![]()
繼上一篇文章: 刻意練習 - 打好基礎 講完整個我對技術人員職涯要持續成長,就必須要刻意的持續練習看法後,這篇我就來舉實際的案例吧。這篇案例是示範,當你學習了技術與管理的知識之後,如何融會貫通,運用在解決問題上的案例。你累積的經驗或是能力,若無法轉換為價值,那是沒有用的。技術人能展現的價值,就是解決問題。怎樣才能讓一個問題拿到你面前你都能迎刃而解? 最有用的就是連結你累積的各種能力。連結越強,織起來的知識網就越強韌,你看問題就會越到位。
這篇我就拿我在去年 91APP TechDay 以及 .NET Conf 2020 分享的主題: 維持非同步系統的 SLO 來當例子吧。這是近年來我擔任架構師,端出來的幾個 solution 之中,對於 “連結” 這件事最有代表性的案例了。這是個包含開發技術,架構設計,服務水準與流程管理等等層面的綜合需求。要解決這問題,你不但要有很札實的技術及實作能力、也要有很到位的 cloud infrastructure 掌控能力,同時還要具備管理知識,缺一不可,才有可能把這件事情解的漂亮。表面上看來,訂定服務水準要達成的目標 (SLO, Service Level Objective) 並落實,是個很純粹的技術題目啊,但是真正做過的人就知道,光是開規格就不知道該怎麼開了,團隊做出來你也很難驗證 (直到上線後碰到流量撐不住之後… )。
我自己的心得是,越複雜的問題 (即使是系統問題),你越需要從全面的角度,包含開發、架構與管理的角度去思考怎麼解決他。
服務水準是很難量化的需求啊! 大部分的開發人員很習慣按照 “規格” 來開發,不論是 UI, Input / Output, Process / Flow, Format 等等有形的規格。唯獨時間維度有關,跟流量或是附載有關,跟可靠度與回應時間有關的需求,往往難以用明確的規格表達。就算訂出規格也難以驗證,最終都得靠完整的壓測 (或是來自真實流量的考驗) 才能確認。我的想法是,就算無法在事前就先訂出規格 (做法),至少也要能用量化的指標來描述吧! 先能量化你才能逐步明確化做法,一步一步的解決問題。
如果你也開始覺得這是件不可能的任務,那恭喜你,你已經開始可以理解這個問題的困難點了。請繼續看下去 XDD
前言: 架構師的修練 系列文章導讀
我在過去一年多 (2020 ~ 2021) 的幾場公開演講,開始做了一點不同的嘗試。除了技術或是架構知識之外,我開始會強調為什麼會這樣思考的過程,也開始會帶到該怎麼培養這樣的經驗與能力的想法。在 2020 下半年,有幾場演講都往這個方向調整了。2020 下半年是個爆忙的半年,到現在終於有點力氣把這些內容整理一下了,於是就開了這系列文章 - 架構師的修練, 刻意練習。
這些場次都得到不錯的回響,我還是擅長用文字來表達這些想法,因此決定開這系列文,把我在當下礙於表達能力沒辦法說清楚的內容,寫成文章。以下是我預計寫的主題:
- 架構師的修練 #1, 刻意練習 - 打好基礎; 2021/03/01
- 架構師的修練 #2, SLO - 如何確保服務水準? 2021/06/04
- 架構師的修練 #3, 刻意練習 - 如何鍛鍊你的抽象化能力? 2021/09/16 (預計)
- 架構師的修練 #4, 刻意練習 - 練習題範例: 生命遊戲 2021/09/16 (預計)
開始前先想一想: 要解決的問題是什麼?
雖然這篇是把我演講的內容寫成文章,但是演講有時間限制,可能大家沒耐性聽我講一堆故事…。不過這是我的部落格,我想寫一些我想寫的…。我想要把演講當下沒辦法交代清楚的脈絡一起寫出來交代清楚,這樣才能前後連貫的說明我思考的脈絡。前面這段 前言,算是問題的背景,我花點時間交代一下…
在我工作的場域,我負責其中一個非同步的系統。就如同大家熟知的 FaaS (Function As A Service), 這套系統要負責執行來自其他團隊委託執行的各種大大小小的任務 (Task)。我用最有效率的方式安排運算資源與執行順序去消化這些 Task, 然後必須在指定的時間內完成,這就是主要的 SLO。在這前提下,當然能花費越少的資源越好。在 Cloud 的環境下,用越少的資源就代表越少的運算費用。我相信用過 Azure Functions, 或是 AWS Lambda 等服務,大概都能想像吧。
這篇文章,我用一個實際的案例來貫穿整個主題的思路。我用外部訊息發送的案例 (可能是推播、簡訊、或是 email) 當作例子,當你一天有上百萬則通知需要推送到外部系統或是服務,有些通知需要在指定時間內發送完畢時,身為產品經理或是技術主管,你該如何面對這問題? 你如何偵測訊息是否在指定時間內發送出去? 無法達成時你該如何調整? 如果極端狀況下真的無法達成 SLO 了,你如何有用系統化的方式讓前端的系統能自動做出調整? 這些都是服務真正上線後,你需要考慮的問題。
當時當我接到這挑戰,思考到這個層面時,我才開始意會到,光是把 code 按照規格寫好,光是把效能調教好是不夠的 (即使這件事我做到 100 分也一樣)。我必須多做點什麼,搭配額外的手段 (不管是技術還是非技術手段) 才有可能。所以我才聯想到過去的一些 Cloud Infra 的基礎知識,以及擔任主管時學到的管理技巧,並且思考將他們應用在系統上…。
主題: 非同步系統的服務水準保證
以下的段落,我就直接用文字還原我在 .NET Conf 2020 這場 session 上面說明的內容。如果你懶得看這些文字,想看現場的,我整理了當時的錄影以及投影片下載的連結,有需要的請直接取用:
主題開始:

其實我每次固定參加的幾場研討會,我發表的內容都是有延續的。例如 .NET Conf, 或是 DevOpsDays Taipei 我都默默地維持這個慣例。一開始我回顧了過去幾年我在 .NET Conf 發表的主題 (我竟然也參加了四年了… Orz)
 2017, 我分享的主題是: 容器驅動開發, Container Driven Development (錄影, 投影片)
2017, 我分享的主題是: 容器驅動開發, Container Driven Development (錄影, 投影片)
說明的是如果容器化部署已經是你團隊中的標準做法了,那麼這樣的基礎建設能替你的開發方式做那些簡化跟改善?
 2018, 我分享的主題是: Message Queue Based RPC (錄影, 投影片, 文章)
2018, 我分享的主題是: Message Queue Based RPC (錄影, 投影片, 文章)
透過 message queue 來做非同步的通訊 (單向) 已經是很成熟的技術了,我們也開始拿它做為分散式非同步任務處理的基礎。使用的地方越多,各種需求就越多,其中一種最常碰到的就是: 如果我想要取得非同步任務的結果該怎麼辦? 雖說是非同步,但是我也期待能夠用同步的方式得到執行結果,那該如何處理?
這個 session 就是說明如何善用 C# 的 async / await 機制,搭配雙向的 message queue 通訊,搭建以 message queue 為基礎的 RPC (Remote Procedure Call) 的設計。你可以同時兼顧 message queue 帶來的可靠度與高效率, 也可以藉由 C# 的 async / await 帶來接近 real time 的便利性。
 2019, 這次玩的比較大,我開始嘗試在同一場研討會分享較大規模的主題,因此跟主辦單位要了連續兩個 session 的時間來分享。主題是:
2019, 這次玩的比較大,我開始嘗試在同一場研討會分享較大規模的主題,因此跟主辦單位要了連續兩個 session 的時間來分享。主題是:
這兩場我說明了大型團隊怎麼在 code / infra / config 三個層面的部署與管理取得一個平衡的作法。通常這是三類型專長的人員在負責的 (開發 / 維運 / 營運)。沒有事先把三者的協作方式定義好,規模一大很容易出問題的。上半場就在講這些設計的概念,下半場則是基於這個概念,那麼開發團隊應該要建立起甚麼樣的基礎框架才能辦的到?
這兩場我覺得很可惜,要講的東西有點龐大,但是我的表達能力還不夠到位,不足以在 100 分鐘內交代完這些想法,最後當然是超時啦,也被迫省略了一些細節。同樣的,這些內容都公開,有機會我再看看有沒有空也把它寫成文章…
 回到 2020, 這次我們直接要了一整軌,用四個主題串起我們想分享的內容。按照順序:
回到 2020, 這次我們直接要了一整軌,用四個主題串起我們想分享的內容。按照順序:
- Ruddy 老師: DevOps 教戰手冊 - 三步工作法
- Andrew: (就是這篇) 非同步系統的服務水準保證
- Steven Tsai: 微型任務編排器 - Process Pool
- Andrew / Fion: (這應該會是下一篇) 刻意練習 - 如何鍛鍊你的抽象化能力
其實這些內容也是我刻意安排的。由 Ruddy 老師多年的 DevOps 心法來開場,講了很多靠經驗累積下來的實作心得。而我這場就是實際推行的案例,就是前面提到的非同步系統怎樣達成 SLO 的期待。而非同步的系統,背後就是靠 2017 / 2018 分享的技術搭建起來的啊! 擴大到全團隊使用,靠的就是 2019 那場分享的框架來搭建的。而要維持資源的高使用率,靠的就是第三場提到的 Process Pool (我先前也寫過這主題的文章)。這一連串的機制,都對團隊的實作能力有很高的要求才辦的到。因此第四場講的刻意練習,就是說明平日該如何鍛鍊才能累積這樣的實作能力。
其實這幾頁投影片,我在當日的 session 只用了一兩分鐘就帶過了 (沒辦法,時間真的有限)。我偏愛寫文章也是這樣,比較沒有篇幅或是時間的限制,內容也容易連結,比較能夠有系統地把這些分享的內容組織起來。如果你是我部落格的忠實讀者,我相信這些主題過去你都看過了。我也累積了夠多的內容,開始可以一個一個串連起來應用了。講到這邊,我就拿這開場來呼應上一篇講的 “連結”,這就是我實際串聯的案例。
既然底層的實作 (Container, Message Queue RPC, Process Pool) 都有另外的篇幅來說明了,我這篇就繼續往我的主題: 服務水準保證(SLO) 來推進吧!
1, 何謂服務水準? 該如何量化與量測?
我習慣在深入各種細節之前,先把主軸或是定義講清楚。既然講到 “服務水準” 這件事,就不能忽略 SLA / SLO(s) / SLI(s) 是什麼。開始之前,我先講一小段案例。我們團隊很擅長大型服務的維運,這背後是有套流程的,為了凸顯我們跟一般的開發團隊的差異 (尤其是開發外包、或是各種系統整合外包商),我拿這張 slide 來說明:

大部分的人,想到大流量,不外乎就是水平擴展 (scale out) 之類很直接的面對流量。實際上這些都是要花錢的,比起力大無窮,實際的狀況更追求精準的力道。要水平擴展前,你必須先知道現在 “該不該” 擴展,也就是必須先做到監控。
既然要監控,就要有明確的監控標的。我們的作法是,先挑選你期待的服務水準。這張投影片上說的是 99% 的 request 都必須在 300 msec 內完成回應 (response)… 這就是我們期待的服務水準 “目標”,也就是所謂的 SLO ( Service Level Objective )。當然你可以定義多個 SLO,不過我們就拿最重要的回應時間當代表就好。
SLO 定義好之後,維運團隊必須按照這個指標 (每一瞬間 99% 的 request, 最高的 response time) 來進行監控。把 SLO 的 O 拆掉後,就只剩單純的指標定義,這個指標就是所謂的 SLI ( Service Level Indicator )。監控的團隊,必須想辦法在系統埋下各種探針 ( probe ), 收集完整的數據, 以便讓維運團隊隨時能掌控 SLI 的狀況。為了加速處理速度,通常也會替 SLI 做分級,與其回報一堆數字,另一種做法是分級用燈號來標示,維運團隊只要看燈號的顏色就能立刻了解目前服務的水準是否需要留意。以前面提到 SLI 必須低於 300 msec 的期待,監控團隊可以這樣設置:
- 當指標低於 150 msec, 該指標的燈號為綠燈 (安全)
- 當指標介於 150 msec ~ 200 msec 之間, 該指標燈號為黃燈 (需要留意)
- 當指標高於 200 msec, 該指標燈號為紅燈 (發送警告通知,需要立即處理)
維運團隊的值班人員,按照這個流程,理論上都能在第一時間讓系統回復正常的服務水準。不過指標會亮黃燈或紅燈,可能是個案,也可能是個趨勢。同時對服務水準的期待 (SLO),也有可能因為市場或是使用者的變化而有所改變。這時維運團隊應該定期檢討指標是否合理? 例如是否該將 300 msec 的要求調低? 或是檢討過去一個月進入黃色燈號的比例已經提高,系統本身應該有其他狀況需要額外處置 (效能優化,或是擴充運算能力等等)。
這整個流程,就是一個基礎的 DevOps 循環,藉由監控的回饋,給開發團隊更明確的優化或是調教的指示。改善後回到前線,評估是否有改善,然後再取得回饋。如此不斷的循環,系統就會不斷的進化。
了解這些過程後,回頭來看看這三個名詞的定義,應該就很清楚了。我擷取網路上的定義:
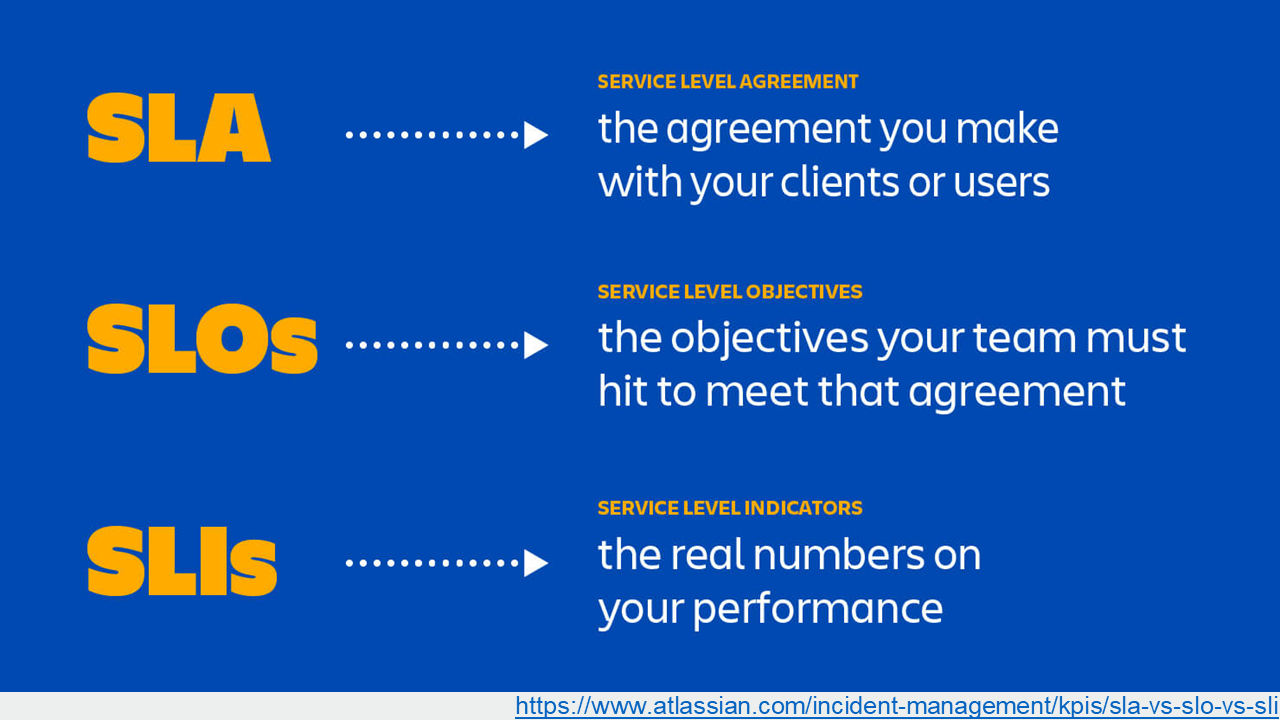 圖片來源: Atlassian.com
圖片來源: Atlassian.com
最後補上前面沒提到的 SLA ( Service LEvel Agreement )。維運團隊內部,工程單位看的是 SLO / SLI, 而 SLA 則是跟使用者達成的協議 (Agreement) 或是合約。意思是當服務未達預期目標 (SLO) 時,服務方應該要做的處置,以及事後的賠償條款等等。
2, Case Study: 驗證簡訊的發送
講一堆文字敘述很難想像,我就直接舉一個內部實際的處理案例吧。有些內部資訊不方便直接公開,因此相關的數據或是描述,我都稍作調整,以下的數據不代表實際的情況。各位應該都碰過這種情況吧? 在一個網站上註冊帳號,為了確定你資料沒有亂填 (例如: 電話號碼),因此在註冊當下,會用簡訊 (SMS) 發送一個 4 ~ 6 位數的驗證碼,到你填寫的手機號碼裡。
驗證碼背後通常都有這幾個條件需要滿足:
- 使用者通常在前端等待,因此驗證碼必須在依定的時間內發送出去 ( ex: 5 sec )
- 為了避免使用者用暴力法闖關,驗證碼都有一段時效限制,你必須在這時間內輸入才有效 ( ex: 5 minutes )
由於發送簡訊,是一連串呼叫內部與外部系統的過程,為了不影響前台的效能,一般都會用非同步的方式處理。因此我們也用了很典型的架構設計來處理這問題。我簡化過後,這是當時我們第一版的系統架構:
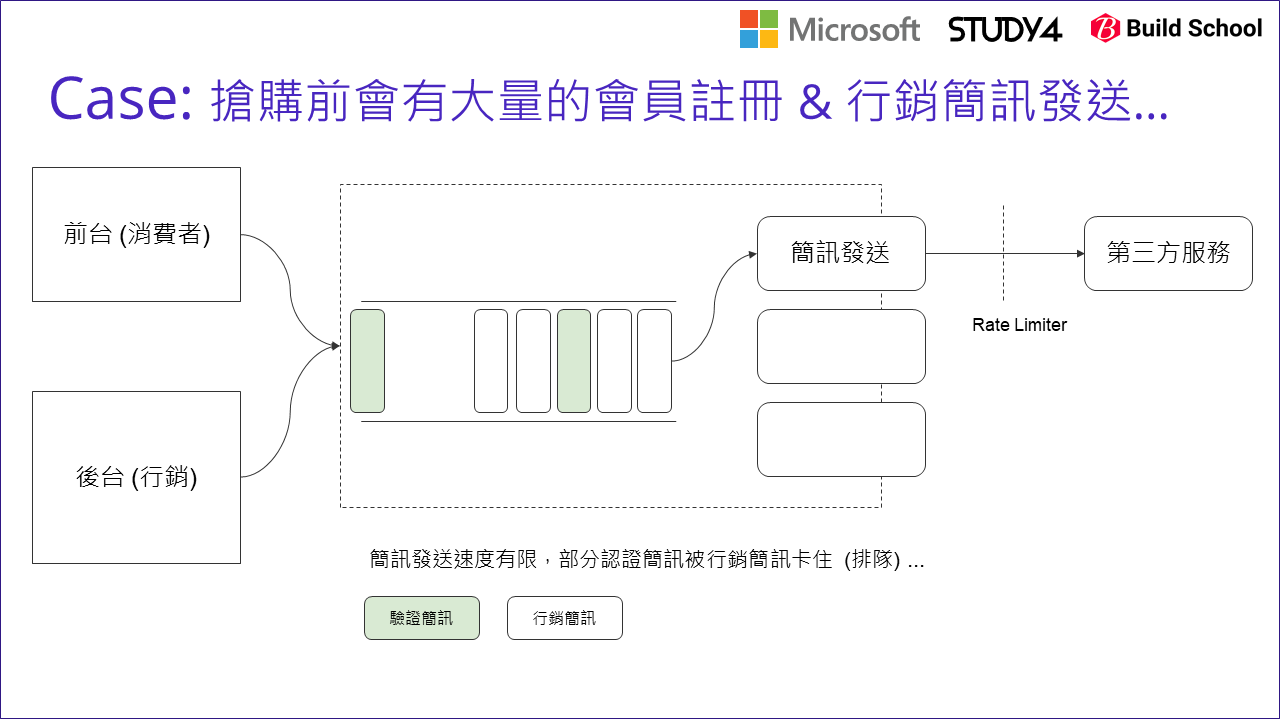
從工程角度,我們很容易地把 “同一種功能” 集中起來重複使用,這很自然,不是嗎? 於是,當驗證簡訊開發完成後,另一個團隊需要發送行銷簡訊,當然就共用同一套 code 了。於是系統就長成上圖的樣子。這時,當碰到周年慶或是大型活動時,瞬間有大量的行銷簡訊發送,於是 message queue 就開始堆積了… 雖然系統不至於垮掉 ( message queue 能夠調節負載,後級可以用最有效率的節奏,穩定的持續運行 ),但是… 驗證簡訊被迫開始要跟著一起排隊,有些簡訊無法在 5 sec 內被發送出去…
(上圖的綠色,代表驗證簡訊)
2-1, 改善的第一步: 找出正確的指標
回想前面的流程。我知道每個工程師都急著想解決方法 (例如 scale out 後端的 worker … )。不過,別急著動手,先想一下如果這種情況發生了,你該如何才能精準的知道: 現在驗證簡訊要花多少時間才能發送成功?
比起怎麼改善,你先掌握正確的 SLI 還來的更重要。你如果直接告訴 infra 團隊,要他在監控系統拉一個 “簡訊發送時間” 的指標給你,他一定跟你翻白眼。沒有任何一個監控系統裝好後就有這指標可以用啊,這完全是 business domain 裡才有的資訊,是我們團隊自行開發的功能。除非你自己把數據抓出來,否則是不會出現在監控系統的指標清單內的。你必須自己從 application 裡面抓出來才行。因此,我繼續把上面那張圖拿出來,把我們期待的指標拆解,拆成幾個系統實際上能監控的更細緻的指標,直到我們能監控為止。
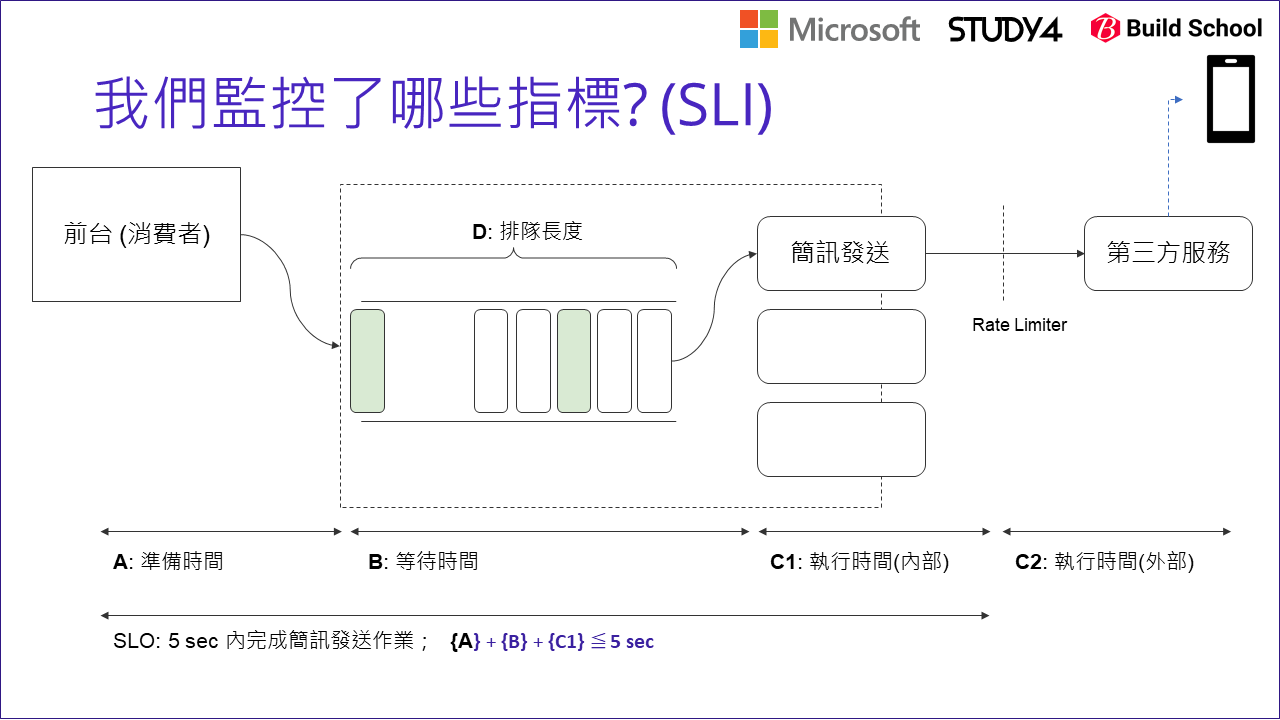
這邊,我就忽略掉簡訊商跟電信商之間的通訊時間了,我定義成 5 sec 內一定要把簡訊成功地送到第三方服務那端。我把這段時間拆成三段:
- A (準備時間):
- B (等待時間):
- C1 (內部執行時間):
發送簡訊的要求,在我們系統內部就拆成這三段,因此我只要能夠監控這三個數據,加起來別超過 5 sec 就是了。因此,開發團隊開始接到新任務,必須按照監控系統提供的 metrics collect API 的定義,把這三個指標送進去。監控人員必須設定警告條件,當 A + B + C1 > 5 sec 時就該發送警告通知。
發現問題後,團隊再來逐一檢測,那就太慢了。所以通常我們會事先擬定好診斷狀況的 SOP,方便值班人員能夠更快的判定數據,做出正確的處置。因此,對於驗證簡訊的處理,我們列了第一份緊急處置標準程序:

當然,每個數值多少算高,多少算低,都有定義,我這邊就省略這些細節,只講重點就好。團隊按照 SOP 做了處置,判定 (B) 的數值過高。不過 (B) 過高還可能有兩種狀況,一種是真的訊息發送量太大,所以堆積太多排隊排太久… 另一種是訊息量正常,但是後端處理很慢都有可能。為了進一步區分這兩種狀況,我們引入了第四個指標:
- D (排隊的長度, Queue Length):
如果 (B) 偏高,(D) 也偏高,就是訊息量太多,高於平日正常的量 如果 (B) 偏高,(D) 正常,那代表是處理效能過慢的原因
透過這樣的對照表,就很容易讓第一線的人員很快判定狀況,做好處置的決策。回到前面行銷簡訊造成阻塞的 case, 應該就是 (B) 跟 (D) 都偏高的 case, 因此團隊很自然地想: 要加速消化訊息,我就把後端的 worker 多開幾個吧!
2-2, 改善的第二步: 解讀瓶頸在哪裡
的確,這樣做很有效果,的確發送延遲的狀況減緩了。不過在定期檢討的時候回過頭來看看,這真的是理想的解決方案嗎?
前面的判斷,算是解決了表面上的問題。 (B) 的數值過高,堆積過多的 message 留在 message queue, 因此提高 worker 的消化速度 (scale out) 的確是個當下能快速解決問題的解方。但是長期呢? 長期你也願意這樣解決嗎? 如何判定?
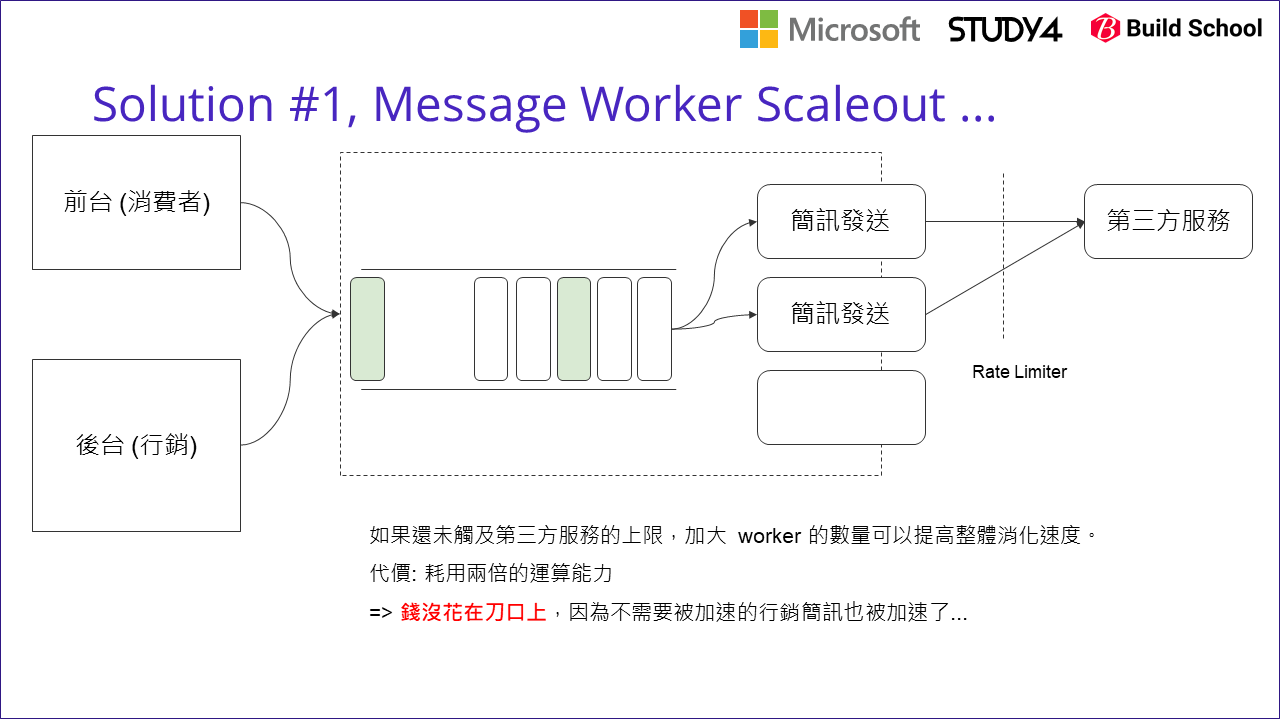
我的作法是回到成本來看。多開幾個 worker 的確是有效的解決方式,唯一的缺點就是: 這做法也間接的改善了相對不重要的行銷簡訊的發送速度啊! 如上圖所示,如果你不在意這些成本的差異,或是處理的人力成本遠高於長期營運的成本,那就可以忽略掉這段了。不過以我們團隊面對的規模來看,這些成本必須被重視。如何能更精準地針對問題改善? 我們團隊提出了修正過的架構:
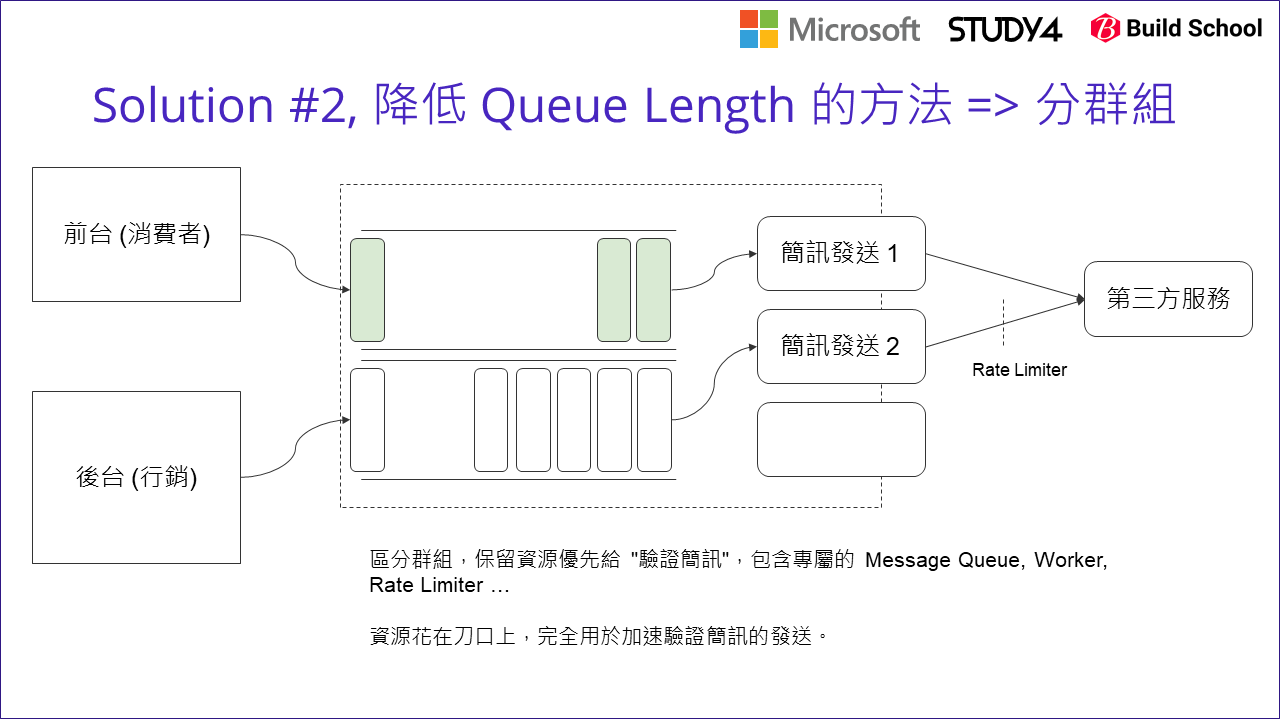
觀念上是先將要處理的訊息,從源頭就按照期待的服務水準分開。一模一樣的架構複製兩組 (其實最主要的差異就是分成兩個獨立的 message queue),然後只針對 SLO 要求較高的註冊驗證簡訊那組,執行需要較高成本的解決方式: 擴大 worker 的數量 ( scale out )。
2-3, 從開發的第一天就弄清楚 SLO
如果以解決問題的話,這個 case 應該到這邊就告一段落了。畢竟效能成本,以及架構都已經到位了。不過由於我負責這個系統的開發與設計,自然不會想就這樣就告一段落。我想的是:
既然都已經完整解決過一輪了,應該能對這問題有更深刻的掌握才是。如果之後碰到類似模式的問題,我還要再來一次整個過程嗎? 如果不是的話,我該在系統本身的設計做什麼改變? 或是在改版的時候做什麼樣的設計,能讓下次面對這類問題時能更快的找到解決方式?
於是,我回過頭對這整個問題解決過程梳理一番,重新抓出過程中的關鍵,作為整體系統設計上的參考。我的結論是:
從開發的第一天,就弄清楚你期待的 SLO
從 DevOps 變成顯學之後,我不斷的強調,不管任何問題,你要先能量化 (測量) 才有辦法開始改善。因此針對這案例,我對 SLO 做了下列的拆解:
對於簡訊發送的機制,我期待的 SLO 是:
- 定義: 當消費者按下 “發送驗證簡訊”,我期待 5 sec 內就要發送到簡訊商的系統上
- 拆解: 在這 5 sec 內,系統總共要完成哪些事情? (定義每個步驟允許花費的時間上限,同時要能觀測每個步驟花費的時間)
- 盤點: 上述這些指標,我是否每個都有能力掌握 (監控)?
- 改善: 如何處理我無法掌握的指標? 是否有間接或是替代的方式? 必要時系統設計時就要能考慮這問題 ( Design For Operation )
- 行動: 善用監控的系統或是服務來掌握這些指標。可透過成熟的系統來做 logs 分析,或是監控服務提供的 metrics API 來達成。
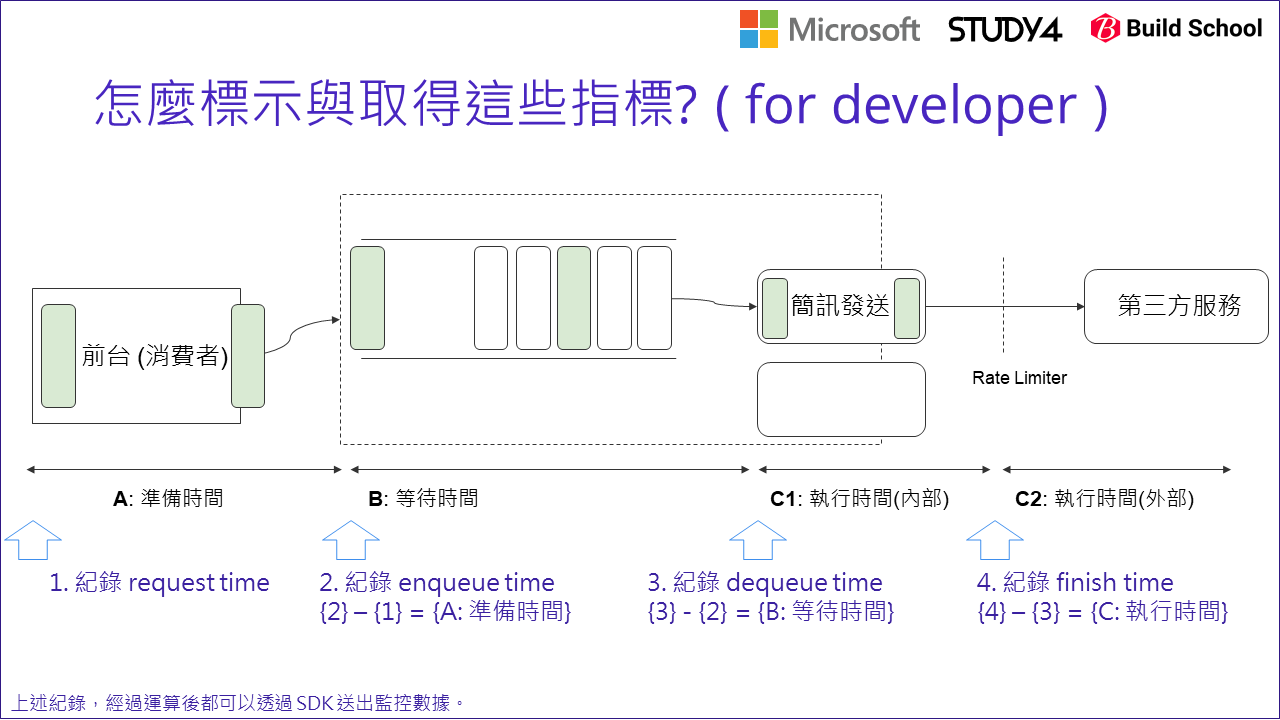
重新拿前面的架構圖,把我們討論過的指標 (SLI) 都標上去 (如上圖)。單純把 5 sec 的過程拆解,大致可以拆成:
{A} + {B} + {C1} 必須小於 SLO (5 sec) 以內。
回到系統的架構,真正有負載需要被監控的系統有兩個,一個是前台(消費者端),從接到消費者的操作到真正發出訊息推送進 message queue 這段時間 (A), 以及非同步系統將訊息從 message queue 取出,交給 worker 處理,直到完成通知第三方服務的這段時間 (C1)。
這兩段是以開發團隊的角度來說,最容易掌握的資訊。如果我們在這幾個時間點標上編號 (1) ~ (4):
(1) 收到 request (2) 送出 message (送進 message queue) (3) 取出 message (從 message queue 取出) (4) 送出 message 至第三方的服務
只要讓開發人員預先在這四個點,都記錄當下的時間,剩下的用計算的就能知道:
{A} = {2} - {1}
{B} = {3} - {2}
{C1} = {4} - {3}
解析到這邊,身為架構師 / 開發團隊的 tech lead, 你應該就能訂出對應的規格讓 RD 完成你的期待了。最簡單的方式,就是挑一套成熟的監控服務,善用他們提供的 metrics API, 將你抓出的數據 ( A, B, C1 ) 推送進去,讓監控服務替你統計、顯示儀錶板、以及在符合景是條件時發送通知給值班人員。
這邊我就不多說了 (這篇我的重點不是要講這些 API 怎麼用啊),我就截錄 Azure Application Insight 提供的 API 範例與規格說明 給大家參考 (如上)。
監控系統當然不只這一套,你可以跟你們負責基礎建設的團隊討論看看,是否有既有的服務,你只要找出怎麼把數據推送進去就好。當你完成這段任務時,上述這些你特定服務內的 SLI 就能直接呈現在 dashboard 上。我就用這個 case, 讓大家看看我們在雙十一各方面流量都是尖峰的時段,讓各位體驗一下我們如何用 AWS cloud watch dashboard 來監控簡訊的發送:
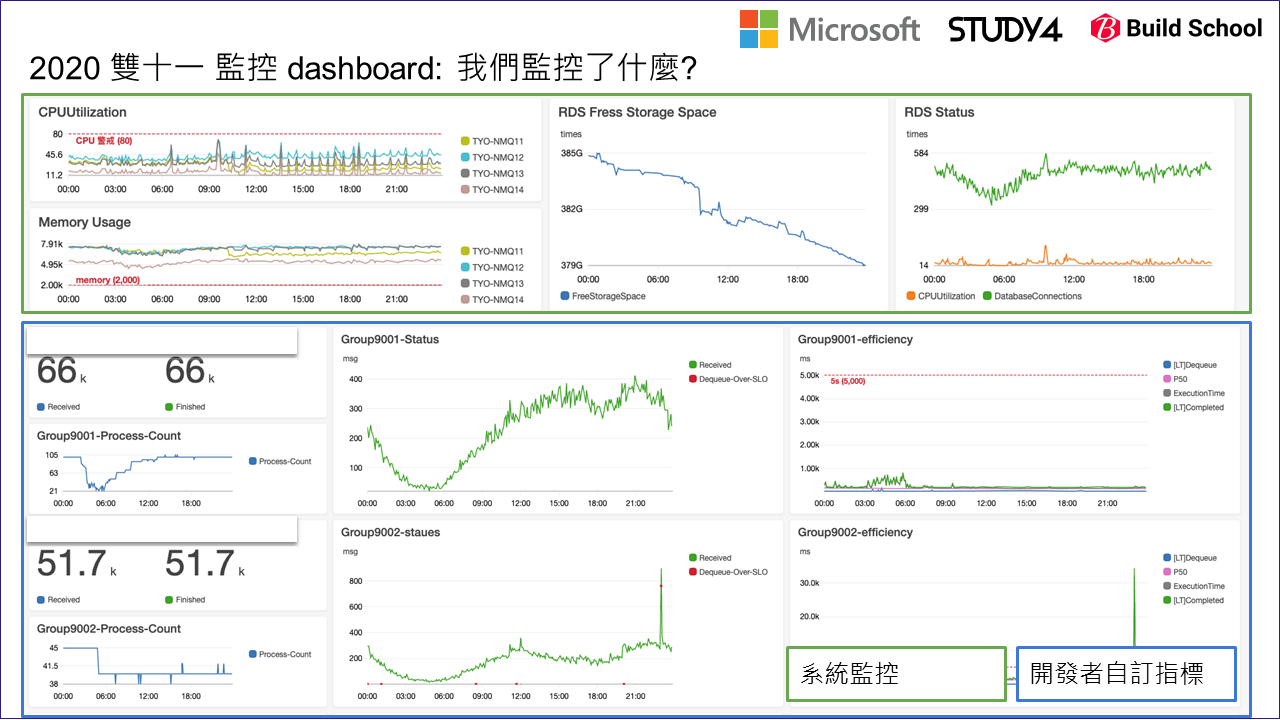
包含系統層面的指標 (例如 CPU / Memory 的使用狀況,Database 的空間以及負載等等),以及應用程式本身的指標 (包含 process pool 啟動的數量、message 接收與消化的數量,message 處理的各個階段數據統計) 都放在同一個 dashboard 方便觀察監控。
至於我們一直在討論的 (A) (B) (C1) 等等指標,我們是如何呈現的? 來看看上述 dashboard 其中一塊,我把它放大來看:
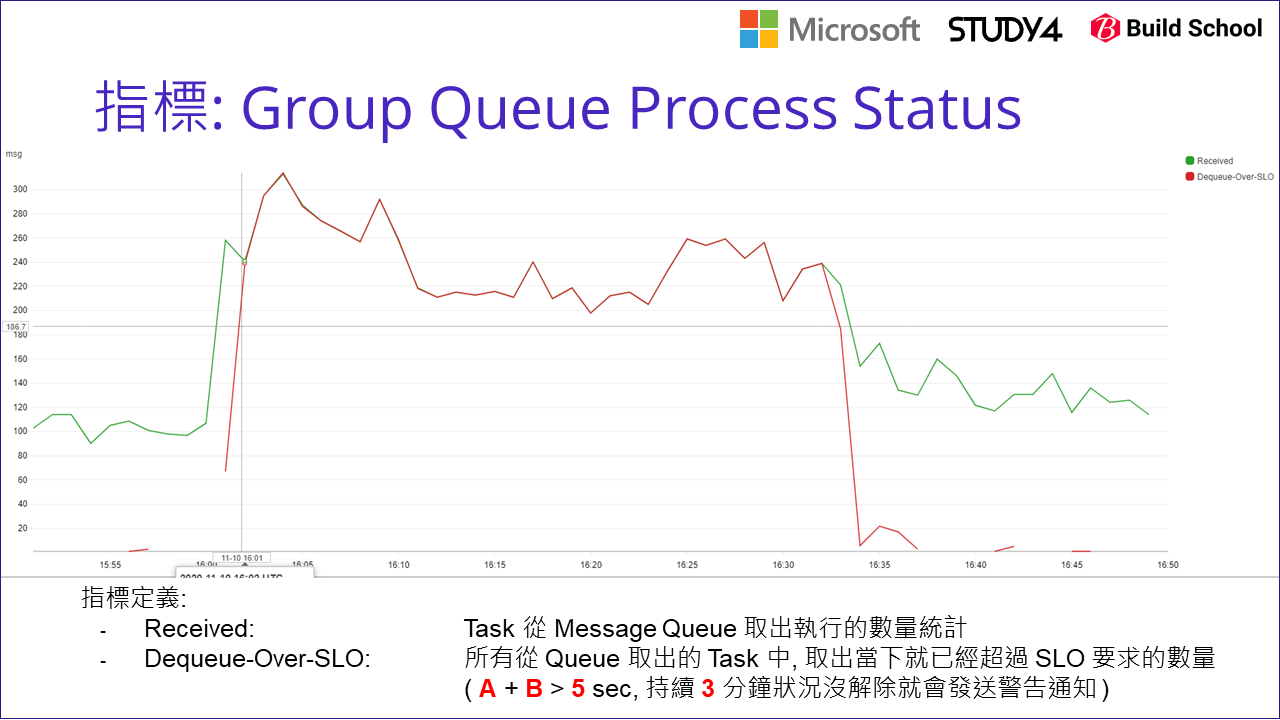
我們把兩個指標放在同一張圖表內方便觀察。其中綠色的指標是 Received, 定義是每個時間區間內有多少 message 從 queue 內取出來執行,簡單的說就是 (3) 的數量統計。而紅線的指標則是指 Dequeue-Over-SLO, 定義是所有 Received 的數字中,有多少是從 queue 取出的當下,就已經超出 SLO 的要求 (也就是 A + B > 5 sec)。
從這張圖,可以理解到,那麼多個 message 都不斷的被處理中,紅色的部分則代表這些 message 還沒被執行,就注定了無法在指定的時間內 (SLO) 被完成,因為光是在 message queue 等待的時間就超過額定 SLO 了啊… 當紅色的指標往上飆升的時候,就代表目前系統已經發生這個案例提到的狀況: 有太多的 message 堆積在 message queue 來不及在時間內被消化,導致塞車的狀況發生,無法及時發送完畢。
如果你的系統已經做到這個地步,那恭喜你,你至少已經可以完全從 dashboard 來掌握你系統的運作狀況了。很多不懂監控的人,只知道從監控系統內拉出一大堆指標出來,看了花花綠綠的各種指標,卻無法精準地從這些指標看出背後的問題,當使用者抱怨系統太慢,你卻無法很快的從 dashboard 診斷出原因立即處理的話,那這整套監控機制等於是白做了。開發人員千萬別只是期待 infra structure 的人員能幫你完成這所有的任務,他們頂多從外圍的資訊,來告訴你系統資源目前的狀況如何 (例如網路延遲、CPU使用率、記憶體剩餘數量等等),告訴你是外部或是內部的問題;更重要的是開發人員要知道內部的運作方式,跟知道內部的指標狀況,你才能判斷瓶頸出現在你程式的哪個環節。要做到這地步,只靠 system 的指標是不夠的,你必須有能力抓出你系統內部的指標,並且自己寫 code 把指標丟出來才行。
2-4, 藉由限制理論 (TCO) 找出對策
我常在舉找醫生看病的例子,都用 “診斷” 這個詞來說明醫生看病的過程。”診斷” 實際上是兩個動詞湊起來的程序: “診” (醫生查看、確認你的症狀); “斷” (醫生判斷當下的病情,決定該如何治療,該開什麼藥方) 兩個部分。前面講了那麼多指標的定義,就是要讓你有足夠的資訊做 “診” 的動作啊! 後面是你要靠你的經驗及知識,加上當下的數據,你才能 “斷” (判斷) 接下來該採取什麼措施來應對。
同樣的,這些只能靠 SOP 嗎? (複雜狀況 SOP 可能列不完),是否有一些背後的理論或是方法可以依循? 有的。這邊我就舉了在管理學上常被討論的 限制理論 (TOC, Theory Of Constraints) 來說明。聽完你就會更清楚為何在當下我能馬上反應該拆開兩個 queue 來解決;甚至我能更進一步的做到不只是監控,讓整套系統能更緊密的整合,做到預測與避免瓶頸的產生。
首先,先來看一張講限制理論常會看到的圖:
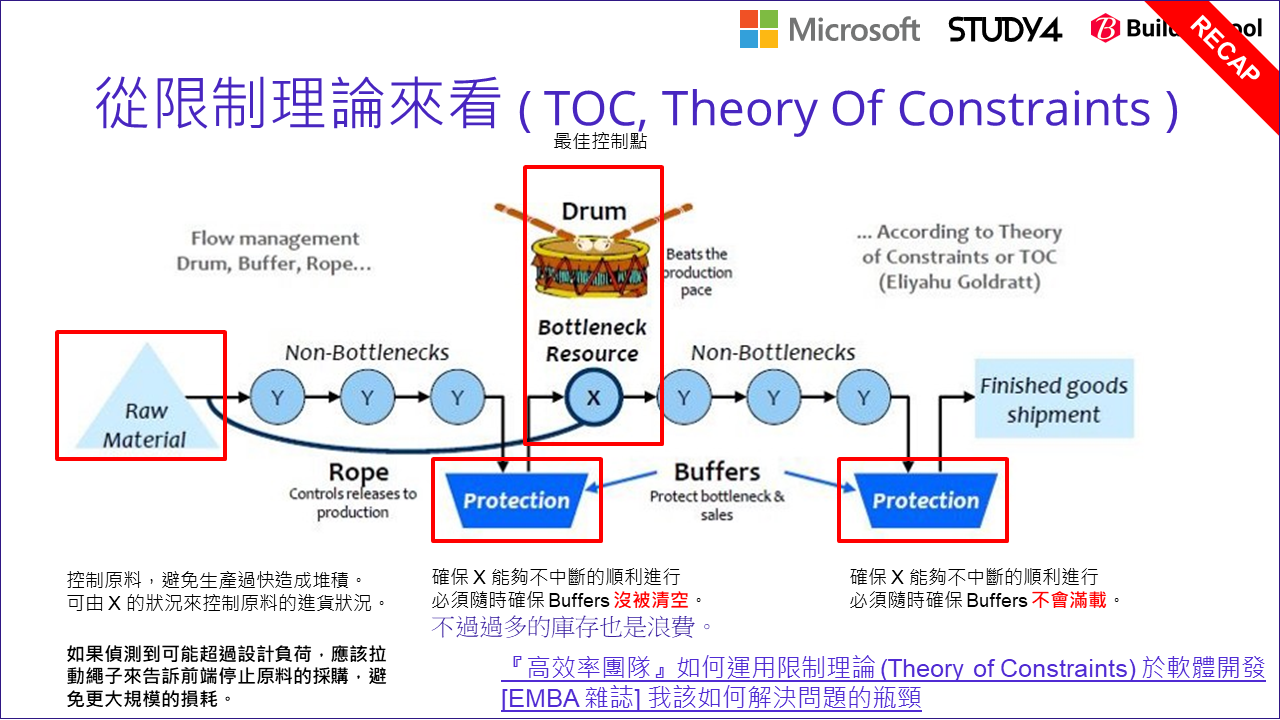
限制理論,說明的背景都是工廠的生產線當例子。我自己對限制理論的理解還很表面,但是掌握基本觀念就已經對解決這些問題有很大的幫助了。我從我的角度把理論跟問題串聯起來,有興趣深入的朋友建議花點時間看一項相關的書籍 (別以為看過我寫的這段就夠了啊,我寫的只是皮毛而已) 我把我認為的幾個重點用紅框框起來了。先來說明一下這張圖,再來解釋 Rope(繩子) 跟 Drum(鼓) 所代表的意義。
我先解釋一下概念跟圖的對應關係。典型的生產線,從 Raw Material(原料) 送進生產線之後,沿路就會經過每一關的工作站 (圖上標示著 X / Y 的藍色圈圈) 加工。加工後的成品就會由輸送帶送到下一站,直到完成為止。完成的產品則會被送走 (Finished goods shipment),不論是直接出貨,或是送到倉庫去。在這整個過程中,需要一些管理跟控制技巧,目的就是要確保整條生產線的效率是最大化的。
限制理論中最廣為人知的一個原則,就是整個生產線裡面最慢的那個步驟,就是 Bottleneck Resource(瓶頸),也是圖上標示為 X 的工作站 (其他非瓶頸的工作站都標示為 Y)。最慢的步驟,限制了整個產線的效率。簡單的說,如果你能改善瓶頸,整個產線的效率就能提升,直到他不再是瓶頸為止。反過來看,如果你讓瓶頸再更慢一點 (不論是有意還是無意的),整條產線也會跟著慢下來。換而言之,控制瓶頸就等於控制了整個產線的效率。因此這張圖就用了 Drum(鼓) 來代表。為什麼用鼓? 就好像軍隊行軍時,部隊的腳步都是配合鼓聲在前進的,鼓手敲打的速度,就控制了整個部隊前進的速度。
那麼,你該如何找出瓶頸在哪裡? 如果 X 是整個產線的瓶頸,那麼在瓶頸的前面應該會觀察到庫存的現象。如果自動化的產線你都有足夠的指標資訊可以觀察,判定哪一關前面的庫存堆積數量過高,那就是瓶頸的所在了。既然瓶頸都已經是整個環節最慢的部分了,你在能改善他之前,你該先做的是想辦法讓他能充分發揮 100% 的產能才是。有時候可能因為各種狀況,瓶頸不一定會出現在同一個地方,這時瓶頸可能會短暫的沒事情做,讓整個已經很慢的產線效率又更往下掉。
預防的方式也很簡單,在瓶頸前一關放置 Buffer (通常是庫存,或是有足夠的空間能保存上一關的產出物),確保瓶頸隨時都能有充足的原料保持運作。由於 Buffer 的作用不只是庫存,更重要的目的是確保瓶頸維持最大的產能,因此圖上用 Protection 來表示。同樣的理由,最後一關要把完成品送走,將完成品送走通常也是個瓶頸 (只是他已經不再產線的範圍內了),所以最後完成品那關也會設置 Buffer, 保護整條產線不會因為運送的貨車臨時塞車,導致整條生產線必須暫停的窘境。
善用 Buffer 的設計,可以讓每個工作站的利用率提高,也降低了各種狀況對整條生產線執行效率的影響。不過, Buffer 的設計總是有極限的,你無限制地堆庫存是沒有用的。前面提到瓶頸的前端最容易堆積庫存,因此由他來判定也最合理。如果瓶頸判定前端庫存的半成品過多,他就該拉動 Rope(繩子) 緊急通知最源頭的 Raw Material 別再繼續把原料放進生產線了,只有從源頭控制才能放慢堆積的半成品繼續增加。
整張圖的控制結構就被勾勒出來了,以 Drum 為中心,前面設置 Protection(緩衝機制), 確保瓶頸的產能達到 100%; 當庫存過高時就必須控制 Rope 停止原料採購,停止前面關卡的生產運作,避免半成品的庫存持續升高到無法控制的地步,直到庫存消化到正常水準為止。這就是整個生產線管理控制的基本作法。
歸納一下整個限制理論告訴我們的,要改善整體效能可以從這幾個步驟著手:

2-5, 將限制理論套用到系統身上
簡單說明過 限制理論 之後,回到我們探討的簡訊發送案例。到目前為止,我們都還是用工程角度在解決問題,完全透過工程師的直覺來改善效能。但是現在我想把這類問題提升成如何用系統性的思考來解決。其中的差別是,我想找出背後問題的模式 (pattern),用更明確的做法一步一步解決,就能導引出正確的 solution. 這件事起頭是困難的,但是一旦我做到了,就能加速後續系統的開發,以及更重要的是系統上線碰到問題後,如何能更快地找出問題,並且解決問題的速度跟門檻。
回到這張圖,我們從幾個指標,來套用限制理論:
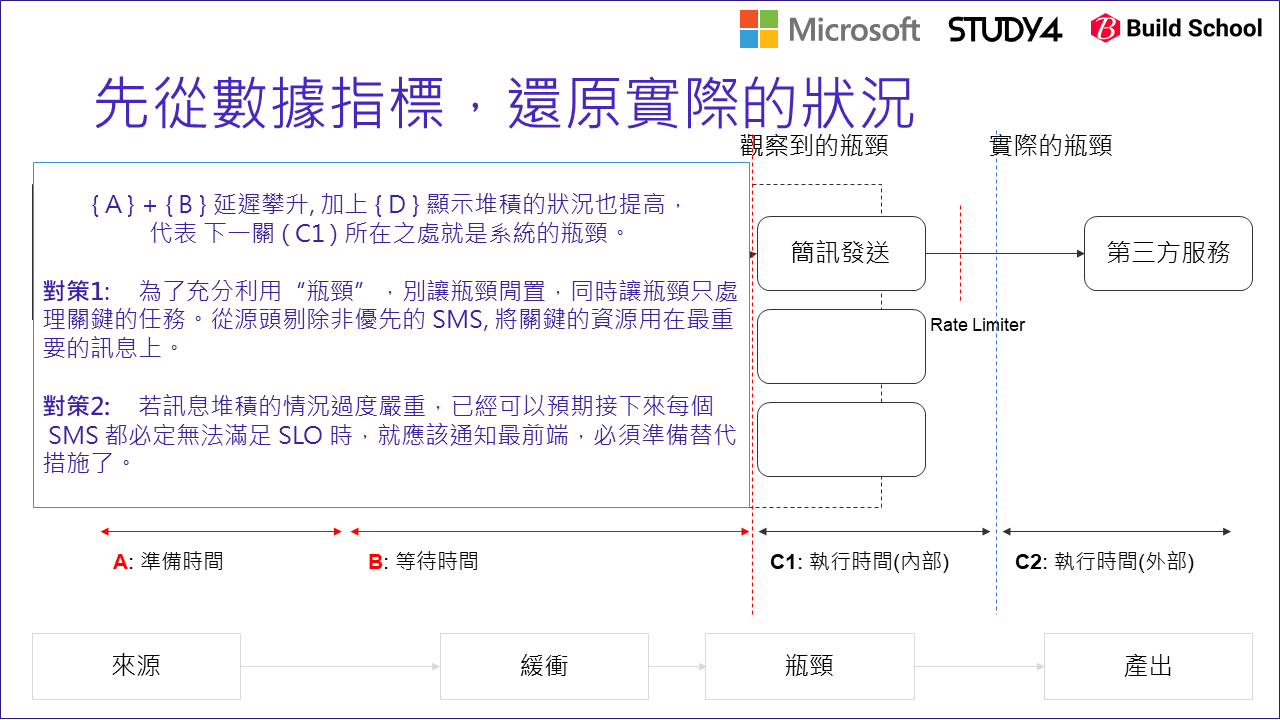
回想一下,真正發送訊息的 Worker 如果是瓶頸,我們會觀察到甚麼? 瓶頸前面堆積的庫存會變多。在這個系統裡,庫存前的 Buffer / Protection 就是 Message Queue 啊,因此 Message Queue 的 Queue Length {D} 就是個觀察的重要指標了。我們該觀察的除了 (A) / (B) / (C) 各階段執行的時間之外,觀察 (D) 也是判定警示的重要指標之一。
當你從監控系統上,觀察到 (D) 過高之後,你該採許甚麼改善措施? 由於瓶頸的資源是寶貴的,所以才有 Buffer 的設計,來確保瓶頸能全速運作。現在瓶頸已經全速運作了 (因為 (D) Queue Length 太高了啊),所以我們得想辦法善用瓶頸,作法是把非優先的訊息排除在外,讓瓶頸效率無法提升的話,就讓他優先生產價值更高的產品 (台積電應該不會拿最先進的製程來生產不重要的 IC 吧 XDD),這就是圖上說明的 “對策1“,也就是前面我們提到分流的做法,把簡訊分兩條獨立的生產線來處理:
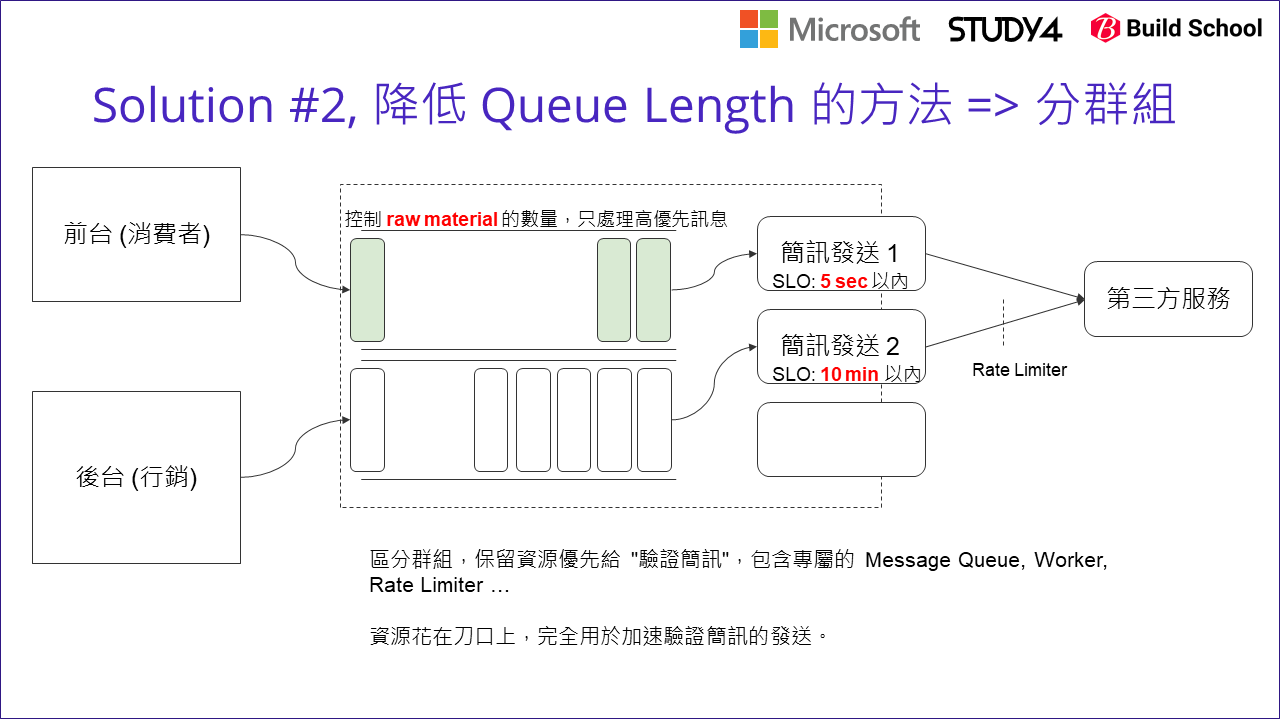
如上圖,調整過後的系統架構,就能更充分的運用瓶頸的生產能力,來處理最高優先的服務了。
2-6, 如果長時間無法滿足 SLO?
接著我們來看看另一種狀況: 假設已經分流了 (對策1), 仍然處理不及,系統塞車到已經不是有幾筆簡訊來不及發送了,而是接下來整個爆滿,所有人都無法在期待時間內收到訊息呢?
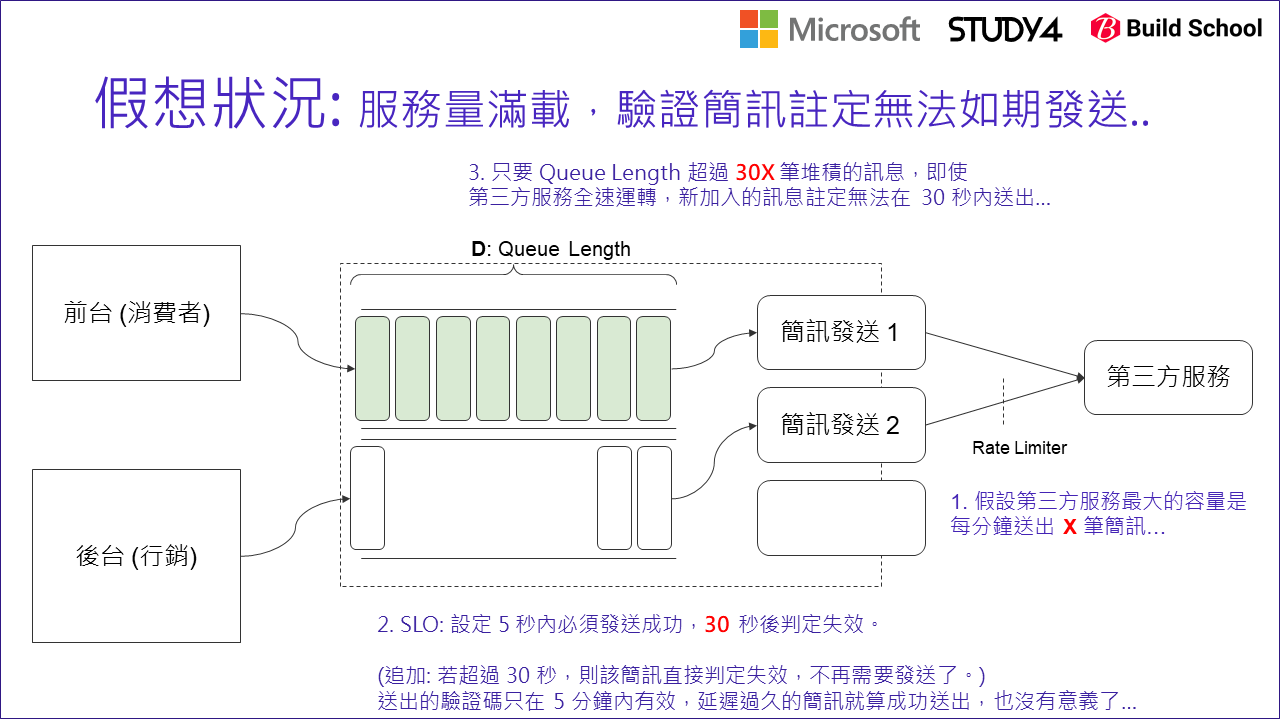
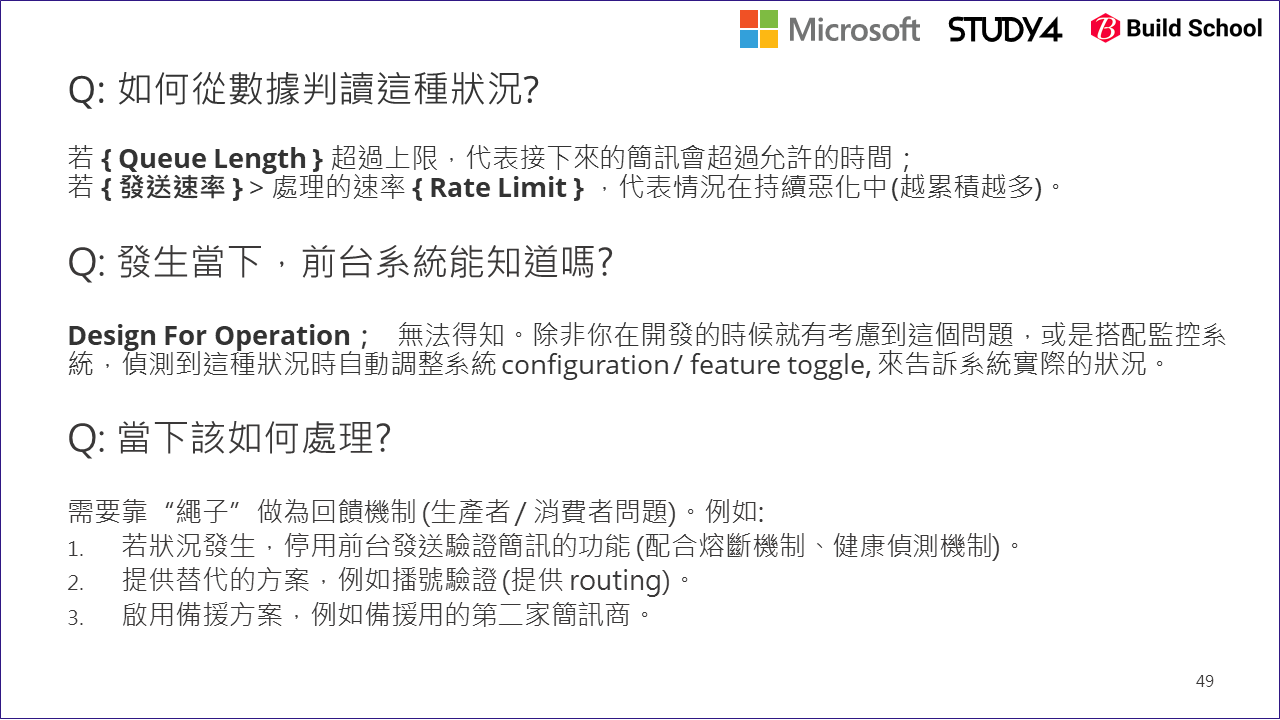
留意一下,在我們這個案例內,認證簡訊是有時效的。如果我輸入電話號碼,從按下確認那一刻開始,5 min 內驗證碼就會失效了,到時你拿著過期的驗證碼就沒有任何用途了。更嚴苛的挑戰是,消費者通常沒那個耐心等五分鐘來輸入驗證碼啊,一般情況下超過 30 sec 大概人就放棄了。這在系統內代表另一個意義,在生產線內的原料是會過期的,想像一下如果這是食品的加工廠,生產速度太慢的話,可能最後你做好了,食材卻已經酸掉壞掉了,等於大家都白忙一場。因此你必須按照 (D) 來判斷,如果現在狀況下已經快要趕不上過期之前送出訊息 (如何判斷後面說明),你就該拉起繩子通知前端了。
系統的角度,通知了前端能幹嘛? 假設目前狀況大家搶著註冊,每個人註冊都需要等 30 sec 以上才收的到驗證碼的話,前端繼續開放註冊已經沒有用了,因為後來才來註冊的人,註定會超過 30 sec 才能收到驗證簡訊,而這時間超過消費者的忍耐極限,在那之前就會放棄,即使收到他也離開畫面不再註冊了,而這些已經沒用的簡訊還堆在 queue 裡面,繼續卡住後面的驗證需求…
如果前端能事先知道,目前狀況已經滿載了,也許產品經理 / 工程師就能先準備備案了啊! 例如改用第二種驗證方式,像是電話號碼撥號驗證 (你用你的手機打指定電話號碼,由 server 端透過來電號碼確認你確實擁有這支電話),也許成本較高,但是至少不會讓狀況惡化。或是更強硬的作法,就在畫面上顯示請使用者稍後再試…。這就對應到了圖上說的 “對策2“,也跟限制理論的 繩子 是同樣的解決方式。
要能做到 “對策2“,你必須對指標要能有更精準的掌握。拿這個例子來說:
- 你必須先掌握你實際的處理速度 (每秒能發送幾筆驗證簡訊)? (如上圖的紅字 X)
- 目前有多少訊息還在排隊等著發送? (如上圖的 (D), queue length)
- 延遲超過多久還沒發送,訊息就沒有發送價值了? (如上圖的紅字 30 sec)
回頭來看看這些指標怎麼取得吧! 通常 處理速度 X 不一定要用計算的,你可以用先前壓測,或是規格得知。這樣可以簡化一點,就是當作設定 (configuration) 就能解決了。如果你想要更精準一點當下計算,統計一段區間的處理量也可以。不過在這邊我就當作你可以事先掌握。
接著,(D) Queue length 只要你有埋設正確的指標,或是成熟的 message queue 大概也都能提供 API 取得這些資訊,我也當作你已經可以再當下掌握到這數字了。
最後,服務允許的最大延遲 (30 sec),這也是當作設定放進系統就行的數值。這數字其實是從商業的需求來決定的,一定是系統外部來的,不用考慮太多。
三個關鍵數據都能掌握了,那剩下的就是簡單的計算了啊! 你只要用這個判斷式,就能知道推算當下要發送驗證簡訊的話,要花多久才能送出去:
(預計發送延遲時間 sec) = (Queue Length) / (發送速率: messages / sec)
當這數字 > 30 sec 就該發警告了,同時也該拉動繩子了。拉動繩子的方法,有兩種做法可以參考:
- 系統提供 API 取得 (預計發送延遲時間),由前端自行判斷
- 由監控或後端服務來處理,當延遲時間超過預期,就自動觸發 feature toggle, 關閉部分功能阻止註定無法成功的需求繼續流進系統
這些過程,也就是這頁投影片要表達的內容,我貼在這裡:
2-7, Case Study 小結
寫到這裡,其實我已經把整個系統服務水準背後的處理概念都完整交代過了。工程師們往往都把注意力放在如何把功能做出來? 但是講到服務水準 這件事往往要求的都是另一回事啊,這就是典型的開發軟體跟開發服務的差別,也是整個軟體開發團隊成熟度的差別。
我自己服務的公司,就是以提供服務的角度來開發系統的,也是大家常聽到的 SaaS (Software as a Service), Software 跟 Service 之間的差異,絕對不是只有你自己準備機器把你自己的 Software 裝起來那麼簡單而已。既然客戶用的是你提供的 “service”, 你就該有義務提供夠好的 Software, 同時也要用夠好的 SLO 讓客戶使用你的 Service 啊! 這時 SLO 就變成服務夠不夠好的 “規格” 了。這整篇就是在告訴你,如何將服務水準變成規格,同時要精準地達成規格的要求,背後整個架構設計的思路跟做法。
如果你有耐心看到這裡 (抱歉我的題目沒寫這麼長都交代不完),你可以試著想想,在過去開發的過程,你花了多少心思在照顧 “服務水準” 呢? 如果沒有,系統上線後碰到服務水準相關的問題你都怎麼處理? 你心裡是否都有對策? 還是網站流量太大,乘載不住,加開機器也沒用的時候,你只能雙手一攤告訴老闆你盡力了呢?
如果是的話,花點時間研究一下我這篇分享的過程,甚至讓你們團隊 (從 Product Owner, Stack Holder, Tech Leader, Team Member) 都一起來討論這整個過程。我相信這樣你們團隊會更有能力去面對服務水準的要求。
3, 其他跟 SLO 相關的進階議題
寫到這邊,我大概把我想講的主軸都交代完了。不過,整個過程中有幾個蠻重要的分支我還沒交代到,我就把他歸類到進階的議題了。
談到 SLO, 我還是必須強調,所謂的 “服務水準” (Service Level), 絕對不是只有講求 “效能” 或是 “流量” 而已。以前面的驗證簡訊當作例子,我談的都不是如何從一秒發送 1000 則簡訊提升到 5000 個簡訊這種議題,而是我在探討怎麼 “確保” 我的系統能在 5 sec 內把每一則訊息發送出去;在做到這個要求之後,再來追求如何在這 “服務水準” 的前提下,做到每秒 1000 則,甚至更高的數字。
只有先維持 “服務水準“,再提高整體流量才有意義啊,否則量做起來,但是每個人得到的服務都不夠好 (都無法在 5 sec 內收到訊息) 是沒有用的。講白話一點就是 “質” 跟 “量” 的差別,兩者必須兼顧。只是我想辦法用更具體一點的方式來描述 “質” 這件事而已。
接下來有兩個延伸的進階議題,就是在這前提下延伸出來的。我就個別針對這兩個主題來探討:
- 成本問題: 你願意為 “服務水準” 付出多少成本?
- 如果有多個 “服務水準” 期待是互斥的,無法同時滿足時,你如何取得平衡?
3-1, SLO 背後的成本問題

前面在講分流的時候,提到單純 scale out 的缺點,就是我為了服務水準額外加開的機器 (費用),不只改善了驗證簡訊,也同時改善了行銷簡訊的發送。不過加開機器背後是有成本的,把費用也考慮進來,問題就變成 “你願意也替行銷簡訊提高 SLO 花同等的費用嗎?”
如果不是,那麼這個段落就是你該探討的。不過這個主題我只會點到為止,當時這場演講只有 50 分鐘,其實放不下那麼多內容了,這篇文章的篇幅其實也有限 XDD,我就把我對這問題的重點摘要說明一下就好。面對 “費用” 的問題,我的處理框架還是同樣那句話:
你要先能量測 (measurement), 你才能改善 (imporovement).
也因此,面對 SLO,你除了掌握前面講的那幾個 SLI 指標之外,請務必把費用相關的指標也一起納入考量。同樣的,也許在某些場合下,費用會變成瓶頸之一,你也應該要用有系統化的思考方式去處理。
在我們團隊的運作方式,比較特別一點。我們統一由架構團隊 (也就是我負責的部分) 統一維護這整套非同步任務處理的機制,因此上述談到的各種指標 ( A, B, C1, D 等等 ) 都是統一由我們開發整合,並且收集資訊監控的。而 Worker 的部分則是我們開出規格,各個團隊自行實作的。為了改善服務水準,同時又要符合經濟效益,我們也把每種任務背後花費的運算費用也納入 SLI,用同樣方式管控。
也因為這樣,我們才會在第一時間就留意到最早的解決方式 (單純加開 worker instance) 並沒有把費用花在刀口上。因為就簡訊的數量來說,驗證簡訊遠遠低於行銷簡訊啊! 但是當我們發現在尖峰時刻,要把機器開到夠,花費的費用遠遠高出想像 (因為費用有納入監控才會立即發現),我們也才能很快的反應到要把費用花在刀口上這件事。
不過費用這指標的取得,對我們而言不是那麼容易啊,因為費用通常是落後指標,你用了之後雲端服務商才會在記帳週期統計好給你 (簡單的說收到帳單之後才知道)。因此我門其實適度地把這些指標簡化了,我們開始不用絕對的費用單位 (例如: 美金 USD),而是改用相對的單位 (例如: 1 core / 2GB ram / 1 hour 當作 1 單位 的計算費用) 來監控。我的目的不是為了自己算帳,而是為了瞭解費用的起伏,因此相對單位就夠了,重要的是要能監控,夠即時反映現況我們才能即時做出修正。
也因此,我們用了很陽春的方式來統計,例如規範所有 worker 用的規格都維持一致,約束在有限的幾種選擇之內。開機時間我們也捨棄真正 infrastructure 的開關機時間,改由 application 的啟動時間替代。中間一定會有誤差,也會有換算的問題,但是換成這樣的指標,有助於我們對 SLO 的監控與整合,只要搞清楚目標,你就不會把他跟真正的費用搞混,效益會更明確,相對的也更不容易誤用。
這部分我們還在努力中,不過因為想清楚了,因此我們也歸納了幾個推動的目標,分別由不同角色的團隊認領:

-
(Infra) Infrastructure / Platform:
架夠團隊應該要想辦法降低維持 SLO 所需要的 COST.
舉個實際的案例,在 .NET Conf 2020 我們團隊另一位成員 Steven Tsai 講的主題 Process Pool, 就是如何管控 process, 安全可靠的提高 VM 的使用率,就是在這樣的出發點下開的案子。這個場次沒有錄影,不過主辦單位有提供投影片下載,我過去也 寫過一篇文章 說明這個主題,有興趣的朋友可以參考。 -
(Dev) Business Logic / Application Developer:
決定應用程式的設計,與配合改善的決策來改寫你的應用程式。舉例來說,前面提到當你已經可以預測現在送出的驗證簡訊,註定無法在 30 sec 內送出去的話,那你在當下可能連發送都不想發送了。這些功能一定要在最源頭的地方實現,源頭不處理的話你已經堆進 message queue 後就注定會影響到後面了,再怎麼優化也是效果有限。這時限制理論講到的 Rope 的用意就很明確了,我們要建立起溝通管道 (Rope),讓 (1) 跟 (2) 的兩個團隊能透過這溝通管道協作,才能達到最好的效果啊。 -
(Ops) Operation Team:
並不是所有團隊的開發(Dev)跟維運(Ops)都是同一組人啊,有時即使是同一個團隊也會有不同負責人。我這邊把負責維運的角色獨立出來,當你已經有能力改善個別問題時,以前面的例子你已經有能力加開機器就改善 SLO 時,最後平衡 SLO 跟 COST 的角色就由 Ops 來負責吧! 前提是這些關鍵資訊都已經被量化,有明確的指標,並且集中在同一個監控系統或是資料來源。取得與比較這些指標的變化要夠容易,你才能夠在日常維運過程中看出端倪,才有空間隨時發現隨時改善。

我這邊就舉個例子 (數字我隨便掰的,只是為了方便討論而已)。我把不同要求的 SLO,跟對應的費用做個比較,然後你就能夠再這些方案之間做出取捨。前面談很久的驗證簡訊,原本定義的 SLO 是 5 sec 內要發送出去 (左)。試著想看看,如果你想把他提高到 1 sec 就要發送出去 (右),到底要花多少錢?
過程當然要做某些程度的效能測試,如果測出來的結果如這張圖所示,你就能讓你的老闆清楚知道品質與費用之間的關聯了。為了從 5 sec 進步到 1 sec, Message Queue 你也許需要開到高一級的規格,需要 3 倍的費用… 各方面的費用也都等比增加。其中留意一下 Message Worker 的費用。單純按照比例來算,你也許需要開到 5x 的 worker, 但是如果你願意花些功夫做好優化 (例如前面提到的 process pool), 你就有能力控制某些項目的費用了。
做好這件事,另一個附帶的效益是: 身為技術決策的人員,你也可以更清楚的交代這些技術專案到底能帶來多少價值? 花了兩個月來處理 process pool, 如果能提高 5x 的 SLO, 但是只花費 1.2x 的運算費用… 加上老闆也知道目前這費用的基數,衡量之下老闆也許就會更支持你做好架構的改善了。如果效益夠明確也夠吸引人,甚至他的優先順序會凌駕於其他的功能開發。能做好這件事,對團隊對公司對客戶而言都是件好事啊! 身為技術決策者 / 架構師的價值就在這些地方。
這主題我就聊到這裡,最後用一張圖把前面的幾個重點表達這些數字的關係:
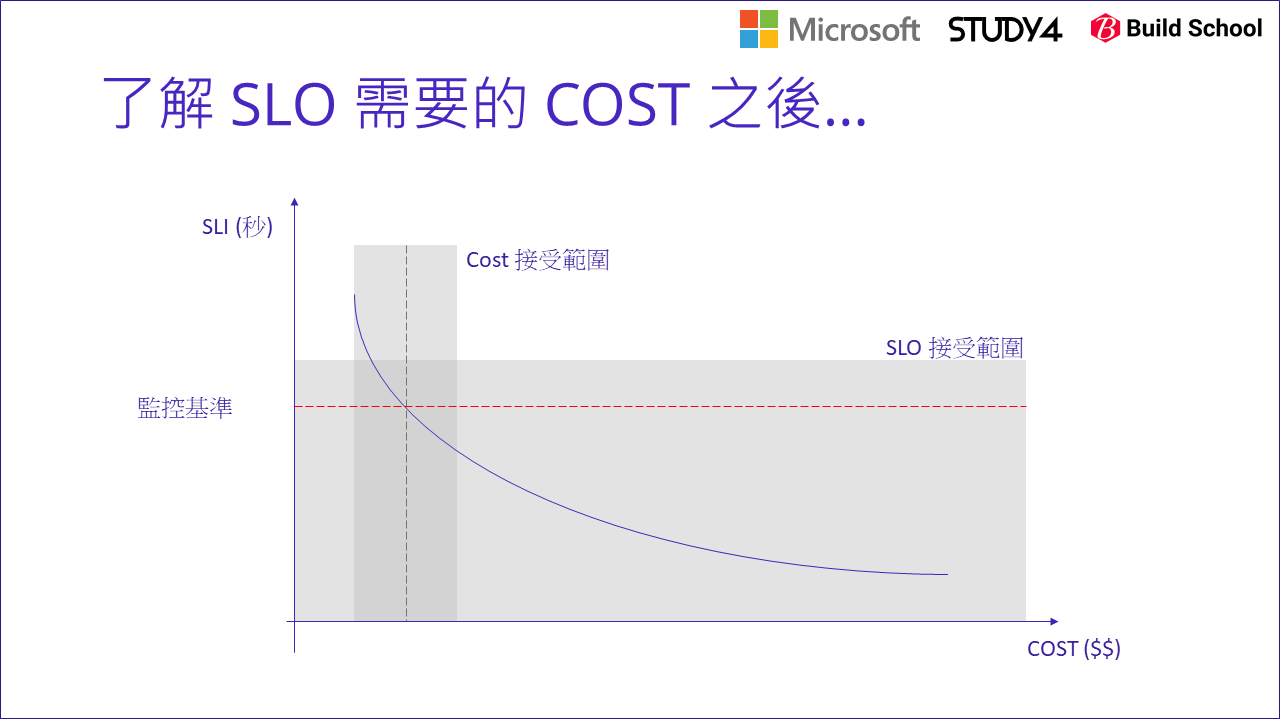
當你對這些指標跟 SLO / COST 的關係夠清楚之後,你應該能掌握 SLO 跟 COST 的關係吧! 當你能勾勒出這關係時,找出 SLO 跟 COST 各能接受的範圍 (通常是商業面的考量,找你的 Product Owner 去跟 Stakeholder 談清楚吧),兩者的交集就是你能夠努力的空間。弄清這對你有甚麼好處? 也許這樣你就知道你根本不需要考慮 SLO 1 sec 的情況 (因為太貴了 XDD),所以你可以集中精力去找如何把 SLO 優化到 3 sec 範圍內的解決方案就行了,某種程度也是讓你能更精準的抓出技術目標。
另一種情況是: SLO 已經無法選擇了 (就是要 1 sec),這時你的目標也很明確,你必須想辦法在 SLO 為 1 sec 的前提下,想辦法做各種的架構改善,把 COST 壓到能接受的範圍內。如果費用指標也很明確,那你的目標就更清楚了,例如你必須把原本要花費 10 單位運算資源 ( (1 core + 2gb memory) x 10 ) 優化到 3 單位運算資源就能完成。這時不管你用什麼方法改善,至少最後是很清楚就能驗證的。
以上都不完全是技術議題了,比較多的都是技術決策,決策的背後你必須平衡技術需求,商業需求與執行成本之間的抉擇。這些都不是容易的事情,當你責任範圍越大,你越需要考量這些問題。
3-2, 多個任務競爭有限的資源(瓶頸)

第二個進階議題,來談談另一種 SLO 吧! 前面談的 SLO 是完成時間 ( 5 sec 內要完成 ),我舉了另一個形式的 SLO: 使命必達,這也是另一種例子。有時候你要做的不是讓速度變快,更重要的可能是讓某件事別跑太快,確保資源能保留給更重要的任務使用。當這資源是有限的,除了需要互相競爭或是分配之外,更糟糕的是他同時是多個生產線的瓶頸。
舉例來說,如果你玩過網路設備,有些網路設備有支援 QoS (Quality Of Service) 也是類似的例子。由於頻寬有限,同時內部有多個服務都需要搶奪頻寬來做事,這時限制不重要的服務使用頻寬 (例如: BitTorrent … 慢一點仍然可以用的服務), 把頻寬保留給必要的服務 (例如: Online Game, Video Conference, Streaming… 這些都是頻寬不足就不能使用的服務 ) 是很重要的。沒有管理好就會面臨單一服務搶了過多資源,可以執行的很順利 (例如 BT 開了上千個 connection …),結果影響了關鍵的服務 (例如交易) 沒有足夠資源可用。這時網管就必須善用 QoS 的機制,確保每個服務都能分配到合理的資源,目的是讓整體 (全公司) 的服務水準最大化。
這邊我想聊聊的是: 局部最佳化 vs 全局最佳化 的差別。我們往往會埋頭做局部最佳化,而忽略的全局。更糟的是你何時才會發現你忽略了? 通常都是有更大更嚴重的問題爆出來了之後 XDD。我試著用前面探討的整個過程,用在另一個案例上,讓大家理解局部最佳化做過頭可能帶來的副作用。這個案例也說明了限制理論的另一個面向: 當你找出瓶頸你就能夠控制整個生產線的效率。改善瓶頸就能提升效率,但是有時候你必須讓他的效率降低一點。這時限制理論告訴你的知識你就能派上用場了。該怎麼控制? 很簡單,你找出瓶頸,讓他再跑慢一點就好了 XDDD
我們把案例的場景,從發送驗證簡訊改成線上交易。線上交易成功後,通常後台還有一連串的任務要處理,例如發出單據等等內部財務流程。這些都很重要必須使命必達的,但是由於他跟前端消費者沒有直接關連,因此我們不需要計較 5 sec 這種等級的 SLO,也許是 5 min 內完成都可以。相對於完成時效,也許確保他能安全可靠的執行完畢會更重要。然而,當你你發現你交易後的處理的狀況開始出現瓶頸,效能不如預期時:
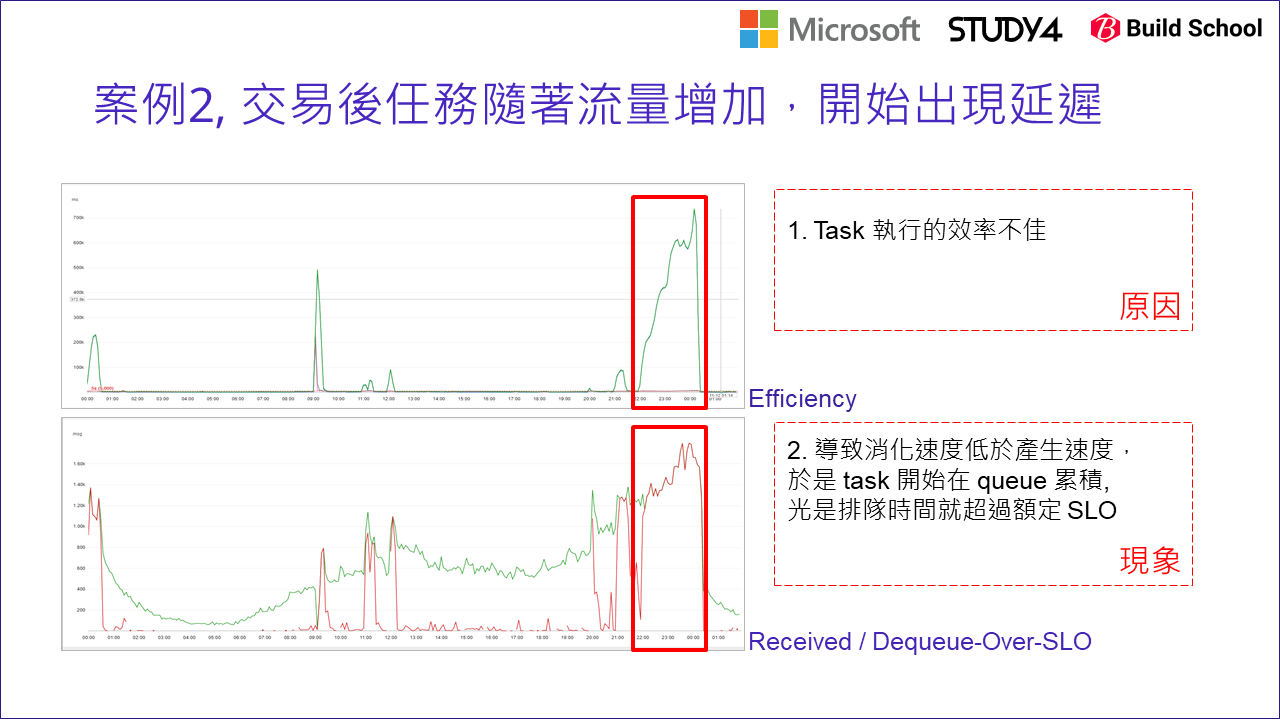
然後很理所當然的,你就按照前面的方式監控並改善….
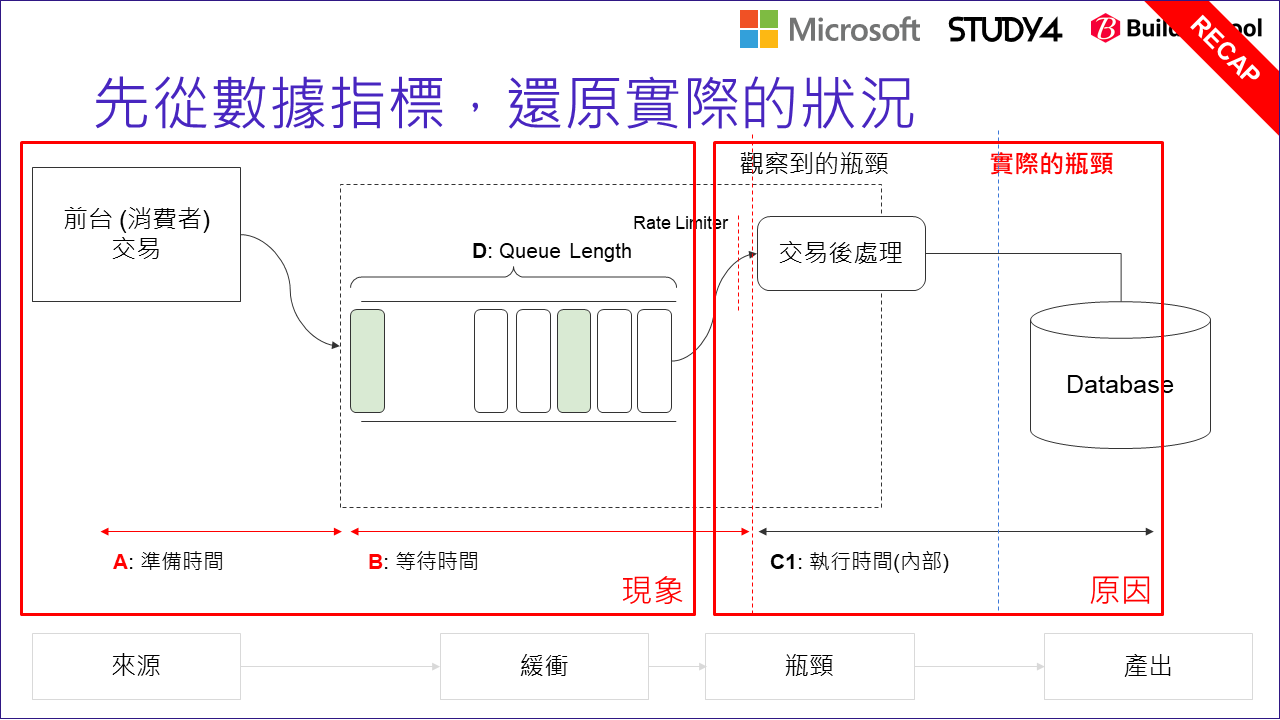
但是,有時瓶頸出現在你觀察不到的地方啊! 以上圖為例,真正的瓶頸 (這是事後才知道的) 是在最後面的 database, 但是因為指標沒有涵蓋到這段,因此我們看到 (D): Queue Length 變大,誤以為 worker (交易後處理) 是瓶頸… 於是就執行了一連串的優化 (例如 scale out), 直到…
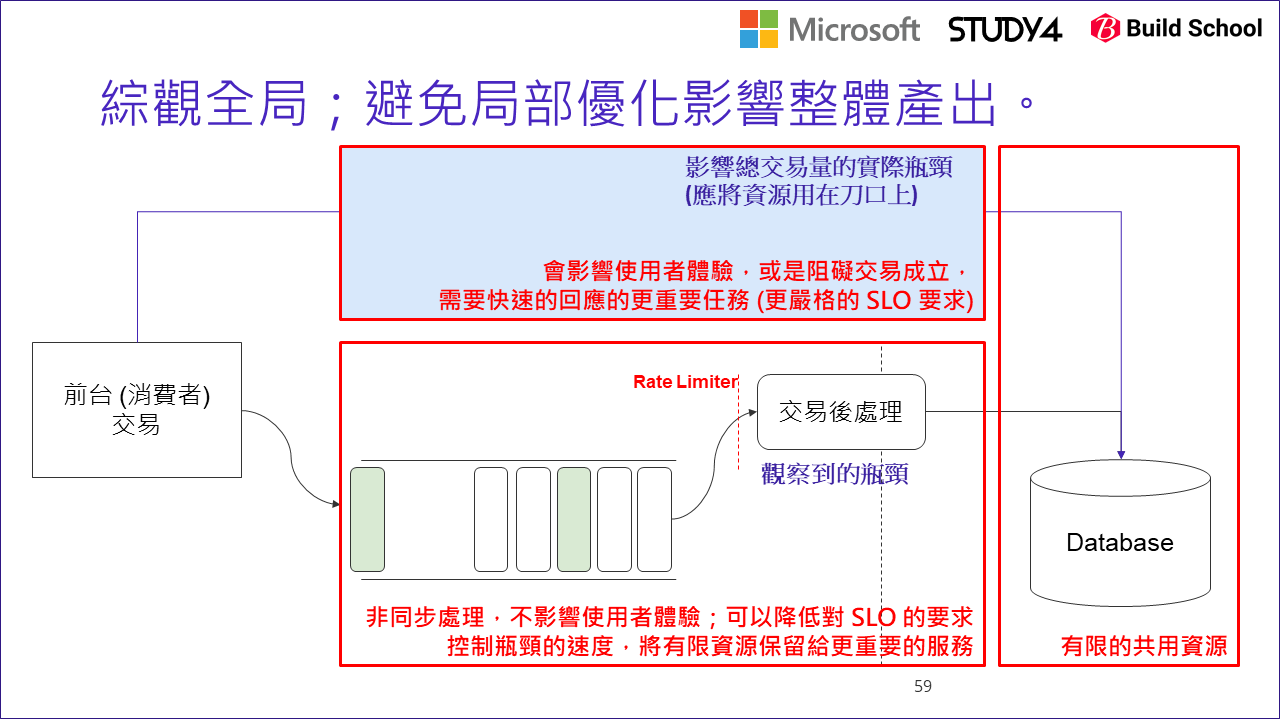
當你持續優化 “交易後處理” 的 worker, 單位時間內處理量自然會提高,同時也會加重 database 的負擔。當你沒有同步擴大 database 的資源,或是對等的也對 database 做最佳化時,處理資源有限的 databases 花更多資源處理交易後的處理任務,可能會間接的影響服務前台的任務,這部分可能更嚴重的影響消費者的交易…
當你沒留意到這一步時,惡性循環就會出現了。交易量增加 –> 交易後處理量增加 –> 交易後處理 scale out –> 資料庫負擔增加 –> 影響到交易量 … 這循環最後的結果是,整體系統交易量下降了,但是系統還是很忙碌並沒有變輕鬆,因為資源沒被合理分配,用在沒那麼重要的環節了。這時局部的最佳化,並沒有替整體業績帶來改善.. 這就是失去平衡的結果了。
當然把 database 切割也是個好作法,但是需要的時間、人力以及成本也都是不同數量級的解決方案。在還沒準備好投入這些資源之前,你該做的就是前面講的: 你該想辦法控制你的生產線 (這邊指的是交易後處理),讓他跑到理想的速度就好,這個速度也許會低於目前執行速度,你就該想辦法替他降速。當你找到瓶頸在哪裡時,降速就變得很容易了。以我們的例子,我們就簡單的在 “交易後處理” 的 worker 加上 Rate Limiter.. 怎麼替你的應用程式做 rate limit ? 很簡單啊,你研究過 QoS 的演算法之後,自己實做其實很簡單的。同樣的當年我也寫過一篇類似的文章,有需要的朋友可以參考: (微服務基礎建設: 斷路器 #1, 服務負載的控制)[/2018/06/10/microservice10-throttle/]
回顧一下前面在探討限制理論的幾個做法:
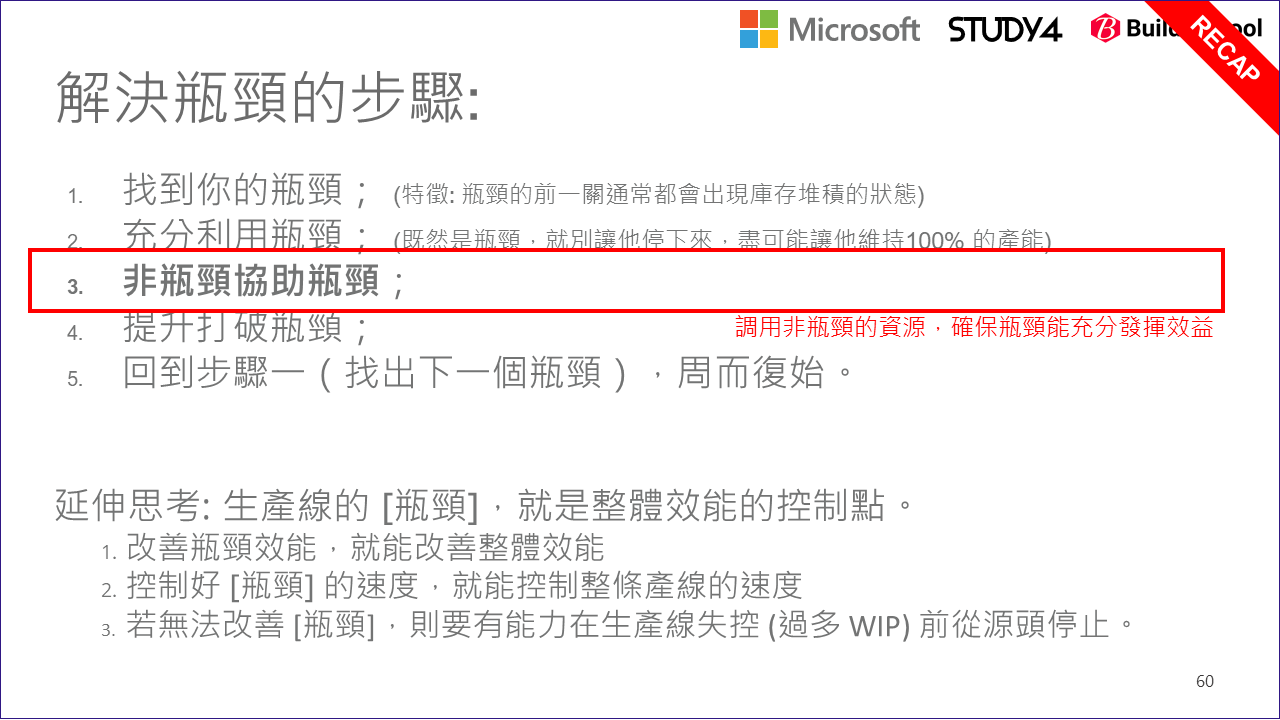
這時,非瓶頸協助瓶頸 這準則的效益就出來了。幫助的方式很多,讓出資源給他使用也是一種做法。
這個主題我也在這裡總結一下,別過度專注於局部的最佳化。回頭看一下限制理論的那張圖,實際生產線可能不是那麼單純,就一條路從頭到尾跑完就結束了。也許主線某個流程需要的原料,就是另一條生產線提供的啊! 因此實際運行的系統關係可能更錯綜複雜。這時適度的抽象思考是必要的,除了瓶頸前需要 Protection 設置 (buffer) 之外,有留意到嗎? 最後完成的地方也有設置 Protection, 而 Drum 也會有 Rope 連接到源頭 Raw Materials… 意思是你考量生產線的效能時,至少要同時關注這三個環節:
- 自身流程內的瓶頸 (Drum)
- 流程的來源協調控制 (Raw Material)
- 流程的終點協調控制 (Finished goods shipment)
這個案例,其實帶入了兩個不同層級的瓶頸啊,一個是自身流程內的 “交易後處理” worker, 另一個則是共用資源 database, 當你解決了眼前的瓶頸效能後,第二個瓶頸開始浮現出來,變成整個系統的新瓶頸了。理想的情況下是你不斷地解決眼前的瓶頸,總有一天就能夠提升整體系統的效能啊! 不過這個案例,我則著眼在眼前的瓶頸已經解決後,浮現的新的瓶頸還沒辦法解決前的這段時間處理方式。我的應變方式是要從整體考量,眼前的瓶頸一次解決最好,不一定是整體最佳解。這時與其讓他全速衝刺,還不如調整成最佳速率。
4, 總結: 改善 SLO 就是落實 DevOps 的精神
總算把這個場次講的內容,完整的交代完了。沒想到嘴巴講 50 min 可以說完的內容,我寫文章竟然花了三個月 XDD, 不過我自己依然是喜歡用文字的方式來說明,文章發布前我可以不斷地來回檢視,修正調整,有助於我把整個內容組織的更有條理一點。在台上就完全靠臨場反應了。常常碰到 slides 沒有寫的東西,在台上一時也漏掉了,因為時間因素,也沒有回頭修正的機會,一些我覺得不錯的觀念就無法補齊了,而文章就沒這種缺點。
回到這篇的主題: 服務水準 SLO 的管理,我還是要把他回扣到 DevOps 的精神。我一直覺得你把 DevOps 的循環做好,把 Ops 的需求或是問題,也當成 Dev 的回饋,很自然地就會留意到這些服務水準的問題了。當你在日常運作過程中不斷地面對這些回饋時,自然就會想找出一些更系統化的方式來面對這些問題,最後就會變成我這篇要說明的主題了。
最後,我用這張圖來說明,DevOps 的循環,怎麼跟這篇講的 SLO 扣在一起:
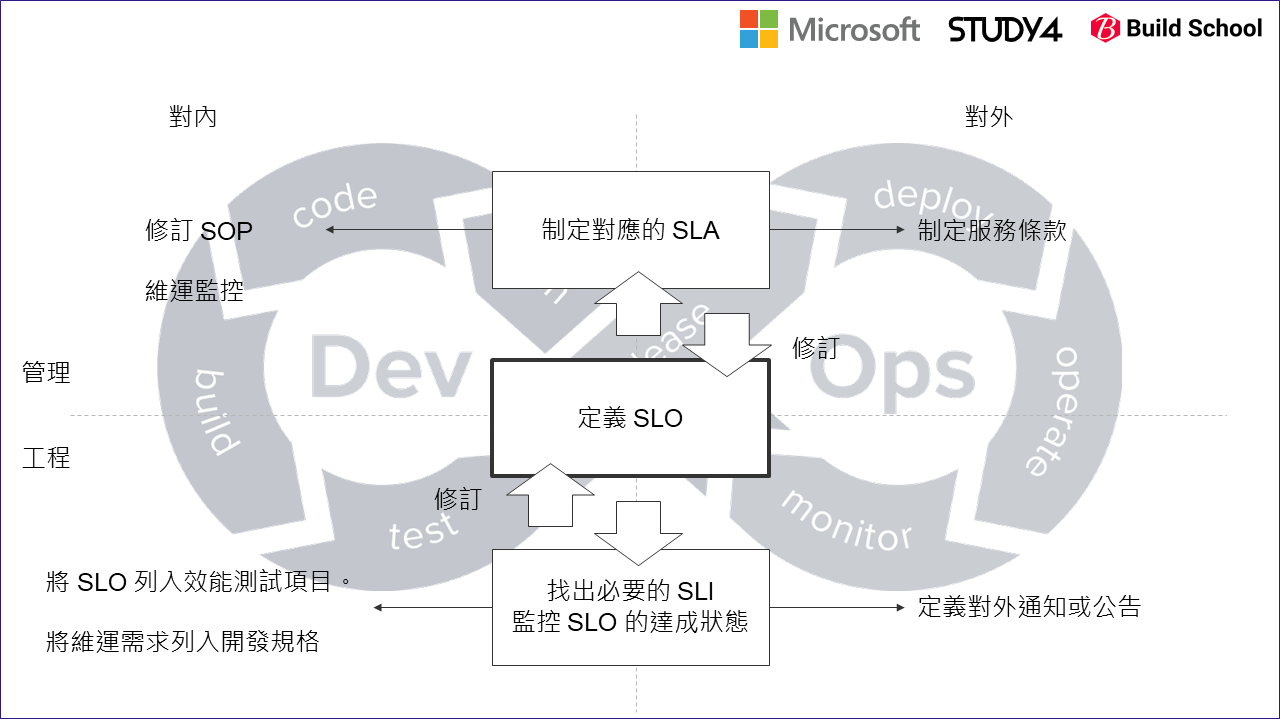
這張圖是我自己畫的,背後的核心概念我是這樣表達的:
-
我把 DevOps 的循環 ( 背景的 8 字型的循環 ) 當作背後的精神:
服務水準的改善當作執行的流程套用上去。所有跟服務水準相關的議題,我一律以 “目標” (SLO) 為核心,先定義出你的服務水準目標到底定在哪裡? 要訂多高? 把定義跟目標抓清楚之後,中間的 “定義 SLO” 夠明確清楚,就能往上下擴展了。 -
我把 SLO 當作團隊顧好服務水準的核心,上下左右分為四個象限:
X 軸區隔的是對內與對外;圖的右邊是對外部 (使用者;客戶;業務單位) 要在意的地方。而 Y 軸則是區隔工程與管理面向的觀點。往上是管理的議題,往下則是工程與實踐的議題。
往上,面對的就是管理任務。以 SLO 為基礎,制定服務的 SLA。還記得 SLA 是什麼意思嗎? 這是對外 (客戶) 的服務條款,你提出系統應該達成的服務水準 (SLO) 後,附帶的保證,當你無法達成 SLO 時你會有什麼措施? 事後會有什麼賠償條款等等。這些都必須要先顧好 SLO 你才能夠推行下去,否則你只是簽了一張空頭支票,列了一堆保證你卻不一定有能力履行合約上的條款。 SLA 制定好之後,對外就是給業務單位列在合約內去談案子了;對內就應該要為了能履行 SLA 的內容,開始檢視修正服務的 SOP,確認團隊有能力充分達成 SLA 的約定。為了確保團隊不會在服務水準上有任何風險,按照 SLA / SLO 上的約定事項做好維運監控的任務是必要的。
往下,面對的就是工程的挑戰了。為了確保系統服務水準能符合 SLO 的要求,你必須將 SLO 拆成多個指標 (SLI) 的組合。找出來的指標就要想辦法在系統層面完成整合。以這篇文章花最多篇幅說明的 “發送驗證簡訊” 這個案例,我們就列了 (A) / (B) / (C1) / (D) 等指標,來判定 SLO 的狀況是否能達標,依據這個來定義 API, 預警, Alert, 監控等等任務。
過程中,不見得所有指標都有現成的,因此如何取得 SLI 的要求,應該也是開發規格的一部分啊! 只是這些需求不是外部來的 (業務單位,或是客戶端),而是來自內部的需求 (主管、基礎建設團隊、架構師等等角色)。對內,只有將這些需求也列入開發規格內,只有公司同時重視服務的功能與服務的品質,這些需求才不會一被新功能的需求排擠而搶不到資源,整個服務品質的正向循環才會轉起來。對外,維運團隊也要做好演練跟準備,一但有任何狀況發生 (例如服務損毀需要緊急搶救之類的) 也應該要由工程角度做好如何直接對外溝通的設計。舉些大家熟悉的例子,各大服務都會有 service status board, 用一張簡表來條列服務背後每個系統的健康狀況,就屬於這類。
看到這裡,你會發現,要做好服務,甚至是顧好服務水準,你需要準備的往往不只是開發團隊 (把 code 寫好) 這回事而已啊! 更重要的是要落實 DevOps 不斷回饋改善的循環,才是推動做好服務水準的關鍵。
4-1, 現場回饋 - 91APP TechDay
最後,讓身為講師兼部落客的我虛榮一下, 這主題我在兩個場合上台分享過,分別是 91APP TechDay 以及 .NET Conf 2020 都分享過,也在這兩個場子的回饋問卷得到不少回饋。對於無償分享內容的人來說,這些回饋不管是好是壞,都是很重要的支持跟鼓勵。我摘要的截錄一部分回饋內容,除了自己看之外,也可以讓其他讀者了解別人聽了這個場次得到了什麼,也許會觸發你有不同的收穫。
首先,是 2020/11/28(六) 91APP TechDay 的心得回饋,我也在我的粉專 貼文感謝 :
- “第一次聽到SLO的概念 覺得能用這種角度去進行開發和維運是一件很有道理也很棒的事情 Andrew的條理清晰 講稿的脈絡也很順暢 很容易理解!”
- 腦袋超清楚又很謙虛,非常厲害,很令人印象深刻
- Andrew 從架構面配合管理學的角度講解實際發生的案例 最後再把主題很自然的帶到“何謂devops” 雖然整個過程短短的一小時不到 但是獲益良多
- 喜歡大大總是講心法帶一點簡單case闡明精神 廢話不多說直接重點 超棒
- 非常明確的表示出系統關注指標的思考過程,然後回饋到開發起點的考量事項,形成一個正向的循環,非常精彩!
- 作為開發學到蠻多的,為維運而開發算是新觀念
- 能夠聽到真實處理大流量的devops經驗,限制理論、SLO如何定義⋯⋯這些都讓我大開眼界
- 很有邏輯性的觀點與做法,感謝。
- 以SLO爲中心向外發散,從設計、開發、維運做起,訂定目標,尋找監控指標,從大量監控點尋找關鍵指標,能透過實務為例,更能印象深刻,雖然演講時間有限但活躍良多。
- 可以從實例了解到以開發者的角度應該如何處理現實中遇到的瓶頸
- 以簡易的說法讓人清楚知道問題及可行性做法
- 定義好SLO,再針對SLO進行監控,並於開發階段做好配合,以隨時調整應付突發事件
- 用簡單的方式描述面對的問題和解決方式,非常清楚,謝謝
- 清楚說明如何找出關鍵的的系統指標,以及如何監控各項數據對症下藥以達到期望的目標
- 超讚,以管理角度去克服技術難題
- 給了很多觀念是,解決問題要在刀口上,並是否有解決最後優化目的!如只解決某個流程問題,但最後結果沒有改善!也是白工
- 剛好工作也在研究監控的部份,主題非常切合期待,也學習了 Andrew 是如何由系統的現況一步步驟拆解問題,透過指標來分析,找到瓶頸後再設計滿足需求的解決方案
- 學習到一個功能流程上,從中規劃量測點與量測目標,以掌握程式的效率與限制,才能後續去制定接下來的修正方針與改善。
- 議程很有啟發,”1. Queue 也應該有 QoS 設計; 2. Design for Maintenance”
- 目前我也正在從零開始開發有非同步需求的系統,但團隊並沒有系統架構師或資深工程師可以請益,很多事情都必須自己研究,Andrew 提供的思維以及 case study 對我來說幫助很大,以後 91APP 的技術分享一定都會參加,謝謝!
- 能更有組織地讓其他人了解如何導入 SLO 觀念
- 過去多著重在開發實務,系統越趨成熟維運的重要性也會逐漸提升,以服務目標與結果來推導過程的思維,非常受用
- 融合限制理論 的軟體工程實踐
- 對SLO有更深一步的認識 感謝🙏
- 對於改善瓶頸有了不同的認識,往往只想著要改良它,殊不知它可以給予 “慢” 的價值。
- MQ 講的不錯,觀念也正確,將 queue 的類型區分出來做分流,DevOps的精神也非常好,不會只停留在 CI/CD 而是整個軟體生命週期的循環不斷的發現問題,不斷的改善。
- 講者邏輯清晰,並且藉由 case study 的討論,讓我們更能深入了解 SLO 的訂定以及場景
4-2, 現場回饋 - .NET Conf 2020
另外,在 Study4.TW 主辦的 .NET Conf 2020 收到的心得回饋,我一樣在我自己的粉專 貼文感謝 :
- 有實際的case study讓我們更容易了解問題的解決方式,很棒!
- 我覺得講的很簡單易懂,從遇到問題到怎麼解決,脈絡都講的很清楚,很喜歡
- 剛志的分享很紮實,讓我們 清楚 軟體遇到問題時,該如何分析與解決
- 覺得 91APP 技術含量真的很不錯,在業界來看相當難得
- 老師講究觀念、心法,也注重程式的品質,非常認同!且在刻意練習的帶領下大家一起成長的感覺一定很棒!最近在被舊程式維運束縛困擾的情況下,雖有在空閒時間讀些書,但還是沒辦法突破現狀,刻意練習彷彿醍醐灌頂,會後就想開始嘗試!
- 很謝謝 Andrew 的分享。覺得當 Andrew 的 team member 很幸福
- 謝謝分享專案上實際遇到問題的解決過程,受益良多
- 非常有結構化的訓練收穫滿滿!
- 刻意練習這概念 非常好 我想這應該要是每一位開發人員 都所需要的
- 感謝分享業界實例經驗
- 謝謝安德魯大持續分享重要觀念
- 促進大腦發展感謝分享!
- 相當有趣的主題以及team building
- 刻意練習的建議很不錯
- 我很認同抽象化是資深開發者必须具備的能力
- 實際展示如何刻意練習,在聽演講的同時也一起體會到刻意練習帶來的好處。很有用。
- 工作思維與訓練方式知識吸收,收穫滿滿
- 感謝分享開發專案的發想過程,用剪片來聯想很有趣
- 講師導出現在台灣科技產業上的痛點,以及如何實施專案上的BrainStorming
- 生物細胞模型很驚艷
- 厲害👍 學到很多 算是唯幾堂很認真聽的課!
- 謝謝老師的分享,提供刻意練習這本書讓我們參考,我會把這本書看完,再思考自己欠缺的能力朝理想前進
- QQ沒有聽的課程好可惜,教室滿了..
- 很感謝分享了如何訓練內部member的做法
- 練習方式很實用
- 謝謝老師教我們怎麼刻意練習
- 又學到新觀念了
- 精闢解析!
最後,更令人感動的是活動才剛結束,就有篇熱騰騰的心得文… 竟然連不是 .NET 族群的朋友都專程的來參加 .NET Conf, 還特地寫了一篇專文分享了廳我們一系列場次的心得… 實在有點受寵若驚 XDD:
首先感謝主辦單位提供了這麼棒的活動,一連兩天的社群技術議程讓我收穫滿滿,在社群日所分享的主題並不限於 .Net 的技術,對於第一次與會的我感到十分新鮮,在此也要肯定微軟在台灣對技術社群的耕耘。
附帶一提,我目前所在的工作專案上並未使用到 .Net 的技術,會參加此活動實在是因為議程主題太吸引我,尤其是 91 App 主講的幾個主題。在實際參與後,也完全沒讓我失望,不僅滿滿的乾貨,也很啟迪人心。
4-3, 知識連結的力量
最後 (這次是真的結尾了),引用一張在 上一篇 引言的圖 來做收尾吧..
這整篇我想交代的過程,其實並不是強調很硬的技術能力,文中說明的驗證簡訊發送,並不是瞬間有非常大的量要發送,必須動用到高併發等等技巧的主題。但是我在這大部分人都會碰到,但是容易忽略掉的 “服務品質” 身上下功夫,因為我除了想要把 code 寫好之外,我更希望我提供的服務是有品質的。品質來自你對各個細節的要求跟堅持,對於及時的回應,這是我更想做好的環節。我期待能在顧好服務的品質的前題下,同時做到服務的流量。
品質的東西本來就很難量化,時間序相關的要求也是很難寫成規格的一個環節。要同時把這兩件事情做好,你面對的就是兩個維度以上交乘出來的複雜度了。要面對這樣的問題,靠的不是很硬的技術能力,而是要靠你在各個領域累積下來的基礎科學的經驗與能力,做事的專案管理能力,以及工作上的管理經驗,這些不同面向的經驗互相搭配才辦的到。
因此,我挑了這個主題,示範了你要如何連結這些經驗跟知識,才能完美的達成目標。藉由上一篇我交代我學習跟累積經驗的過程,在這一篇我展示了把這一切串起來能做到什麼,寫成文章展示給大家。如果你覺得工程師的生涯除了不斷的追求技術之外就沒有目標了,試試看多累積幾個不同領域的能力吧! 軟體業是非常有變化與彈性的產業,好好思考你一定能找到你能發揮的場合的。
希望這篇文章能對大家有所幫助,也請期待這系列的第三篇文章: 刻意練習 - 鍛鍊你的抽象化思考能力 ~
