#6 進階 RAG 應用, 生成檢索專用的資訊
有了 SK ( Semantic Kernel ) 跟 MSKM ( Microsoft Kernel Memory ), 對於 RAG 這樣的應用, 我們開始有了高一層的控制能力了。今天就來聊聊面對 RAG 的應用時, 有哪些在設計之初就能改善檢索效果的技巧吧
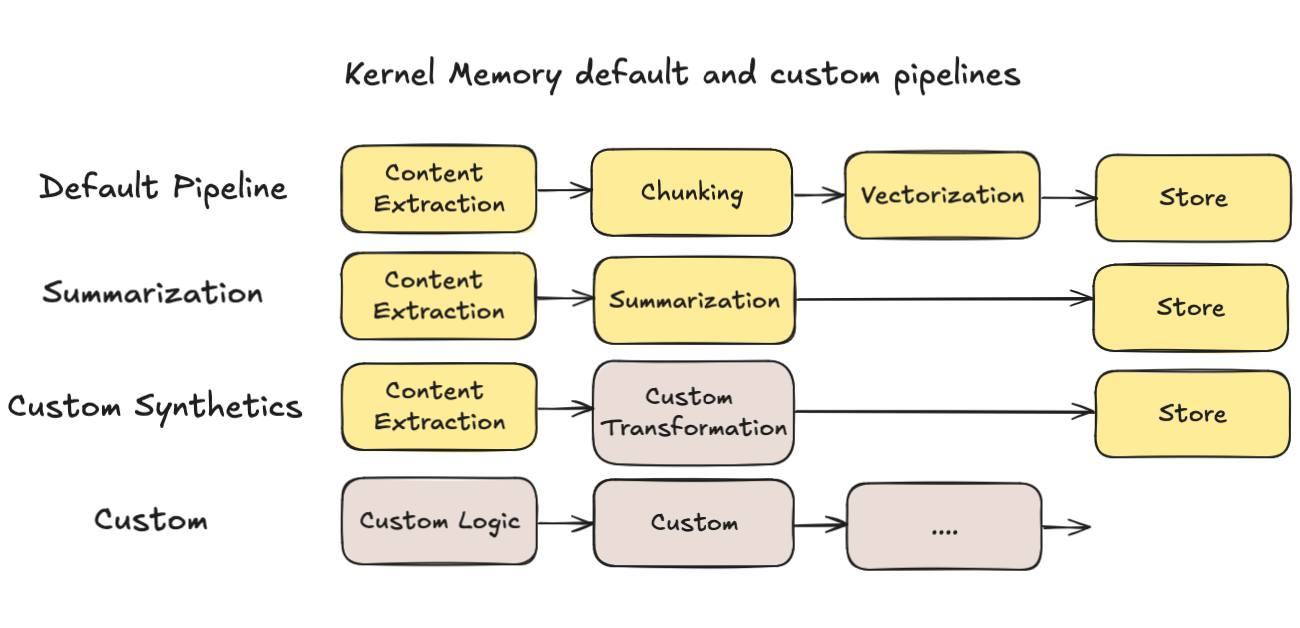
大部分教科書, 都是教你要把內容分段 (分段有很多策略, 長度, 分段符號, 重疊範圍等等),不過我實際拿我自己部落格文章來測試,老實說效果並沒有很好.. 拿最基本的 MSKM 預設設定 ( pipeline ),流程大致上是這樣:
-
文字化 ( content extraction ) 如果你的內容不是純文字, 會先有一個 handler 來處理。例如 PDF 先轉成文字, 或是圖片先進行 OCR 等等
-
分段 ( chunking ) RAG 主要檢索用的技巧, 就是把內容向量化。向量化的模型通常都有最適合的內容大小。以我使用的 OpenAI text-embedding-large3 來說, 建議輸入是 512 tokens, 上限是 8191 tokens .. 文字太長的話就需要先分段, 也就是 chunking 在做的事情
-
向量化 ( vectorization ) 就是把 (2) 分段後的文字,逐段都交給模型轉成向量。這過程有的地方會稱他為 “內嵌” (embedding)
-
儲存 ( store ) 單純的把前面處理的資訊, 原始內容, meta data, 還有向量通通都存起來。一般會直接存到支援向量搜尋的 database, 作為後續檢索查詢使用的資料來源
然而,我實際拿我部落格文章測試,基本檢索其實還不錯,但是當我問題問的遠一點就很糟糕了。有在看我文章的人,大概都知道,我文章寫得很長… 初步統計一下,我部落格的 .md 檔案統計:
- 總共有 330 篇文章 ( 後期都是 .md , 早期用 .html )
- 單篇文章純文字內容, 約在 50k ~ 100k
而向量檢索的基本動作,是把你的詢問也轉換成向量, 然後拿著這向量 (query) 到資料庫內挑出相關度高的內容,最後把這些資料交給 LLM 合成最終答案。如果你不對你自己的檢索內容做任何調整,那麼一篇文章平均會被切成 100+ 個分段 ( partitions ),你的查詢,會從這些分段中找出相關度高的來使用。但是,資訊的密度根本對不齊,往往會得到牛頭不對馬嘴的狀況。
舉幾個例子,我寫了篇 WSL 的應用,花了很多篇幅介紹 WSL 應用的細節跟隱藏的地雷,然後有人問了 “WSL 能幹嘛” 的時候,你希望向量資料庫給你那些分段?
基本上這是無解的題目,因為給哪一段都不對啊… 除非我自己寫文章時候習慣很好,最前面的簡介就寫得很好,把整篇文章的摘要都濃縮在一個分段內,那麼 RAG 檢索時候這簡介應該會排到比較高的分數,會被拿來生成答案。
雖然有解法了 (我自己替每篇文章補上一段 1000 字以內的摘要..),不過這時代有 LLM,我應該不用那麼辛苦才對。因此,我開始嘗試,能不能在把文章送進去檢索前,我自己先靠 LLM 生成我欠缺的部分? (摘要)
果然效果好的多,而且 MSKM 的 pipeline 也內建這機制了,你只要在 ImportText 時指定自訂的 pipeline, 加上 Summarization 這個 handler 就夠了。
不過我想做更多嘗試,因此我先選擇在 MSKM 外面先自己處理好內容,暫時沒有直接搬進 MSKM 的 Handlers. 除了前面做的摘要 ( summarization ) 之外,我多做了好幾種嘗試,包含:
- 全文章的摘要 ( abstract )
- 文章每個段落的摘要 ( paragraph-abstract )
- 轉成 FAQ 清單 ( question / answer )
- 轉成解決方案案例 ( problem / root cause / resolution / example )
其餘還有別的嘗試,我就不一一列出了。這效果比起之前無腦的 RAG 好得多,因為很多查詢的角度,我可以得到語意更正確的檢索結果了。除了前面提到的摘要之外,我拿 FAQ 跟解決方案當例子
我的文章寫了很多我解題的思路,但是大家應該都是抱著問題來找答案的,所以提出的查詢應該都是以問題為主 ( 包含: question, 也包含 problem, 中文都叫做 “問題”,其實意義上有區隔 )。
這是視角的問題,使用者用他的視角來詢問,而我用我的視角來寫文章內容。當兩邊的視角不一致的時候,單純向量化的相似性是挑不出兩者的關聯的。因此我主要解題的方向就是,靠 LLM 良好的推理與彙整能力,將我文章內容生成成對應視角的內容 (我列了那四項就是四種視角),再把這些內容標上合適的 tags, 通通向量化加入檢索。
因此,應用的方式開始更靈活也更有趣了。由於這些是文章產生或異動時處理一次就好的任務,跟使用者查了幾次無關,因此我挑了貴一點的模型來測試 ( 我用 OpenAI 的 o1 ),效果還不錯,用 SK 先生成這些檢索用的內容後,再交給 MSKM 檢索處理。最後讓 AI APPs, ChatBot, Agent 等前端介面直接到 MSKM 查詢相關資訊,用 RAG 來生成最終答案回應使用者
當我搞懂這一切後,我才發覺 RAG 不應該是一套 “系統”,或是 “產品” 才對,她更像是 design patterns 那樣的設計模式,告訴你 AI 的知識檢索該怎麼做。RAG 終究需要做某種程度的客製化調整才會好用,因此你如果想做好 RAG,應該要有對應的技能,也要對你要檢索的內容,跟怎麼被查詢的方式有所掌握。最後你手邊應該要有一些你掌握度高的工具箱,必要時能隨時拿出來應用。這時 SK, MSKM, 還有其他 No Code 的 AI APPs 平台,都會是你的好幫手。
– 葉配時間又來了,以上這些概念,我都有對應的 sample code 可以當場示範,有興趣的請參加 03/25 的直播 XDD
直播連結請見第一個留言