘的是我還完全無法控制狀態,連資料都被改壞了 (欄位內容不符合商業情境) -
你需要更多的測試與驗證,才能確保系統正常運作…
這我就不多說了,當你沒辦法在設計上就讓行為與結果是收斂的話 (例如你開了所有欄位都自由更新的 CRUD API,你就別指望所有的人都會有系統的呼叫 API 維護這些欄位內容),你的測試要涵蓋的範圍就收斂不了了 (測試範圍太大測不完)。這噩夢不控制好的話,再加上 AI 的不確定性 (每次的回答都可能不同),基本上你是沒辦法控制系統的可靠度的…
其他狀態,資料正確性,分散式交易等等議題就更不用談了,我連正常的展示安德魯小舖的情境都沒辦法。經過這些折騰,我重新好好的照設計方式來開 API,結果一次就成功了。
最後還是老話一句,重視 API 設計品質是必要的。不論你用 DDD 或是 OOA / OOD 等等設計方法論都好,別忽視設計品質的問題。這直接影響 AI DX,這關沒有過,你的 API 在未來 AI 世代是禁不起考驗的。你如果不想讓你的服務在未來幾年被淘汰,現在開始正視這問題吧。
3-2, 你該練習的基本功夫
(有人說我用動畫的梗圖用的比 AI 產圖還到位 XDD, 我就繼續拿動畫梗來用了.. 這次是千年魔法使出場)

// 簡報 P37, THINK: 如何訓練出一階魔法使?
“葬送的芙莉蓮” 這部動畫不需要我介紹了吧 XD, 撇開勇者等等的故事, 單就 “專業” 角度來看,芙莉蓮傳達給徒弟的專業知識 & 觀念是很正確的,包含 “隱藏實力” (沒有必要的話就別拿大招出來,其實就是技術選擇的能力),做好 “基礎訓練” (基礎魔法練好就足以對付這時代的魔法使了,其實就是基礎知識與技能掌握能力的問題),魔法靠的是 “想像力” (你要想像的出來才有可能學的會,其實就是架構思考的能力) 都是,未來我給新人訓練的教材應該要加上這三條… XDD
實際上我工作 2x 年的經驗 ( Orz, 離活了千年的魔法使還差 20 倍 ) 看來真的是這樣。常看我文章的大概都知道,我通通都在講基礎知識。基礎知識要學得透徹,我都會用 PoC 的方式從頭到尾做過一次,驗證設計,開發,實際上線運作,監控,維運等等過程。這些都能掌握,就是基本功夫。
為何我會在 AI 這主題談這個 (基礎功夫) ? 有兩個原因:
- 你必須顧好 API 的基礎設計,在 AI 時代它的重要性會更勝以往。
- 有新的 AI 基礎功夫出現,你要有能力掌握新時代基礎元件的功夫。
我的做法都一樣,看清楚背後做什麼 (想像力),你有能力自己 PoC 跑過一次掌握重點 (基礎功夫),剩下的就是實戰練習了 (技術選擇)。
到目前為止,要開發 AI 應用程式,撇開那些需要大資本,大數據才能玩的領域 (模型,訓練,算力) 之外,我認為該要有的基礎是: “理解 AI 怎麼處理問題” ..

// 簡報 P38, AI 時代的基礎魔法: 理解 AI 怎麼處理問題
我列舉了四個我認為的基礎:
- API First (前面都在講這題, 這邊省略)
- 架構規劃好 AI 該擺哪裡,該怎麼擺
- 了解 AI 相關基礎元件與運作原理 ( Embed, VectorDB, Prompt 等 )
- 了解 AI 應用常用的設計模式 ( RAG, 推薦模型 )
3-3, Prompt Engineering
這段其實就是大家常常聽到的 “Prompt Engineering”, 提示工程。不過常看到的案例都是教你怎麼在 ChatGPT 問問題等等 “工具” 的使用技巧,實際上真正該問問題的是開發應用程式的工程師,你某部分的邏輯,應該要變成 prompt 才能正確的命令 LLM 做你要做的事情,這段就是講這些技巧。

// 簡報 P39, 學習如何透過程式運用 LLM ( Large Language Models )
這邊技巧太多了 (我也沒有熟悉到那種程度),我挑了一篇講得還蠻清楚的文章,擷取了其中三種用法當案例就好。這些用法大家都可以直接拿手邊的 ChatGPT 親自驗證看看,專業一點的你可以找 Azure OpenAI 提供的 Playground (遊樂場),直接用他的介面來測試你下的 prompt 會有何種回應。用 ChatGPT 當作測試環境,你完全不需要準備任何特殊的環境。你只要想像未來這些問答的內容,是你自己用程式碼組出來的就好,其他通通都一樣。
3-3-1, 基本型
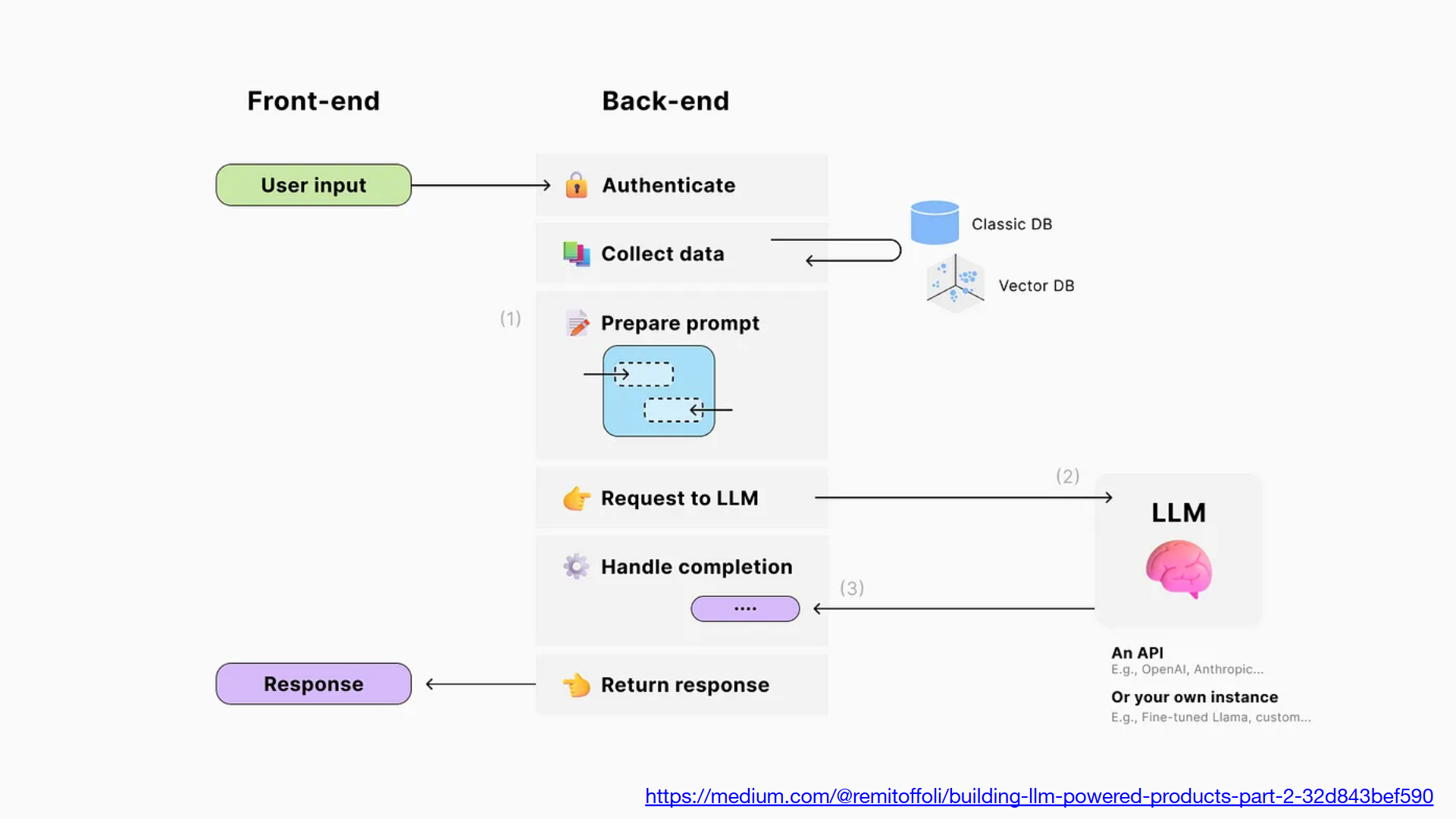
// 簡報 P40, Building LLM-powered products — Part 2
看到這篇寫的比我還好,我就沒必要自己寫了 XDD,單純導讀一下就好。
第一張圖,可以算是最基礎的應用了。左半完全是標準的 Web Application 設計,有 Frontend / Backend 的互動。後端重點在於取得前端 user input, 然後用預先設計好的 prompt (template), 套入部分參數後丟給 LLM (Request to LLM)。
LLM 的回應也經過應用程式處理 (Handle completion) 後再決定該如何回應 (Response)
容易搞混的地方,就是 user input / response 了。這邊很容易被誤會成類似 ChatGPT 的 user 輸入 & GPT 回應,其實不是,這裡指的只是單純 user 的操作與應用程式回應而已,例如 user 按下 “加入購物車” 這樣的操作。
核心概念就是: 處理過程中如果有你想要依賴 LLM 處理的部分,就該走這流程。Prepare Prompt 的部分關鍵就在於 developer 自己應該先嘗試哪樣的 Prompt 能得到最好品質的回應? 包含正確性,花費 Token 最少等等期待。這邊 developer 是需要一些 prompt 的技巧的,剩下就是把 prompt 的關鍵內容換掉而已。
這邊我就不特別舉例了,後面的例子會一起看到這部分。
3-3-2, Json Mode
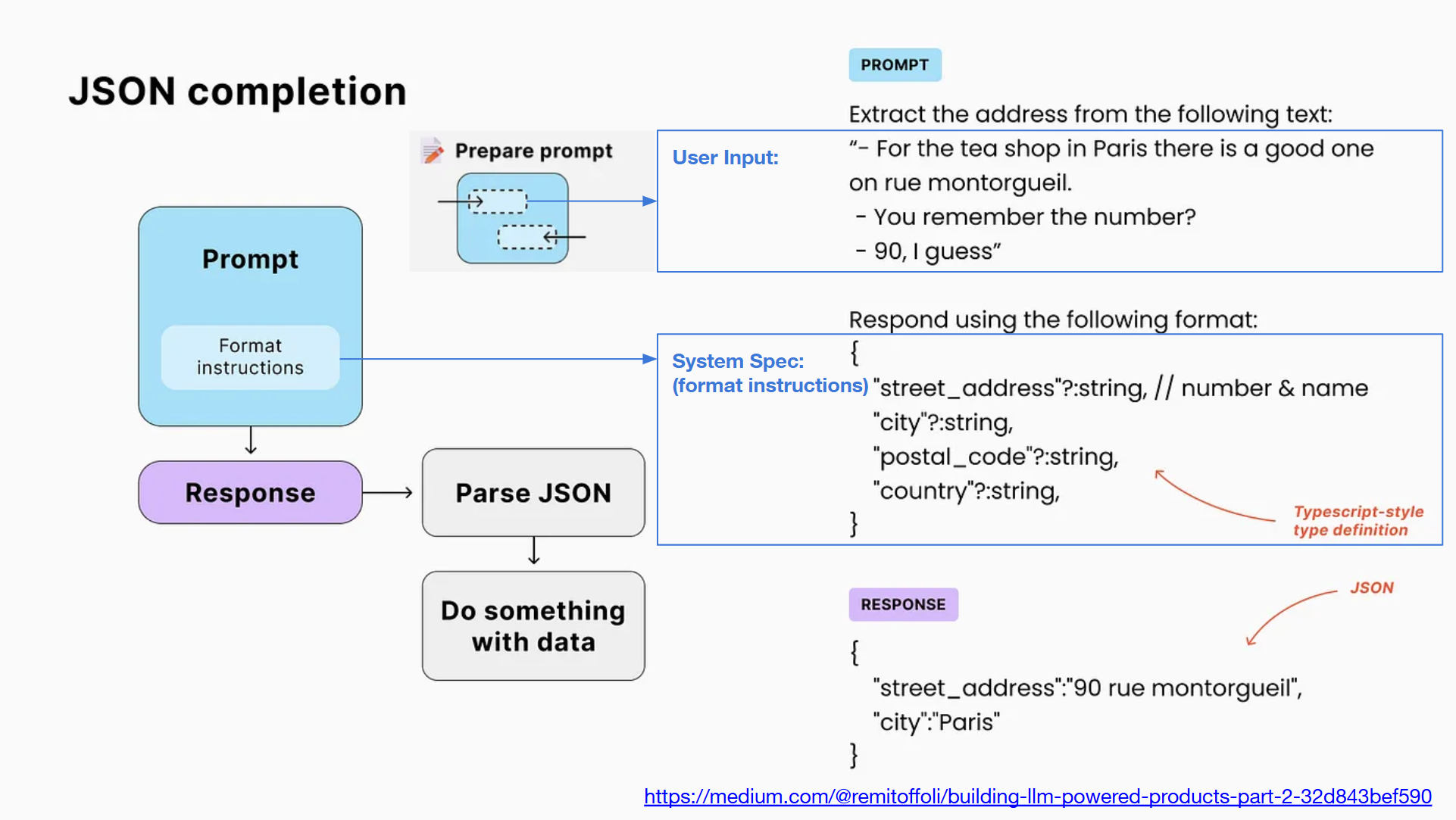
// 簡報 P41, Building LLM-powered products — Part 2
來自同一篇文章,這個例子開始進階一點了。處理自然語言是 LLM 的強項,但是不是一般 developer 很容易處理的環節。例如 LLM 回答 “好的” 跟回答 “OK”,要我寫程式處理就很傷腦筋了,哪天 LLM 回答我更口語的 “好呦” 我不就又要弄個 AI 來處理 AI 了…,因此開始有些先進一點的模型,直接提供 json mode .. ( 例如: OpenAI GPT4 - Json Mode ),經過正確的 prompt 提示,他可以按照你期待的方式給你結構化的回應,你不再需要去 Parsing 自然語言的內容
這例子很有趣,要從一段對話,抽出其中的地址資訊。這段對話內容大概是這樣:
A: For the tea shop in Paris there is a good one on rue montorgueil.
B: You remember the number?
A: 90, I guess
(我幫大家翻譯成中文):
A:在巴黎的蒙托蓋伊街 (rue montorgueil) 上有一家不錯的茶館。
B:你記得號碼嗎?
B:我猜是 90
一般人想都不用想,看完對話就能理解這家茶館的地址是: 巴黎 蒙托蓋伊街 90 號,不過要如何寫程式轉換這段對話? 更重要的是,如果你要存入標準的地址格式,你得正確拆解國家,路,巷弄,號 等等資訊…
於是 developer 就可以這樣下 prompt (如上圖):
Extract the address from the following text:
"
{ 填入你的對話內容 }
"
Respond using the following format:
{
"street_address"?: string, // number & name
"city"?: string,
"postal_code"?: string,
"country"?: string,
}
順利的話,你會得到這樣的 Json 輸出 (而不是白話)
{
"street_address":"90 rue montorgueil",
"city": "Paris"
}
回到一開始,你怎麼知道要這樣下 prompt ? 我自己都會先這樣在 ChatGPT (或是其他 LLM 都會有類似 ChatGPT 簡易的操作介面, 例如 ollama + webui 之類的) 上面先測試過,再放到 code 裡面驗證。
在 ChatGPT 跑這段 Promot:
(不論是 GPT4, GPT4o, 或是 GPT4o-mini 都得到正確的結果)
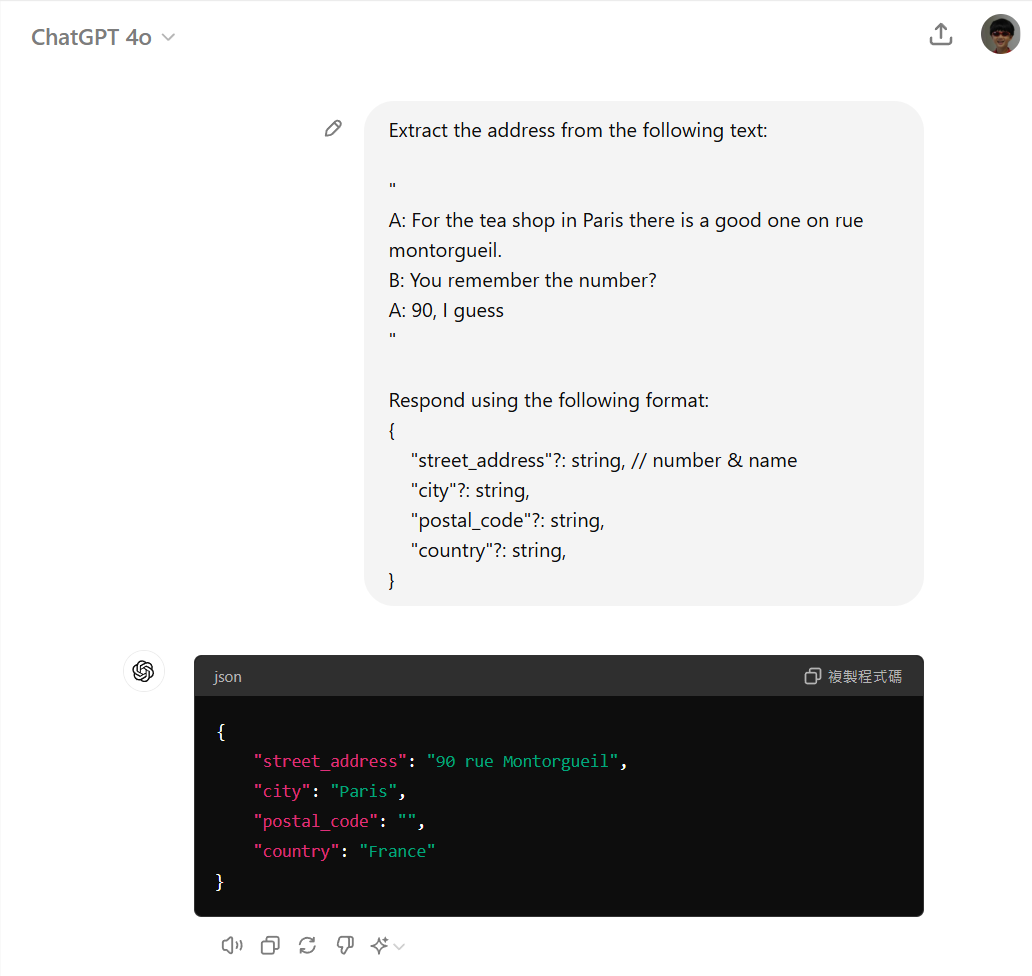
如果你要呼叫 OpenAI 的 API 也沒問題,官方原生支援 json mode,你可以直接取回 json response。這篇我就不談太多實做細節,附上官方的開發文件說明,有需要的自己看:
3-3-3, Function Calling
其實,變得出 Json Mode, 就已經離 API call 不遠了。延續 Json Mode 控制 LLM 回應格式的技巧,再來看這個例子:
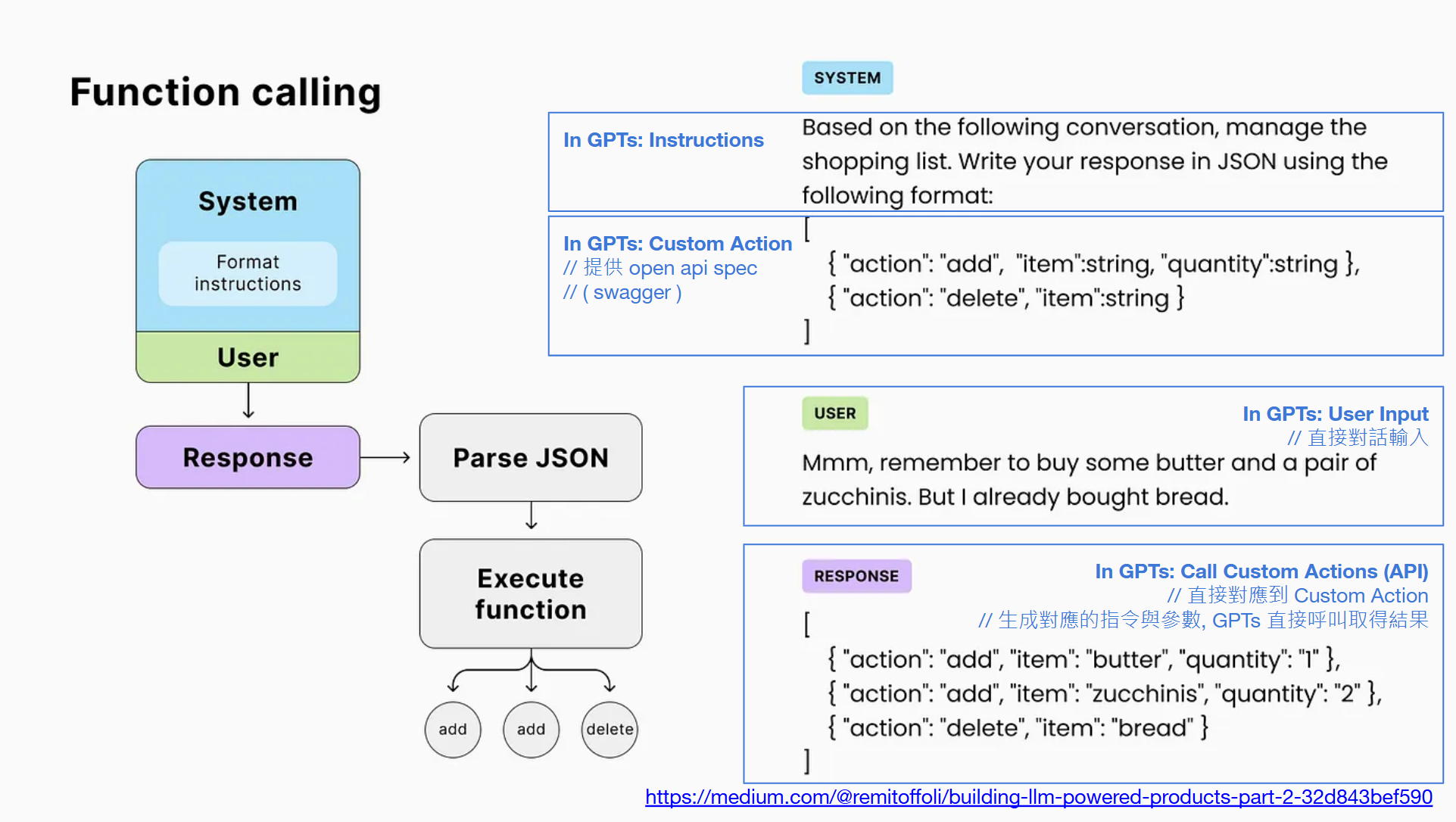
// 簡報 P42, Building LLM-powered products — Part 2
過程我就不多說了,例子幾乎一樣,只是換一個案例而已。這次是維護購物清單的 prompt:
先下 system prompt (或是 GPTs 的 instruction 都是同等層級的東西):
Based on the following conversation, manage the shopping list. Write your response in JSON using the following format:
[
{ "action": "add", "item": string, "quantity": string },
{ "action": "delete", "item": string }
]
這次,不用自己寫 code 去替換字串了,直接下 user prompt (或是 GPTs 的正常對話輸入部分):
Mmm, remember to buy some butter and a pair of zucchinis. But I already bought bread.
LLM 會回應這樣的內容給你:
[
{ "action": "add", "item": "butter", "quantity": "1" },
{ "action": "add", "item": "zucchinis", "quantity": "2" },
{ "action": "delete", "item": "bread" }
]
這個案例開始包含一部分的邏輯推演 (把對話的要求翻譯成 action),也包含輸出格式的轉換 (翻譯成指定的 json 結構)。當這兩件事都做到的話,剩下的就很簡單了,你的程式接到這段 json, 自己 parsing 成 object, 跑個 for loop 逐步處理完每個 action 就夠了。
最後這段,不就是 call API 了嗎?
想像一下,你指定的 json format, 其實就是在告訴 LLM API 的規格。在 GPTs, 你不用自己寫這樣的 prompt, GPTs 背後也幫你做了類似的事情,只是你只要貼上 Open API 的 spec ( swagger ) 給 GPTs, 他會自己幫你翻譯, 讓 GPTs 知道你有哪些 API 可以叫用,每個 API 需要那些參數。
只是,這一切 GPTs 背後都幫你做掉了,所以你就看的到我上面展示的 “安德魯小舖”,從對話可以解析意圖,推論需要執行那些 API,經過使用者同意就真的呼叫 API 執行操作。
同樣的,這段對話,我也真的貼到 ChatGPT 試試看,可以得到完全相同的結果:
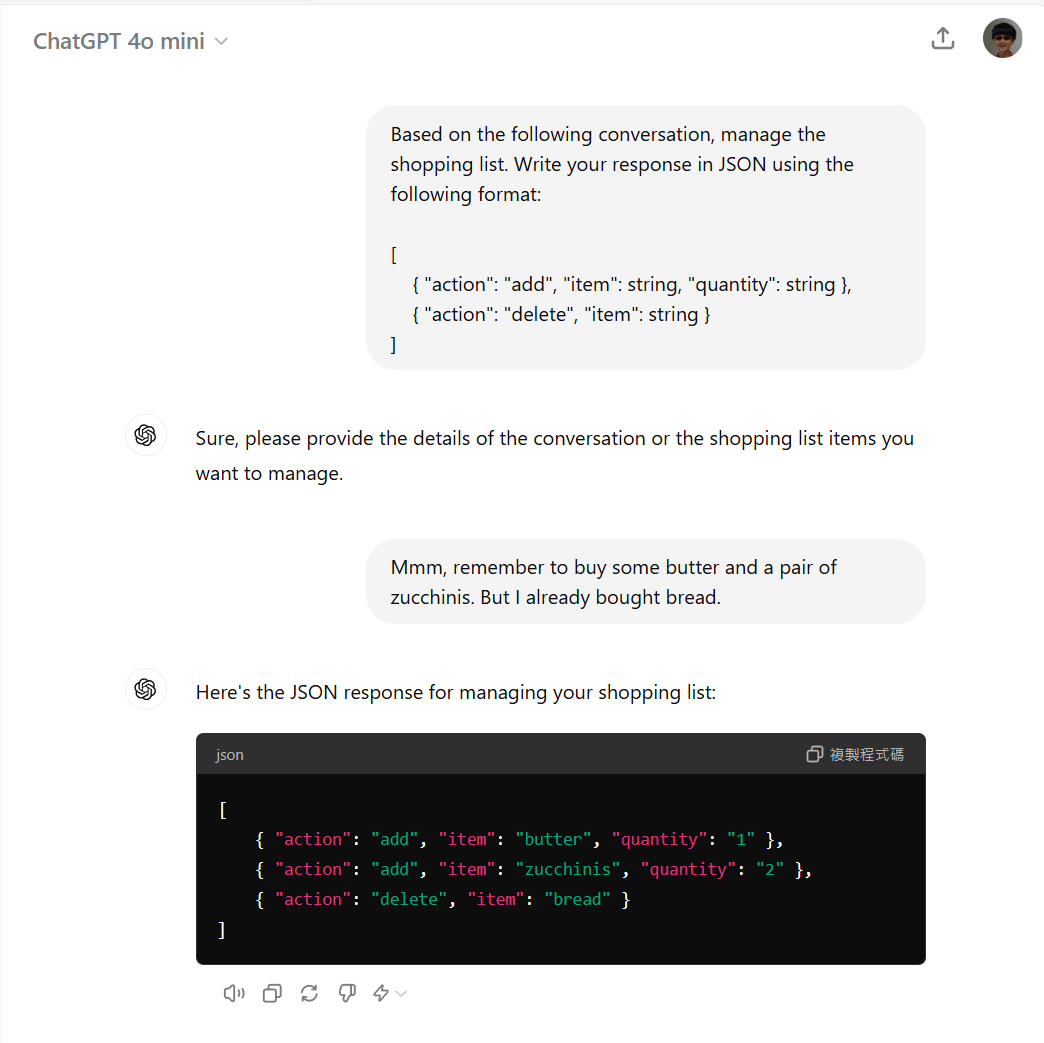
3-3-3, Workflow
接下來看第三個應用案例,算是組合技,也是最吃 AI 推理能力的情況,因此不同的 LLM 行為差異會比前面兩個案例還大。使用前務必多方嘗試,挑選推理能力較好,或是參數數量較大的模型比較能得到預期的效果。
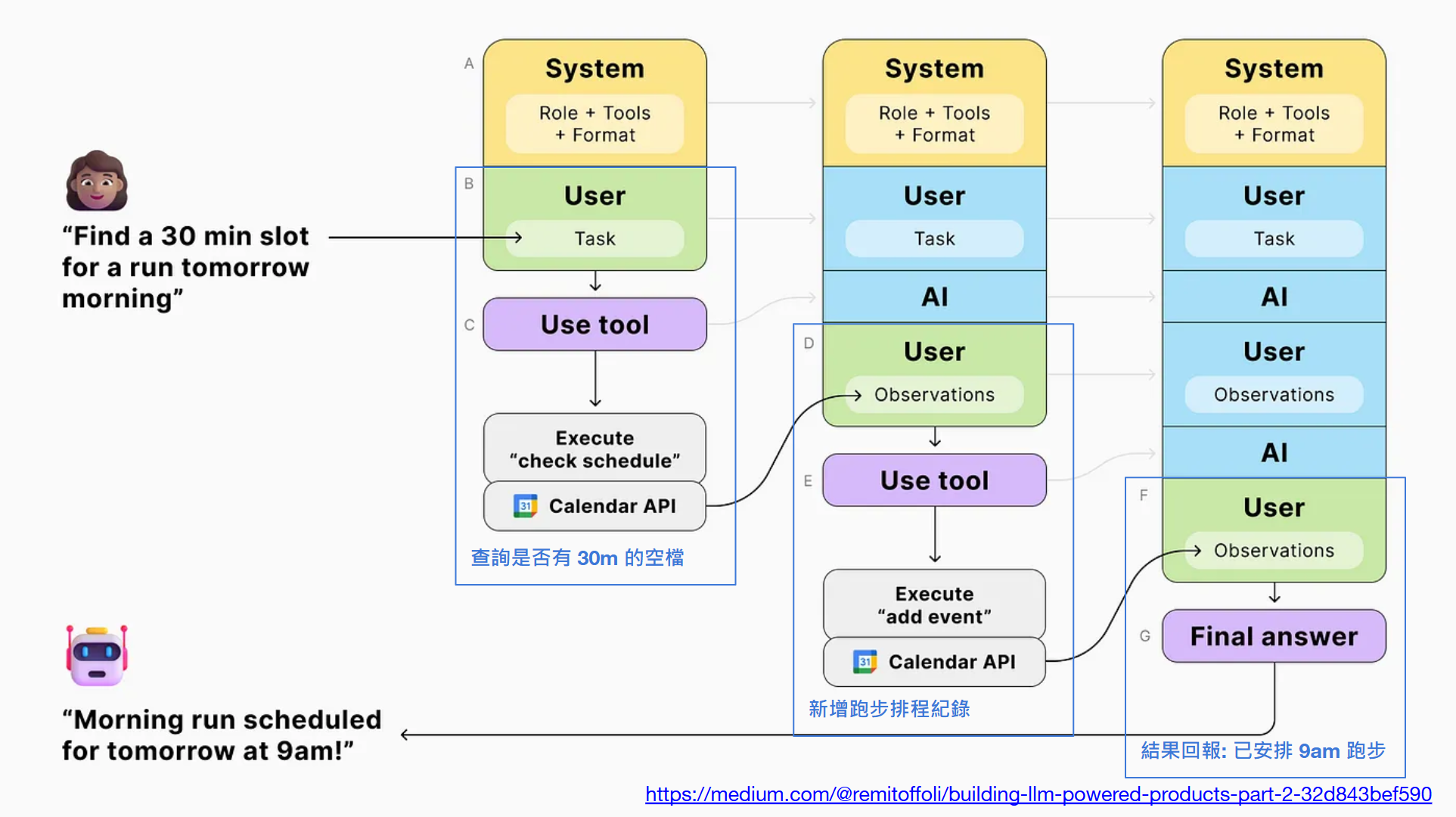
// 簡報 P43, Building LLM-powered products — Part 2
這情境基本上就是組合前面的幾種用法,但是重複多次。圖上的案例是:
使用者: Find a 30 min slot for a run tomorrow morning
中間則是 LLM 跟應用程式處理的黑箱 (使用者看不到),我先跳到最終結果,使用者會看到這樣的回應:
機器人: Morning run scheduled for tomorrow at 9am!
中間做了甚麼? 當你都先透過 system prompt ( instruction ) 告知做事的原則,以及告知它有哪些 action 可以執行,他基本上就有基本能力了。所以她聽到要求內容後,邏輯上 LLM 會產出執行計畫:
- (Use tool) Execute “check schedule”, 查詢明天早上是否有 30m 的空檔
- (Use tool) Execute “add event”, 新增一筆跑步排程紀錄
- (Final answer) 回報結果
(1) 跟 (2) 都是個別的 function calling 就能搞定的動作,而 LLM 必須有能力從使用者的意圖先思考要做這三個步驟才能回覆使用者,進而分批回應 (只是這回應是回給 application, 不是回給 user)。這時,控制整個程式的流程,已經不再是 developer 或是 product owner 了,而是 LLM。與其說 “控制”,更精確的說應該是 “計畫” 或是 “決策”,應用程式頂多只是按照指示來執行罷了。
這個案例,其實就很清楚說明了 LLM 能執行複雜任務的拆解過程。這個例子不大好直接用 ChatGPT 展示,因此我做了一點調整,試著練習看看。大家可以體會一下我這段 prompt 的下法:
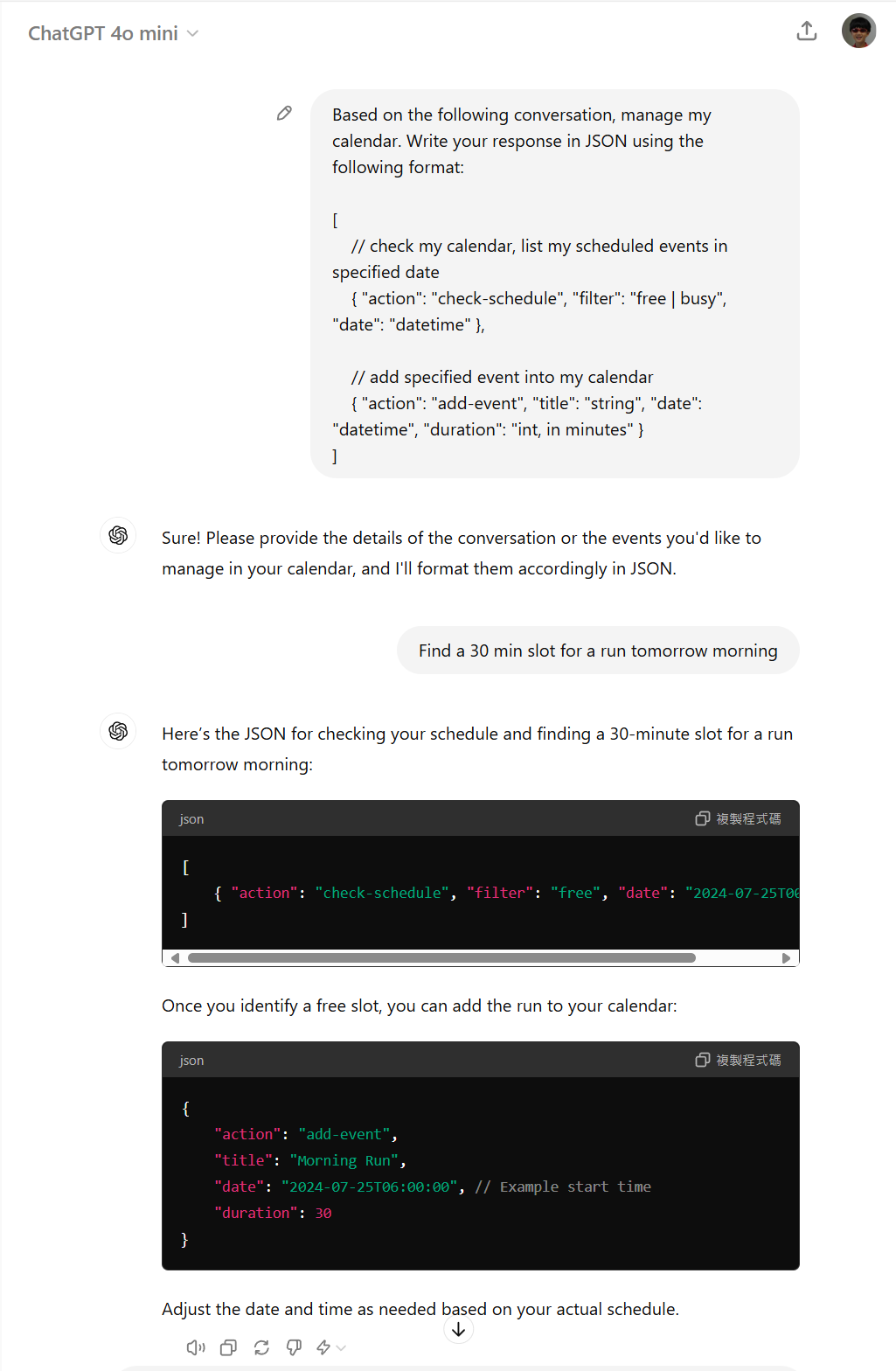
結果差強人意,原因是我給的 API 規格只給了一半。我給了 request, 沒給 response, 不過 GPT4o mini 倒也給我很正確的答案。她告訴我要先 “check-schedule”,然後得到結果後才接著 “add-event”。
中間有一段邏輯:
Once you identify a free slot, you can add the run to your calendar
這有點類似我在 “安德魯小舖 GPTs” 的預算問題,你可以全權讓 AI 決定,你也可以用對話方式回覆,讓使用者決定;或是你的 Application 能接到這樣的指令,跳出合適的 UI 讓使用者選擇 (這樣會有額外的 “select-time-slot-dialog” action 定義,你的 application 就知道要跳出對話窗)。
不論如何,你會發現,軟體開發到這個階段,你開始會有感覺是 AI 指導你該做甚麼的錯覺了,不再是過去完全由 developer 決定程式怎麼跑,或是由 product owner 決定規格。開始有越來越多的 “應用程式設計” 是來自 AI,而不是來自設計師。
同時,看到 “定義 API 規格” 在 AI 應用程師開發領域裡越來越重要了嗎? 這個例子中,AI 雖說 “規劃” 了該怎麼回答這問題,給了一系列的指令,但是 AI 終究是在最前面的 system prompt 由你給他的指令清單,從裡面組合出來合適的指令。
我給的指令清單 (有時你亂寫,甚至寫成註解也會通):
[
// check my calendar, list my scheduled events in specified date
{ "action": "check-schedule", "filter": "free | busy", "date": "datetime" },
// add specified event into my calendar
{ "action": "add-event", "title": "string", "date": "datetime", "duration": "int, in minutes" }
]
開發人員的價值就在這裡,你能給 AI 多完整的 “工具“,決定了 AI 能幫你做多少事。你的 “工具” 設計的越精良,AI 的表現就會越到位 (工欲善其事,必先利其器),工具設計的好壞,就是我前半段一直再提的 “API 設計品質“。
然而,AI 也有聰明與否的區別的,情況越來越複雜時,能使用的工具越來越多樣時,推理能力強大的 AI 能給你越精準高效率的指令。我在安德魯小舖 GPTs 的常識過程中就充分體會到這關聯,預算處理就是一例。去年 (2023) 12 月我使用的是 GPT4, 到現在的 GPT4o, 差異雖不大,但是的確有感覺他的回應 “聰明” 多了。
模型的推論能力,通常不是個別的軟體開發人員 (developer) 能改變的,模型好壞你能做的事很有限,除了條件允許,你可以訓練自己模型 (或是微調) 之外,對一般小型團隊比較可行的方案只有兩個: 一個是在你能力範圍內盡量挑選能力最好的模型 (夠用後再慢慢降級,看看小一點的模型是否也能勝任),再來就是調整你的 prompt,看看模型沒那麼聰明時,你給的指令明確一點能不能引導他順利完成任務。
這整個過程,其實就是 prompt engineering。未來的 developer,除了要能掌握程式語言跟電腦溝通之外,也要開始掌握 prompt engineering 來跟 AI (LLM) 溝通了。
3-4, Copilot 的設計架構

// 簡報 P47, DEMO #3, 安德魯小舖 Copilot
接著,再來看一下這個版本的 “安德魯小舖” DEMO 吧! 這次我脫離 ChatGPT 的 GPTs, 改用 .NET Console Apps + Semantic Kernel, 自己寫 code 來呼叫 Azure OpenAI API, 嘗試自己來開發完整的 AI 應用程式。
這次我的構想是: 不要再全部都用對話來操作了 (對話很貴的…)。都用對話操作很炫,但是也很不實際。明明簡單明瞭的 UI 操作起來會更簡單,我只要我碰到困難時再用對話的方式就好了。於是我開始嘗試 Copilot 的模式,來重做一次這個 PoC。
Copilot 要做什麼,直接看這頁簡報:

// 簡報 P49, AI 成為完全的 Agent 之前,先成為 Copilot …
DEMO 過程,我錄了影片,直接看操作就好了:
我簡單用文字敘述,寫一下這段 DEMO 背後的操作情境
- (00:00 開始) 我連續三次都叫出功能選單說明, Copilot 就跳出 (黃字) 關心我,是否在操作上碰到困難?
- (00:15 開始) 我正常的用指令操作購物系統, Copilot 並沒有干擾我的操作
- (00:33 開始) 結帳前我突然想起有預算 (600) 以及想要買的東西 (啤酒),但是我不想重新操作 & 計算,直接問問題讓 Copilot 協助我
- (00:55 開始) 回覆正常流程,我自己做結帳的操作
回到這個 DEMO 本身,我實在懶得慢慢刻畫面,所以才用 console app 來表現互動的過程。背後的運作跟想法,其實我在今年 3 月的這篇文章有聊過了,有興趣的可以看這篇:

#安德魯的部落格, 替你的應用程式加上智慧! 談 LLM 的應用程式開發
這個 DEMO,我想重現的就是: 該如何在一般的操作介面中,安插 Copilot (AI) 的輔助機制? 既不需要改變現在的操作方式,又可以帶來 AI 輔助應用的優點? 先不管技術上怎麼做,前面兩個 DEMO 我都提到了 “用不同維度的做法來改善 UX” 這件事,但是也都提到不要丟掉現在成熟可靠的做法了嗎?
答案就是 Copilot 了。兩種操作模式整合在一起就是最適合目前階段的答案,兩種路線都還可以同時並行,各自改善;而使用者得到的體驗改善,則是兩者相乘的效果,沒有互相抵消。
歸納一下 Copilot 的設計方向吧,我理解的有這幾個要點:
- Copilot 在旁邊輔助你
( APP 不時把操作過程,用文字敘述傳給 LLM, 有需要提示時再回覆 Hint 訊息),你不用改變既有的操作習慣。 - Copilot 要能依據事先設定好的指示,或是從服務資料庫內搜尋,判定使用者碰到困難時主動協助
(例如我安排了一直顯示操作方式,就要詢問使用者是否操作有困難)。這一切不是由寫更多的 code 來達成,而是要給 AI 更正確的 instruction,所謂的用嘴巴寫程式就是這意思。 - 使用者有管道可以直接向 copilot 尋求協助
( 不下指令操作 APP, 直接輸入問題。LLM 可以直接調用 API 來代替使用者操作系統)
然而,對我來說最大的收穫,是我想清楚了應用程式架構該怎麼調整,該留那些位置給 AI 的核心 (LLM) 跟對應的基礎元件。在沒有 AI 之前,應用程式大概長這樣:
// 簡報 P51, 應用程式的基本架構 (MVC, 動畫播放前)
而有了 AI 之後,長這樣
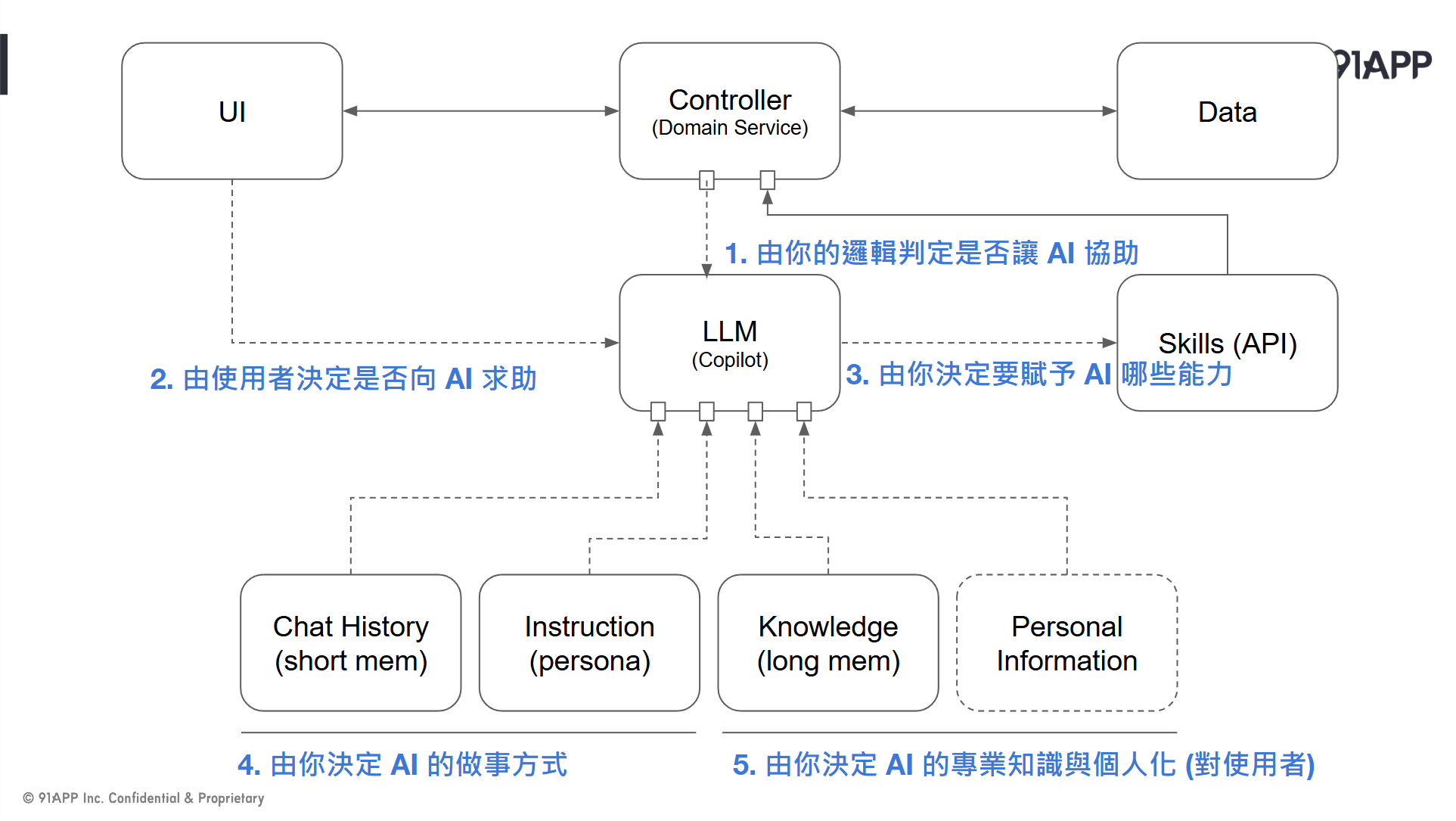
// 簡報 P51, 應用程式的基本架構 (MVC + AI, 動畫播放後)
對架構師而言,最大的改變就是 (這就是: 魔法使的想像力):
控制整個應用程式行為跟流程的,從唯一的 Controller, 變成 Controller (正駕駛) + Copilot (副駕駛) 了。Controller 開始可以把繁雜瑣碎的任務交給 Copilot 了,Controller 則可以負責更複雜,往 AI 還無法擔任的角色發展。而 Copilot 的能力也會越來越強大,當某一天 Copilot 能完全涵蓋 Controller 該做的事情時,Full Agent 的時代就來臨了。
不過各位不用擔心,我認為 Controller 不會消失的,AI 越來越強,人的期待就會越來越大。人的期待一定都是先由 Controller 來實現,然後再逐步轉移給 Copilot。目前 LLM 的推理能力還不足以負擔太複雜或大型的任務,執行效率與執行成本也高,但是現在發展的程度,我覺得已經足夠你做各種的 PoC 了,現在開始嘗試各種可能性,是個很好的時間點。
3-5, RAG 基礎元件 & 設計模式

// 簡報 P57, DEMO #4, 安德魯的部落格 GPTs
這段,我就來聊聊其他我也認為很重要的 AI 基礎開發能力,但是沒有包含在 “安德魯小舖 GPTs” 內的部分吧。除了 AI + API 之外,另一個我認為一定要會的就是 RAG 了。
// Google Cloud: 什麼是檢索增強生成 (RAG)?
很巧的,我剛好也有另一個自己開發的 GPTs: “安德魯的部落格 GPTs” .. (葉配),就是在做 RAG.. 這段我就拿這個 GPTs 來示範。
// 簡報 P58, 安德魯的部落格 GPTs
這個 GPTs,你可以把它當成我部落格的專屬小編,他熟讀我所有的文章。你可以簡單的問他某段內容在哪一篇,也可以問她困難一點的問題,問問我的文章講的知識該怎麼解。
其實針對這個主題,我也有一篇文章就在聊這個,想看完整內容可以看這篇,這邊我就講摘要就好

#安德魯的部落格, 替你的知識庫加上智慧! 談 RAG 的檢索與應用
同樣的,我也錄了一段 DEMO video, 各位可以實際體驗一下這 GPTs 能幹嘛:
其中背後的技巧,我用了一部分是 API 呼叫的能力 (我背後用了 Microsoft Kernel Memory 這個專案來提供向量索引跟查詢),而查詢後的結果則是靠 GPTs 來消化與彙整最後的答案。你可以想像我是用我的知識庫 (API) 來強化 ChatGPT 的知識 (特別是專注在我寫的文章上),用強化過的 GPTs 來回答各位問他的問題。
RAG 的拆解,其實也跟前面 3-3-3 workflow 相同,只是他拆解的任務特別專注在 “檢索” + “增強” 而已。他其實就是一種 workflow, 只不過知識庫的應用太大了,幾乎是 LLM 的主要應用領域,所以這樣的組合也有了專屬的名字跟用法: RAG
我在這頁 sequence diagram 大概說明了這流程
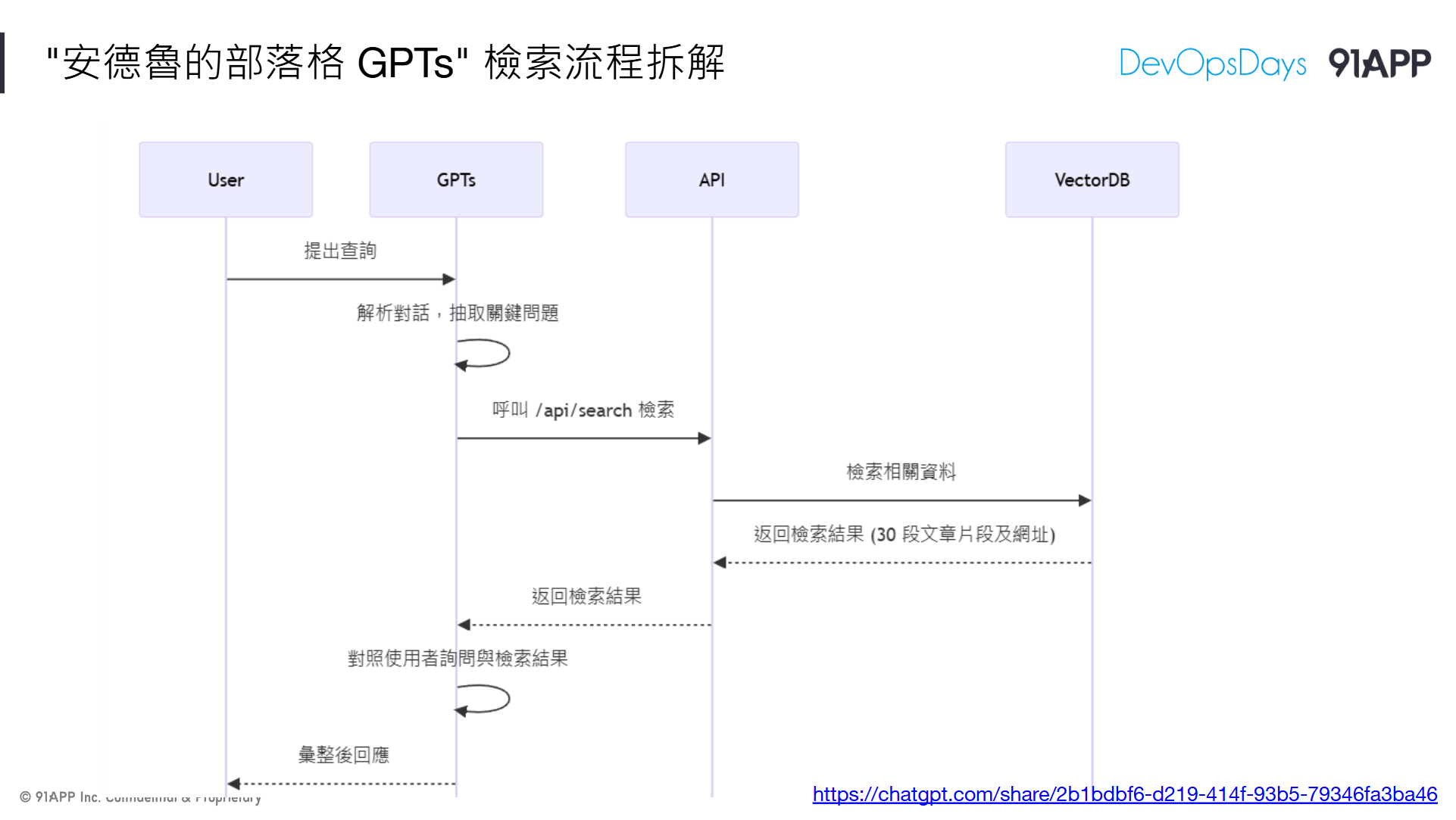
// 簡報 P62, “安德魯的部落格 GPTs” 檢索流程拆解 (動畫播放前)
一切都是從對話開始。LLM 從對話過程中,會判斷你要問的關鍵問題是甚麼,會透過 API 查詢資料庫,把跟這些關鍵問題最相關的前 30 筆資料拿回來 (包含片段文字內容,對應文章的資訊等等)。
而這些檢索出來的內容,會合併成一段大的 prompt,簡單的說,就像你在 ChatGPT 這樣問他:
Hey, 我從資料庫查到這些內容:
{ 檢索的內容都放在這邊 }
我想問的是:
{ 你的問題放在這邊 }
請告訴我答案。
為何說這是檢索增強? 因為你已經先把相關資料檢索出來了,只是你懶得 “讀懂” 他,於是你就把檢索好的資料,連同問題一起丟給 LLM。LLM 不需要到外部去取得知識,靠你給他的 “檢索內容” 就能彙整回答問題了。即使這些資料在 LLM 訓練過程中還不存在也無妨。
這就是 RAG 的基本型態。當然為了強化效率與提高正確性,RAG 還有很多變形,像是加了 Ranking Model ,或是建立資料庫的演算法,內容分段方式,多媒體的索引方式等等都是熱門的研究課題,這我就點到為止,讓大家知道 RAG 的應用模式為何就好。

// 簡報 P61, AI 時代基礎能力的運用
這邊我就補充一小段,我做這個 GPTs 額外考慮過的問題,當作心得給大家參考吧! 除了前面聊很多的 AI + API,模型選擇等等之外,主要還有兩項:
- AI 算力部署,模型部署與調配算力選擇的能力
- 數據收集,資料更新的能力 ( AI 相關的基礎建設該如何持續部署 )
3-6, 小結
這整段,我想談的主軸,就是:
當 AI 已經變成應用程式開發的主要元件之一時,現在整個軟體開發領域一定會高度往 AI 偏斜。
到那時,每個人必備的基礎會是什麼? 這些基礎在將來會是用甚麼型態出現在產品、服務、架構與流程內?
想通這些後,你就會清楚你現在該準備的是什麼,而不是整天擔心會不會被 AI 取代等這類問題。
前面第二段,談到產品服務該累積的基礎是高品質的 API
這段,我談的是開發人員該累積的則是各種 AI + 軟體開發相關的基礎能力。 具體來說,最重要的兩個基礎能力就是: 你的服務該怎麼運用 LLM? 以及你該如何管理與部署這些基礎服務?
我就彙整一下我對這兩點的看法,當作第三段的小結。
第一, 思考 LLM 該擺在軟體架構圖的哪個位置?
我再貼一次前面談 Copilot 用過的這張圖:
// 簡報 P51, 應用程式的基本架構 (MVC + AI, 動畫播放後)
從 Copilot 的開發架構來看,Controller + LLM 會是決定核心邏輯的兩大關鍵。這時是個很好的時間點,除了思考你的應用程式架構之外,資訊基礎建設的架構其實也該開始思考了。這張圖我並沒有標示實際的部署方式,Controller + Copilot 就如同當年的三層式架構一般;可以小到塞進同一個 Application 內,就如同 Copilot DEMO 一樣,收在單一一個 .NET Console App, 靠 Semantic Kernel 整合起來;也可以 scale out 到大型系統,Controller / LLM 可以是獨立的服務各自部署,靠呼叫 API 來整合。
這張圖,其實也涵蓋很多思考跟決策的結果。回應一下這一段最開頭提到的兩個選擇: 資訊科學很擅長的 “精確計算” 與 LLM 擅長的 “意圖理解” 是兩大路線,現在的 LLM 已經展現他的潛力了,但是結果尚未令人滿意,還有很大的改善空間。因此以 Controller 為優先 (必要時才轉發給 LLM) 的架構設計,其實就是 Copilot 模式的核心。
如果 LLM 再更成熟一點,足以擔下這重責大任時,結構上是不是就可以反過來,以 LLM 為優先 (必要時才轉發給 Controller / Service) 的架構設計,這就是 Agent 模式的核心。你可以說,何時能從 Copilot 進步到 Agent ? 最主要就是看 LLM 的處理能力是否夠成熟吧,這是兩者間的分水嶺。
在這邊,我其實是一直把 LLM 當作 “人”,當作是跟 “人” 溝通的抽象化介面 (interface) 後的實作 (implementation)。大家還記得 “圖靈測試” 嗎? 只透過文字聊天的介面,測試者無法分辨出後面是電腦 or 真人,那就代表人工智慧成功了的測試。在這邊,”聊天” 是 interface, 背後有 UI 讓真人輸入是這 interface 的一種實作,而同一個 interface 轉給 LLM 處理並回應,則是另一種實作。
LLM 大模型的訓練,其實就是圖靈講的 “模仿遊戲” (imitation game) 的具體化,為了達到通過圖靈測試的程度,用了巨量 (世界等級) 的資料來訓練,用當今的計算能力訓練出來的模型,主要目的就是讓他能 “模仿” 人類的回應。當 LLM 這份實作開始可以追上 “真人” 的實作效果時,就是這次我們一直在談的 “意圖理解” 了。既然我都把 LLM 當作是 “意圖理解” 這要求的 interface 的一種實作,那代表應用程式只要需要用到 “意圖理解” 來解決問題的情況,都可以開始用這個 interface 來設計了。而這 interface 都是 ChatCompletion 的操作,因此,開發人員要在系統內正確使用這 interface 來解決 “意圖理解” 的問題時,自然就是給合適的 text ( input / output ), 也就是所謂的 prompt engineering,來驅動對話 (response),以及驅動後面的邏輯推論與該執行的動作 (tool use)。
剩下的,就是如何安排必須精確執行的邏輯程序 (controller) ,以及需要高度抽象思考的意圖理解 (LLM) 兩個角色了。對我來說就是前面講的,以誰為主,以誰為輔的問題。這段,就是我在思考整個應用程式架構時,我給 LLM 的定位。現在的 LLM (實作) 效果還未令人滿意,但是你應該開始準備好開發框架了,等待以後成熟的 LLM 出現後,把背後的實作替換掉,這就是 OOP 常提到的依賴介面,而不依賴實作的思路。
第二, 思考 LLM 該如何安排進開發與部署的 Pipeline ?
而 LLM 的部署方式,也會是將來基礎建設的課題之一。你有可能從 Cloud 取得其他 AI 公司發展的私有模型服務 ( ex: Azure OpenAI, By Token 計價),也有可能來自 Cloud 的 Hosting 的其他 LLM (例如 LLaMa3),按照 Token 或是 GPU hours 計價;當然也可能是自己準備機器 + GPU,準備足夠的專屬 AI 算力來跑模型訓練或是推論;更極端一點的甚至是開始部署 Edge 端的算力,用 CPU / NPU / GPU 讓設備端也開始有 LLM 的推論能力,這些應用程式將可以在終端設備離線獨自運作 (例如前陣子新聞炒很兇的 AI PC / Copilot+ PC ,使用內建在 Windows Copilot Runtime 的 SLM) …
這些部署方式也會影響你的成本結構。舉我 3-5 RAG 的案例來說,我最終選擇在 GPTs 展示 RAG,而非在我的 API 內執行 RAG 的完整流程 ( LLM + Embed + VectorDB ),其中一個原因就是 Token 的價格,我想把費用分攤到每個使用者自己 ChatGPT 的額度,而不是全部綁在我自己的 OpenAI APIKEY。每個人都有基本的額度,足以拿來嘗鮮與 PoC, 而集中用 AP 端的 APIKEY 則有整體成本管控的效益 (但是我得替所有體驗的人買單,問一次問題大約要台幣 TWD$ 3 ~ 5 元左右)。這些經驗與能力,其實都會是將來正式開發 AI 應用程式需要考量的規劃與設計。
最後一個我這次演講提到的,就是整個應用程式的部署 Pipeline。多了 AI ,需要部署的服務與資源也會不同。我在 DevOpsDays Taipei 2021 講了這個題目: 大型團隊落實 CI/CD 的挑戰
 // DevOpsDays Taipei 2021, 大型團隊落實 CI/CD 的挑戰
// DevOpsDays Taipei 2021, 大型團隊落實 CI/CD 的挑戰
裡面提及這張圖:
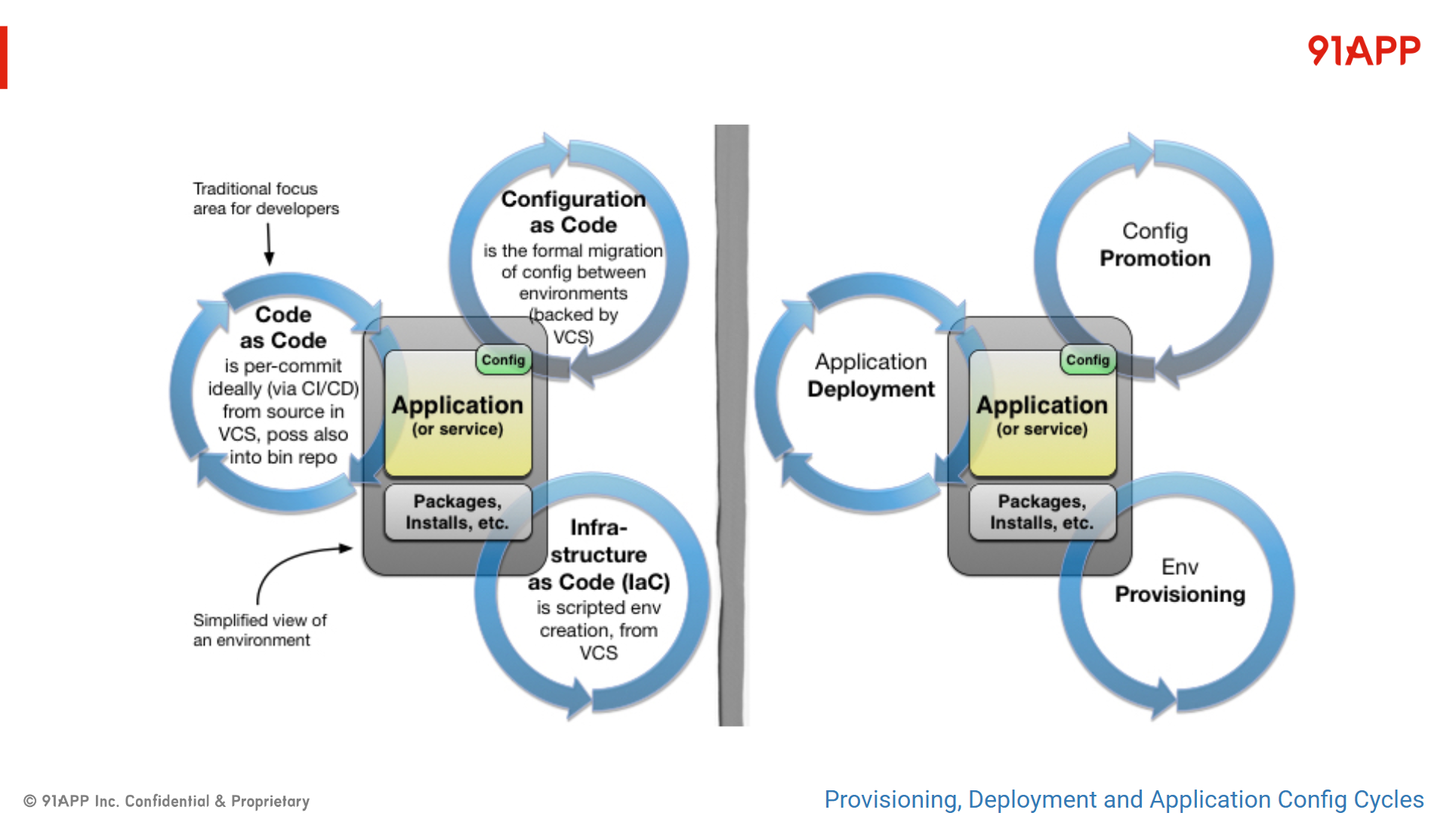 // 簡報 P13 , 來源: Provisioning, Deployment and Application Config Cycles
// 簡報 P13 , 來源: Provisioning, Deployment and Application Config Cycles
// 其實這張圖的作者 Paul Hammant, 就是這次大會邀請的 TBD (Trunk Based Development) 的 Keynote Speaker, 特此感謝 : )
今年,我再度拿這張圖出來用,部署應用程式的三大 pipeline 應該再多一條 AI 專屬的 pipeline:
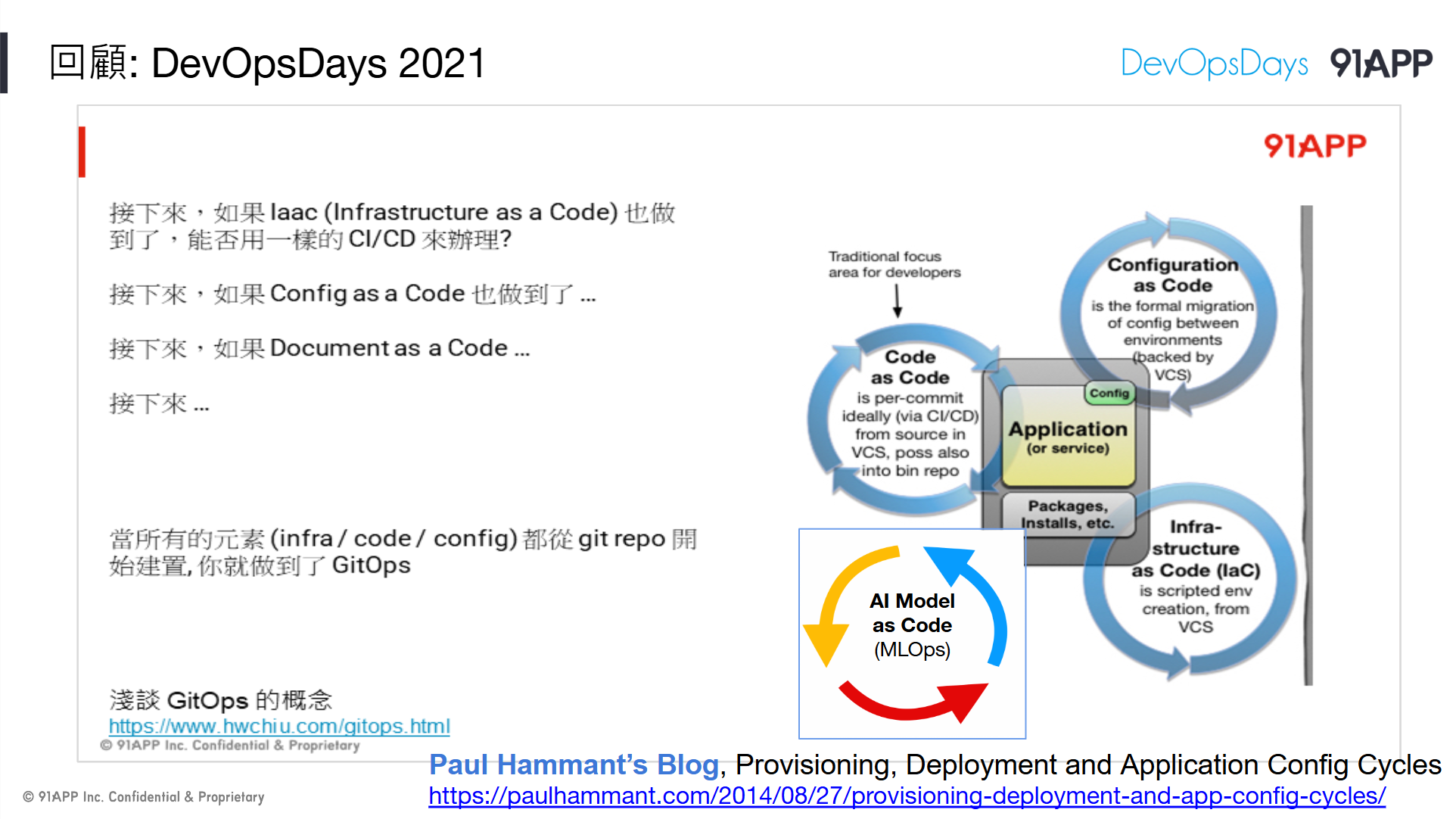
// 簡報 P56, 回顧: DevOpsDays 2021
應用程式主要是由 Application + Configuration + Environment 三大面向組合起來的,如果這三大面向的產出都用 code 來管理 ( Git Repository ),部署流程就都能用 CI / CD 的模式來推送上線,那整個 Application 的部署管理模式就能統一用 GitOps 來運作了,這是當時我講這頁背後的精神。
那麼,加上了 AI 會有何不同?
我覺得不會有什麼不同,一樣是 Git Ops。只是你需要部署的東西,多了第四個面向要考量了,那就是 AI。
AI 會有資料 (收集的資料要轉移去訓練模型),會有模型 (訓練好的模型要部署上線),會有 AI 算力的部署與調度等等問題,這些也都該有專屬的 Pipeline 來達成,才會是個成熟的 AI 應用程式執行的環境。
最後: 架構設計 & 開發部署,軟體開發必要的基本功夫:
我想,這些就是軟體開發團隊,在 AI 時代必須做好的基本功夫。最後我再用一次這段開頭的投影片當結尾:
// 簡報 P37, THINK: 如何訓練出一階魔法使?
… … … … 用基礎的魔法,就足以對付這個時代的魔法使了 … … … …
4. Ref: 零售業的 AI 應用情境
這段,其實在演講當下是被我跳過的,沒辦法,台下已經在舉牌催我了 XDD,我當下覺得很可惜,因為我講了這些,其實都完全能跟我老闆 Happy 在 生成式 AI 年會上分享的內容 ( 零售業的 AI 應用 ) 相互呼應啊,他提到的案例,背後就是 Agent / Engine 的各種組合與應用,其實就是我提到的 AI / API ,只是用語不同而已。
所幸,在我準備這些文章內容的同時,Happy 的這些內容也有部落格文章的版本了,有興趣的可以直接看他的原文:
 #零售的科學, 零售業的四種銷售場景, Happy Lee
#零售的科學, 零售業的四種銷售場景, Happy Lee
其他相關連結我也一起附上:
- Generative AI 年會: 大會共筆 - 李昆謀
- 簡報連結: 零售業的 AI 產業應用
我這邊只補充簡介,以及跟我想傳達的主題有關聯的部分。節錄 Happy 這篇文章的最後一段:
…
這是一個相對富足的時代,我們販賣的是消費的「心理滿足」,而不只是販賣消費者的「基本需求」。回到零售業的四種銷售場景,透過這樣子的討論,我們更可以進一步思考這些線所代表的銷售場景的意義。雖然零售業進入到了全通路的時代,有各式各樣五花八門的銷售場景,但如果回到這種本質面的討論,更可以知道在銷售端,身在零售業,應該要如何佈局。
透過用零售業的四種銷售場景來思考,可以一種全新的視角,探討零售業,在各種新科技的衝擊下,所面臨的機遇與挑戰。
尤其在 AI 到來之後,零售業的銷售場景,會遇到怎樣子的衝擊與改變呢?
在 AI 開始介入零售業之後, 現在的這四種銷售場景,會有什麼改變呢?
AI是會取代無人的銷售? 還是會取代有人的銷售?
…
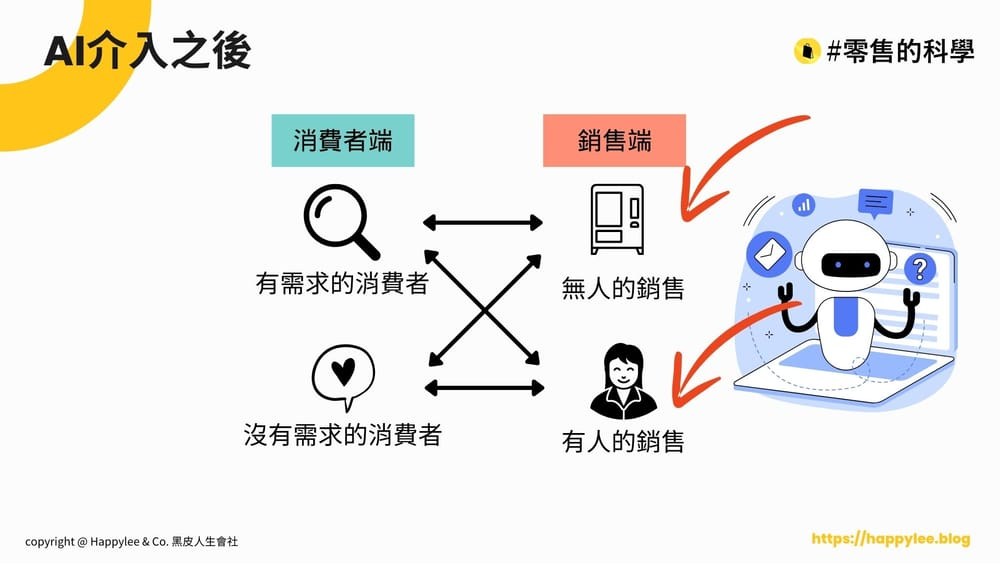
現在零售業賣的是「心理滿足」,而不只是販賣「基本需求」,經驗老到的業務員,就是能抓住顧客的「心理滿足」,這個維度的問題不是傳統資訊科學能有效面對的,而 LLM 開始有能力理解消費者的意圖,這件事開始看的到曙光了,我前面在做的 PoC (偵測滿意度,個人化) 其實就是在做這件事。
另一段,Happy 還沒寫成文章,不過他在 Generative AI 年會已經釋出的簡報有提到,未來是各種 Agent + Engine 協作的年代;Agent 可以代表消費者,也可以代表店家;而 Agent 在代表人類進行各種交涉與收集資料的同時 ( 我示範的 安德魯小舖 GPTs, 就是代表店長的 Agent ),也需要各種後端系統的輔助 ( 就是 Engine ),我節錄一頁 Happy 的簡報:
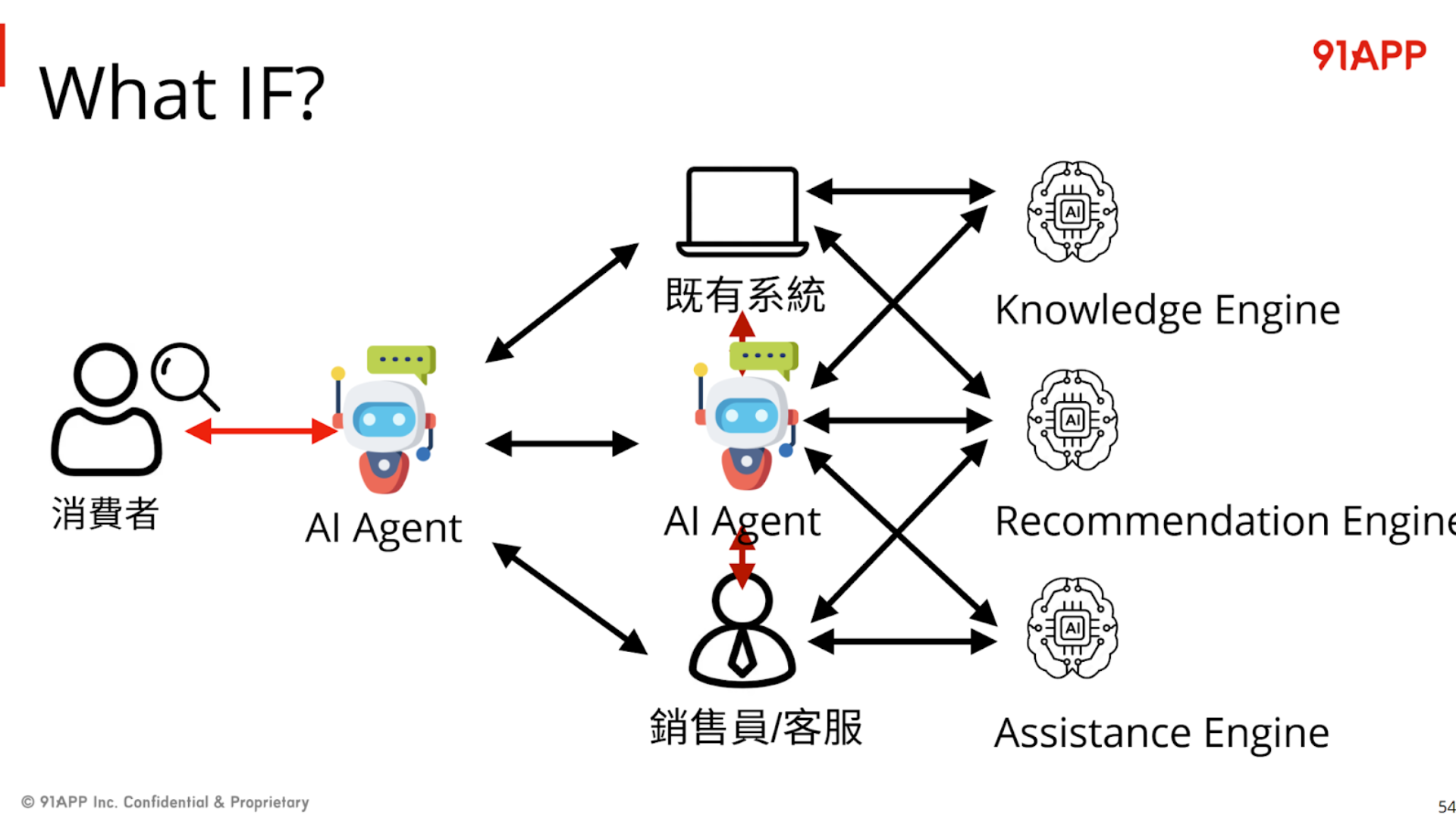
// 簡報 P74, What IF?
AI (Agent) 會變成最終面對人類 (不論是店長、客服、或是消費者) 的代理人,負責溝通的管道 (所以要會自然語言,要會察言觀色)。而他也需要有使用工具的能力,善用後端的各種 Engines (如簡報上的 Knowledge Engine, Recommendation Engine, Assistance Engine)。
看懂之間的對應了嗎? AI Agent, 就是我前面不斷的在嘗試的 “安德魯小舖 GPTs” 這樣的角色,而我一直強調的 API, 就是取用後端各種 Service (或是 Happy 的用語: Engine)。API First 講求的就是你後端服務,必須要有良好的介面設計,必須針對 Domain 設計,而非 UI;你必須有良好的 AI DX,讓 AI 能看得懂,能夠有效運用… blah blah, 其實講的就是同一件事。
這個案例我就點到為止,說實在話 Happy 的這場演講比我的更值得好好消化思考。如果你是技術人,可以先看懂我的文章之後再去看 Happy 的應用案例;如果你的重點不在技術而在應用,推薦你先看 Happy 的演講 (官方記得有販售錄影回放票),想知道怎麼做再來看我的文章。
5. 寫在最後
這篇,算是我年初那三篇文章的總結,加上這半年我延伸的應用心得,以及補上這半年實際開發與部署的想法。可以把它當作這三篇文章的續作。同時,剛好在 DevOpsDays Taipei 上,這主題也是前三年在台上分享內容的延續,於是在準備 Keynote 的內容,同時也有了這篇文章。
除了前面兩大段落的小結,剩下我還有一些想談,另外還有事後的紀錄,包含大會的問券回饋,以及意外發現網友的研討會參加心得 (有提及我這場的心得感想),我就一起寫在這裡了。
5-1, AI 會讓每個環節都帶來改變

// 簡報 P77, 今天沒辦法談到的部分
架構會改變,流程也會改變,開發人員的角色也會改變。
用 AI 寫 code, 社群上已經很多人在聊了, 我是認同這些工具的能力的, 最終你需要具備的, 是鑑別這些工具產生的結果做的對不對,需要的是技術與架構的決策 & Review。而 AI 寫 code 已經普及了,這篇我也花了半篇的篇幅在談 AI 用 API (code),如果 AI 再更成熟一點會是甚麼? AI 自己寫 code 自己用嗎? 其實這並非不可能, 分開來看現在都已經實現了,只差更好的整合而已。
當 code 已經越寫越快,真正有價值的事情會從 “量” 開始變成 “質”,比起寫得快,能否判定寫的 “對” 的能力會更重要。同樣的,API 也是重要的資產,比起你能很快的量產能動的 API,正確的設計 & 高品質的 API 會來的更重要,因為這是 AI 往 Agent 發展很重要的環節,唯有你的 API 夠成熟可靠,你的服務才能被 AI 加值應用。
你現在該思考的是 AI 越來越聰明,越來越便宜的話,你想要拿它來幹嘛? 例如我示範的 “安德魯小舖”,你會想拿 AI 來做什麼應用? 如果 AI 的算力 ( GPU / NPU ) 不再昂貴,成本已經不再限制你模型的選擇與部署的方式時,你會如何布局你的基礎建設?
這些都是很好的思考題目,對我來說,就像是十年前大家都在談論 Cloud Native 時,我在想像 Microservice 對於設計與部署的樣貌是一樣的光景。現在雖然 AI 已經把軟體業翻了一輪了,不過他還是剛起步,很多領域都還在發展中,各位其實還有時間做好準備。最後,我還是拿我最關注的軟體架構設計這領域,用這兩張簡報來做結尾吧!
第一個心得是: 思考你的產品服務,未來該用 AI 強化什麼?
我嘗試的是 Agent & Copilot, PoC 的過程中我已經得到了我想要的實做經驗跟細節了,我有更充足的資訊支撐我繼續往下思考軟體服務該怎麼善用 AI 這課題。
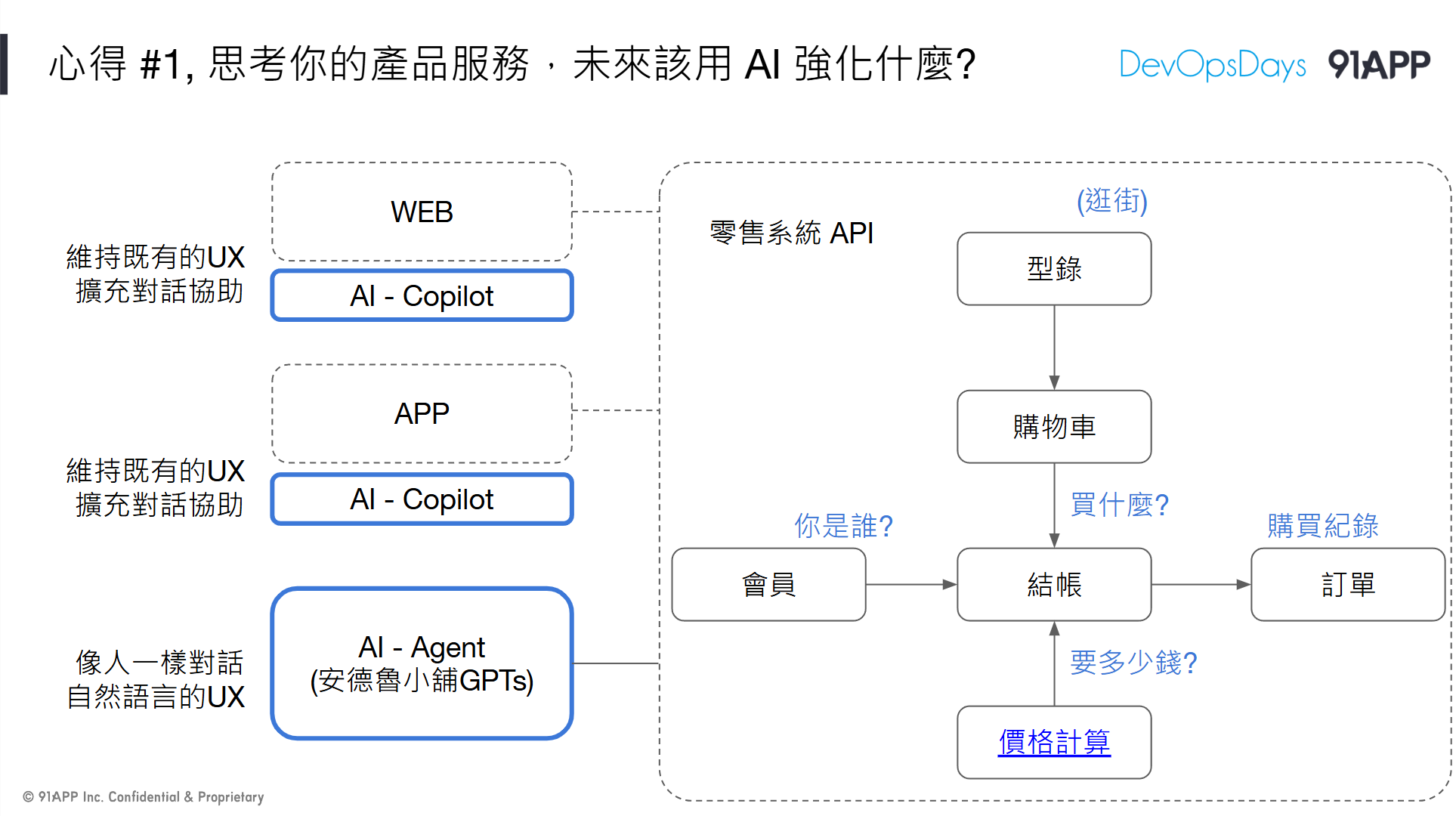
// 簡報 P78, 心得 #1, 思考你的產品服務,未來該用 AI 強化什麼?
另一個心得是: 思考你的技術架構,你的基礎建設與開發元件,還需要補足那些環節?
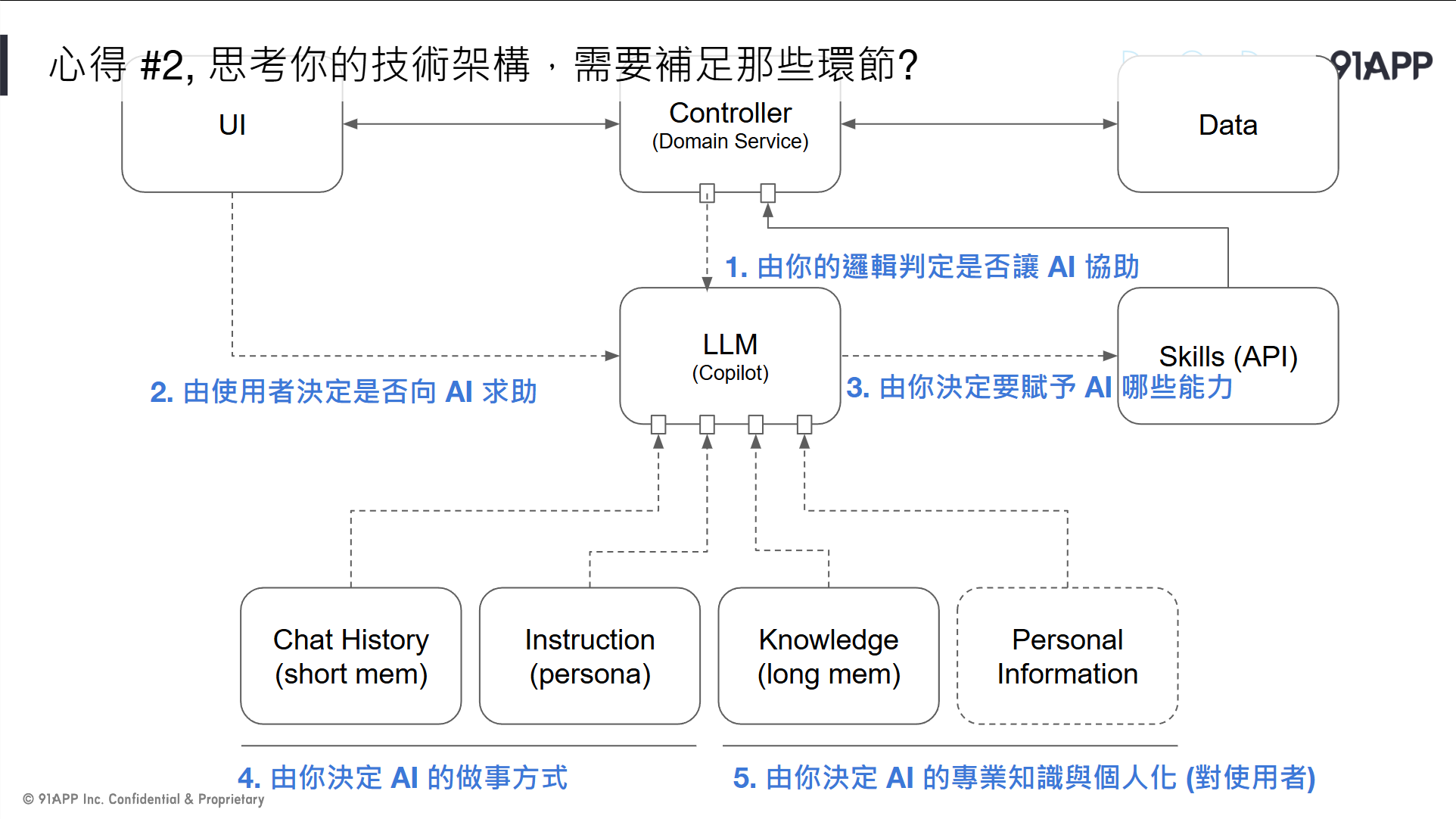
// 簡報 P79, 心得 #2, 思考你的技術架構,需要補足那些環節?
5-2, 大會滿意度問券
就在這篇文章要發表的時候,正好也收到了大會寄來的問券與回饋。留一點篇幅感謝主辦單位、工作人員,以及 2024/07/10 當天在台下聽我講這場的朋友們。每年我都在等聽眾的回饋,比起分數,這些意見更能讓我覺得我做的事情是有價值的..

Keynote 的滿意度分數不好拿,參加的人多,就很難面面俱到,正反面意見都會有.. 看到其他 session 可以拿到 4.85 分, 工作坊可以拿到 5.00 分的滿意度,對我來說都是遙不可及的.. 這次拿到 4.7, 看到結果後鬆了一口氣, 本來我預期應該會更低, 因為今年共筆沒看到太多回饋,事後也沒看到太多心得感想,實在很難客觀的判定今年講的好不好,直到收到這封 email..
一樣,回饋總是有好有壞,但是都是大家給我的意見,應該都要接納才對,我就一次不刪的全文照貼了,也當作我明年準備的參考:
- 展示的影片若是可以字體更大,或是用ppt方式呈現會更好,明白講者有用說的來解釋,但因為會場過於龐大,有時其實會漏聽幾句,感覺就是少了些什麼
- 非常實用且對初學者友善,用了簡潔明瞭的方式說明,投影片中也附加豐富的註解,透過這些解釋可以解開心中的疑惑,讓聽眾更能進入狀況。
- 以我一個從業15年以上的軟體開發人員,真的感受很多,收益匪淺。 大師的觀點跟著墨相當獨特。
- api first is a awesome solution for biz api, but how to make the api list, It’s a hard job for me maybe can merge ddd thinking that mix both for the full biz domain api list
- 內容講解的維度很高,可以從更高的視野看待 AI,強度也算很高!但時間不夠嗚嗚嗚
- 學到很多,對於AI應用在開發上的理解很具啟發,與API first的策略結合也深具巧思
- 聽完會覺得是從不同角度來思考ai 應用,在軟體開發中思考可以怎麼留位置給 ai
- 新的啟發,但還不能實際應用,未知錯誤難以控制
- 實際已運行的商業應用面可以增加
- 很特別的發掘角度,但實務應用還需努力
- 專業 實用 啟發
感謝大家在填滿意度分數的同時,還願意多敲幾個字留這些意見給我 : )
5-3, 來自 Mick Zhuang, 參加心得分享

// 網友 Mick 分享的參加心得, 來源
一樣是在文章貼出去後才發現的,我本來只是在納悶,怎麼今年 DevOpsDays 結束後都沒看到什麼心得分享… 就順手 Google 一下,結果就看到這篇 Mick 網友發表的參加心得,分享了他最喜歡的三個議程
很榮幸的, 我的這場 “從 API First 到 AI First” 也在其中 :D
當然會轉貼這篇不只是因為他選中我的場次 (咦?
更重要的原因是,他總結的重點,完全就是我當天想傳達的 (這篇總結得比我自己講的還好) 懶得看我落落長的文章,可以先看看他的參加心得。
我節錄他摘要我演講內容的片段:
在生成式 AI 湧現 後,可以用 AI 改善很多不同的流程,這個演講針對的是「把 AI 融入你的服務之中」。
過往要產生好用的使用者介面,往往仰賴的是設計師對產品價值及對使用者的了解,加上自己的經驗來設計介面,提供適合使用者的資訊內容與呈現方式。有了生成式 AI 的聊天介面後,透過大型語言模型對語意的理解,提供對話方式也成為一種新的使用者介面。
在這個演講,Andrew 主要使用的是 OpenAI ChatGPT 的 GPTs,利用 GPTs 背後能夠設定 Prompt 和 Function Calling 的功能,提供一個電商的聊天客服介面,在 投影片 裡面可以找得到他的 Demo 影片。
覺得蠻有洞見的是,他從兩年前的 API First 主題,強調好的 API 設計是提供商業價值與長遠的擴充性不可或缺的部分,到了這兩年生成式 AI 的大幅發展,他將其疊加在 API First 的概念上,好的 API 設定提供了符合商業價值的功能定義,而生成式 AI 是用大量通則資訊訓練而成的,所以如果你的 API 設計上越符合真實世界的行為,AI 就能用得更好。
文章在這邊: blog.mickzh.com/blog…
