上週 OpenAI 發表的 GPT5.2 的同時, 也發布了測試報告.. 其中這張圖引起我的關注, 正好之前 (2025/09) 我才貼過一篇研究論文的心得, 講的正好是 LLM 針對 long context 的 “大海撈針” 性能測試…
這測試蠻有意思的, 在 context window 不同位置放了應該要被找到的資訊 ( “針” 就是指這個 ), 然後塞了一堆不相關的資訊 ( 就是稻草堆, 不過中文講的是大海.. 總之一樣的意思 )… 而這實驗就是要測試, context 的大小, 對 LLM 能否找出正確的資訊的能力…
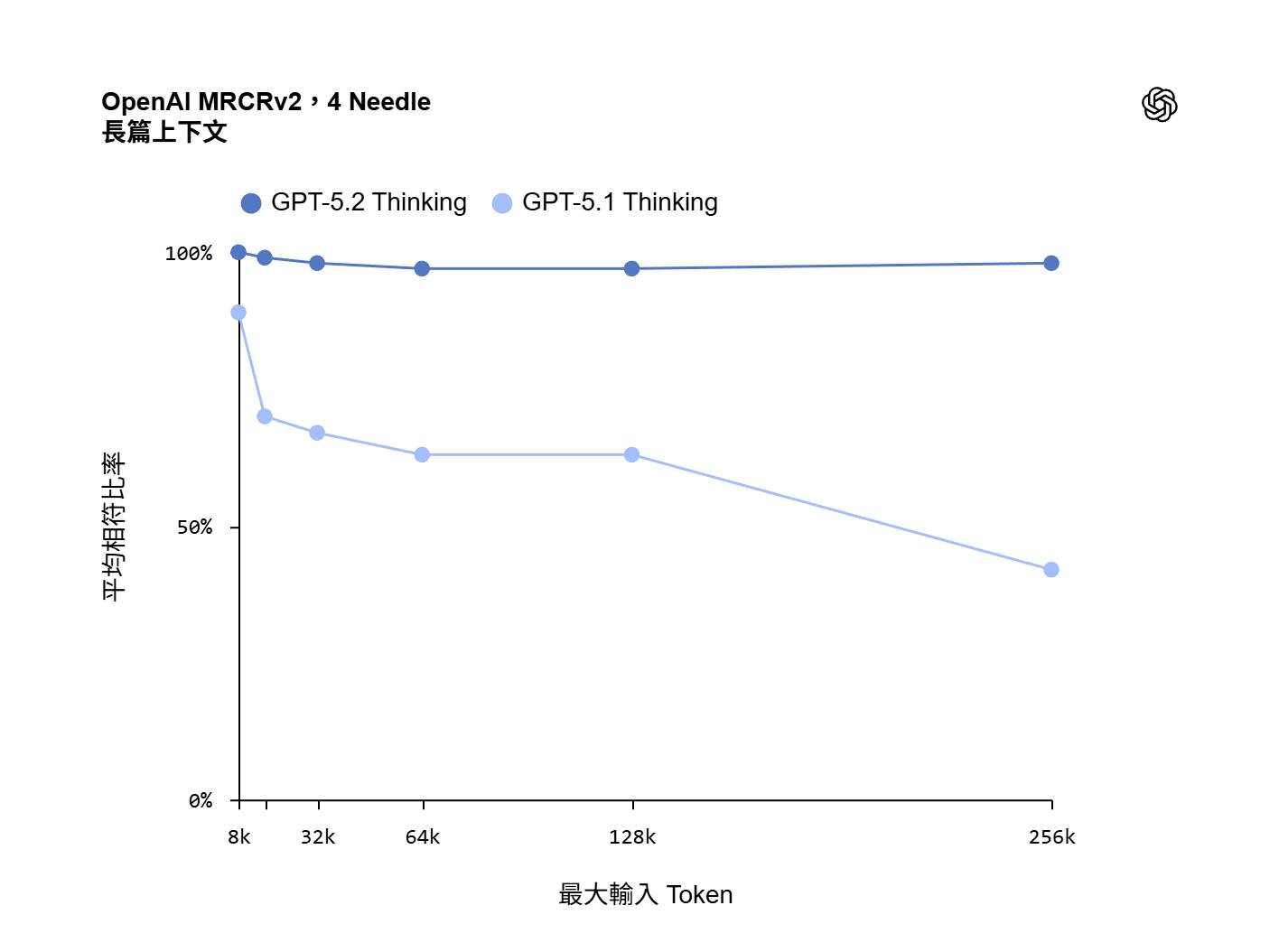
單純看到這張圖, 大家可能無感, 但是在 GPT5.2 之前, context 放大後, LLM 找到正確資料的能力可是呈指數的滑落的… GPT5.1 其實還算不錯的了, 其他模型更是慘不忍睹 ( 可以參考我 2025/09 的心得, 我放在留言 )
而這次 GPT5.2 的測試報告, 幾乎無視 context 的大小, 維持幾乎是滿分的 100% …, 這代表的意思是, 就算你把 context window 塞滿, GPT5.2 也能正確的把資訊抓出來
實際應用的場景, 最有感的就是 RAG, 以及你丟長文件給 LLM 整理了。RAG 的第一個步驟, 通常都是先用向量檢索, 挑出高度相關的內容, 而 “相關” 還不代表是正確答案, 只是有關聯而已, 因此下一步還要靠 LLM 彙整。向量檢索的精確度對回答問題而言還不夠高, 你要是挑太少內容, 可能正確的答案根本沒被放進 context, 挑太多的話 context 就算還沒炸掉, 正確率也會大幅滑落, 這其實是兩難, 很難調校到理想狀態.. 在 context windows 爆掉之前, 你的正確率早就爆掉了… 這種情況下拉高 context windows 大小上限, 其實沒什麼實質意義..
留意一下, OpenAI 的圖表, X 軸是 context size, 是 “線性” 的, 從 8k 到 256k.., 而先前的研究報告, X 軸也是 context size , 但是數字是 “對數” 的, 從 10^3 (1k) 到 10^6 (1000k) … 如果把 OpenAI 提供的數據換成對數, 這正確率會掉的更快… 大家別只看圖形, 沒看座標 XDD, 另外要注意的是, 這測試是找出四根針 (4 needle), 先前我貼的報告是找一根針, 難度也不同..
GPT5.2, 我自己還沒認真測試過, 如果真如 OpenAI 自己宣稱, 那真是不得了, 開始可以不用擔心 context size 對正確率的影響了。看起來 GPT5.2 沒那麼不堪一擊, 過去被這類問題困擾過的朋友們可以試試看..
文內提到的參考資料, 我都放在留言