這篇也是個練習題,這次換個實際一點的主題,”排程任務” 的處理機制。

後端服務做久了,一定有碰過這類需求: 使用者想要預約網站在某個指定的時間點執行預先排定的工作。不過,Web Application 先天的框架,就都是 Request / Response 的被動處理模式,有 Request, 才有 Response… 這模式先天就不擅長處理預先排定時間執行的任務。因此這類需求,通常都必須另外處理。雖然有不少現成的套件或是服務可以解決,不過我還蠻期待工程師都能思考看看,如果我找不到合適的套件,必須自己處理時,我知道該怎麼做嗎?
別誤會我不是要大家丟掉現成的服務,全部都自己造輪子…,但是現實狀況的確不是每個情境都完全適用的,這個練習就是讓你先做好準備,有必要時就有能力自己打造。當你能理解背後的設計時,你也同時有能力更精準的評估現有方案的好壞。擁有這能力,你也開始有機會做到更好的整合性。當你必須在既有的系統限制下實做這功能,又不想增加太多不必要的相依姓,或是更動既有的系統架構,都是運用的好時機。
如果不考慮 “預約” 這因素,其實這問題很簡單啊,用 message queue 搭配 worker(s) 就解決了,但是 message queue 都是一瞬間的事情, 預約一小時後才要執行的任務,丟到 queue 然後再讓它佔個位子等一小時才消化,實在不是個好主意。於是我就把這主題簡化一下:
在資料庫內維護排定工作的時程表, 你的解決方案只能用 pooling 輪詢的方式, 在指定的時間啟動工作。需要同時解決高可用,以及降低輪詢對於 DB 的效能負擔。
這練習題是我在公司,拿來給架構團隊的 team member 練習思考用的題目,同時也準備實際應用在要上線的專案身上。我想既然都做了準備了,因此也在這邊開放給大家練習看看。規則跟 上一篇 一樣,有興趣的請自行到我的 GitHub 取用,願意的話,也歡迎將你的 solution PR 放上來,我會在後半段文章用我的角度幫你 code review 。
問題定義
開始解題之前,先對問題做一些了解吧! 主要要解決的問題,是資料庫內有排定的任務清單資料。資料庫隨時會異動,除了定期輪詢之外無法有其它的通知機制告知排程改變。資料庫只能很單純的提供 “被動” 的查詢,意思是不支援像是 SQL notification service 這類主動通知異動的機制;資料庫的表格大致像這樣:
| ID | CreateAt | RunAt | ExecuteAt | State |
|---|---|---|---|---|
| 1 | 10:00 | 10:30 | NULL | 0 |
| 2 | 10:00 | 12:00 | NULL | 0 |
| 3 | 10:00 | 08:15 | NULL | 0 |
其中,CreateAt 代表這筆資料建立的時間,RunAt 欄位代表 “預定” 要執行的時間, ExecuteAt 代表實際上被執行的時間,State 則是這筆 Job 的狀態 (0:未執行, 1:執行中, 2:已完成)。
這類問題,如果只管能不能做出來,其實很容易解決啊。只要每分鐘都查一次是否有該執行卻未執行的 jobs, 若有就撈出來處理掉:
select * from jobs where state = 0 and runat < getdate() order by runat asc
不過,這方法常常令工程師陷入兩難…
“什麼? 精確度只能到分鐘? 能不能精準到秒??”
於是,原本每分鐘查詢一次的動作,就被調快成每秒查一次….
“為什麼 DB 沒事做也這麼忙? 到底在幹嘛??”
於是,改成每秒查一次的動作又被調慢成每分鐘… 這問題最終會變成死結,因為對於精準的需求會一直提高 (至少到秒級),而資料量也會一直增加,但是資料庫的效能終究是有極限的…
需求定義
由於 DB 的效能是很昂貴且有限的運算資源,因此這樣輪詢的機制,往往要在效能(成本)與精確度之間做取捨…。光是從 “分” 提升到 “秒”,執行的成本就增加了 60 倍… 所以,這次練習主要的目的,就是試著找出,在只能用輪詢的前提下,如何達到下列幾個要求?
- 對於 DB 額外的負擔,越小越好
- 對於每個任務的啟動時間精確度,越高越好 (延遲越低越好,延遲的變動幅度越低越好)
- 需要支援分散式 / 高可用。排程服務要能執行多套互相備援
- 一個 Job 在任何情況下都不能執行兩次
當然,這些要求的同時也有一些附帶的條件限制,例如:
- 所有排進 DB 的預約任務,至少都有預留固定的準備時間 (MinPrepareTime, 例如: 10 sec) 。
- 每個排定的任務,必須在最大允許的延遲時間 (MaxDelayTime, 例如: 30 sec) 內啟動。
講白話一點,如果按照上面的例子 (MinPrepareTime = 10 sec, MaxDelayTime = 30 sec),意思就是排定 10:30:00 要執行的任務,一定會在 10:29:50 之前就寫入資料庫;同時這筆任務最慢在 10:30:30 之前一定要開始執行。每一筆都只能執行一次,不多不少。否則,你的成績再好看都是假的。
評量指標
你能夠滿足基本需求後,接下來就是比較怎樣做會比較 “好” 了。為了方便量化每種不同作法的改善幅度,我直接定義一些指標,將來只要監控這些數據,我們就能量化處理方式的優劣。 假設在一定的測試執行時間內 (ex: 10 min),我有工具按照上述的約束,不斷的產生任務資料排入 DB;額定的時間超過之後 (ex: 10 + 1 min), 應該要滿足下列所有條件才有評比的資格。
對於是否合格的通過條件指標:
- 所有資料的狀態 (state) 都必須是 2 (已完成)
- 每一筆紀錄的前置準備時間 (
RunAt - CreateAt) 都應該大於要求 (MinPrepareTime) - 每一筆紀錄的延遲時間 (
ExecuteAt - RunAt) 都應該小於要求 (MaxDelayTime)
對於排程機制對 DB 額外產生的負擔,我看這些指標最後算出來的分數:
- 所有查詢待執行任務清單的次數 (權重: 100)
- 所有嘗試鎖定任務的次數 (權重: 10)
- 所有查詢指定任務狀態的次數 (權重: 1)
花費成本評分(cost score): (1) x 100 + (2) x 10 + (3)
對於任務實際執行的精確度,我用這些指標最後算出來的分數:
- 所有任務的平均延遲時間,
Avg(ExecuteAt - RunAt) - 所有任務的延遲時間標準差,
Stdev(ExecuteAt - RunAt)
精確度評分(efficient score): (1) + (2)
用圖示化的方式說明一下這過程吧。由左到右是時間軸,空心三角形代表預定執行的 Job:
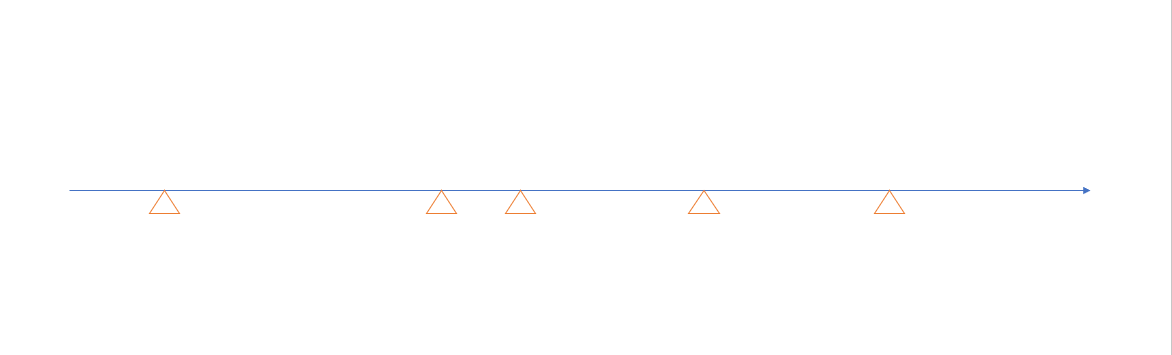
如果我定期 (垂直虛線) 掃描一次該執行的 Job …
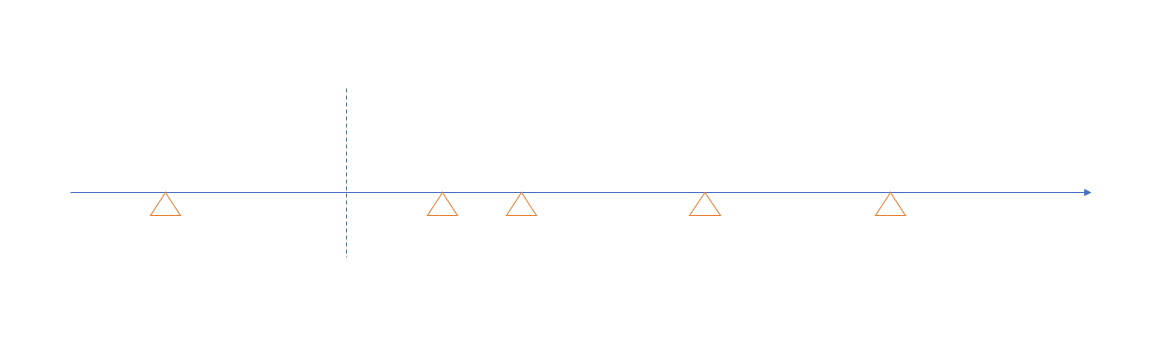
啟動掃描到的 Job (實心三角形):
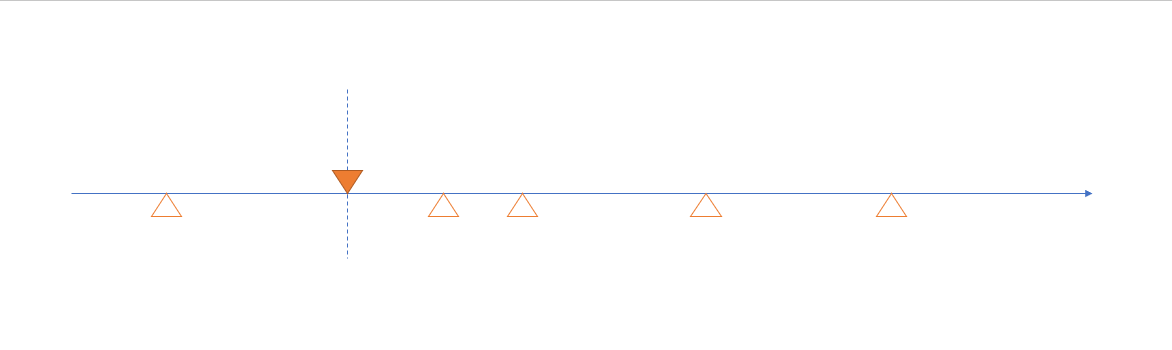
不斷重複同樣的動作:
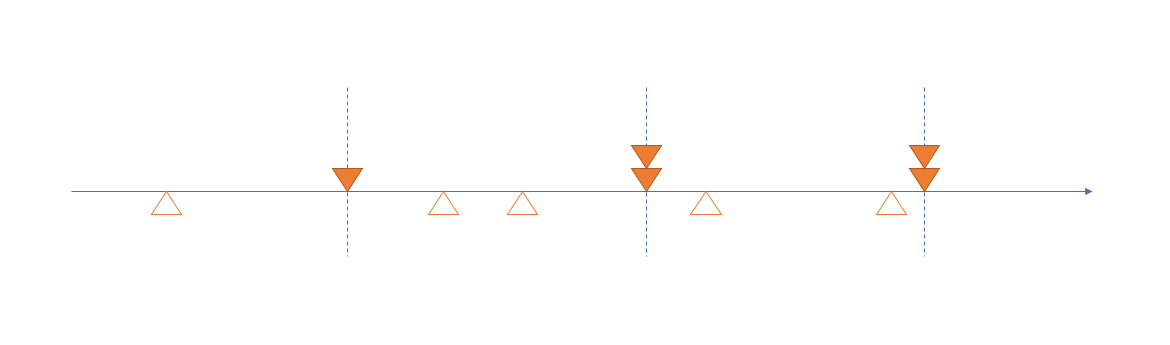
我們分別標出每個 job 的延遲時間 (Delay #1 ~ #5)
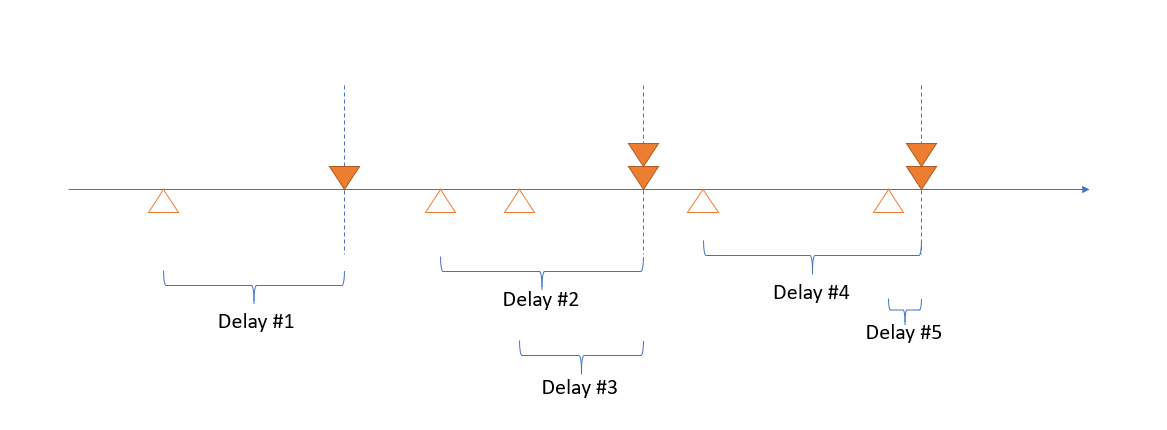
這五筆延遲時間的平均值,以及標準差,就是我們精確度評分的項目。
測試方式
指標都定義結束了,剩下的問題就簡單了。最後是測試方式。不論你用何方式來開發你的解決方案,我最終會這樣驗證與計算你的程式得分:
首先,先測試可靠度是否達標:
- 啟用測試程式,會清除資料庫,重建資料。
- 同時啟用你的排程程式,一次跑 5 instances
- 隨機次序與時間,再測試程式還未結束前,按下 CTRL-C 中斷 3 個 instance
- 測試結束後,驗證通過指標
接下來就來測測評分了:
- 啟用測試程式,會清除資料庫,重建資料。
- 同時啟用你的排程程式,一次跑 5 instances
- 測試結束後,驗證評分結果
如果兩個以上的解決方案都不分上下,那可以再做個延伸測試: 重複執行數次上述測驗,找出一次跑多少個 instances 能得到最佳的評分?
開發方式
接下來就要開始看 code 了。有興趣的朋友們,請到我的 GitHub: https://github.com/andrew0928/SchedulingPractice
準備資料庫:
首先,在開始寫任何一行 code 之前,請先準備這次測試需要的資料庫。資料庫的需求很低,只要是 Microsoft SQL Server 即可,版本不要太舊應該都沒問題。我只是用 localdb 就可以搞定了。這次的測試對 DB 的效能要求很低,請不用擔心 SQL 會影響你的測試成績…
為了省麻煩,我的 code (後面說明) 預設就用這組 connection string, 如果你不介意的話,請用 LocalDB, 名字取名為 JobsDB 可以省掉一些麻煩。當然你要另外自己建立也無訪,記得改 code 即可。
預設連線字串: Data Source=(localdb)\MSSQLLocalDB;Initial Catalog=JobsDB;Integrated Security=True;Pooling=False
建立 SQL 用的 script:
CREATE TABLE [dbo].[Jobs] (
[Id] INT IDENTITY (1, 1) NOT NULL,
[RunAt] DATETIME NOT NULL,
[CreateAt] DATETIME DEFAULT (getdate()) NOT NULL,
[ExecuteAt] DATETIME NULL,
[State] INT DEFAULT ((0)) NOT NULL,
PRIMARY KEY CLUSTERED ([Id] ASC)
);
GO
CREATE NONCLUSTERED INDEX [IX_Table_Column]
ON [dbo].[Jobs]([RunAt] ASC, [State] ASC);
CREATE TABLE [dbo].[WorkerLogs] (
[Sn] INT IDENTITY (1, 1) NOT NULL,
[JobId] INT NULL,
[LogDate] DATETIME DEFAULT (getdate()) NOT NULL,
[Action] NVARCHAR (50) NOT NULL,
[ClientId] NVARCHAR (50) NULL,
[Results] INT NULL,
PRIMARY KEY CLUSTERED ([Sn] ASC)
);
測試程式導覽:
前面段落提到,測試過程會有個測試程式,啟動後的 10 min 內會不斷的產生測試資料,就是現在要說明的。請看這個 project: SchedulingPractice.PubWorker
程式我就不一一說明了。我說明一下這段 code 執行的流程。最前面幾行,是整段程式的設定,如果你嫌 10 min 跑太久可以改掉:
TimeSpan duration = TimeSpan.FromMinutes(10);
DateTime since = DateTime.Now.AddSeconds(10);
另外,我藏了部分整個機制運作的設定,放在 SchedulingPractice.Core:
public static class JobSettings
{
/// <summary>
/// 最低準備時間 (資料建立 ~ 預計執行時間)
/// </summary>
public static TimeSpan MinPrepareTime = TimeSpan.FromSeconds(10);
/// <summary>
/// 容許最高延遲執行時間 (預計執行 ~ 實際執行時間)
/// </summary>
public static TimeSpan MaxDelayTime = TimeSpan.FromSeconds(30);
}
其中, since 是代表測試開始的時間, duration 則代表要測多久。這邊分別指定的是 10 sec 後開始,測 10 min ..
在測試開始前的這 10 sec 內, 會 ASAP 的預約接下來 10 min 應該執行的 jobs 資料。包括:
- 清除 database 的內容
- 測試期間每隔 3 sec, 就預約 1 筆 job
- 測試期間每隔 13 sec, 就預約 20 筆 job (測試瞬間多筆 job 的消化能力)
- 測試期間每隔 1 ~ 3 sec (隨機), 就預約 1 筆 job
接下來 10 sec 應該就過去了,在 duration 這段期間, 測試程式還是不斷的在進行。這期間測試程式還是不斷的在產生測試資料。這時產生的是:
- 測試期間,會隨機 sleep 1 ~ 3 sec, 醒來後立刻預約 10 sec 後執行的 job, 一次預約 1 筆
等到 10 min 都過去之後, 測試程式會再多 sleep 30 sec, 等待所有 jobs 應該都被處理完畢後,開始查詢統計資訊。統計的細節我們後面看…。
撰寫排程服務
這邊我先說明一下, 我提供了這個 project: SchedulingPractice.Core, 裡面包含了 JobsRepo, 當作存取資料庫的唯一管道。我信任大家不會在 code 裡面動手腳亂搞資料庫,就不做特別防範了。請不要在你的解題內用任何 JobsRepo 以外的方式存取資料庫!!
我直接說明一下 JobsRepo 的結構就好,我內部是用 Dapper 開發的,有興趣可以挖 code 看看我到底寫了那些 SQL;我列出你在寫解決方案過程中,你可能會用到的 method:
public class JobsRepo : IDisposable
{
public IEnumerable<JobInfo> GetReadyJobs() {...}
public IEnumerable<JobInfo> GetReadyJobs(TimeSpan duration) {...}
public JobInfo GetJob(int jobid) {...}
public bool AcquireJobLock(int jobId) {...}
public bool ProcessLockedJob(int jobId) {...}
}
- 查詢(清單):
你可以用GetReadyJobs()取得已經到預約時間,該執行的所有 Jobs 清單。如果你要預先抓未來 10 sec 要被執行的清單,可以加上duration的參數。 - 查詢(單筆):
如果你需要判讀個別單一一筆 job 的狀態的話,你也可以用GetJob(jobid)來完成這件事。 - 鎖定:
你要先鎖定這個 job, 鎖定成功後才能處理這個 job。如果有多個 worker 同時想要搶奪同一個 job 的執行權,呼叫AcquireJobLock()只會有一個 worker 得到 true 的傳回值 (代表鎖定成功), 其他都會是 false. - 執行:
當你成功鎖定 job 之後,就可以呼叫ProcessLockedJob()來執行他。不過,為了凸顯平行處理的必要,我仿照前個練習,加了一點限制;呼叫ProcessLockedJob()會延遲一小段時間 (預設 100ms), 同時單一 process 內的平行處理也會做一點限制 (並行上限: 5), 不過若你用獨立 process / host 則完全無限制。
以上的動作都有做防呆,例如你沒鎖定就執行,會得到 exception. 每個動作都有做對應的 log, 最後的評分就是靠這些被後埋的 log 計算出來的。
我提供了一個無腦的解題版本,一樣這是墊底用的低標 solution, 你可以參考這 project 的作法, 但是我預期每個人的 solution 應該都要比他強才對。
接著就來看看這個 demo project: SubWorker.AndrewDemo, 主程式很短,我就全部都貼上來了:
namespace SubWorker.AndrewDemo
{
class Program
{
static void Main(string[] args)
{
var host = new HostBuilder()
.ConfigureServices((context, services) =>
{
services.AddHostedService<AndrewSubWorkerBackgroundService>();
})
.Build();
using (host)
{
host.Start();
host.WaitForShutdown();
}
}
}
public class AndrewSubWorkerBackgroundService : BackgroundService
{
protected async override Task ExecuteAsync(CancellationToken stoppingToken)
{
await Task.Delay(1);
using (JobsRepo repo = new JobsRepo())
{
while(stoppingToken.IsCancellationRequested == false)
{
bool empty = true;
foreach(var job in repo.GetReadyJobs())
{
if (stoppingToken.IsCancellationRequested == true) goto shutdown;
if (repo.AcquireJobLock(job.Id))
{
repo.ProcessLockedJob(job.Id);
Console.Write("O");
}
else
{
Console.Write("X");
}
empty = false;
}
if (empty == false) continue;
try
{
await Task.Delay(JobSettings.MinPrepareTime, stoppingToken);
Console.Write("_");
}
catch (TaskCanceledException) { break; }
}
}
shutdown:
Console.WriteLine($"- shutdown event detected, stop worker service...");
}
}
}
為了解決 HA (High Availability) 的問題,我用了 .NET core 支援的 generic host 的機制來處理 graceful shutdown 的問題。透過新的 generic host, 你可以輕易開發出適用在 container (long running), windows service (windows), systemd (linux) 這些管理機制 上的服務。撇開這些設計,剩下的就是單純的排程處理了。
我這段 code 示範的就是最常見的作法,只要你沒有按 CTRL-C 中斷執行,那麼解題程式就會不斷重複這動作:
查詢該執行而未執行的 jobs, 如果有的話就試著 lock, 成功就 process。處理完就再查詢一次看看是否還有新的 job 被排入資料庫? 沒有的話就休息 10 sec 再重複。過程中如果按下了 CTRL-C, 則會在處理目前這筆 job 後才會退出,不會發生 lock 卻未 process 的狀況。
處理結果:
按照前面我說的測試方式,跑 10 min 後可以看到這樣的 console output:
Init test database...
- now: 8/31/2019 2:21:32 AM
- since: 8/31/2019 2:21:42 AM
- until: 8/31/2019 2:31:42 AM
Step 0: reset database...
Step 1: add job per 3 sec
........................................................................................................................................................................................................
- complete(200).
Step 2: add 20 jobs per 13 sec
............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
- complete(940).
Step 3: random add job per 1 ~ 3 sec
.........................................................................................................................................................................................................................................................................................................
- complete(297).
Step 4: realtime: add a job scheduled after 10 sec, and random waiting 1 ~ 3 sec.
.................................................................................................................................................................................................................................................................................................
- complete(289).
Database initialization complete.
- total jobs: 1726
- now: 8/31/2019 2:31:33 AM
- since: 8/31/2019 2:21:42 AM
- until: 8/31/2019 2:31:42 AM
Jobs Scheduling Metrics:
--(action count)----------------------------------------------
- CREATE: 1726
- ACQUIRE_SUCCESS: 1726
- ACQUIRE_FAILURE: 4916
- COMPLETE: 1726
- QUERYJOB: 0
- QUERYLIST: 702
--(state count)----------------------------------------------
- COUNT(CREATE): 0
- COUNT(LOCK): 0
- COUNT(COMPLETE): 1726
--(statistics)----------------------------------------------
- DELAY(Average): 4343
- DELAY(Stdev): 2858.51700217987
--(test result)----------------------------------------------
- Complete Job: True, 1726 / 1726
- Delay Too Long: 46
- Fail Job: True, 0
--(benchmark score)----------------------------------------------
- Exec Cost Score: 119360 (querylist x 100 + acquire-failure x 10 + queryjob x 1)
- Efficient Score: 7201.52 (average + stdev)
C:\Program Files\dotnet\dotnet.exe (process 10880) exited with code 0.
Press any key to close this window . . .
測試的結果不算好看,總共 1726 筆 job 預約紀錄中, 平均延遲竟然到了 4343 msec, 標準差也到了 2858 .. Jobs 全部都成功執行完畢,但是有 46 筆沒辦法在指定時間內完成…
最後的 cost score / efficient score 分別是 119360 分 / 7201.52 分。
寫在最後
這次的題目,算是比較務實的問題解決,考驗的是你解決實際問題的技巧。平時專案進行過程中,應該沒太多機會練習或是討論這類議題吧! 如果缺乏明確的指標,有時你可能也無從得知不同作法到底有沒有差異。這次會有機會,在公司內部進行這樣的練習與評估,主要原因是專案需要,同時我也希望團隊成員除了交付專案的需求之外,也能自我要求,在能力所及的範圍內做到最好。為了讓團隊能夠明確的比較各種方式的優劣,我才會自己先花時間準備了這個練習題,同時也花了些時間準備評估的方式。
有興趣的話,趁這次機會,用簡化過的 POC 環境來練習看看吧! POC 的好處是你可以專注在問題本身,盡可能地排除其他環境或是框架帶來的干擾,讓你專心地思考問題本身該怎麼解決。也只有 POC (尤其是我提供的練習環境),你才能有機會觀察到實際測試的統計數據與評分,讓你比較與改善的過程可以更加科學。
最後還是要來工商一下,你對這樣的挑戰與工作方式感興趣的話,歡迎在 FB 留言找我聊聊 :D
Solution & Review (2019/12/01 補完)
這次的挑戰,在 10/18 截止之後,一直忙到現在才有空, 先是準備 DevOpsDays 2019 的演講, 接著是 .NET Conf 2019 連續兩個 session 的演講, 然後再接著公司的雙十一… 不知不覺就 12 月了, Orz… 想到有這麼多朋友發 PR 來支持我發起的活動,想想還是擠出時間把後半段補完了。接著就來看看大家貢獻的 PR 執行結果吧! 這次一樣先感謝願意貢獻 code 給我的朋友們 (按照發 PR 的順序排列):
- PR#1, acetaxxxx
- PR#2, toyo0103
- PR#3, Jyun-Wei Chen
- PR#4, levichen
- PR#5, borischin
- PR#6, Julian-Chu
- PR#7, andy19900208
這次的題目,不像上次可以簡單幾行 code 寫完就交差了,這次扯到比較多實作,開發起來比較花時間,參加人數明顯少了很多… 再次感謝願意參加的朋友們。一開始,我先公布這次跑完的成績,然後再來一個一個進行 code review。前面的需求,是要求跑 10 min, 最多 5 instances, 在可靠度達標的前提下,時間及成本分數越低越好。
老實說這測試還真花時間,連我自己的範例,總共有八組測試要跑,每一組除要跑 10 次測量統計數據,外加 1 次 HATEST 做可靠度測試,全部跑完一次就足足花掉 10 小時以上,還不包括測試 script 沒寫好重跑的時間… (我該慶幸還好參加的人沒有很多嗎?? T_T )
不過為了徹底了解大家寫的 code 表現如何,我還是硬著頭皮把他跑完了 XD,我也加碼直接跑了 1 ~ 10 instances 的數據。我們先從需求規定的 5 instance 來看看結果 (點我看大圖):

說明一下這表格怎麼看。我按照原始的規定,從每個人的統計分數中,挑出 5 instances 內 EFFICIENT_SCORE 最佳的那筆紀錄當作代表做成這張表格。若有需要完整的 EXCEL 可以點這裡下載。我先交代一下幾個關鍵的欄位意義:
-
RUNNER:
代表參賽者,我用各位的 github id 當作代號。最後一位 “demo” 則是我隨附墊底用的範例。 -
MODE:
代表該筆成績的測試模式,有WORKERS{N}與HATEST兩類。第一類WORKERS{N}代表這是同時跑幾個 instances 的組態,例如WORKERS03代表同時間並行三個 instances 組態跑出來的結果。而HATEST則是用我預先寫好的 scripts, 不斷的模擬每個 instance 啟動與結束的狀態。這模式的分數不列入排名計算,但是會參考這模式下是否每個 job 都能被成功的執行。 -
ACQUIRE_FAILURE~DELAY_STDEV:
代表這次評分用的幾個指標,意義如同上面文章說明。 -
DELAY_EXCEED:
代表整個測試跑下來,是否有超出額定時間才被執行的 job ? 這欄位數值若超過 0 則不合格 -
EARLY_LOCK:
這欄位代表 job 在預計執行的時間點之前就被 lock 的總數。雖然說這樣有點偷吃步,但是就結果來說這樣不算違規。大家很聰明的都有在這地方動一點手腳 XDDD,我就把這個數值列出來統計給各位參考參考。 -
EARLY_EXEC:
如果你的 job 在預定時間到達前就開始執行,則會被列入這欄位統計。這情況發生時,就已經不符合需求規格了。 levichen 選手應該是有 bug 沒有抓乾淨就發 PR 了,這欄數字過高,因此不列入排名 (我整排標為灰色)。 -
COST_SCORE:
就是需求說明裡定義的COST_SCORE,代表 database 的負載分數,越低越好。我把最低分的數值當作 100%, 分為三個區間: 100%, 101 ~ 150%, 151% ~ 300%, 由深至淺標上綠色。 -
EFFICIENT_SCORE:
同需求說明裡定義的EFFICIENT_SCORE,代表執行時間的效率分數。這分數要漂亮,平均值要低,標準差也要低。我同樣用最好的那一筆當基準,標三個顏色。
前面放了所有人在 5 instances 條件內最好的一筆紀錄做成總表,這份則是 10 instances 內的最佳紀錄表。僅供各位參考用。做 1 ~ 10 的目的是我想在後面的評論,拿來驗證 solution 在不同狀況下的表現用的, 超出 5 instances 的數據我就不列入排名了,以示公平。以下是整理好的表格,給大家參考 (點我看大圖):
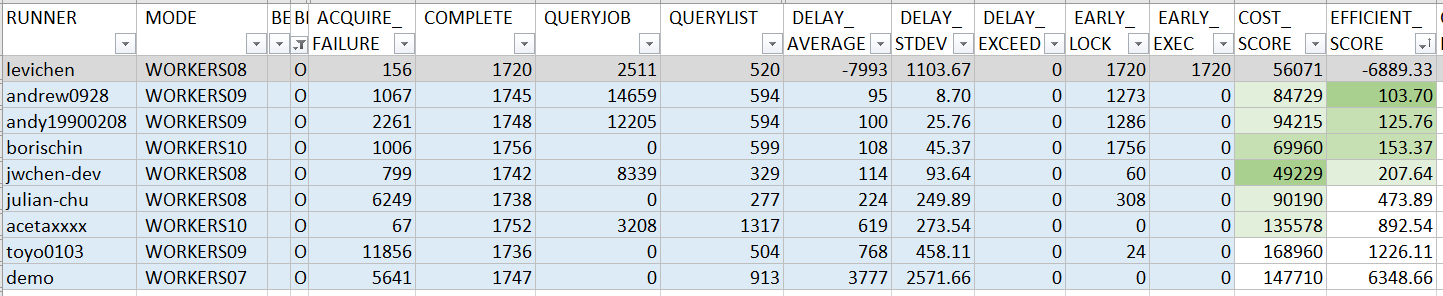
分數各有千秋,但是兩組測試結果都類似。EFFICIENT_SCORE 最佳的那一組都是 andrew0928 (是我自己, 不好意思 XD), COST_SCORE 最佳的那一組都是 jwchen-dev …, levichen 都因為出現 “偷跑” 的狀況而被排除最為可惜… 我的 source code 都有公布,包含測試程式,歡迎各位自行下載回去玩看看。
特別題一下 HATEST 的做法。Windows 不如 Linux, Windows 打從娘胎開始就有 GUI, 很多設計都跟 GUI 密不可分。在 Windows 下,只有 Windows Application, 或是 Windows Service 這兩種類型的執行檔,你才有方法用程式化的方式傳遞關閉的訊號給他,同時讓程式有機會做好收尾的準備。
但是在 ConsoleApps 模式下就沒有這種機會了,OS 並沒有像 Linux 這樣,可以 send signal: SIGTERM 模擬關機的狀態,也沒辦法模擬 CTRL-C… 如果你從 kill process 下手,那就會變成強制終止程序, 你根本也沒機會做 graceful shutdown 在收到訊號後還有機會收拾一下殘局。
因此,最終我選擇了一個折衷的方式: 我從 GenericHost 下手。題目要求每個人都是準備自己的 BackgroundService, 因此我自己寫了一個 ConsoleApp, 加入每個人的 project 參考, 我自己控制 Host 的 Start / Stop, 來模擬每個人的 BackgroundService 怎麼面對 OS shutdown …
我 HATEST 測試的腳本是:
- 一次啟動五個 instance, 執行 10 minutes
- 每個 instance 啟動後, Host 會啟動 10 ~ 30 sec (隨機) 後自動 shutdown, 然後再自動重新啟動一次。不斷重複直到超過 10 min 後為止
- 所有 instance 都執行完畢後, 看統計資訊,確認沒有異常狀況則算通過。
我這邊定義的異常,包含這幾種:
CREATE的個數與SUCCESS的個數不相等EARLY_EXEC,DELAY_EXCEED的個數 > 0- 測試過程中出現
Exception(註: 只會列為參考,主要還是看 1, 2 兩項數據)
最後交代一下執行的環境。這次執行環境包含 database, 因此也跟你機器效能有些微的關係。為了客觀起見,我一起把我的執行環境列一下:
| OS: | Windows 10 Pro for Workstations (1903) |
| SQL: | Microsoft SQL Server 2017 Develop Edition |
| CPU: | AMD Ryzen 9 3900X (12C/24T, 3.80Ghz) |
| RAM: | 64GB DDR4 (Kingston 16GB 3200 x 4) |
| DISK: | 512GB Samsung 970Pro SSD (NVMe M.2 2280 PCIe) |
OK,接下來要開始進入 code review 的階段了,我們就按照發 PR 的順序一個一個來看吧~ 以下每個 PR,我都會個別列出 11 筆測試結果,同時也會標記 HATEST 是否通過。我也會依據測試結果與 source code 來提供我 review 的結果。
PR1, HankDemo
感謝第一個捧場的 acetaxxxx, 開始前先看一下 HankDemo 的測試結果:
Benchmark:
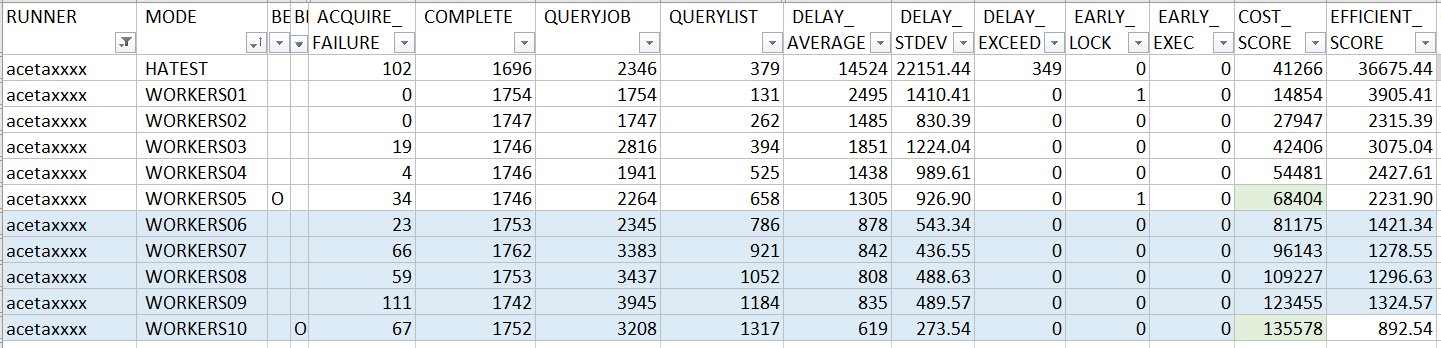
HA test: PASS
至於 source code, 其實不長, 我就全貼了:
public class HankTestProgram : BackgroundService
{
private static Dictionary<int, Queue<JobInfo>> jobList;
protected async override Task ExecuteAsync(CancellationToken stoppingToken)
{
ThreadPool.SetMaxThreads(5, 5);
ThreadPool.QueueUserWorkItem(Worker, 0);
ThreadPool.QueueUserWorkItem(Worker, 1);
ThreadPool.QueueUserWorkItem(Worker, 2);
ThreadPool.QueueUserWorkItem(Worker, 3);
ThreadPool.QueueUserWorkItem(Worker, 4);
using (JobsRepo repo = new JobsRepo())
{
while (stoppingToken.IsCancellationRequested == false)
{
var newJob = repo.GetReadyJobs(TimeSpan.FromSeconds(15)).ToList();
jobList = getCleanDictionary();
for (int i = 0; i < newJob.Count; i++)
{
jobList[i % 5].Enqueue(newJob[i]);
}
try
{
await Task.Delay(5000, stoppingToken);
Console.Write("_");
}
catch (TaskCanceledException)
{
break;
}
}
}
shutdown:
Console.WriteLine($"- shutdown event detected, stop worker service...");
}
private static void Worker(object obj)
{
var index = (int)obj;
JobInfo job;
while (true)
{
if (jobList == null || jobList[index] == null || jobList[index].TryDequeue(out job) == false)
{
Thread.Sleep(20);
continue;
}
if (job != null && job.RunAt <= DateTime.Now)
{
try
{
using (var repo = new JobsRepo())
{
job = repo.GetJob(job.Id);
if (job.State == 0 && repo.AcquireJobLock(job.Id))
{
repo.ProcessLockedJob(job.Id);
Console.Write("O");
}
else
{
Console.Write("X");
}
}
}
catch
{
Console.Write("E");
}
}
}
}
private static Dictionary<int, Queue<JobInfo>> getCleanDictionary()
{
return new Dictionary<int, Queue<JobInfo>>()
{
{0, new Queue<JobInfo>()},
{1, new Queue<JobInfo>()},
{2, new Queue<JobInfo>()},
{3, new Queue<JobInfo>()},
{4, new Queue<JobInfo>()},
};
}
}
這 code 做法有點可惜,方向都很合理,但是細節卻沒有搭配得很好,導致排程服務最關鍵的時間精確度 (EFFICIENT_SCORE) 沒有被最佳化。從幾個地方都可以看到這樣的現象:
主結構:
先從這 solution 怎麼將 database 裡面的 job 拿出來分配吧。主結構是個 while loop, 每隔 5 sec, 查詢 15 sec 後必須被執行的 job list. 不過其實題目給的前提, prepare time 有 10 sec 啊! 用了 1/2 的時間 (5 sec) 來查詢,等於多了一倍的 QueryList 執行成本, 預先查詢 15 sec 的範圍雖然不會有甚麼問題,但是 10 ~ 15 sec 區間還有可能在查完之後插入新的 job… 會增加後面 worker 處理時的困擾。
這樣的設計,除了浪費一點 COST_SCORE 之外,對於 EFFICIENT_SCORE 倒是沒有很明顯的影響。我們接下來繼續看 worker 的設計:
Worker 設計:
查出來的 job, 會被分配到 5 個平行進行的 worker 處理。每個 worker 都有專屬的 queue 來存放即將被處理的 job. 由於 job 的分配時間點,是在主迴圈拿到 job list 那一瞬間就決定了,因此之後每個 worker 的執行速度若有快慢, 或是特定的 worker 當掉了之類狀況, 其他 worker 不會有替補或是備援的機制。
同時,前面提到額定的規範是 10 sec 準備時間, 但是預查 job list 查到 15 sec, 若查完 query list 後還有新的 job 被插入在 10 ~ 15 sec 內,現有的 source code 沒看到可以重新排序的機制,也因此這些 job 可能會發生明明是 10 sec 後就預約要執行的,卻因為這設計被擋在 15 sec 後才執行。平白就多浪費了 5 sec 的 delay time…
平行處理的技巧:
除了結構上的改善空間之外,實際 coding 平行處理機制的技巧也可以優化。Worker 從專屬的 queue 取出 job 後, 應該要 “等待” 預定時間到了之後才執行。這段 code 很可惜的沒有直接用 Sleep 之類的機制來等,而是在中不斷的判斷時間到了沒,這是典型的 “busy waiting” 的作法。精確度沒有甚麼問題,問題在這段過程中 CPU 會不斷的空轉,造成 CPU 使用率降不下來,若再負擔較重的 server 上面可能就會影響其他服務的運作。
另外在其他幾個地方的細節,也可以再善用各種同步機制 (如 AutoResetEvent) 來做更精準地控制,對於 shutdown 這件事的處理也是。主迴圈等待 5 sec 的地方有考慮到了 CancellationToken, 可以精準的偵測是否該停機了, 而不會傻傻地繼續等下去。但是在 worker 內的 sleep 等了 20 sec, 就完全沒有正常的退出機制, 有點可惜。
最後一個是平行處理的方式。這邊並沒有用常見的 Task 或是 Thread 方式來實作平行處理,而是把每個 worker 當作一個 thread pool 的 job 來處理。thread pool 擅長的是處理大量的小任務啊! 因為任務又多又小又快,過度頻繁建立及刪除 threads 的開銷很大,因此才用 thread pool 來改善。
可是,這 worker 一跑就是 10 分鐘, 實際狀況可能更久, 一整年不停機都有可能。這種狀況用 thread pool 會有很多副作用,例如:
- threads 可能有上限, 如果 worker 超出上限,沒有其他工作退出,可能有些 worker 永遠都不會被執行
- worker 本身長時間佔住了 thread, 可能導致 pool 內能夠拿來消化其他 task 的 pool 變少甚至沒有, 會讓其他任務塞住
- 如果 worker 內還有其他直接或間接的任務要靠 thread pool 處理 (尤其是內建 BCL 機率更高),那就會發生 dead lock ..
我通常會建議,長時間而且使用模式很固定可預期的情況下,自己管理 thread 是比較好的做法。
整體來看, 由於在時間的控制不夠精準,導致處理過程中的空隙太多, 所以 EFFICIENT_SCORE 並沒有佔到任何優勢, 落在 300% 的範圍之外,有點可惜。不過在 process job 時有動了一點腦筋, 由於 AcquireJobLock() 的成本是 GetJob() 的 10 倍, 因此在嘗試 lock 前先 query, 花費 1 的 cost 去確認該不該花 10 的 cost 去 lock, 其實是划算的。反倒是在 repo 的使用上很謹慎, 因此在 COST_SCORE 的分數上還有擠進 300% 內。
即使如此, 表現的成果仍然可以精確到 1 ~ 2 sec 左右的誤差。在實際的狀況下,只要解決 busy waiting 的問題,其實也很夠用了。畢竟大部分 OS 提供的排程服務都只精準到 minute 而已啊! 但是既然都有明確的指標了,可以嘗試看看把自己的 code 改到極致的狀態吧!
PR2, JolinDemo
照例先看結果…, 以下是 toyo0103 提交的 PR 跑出來的成績:
Benchmark:
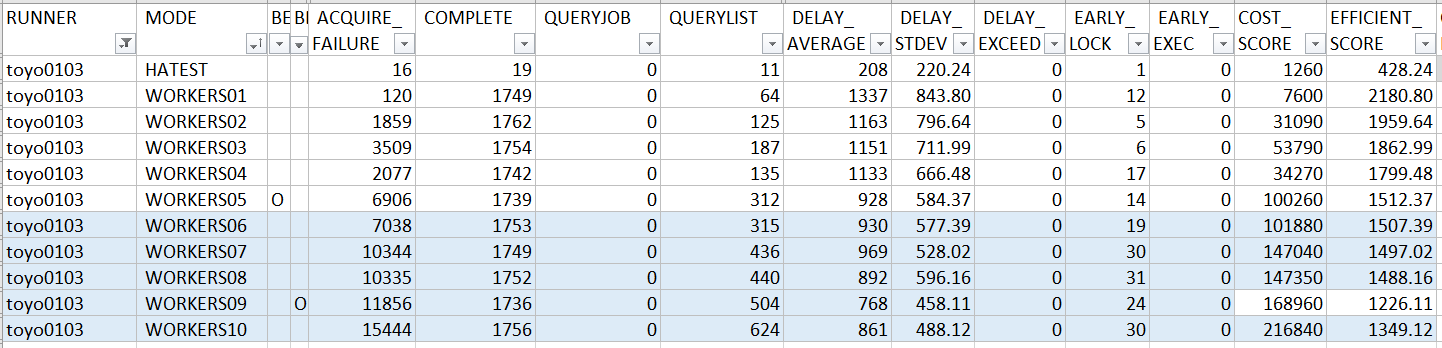
HA test: PASS
我貼了主要的 source code, 其餘無關的我直接省略:
private void ExuteBody()
{
while (_stop == false)
{
JobInfo job = null;
while (this._jobList.TryTake(out job))
{
if (job.RunAt > DateTime.Now)
{
var sleepTime = job.RunAt.Subtract(DateTime.Now);
int index = Task.WaitAny(
Task.Delay(sleepTime),
Task.Run(() => _stopAre.WaitOne()));
if (index == 1)
{
break;
}
}
using (JobsRepo repo = new JobsRepo(this._connectString))
{
if (repo.AcquireJobLock(job.Id))
{
repo.ProcessLockedJob(job.Id);
Console.Write("O");
}
else
{
Console.Write("X");
}
}
}
Task.WaitAny(
Task.Run(() => _stopAre.WaitOne()),
Task.Run(() => _doJobAre.WaitOne()));
}
}
private void FetchJob()
{
while (_stop == false)
{
using (JobsRepo repo = new JobsRepo(_connectString))
{
var jobs = repo.GetReadyJobs(TimeSpan.FromSeconds(_intervalSecond));
foreach (var job in jobs.OrderBy(X => X.RunAt))
{
this._jobList.Add(job);
Console.WriteLine(job.Id);
}
_doJobAre.Set();
_doJobAre.Reset();
}
Task.WaitAny(Task.Delay(TimeSpan.FromSeconds(_intervalSecond)),
Task.Run(() => _stopAre.WaitOne()));
}
}
toyo0103 的做法也類似,由一個主程序 FetchJob 負責跟 JobsRepo 不斷的取得再 10 sec 內應該要執行的 jobs 清單, 透過過去前幾篇不斷提到的 BlockingCollection 往後送。而 ExuteBody() 則負責從 BlockingCollection 取得 jobs, 到排定的時間後就執行。
值得一提的是,這個 solution 對於平行處理的技巧純熟的多,很多多執行緒情境下的問題都處理的很到位。例如典型的生產者消費者問題,巧妙的用 BlockingCollection 就隔離開來了,再兩端的控制都是透過背後的同步機制進行,少了 timer 等候輪巡,反應的時間完全取決於 CPU 的速度,通常都會在 msec 以下。
至於 shutdown 的處理,也做的到位,直接用 WaitHandle 來協調, 讓 FetchJob 能精確掌握 ExuteBody 是否全部結束, 然後正常的退出。雖然中間經過兩種不同的 wait 機制轉換 (從 WaitHandle 再多一層包裝成 C# async / await), 不過瑕不掩瑜, 終究這段 code 能精準地完成 shutdown 的過程。
回到主要處理排程任務的部分 ExuteBody(), 來看真正這部分的核心邏輯:
using (JobsRepo repo = new JobsRepo(this._connectString))
{
if (repo.AcquireJobLock(job.Id))
{
repo.ProcessLockedJob(job.Id);
Console.Write("O");
}
else
{
Console.Write("X");
}
}
很標準的作法,等待到預定時間後,AcquireJobLock(), ProcessLockedJob()… 真的要挑缺點, 大概就是 JobsRepo 其實可以適度的 reuse 這類工程問題而已。但是看看跑出來的結果,很可惜在 COST_SCORE 或是 EFFICIENT_SCORE 上都沒有擠進 300% 的範圍內 (請看總表)。由於這部份原因我沒有實際用工具去看執行過程,因此純粹就經驗來推斷,如果有朋友實際實驗結果有落差請記得跟我說 :D
先談談 COST_SCORE, 這作法其實是很標準的作法,沒有啥好挑剔的,但是相較於其他競爭者都花了不少心思優化,標準做法反而變成 “公版” 一樣,在效能表現上就居劣勢了。我舉幾個在排程部分,有機會進一步優化的地方:
降低鎖定次數:
由於 AcquireJobLock() 這動作的 COST_SCORE 定義上是 GetJob() 的 10 倍, 加上這又是平行處理的架構 (5 thread x 10 process = 50 concurrency), 很多參加的選手都有用這招, 先 GetJob() 後再決定要不要 AcquireJobLock(), 猜錯了 COST_SCORE 就是 10 + 1, 猜對了就是 1 … 如果乘上 50 個併行處理的總數, 真正會執行 AcquireJobLock() 的個數應該很有限才對, 因此這部分 COST_SCORE 可能就會從 50 x 10 降到 50 x 1 + N x 10, 其中 N 應該只會是個位數…
降低延遲:
接下來又是個暗黑技巧,toyo0103 很老實的在時間到了之後才執行這一連串的動作 (還包括 new JobsRepo() …), 最後計算的時間點則在 ProcessLockedJob(), 這中間的時間就都被算到 DELAY 了。因此另一招是 “偷跑”。
再次看一下總表,EARLY_LOCK 欄位代表的就是你 AcquireJobLock() 的時間點是不是在預約時間點之前? 你會發現排名高的這項統計都不低 (代表大家都有偷吃步)。先撇開正確性不說,光是提前 100ms AcquireJobLock(), 你就能在整個延遲的計算裡面省掉這段開銷。這段 code 能省掉的有 new JobsRepo(), 跟 AcquireJobLock() 兩段。
最後,只能說很可惜的,這份 code 其實很標準,可以拿來做講解的範例,可惜 COST_SCORE 跟 EFFICIENT_SCORE 都沒有顧好最佳化,兩邊都沒佔到便宜就被超車了 XDD
PR3, JWDemo
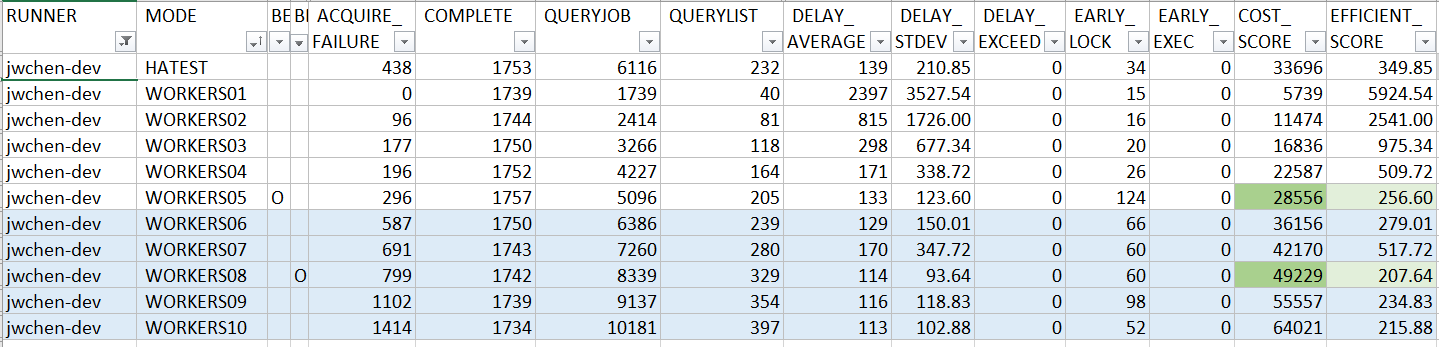
以下是 Jyun-Wei Chen 提交的 PR 跑出來的成績:
Benchmark:
HA test: PASS
一樣,直接看最關鍵的部分: 如何執行指定執行時間的 job :
using (JobsRepo repo = new JobsRepo())
{
while (true)
{
JobInfo job = Queue.pop();
long delay = (job.RunAt.Ticks / TimeSpan.TicksPerMillisecond) - (DateTime.Now.Ticks / TimeSpan.TicksPerMillisecond);
if (delay > 0)
{
Task.Delay(TimeSpan.FromMilliseconds(delay)).Wait();
}
if (repo.GetJob(job.Id).State == 0)
{
if (repo.AcquireJobLock(job.Id))
{
repo.ProcessLockedJob(job.Id);
Console.Write("[" + job.Id + "]" + "O");
}
else
{
Console.Write("[" + job.Id + "]" + "X");
}
}
}
}
跟 toyo0103 一樣,中規中矩的 code, 唯獨這邊留意到了 COST_SCORE 的問題,在真正 AcquireJobLock() 前先做一次 GetJob() 來確定是否真的需要 Lock ..
另外, 這 solution 一樣用了 BlockingCollection 來做 job 的分派管理. 唯獨一個不解的是, 其中硬生生的又把 BlockingCollection 包了一層, 對實際結果其實沒有任何影響, 只是好奇這樣的目的… 變成 Queue, 看來應該是習慣 pop / push 的用語吧? (這不是 stack 的用語嗎? XDD)
回頭來看看主要分派 job 的程式碼結構:
protected async override Task ExecuteAsync(CancellationToken stoppingToken)
{
ThreadPool.SetMinThreads(MAX_CONCURRENT_SIZE, MAX_CONCURRENT_SIZE);
Random random = new Random();
TimeSpan sleepSpan;
double runAtRange = JobSettings.MinPrepareTime.TotalSeconds;
for (int i = 0; i < MAX_CONCURRENT_SIZE; i++)
{
Task.Run(() =>
{
JobWorker jobWorker = new JobWorker(MAX_CONCURRENT_SIZE);
});
}
await Task.Delay(1);
using (JobsRepo repo = new JobsRepo())
{
while (stoppingToken.IsCancellationRequested == false)
{
JobInfo tmpJobInfo = null;
foreach (JobInfo job in repo.GetReadyJobs(TimeSpan.FromSeconds(runAtRange)))
{
Queue.push(job);
tmpJobInfo = job;
}
//計算SLEEP多久
if (tmpJobInfo == null)
{
sleepSpan = TimeSpan.FromMilliseconds((10 * 1000) + random.Next(5 * 1000));
}
else
{
sleepSpan = TimeSpan.FromSeconds((tmpJobInfo.RunAt.AddSeconds(random.Next(15)) - DateTime.Now).Seconds + 1);
}
await Task.Delay(sleepSpan, stoppingToken);
Console.Write("_");
}
}
}
主結構用了 Task 來啟動指定個數的 worker, 不過啟動之後卻沒有確定他跑完了才結束主程序… 這是需要加強的地方, 程序沒有明確的正常終止的過程。雖然如此, 這樣的 code 卻也沒有在 HATEST 裡碰到任何意外…
不過我看到一段比較詭異的 code, 摸不大清楚這段 code 背後真正的目的。抓完 GetReadyJobs() 後, 照道理應該等 10 sec 結束後繼續抓下一周期的 job 清單出來… 這邊看到了一段刻意插入的隨機動作:
如果這輪沒有抓到任何 job, 下一輪就等 10 +- 5 sec 才開始抓… 如果有, 就等到從上次最後一筆 job 預約時間再往後 15 sec 以後在開始抓下一輪…
其實在可以很精準控制的環境下,刻意加入這種隨機的因子,是有點冒險的。因為最長可能拖過 15 sec, 而題目規定的 prepare time 只有 10 sec 啊! 你可能會因此錯過了 10 ~ 15 sec 區間的 job.., 雖然最後一樣會被執行, 但是你可能趕不上而平白多增加了 0 ~ 5 sec 的延遲..
但是,把他錯開其實有其他好處的。我的測試都是同時啟動每個 instance, 很有可能每個 instance 的每個 thread 在執行 GetReadyJobs() 的時間點都一樣,加上 Random 有助於錯開這些時機。後來看測試結果才發現,原來這樣做也是有目的的。如果有多個 instance 同時在進行,也許漏掉 10 ~ 15 sec 的 job 並不是那麼嚴重,因為我漏掉了會有別人來補啊! 但是這樣一來,整體的 COST_SCORE 就會下降很多, 而 EFFICIENT_SCORE 還能維持在一定範圍內。
進一步觀察測試結果,更可以證實我的推論。看一下 1 instance 時, EFFICIENT_SCORE 的分數高達 5924.54 … 但是隨著 instance 數量拉高, 這分數快速的下降, 5924 是所有人 1 instance 時是後段班的成績, 但是拉到 3 instance 就擠進 1000 分以內了, 跑到最後竟然可以爬到 300% 以內的族群..
這些細節我會特別重視,反而我刻意忽略了部分工程上的細節,因為我覺得這問題本身的 domain 才是最需要深入探討的啊,其他工程上的問題只要方法到位了,實作的細節影響應該有限 (重點是比我厲害的人應該很多 XDD)。這些處理 domain 本身的做法,才是真正影響分數的主因。
不過,很多狀況都是我多慮了 XDDD, 即使 code 看起來有些潛在的隱憂,實際跑起來是運作的不錯的。首先,這 solution 成功的通過了 HATEST, 再來這樣的設計也創造了最低的 COST_SCORE 分數 (恭喜!!!)。至於 EFFICIENT_SCORE 分數,雖然有我擔心的那些問題,但是也跑出了 256.60 分的成績,擠進了 300% 的前段班。
PR4, LeviDemo
以下是 levichen 提交的 PR 跑出來的成績:
Benchmark:
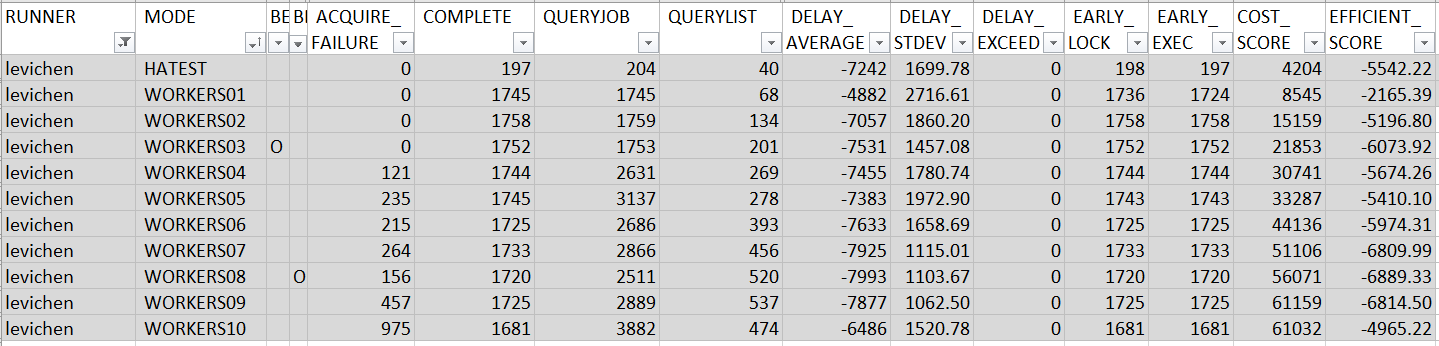
HA test: FAIL
這 PR 有點可惜, 看來是疏忽沒有改好就發 PR 上來了,沒有通過 HATEST 的測試。每一筆 job 通通都還沒到預定時間就執行了。所以 EFFICIENT_SCORE 的分數都是負的,被排除在排行清單之外了。
不過,雖然沒有通過基本的測試,但是不代表程式碼沒有值得探討的地方。levichen 選手自己刻了個 thread pool: SimpleThreadPool, 不論做的好壞, 能自己成功刻出來就已經代表觀念跟實作能力有一定的水準了。不過這不是我這篇的重點,哈哈…
主程式都以這個 thread pool 為主要核心去發展出來的, thread pool 的模式,背後其實就隱含了 queue 及 dispatch 到個別的 thread(s) 的機制了。所以剩下的環節,就是來看看主程式如何處理 jobs, 以及每個 jobs 如何被執行。
花了一點時間,找到執行 job 的片段:
while (_workItems.Count > 0)
{
JobInfo job = null;
lock (_workItems)
{
if (_workItems.Count > 0)
{
job = _workItems.Dequeue();
}
}
if (job == null) continue;
if (repo.GetJob(job.Id).State == 0)
{
if (repo.AcquireJobLock(job.Id))
{
repo.ProcessLockedJob(job.Id);
Console.WriteLine($"[Consumer][Done] #{job.Id}");
}
else
{
Console.WriteLine($"[Consumer][Failed] #{job.Id}");
}
}
// 後面省略
果然,一眼就看到 bug 在哪裡了 XDD, 這段 code 用了前面提到的技巧, AcquireJobLock() 前先查詢看看, 降低 COST_SCORE 較高的 lock 執行次數,畢竟 lock 失敗也算一次啊,盡可能確保真的能成功 lock 再去呼叫就好。不過這段 code 有個很嚴重的缺失, 就是完全沒有判定 RunAt 的時間到了沒這件事。按照 code 來看,就是拿到 job 就不管三七廿一就直接執行了, 每 10 sec 呼叫一次 GetReadyJobs(), 所以平均會 delay 5000+ msec 看起來就很合理了。
PR5, BorisDemo
以下是 borischin 提交的 PR 跑出來的成績:
Benchmark:
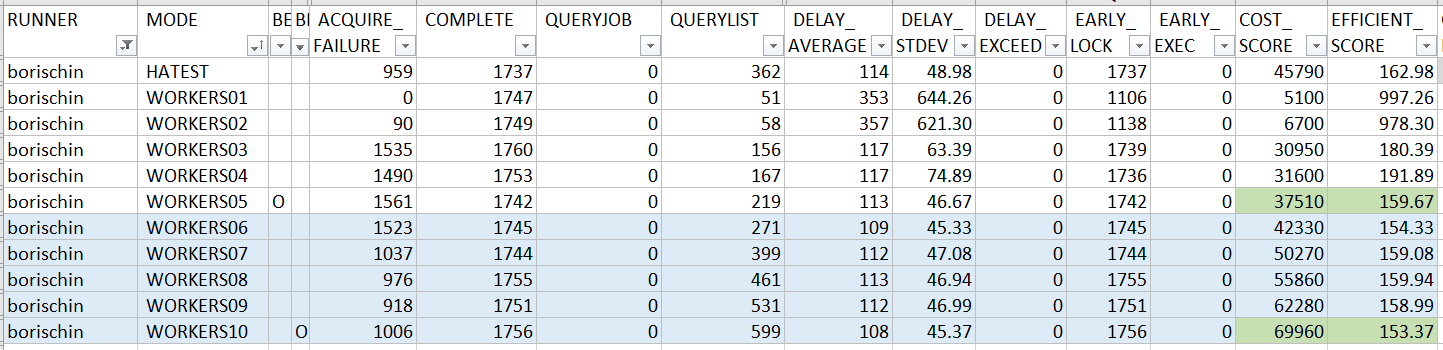
HA test: PASS(註)
開始評論 code 前先說明一下,這 code 在進行 HATEST 的過程中,碰到一些零星的 Exception… 這些 Exception 不影響測試的數據, 但是看到這些 exception message 噴出來時在有點惱人, 這類問題通常都是多執行緒的機制, 在 shutdown 時沒有好好地按照順序正常終止造成的。
我把攔截到的 exception message 貼一段上來參考:
System.AggregateException: One or more errors occurred. (A task was canceled.) ---> System.Threading.Tasks.TaskCanceledException: A task was canceled.
--- End of inner exception stack trace ---
at System.Threading.Tasks.Task.Wait(Int32 millisecondsTimeout, CancellationToken cancellationToken)
at System.Threading.Tasks.Task.Wait()
at SchedulingPractice.SubWorkerRunner.Program.Main(String[] args) in D:\CodeWork\github.com\SP\SchedulingPractice.SubWorkerRunner\Program.cs:line 87
---> (Inner Exception #0) System.Threading.Tasks.TaskCanceledException: A task was canceled.<---
接著來看看 code, 這 code 的結構很單純, 沒有包裝太多的 class 或是 interface, 所有邏輯都包在單一 method 內。不過除了風格不大一樣之外,大家的 code 處理模式都類似,都有一個 thread (或是 task) 負責從 JobsRepo 不斷的抓取 job 清單, 分配給其他 threads 等待啟動時間,及負責執行他。
code 我就不整段貼了。先來看 fetch (抓取清單) 的部分:
using (JobsRepo repo = new JobsRepo())
{
while (true)
{
foreach (var job in repo.GetReadyJobs(JobSettings.MinPrepareTime))
{
if (stoppingToken.IsCancellationRequested) break;
if (repo.AcquireJobLock(job.Id))
{
_queue.Add(job);
}
}
if (stoppingToken.IsCancellationRequested)
break;
try
{
await Task.Delay(JobSettings.MinPrepareTime, stoppingToken);
}
catch (TaskCanceledException ex) { }
catch (OperationCanceledException ex) { }
}
}
_queue.CompleteAdding();
這邊比較特別的是, 抓出 job 時不等到預定時間到達,就直接先 AcquireJobLock() 了, 然後再丟到 _queue (型別: BlockingCollection) 等待其他 threads 把他拿走去處理。
接著來看看處理的部分 code:
var threads = Enumerable.Range(1, ThreadCnt).Select(tid => new Thread(() =>
{
using (JobsRepo jr = new JobsRepo())
{
while (!_queue.IsCompleted)
{
JobInfo job = null;
try
{
Console.WriteLine($"Thread({tid}) is waiting for a job...");
_queue.TryTake(out job, 3000);
}
catch (OperationCanceledException ex)
{
Console.WriteLine($"Thread({tid}) stopped waiting for a job...");
}
if (job != null)
{
var diff = (int)(job.RunAt - DateTime.Now).TotalMilliseconds;
if (diff > 0)
{
Console.WriteLine($"Thread({tid}) is waiting to run job({job.Id})...");
Thread.Sleep(diff);
}
Console.WriteLine($"Thread({tid}) is running job({job.Id})...");
jr.ProcessLockedJob(job.Id);
Console.WriteLine($"Thread({tid}) processed job({job.Id}).");
//Console.Write("O");
}
}
}
})).ToArray();
foreach (var t in threads) t.Start();
除了提前 AcquireJobLock() 之外,後面的動作其實蠻標準的 (這也可以拿來當示範教材了 XD),很多工程及多執行緒的寫法都很標準也很到位。唯一可惜的地方,我想應該也是疏忽吧。當 _queue 已經空了, TryTake() 這 method call 應該會被 blocked. 不過這邊給了固定的 timeout 時間: 3000 msec, 而不是配合 CancellationToken 來中斷 blocking call, 也許就是這個地方造成 service shutdown 沒辦法正確的終止問題吧。
回頭來看看,這段 code 對於 “scheduling” 這件事本身來說做得如何? 由於 instance 執行時間應該都會錯開, 相較於 job 要執行前那瞬間才 lock (大家應該都會在那瞬間一起醒來), 有很高的機率會發生大家判定狀態都還沒 lock, 然後都同時要 lock, 最後只有一個人成功, 但是會花掉好幾個 lock 的動作 (COST…), borischin 選擇在 GetReadyJobs() 時就先 lock, 競爭那瞬間的機率大幅降低了。換來的好處,果然反應在成果上了。這 solution 拿到了不錯的 COST_SCORE (排第三), 同時在 EFFICIENT_SCORE (排第二) 也有不錯的成績,同時能拿下這兩個分數的前段班,算是很好的拿捏到一個平衡點了。
過早提前 lock 的缺點, 真的要說就是 worker 已經拿走了卻臨時被停止, 你必須避免已經 lock 卻沒辦法 process 的狀態了。因為你一但 lock 住這個 job, 就代表其他 worker 完全沒機會再去處理他了。也因此,這份 code 在處理 shutdown 狀況時, 不是把眼前這個 job 清空就可以退出了,是必須把所有擺在 _queue 裡面的 job 通通清空才能退出。
以這個 case 的設定, 最極端的狀況下, 一個 job 可能會提前 10 sec 就被 lock… 代表這個 worker 若這瞬間就收到 shutdown event, 他必須 “撐住” 10 sec 才能正常離開, 否則資料就會損毀了。然而 OS 不見得能保證能讓你跑完這 10 sec, 更何況 10 sec 這數值不是寫 code 的人決定的, 可能是依據商業邏輯來決定的…,以我們實際的 case, 可能有些狀況 prepare time 會拉長到 60 分鐘這樣的數字, 那就更不可能這樣設計了…。
不過,即使如此,這些是 production 上的考量, 畢竟題目的需求一開始就明定 10 sec, 我的結論還是一樣, 這 solution 算是取得很好的平衡點,同時兼顧 COST_SCORE 跟 EFFICIENT_SCORE 都有不錯的成績..
PR6, JulianDemo
以下是 Julian-Chu 提交的 PR 跑出來的成績:
Benchmark:
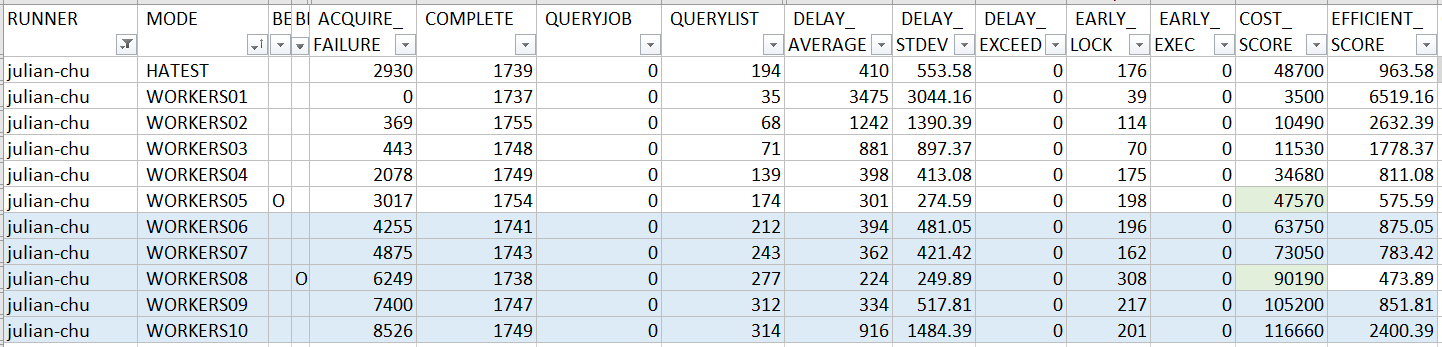
HA test: PASS(註)
Julian 的 PR, 在進行 HATEST 時也碰到零星的 exception:
System.AggregateException: One or more errors occurred. (A task was canceled.) ---> System.Threading.Tasks.TaskCanceledException: A task was canceled.
--- End of inner exception stack trace ---
at System.Threading.Tasks.Task.Wait(Int32 millisecondsTimeout, CancellationToken cancellationToken)
at System.Threading.Tasks.Task.Wait()
at SchedulingPractice.SubWorkerRunner.Program.Main(String[] args) in D:\CodeWork\github.com\SP\SchedulingPractice.SubWorkerRunner\Program.cs:line 87
---> (Inner Exception #0) System.Threading.Tasks.TaskCanceledException: A task was canceled.<---
看起來狀況都類似, 沒有按照預期順序終止之類的問題。同樣也不影響 HATEST 的結果,數據也正常,我就只列出來供參考。
延續上一篇的挑戰, Julian-Chu 同樣搬出了效能比 BlockingCollection 還要好的 Channel 出來應戰。BlockingCollection 把非同步的細節封裝起來了,但是他對外的 interface 則是完全以 sync 同步的型態呈現的。換句話說你如果想要用 async 非同步的方式去處理他,你得另外再包一層 Task, 這樣不但囉嗦多一道手續, 你也沒辦法很精準的掌握 async return 的時間點。換句話說要使用到 async 真正的好處, 你必須在 call stack 每一層都用 async 才行… 中間若經過 sync 包裝,然後再用 Task 提供 async 介面, 那就失去意義了, 你只會得到表面上的 async 使用方式而已。
撇除 Channel 跟 BlockingCollection 先天的差別, 兩者其實都是拿來處理生產者消費者問題的。我就不在這篇繼續探究了,我回到我們主要的 domain: scheduling 的處理。先來看看從 JobsRepo 取得 jobs 清單的 code:
var channels = new List<Channel<JobInfo>>();
for (int i = 0; i < maxChannelNumber; i++)
{
var ch = Channel.CreateBounded<JobInfo>(new BoundedChannelOptions(1)
{SingleWriter = true, SingleReader = true, AllowSynchronousContinuations = true});
channels.Add(ch);
}
foreach (var ch in channels)
{
DoJob(ch);
}
using (JobsRepo repo = new JobsRepo())
{
while (stoppingToken.IsCancellationRequested == false)
{
var newJobs = repo.GetReadyJobs(TimeSpan.FromSeconds(10)).ToList();
foreach (var job in newJobs)
{
var done = false;
while (!done)
{
foreach (var channel in channels)
{
var writer = channel.Writer;
if (writer.WaitToWriteAsync(stoppingToken).Result)
{
writer.TryWrite(job);
done = true;
break;
}
}
}
}
try
{
await Task.Delay(JobSettings.MinPrepareTime, stoppingToken);
Console.Write("_");
}
catch (TaskCanceledException)
{
break;
}
}
}
我不確定 Julian-Chu 寫這段 code 時心裡真正的意圖, 所以我試著猜看看… (歡迎留言告訴我你的想法)。主迴圈抓出 newJobs 清單後,下一步就是用各種方式分配下去執行了。這 code 開了 5 個獨立的 channel, 然後又在每個 job 試圖掃一次所有的 channel… 因為 channel 不見得隨時都能立刻寫入, 要經過 WaitToWriteAsync() 後才行。我猜這段的意圖,應該是要從 5 個 channel 找出最快能寫入的那個 channel, 但是按照 code 實際進行的狀況, 應該都會寫到第一個 channel, 沒什麼機會會寫到後面其他 channel …
如同前面的例子,不論是 Channel 或是 BlockingCollection 都好,他們本來就是要拿來解決生產者消費者問題的,因此整個機制應該只需要一個 channel 就夠了,這邊一次開了 5 個, 我想應該是還沒調整好的關係吧。如果只用一個 channel, 那也沒有所謂的 “挑選最快可以使用的那個 channel” 這需求了, 可以直接閃過前面討論的狀況。
當然這樣的作法結果還是對的,只是效益就沒有出來了。如果所有 job 都擠在同一個 channel, 而這個 channel 背後又只有一個 thread 在處理的話, 換個角度來說就沒有平行處理了。我刻意在 ProcessLockedJob() 裡面動了一點手腳,你要適度的平行處理才能拉高效能,我也在產生測試 job 的地方製造了這樣的 pattern: 會隨機在某些瞬間一口氣預約好幾筆 job 在同樣時間預約執行,目的就是要觀察大家的 code 是否能有效的紓解這樣的瓶頸。
比對一下結果: 由於大家的做法都雷同,整體的表現其實沒有太大的差距。 COST_SCORE 有在 300% 範圍內,只是 EFFICIENT_SCORE 就沒那麼幸運了,沒有擠進 300% 的範圍內。觀察 1 ~ 10 instance 的數據,可以看到 EFFICIENT_SCORE 仍有隨著 instance 數量提高而改善 (降低),代表還有優化的空間,只是進步的速度不如期他在單一 instance 內 (靠 thread) 就做好更完善優化的對手了。同樣的我沒有親自去驗證, 只是推測而已, 很有可能就是 channel 的機制沒有處理好, 在我故意製造的尖峰流量下就沒辦法顧好 EFFICIENT_SCORE 了,所以在這部分沒拿到應有的成績,實在可惜。
PR7, AndyDemo
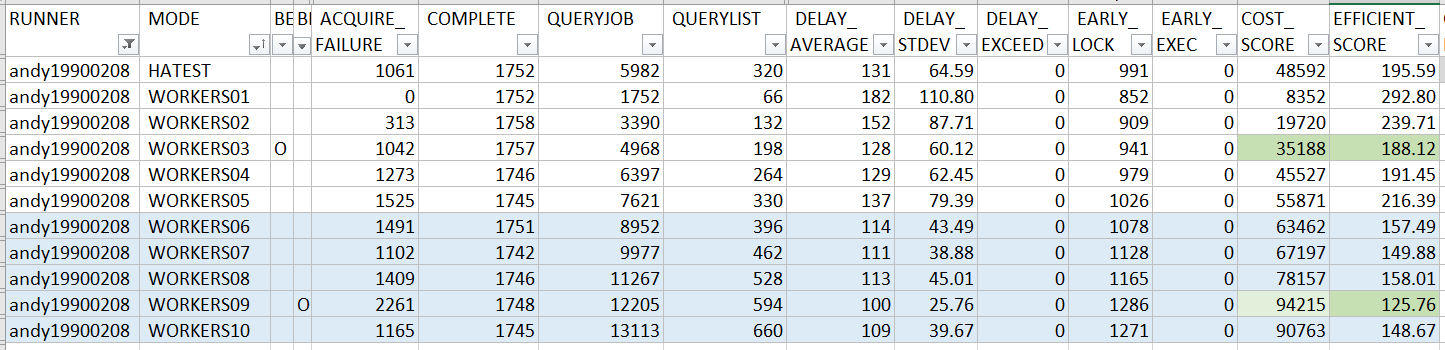
以下是 andy19900208 提交的 PR 跑出來的成績:
Benchmark:
HA test: PASS(註)
andy19900208 的 PR, 在進行 HATEST 時也碰到零星的 exception:
System.AggregateException: One or more errors occurred. (A task was canceled.) ---> System.Threading.Tasks.TaskCanceledException: A task was canceled.
--- End of inner exception stack trace ---
at System.Threading.Tasks.Task.Wait(Int32 millisecondsTimeout, CancellationToken cancellationToken)
at System.Threading.Tasks.Task.Wait()
at SchedulingPractice.SubWorkerRunner.Program.Main(String[] args) in D:\CodeWork\github.com\SP\SchedulingPractice.SubWorkerRunner\Program.cs:line 87
---> (Inner Exception #0) System.Threading.Tasks.TaskCanceledException: A task was canceled.<---
看來大家清一色都碰到類似的狀況,我沒有花時間下去追查,就單純列出紀錄供參考。
回到解決問題的主軸,來看看解法。先看看 fetch 的部分:
using (JobsRepo repo = new JobsRepo())
{
while (stoppingToken.IsCancellationRequested == false)
{
DateTime LastQueryTime = DateTime.Now;
foreach (JobInfo job in repo.GetReadyJobs(JobSettings.MinPrepareTime))
{
if (stoppingToken.IsCancellationRequested == true)
{
break;
}
if (repo.GetJob(job.Id).State == 0 && repo.AcquireJobLock(job.Id))
{
if (job.RunAt > DateTime.Now)
{
await Task.Delay(job.RunAt - DateTime.Now);
}
queue.Add(job);
}
}
if (stoppingToken.IsCancellationRequested == false
&& LastQueryTime.Add(JobSettings.MinPrepareTime) > DateTime.Now
)
{
await Task.Delay(LastQueryTime.Add(JobSettings.MinPrepareTime) - DateTime.Now);
}
}
}
這裡的做法,跟前面 borischin 的做法類似,都是在主要迴圈查詢所有待處理的 jobs 清單時就預先把該做的程序都處理掉了。包括 AcquireJobLock()… 不同的是, 這邊也採用了先花點成本先查詢 GetJob() 後再決定要不要 AcquireJobLock() 的做法。比 borischin 更進一步的是,連同等待到預約時間開始的這段邏輯,都搬到這裡了。等待到預約時間到了之後,才把 job 放到 queue (型別: BlockingCollection) 內。放到 queue 的 job 馬上就會被背後的 threads 拿走立刻處理。
確認一下背後的 worker threads 做的事情:
using (JobsRepo repo = new JobsRepo())
{
foreach (JobInfo job in this.queue.GetConsumingEnumerable())
{
repo.ProcessLockedJob(job.Id);
}
}
就如前面所說,所有的準備動作都在前半段的部分處理掉了,worker threads 負責的任務很單純,拿出 job 就執行了。接著來看看這樣的做法效果如何。
從總表來看,andy 的解決方式,特性跟 borischin 的很類似, 都在 COST_SCORE 與 EFFICIENT_SCORE 取得不錯的平衡點, 兩項分數都有進入排行 (綠色)。不過兩者的 COST_SCORE 與 EFFICIENT_SCORE 則互有領先,我推測原因應該是:
AcquireJobLock()前的GetJob()發揮作用, 雖然這結構在同瞬間去搶 lock 的機會比其他人低很多, 但是看來GetJob()的確可以把COST_SCORE再往下降一些。- 如同前面例子提到, 適度的平行處理在這個題目是有直接幫助的。產生測試情境的 code, 我刻意加入了會瞬間有多筆 job 同時預約執行的情境。這結構把所有事情 (除了
ProcessLockedJob()之外) 都處理完才丟到後端的 worker threads, 代表前面這段是沒辦法平行處理的。因此我預期再這邊若瞬間有多個 job 預約同時間執行, 這作法會在EFFICIENT_SCORE的表現略差
從數據上證實了這個推測,我建議 andy19900208 可以花點時間驗證看看真正原因是否如我猜想。事實上如果再看 andy19900208 的 1 ~ 10 instances 測試數據可以進一步證明, EFFICIENT_SCORE 是有隨著 instances 數量增加而逐步改善,證明平行處理是還有改善空間的,只是 instance 內的 threads 只能幫助一部分,還是需要靠多個 instance 才能進一步分攤這些 loading …
連同上一篇文章的 PR 一起看, andy19900208 的 code 表現一樣精簡 & 洗鍊, 可以在 100 行以內搞定這題目, 而且程式碼看起來一樣很舒服, 不像是那種硬要縮減行數的寫法… 這只有本身思路就已經把邏輯想的很收斂才辦的到。 雖然沒有多提, 但是在多執行緒的處理、非同步的處理、還有程式碼本身都寫得很洗鍊,一樣是可以拿來當作教材的好範本。
示範專案
最後終於輪到我自己了。我在出題的當下就準備好一份 code 了,因為這同時也是公司某專案需要解決的問題啊 XDDD, 所以當時就先寫了一份,只是事後一樣有為了這篇文章的練習做一些簡化與調整。我就把他也貼上來附在最後面了。評論就不用了 (我自己的 code 有啥好 review 的?),我說明一下我寫這段 code 背後的想法:
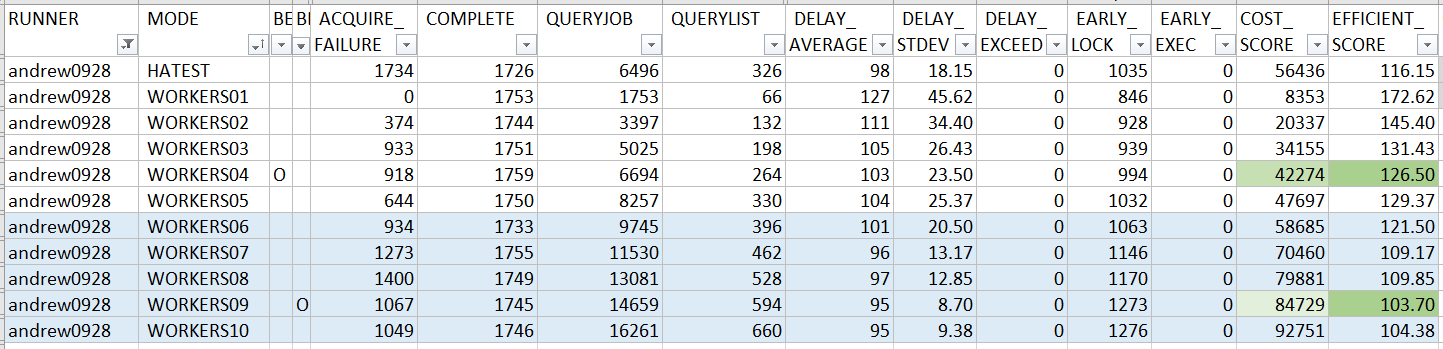
Benchmark:
HA test: PASS
public class AndrewSubWorkerBackgroundService2 : BackgroundService
{
private int _process_threads_count = 10;
private BlockingCollection<JobInfo> _queue = new BlockingCollection<JobInfo>();
private CancellationToken _stop;
protected async override Task ExecuteAsync(CancellationToken stoppingToken)
{
await Task.Delay(1);
this._stop = stoppingToken;
// init worker threads, 1 fetch, 5 process
Thread[] threads = new Thread[_process_threads_count];
for (int i = 0; i < _process_threads_count; i++) threads[i] = new Thread(this.ProcessThread);
foreach (var t in threads) t.Start();
// fetch
Stopwatch timer = new Stopwatch();
Random rnd = new Random();
using (JobsRepo repo = new JobsRepo())
{
while(true)
{
if (stoppingToken.IsCancellationRequested) goto shutdown;
timer.Restart();
Console.WriteLine($"[T: {Thread.CurrentThread.ManagedThreadId}] fetch available jobs from repository...");
foreach (var job in repo.GetReadyJobs(JobSettings.MinPrepareTime))
{
if (stoppingToken.IsCancellationRequested) goto shutdown;
int predict_time = rnd.Next(300, 1700);
if (job.RunAt - DateTime.Now > TimeSpan.FromMilliseconds(predict_time)) // 等到約一秒前,可以被取消。一秒內就先 LOCK
{
try { await Task.Delay(job.RunAt - DateTime.Now - TimeSpan.FromMilliseconds(predict_time), stoppingToken); } catch { goto shutdown; }
}
if (repo.GetJob(job.Id).State != 0) continue;
if (repo.AcquireJobLock(job.Id) == false) continue;
if (DateTime.Now < job.RunAt) await Task.Delay(job.RunAt - DateTime.Now);
this._queue.Add(job);
}
try {
await Task.Delay(
(int)Math.Max((JobSettings.MinPrepareTime - timer.Elapsed).TotalMilliseconds, 0),
stoppingToken);
}
catch
{
goto shutdown;
}
}
shutdown:
this._queue.CompleteAdding();
}
foreach (var t in threads) t.Join();
Console.WriteLine($"[T: {Thread.CurrentThread.ManagedThreadId}] shutdown background services...");
}
private void ProcessThread()
{
using (JobsRepo repo = new JobsRepo())
{
foreach(var job in this._queue.GetConsumingEnumerable())
{
repo.ProcessLockedJob(job.Id);
Console.WriteLine($"[T: {Thread.CurrentThread.ManagedThreadId}] process job({job.Id}) with delay {(DateTime.Now - job.RunAt).TotalMilliseconds} msec...");
}
Console.WriteLine($"[T: {Thread.CurrentThread.ManagedThreadId}] process worker thread was terminated...");
}
}
}
其實我的結構跟大家大同小異,主結構負責 fetch jobs, 另外養了多個 threads 去等待 & 消化這些 jobs, 中間就靠 BlockingCollection 來協調兩端的進度。不同的是,我在參數與處理的細節,特地多花了一點心機來調教…。我比各位的做法多花了這些功夫:
-
透過測試找出最佳的 worker threads count:
大家其實都被我題目的假設誤導了。雖然我很明確的說 process 裡面有動手腳,Semaphore限定最高上限 5 threads… 但是不代表 worker thread 只做 process job 這件事啊! 他只是大部分,或是比重最高的一個部份而已。我花了點時間去測試 threads 開多少才最適合, 最後 10 threads 是我測試的結果。 -
提早 lock 爭取時效, 同時又要盡可能避免過早 lock 造成 shutdown 時的風險:
這點跟幾位的做法類似,例如 borischin / andy19900208 就選擇了 fetch 時 “順手” 一起AcquireJobLock()一樣。只是我顧及 shutdown 時也希望能在一定時間內就完成關機,因此我控制在 1 sec 前才 lock, 限定提前 lock 的時間別偷跑太多… 這樣就能兼顧效能與關機需要的處理時間。經過這樣處理,我可以控制在隨時都能在 1 sec 內完成 shutdown 的動作。 -
避免碰撞,提前 lock 的時間加入隨機的漂移, 盡可能讓
GetJob()能準確判斷狀態:
因為有多個 instance 彼此競爭,很有可能每個 instance 同一瞬間都去GetJob()拿到狀態是未 lock, 就同時都去執行AcquireJobLock(), 太過精準就導致這個方法失效了。我的做法就是把提前 1 sec 執行 Lock 這件事,加上一點亂數讓他前後有點誤差,飄移一點,時間錯開的話碰撞的機率就會降低了。因此提前 1 sec 我改成 1 sec +- 700 msec (也就是從 300 msec ~ 1700 msec 隨機決定), 讓主要結構不改變的前提下,進一步降低COST_SCORE,同時也可以在 1700 msec 內完成 shutdown 的動作。
我心裡在寫這些 code 的時候, 我其實是把 EFFICIENT_SCORE 擺在第一位的,我的目標是要盡一切可能壓低 EFFICIENT_SCORE, 至於 COST_SCORE, 我只要壓低到我覺得合理的程度就夠了。也因為這樣的策略,我拿下最低的 EFFICIENT_SCORE, 而 COST_SCORE 也佔到前段班的成績。
不過容我自豪一下,總表的分數,是取每個人所有表現裡面 EFFICIENT_SCORE 最好的那筆出來當代表… 我看了一下我自己的 1 ~ 10 instance 成績, 發現…
其實我不用挑最好的那筆,EFFICIENT_SCORE 也可以拿到第一名啊 XDDD, 何況 instances 降低了,COST_SCORE 也會跟著降低,如果單純要拚排名, 其實我拿 WORKERS02 那筆紀錄, EFFICIENT_SCORE 就已經是 145.40,COST_SCORE 是 20337, 足以拿到兩個分數都是第一名…
不過,比起名次,能把效能推到極致對我來說更重要一點 (尤其這是個練習不是嗎?)。撇開平衡的選擇,我更在意若需要極致的效能時,我能做到的極限在哪裡? 這樣真正在 production 環境下,我才有更寬廣的空間可以選擇。這次練習我就選擇 EFFICIENT_SCORE 最好的這組來應戰了。
結論
最後,經歷三個月,總算把這篇文章的後半段補完了。雖然現今的軟體開發,絕大多數的應用都已經有現成的套件了,連服務都有雲端廠商幫你把 IaaS / PaaS / SaaS 都架好了,只等你開起來用。不過即使如此,你仍然有很多機會需要自己打造自己的基礎服務。通常,若你需要高度整合的解決方案,你就得認真評估到底是整合現成的 solution, 或是自己打造來的好了。整合現有方案,你沒有主控權;整合的成本也要看目標服務跟你期望的落差有多大? 落差越大整合的成本越高。
另一個考量 (特別是 SaaS 的開發團隊),則是你要評估好 application 跟 infrastructure 的分界。我常跟同事聊這件事, 如果來自 application level 的行為, 要觸發 infrastructure level 的動作,那麼你要小心了 (例如 user 只是填填資料按下滑鼠你就要自動開一台 VM),這是不對等的動作,你的 application 可能需要很大的權限,才能觸動 infrastructure 的動作。這時就系統的角度,或是經營的角度,或是成本的考量,甚至是資訊安全的角度來說,都不是個適合的方案。
這時,對應的動作也由 application level 來服務,可能是個較合適的解決方案。因此開發 SaaS 服務時,有些你習以為常的服務你就得認真評估是否該自己打造? 排程服務就是一例,你如果不評估如何自己有效的處理他,而是一股腦地把資料庫裡的排程資訊倒到 crontab 的話,未來的管理跟維護都會是個災難。
因此,我常常會在腦袋裡練習,思考很多習以為常的服務 “如果” 我必須自己打造的話該怎麼做? 這個練習就是這樣發想出來的。你當然不需要任何事情都自己打造,但是還是那句話,如果你有能力重新發明輪子,你在各種極端的狀況下會有更強的適應能力。這些能力備而不用,而不是看到任何東西都像釘子,都想要拿起槌子敲下去。
為了不走火入魔,所以這次練習我其實刪減了很多實作的細節,盡量做到讓大家能好好思考背後的作法,同時又不會掉到自己重新發明輪子那冗長無效率的過程。希望這次大家都能從中學到一些經驗。
再次感謝這次發 PR 給我的朋友們,有你們的貢獻我才有題材可以寫這篇文章,希望下次有新的主題各位還可以繼續捧場 :)
