前面兩篇聊了不少 CLI / PIPELINE 開發的技巧跟基本功夫,這篇換個方式,來聊聊後端工程師該如何自己練習基本功夫吧。這次談的是 “精準” 控制的練習。
![]()
我在公司負責架構的團隊,兩個月前,我出了個練習題讓團隊的人練習,目的是測驗大家對於處理大量複雜的任務的精準程度。所謂的 “精準”,是指你腦袋裡面能很清楚的掌握你 “期望” 程式該怎麼跑,以及實際上你的程式是否真的如你預期的執行。這篇文章,我想換個方式,把這練習題的 source code 公開出來,用實際的 Hands-On Labs 練習的方式來進行。有興趣的朋友可以親自練習看看。練習的目的,是讓你思考如何精準的處理任務,而不是學習一堆大部頭的框架,因此我設計的這練習題,你只要熟悉基本的 C# 語法與 BCL (Basic Class Library) 就足以應付了,困難的地方在於你如何解決問題。
練習可以很簡單,也可以很複雜;我還蠻想試看看收集大家的解法,在這篇文章的後半段統一做個評論的;如果你願意將你的 solution PR 放上來,我會在後半段用我的角度幫你 code review 當作回報。之前會想在內部讓 team member 做這練習,目的很簡單,現在的工程師越來越容易忽略掉一些開發的基礎能力,面臨問題就越來越依賴外部的工具或服務來解決。使用不得當,往往就會在執行效率,程式碼維護,或是系統維運的階段付出代價。我們都用 public cloud, 光是 VM 的 instance 數量就超過百台,工程師們你知道你寫的 code 會直接反映在成本上嗎? 只要改善 1% 的效能,每個月的費用成本就可以降低 1% …, 這情況在你的流量很大的時候,加上背後的運算資源都來自雲端服務時會更明顯…。
因此,在公司我都會跟工程師在一對一面談的時候,問問 developer 自己是否想過這些問題:
- 你是否能很 精準 的掌控你寫出來的 code ?
- 你是否清楚了解你面對的問題 理想 的效能在哪裡?
- 針對效能這件事,你是否有明確的 指標 來量化及評斷每個 solution 的好壞?
- 你的解法離 理想 情況還有多遠? 是否還有改善空間? 還是已經到理論極限了?
後端工程師免不了必須解決很多效能及穩定度的問題,因此 “精準” 的掌握你程式碼在做啥事,我覺得是很關鍵的一點。商業邏輯我想你寫得出來大概都沒問題,但是每當我講到平行處理 (例如非同步、多執行續、或是 scale out) 等等議題時,我發現能清楚掌握的人就少的多了。大部分的人都停留在多開幾個 threads, 或是丟到 thread pool, 或是多開幾個 VM 用 scale out 的方式來解決就了事了。如果討論我們多執行緒應該怎麼安排這些任務的處理規則,能精準地寫出來的人又少了一大半…。
我設計了一個 class library (ParallelProcessPractice.Core), 函式庫內我定義了一個類別 MyTask,他的 instance 必須按照順序呼叫 DoStep1(), DoStep2(), DoStep3() 才算完成。練習的題目就是: 你必須處理完 1000 個 MyTask 物件才算完成任務。處理過程中有些限制需要留意:
- 每個 task instance 的 Step 必須按照順序進行。
- 每個 Step 的平行處理數量是有上限的。
- 不同的 Step 執行時需要花費的時間不同。
- 每個 task instance, 每個 step 執行過程都需要 allocate 不同的 memory, step 一開始就會 allocate memory, 結束才會 free memory。
會定義這些規則,目的就是希望 developer 在解題的過程中,必須知道你用的方式會花費多少資源? 例如 (4), 你就不能無限制地開啟任意數量的 threads 來處理, 過多的 task 都在處理中, 你的 memory 可能會爆掉;受限於 (1) 的限制, 你開啟過多 threads 不會得到對等的效能提升,會被 (2) 的上限綁住,過多的 threads 只是浪費資源而已。
題目會用 IEnumerable<MyTask> 的方式交付 100 個物件,你的目標是寫一個 Runner 接到 MyTask, 把它消化完畢就對了。不限定你用任何方式或是框架來處理。不過,我會看這幾個指標來判定你做出來的品質:
- 主要目標: 是否有確實完成每個 Task? 每個 Task 都必須按照順序完成每個 Step。
- 品質指標 1: 過程中最大的 WIP (WIP: Work In Progress, 半成品, 只要開始 step1 而未完成的 task 都算) 數量。
- 品質指標 2: 過程中占用的 memory size 最大值 (max memory allocated)。
- 品質指標 3: 程式啟動後,第一個 task 完成所需要花費的時間 (TTFT, time to first task)。
- 品質指標 4: 所有 Task 處理完畢的時間。
準備好接受挑戰了嗎? 現在就去下載題目來試著解看看吧! 這篇文章我會分成前後兩段來發布。前半先發布題目,如果你有意願的話,在一個月內 (時間 FB 我會說明),在 GitHub 把你的 Runner 發 Pull Request 給我, 我會在後半段發布的內放上 PR 給我的 code, 並且評論一下每種解法的優缺點。
平常在做 code review 很難深入到這樣的問題啊 (要是真正有 deadline 的專案,用這樣的標準來 code review, 大概整段 code 都會被我翻掉),在動手寫 code 之前就先做好充分練習才是根本之道,因此我就出了這樣的練習題給 team member 試看看,發現效果還不錯,於是就擴大範圍,也讓其他有興趣的朋友們參與看看。
當然我還有另一個動機: 招募。我也希望能藉這機會找到有心想磨練自己基本功的工程師,這樣的 code 交流我相信比面試聊上一個小時精準的多了。最重要的是透過這樣的方式,你會更清楚知道團隊的要求,你也可以藉這機會試試自己能力;加入團隊後會有更多這樣的挑戰與應用的機會。這不見得是件輕鬆的事情,但是如果你有興趣,這絕對是個難得的機會。
解題規則說明
現在就開始捲起袖子,動手練習吧! Source Code 請到我的 GitHub Repo: ParallelProcessPractice 自行取用。
1, 建立並執行你的 TaskRunner
規則很簡單,我把題目的部分都封裝在 ParallelProcessPractice.Core 這個 .NET core 的 class library 內了。你只要另外用 console app project, 繼承 TaskRunnerBase, 寫一個你自己版本的 TaskRunner, 然後在 Main 裡面啟動他就可以了。
隨題目我附上一個很無腦的 demo, 只是示範最低標準能 pass 主要目標的版本,單純示範答題規則而已。請參考 AndrewDemo 這個 project, 基本上就是用 for loop 把每個 task 的 DoTaskN() 從 1 ~ 3 分別執行一次而已,完全沒有平行處理也沒有最佳化,各位就當作墊底的競爭者吧,理論上你應該不會寫出比這個 demo 還慢的版本…
規則很簡單,第一,先準備一個你的 TaskRunner:
public class AndrewTaskRunner : TaskRunnerBase
{
public override void Run(IEnumerable<MyTask> tasks)
{
foreach (var task in tasks)
{
task.DoStepN(1);
task.DoStepN(2);
task.DoStepN(3);
}
}
}
然後,在 Main() 內這樣啟動你的 Runner 就夠了:
class Program
{
static void Main(string[] args)
{
TaskRunnerBase run = new AndrewTaskRunner();
run.ExecuteTasks(100);
}
}
2, 檢查 console output
執行完畢之後,會有兩個地方可以看到執行結果。第一個是 console output:
Execution Summary: AndrewDemo.AndrewTaskRunner, PASS
* Max WIP:
- ALL: 1
- Step #1: 1
- Step #2: 1
- Step #3: 1
* Used Resources:
- Memory Usage (Peak): 1536
- Context Switch Count: 300
* Waiting (Lead) Time:
- Time To First Task Completed: 1443.1671 msec
- Time To Last Task Completed: 143032.4147 msec
- Total Waiting Time: 7223482.8365 / msec, Average Waiting Time: 72234.828365
* Execute Count:
- Total: 100
- Success: 100
- Failure: 0
- Complete Step #1: 100
- Complete Step #2: 100
- Complete Step #3: 100
C:\Program Files\dotnet\dotnet.exe (process 6368) exited with code 0.
Press any key to close this window . . .
3, 進階監控資訊 (csv) 說明
Console output, 基本上就已經顯示了主要目標與品質目標的數值了。不過只看這些指標,對於我要求的 “精準” 還有段距離… 我同時準備了另一個紀錄檔,在跟執行檔同目錄會輸出成 .csv, 可以看到執行過程中更詳細的數據, 裡面會有執行過程中不斷記錄下來的幾個關鍵指標:
TS,MEM,WIP_ALL,WIP1,WIP2,WIP3,THREADS_COUNT,ENTER1,ENTER2,ENTER3,EXIT1,EXIT2,EXIT3,T1,T2,T3,T4,T5,T6,T7,T8,T9,T10,T11,T12,T13,T14,T15,T16,T17,T18,T19,T20,T21,T22,T23,T24,T25,T26,T27,T28,T29,T30
8,0,0,0,0,0,0,0,0,0,0,0,0,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
32,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
60,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
90,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
120,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
150,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
180,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
210,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
240,1536,1,1,0,0,1,1,0,0,0,0,0,1#1,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
(以下略)
繼續之前先簡單說明一下欄位的意義:
- TS (time stamp): 該筆資料的時間,從 Runner 啟動開始計算 (單位: msec)。
- MEM: 當下模擬的 memory 使用量
- WIP(ALL,1,2,3): 當下在處理中狀態的 Task 總數
- THREADS_COUNT: 當下所有正在處理 Task 的執行緒總數
- ENTER / EXIT: 當下已經開始/已經結束第N個步驟的 Task 統計總數
- T1 ~ T30: 當下每個 thread (最多顯示 30 個執行緒) 正在處理的 Task 資訊 (格式: {Task序號}#{Step} )
做成 csv 為的是方便你用 excel 打開,直接用圖表來將你的執行成效視覺化用的。舉例來說,前兩個欄位 TS (time stamp, msec) 跟 MEM (allocated memory, bytes) 我把它用 excel 繪製成圖表的話,就可以看到這樣的 chart, 模擬像是你用 visual studio profiler 這類工具來監控你程式執行過程:
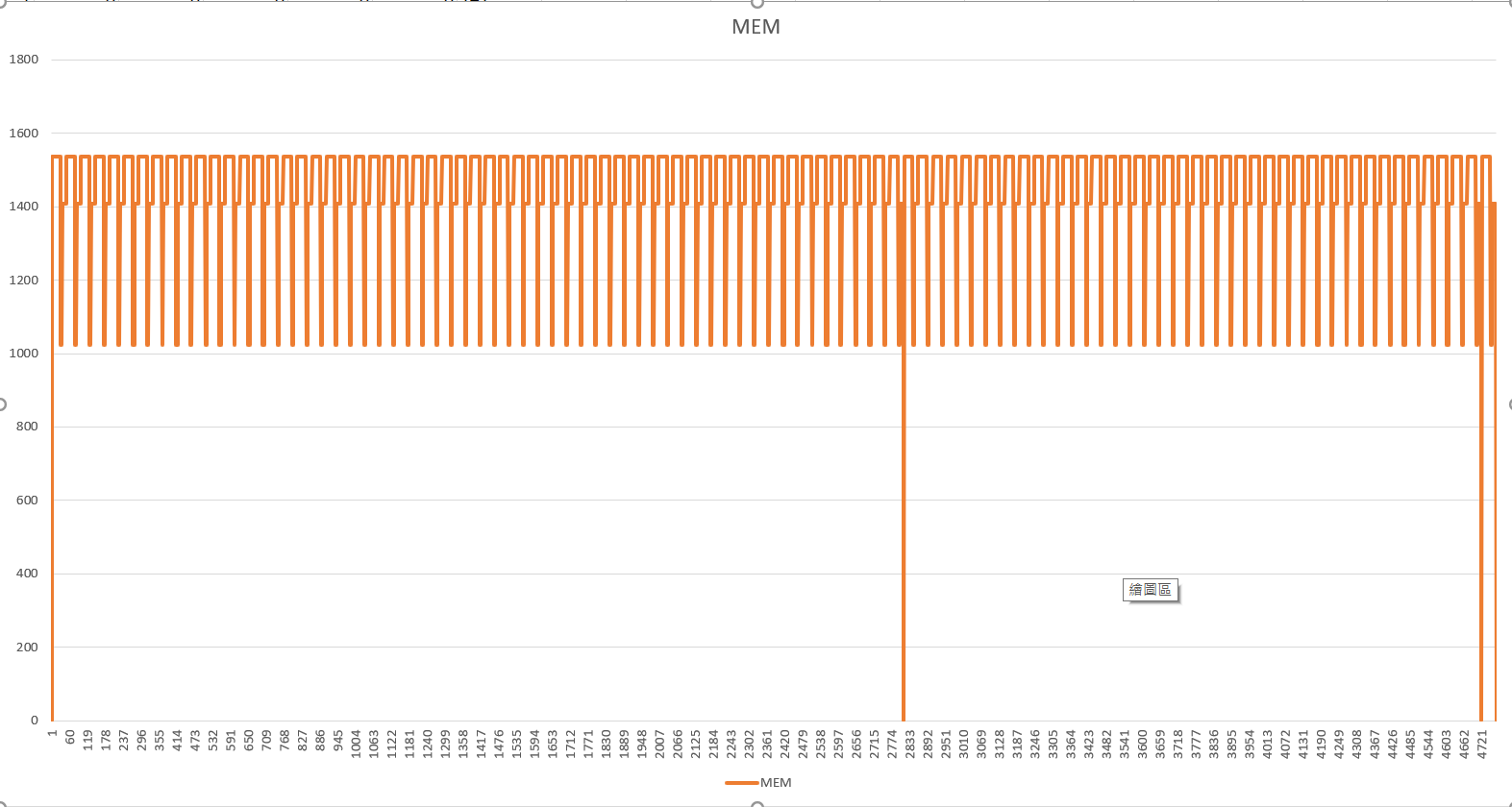
不過,這個版本的 code 實在太單調了,完全看不出啥效果… 我換一個我自己用 thread pool 的 Runner, 拿 TS 當 X 軸, MEM 當 Y 軸,就可以看記憶體使用量:
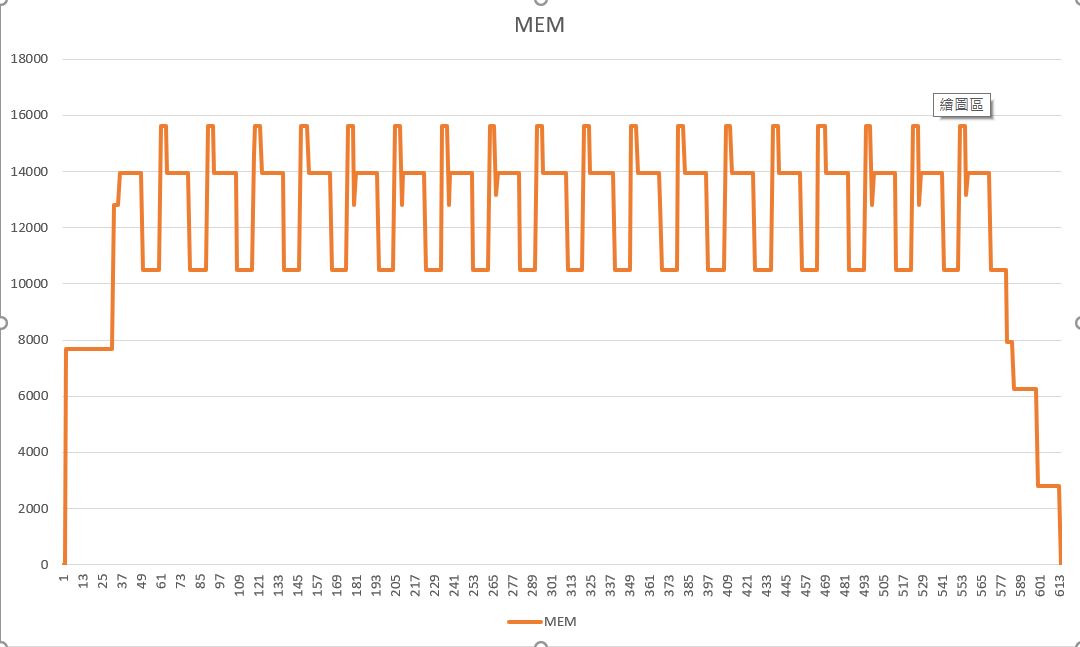
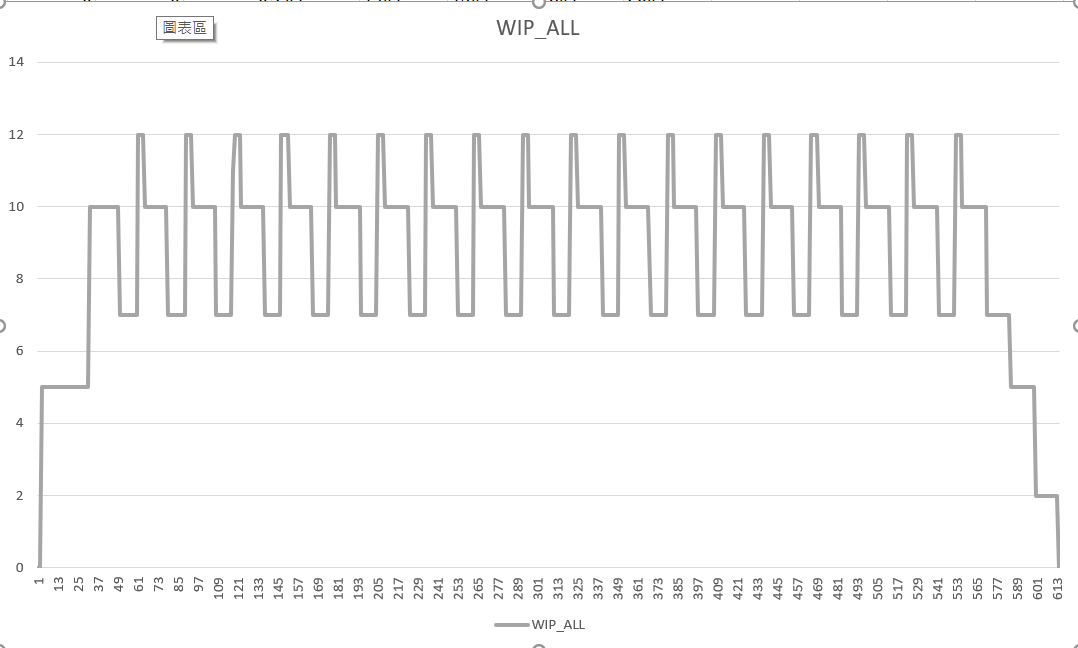
其實 .csv 內還藏了不少數據, 再來看看其他數據: WIP1 ~ WIP3, WIP_ALL, 分別代表在 Step1 ~ Step3, 以及所有未完成的 task(s) 總數:
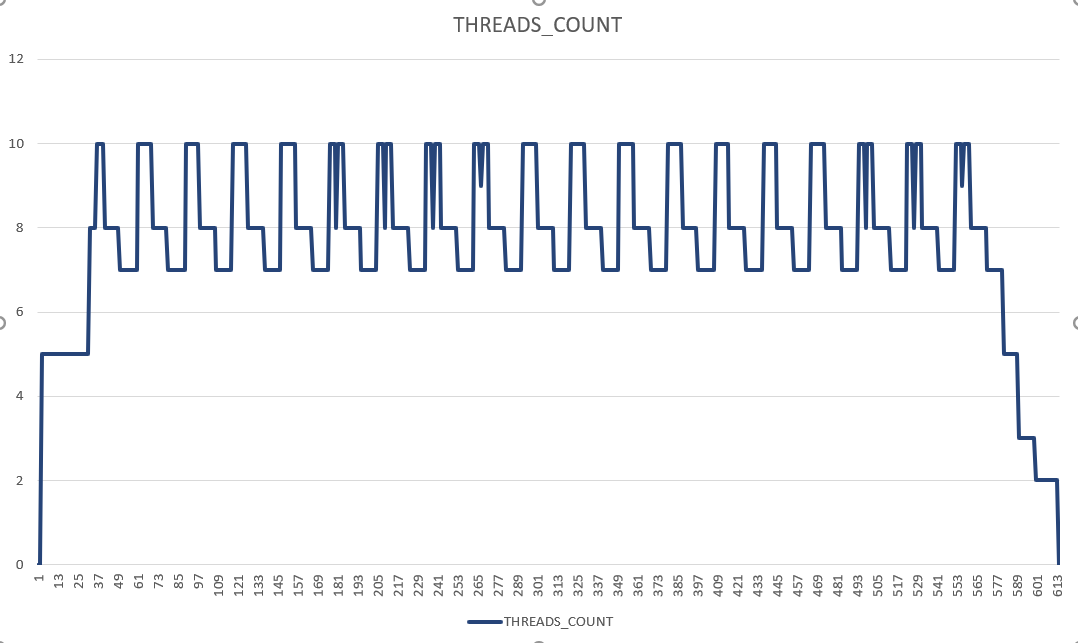
如果我想看看 thread pool 背後到底動用了多少執行緒出來工作,打開 THREADS_COUNT 欄位可以看到過程中同時有多少個 threads 並行:
最後,如果我真的想看每個瞬間,每個 thread 到底都在幹嘛,來看看最後 T1 ~ T30 的欄位… 這就不是看圖表了,直接看表格的內容。我在 EXCEL 表格的格式加了工,把同一個 Task 用粗的框線框起來,讓視覺化更明顯一點:
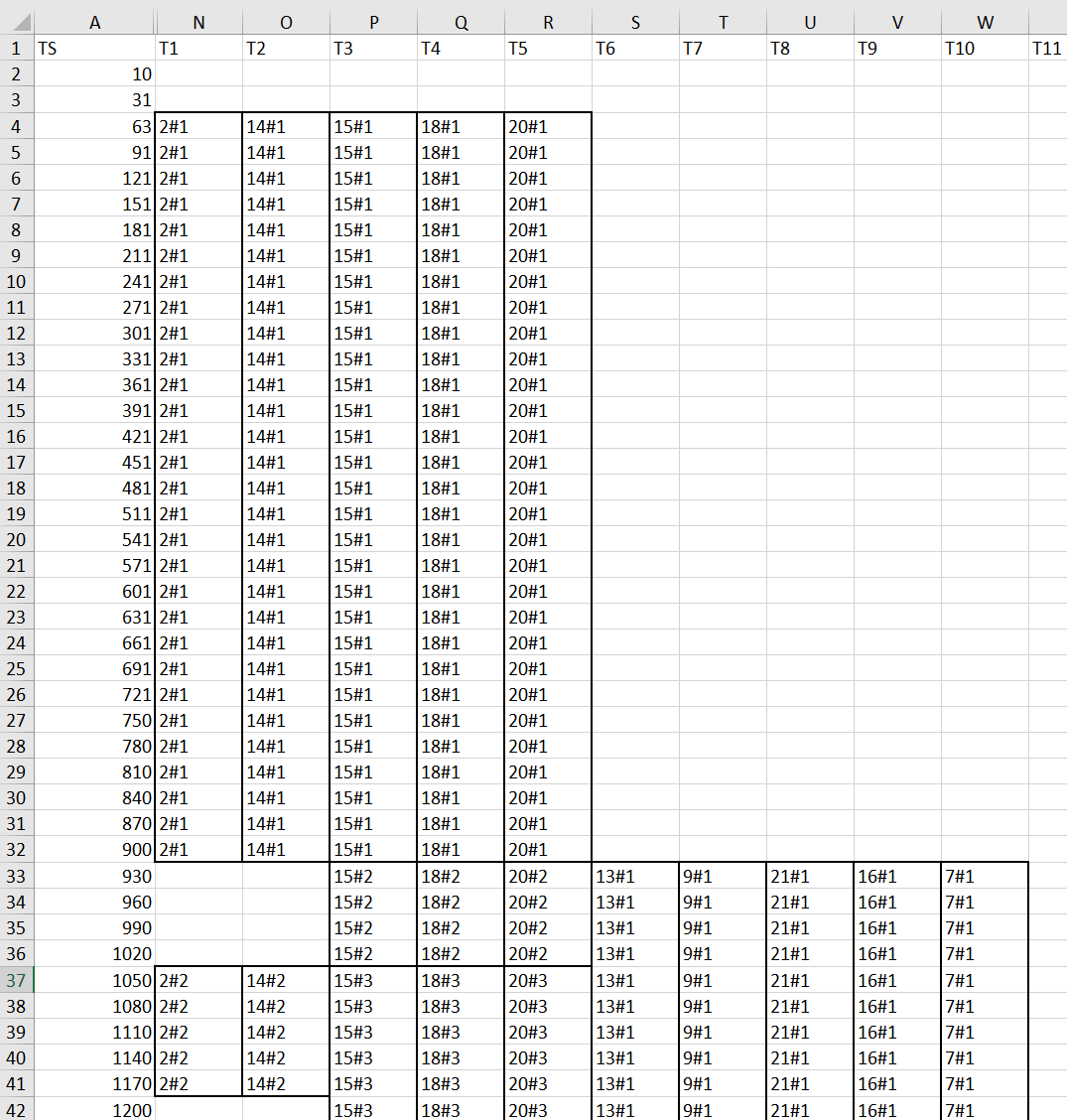
TS 代表程式開始執行的時間 (單位: msec), T1 ~ T30 則代表我最多會顯示每個時間點,每個 thread 都在做啥事,T1 代表第一個 thread, T2 代表第二個,以此類推。至於表格內的數字,如 14#1, 則代表 第 14 個 task 的第一個步驟,我加上了框線,讓大家看得清楚一點,從上到下,可以看到你的 task 是如何被分配到每個 threads 執行的。你會發現,因為平行運算被受到限制,並不是每個 threads 都隨時保持忙碌的,中間空白的部分代表這個 thread 正在發呆,沒有任務可以進行。
到目前為止,這些資訊都是為了讓你 精準 的了解你的 code 到底是怎麼跑的,對於效能好壞也有個明確的指標可以評估。寫到這裡,你應該有所有足夠的資訊,可以用來了解你的 solution 實際執行狀況了。剩下的考驗,就是你是否能想出最佳的解法? 這些資訊可以協助你驗證,你的 code 是否真的很精準地照你的想法在執行?
品質指標的挑選
前一段說明了答題的規則,以及如何看輸出的資訊。接下來這段我們就來探討一下這些指標背後的意義與用意吧。
要通過這個測驗,其實很簡單,我附上的 AndrewDemo project, 寫個 for loop, 10 行以內的程式碼就可以搞定了,但是要比較出好壞,那就要花點心思。我這邊說明一下為何我要挑選這幾個指標來評斷 code 的優劣。這些指標,其實都可以對應到各位日常碰到的實際案例,我就一一來說明。很多指標其實在前兩篇也都帶到了,有興趣的朋友也可以參考前面的文章:
- 後端工程師必備: CLI + PIPELINE 開發技巧, 2019/06/15
- 後端工程師必備: CLI 傳遞物件的處理技巧, 2019/06/20
指標: 最大處理中任務數 (Max WIP)
這裡指的 “半成品” (WIP, Work In Progress) 數, 就是指同一瞬間,有多少 Task 是處於 DoStepN(1) 已經開始,而 DoStepN(3) 還沒完全結束的階段。
為何我會拿 WIP 當作指標? 對應到現實世界的 Task, 通常啟動後就會占用一些資源,從 temp file, memory cahce, memory buffer, 甚至是為了處理任務過程中需要的 temp object 等等都算。如果你用了各種平行處理的技巧來加速,別忘了每存在一個 WIP, 背後這個 Task 就要占用一些資源, 直到 Task 結束為止。這些資源要在 DoStepN(3) 結束後才會被釋放,如果佔用的是很有限 (或是成本很高) 的資源,那麼你必須在平行處理的數量與 WIP 數量之間取得平衡。
WIP 過高,先不論對效能的影響,如果對於關鍵資源 (如 memory) 敏感一點的環境, 也許你的系統撐不過尖峰就會掛掉了。因此這次的題目,會監控 Runner 全程執行過程中,WIP 的最大值,當作 max(WIP) 指標。
指標: 第一個任務完成時間 (Time To First Task, TTFT)
熟悉 SCRUM 的大概都對 WIP 不陌生,這名詞我的卻是從那邊借來用的。另一個 SCRUM 在做任務管理的指標就是 Lead Time (交期, 從需求提供到任務完成交付的時間)。這邊我也拿 Lead Time 當作指標之一。不過我比較偏好 TTFT (Time To First Task completed) 這名詞。這名詞我是從 Browser 的開發工具那邊學來的用法。監控網頁下載效率,有個很重要的指標 TTFB (Time To First Byte) 也是一樣的意思。
TTFT, 指的是 Runner 啟動之後, 完成全部步驟的第一個 Task 要花費的時間 (不限定一定要按照 Task 的順序執行)。TTFT 會直接影響使用者的感受,有大量 Task 交付執行時,你能完成第一個的時間,就是使用者視角看到的 Lead Time。過去在念作業系統 (OS, Operation System) 時, 對於多工排程的機制也有類似的指標,那個叫 “平均等待時間”,意思是每個 Task 從被交付到 OS 開始 (這裡指的是 Runner 啟動) 到 Task 完成的時間平均。TTFT 越大,代表你花越多時間在 “等待” 某些階段的完成。
我在這個例子,我挑選 Lead Time, 而不挑選 Execution Time 的原因是: Lead Time 包含 Task 等待被處理的時間 + 執行時間。執行時間考驗的是 Task 內的效率或是機器的效率, 在這了練習題內是固定的。我的重點在於你的 Runner 安排規劃的能力,因此我挑選 lead time, 更能代表終端使用者的感受。如果你能越早交付第一個 Task, 使用者就會感受到系統的回應速度越快,如果使用者端能配合,或許有後續的任務就能越快啟動。這是我挑選這個指標的用意。
指標: 所有任務完成時間 (Time To Last Task, TTLT)
相較於 TTFT 在意第一個 Task 完成的時間,另一個代表整體效能的指標則是整體完成時間。在互動的體驗不是那麼重要的情況下 (例如半夜的批次作業),有時整體效能反而更為重要。因此能代表整體效能的,我挑了另一個指標: 最後一個 Task 的 lead time。如果硬要跟 TTFT 來對比,那這個指標就是 TTLT (Time To Last Task completed)。這指標完全不管過程中你如何交付 Task 的,只看最後一筆的交付時間,這指標代表整體的處理效率。
有些情況下,TTFT / TTLT 哪個重要,其實很難斷定,完全看你對於系統的服務品質怎麼定義。舉例來說,當 Task 的數量很大的時候,你能否忍受一個明明只要一秒鐘就能完成的任務,卻要在 1 小時後才能得到結果,換來的代價可能是整體完成的時間可以加速 30%, 或是執行的成本降低 30% ? 不同的考量,會影響這些指標的重要程度。
我在這個案例,由於我考量的是 pipeline, 越快完成第一個任務,我後續的階段就能越快開始,因此我把 TTFT 的重要性排在前面。
指標: 平均完成時間 (Average Lead Time)
這是從 OS 排程那邊學來的另一個指標。只看第一個任務,跟只看最後一個任務的完成時間,其實都是兩個極端。老實說我要是知道規則還蠻容易作弊的 XDDD, 假設我整批處理能縮短 30% 的執行時間,那麼為了 KPI 好看,我可以只處理第一筆,然後就交付成績;後面 2 ~ N 筆再用最有效率的做法,再最後才一次交付 2 ~ N 筆 Task 的成果,來衝這兩個 KPI 帳面上的數字…
當然這樣就本末倒置了,使用者體驗一定是不好的啊,因此我追加一個 OS 提到的指標: 平均等待時間。
這指標的定義是:每個 Task 的交期的平均值。這個案例裡,就是每個 Task 從 Runner 啟動開始,到 DoStepN(3) 完成為止的時間總平均。這是介於 TTFT 與 TTLT 中間的指標,越低代表使用者需要等待 (就是 Lead Time) 的時間越短。
下一步: 提交你的 TaskRunner !
有看過前面兩篇探討 CLI 的文章的話,應該不難發現這練習題要解決的問題,跟前面的 pipeline 很類似,連同我探討解決方式優劣的方式 (指標定義) 也很雷同。的確,我就是把這些問題抽象化之後,化簡為類似 LeetCode 那樣的模式來進行而已。
我在公司內部,試著進行這樣的練習,其實成效還不錯,藉著幾個明確的指標,這練習成功的刺激工程師們想清楚他的解決方式的處理細節,為何結果會是這樣? 跟理想的解決方案還有哪些差距? 要如何才能做得到… 等等。
除了練習之外,後續在幾個實際上的 project 面臨的效能問題,也能透過調整 Task 的 參數設定檔,同時找出該校能問題最關鍵的品質指標是哪一個,接下來的問題就迎刃而解了。很多大師都說 “問對問題,就解決了一半” 是很有道理的,這樣的練習題就能具體的用 code 把你的問題定義清楚,剩下的就是找出解決方式,把品質指標改善到預期的範圍內。
當你覺得技術跟框架學不完,或是都覺得已經很熟練了,但是碰到問題有時還是不得其門而入時,不彷暫時跳出 “skill” 層面的學習, 讓自己有些空間思考問題的本質,並且試著挑戰看看吧!
有興趣的朋友,歡迎 PR 你的練習結果給我。我會在後續的文章內容內來探討每種做法的優缺點與適用情境。探討會擺在下一章節內,有任何討論可以在底下的 comments, 或是到我的 facebook 粉絲專頁留言給我都歡迎!
PART II, Solution & Review (2019/09/16)
終於到揭曉的時間了,下半段文章是 9/16 後追加的。感謝各位的貢獻,我們就開始來後半段的 code review / solution review 吧!
開始之前,先感謝各位有發 PR 給我的網友們。我沒有各位的 FB 帳號,因此我貼 github 來代表:
- lex.xu
- Jyun-Wei Chen
- YingPing, Lin
- SeanLiao7
- Phoenix
- Julian-Chu
- gulu0503
- Maze
- andy19900208
- NathanWu8343 (沒能趕上截稿時間 T_T, 有加入評比, 沒列入 code review.. 下次請早)
理論極限在哪邊?
其實這是個典型的生產者/消費者問題 (雖然問題被我簡化過了)。試著這樣思考,如果這些任務是要分配給很多員工處理的,那應該怎麼分配? 典型生產線會這樣安排:
- 第一關安排幾個員工,拿到 task 就處理 step 1
- 第二關處理 step 2
- 第三關處理 step 3
再來看看每個 step 的限制:
public static readonly int[] TASK_STEPS_DURATION =
{
0, // STEP 0, useless
867,
132,
430,
};
public static readonly int[] TASK_STEPS_CONCURRENT_LIMIT =
{
0, // STEP 0, useless
5,
3,
3
};
先用 “我有無限制的運算資源” 為前提,來想像一下每個數據的理想數值會落在哪邊吧!
TTFT / TTLT
TTFT (Time To First Task) 很簡單,一切都安排妥當的話,就是 step 1 + step 2 + step 3 按順序執行就好了。 理想的 TTLT = 867 + 132 + 430 = 1429 msec
TTLT 就要花點腦筋了, 先概略估計一下。由於這是生產者消費者的問題,我們先來看看每個階段的處理速度:
| step | task / msec |
|---|---|
| #1 | 867 / 5 = 173.4 |
| #2 | 132 / 3 = 44 |
| #3 | 430 / 3 = 143.3 |
因此,理想狀況下,瓶頸應該會掉在最慢的 step #1, 其次是 step #3, 剛好是頭跟尾, 改善瓶頸的效能,永遠是優化產線效率的第一步。我們以最慢的 step #1 為基準, 處理完全部 1000 筆, 最快應該需要 173.4 x 1000 = 173400 msec = 173.4 sec, 大約是 3 分鐘。
不過,精準一點預估的話,要讓每個階段都最佳化執行,應該是每個階段個別都有專屬的 threads, 數量剛好跟平行限制的數量一致,例如 (時間軸是由左到右,不是由上到下):
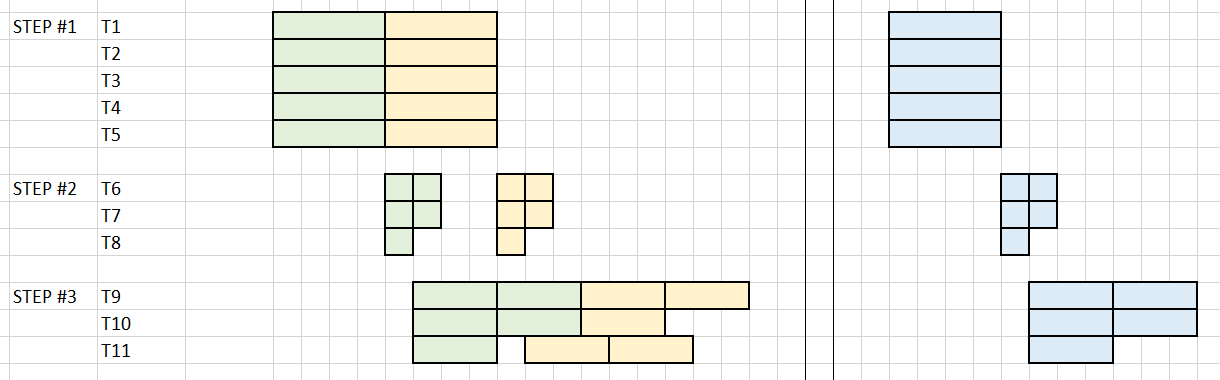
這是理想的安排狀況,step #1 在理想狀況下會被分成 1000 / 5 = 200 組進行, 共需要花費 200 x 867 = 173400 msec 完成 (跟前面的答案一樣)。
假設最後一批 step #1 執行完畢, 那麼 step #2 的前三筆, 應該要花費 132 msec 可以交付給 step #3, 這批交付出去之後, step #2 就不再是瓶頸了。
接著看看 step #3, 接到 step #2 第一批 (3 tasks), 需要 430 msec 才能處理完畢,這時剩下的第二批 (2 tasks) 應該也準備好了, step #3 需要再一次的 430 msec 才能全部處理完畢。
因此,極致的生產效率最佳化之下, TTLT 應該是: 173400 + 132 + 430 + 430 = 174392 msec
AVG_WAIT
按照定義,1000 tasks 送交給 runner 的那一瞬間,每個 task 的碼表就都已經按下去了, task 執行結束,自己的碼表就按停, 1000 個 task 的碼表數字加起來就是這個數值。因此按照上面那張圖來看,一樣五個五個一組:
第一組的 TWT (total waiting time) 應該是: ( 867 + 132 + 430 ) x 3 + ( 867 + 132 + 430 + 430 ) x 2
不過第二組以後就越來越難算了 XDD, 我決定忽略一些難以預估的部分,約略估計即可… 假設運作一段時間後,都會變成 step #1 是整體瓶頸, step #2 / #3 都會等著處理, 那麼第 N 組 (N <= 200) 的 TWT 應該是: ( 867 x N + 132 + 430 ) x 3 + ( 867 x N + 132 + 430 + 430 ) x 2 = 4335N + 3670
因此 N 從 1 ~ 200 的 TWT 都加起來的話… (我懶的寫計算過程了),結果是: 87867500 msec 因此 AVG_WAIT (Average Waiting Time) = 87867.5 msec
為何要知道理論極限?
原則很簡單,看到全貌你才能做出正確判斷。也就是你必須先知道你的目標在哪裡,你離目標還有多遠,你才知道你的最佳化做的夠不夠。就像在沙漠中你如果不知道還有多久才到綠洲,你可能在最後一哩路放棄… 舉例來說,你如果不知道 TTLT 的理論極限是 174.392 sec, 你的程式從 200 sec 優化到 175 sec, 你會知道你已經沒有多少優化空間了嗎? 如果你不知道,你可能會花了 5 倍額外的努力,卻只換來 0.6 sec 的成效,更糟的是你不知道已經到了極限,還繼續投入不願意停下來。這時,比起投入更多努力擠出 0.6 sec, 也許不如去尋求其他範圍是否有其他作法直接更根本的換成另一套做法,可能還比較有效。
當你碰到的問題,是你以前沒碰過的,或是很難直接 google 的到解答的,大概都會面臨這種難題: 我連有沒有解答都不知道,我到底是要繼續努力 google, 繼續嘗試解決方案, 還是直接放棄? 如果沒有辦法站的更高,先幫助你判定還直不直得繼續挖下去的話,你很容易就會陷入兩難,尤其能力越好,或是越認真求好心切的人,越容易陷入這個陷阱裡面。也因此,我才會告訴 team member, 解決困難問題的第一步,請先盡量想辦法去弄清楚,你能做到的理論極限到底在哪裡?
Benchmark Result
這次收到 13 筆 pull request, 總共 10 位網友參加挑戰。最後放進 benchmark 評比的有 10 (網友) + 3 (同事) + 5 (示範程式) = 18 組。 直接先看結果吧! 每個人的 TaskRunner 都各丟 1000 個 task 執行的統計:
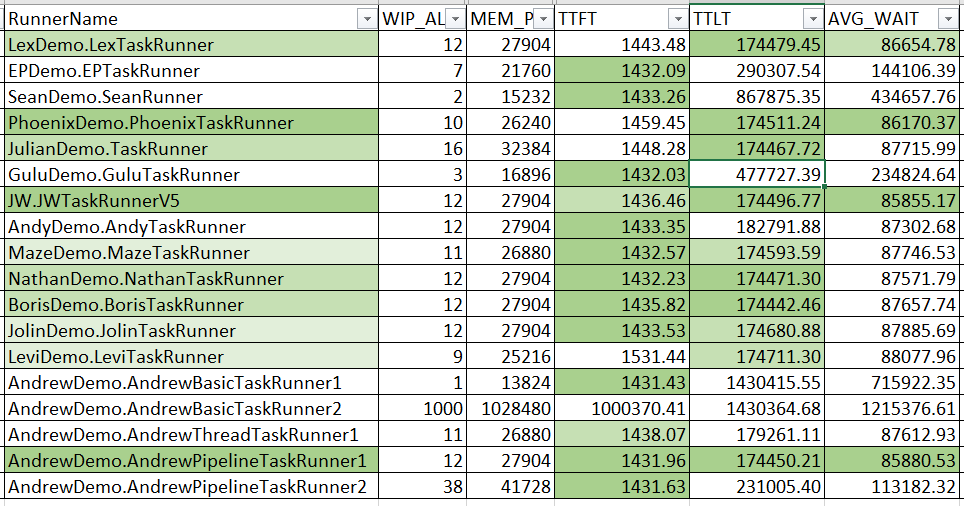
雖然我列了 WIP / MEM 等等其他參考的指標,但是既然是以效能為主,我還是關注在 TTFT / TTLT / AVG_WAIT 這三個數字上吧。顏色標示的規則很簡單,以前面提到的 “理想值” 為目標,這三項分數如果跟理想值的差距在 1% 以內,就標上綠色。如果落在 0.5% 以內就標上深綠色。唯獨 AVG_WAIT 比較特別,大概是我理想值估的太保守了,竟然有幾個挑戰者跑出比我認知的 “理想值” 還要好的成績… 因此 AVG_WAIT 這欄標顏色的規則稍微調整,我用成績最好的那一筆 (JW.JWTaskRunnerV5) 當作理想值,其餘規則不變。
因為 TTFT 太容易,大家成績都差不多,因此評比我就只看 TTLT 跟 AVG_WAIT 兩項。兩項都達到 0.5% 內的,我在 RunnerName 那欄標上深綠色;只有一項 0.5%, 或是兩項 1% 標淺綠色;只有一項 1% 則標上更淺的綠色。
底下我就列出完整的測試數據給大家參考:
| RunnerName | WIP_ALL | MEM_PEAK | TTFT(msec) | TTLT(msec) | AVG_WAIT(msec) | TTFT(%) | TTLT(%) | AVG_WAIT(%) |
|---|---|---|---|---|---|---|---|---|
| LexDemo.LexTaskRunner | 12 | 27904 | 1443.48 | 174479.45 | 86654.78 | 101.01% | 100.05% | 100.93% |
| EPDemo.EPTaskRunner | 7 | 21760 | 1432.09 | 290307.54 | 144106.39 | 100.22% | 166.47% | 167.85% |
| SeanDemo.SeanRunner | 2 | 15232 | 1433.26 | 867875.35 | 434657.76 | 100.30% | 497.66% | 506.27% |
| PhoenixDemo.PhoenixTaskRunner | 10 | 26240 | 1459.45 | 174511.24 | 86170.37 | 102.13% | 100.07% | 100.37% |
| JulianDemo.TaskRunner | 16 | 32384 | 1448.28 | 174467.72 | 87715.99 | 101.35% | 100.04% | 102.17% |
| GuluDemo.GuluTaskRunner | 3 | 16896 | 1432.03 | 477727.39 | 234824.64 | 100.21% | 273.94% | 273.51% |
| JW.JWTaskRunnerV5 | 12 | 27904 | 1436.46 | 174496.77 | 85855.17 | 100.52% | 100.06% | 100.00% |
| AndyDemo.AndyTaskRunner | 12 | 27904 | 1433.35 | 182791.88 | 87302.68 | 100.30% | 104.82% | 101.69% |
| MazeDemo.MazeTaskRunner | 11 | 26880 | 1432.57 | 174593.59 | 87746.53 | 100.25% | 100.12% | 102.20% |
| NathanDemo.NathanTaskRunner | 12 | 27904 | 1432.23 | 174471.30 | 87571.79 | 100.23% | 100.05% | 102.00% |
| BorisDemo.BorisTaskRunner | 12 | 27904 | 1435.82 | 174442.46 | 87657.74 | 100.48% | 100.03% | 102.10% |
| JolinDemo.JolinTaskRunner | 12 | 27904 | 1433.53 | 174680.88 | 87885.69 | 100.32% | 100.17% | 102.37% |
| LeviDemo.LeviTaskRunner | 9 | 25216 | 1531.44 | 174711.30 | 88077.96 | 107.17% | 100.18% | 102.59% |
| AndrewDemo.AndrewBasicTaskRunner1 | 1 | 13824 | 1431.43 | 1430415.55 | 715922.35 | 100.17% | 820.23% | 833.87% |
| AndrewDemo.AndrewBasicTaskRunner2 | 1000 | 1028480 | 1000370.41 | 1430364.68 | 1215376.61 | 70004.93% | 820.20% | 1415.61% |
| AndrewDemo.AndrewThreadTaskRunner1 | 11 | 26880 | 1438.07 | 179261.11 | 87612.93 | 100.64% | 102.79% | 102.05% |
| AndrewDemo.AndrewPipelineTaskRunner1 | 12 | 27904 | 1431.96 | 174450.21 | 85880.53 | 100.21% | 100.03% | 100.03% |
| AndrewDemo.AndrewPipelineTaskRunner2 | 38 | 41728 | 1431.63 | 231005.40 | 113182.32 | 100.18% | 132.46% | 131.83% |
Solution & Code Review
開始重頭戲了。在 merge 各位的 PR 時,我也順帶的看了一下大家都怎麼解決問題的。果然要分享才會學到技巧啊,藉由各位的 code 我也學到不少以前沒想過的技巧。回到問題,我把解決這類問題的方法分成三大類:
- 善用多工處理 (Thread / ThreadPool / Task):
.NET 提供了很強悍的平行處理能力,因此熟悉 Thread / Task 運用方式的朋友們,很容易的就能把這堆 task 的每個 step 都丟給 .NET 幫你處理。 我這邊的定義是,如果你沒有明確的控制每個 step 的處理, 也沒精準地控制下個步驟的處理時機與順序, 而是直接把下個 step 交給 .NET 決定的方式,我都歸在這類。 這種方式的好處是簡單,複雜度也不高,通用性也高 (跟你的 task 特性, 以及每個 step 的限制沒有太大關連)。如果你無法很精準的預測任務的屬性,與其胡亂調教參數最佳化,還不如直接交給 .NET 來幫你處理,通常都有水準以上的表現。
以我的角度,屬於這類的方式有這幾個 Runner:
- LexDemo.LexTaskRunner
- AndyDemo.AndyTaskRunner
- MazeDemo.MazeTaskRunner
- LeviDemo.LeviTaskRunner
- AndrewDemo.AndrewThreadTaskRunner1
- 生產者消費者的管理 (Pipeline / BlockingCollection / Channel / Queue … etc):
大體上跟 (1) 沒有太大差別,不過題目已經明確地分成三個 step 了,因此這問題很明顯地變成是生產者消費者典型的題目。這類問題都有同樣的特色,就是像生產線一樣,第一關處理完就要交到第二關,因此要有明確的移交到下一關的動作。每一關之間的處理速度都不一樣,因此要有明確的調節機制。中間是否有 buffer / queue 這類的緩衝區, 兩端是否有明確的 notify 機制來叫醒等待中的 worker …
這種做法的好處是 “精準”。因為精準,你才有機會逼出極限的效能;也因為精準,你才有機會使用最少的資源來處理任務,將 WIP 壓到最低,同樣能完成任務。
以我的角度,屬於這類的方式有這幾個 Runner:
- EPDemo.EPTaskRunner
- SeanDemo.SeanRunner
- PhoenixDemo.PhoenixTaskRunner
- JulianDemo.TaskRunner
- GuluDemo.GuluTaskRunner
- JW.JWTaskRunnerV5
- NathanDemo.NathanTaskRunner
- BorisDemo.BorisTaskRunner
- JolinDemo.JolinTaskRunner
- AndrewDemo.AndrewPipelineTaskRunner1
- AndrewDemo.AndrewPipelineTaskRunner2
- 其他 例如我提供的那個墊底的 sample code, 無法歸類在上面兩種的做法,我都歸在這一類。看來只有我自己惡搞的兩個墊底範例屬於這類 XDD
- AndrewDemo.AndrewBasicTaskRunner1
- AndrewDemo.AndrewBasicTaskRunner2
分類的方式沒有代表絕對的優劣,從測試結果也看的出來方法跟分數沒有明顯的正相關… 接下來就一個一個 case 來看看吧!
所有的測試,我都在同樣的環境下執行。我執行的配備如下:
- CPU: AMD Ryzen 9 3900X 12C/24T
- RAM: DDR4-3200 16GB x 4
-
SSD: Samsung SSD 970 PRO 512GB (NVME)
- Microsoft Windows 10 Pro (1903)
- Microsoft Visual Studio Enterprise 2019 / 16.2.5
PR1, LexDemo.LexTaskRunner
感謝網友 lex.xu 第一個支持這活動,搶到頭香第一個發了 PR 給我 :D
先來看看 code:
public class LexTaskRunner : TaskRunnerBase
{
private static readonly int _maxCount = Environment.ProcessorCount;
private static readonly SemaphoreSlim _semaphoreSlim = new SemaphoreSlim(_maxCount);
public override void Run(IEnumerable<MyTask> tasks)
{
var processTasks = tasks.Select(processTask)
.ToArray();
Task.WaitAll(processTasks);
}
private Task processTask(MyTask myTask)
{
_semaphoreSlim.Wait();
return Task.Run(async () =>
{
await Task.Run(() => myTask.DoStepN(1)).ConfigureAwait(false);
await Task.Run(() => myTask.DoStepN(2)).ConfigureAwait(false);
await Task.Run(() => myTask.DoStepN(3)).ConfigureAwait(false);
_semaphoreSlim.Release();
});
}
}
Benchmark 成績摘要:
- TTFT: 1443.48 (101.01%)
- TTLT: 174479.45 (100.05%)
- AVG_WAIT: 86654.78 (100.93%)
很標準的多工處理方式,用 LINQ 的 Select() 把每個 MyTask 分配給 processTask 這個 method, 每個都用 Task 來等待執行結果,一次撒出去後用 Task.WaitAll() 確認是否全部都執行完畢。
值得一提的是,為了最佳效率,用了 Semaphore 的物件來控制並行數量,避免 .NET 的 Task 衝過頭了。這邊 Semaphore 的參考依據是用 CPU 核心數,例如我跑這測試的 PC 是 AMD Ryzen 3900X, 規格上有 12C24T, 這邊會抓到 24 ..
這邊很可惜的一點是: 限制併發數量是對的,但是這個案例裡,決定併發數量的關鍵因素並不是 CPU 核心數量,我們處理的任務內容也不是 CPU Bound … 實際上的限制因素主要是我題目提到的:
- step 1 最多只能同時 5 個 task 同時進行
- step 2 最多只能同時 3 個 task 同時進行
- step 3 最多只能同時 3 個 task 同時進行
在這題目的假設上,應該跟 CPU 核心數沒有太大關連,因此參照 CPU Core 並不洽當。另外,程式碼內是一個 Task 連續執行三個步驟 (這三個步驟又額外拆成三個 Task), 應該管控的是每個步驟的併行數量啊,而不是總數。
以上是這段 code 應該可以在更精進的地方,作法到位了,但是控制的細節可以再精確一些。不過即使有些許改善空間,但是跑出來的成績其實是不錯的。看的出來, 長遠來看, 跑完 1000 個花了近三分鐘的時間, 總共發出了 4000 個 Task 交給 .NET 處理,只再 TTFT 這邊吃了一點虧, 第一個 MyTask 可能沒有很即時的銜接好 step 1 ~ step 3, 只靠 .NET 自己排程,所以 TTFT 小輸了一點,沒能擠進 1% 的範圍內。不過其他成績都不賴,尤其是代表整體效能的 TTLT, 成績只跟理想值差了 0.05% ..
只能說 .NET 的優化做的太好了, 泛用的機制都能得到這麼好的效能表現。Developer 不需要過度深入掌控細節就能得到很好的效率。
最後來看看 TTFT 到底輸在哪邊吧! 我特地調出紀錄檔出來看,我們就看第一個 MyTask 就好:
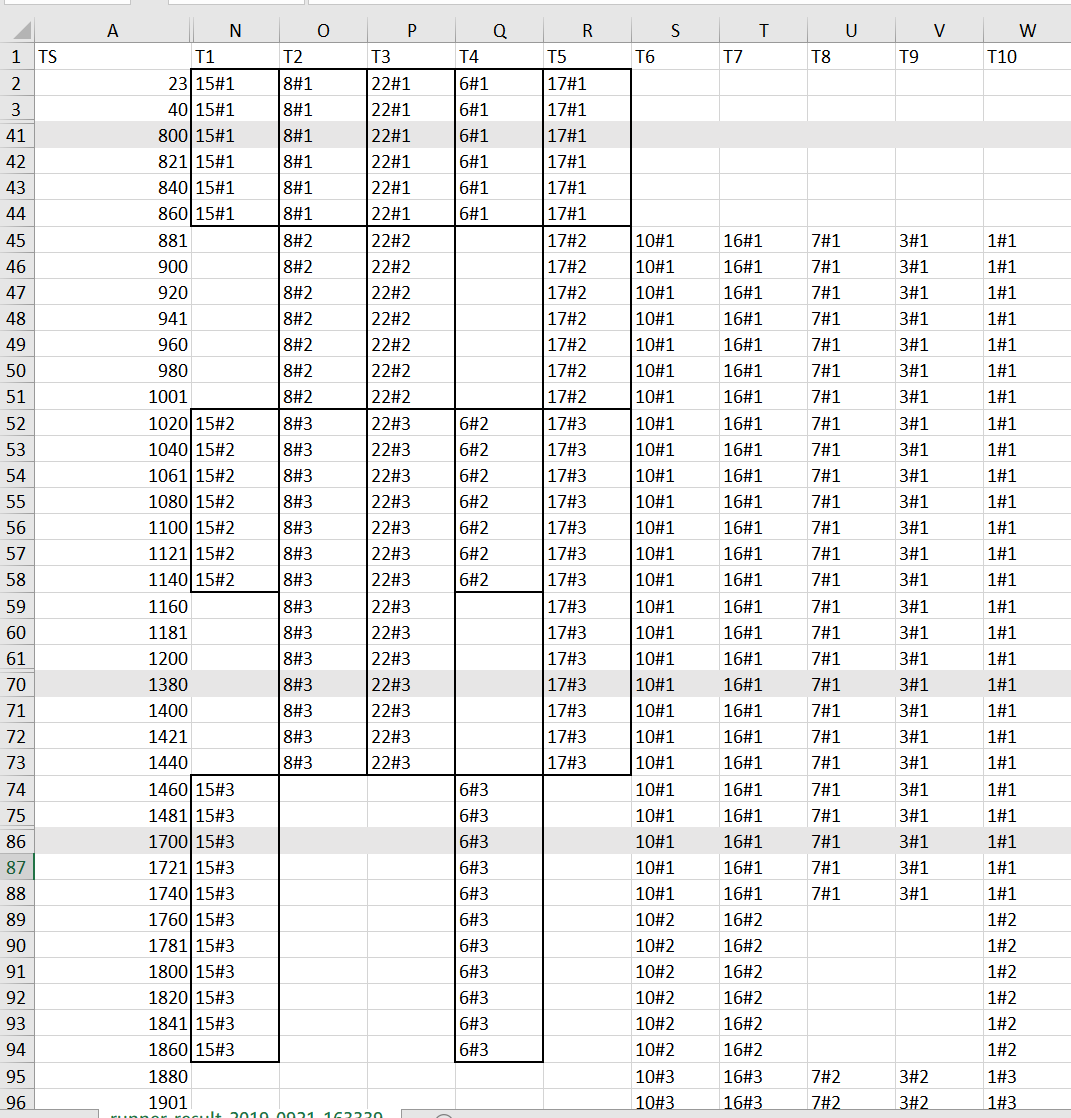
TS 那欄是整個測試執行的時間軸,單位是 msec, 為了方便擠進文章內,我把中間重複的部分都隱藏起來了。看的時候留意一下左邊的 TS, 標了一行灰色的,代表有部分資料被我隱藏了。因此整個視覺上的呈現,不代表實際的比例。
第一波被丟進去執行的 (其實沒有按照順序),TaskID 分別是 15, 8, 22, 6, 17 這五個,step 1 都有如預期的最佳化。但是 step 2 就只剩下 8, 22, 17 這三筆立即被執行, 而且是用同一個 thread .. 15 與 6 這兩個 Task 的 step 2 沒立即搶到運算資源, 反而被新的 Task (10, 16, 7, 3, 1) 的 step 1 搶走了。15 與 6 的 step 2 被延後到 TS: 1020 後才啟動。同樣的狀況也發生在 step 3…
雖然 TTFT 只要求 “第一個” 完成的時間, 這方式另外有幾個地方吃了虧:
- 要先花費一些時間處理
.Select()準備Task.. - 實際執行並沒有按照順序, 第一批交付執行最大的 TaskID 是 22, 代表
.Select()至少已經處理到第 22 筆後才開始..
前面一開始額外的延遲,加上看的出來執行的順序沒有被安排的很緊密,造成了第一個 MyTask 優化剛剛好差了一點, 沒有擠進理想值的 1% 內,但是整體的優化是有被系統的機制追回來的,才造成這樣的結果。不過,實際的案例,除非你的應用真的很在意 TTFT 這些指標,不然 1% 的差距根本可以不用理他,對我而言 TTLT / AVG_WAIT 還更重要有感一些。整體而言,這個方法在簡潔、可維護性跟效能上做到很好的平衡。
給 Lex 的建議: 試著了解你的每一行 code 的目的是啥,也是著了解每一行 code 的用途是啥。很多時候你可以避免不必要的限制或是浪費 (例如這案例的 ProcessorCount)。試著在自己能掌控的範圍內,盡可能的讓你的 code 能照你想要的方式執行 (如果有必要的話)。這些算是內功,也許大部分時間用不到,但是一旦需要時你沒練習你是施展不出來的。
PR3, EPDemo.EPTaskRunner
這次是網友 YingPing, Lin 貢獻的 PR, 挺有意思的一段 code, 我先貼上來:
public class EPTaskRunner : TaskRunnerBase
{
public override void Run(IEnumerable<MyTask> tasks)
{
foreach (var task in GogoNstepAsync(GogoNstepAsync(GogoNstepAsync(tasks, 1), 2), 3))
{
;
}
}
public static IEnumerable<MyTask> GogoNstepAsync(IEnumerable<MyTask> tasks, int step)
{
List<Task<MyTask>> hohoho = new List<Task<MyTask>>();
foreach (var task in tasks)
{
var t = Task.Factory.StartNew(() =>
{
task.DoStepN(step);
return task;
});
hohoho.Add(t);
if (hohoho.Count >= 3)
{
Task.WhenAny(hohoho).Wait();
for (int i = 0; i < hohoho.Count; i++)
{
if (hohoho[i].IsCompleted)
{
yield return hohoho[i].Result;
hohoho.RemoveAt(i);
break;
}
}
}
}
while (hohoho.Count != 0)
{
var o = hohoho[0];
if (o.IsCompleted)
{
yield return o.Result;
hohoho.RemoveAt(0);
}
}
}
}
Benchmark 成績摘要:
- TTFT: 1432.09 (100.22%)
- TTLT: 290307.54 (166.47%)
- AVG_WAIT: 144106.39 (167.85%)
有意思的是,這 code 的結構其實有很巧妙的用上 .NET / C# 的特性。IEnumerable<T> 介面搭配 C# yield return 的語法糖, 目的就是讓你能用 “串流” 的模式去處理資料。這段程式碼想表達的意境,是 GogoNstepAsync() 接受 IEnumerable<MyTask> 的輸入, 接到一筆就處理一筆 step N, 然後再用同樣的介面 IEnumerable<MyTask> 交給下一棒,下一棒比照辦理直到全部步驟結束為止。
這些機制安插好之後,主程式只要靠一個 for loop 不需要做任何事情,就能驅動整個流程跑起來:
foreach (var task in GogoNstepAsync(GogoNstepAsync(GogoNstepAsync(tasks, 1), 2), 3))
{
;
}
以上是這結構的精妙之處,這方法能夠很有效的控制使用的資源。因為很精準的一棒一棒往下交,你的 WIP 很精準的被壓制在最小範圍。這點可以從 WIP 跑出來只有 7 得到證實。不過可惜的是,在多工的處理部分沒有很到位,過低的 WIP 反而阻礙了整體的效能,也因此這方法跑出了很棒的 TTFT,但是 TTLT 跟 AVG_WAIT 並不理想。
給 EP 的建議: 你的做法跟我提供的五個範例其中一個很類似, 可以參考看看最後面的範例程式碼。
PR4, SeanDemo.SeanRunner
public override void Run(IEnumerable<MyTask> tasks)
{
var maxCount = tasks.Count();
using (var pipe = new PipeLineHead<MyTask>(tasks, x => x.DoStepN(1)))
{
pipe.SetNextPipeLine(new PipeLine<MyTask>(maxCount, x => x.DoStepN(2)))
.SetNextPipeLine(new PipeLine<MyTask>(maxCount, x => x.DoStepN(3)));
pipe.StartPipeLine();
var isComplete = pipe.WaitForCompletion();
Console.WriteLine(isComplete);
}
}
Benchmark 成績摘要:
- TTFT: 1433.26 (100.30%)
- TTLT: 867875.35 (497.66%)
- AVG_WAIT: 434657.76 (506.27%)
這段 code 底下還有很多實作, 我就不一一貼了 (有點長, 有興趣的可以直接看 github PR4)。值得稱讚的是,結構上也有善用到前一個案例提到 “串接” 的架構來處理了。只是沒有直接運用 IEnumerable<T> + yield return 來精簡程式碼, 都是自己刻出來的。因此程式碼會看到 StartPipeLine() 這樣的 code. 不過這只跟風格有關,跟實際的執行成效沒有太大影響。
另一個值得一提的是: pipeline buffer. 生產者消費者問題,很重要的一環是兩端的平衡。如果產能不穩定,你就必須在中間有個 “倉庫” 來調節。一來避免生產者生產太快,產品沒地方放;二來避免消費者消費太快,沒有原料可以給他。
中間調節的倉庫,是很難搞的議題,太大可能造成 WIP 過高,浪費資源,太低可能造成特定 step 停擺, 影響整體效能。除了倉庫容量之外,倉庫跟前後一關的溝通也很重要,滿了要立刻讓生產者知道要暫停產線別再生產了,不然會沒地方放;當倉庫有空間了也要立刻通知生產線繼續生產。
同樣的溝通也會發生在倉庫與消費者,因此這邊的難題就是如何很 “精準” 的做好通知? 這是平行處理最討厭的技巧… 你如果善用 notify 的機制,延遲可能是 1ms 以下。如果你用 pooling, 你就得砸下 CPU 運算能力來降低延遲了,不過在怎麼做通常都會在 1ms 以上…
這類典型的例子,.NET 常用的就是 BlockingCollection<T> 或是 Channel 了… Sean 在這個例子就運用了 BlockingCollection 來實作他的 pipeline.
BlockingCollection 的優點就是讓他擔任 “倉庫” 的角色,他可以把通知的動作封裝成同步的呼叫,該停止的話就直接 block call, 你的 code 不大需要花腦筋解決這段問題。
因為精準,加上循序處理,因此在 TTFT 上有很好的表現。
給 Sean 的建議:
程式碼不夠簡潔,抽象化不夠到位。舉例來說, PipeLine 為了區分是不是第一棒,你的實作分成 PipeLineHead 跟 PipeLine, 但是實際上大部分的串流或是 pipeline 的結構都不需要分兩個,你只要實作 pipeline, 串在第一個就是第一個。對這些結構的抽象化能力不夠,導致你的 code 就沒辦法很收斂。這是可惜的地方,否則你運用的技術是很正確的。
另一個可惜的地方是整體效能不佳,理論上你用的方式應該可以表現很棒的。不知你有沒有留意到關鍵? TTLT / AVG_WAIT 這兩個可以代表整體指標的數值,你都大約落後理想值的 5x, 剛剛好就是 step 1 的平行處理上限。看到關鍵了嗎? 你在 PipeLineHead.StartPipeLine() 的地方沒處理好,導致你的 code 在 step 1 是 “完全” 沒有平行處理的。加上 step 1 又是瓶頸, 所以…
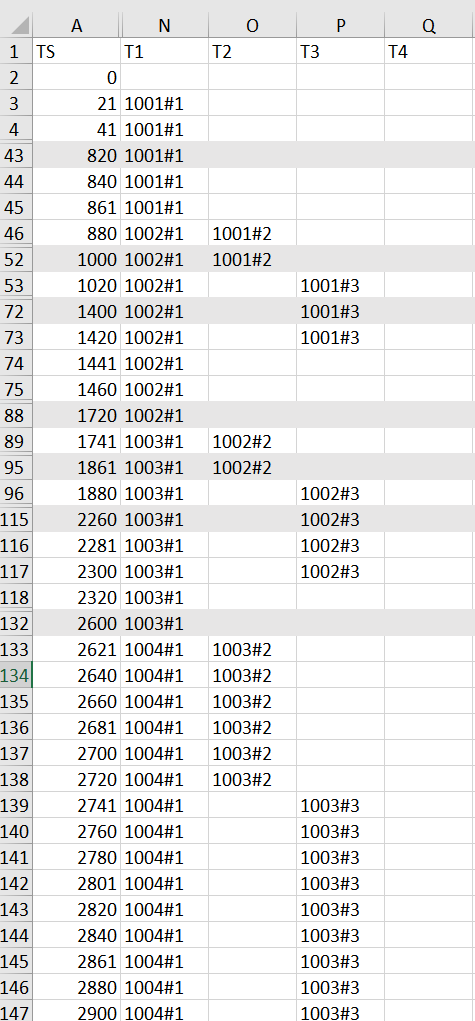
這現象可以從你的 log.csv 看出端倪,所有 task 的 step #1 都集中在 T1 這個 thread 執行,被平行處理的只有 step 2, step 3…
其實只要改一兩行就能解決問題了,讓你的整體效能瞬間提升五倍。但是你沒察覺,應該是你沒先思考理論極限在哪,因此看到 PASS 後也不知道自己的 code 是否夠 “理想” ?
不夠抽象化,把 PipeLineHead 跟 PipeLine 拆開也是原因之一,後面有做到位,前面卻漏掉了 XD, 實在可惜.. 你運用的結構跟我的 demo 很類似,有興趣可以參考看看我的範例:
PR5, PhoenixDemo.PhoenixTaskRunner
public class PhoenixTaskRunner : TaskRunnerBase
{
private BlockingCollection<MyTask> m_Pipe1 = new BlockingCollection<MyTask>();
private BlockingCollection<MyTask> m_Pipe2 = new BlockingCollection<MyTask>();
private BlockingCollection<MyTask> m_Pipe3 = new BlockingCollection<MyTask>();
private SemaphoreSlim m_Semaphore1 = new SemaphoreSlim(5);
private SemaphoreSlim m_Semaphore2 = new SemaphoreSlim(3);
private SemaphoreSlim m_Semaphore3 = new SemaphoreSlim(3);
public override void Run(IEnumerable<MyTask> tasks)
{
Method2(tasks);
}
private void Method2(IEnumerable<MyTask> tasks) => tasks.ToObservable()
.Select(t =>
{
m_Semaphore1.Wait();
return Task
.Run(() => t.DoStepN(1))
.ContinueWith(_ =>
{
m_Semaphore2.Wait();
m_Semaphore1.Release();
return t;
});
})
.SelectMany(t => t)
.Select(t =>
{
return Task
.Run(() => t.DoStepN(2))
.ContinueWith(_ =>
{
m_Semaphore3.Wait();
m_Semaphore2.Release();
return t;
});
})
.SelectMany(t => t)
.Select(t =>
{
return Task
.Run(() => t.DoStepN(3))
.ContinueWith(_ =>
{
m_Semaphore3.Release();
return t;
});
})
.SelectMany(t => t)
.Wait();
}
}
Benchmark 成績摘要:
- TTFT: 1459.45 (102.13%)
- TTLT: 174511.24 (100.07%)
- AVG_WAIT: 86170.37 (100.37%)
這份 code 讓我學到不少技巧 XDD, 最大的特色就是這 code 善用了 RX + Semaphore 來解決這問題。 RX (Reactive Extensions for .NET) 有興趣的朋友可以花點時間研究一下,之前同為 MVP 的小黑也有在 .NET Conf 2017 介紹 過這套件。
細節我就不多說了 (免得讓人發現我不會 T_T)
不過雖然用了 RX 來處理主要結構,過程中一樣用到了 Semaphore + BlockingCollection 的組合來最佳化整個流程。step 1 結束,觸發下個 step 2, 則是透過 .NET Task 的 .ContinueWith() 來進行的,不失為是個簡潔的好方法。
整體而言沒啥好挑的,跑出來的成績也很理想,除了不大重要的 TTFT 之外 XD, 真要挑毛病,大概就是 RX 用的不夠徹底,RX 只用在 IEnumerable<MyTask> 流入 TaskRunner 這段, 用上 Observer 的機制… 但是在後面的階段則是自己處理了,如果用的再徹底一點,整個程式碼應該會更簡潔。或是若沒有那麼大的 RX 使用需求,直接都自己處理,也可以少掉一個 RX 的相依性。
PR6, JulianDemo.TaskRunner
接下來是 PR6 Julian-Chu 網友的 code:
public override void Run(IEnumerable<MyTask> tasks)
{
var ch1 = Channel.CreateBounded<MyTask>(new BoundedChannelOptions(1)
{SingleWriter = true, SingleReader = true, AllowSynchronousContinuations = true});
var ch2 = Channel.CreateBounded<MyTask>(new BoundedChannelOptions(1)
{SingleWriter = true, SingleReader = true, AllowSynchronousContinuations = true});
var processStep2 = ProcessStep2(ch1.Reader, ch2.Writer);
var processStep3 = ProcessStep3(ch2.Reader);
var processStep1 = ProcessStep1(ch1.Writer, tasks);
Task.WaitAll(processStep1, processStep2, processStep3);
}
private static async Task ProcessStep1(ChannelWriter<MyTask> writer, IEnumerable<MyTask> tasks)
{
var ts =tasks.Select(async t => await Task.Run(
async () => {
t.DoStepN(1);
while (await writer.WaitToWriteAsync())
{
if (writer.TryWrite(t)) break;
} }
));
Task.WaitAll(ts.ToArray());
writer.Complete();
}
// ProcessStep2(), ProcessStep3() 略
Benchmark 成績摘要:
- TTFT: 1448.28 (101.35%)
- TTLT: 174467.72 (100.04%)
- AVG_WAIT: 87715.99 (102.17%)
又是一個讓我不敢講太多的 code, 免得又讓人發現我不會 XDD… 這份 code 基本上也是生產者消費者的結構,但是中間的 “倉庫” 角色,用了 System.Threading.Channels 這套件的 Channel<T> 來替換前面一直看到的 BlockingCollection<T>。
其實兩者的目的是一樣的,不過看名字就知道差別,BlockingCollection<T> 的重點在於 “Blocking”, 用 Block Call 的作法讓你很容易的調節兩端的流量。為了簡單易懂,他是用 sync 同步的方式來封裝這結構的。如果你就是不喜歡 sync call, 那麼 Channel<T> 就是原生 async 非同步的版本。
有一篇文章 Asynchronous Producer Consumer Pattern in .NET (C#) 寫的不錯,整理了 .NET 三種處理生產者消費者問題的 framework (DataFlow, BlockingCollection, Channel), 另外 Microsoft 也有篇說明各種 .NET 平行處理策略的文章: Parallel Programming in .NET 都寫的不錯,可以參考看看。
這篇文章 Asynchronous Producer Consumer Pattern in .NET (C#) 的後面有跑一些 benchmark, 來比較 DataFlow, BlockingCollection 跟 Channel 的效能差異。在正確的情境上, Channel 的效能完全甩掉其他兩種方法一條街… 不過,最後還是來看一下 TTFT 吧,為何有這些差距? 我試著挖掘一下原因,一樣我把 .csv 的 log 挖出來看看:

我特地把第一個 Task (Id: 1) 的每個步驟框出來。還是一樣的問題,忽略了 “精準” 控制每個 task 的執行方式,就會有些環節不夠理想。這個 Task 的 step 1 執行結束是 860ms 的位置, 但是 step 2 被啟動時已經是 1460 msec 的位置了。一開始的時候應該都還沒踩到任何併發處理的限制,這只能說 .NET 剛好沒有在第一時間挑選我們希望的 Task 起來執行造成的了。
這 600 msec 就這樣被 .NET 浪費掉了… 實際上這 log 顯示,真正第一個完成的是 27, 不過中間也是被晾了 20 ~ 40 msec, 跳過前面 26 個 Task 也是要時間的,這一來一往,就導致跟理想值跑出 1.35% 的差距… 這些現象也穿插在後面的每一個 Task 之間,也間接的導致每個 Task 的交期變長,影響到 AVG_WAIT。
即使如此,Julian 的 code 沒啥好挑了 XDD, 結構漂亮, 效能不錯, 用的方法也簡潔, 只差在執行順序跟時機掌握在精準一點就完美了。其實我前面的案例一直想講的是, 自己用 Semaphore 來 “控制” 併發數量,其實是多此一舉。因為 Semaphore 埋在 Task 內,那是等 Task 被啟動後才會被 Semaphore 檔下來啊,其實已經來不急了,如果真的有用,我的 MyTask 內的實作也是用一樣的方法檔啊 XDD
這份 code 看來應該看穿這把戲了,所以乾脆連檔都不檔 XDD, 事實也證明跑出來的整體效能不受影響。真要挑就只剩下 ProcessStep1 ~ 3 沒有合併成一個,看來有點礙眼罷了。不過瑕不掩瑜, 不影響 review 結果。
PR7, GuluDemo.GuluTaskRunner
public override void Run(IEnumerable<MyTask> tasks)
{
var worker = new Worker(tasks, 3);
worker.DoWork();
}
public class Worker
{
private readonly ConcurrentQueue<MyTask> _workQueue;
private readonly IEnumerable<MyTask> _myTasks;
private readonly int _threadCount;
private bool _isComplete = false;
public Worker(IEnumerable<MyTask> myTasks, int threadCount)
{
if (threadCount <= 0) throw new ArgumentOutOfRangeException();
_workQueue = new ConcurrentQueue<MyTask>();
_myTasks = myTasks;
_threadCount = threadCount;
}
public void DoWork()
{
var tasks = new Task[_threadCount];
for (var i = 0; i < _threadCount; i++)
{
tasks[i] = Task.Factory.StartNew(ConsumerRun, TaskCreationOptions.LongRunning);
}
ProducerRun();
Task.WaitAll(tasks);
}
private void ProducerRun()
{
foreach (var myTask in _myTasks)
{
while (_workQueue.Count > _threadCount)
{
//Thread.Sleep(0);
}
_workQueue.Enqueue(myTask);
}
_isComplete = true;
}
private void ConsumerRun()
{
while (true)
{
if (!_workQueue.TryDequeue(out MyTask myTask))
{
if (_isComplete) break;
continue;
}
myTask.DoStepN(1);
myTask.DoStepN(2);
myTask.DoStepN(3);
}
}
}
Benchmark 成績摘要:
- TTFT: 1432.03 (100.21%)
- TTLT: 477727.39 (273.94%)
- AVG_WAIT: 234824.64 (273.51%)
一樣是很典型的結構,用了生產者消費者模式,中間也用了適當的資料結構來當作緩衝。 Worker 的程式碼看的出來,自己用了 ConcurrentQueue 跟 Task 來封裝,模擬 BlockingCollection 類似的效果。
結構的部分前面很多例子都談過,這邊我就跳過不多著墨了,我針對結果來看有哪些可以改善的。我覺得最大的盲點,就在於沒有事先搞清楚極限在哪裡,因此會不知道該怎麼拿捏 thread 的數量 (PR 的 code 裡面是 3 )。題目雖然有併行的上限,但是整體的 thread: 3 遠低於這個上限啊 (5 + 3 + 3 = 11), 因此過低的 threads 導致了很低的 WIP, 同時也低到影響整體效能了。
不過,這做法的優點我還是要提一下,就是能夠很 “精準” 的做你的 Task. 來看看 log.csv:
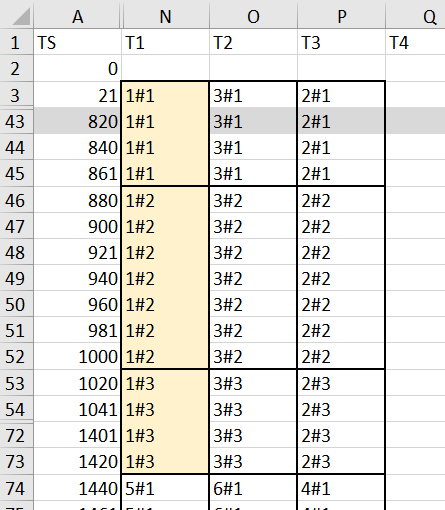
雖然整體的效能沒有調教好,但是看的出來很工整,所有 Task 都是按照順序,按照步驟,把有限的三個 threads 擠得滿滿的,一點空檔都沒有。因此可以跑出很好的 TTFT 成績。換個角度說,如果 WIP 是你系統很關鍵的因素 (例如 WIP 過高就會 OutOfMemoryException 之類的), 這是個不錯的方法。
給 Gulu 的建議: 一樣,先了解這問題的極限在哪,你才知道跑出來的數據合不合理。這份 code 其實寫的不錯,就是缺乏適當的效能調教,找出最佳的 thread count 限制而以。
PR8, JW.JWTaskRunnerV5
接下來是 PR8 Jyun-Wei Chen 網友的 code:
public override void Run(IEnumerable<MyTask> tasks)
{
int maxConcurentTasks = (5 + 3 + 3) + 3;
ThreadPool.SetMinThreads(maxConcurentTasks, maxConcurentTasks);
ThreadPool.SetMaxThreads(maxConcurentTasks, maxConcurentTasks);
int toProcess = Enumerable.Count(tasks);
Queue.Init();
using (ManualResetEvent resetEvent = new ManualResetEvent(false))
{
Task.Run(() =>
{
JobWorker jobWorker1 = new JobWorker(1, 5);
});
Task.Run(() =>
{
JobWorker jobWorker2 = new JobWorker(2, 3);
});
Task.Run(() =>
{
JobWorker jobWorker3 = new JobWorker(3, 3, toProcess, resetEvent);
});
//initial Step 1 in queue
foreach (MyTask task in tasks)
{
Queue.Produce(1, task);
}
resetEvent.WaitOne();
}
}
Benchmark 成績摘要:
- TTFT: 1436.46 (100.52%)
- TTLT: 174496.77 (100.06%)
- AVG_WAIT: 85855.17 (100.00%)
後半段的 code 我就省略了,看到前面出現 ThreadPool, 大概就能想像後面在做啥事了,就是透過 JobWorker 把封裝後的任務丟到 ThreadPool …。這段 code, 老實說看的有點 OOXX 的,因為…. 差點害我面子掛不住啊 XDD, 所有 case 裡面,就是這份 code 跑出最低的 AVG_WAIT 數據了。我預估的方式其實有點保守,忽略了一些我比較難預測的最佳化空間 (我想應該沒人能擠出這段效能吧?)。結果竟然還被擠出來了…
所以,大家的 AVG_WAIT 這項成績用的基準值 (100%) 不是用我預估的理論值,而是直接用 JW 網友跑出來的數據當作 100% ..
這份 code 是所有參加的朋友們,除了我自己之外,唯一一個同時在三個指標內都拿到 1% 內的成績,TTFT 差了一點,不然就三項都拿到 0.5% 了,而且還有一項是第一名… 表現各方面都不錯, 不但平衡而且效能都在前段班。
這 code 處理問題的結構,比前面幾個 case 更進化了一些。基礎結構一樣,是用三組 BlockingCollection<T> 來搭建起生產者消費者的處理結構。每一關都是上一關的消費者,同時是下一關的生產者。不同的地方在於,背後用 ThreadPool 來承接這些任務。ThreadPool 的 thread 數量限制在 5 + 3 + 3 + 3, 多的 3 我不知道怎麼來的,應該是實驗跑出來的最佳值吧(?)
環境準備好之後,用 for loop 把 task 通通灌進去,就驅動整個機制跑起來了。任務丟進去後,就會驅動第一關開始把任務往 ThreadPool 丟,結束就往第二關丟。如此重複直到結束為止。
整個體系,一樣用了 Semaphore 控制別超出預期的併發量, 也用了 ManualResetEvent 來通知 Runner 是否全部執行完畢。
結果就如同大家所看到的,跑出很亮眼的成績。還好 TTFT 沒有擠進 0.5%, 讓我還有點空間可以挑毛病 … Orz
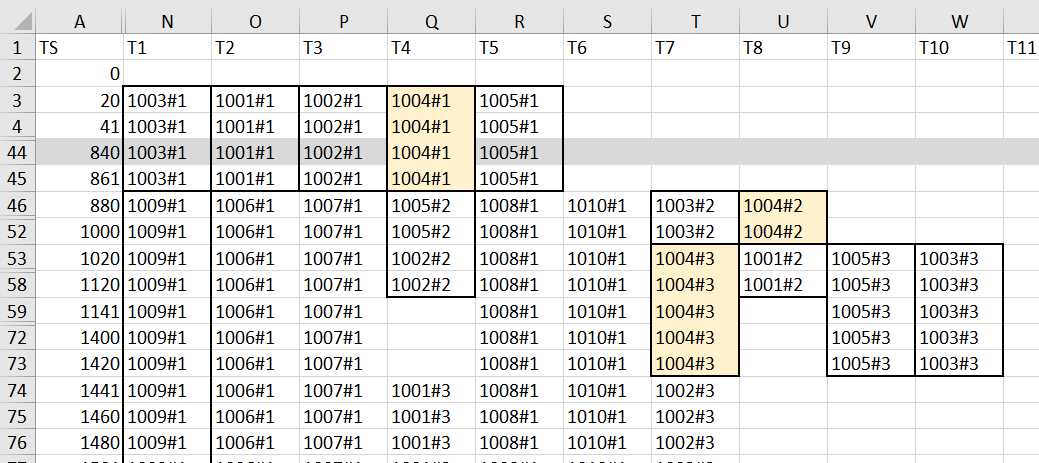
交出排程的控制權,給 ThreadPool 這類通用的排程機制,大概都有這種盲點,針對個案的最佳化,稍微要碰一點運氣,但是整體的成效都很讚。我一樣用 log 來看,第一個完成的其實是 Task Id 為 1004 (其實 1003 1005 都是同時完成的),我特地把 1004 三個步驟的完成順序標示出來 (淺黃色)。
整體而言,沒有在 20ms 這樣的區間看的到的浪費,但是整體來看,每個 threads 的排程排的有點凌亂,難以避免的是有些空檔沒被填滿,而排程之間也沒有完全按照順序執行,有些微的最佳化空間就沒把握到 (例如第一個進去的 Task: 1001, 沒有被排在第一個執行完畢)。
當然這些影響並不大,所以還有擠進 1% 範圍內,只是剛剛好就掉出 0.5% 的範圍內了 (好險 XDD)。
如果考量實際的應用,這份實作大概可以當作範本給大家觀摩了,處理的架構,背後的機制,細節的處理都做的不錯。真的要挑剔就是 code 的封裝還可以再改善一點而已。另外就是如果沒有太多 worker threads 調節的情況 (要動態建立新的 thread, 或是回收),可以考慮自己維護 threads, 可以控制的更精準一點。
PR10, AndyDemo.AndyTaskRunner
接下來是 PR10 andy19900208 網友的 code:
public class AndyTaskRunner : TaskRunnerBase
{
public SemaphoreSlim sem_1 = new SemaphoreSlim(5);
public SemaphoreSlim sem_2 = new SemaphoreSlim(3);
public SemaphoreSlim sem_3 = new SemaphoreSlim(3);
public override void Run(IEnumerable<MyTask> tasks)
{
Parallel.ForEach(tasks, (myTask)=>{
sem_1.Wait();
myTask.DoStepN(1);
sem_1.Release();
sem_2.Wait();
myTask.DoStepN(2);
sem_2.Release();
sem_3.Wait();
myTask.DoStepN(3);
sem_3.Release();
});
}
}
Benchmark 成績摘要:
- TTFT: 1433.35 (100.30%)
- TTLT: 182791.88 (104.82%)
- AVG_WAIT: 87302.68 (101.69%)
簡潔有力的程式碼,簡單的說就是直接用 TPL(Task Parallel Library) 來把每個 task (包含 step 1 ~ 3) 拆開丟給 .NET 去排程執行。由於沒有再去拆細 Step1 ~ 3, 反而整體的效能都做到不錯的平衡。雖然 TTLT / AVG_WAIT 沒有能擠進 1% 的範圍內,但是以這樣的 code 複雜度,能做到這樣的成效,在實戰的時候是很實用的作法 (實戰不會在乎那 1% 啦,但是你別把差距 100% 的東西推上線還比較重要)。
給 Andy 的建議: 真的要挑就只有兩個地方..
- 在
Task內去控制Semaphore沒太大的意義 (我在MyTask背後都做了一樣的事情) Parallel.ForEach()沒給他明確的指示,因此背後使用的 thread 數量可能會跟你想像的有很大的落差,也許背後預設會直接用 CPU x N 的方式來決定。
不過,如果要挑戰自己的極限,可以試試更精準的手法來寫這段 code…
PR11, MazeDemo.MazeTaskRunner
public override void Run(IEnumerable<MyTask> tasks)
{
if (tasks == null)
{
throw new ArgumentNullException();
}
var tasklist = Task.WhenAll(
Partitioner.Create(tasks)
.GetPartitions(Environment.ProcessorCount)
.Select(partition => Task.Run(() =>
{
using (partition)
while (partition.MoveNext())
{
if (partition.Current == null) continue;
partition.Current.DoStepN(1);
partition.Current.DoStepN(2);
partition.Current.DoStepN(3);
}
})));
tasklist.GetAwaiter().GetResult();
}
Benchmark 成績摘要:
- TTFT: 1432.57 (100.25%)
- TTLT: 174593.59 (100.12%)
- AVG_WAIT: 87746.53 (102.20%)
這也是個寫的很收斂的案例, 雖然跑出來的成績沒有樣樣都理想,但是實戰上只要用幾行 code 就能做到逼近理想直的效能,這是很實用的案例。
這結構基本上也是 PLINQ(Parallel LINQ) 的應用。透過 Partitioner 把 tasks 先分群, 然後再一群一群的交給 Select 分頭執行。比起直接用 TPL 或是 PLINQ, 多了一層分層的能力。
這寫法精妙的地方在於,巧妙的利用分群的能力,完全把控制 thread 數量的任務往 PLINQ 裡面丟了,一行 code 都不用沾到,而實質上卻又有類似 thread pool 的好處。不過分群最怕的就是分配不均,這案例看來沒有特別指定 partition 的機制,只給了 CPU 數量當作上限, 基本上我就把它當作隨機了。每個 task 的 step 並沒有分開處理, 就單純的循序,因此能很有效的控制 WIP
同樣的,我也覺得沒啥好挑毛病了,這些很精簡的 code, 又都能達到不錯的效能水準 (其實跟理想值差距 10% 以內都算實用了),如果不是拿來拚 benchmark 的話,都是實際拿來運用在 project 上的好選擇。
參考文章: https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/custom-partitioners-for-plinq-and-tpl
範例與總結
其實我在公司內部 (大約是 2019/07) 跟同事們在討論這問題時,我就自己寫了各種方案的 sample code 了,只是先前怕影響大家的思考我都沒拿出來。這次在 merge 各位的 PR, 老實說有點擔心… 哈哈哈,看到各種精巧的寫法,我還挺擔心招牌被拆掉 XDD
還好有保住一點面子,雖然沒有辦法所有項目都取得領先,但是我標榜 “精準” 控制的原則,讓我順利的在 TTFT, TTLT, AVG_WAIT 三項都還能擠進前 0.5% … 最後我就拿我自己的 sample code 當作結尾吧! 同時我也以我的角度,來總結一下各位使用的幾種方式。
首選: AndrewPipelineTaskRunner1
public class AndrewPipelineTaskRunner1 : TaskRunnerBase
{
public override void Run(IEnumerable<MyTask> tasks)
{
List<Thread> threads = new List<Thread>();
Thread t = null;
int[] counts = { 0, 5, 3, 3 };
for (int step = 1; step <= 3; step++)
{
for (int i = 0; i < counts[step]; i++)
{
threads.Add(t = new Thread(this.DoAllStepN)); t.Start(step);
}
}
foreach (var task in tasks) this.queues[1].Add(task);
for (int step = 1; step <= 3; step++)
{
this.queues[step].CompleteAdding();
for (int i = 0; i < counts[step]; i++)
{
threads[0].Join();
threads.RemoveAt(0);
}
}
}
private BlockingCollection<MyTask>[] queues = new BlockingCollection<MyTask>[3 + 1]
{
null,
new BlockingCollection<MyTask>(),
new BlockingCollection<MyTask>(),
new BlockingCollection<MyTask>(),
};
private void DoAllStepN(object step_value)
{
int step = (int)step_value;
bool _first = (step == 1);
bool _last = (step == 3);
foreach (var task in this.queues[step].GetConsumingEnumerable())
{
task.DoStepN(step);
if (!_last) this.queues[step + 1].Add(task);
}
}
}
Benchmark 成績摘要:
- TTFT: 1431.96 (100.21%)
- TTLT: 174450.21 (100.03%)
- AVG_WAIT: 85880.53 (100.03%)
我比較 old school, 所以我選擇了自己維護 thread(s), 避免任何意料之外的因素影響了整個體系的運作。我的概念是,既然每個 step 都有各自的限制,我的想法是每個 step 都有專屬的一群 threads 去服務他。中間的轉移就透過 BlockingCollection<T> 來替代就好。說真的我這版本,跟其他幾個同樣用 pipeline 的網友真的差不多,唯一差別只在於這些 BlockingCollection 之間,我是唯一一個自己精確的維護我需要的 threads 而以。其他都是 create Task 然後丟給 .NET 處理。
這也是典型的生產者消費者的處理模式啊! .NET 4.0 開始推出的 Task 實在太方便,方便到現在沒甚麼人會自己去維護 threads 了。不過越需要精準控制的情況下,直接掌握 thread 才是王道… 這樣下來,我不但可以兼顧執行順序,我也可以兼顧執行效率, 同時每個階段之間的 buffer 我也可以精準控制。
如果兩個階段之間的效率落差過大,我甚至可以簡單的控制 BlockingCollection 容量來調節我願意支出多少資源來養這些 WIP? 這些都是精準控制下你能獲得的好處。
這 sample code 我直接 push 到 github 上了,隨著這篇文章上架,各位就可以直接從 github 取得最新的 code, 有興趣的可以抓回去跑看看, 觀察看看 log.csv , 別急著看程式碼,先看看這樣的任務安排,你是否有辦法想出更好的執行方式? 如果有,再來想看看如何把他寫成 code?
唯有思考過程改變,你才不會掉入局部最佳化的困境: 不斷地盯著眼前的 code, 想著怎麼把那幾行改得更好一點? 這些事情,最後再做就好了,比起局部優化,正確的架構才是更重要的。
類似的架構,我也寫了另外幾版,不過效果都沒這版好。因此我就列出來給大家參考就好:
- 使用 PLINQ (用來取代自己維護 threads) 的版本: AndrewPipelineTaskRunner2
- 使用 Channel (用來取代 BlockingCollection) 的版本: AndrewPipelineTaskRunner3
其他類型: 使用多工排程的技巧
如果要應付實戰,同時我沒辦法那麼清楚掌握每個 task, 每個 step 之間的限制關係的話,這時使用無腦的多工處理,把複雜的問題交給 .NET 是比較好的選擇。還是一樣,我對於 code 有點潔癖,因此太囉嗦的 code 我就會想把他精簡一下。多工處理模式的架構下,我會這樣寫 code :
public class AndrewThreadTaskRunner2 : TaskRunnerBase
{
public override void Run(IEnumerable<MyTask> tasks)
{
tasks.AsParallel()
.WithDegreeOfParallelism(11)
.ForAll((t) =>
{
Task.Run(() => { t.DoStepN(1); })
.ContinueWith((x) => { t.DoStepN(2); })
.ContinueWith((x) => { t.DoStepN(3); })
.Wait();
});
}
}
我用 PLINQ 的 .AsParallel() + .ForAll() 來達到平行處理的目的。如果我要精確控制併發的數量,中間插一段 .WithDegreeOfParallelism(11) 就可以了。這就是 .NET 設計精妙之處,你不用犧牲可讀性與精簡,你仍然能精確的掌控你要的細節。
既然要交給 .NET 分配處理的順序,那就切徹底一點。在 .ForAll() 底下,我繼續把每個 step 也拆成獨立的 Task, 不過我不直接 create 新的 Task, 而是用 .ContinueWith() 掛在原本的 Task 後面。這邊的關鍵是,既然你要交給 .NET 全權處理,那你就要盡可能的給他足夠的提示,告訴他怎樣的順序是你最想要的。這樣 .NET 在做全面優化的同時,才知道該怎麼安排你的 Task.
這樣處理下來,我可以用一行 code, 也能做到大部分上述的效果。一行 code 可以做到這些事, C/P 直算很高的了。這也是我為何會在實際的專案上選擇這樣做的原因了。除非我要處理的是很核心的任務,或是這部分 code 要面臨很大量的任務,差距 1% 可能就影響到不少的雲端運算成本,這時我就會把我壓箱寶都拿出來使用。
結語
看到最後,不論你有沒有參與這次的練習挑戰,有無任何想法嗎?
很多人都說,程式寫到最後,用什麼語言,用什麼框架已經不重要了,這次練習就是個例子;基本上如果你腦袋裡的解決方案夠清楚,你對你採用的程式語言掌握能力也足夠,其實這類問題很輕鬆就可以解決掉的。越是關鍵的核心服務或是元件,設計就越精巧。我常常拿小時候拆解鬧鐘的經驗當作比喻,拆玩具車之類的,我都很容易組裝回去,但是拆開鬧鐘就沒那麼容易了,因為鐘錶的零件很多巧妙的設計,一個齒輪,一個拉桿,同時連動好幾個機關… 這樣精巧的設計造就了用很少的零件,就能做到複雜的任務。
後來念自然課、物理課也有一樣的感覺,看到蒸汽機,引擎的設計也是,活塞跟點火機制的設計也是一樣,整個循環一氣呵成。寫這種核心元件我也有這種感覺,十年前看 MSDN 文章, Stream Pipeline 只要幾十行就變出來, 某前輩寫的 thread pool, 一百行不到就可以把完整功能的 thread pool 變出來,都讓我覺得這才是真正的本事啊!
不過這種能力也不容易培養,因此我才想用這練習題,先讓大家親身體會一下這類問題應該如何動手? 收集各位貢獻的 code, 我再補上一些整理與 code review, 也讓大家可以更清楚其中設計的奧妙與差異。最後就是結果,這個 benchmark 並不是讓各位拿來拚輸贏的,而是想辦法讓你的程式碼表現能夠量化。不同的場景,你會有不同的指標需要照顧。以這次的練習為例,如果你無法同時兼顧所有的指標,我希望你對這練習的掌握,能夠精準到需求方告訴你哪個指標最重要,你都有能力把他優化到極致。
這是我第一次嘗試這樣的練習,除了我自己寫 sample code 跟文章說明我的想法之外,我也讓有興趣參與的朋友親自貢獻一些 code. 有實際練習過,再來看 code review 應該會更有感覺。如果你覺得這方法對你很有幫助,歡迎在我的 facebook 粉絲專頁給我意見, 如果你的朋友也有興趣, 也歡迎你把文章轉貼分享給他。
最後,再次感謝這次參加練習,以及願意發 PR 給我的朋友 :)
參考資料
這次引用了很多參考文章, 我把它收集起來列再一起:
- .NET Conf 2017 Taiwan, Study4TW, 響應式程式設計 (Reactive Programming) 之 .NET Core 應用
- Asynchronous Producer Consumer Pattern in .NET (C#)
- Microsoft .NET Guide (EBOOK): Parallel Programming in .NET
