
不知道要找啥當 Logo 了, 這次就放 NieR Automata 吧, 一個操控 AI (2B, 9S and A2) 的 context window 到極致的故事… (咦?)
–
首先, 我自己打臉我半年前寫的那篇 聊聊 Vibe Testing 實驗心得 的文章。 其實那篇文章研究的 “自動執行 API 測試” 是可行的, 但是應該拿來探索測試步驟用, 而不是拿來當最終重複執行用。 當時我的思路是:
” 現在的流程太花人工了, 那我讓 AI 替代人工來跑測試吧 “
結果, 不知不覺就掉到這 “局部最佳化” 的陷阱裡.., 手上有威力很強的新武器, 我卻還在用傳統作戰的戰術去運用它… 有效是有效, 但是總覺得沒有完全發揮出應有的戰力…
所以我在想, 如果我重新設計工作流程, 是否這一切都會變得簡單且有效率? 因此重新想過一輪之後, 這篇我想談:
” 從 AI 的能力出發, 重新思考 “測試” 這件事應該怎麼進行? “
這陣子思考 + 嘗試實作, 有了一點心得, 我換了個方式拿 AI 來進行軟體測試, 這次的效果比我預期的好, 於是就有了這篇…。
我想起 Sam Altman 前陣子的專訪, 有一段話讓我印象深刻, 他提到不同世代的人, 對 AI 的使用方式會有很大的差異, 而其中提到這句話:
20 歲的年輕人, 把 ChatGPT 當成 “作業系統” 來使用…
原文如下 Sam Altman says young people use ChatGPT as an operating system :
”
Older people use ChatGPT as a Google replacement.
People in their 20s and 30s use it as a life advisor.
People in college use it as an operating system.
“
什麼叫做 “把 AI 當作 OS 來使用” ? 對應到我這次的主題, 我應該思考的是:
”
如果我想從 AI 已經是作業系統般的存在時, 那測試流程會變成什麼樣子?
“
回到 30 年前的 DOS 時代, 那時的 OS 沒那麼複雜, 就是處理資料 (file) 跟執行應用 (.exe) 而已, 所以才叫做 DOS ( Disk Operating System ), 而現在的 coding agent, 不就也是同樣的模式嗎? 大部分情況下都是處理資訊 (對話) 跟調用工具 (MCP), 而重點則是你所有事情都依賴他來處理了
這就是使用深度的差異吧, developer 這族群, 算是目前工作流程被 AI 影響最巨大的族群了, 我看到很多人已經拿 Claude Code 這類 CLI Tools 來當作他們主要的工作介面, 不只用來寫 code, 也用來寫文件, 更用來做各種其他任務或是自動化…, 而回到半年前我用 vibe testing 的角度來思考測試這件事, 我發現我的思路是:
”
vibe coding 很炫, 那我是不是也能 vibe testing 呢?
目前的測試都需要仰賴人工操作, 那我是不是也能用 AI 來代替人工操作呢?
如何讓 AI tools 無痛的融入現有的測試流程, 解放過去投在裡面的人力??
“
其實這些思路都沒錯, 也都得到效率的提升, 但是我總覺得不對勁, 因為最關鍵的流程 (workflow) 並沒有改變, 只是把 “人” 換成 “AI” 而已。 如果 AI 的能力已經是個 “變革”, 其實整個環節搭配的平衡都已經改變了, 流程勢必要重新檢視一次才對。 人類有擅長的能力 (Brain), AI 也有他擅長的能力 (GPU), 而傳統的應用程式也是 (CPU), 能鑑別出這些 “運算資源” 的使用範圍跟邊界, 適當的資源配置, 然後重新設計流程, 才是最重要的事情。
過去軟體開發的流程, 最大瓶頸就是 “人寫 code 的速度太慢”, 所有流程都圍繞著這點在強化跟改善。 突然間出現了 coding agent, 讓 “coding” 這件事突然變成 10x, 平衡被打破了, 瓶頸轉移到需求跟規格不夠清楚, 所以現在軟體開發領域的流程整個被重塑了, 開始也有 SDD 這類嚴謹的流程被提出來…, 這些都是 “基本的流程” 正在被改變的現象。
因此, 距離我上一次談 vibe testing 這題目隔了五個月, 我重新想這題目的同時, 也研究了 MCP design, Context Engineering, SpecKit 等等其他題目, 重新用 “TestKit” 的想法來包裝 AI-First Testing 這題目, 成果還蠻令人滿意的, 於是整理了這篇文章來分享一下我的心得。
接下來的文章內容, 我會在第一段先介紹想法的轉變, 然後把測試流程拆成三個關鍵步驟來示範 TestKit:
- 決定你該測什麼: 用 AI 把需求展開成 Decision Table, 輔助專家把「對的測試」定義清楚
- 決定你該怎麼測: 把 AI 放在「探索 + 產生自動化測試程序」的位置, 而不是讓它去負責執行測試
- 決定如何自動化: 把驗證過的測試程序自動化, 讓 AI 精準地寫出自動化測試的程式碼
而把這些基礎都做好, 還有附加的效益:
- 讓 test case 能重複運用, 搭配不同操作介面的規格, 可以同時覆蓋 API / UI 的測試需求
- 不再需要維護多份同樣邏輯不同操作介面的測試案例, 降低測試文件的數量級
1. AI-First Testing
概念談完了, 這段就來聊聊對於 AI-First Testing 工作流程的想法吧, 我會把想法從 “理想” 收斂到 “具體可行” 的流程為止, 而文章的後半段, 則是敘述依據這些想法實際做出來的 side project 展示可行性。
“測試” 要做的好, 其實是很困難的一件事, 第一個痛點就是: 測試的 “量體” 太大了, 這代表有寫不完的測試案例, 準備不完的測試資料, 以及跑不完的手動 & 自動測試。 即使有 AI 加持, 你要測完所有的狀況也幾乎是不可能的事情, 勢必要有一些方法, 有效率的展開測試案例, 並且優先完成重要有價值的測試才是正途。
1-1. Workflow Design Concept
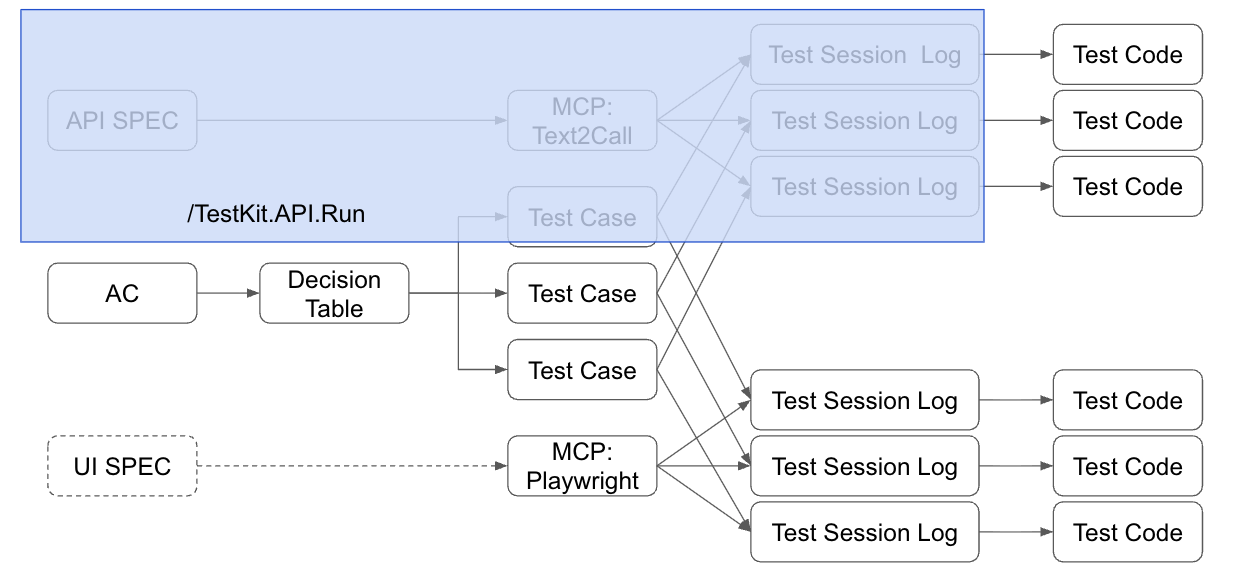
為了聚焦我的主題跟思路, 不相關的環節我就大幅簡化了, 我用這張圖來說明:
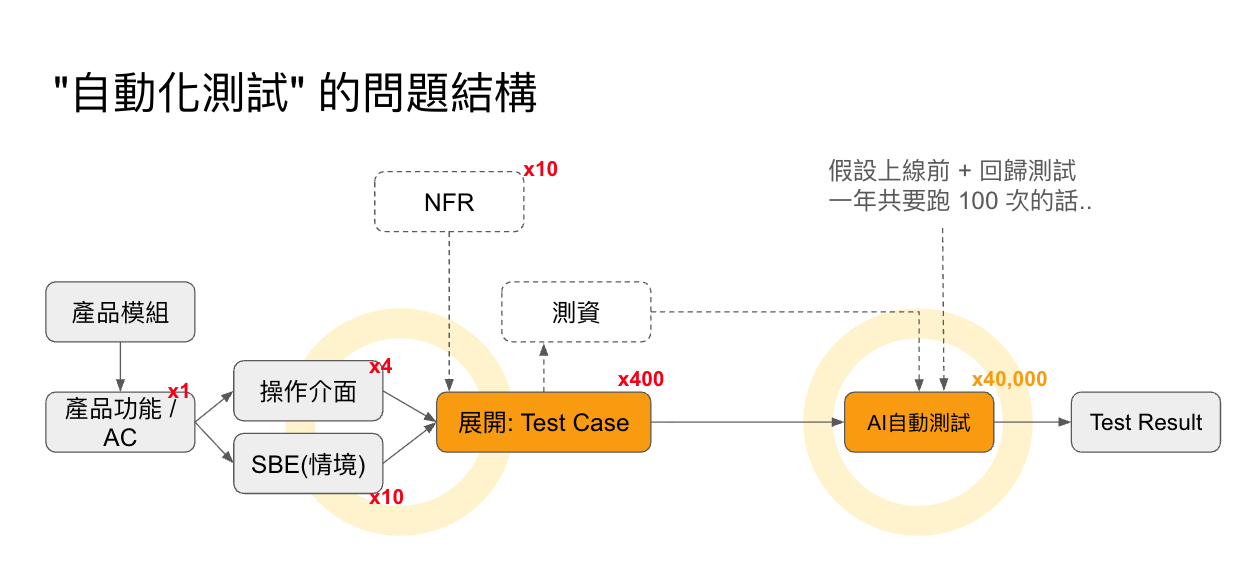
從左到右, 是從需求規格中的驗收條件 (AC, Acceptance Criteria) 開始, 到測試結果的流程。 每個步驟上面標的數字, 就是可能要展開的數量 (數量級)。
試著估算看看:
如果系統需求列了一項 AC (ex: 購物車結帳時必須檢查折扣計算規則, 以及購買條件限制), 最終應該展開多少筆 Test Cases ? 在系統的生命週期內你需要執行幾次測試? 成本與代價是什麼?
測試量體估算:
- 每 1 個 AC 平均展開 10+ 個 Test Case
- 系統有 4 種操作方式 (操作: Web UI, Android APP, iOS APP, REST API)
- 系統有 10 種非功能性需求 (NFR, Non Functional Requirement, 如資安, 授權, 效能等等)
測試執行瓶頸:
- 測項數量:
如果這些組合都展開, 每一個 AC 就必須要維護 4 + 10 + 10 份規格文件, 以及產生出來的 1 x 4 x 10 x 10 = 400 份不同的測試腳本… 這量體, 光是文件就已經難以維護了.. 過去需要人工撰寫, 而現在即使使用 AI 來撰寫, 這麼多的數量就算只要 Review 也是一大負擔。 這是第一個瓶頸。 - 探索步驟:
測試案例通常需要由人工將測試要踩過的商業情境, 轉化成系統的操作步驟。 這是另一個非常花費人力的環節。 AI 現在有理解意圖的能力, 如果有明確的操作規格 (api spec), 搭配只保留抽象敘述的測試案例, AI 是有能力幫你探索出操作步驟的, 但是這需要花時間讓 AI 理解規格, 並且嘗試呼叫 api 來確認是否完成任務。 這是第二個瓶頸。 - 執行次數:
就算真的有 400 份測試案例, 一年你會需要跑幾輪測試?
假設一週 release 一次, 每次 release 前內部 QA 至少測一次, release 後正式環境也至少測一次, 那一年應該要跑 50 x 2 = 100 輪, 總共是 400 x 100 = 40,000 次測試… 要有效率, 並且確實, 用合理的成本執行他們, 是第三個瓶頸。
試算執行成本:
一年執行 40000 次測試, 若用 AI 來自動執行, 需要花多少錢?
如果我真的用 vibe testing 用 AI 當下執行 API test, 每跑完一次約需要 2 分鐘, 對應的 api token 約 USD$ 0.03 (剛好約 NTD$ 1.0) 左右, 一年要花 2 x 40000 = 80000 分鐘來執行 (55.56 天), 整個過程共計要花掉 4 萬台幣的 token 費用… 而這只是完成 “一個 AC” 的要求需要的測試而已…
簡單的計算, 就知道這方法還無法實際應用。 雖然比單純用 “人力” 來測試已經好很多了, 但是遠遠跟不上測試的通膨啊…, 而且 AI 執行測試也有缺點, 除了速度跟費用之外, AI 每次執行的結果都有一些差異, 這也是另一個頭痛的問題。
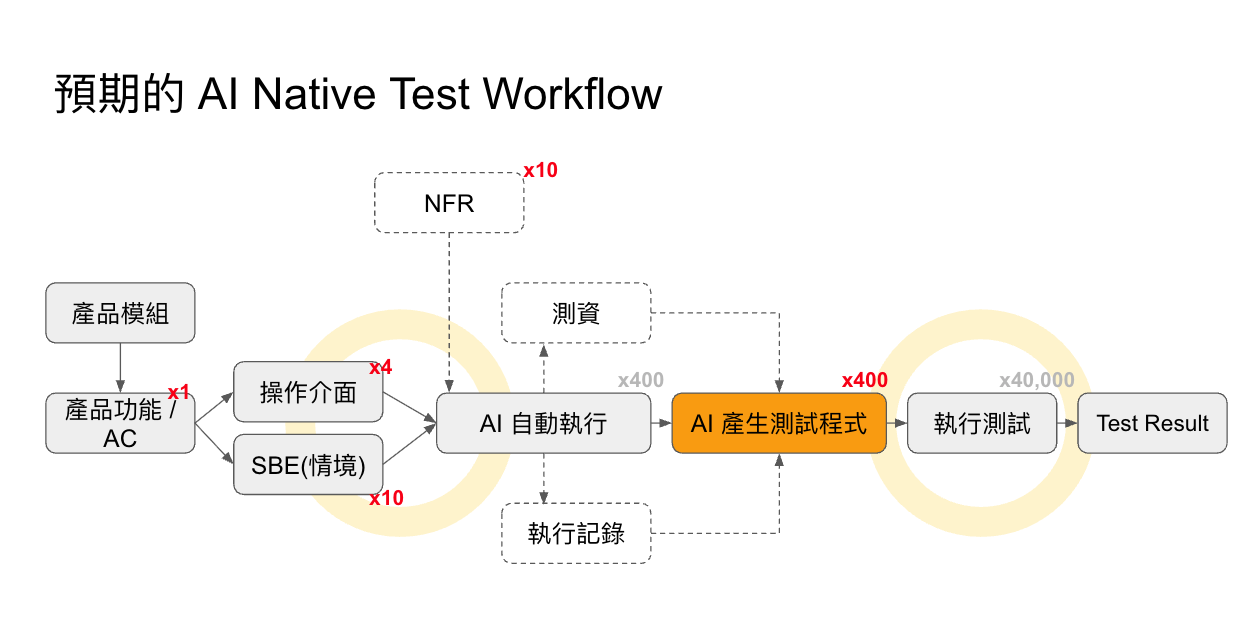
合理的解套方式, 應該是 “寫自動化測試程式” 才對, 因為他花的是 CPU, 不是很貴的 GPU, 也不是很有限的 Brain (人腦)… (成本: Brain » GPU » CPU) 因此整個流程應該導向 “探索” 的結果如何有精準有效率的轉化成 “自動化測試” 程式?
這就是 AI 自動化測試 “左移” 啊, 讓 AI 專注 “探索” 測試步驟。 當探索確定後, 剩下單純 “自動化” 的要求, 則再交給 AI 一次性的翻譯成對應的自動化測試程式就好, 這樣既提高效率, 降低成本, 同時也能確保每次執行的測試步驟都會一模一樣 。
同樣的, 測試案例的數量問題, 也能 “左移”。 如果我能將 AC + 決策表維護好, 是否就能穩定的輸出展開的 test cases? 如果 test case 夠單純, 不涉及操作細節, 需要的當下再靠 AI 的理解能力, 搭配操作規格 (api spec) 就能展開操作步驟的話, 是否就能讓 test case 高度複用?
這些流程越想越清晰, 越能掌握關鍵, 因此既有流程該調整的是:
-
“文件的維護” 左移:
驗收條件 (AC) 的展開, 用一張決策表 (decision table) 來處理, 就能框出測試範圍以及關鍵的控制變因; 而展開的測試案例 (test case) 若能維持抽象層級, 就不需要為了各種操作介面重複產生不同的測試案例了。 如果這些都有做到, 我需要維護的是 (decision table) x 1 + (test case) x 10, 而不是原本要維護的 4 (操作方式) x 10 (測試案例) x 10 (非功能性需求) = 400 -
“自動化執行” 左移: 自動化執行再拆解, 困難的地方有兩個, 一個是探索 (看規格跟情境, 對應出操作步驟的過程), 這在過去通常都要靠工程師的經驗來決定。 而另一個環節, 則是讓他自動化執行。 對比每次都用 AI 或人工執行 40000 次測試, 花費的是 40000 x GPU; 而改善過的方法, 你需要執行 400 次探索 (GPU), 400 次測試程式碼生成 (GPU), 40000 次自動化測試 (CPU), 最大的瓶頸跟不確定性, 已經簡化成一般的程式執行了, 從 40000 次 AI 任務, 降低為 400 + 400 次 AI 任務
改良過的流程, 我用這張圖來表達:
剩下的就是親自找一個實際案例來驗證看看了, 這也是這篇文章我想要展示的主要內容。
1-2. TestKit 的構想
接下來, 這流程跟想法, 我想要把他具體化一點, 我直覺想到的就是 SpecKit 的做法, 我自己仿照那個樣貌, 弄了一套簡單的 TestKit 來封裝我想像的 AI-First Testing Workflow.
前面拆解的步驟, 我用系統的角度再重新定義一次 (括號裡面代表的就是 TestKit 對應的指令):
-
Generate Test Case from Decision Table (TestKit.GenTest)
展開測試: 將 AC 展開成 decision table, 並且決定測試範圍, 收斂出有價值的測試, 並將之轉成可用的 test case(s). -
Explore Test Steps with AI Agent (TestKit.API.Run / TestKit.WEB.Run)
探索執行步驟: 讓 AI 探索測試的執行步驟, 詳細記錄執行過程, 並確認測試結果。 符合的結果的執行過程, 能當作後續自動化的重要參考。 -
Generate Test Code from Test Case & Test Steps (TestKit.API.GenCode / TestKit.WEB.GenCode)
自動化: 將 (1) 及 (2) 獲得的成果, 透過 AI 生成能重複執行測試的 test code.
畫成流程圖, 以 “產出” 文件的視角來看, 大概就是這樣:
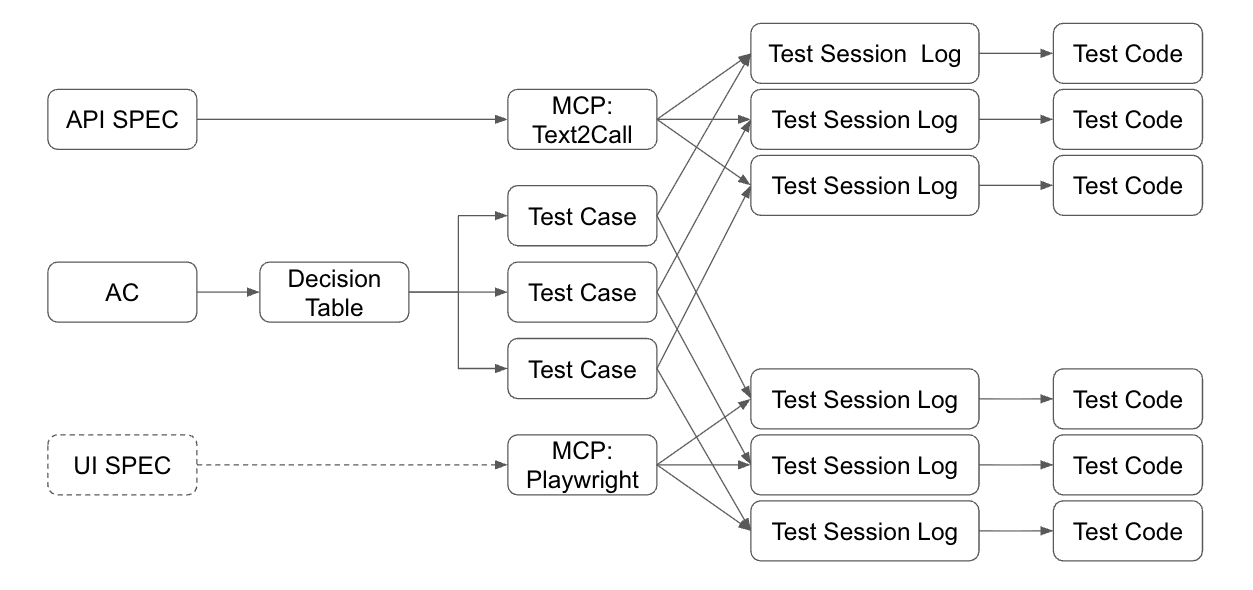
每個步驟, 都有他主要的目的, 也有關鍵的產出, 我列一張對照表:
| 編號 | 目的 | 產出文件 | 檢核項目 |
|---|---|---|---|
| 1 | 決定測試的範圍 | decision table, test case(s) | 條件組合完整性、測試案例邊界值 |
| 2 | 探索測試的步驟 | test session log, summary | 執行步驟正確性、結果驗證精準度 |
| 3 | 自動化執行測試 | test code | 程式碼執行穩定性、正確性 |
構思到這邊, 我想像的流程大致都完善且確認下來了, 接下來就是想辦法實作出來, 證明他的可行性。 實際操作這個流程:
- 靠 AI agent 來輔助 “專家 (真人)” 來做決策, AI 負責內容整理及輸出。
- 靠 MCP 來輔助 AI agent 進行探索, 實際操作系統, 不斷嘗試與修正, 直到能順利完成為止。 MCP 需要支援步驟的記錄, 供後續步驟運用。
- 靠 AI agent + SpecKit 來生成自動化測試程式碼, 生產出大量, 行為一致的自動化測試。
試想一下步驟 (3), 我需要提什麼 spec, 才能讓 AI 寫出夠理想的測試程式碼? 其實所有必要的資訊, 都包含在 workflow 的每個階段了啊:
- 操作規格 (以 api 而言, 就是 api spec), 說明操作方式跟細節, 讓 AI 能有跡可尋
- 測試案例 (test case), 測試本身要做的事情是什麼… (流程已經準備好了)
- 操作範例 (探索測試留下來的 session log 就是最好的操作範例了)
這些必要的 spec , (1) 是流程中早已準備, (2)(3) 則是流程中間的產物, 其實我都能控制其品質, 有了這些高品質的規格, 要生成穩定可靠的程式碼並不難。
其實在做這個 side project, 最有成就感的環節就是, 你把一切都準備好, 然後看著他按照你要求動起來的那瞬間, 就像你疊完整屋子的骨牌, 然後推倒的那一瞬間一樣…
1-3. Init TestKit
接下來連續三個段落, 我會實際演練這些步驟 “具體” 該怎麼實際操作。 而這邊我用 coding agent 常用的配置方式, 自己準備了 testkit 來收整相關的資源跟設定 (我用的是 vscode + github copilot, model: claude haiku 4.5)。 因此這段我會額外穿插介紹 testkit 的說明。
我仿照 SpecKit, 把我為了 AI-First Testing Workflow 相關的準備 (包含: prompts, documents, tools) 通通都準備好了, 包裝成 TestKit. 對應上面的三大步驟, 以及我支援的兩大操作介面 (API, WEB UI), 展開成 TestKit 的五組指令 (就是上面列的: gentest, api.run, api.gencode, web.run, web.gencode)。
我沒有花太多時間準備搭配的 npm 套件 / shell script, 因此安裝就陽春一點吧, 直接 fork 我的 repo, 必要的資源都在裡面了: AndrewDemo.TestKitTemplate (不過, MCP 我還沒準備好 public release, 請耐心等候)
而搭配測試的標的, 我就用之前我為了驗證 “安得魯小舖” 而開發的 API, 我簡單做了改版, 目的是用來示範這次的 AI-First Testing Workflow..
簡單交代幾個 “安得魯小舖” 重要的 url:
- Web UI: 由於我是前端大外行, 這是完全用 vibe coding 生出來的 web ui, 純示範用途..
- REST API: 自帶支援 oauth2 授權, api 需要 access token 才能正常識別個人身分運作
- OpenAPI Spec, 對應的 api spec
1-4. AI-First Workflow 小結
關於測試流程的設計, 到這裡為止, 主要問題都解決了, 相關資源的供應鏈也設計好了。 想到這邊, 我總算可以說說我對 AI-First (Testing) Workflow 的想法了。 先把 AI 用在 “改善”, 能得到立即的效益當然沒問題, 不過別因此而放棄了新流程的研究, 因為只有這麼做, 當 “舊流程” 已經碰到瓶頸的時候, 你才知道 “新流程” 應該怎麼做。
封裝 Workflow 的過程中, 我意識到有效率的配置 Agent 需要的資源是很重要的, 因此我選擇了 coding agent (目前相對成熟的 agent platform, 各 AI 互相較勁的戰場), 弄清楚當下需要的 context 是什麼, 以及區分清楚你需要什麼 tools 來輔助 agent (MCP)。
這次 AI 變革來的太快, 什麼是正確的 “新流程” 也沒人知道, 如果你先做過嘗試, 時機到了你就會知道如何應變。 我做的 side project 就是在做這件事, 而探索這些新流程該怎麼做, 也是最有趣, 最有成就感的地方。
因此, 前面我都在思考『測試流程應該長什麼樣子』, 接下來的三個章節, 我要開始切換到實作模式了, 搭配 testkit, 並且用安得魯小舖的 API 當作案例, 照這個 workflow, 實際按照步驟跑完整個流程~
2. 用 Decision Table 定義 “有價值的測試”
階段: Generate Test Case from Decision Table (TestKit.GenTest)
整個測試流程, 第一個就是展開 test case - decision table 。 這邊要面對的第一個大魔王, 是測試的 “量體問題”, 而我第一個要解決的題目就是:
”
我怎麼用最少的文件跟步驟, 決定真正有價值的測試是哪些?
“
於是, 經過一番研究, 最簡單實用的就是名為 decision table 的做法, 這是老早就存在的技巧, 跟 AI 沒有直接的關聯, 但是當你能用 decision table 說清楚你要測試的範圍時, AI 很容易就能接手幫你完成後面各種繁瑣的苦工..
這環節就是這麼重要, 你可以讓 AI 幫你整理, 但是你一定要 review 確認, 這表格內容完全會影響到你後面的測試品質。
想了解 decision table 的朋友們, 我推薦 柯仁傑 在今年的鐵人賽寫的這篇, 可以先補充一下相關的基礎知識:
- Day 21 開立範例的方式 - DTT (DTT: Decision Table Testing)
回到原點來看測試:
測試的涵蓋率, 是判定測試成果的重要指標之一, 它表達了所有的條件組合中, 有哪些情境你的測試會踩過驗證。 這時你沒有用有系統的方式把所有組合列出來的話, 其實你很難確認涵蓋率的, 當然你就更難分類及排序, 也難以決定哪些條件組合是重要的。 而除了覆蓋率之外, 其他考量, 像是情境的設計, 風險, 價值等等優先順序的考量都是評估要素。
而 “決策表” (decision table), 是有系統的列出所有組合的方法, 它能用很系統化的方式讓我掌握全貌, 以及將測試分類, 以利我辨識出風險與優先順序等。 我第一個示範,就是用 decision table 來讓 AI 替我建立 decision table, 讓我確認我該怎麼測, 該測哪些組合。
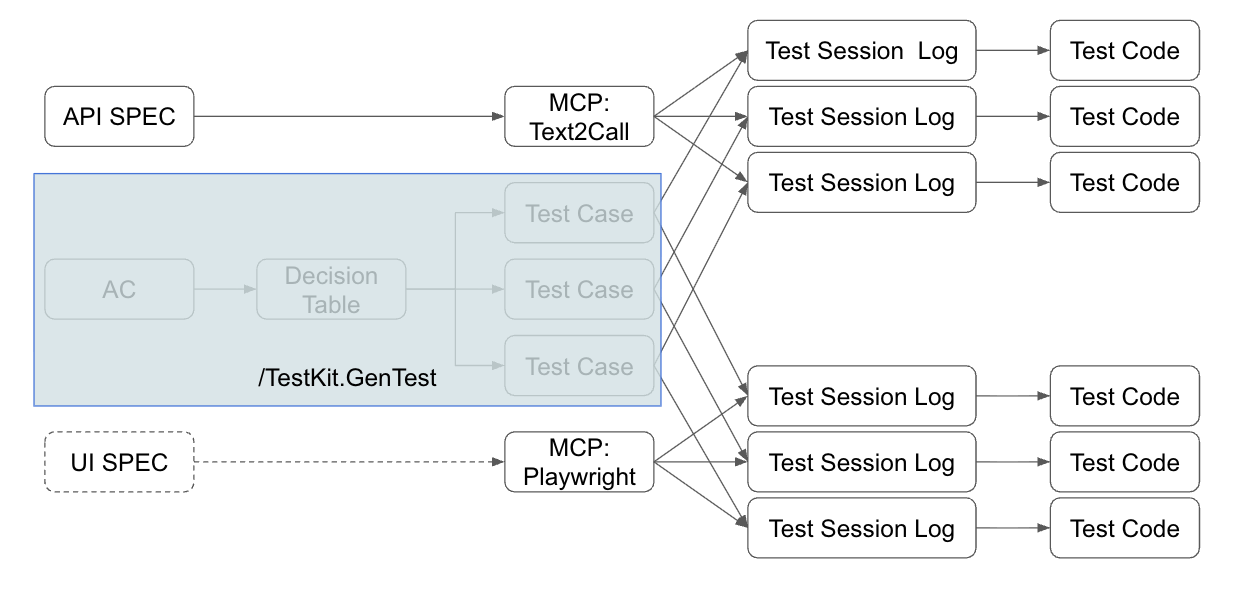
對應到前面提到的流程圖, 那麼這個章節, 我要實作的, 就是藍色框起來的部分, 從 AC 展開決策表, 決定測試範圍, 最後展開成對應的測試案例, 並且直接把預期行為 (action) 的結果也明確列出來, 讓你在一張表格就能看到 criteria / action / rules 的所有排列組合, 框出你想要的測試範圍, 後面再逐步探索 + 自動化。
實際操作下來, 我自己使用的心得是: AI 替你抓的 decision table 格式通常都很工整也符合規範, 但是他建議的 criteria / action / rule 通常都很糟糕, 你需要花一些心思來 review 這張表格的設計, 並且驗證表格展開的 action 是否正確的符合你的領域設計。 這會決定你後面的測試案例的生成是否夠精準, 有沒有確實涵蓋你的系統流程。
不過, decision table 並不是萬能的, 也請各位留意, 它適合用來表達 “條件組合” 的測試, 但是其他目的的測試 (ex: 效能測試, 安全性測試, 壓力測試, 狀態機, 甚至是高併發的狀態異常等等), 就不適合用 decision table 來表達了。 這些測試通常需要其他的設計方式來處理, 這點請各位留意。
2-1. Prepare and Review
用 gentest 這指令, 簡短敘述你的 AC:
/testkit.gentest
購物車結帳時, 必須依據購物車內的商品項目與數量, 配合折扣規則正確計算結帳金額
目前可接受的折扣規則有:
- 指定商品第二件六折
商店系統有這三件商品上架:
1. 啤酒, 第二件六折, 單價 65
2. 可樂, 單價 18
3. 綠茶, 單價 25
系統限制
- 單一訂單內, 每種商品限購 10 個
驗證購物的身分:
- username: andrew
- password: 1234
其實我已經把 AC 簡化到不能再簡化了, 這邊敘述的是我要測試的結帳流程, 要檢驗在各種購買組合下, 結帳金額, 折扣計算, 允許結帳條件都必須正確。 而先預告一下, 結帳限制 (單一訂單內, 每種商品限購 10 個) API 並沒有實作, 因此我預期測到這項時, 測試應該要失敗。
而對應的測試資料, 我預先都先準備好了 (商品已經先上架, 折扣已經先設定好)。
經過上面的輸入, Agent 會給我第一版的 decision table:
| 規則 | C1 有啤酒 |
C2 啤酒≥2 |
C3 有可樂 |
C4 有綠茶 |
C5 數量≤10 |
A1 啤酒折扣 |
A2 可樂計價 |
A3 綠茶計價 |
A4 正確總額 |
A5 拒絕結帳 |
|---|---|---|---|---|---|---|---|---|---|---|
| R1 | Y | Y | N | N | Y | ✔ | – | – | ✔ | – |
| R2 | Y | N | N | N | Y | – | – | – | ✔ | – |
| R3 | N | N | Y | N | Y | – | ✔ | – | ✔ | – |
| R4 | N | N | N | Y | Y | – | – | ✔ | ✔ | – |
| R5 | Y | Y | Y | N | Y | ✔ | ✔ | – | ✔ | – |
| R6 | Y | Y | N | Y | Y | ✔ | – | ✔ | ✔ | – |
| R7 | Y | Y | Y | Y | Y | ✔ | ✔ | ✔ | ✔ | – |
| R8 | Y | N | Y | Y | Y | – | ✔ | ✔ | ✔ | – |
| R9 | Y | Y | N | N | N | – | – | – | – | ✔ |
這是個符合 “規範” 跟 “格式” 的決策表, 但是對我而言並不是個理想的決策表, 因為條件跟結果過度簡化, 我要安排實際的測試案例不是那麼容易對應。 而這決策表的 criteria / action 我覺得設計過度草率 (都只有 Y / N, 我想要更精確的驗證個數不同的狀況)。 因此, 我直接要求 AI 把 decision table 改成我要的樣子:
(對談過程略過, 我直接列出最終的 decision table 版本)
| 規則 | C1 啤酒數量 |
C2 可樂數量 |
C3 綠茶數量 |
A1 啤酒優惠組數 |
A2 總金額 |
A3 總優惠 |
A4 結帳金額 |
A5 允許結帳 |
|---|---|---|---|---|---|---|---|---|
| R1 | 0 | 0 | 0 | 0 | $0 | $0 | $0 | ❌ 拒絕 |
| R2 | 1 | 0 | 0 | 0 | $65 | $0 | $65 | ✅ 允許 |
| R3 | 2 | 0 | 0 | 1 | $130 | -$26 | $104 | ✅ 允許 |
| R4 | 3 | 0 | 0 | 1 | $195 | -$26 | $169 | ✅ 允許 |
| R5 | 4 | 0 | 0 | 2 | $260 | -$52 | $208 | ✅ 允許 |
| R6 | 10 | 0 | 0 | 5 | $650 | -$130 | $520 | ✅ 允許 |
| R7 | 11 | 0 | 0 | 5 | $715 | -$130 | $585 | ❌ 拒絕 |
| R8 | 12 | 0 | 0 | 6 | $780 | -$156 | $624 | ❌ 拒絕 |
| R9 | 0 | 5 | 0 | 0 | $90 | $0 | $90 | ✅ 允許 |
| R10 | 0 | 0 | 4 | 0 | $100 | $0 | $100 | ✅ 允許 |
| R11 | 2 | 3 | 0 | 1 | $184 | -$26 | $158 | ✅ 允許 |
| R12 | 3 | 2 | 4 | 1 | $331 | -$26 | $305 | ✅ 允許 |
| R13 | 0 | 11 | 0 | 0 | $198 | $0 | $198 | ❌ 拒絕 |
| R14 | 5 | 5 | 11 | 2 | $690 | -$52 | $638 | ❌ 拒絕 |
條件定義 (Conditions) 直接換成放進購物車的每種商品個數:
- C1: 購買啤酒的數量 (單價 $65, 每 2 件中第 2 件 $39)
- C2: 購買可樂的數量 (單價 $18)
- C3: 購買綠茶的數量 (單價 $25)
動作定義 (Actions)
- A1: 啤酒優惠組數
- 計算公式:
floor(啤酒數量 / 2) - 例: 3 件 → 1 組, 4 件 → 2 組, 10 件 → 5 組
- 計算公式:
- A2: 總金額 (未折扣)
- 計算公式:
啤酒數量 × 65 + 可樂數量 × 18 + 綠茶數量 × 25
- 計算公式:
- A3: 總優惠 (負數)
- 計算公式:
啤酒優惠組數 × -26 - 說明: 每組優惠省 $26 (原價 $65 - 六折 $39)
- 計算公式:
- A4: 結帳金額
- 計算公式:
總金額 + 總優惠
- 計算公式:
- A5: 是否允許結帳判定
- ✅ 允許: 所有商品數量 ≤ 10 且購物車不為空
- ❌ 拒絕: 任一商品數量 > 10 或購物車為空
展開的規則說明 (附上測試企圖, 與按照重要性分類)
基本購物車操作測試
- R1: 空購物車
- 測試企圖: 驗證系統能正確拒絕空購物車結帳
- 重要性: 防止產生無效訂單, 確保業務邏輯完整性
- R2: 單件啤酒無優惠
- 測試企圖: 驗證未達優惠門檻時, 系統按原價計算
- 重要性: 確認優惠規則不會誤觸發, 保護商家利益
- R3: 2 件啤酒觸發優惠 (1組)
- 測試企圖: 驗證剛好達到優惠門檻時, 系統正確計算 1 組優惠
- 重要性: 這是優惠規則的最小觸發邊界, 必須精準計算以建立客戶信任
- R4: 3 件啤酒 (1組優惠 + 1件原價)
- 測試企圖: 驗證奇數件數時, 優惠組數計算正確 (只有 1 組, 第 3 件原價)
- 重要性: 確認系統能正確處理不完整組合, 避免多給或少給優惠
- R5: 4 件啤酒 (2組優惠)
- 測試企圖: 驗證多組優惠時, 系統能正確累加計算
- 重要性: 確認優惠規則能正確累加, 測試整數組合的計算邏輯
- R6: 10 件啤酒 (5組優惠, 上限邊界)
- 測試企圖: 驗證達到系統限制上限時, 優惠計算與允許結帳邏輯都正確
- 重要性: 測試最大合法邊界, 確認 5 組優惠計算無誤, 且系統不會錯誤拒絕合法訂單
啤酒超限測試
- R7: 啤酒超過 10 件 (11件, 5組優惠)
- 測試企圖: 驗證系統能正確拒絕超過單項限購數量的訂單, 但仍能正確計算優惠組數 (供錯誤訊息使用)
- 重要性: 測試最小違規邊界 (10+1), 確保限購機制有效, 且錯誤處理時金額計算邏輯不崩潰
- R8: 啤酒超過 10 件 (12件, 6組優惠)
- 測試企圖: 驗證更大的違規數量 (10+2) 也能被拒絕, 且能正確計算 6 組優惠
- 重要性: 確認限購機制不是硬編碼單一數值, 而是真正的邏輯判斷 (>10 皆拒絕)
非優惠商品測試
- R9: 僅購買可樂 (無優惠商品)
- 測試企圖: 驗證非優惠商品的正常計價流程
- 重要性: 確保優惠邏輯不會影響非優惠商品, 系統能正確區分商品類別
- R10: 僅購買綠茶 (無優惠商品)
- 測試企圖: 驗證另一個非優惠商品的計價邏輯
- 重要性: 與 R9 互補, 確保所有非優惠商品都能正確處理
混合商品測試
- R11: 混合商品 (含 1 組優惠)
- 測試企圖: 驗證優惠商品與非優惠商品混合購買時, 系統能正確分別計算
- 重要性: 這是真實購物場景, 必須確保優惠只套用在啤酒, 其他商品不受影響
- R12: 三種商品混合 (含 1 組優惠)
- 測試企圖: 驗證最複雜的購物組合, 所有商品類型都存在且啤酒為奇數件時的計算正確性
- 重要性: 測試系統在最複雜情境下的穩定性, 確保優惠計算邏輯不會互相干擾
其他商品超限測試
- R13: 可樂超過 10 件 (11件, 無優惠)
- 測試企圖: 驗證限購規則適用於所有商品, 不只優惠商品
- 重要性: 確認限購是全商品通用規則, 避免規則漏洞
- R14: 混合商品但綠茶超限 (11件, 含 2 組啤酒優惠)
- 測試企圖: 驗證混合購物時, 系統能正確檢查每項商品的限購規則, 即使其他商品合法
- 重要性: 確保限購檢查不會因為多商品混合而失效, 保護庫存管理
在調整 decision table 內容的過程中, 除了調整我想要的結構之外, 也抓出一些 AI 對商業規則的 “誤解” 以及計算錯誤。 例如 AI 曾經就誤會所謂第二件六折, 是指同商品的第二件以後都六折 (ex: 買三件, 第二第三件六折, 而原意應該是兩件一組, 每組的第二件六折才對), 另外也碰到規則都理解正確, 但是數字卻計算錯誤的狀況, 這些都是需要核對的地方 (ex: R14 就是我修正過的結果, 原本 AI 在 decision table 替我計算的數字是 $740, 不是 $690, 是我在 review 的過程中挑出來的)。
當最終的 decision table 內容定案後, 就可以繼續下個步驟, 逐一產生每個 rule 對應的 test cases …
2-2. Generate All Test Cases
確認完 decision table 之後, 剩下的只剩文書作業了, 基本上格式我在 testkit 都定義好了, 測試範圍也在 decision table 都決定好了, 這步驟就是把所有的 test case 寫出來而已。
按照前面 decision table 的內容, 總共有 14 個 test case 需要展開, 我直接貼 AI 產完給我的摘要:
📁 目錄結構
/tests/shopping-cart-checkout/
├── decision-table.md (決策表文件)
├── tc-01-空購物車.md
├── tc-02-單件啤酒無優惠.md
├── tc-03-2件啤酒觸發優惠.md
├── tc-04-3件啤酒1組優惠.md
├── tc-05-4件啤酒2組優惠.md
├── tc-06-10件啤酒5組優惠-上限邊界.md
├── tc-07-11件啤酒超限拒絕.md
├── tc-08-12件啤酒超限拒絕.md
├── tc-09-僅購買可樂.md
├── tc-10-僅購買綠茶.md
├── tc-11-啤酒加可樂混合.md
├── tc-12-三種商品全混合.md
├── tc-13-可樂超限拒絕.md
└── tc-14-混合但綠茶超限.md
📊 測試覆蓋率分析
- 條件數: 3 (啤酒、可樂、綠茶數量)
- 動作數: 5 (優惠組數、總金額、總優惠、結帳金額、允許判定)
- 規則數: 14
- 測試案例: 14
🎯 測試類型分類
- 正常結帳流程 (R1-R6): 空購物車、啤酒 1-10 件
- 啤酒超限測試 (R7-R8): 11-12 件
- 非優惠商品 (R9-R10): 可樂、綠茶
- 混合購物 (R11-R12): 多商品組合
- 其他商品超限 (R13-R14): 可樂、綠茶超限
🎁 每個測試案例包含
- ✅ Given-When-Then 格式
- ✅ 明確的測試資料 (輸入/輸出)
- ✅ 詳細的金額計算明細
- ✅ 業務規則驗證點
- ✅ API 呼叫序列建議
- ✅ 測試重要性說明
實際上的 test case 我也貼一下, 其實也寫的很不錯, 我的要求都有做到。 總共有 14 份, 我貼一份當作代表就好, 我貼 R2:
(為了不影響文章結構, 我移除了 markdown 的章節資訊)
TC-02 單件啤酒無優惠
測試目標 驗證未達優惠門檻時, 系統按原價計算, 確認優惠規則不會誤觸發。
前置條件 (Given)
- 使用者已登入 (username:
andrew, password:1234) - 購物車內商品:
- 啤酒: 1 件 (單價 $65)
- 可樂: 0 件
- 綠茶: 0 件
測試步驟 (When)
- 使用者將 1 件啤酒加入購物車
- 使用者進行購物車結帳
- 系統計算結帳金額
預期結果 (Then)
- ✅ 系統允許結帳
- ✅ 啤酒按原價計算 (無優惠)
- ✅ 總金額: $65
- ✅ 總優惠: $0
- ✅ 結帳金額: $65
- ✅ 訂單成立
測試資料
輸入參數
- 啤酒數量: 1
- 可樂數量: 0
- 綠茶數量: 0
預期輸出
- 允許結帳: ✅ 允許
- 啤酒優惠組數: 0 (未達 2 件門檻)
- 總金額 (未折扣): $65
- 總優惠: $0
- 結帳金額: $65
金額計算明細
啤酒: 1 件 × $65 = $65
可樂: 0 件 × $18 = $0
綠茶: 0 件 × $25 = $0
----------------------------------------
總金額 (未折扣): $65
啤酒優惠組數: floor(1/2) = 0
總優惠: 0 × -$26 = $0
----------------------------------------
結帳金額: $65 + $0 = $65
業務規則驗證
- ✅ 單件啤酒不觸發優惠 (需 2 件才享第二件六折)
- ✅ 優惠門檻控制正確
API 呼叫序列
add_to_cart- 加入 1 件啤酒get_cart- 取得購物車內容calculate_total- 計算結帳金額checkout- 執行結帳
測試重要性 確認優惠規則不會誤觸發, 保護商家利益。 這是優惠計算的基準線測試。
3. 讓 AI 探索並記錄 API 的執行步驟
階段: Explore Test Steps with AI Agent (TestKit.API.Run)
這步驟算是整個流程最核心的地方, 依賴 AI 的理解與推理能力, 找出正確使用 API 來執行 test case 的環節。 對應到流程圖, 就是藍色框起來的部分。 開始之前先來複習一下, 流程跑到這裡, 我手上有哪些測試相關的資訊 (context):
- test case (要測試的業務情境, 上一步產生)
- api spec (api 的操作規格, 使用者提供)
- text-to-calls mcp (來自上一篇文章 vibe testing 的實驗, 封裝成 mcp)
理論上有了 (1) + (2), 就有足夠資訊推導出 api 該怎麼呼叫了, 而 (3) 就是讓 AI agent 能真正自動化執行它的工具 (這是給 agent 的工具, 不是給我)
現在萬事具備了, 我就開始啟動它。 一次跑完太花時間了, 既然我前面都讓 AI 幫我標記重要性了, 我就挑選第一組: 正常結帳流程 (R1-R6) 來示範。
3-1. 讓 MCP 負責處理 API call
MCP 的處理, 是這個步驟重要的環節, 我多花點篇幅介紹過程發生了什麼事。 AI 負責 “探索”, 靠的就是 agent + mcp 的組合, 不斷的修正, 從規格與測試案例中找出最理想的執行步驟, 並且存成 session logs 作為後續產 code 的執行步驟指引。
這段是整個 side project 我花最多時間的地方, 光是為了讓 agent 能有效的處理 API 就嘗試了好幾種方法。 這段我想還原一下處理過程中碰到的問題, 會多帶一些 MCP 的設計考量, 如果沒有開發這個 MCP, 我覺得這個 workflow 應該沒機會實現吧, 沒有妥善的替 agent 隔離 context 的雜訊 (處理 api 呼叫的過程實在太多干擾資訊了) 的話, agent 根本無法完成複雜的 API + Test Case 探索任務。
–
首先, 我在 copilot chat 視窗下了這道指令, 調用 testkit.api.run :
/testkit.api.run
執行: 正常結帳流程 (R1-R6)
整個程序就開始啟動了, 我在 MCP 封裝了 4 個 tools, 分別是:
- QuickStart (MCP 使用說明)
- ListOperations (解析待測 API 提供哪些 operation 可以使用, 摘要資訊)
- CreateSession (建立 session, 執行的記錄資訊都會收錄到目前的 session 中)
- RunStep (在當前的 session 中執行指定的 API operation)
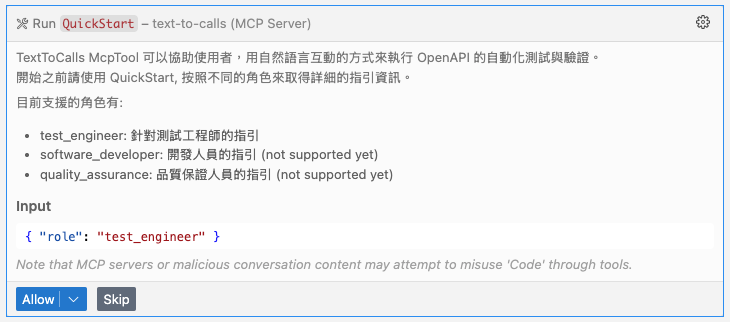
Agent 第一次使用, 就按照 tools description 的指示, 先呼叫 QuickStart. 其實這做法是從 Shopify 學來的 (參照我 facebook post), 我用 tools 的方式傳回明確 (而且可以是動態的提示) 的使用說明給 Agent, 最大化的正確引導 agent 來用我的 MCP:
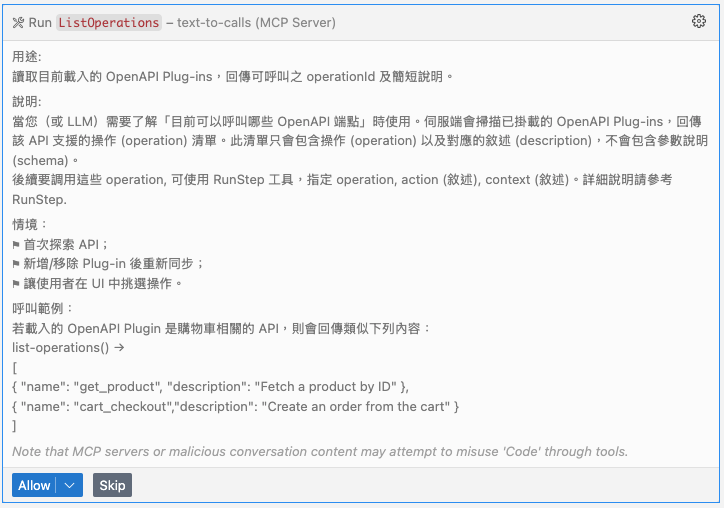
接下來, agent 果然按照 QuickStart 的指示, 用 ListOperations 查詢 API 可用的操作有哪些:
我曾經實作過一個版本, 直接將 API 的 swagger 所有規格都直接提交出去, 其實就是去年在 MyGPTs 上實作 “安德魯小舖” 的做法, 省掉了包一層 MCP 的功夫。 市面上有現成的 swagger -> mcp 套件可以用, 我其實不必要自己寫。 不過實驗之後, 我放棄這條路了, 改用現在的做法, 因為:
- api spec 包含太多不必曝露給 agent 的細節
- api spec / request / response 資訊過多, 呼叫一兩次就把 agent 的 context window 塞爆了
- api 包含太多不適合給 agent 處理的動作 (尤其是機械式的操作, 例如 oauth2)
因此, 我想清楚我自己包一層 MCP 的動機了, 就是要將 “呼叫 API” 這件事抽象化, 讓主要的 agent (github copilot) 能夠專注在主要任務 - 執行 test case 上, 排除一切干擾。
這樣做的原因, 有興趣繼續探究的, 可以看我的這則 facebook post, 這篇 研究報告 很仔細的說明了 context 內的雜訊, 對 agent 的能力影響有多大。 若我不做分層管理, 讓過多的 api 規格細節出現在 context window 內, 這就是 “雜訊”, 會嚴重影響 test case 主要任務的進行, 這是 context management 的大忌。 因此我藉由 MCP 的實作, 簡化了 agent 操作 API 的難度, 只要指定 operation 跟 action 敘述即可, 剩下的細節由 MCP 內部的另一個 LLM 來分層處理。
所以我的抽象化切角就是:
- ListOperations, 用文字敘述 (只有 api-name 是明確 id) 告訴 agent 有哪些 api 可以用
- CreateSession, 明確告訴 agent, 建立 session 來收納一個 test case 的執行過程記錄
- RunStep, 接受 agent 的指示, 在當前的 session 內要執行指定的 operation, 並且用文字敘述告知 mcp 操作的內容 ( mcp 內部還有另一個 LLM, 會真正負責解析 text -> api call 的參數對應跟生成)
Agent 透過 list operations, 並且對照 TC-01 test case, 挑出這步驟可用的操作有這四個:
- GetCart - 取得購物車內容
- CreateCart - 建立新購物車
- EstimatePrice - 試算結帳金額
- CreateCheckout - 建立結帳交易
用這四個操作就足以組合出 test case 01 的情境了, 接下來 agent 真正要開始執行, 於是就先執行 CreateSession:
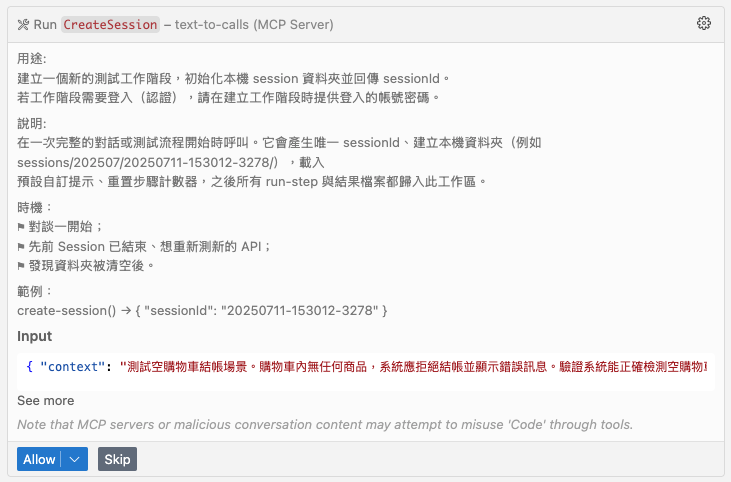
建立完 session, 包含認證 (測試用的帳號密碼) 資訊, MCP 除了建立 session 之外, 也會先完成 OAuth2 認證流程, 並取得 access token 供後續操作 operations 使用.. 這些操作如果不是在 MCP 內用 code 處理, 我不知道還要寫多少 prompt 才教的會 AI 來做這些事… (而且還會有一定機率不受控制)
到這邊終於可以開始執行 RunStep, 呼叫 API:

我特別貼一下 agent 傳給 RunStep 的資訊, 都被抽象化了, 只剩下 operation, action, context:
{
"operation": "CreateCart",
"action": "create an empty cart",
"context": "User andrew logged in. Create a new empty cart to test checkout with no items. This should later fail at checkout."
}
如果把 MCP 當作 sub-agent (他也有 LLM 文字處理能力), 其實這就是個簡化的 A2A protocol 了, Agent 交代 MCP 要 Run 哪個 API (operation), 描述想要他完成的任務 (action) 是什麼, 完成這任務的背景資訊摘要 (context), 其餘就是 MCP 按照這些資訊, 用內置的 LLM (這邊我用 OpenAI GPT-5-mini) 觸發 function calling 機制來完成 api call 的任務
RunStep 這操作, 執行過程中可能會呼叫 1 ~ N 次不同的 api, 我在 MCP 的實作中, 所有透過 HttpClient 呼叫的 API, 這些過程都會在 _session 目錄下留下足跡。 舉例來說 RunStep -> CreateCart, 就真正對應到 POST /api/carts/create, 具體的 api call request / response 都有被記錄下來:
而抽象化的執行順序, 也會被記錄在 session-logs.md 下 (我節錄 RunStep[1] 的片段, 這些都是 MCP 自己留下的記錄):
RunStep[1], CreateCart
action: create an empty cart
context: User andrew logged in. Create a new empty cart to test checkout with no items. This should later fail at checkout.
result:
answer:
已成功建立一個空購物車(id=163)。 執行成功且結果如預期:回傳的購物車內容為空(prodQtyMap 與 lineItems 均為空), 可用於後續驗證「空購物車結帳應被拒絕」的測試。
details:
依據執行結果, API 回應內容如下(已轉成可讀敘述):
- 請求:POST https://shop.chicken-house.net:443/api/carts/create
- 回應 Content-Type: application/json; charset=utf-8
- 回應 JSON 內容:{ “id”: 163, “prodQtyMap”: {}, “lineItems”: [] } 敘述說明:系統已建立一個新的購物車, 購物車編號為 163;目前購物車內沒有任何商品(prodQtyMap 空物件, lineItems 為空陣列), 符合「建立空購物車」的需求與測試前置條件。 無 HTTP 錯誤或例外回傳, 操作順利完成。
instructions:
下一步建議:
1) 嘗試呼叫 CreateCheckout(payload: { cartId: 163 })以確認系統在建立結帳交易階段是否拒絕空購物車。 期望行為:API 應回傳錯誤(或拒絕建立交易), 並說明原因(例如:「購物車為空, 無法結帳」)。
2) 若 CreateCheckout 被接受(意外情況), 請接著模擬付款並呼叫 CompleteCheckout, 檢查是否會在完成結帳時被阻擋;若 API 回傳成功建立訂單, 視為系統行為不符合預期, 需進一步調查。
3) 測試檢查要點:確認 API 回傳的錯誤碼與錯誤訊息, 並在測試結果中斷言系統應拒絕空購物車結帳以防無效訂單產生。
4) 若需要, 我可以代為執行 CreateCheckout 並回報其實際回應內容以完成此測試情境驗證。
summary:
前次 context:使用者 andrew 已登入, 目的是測試空購物車結帳場景(購物車內無任何商品, 系統應拒絕結帳並顯示錯誤訊息)。
此次 action:CreateCart — 建立一個新的空購物車。
此次 answer:建立成功, 系統回傳購物車 id=163, prodQtyMap 與 lineItems 均為空, 符合建立空購物車的預期。 後續請嘗試呼叫 CreateCheckout (cartId=163) 以驗證系統是否正確阻止空購物車結帳;我可以協助執行並回報結果。
3-2. Session Logs
前面的 “探索” 完成後, 接下來要看看 session logs 留下了哪些線索給下一步使用。 這步驟關鍵的地方在於, 探索的結果不一定每次都是理想的, 你可能會挖到寶藏, 也可能會撲空什麼都沒找到。 因此我希望 “真人” 能夠透過 session logs 的 review 來確認 AI 探索的結果是否符合期待, 不管是修正 prompts, 或是微調 test case, 直到得到你預期的結果為止。
先來看測試案例 TC-01, 這測試案例講的是, API 應該要拒絕空的購物車結帳請求才對, 不過實際上我的 API 並沒有實作這限制, 所以我預期這個測試應該會成功的失敗才對 (咦?)
測試的 test case 主要部分如下:
前置條件 (Given)
- 使用者已登入 (username:
andrew, password:1234) - 購物車為空
- 購物車內商品數量:
- 啤酒: 0 件
- 可樂: 0 件
- 綠茶: 0 件
測試步驟 (When)
- 使用者嘗試進行購物車結帳
- 系統檢查購物車內容
預期結果 (Then)
- ❌ 系統拒絕結帳
- ✅ 顯示錯誤訊息: “購物車為空, 無法結帳”
- ✅ 不產生訂單
- ✅ 購物車狀態維持為空
實際執行的步驟, 到 Step3 之前都還正確 (建立購物車, 計算購物車金額-空車):
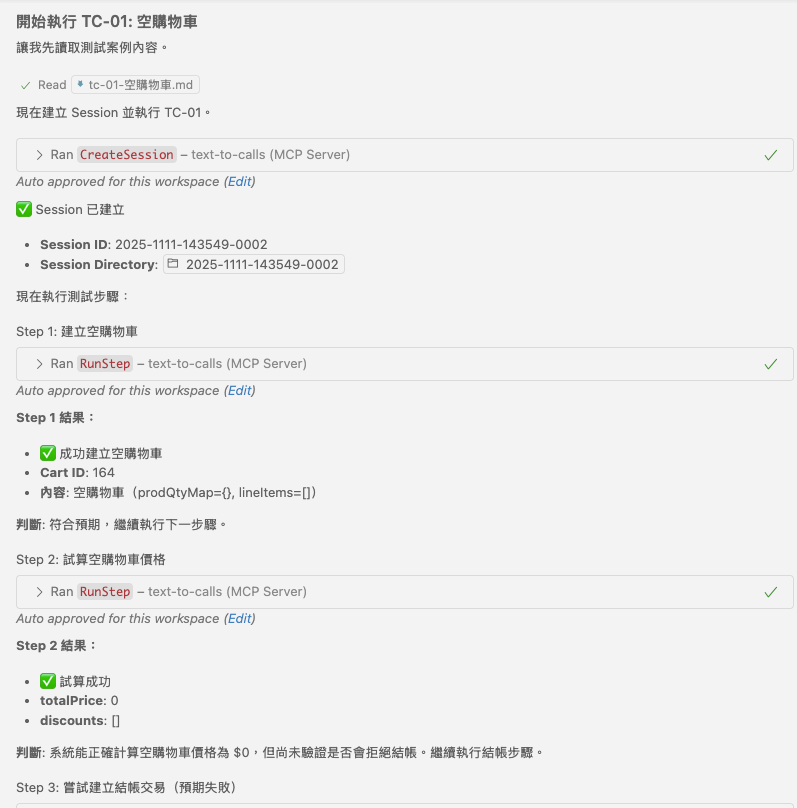
然而, 到了真正要執行結帳的時候, API 呼叫就不如預期了, API 沒有阻止空的購物車進行結帳:
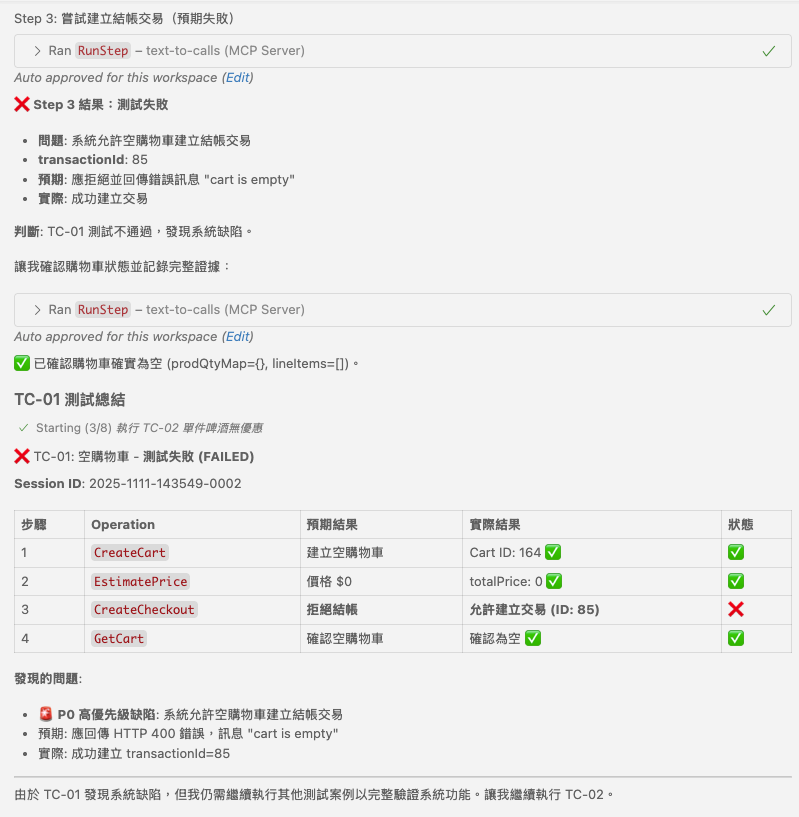
看到這邊, 可以放心了, agent + MCP 有認真替你執行 test case 的每個步驟, 也有確實檢驗結果是否符合預期。
3-3. Test Suite Result
看完一筆 test case 執行過程, 其他剩下的 test case 我就跳過了, 直接看最後結果 (我只 RUN 了基本測試, TC-01 ~ TC-06):
我有實作基本功能, 但是基本上邊界的檢驗都沒做, 所以基本測試 TC-01 空購物車結帳測試預期會失敗, 其他正常結帳跟折扣計算應該都會通過 (TC-02 ~ TC-06), 如果後面還有執行超過 10 件商品的測試應該也會失敗 (應該要拒絕結帳, 但是實際會結帳成功), 這些都驗證測試有發揮效用。 我擷圖讓各位看一下 AI 給我的摘要報告:
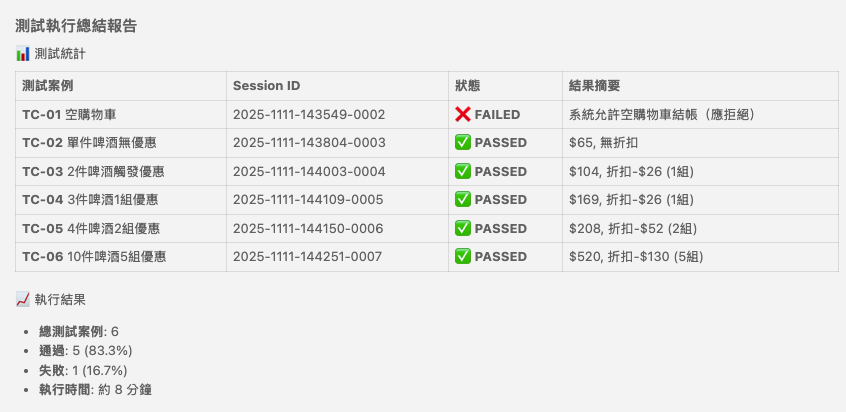
針對測試失敗的部分 (TC-01), AI 也特別說明他判定問題出在哪邊:

而這些執行過程的記錄, 通通都鉅細靡遺的保存在 session folder 內:
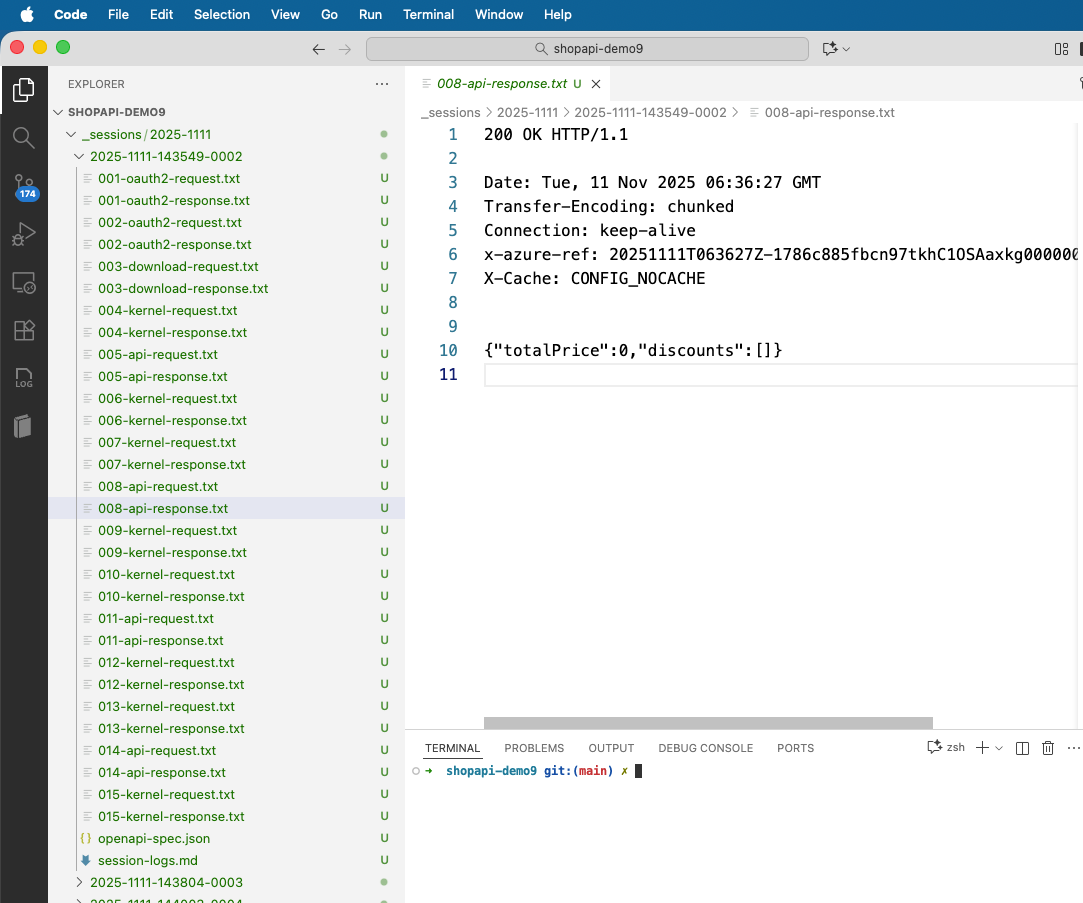
001, 002 -> OAuth 認證過程 003 -> 下載保存 openapi spec 004 -> MCP 呼叫 LLM 處理 function calling 005 -> call api: create cart … (懶的寫了, 總之當成 postman 來看待就好)
openapi-spec.json, 就是 003 保存下來的 API spec 快照 session-logs.md, 就是呼叫過程中的抽象資訊傳輸記錄, agent / MCP 的通訊內容都在這邊, 基本上這是給 “人” 看的歷程…
而我會設計 mcp 要保留這些資訊, 目的很單純, 這些都是將來要寫 “API 自動化測試” 最重要的規格, 以後這些都會是餵給 SpecKit 執行的養分。
3-4. AI 探索測試步驟 - 小結
這階段的重點, 就是最大化的靠 AI 輔助, 來完成 “探索 API 呼叫步驟” 的任務。
所謂的 “探索”, 是讓 AI 不斷的嘗試, 直到找出理想的測試步驟的過程。 因為所謂的 “過程” 不會有標準答案, 如果你想在 “靜態” 的分析下就把步驟找出來, 我覺得不是不可能, 但是成功率會低, 而你會在後面階段才能驗證對不對 (或是好不好), 提前讓 AI 在前面階段就先進行 “探索”, 其實可以大幅降低走錯路的機會, 我覺得很值得嘗試, 而不是表面上看來好像多了一個步驟浪費時間一樣。
因此, 也特別留意, “探索” 其實是測試步驟測試的一環, 而不是回歸測試的一環, 它並不是讓你在 CI/CD 階段要執行的任務, 藉由探索後生成的自動化測試程式才是。
這是我花時間介紹這個段落的用意, 看懂它的價值後, 再繼續往下看, 你就能理解為何我要拆成這兩個步驟的原因了。
4. 共用 Test Case, 同時探索 API / Web
階段: Explore Test Steps with AI Agent (TestKit.WEB.Run)
在討論流程的瓶頸時, 有提到我希望最大化 test case 的使用範圍, 一個 test case 能夠同時應用於多種操作介面, 在這案例中, 就是我希望 API / WEB UI 兩種測試, 都能共用同樣的 test case。
我的服務同時提供 WEB UI / API 兩種使用方式, 對象跟使用場合不同, 但是處理的商業情境是一樣的 (就是購物啊), 這一段我會示範用同樣的 test case, 搭配 Playwright MCP, 嘗試完成同樣的測試行為:
拜 coding agent 所賜, 這次我特地準備了一個有 Web UI 的 “安得魯小舖”。 我是前端大外行, 終於也能生出還過的去的純前端測試網站了 XDD, 這是 React + NodeJS 的前後端架構, 背後 call 同樣的 API 搭建的 web app, 有興趣的人可以進去玩玩看:
Andrew Shop: https://shop.chicken-house.net
這次, 同樣來看看我準備了什麼資訊:
- test case (要測什麼的業務情境, 同 api)
- ui spec (web ui 遵循無障礙的設計, playwright mcp 會參考它, 後面說明)
- playwright mcp
mcp 的安裝設定我就不講了, 大家自己看 playwright mcp 的官網, 我開啟 copilot chat 輸入這段指令:
/testkit.web.run
執行: 正常結帳流程 (R1-R6)
這段我沒有另外再寫 MCP 來支持這些操作, 例如 session, logs 等等, 因此這部份就簡單處理 (我直接寫在 prompt 而已), 所以 agent 一樣會幫我建立 session folder, 只是是靠 shell, 相對的資訊就沒有 API 那麼完整, 就是留下操作的文字記錄而已 ..
草草的準備好測試環境之後 (咦?) , 正式的測試就要開始了, 第一次呼叫 playwright mcp, 就是啟動首頁:
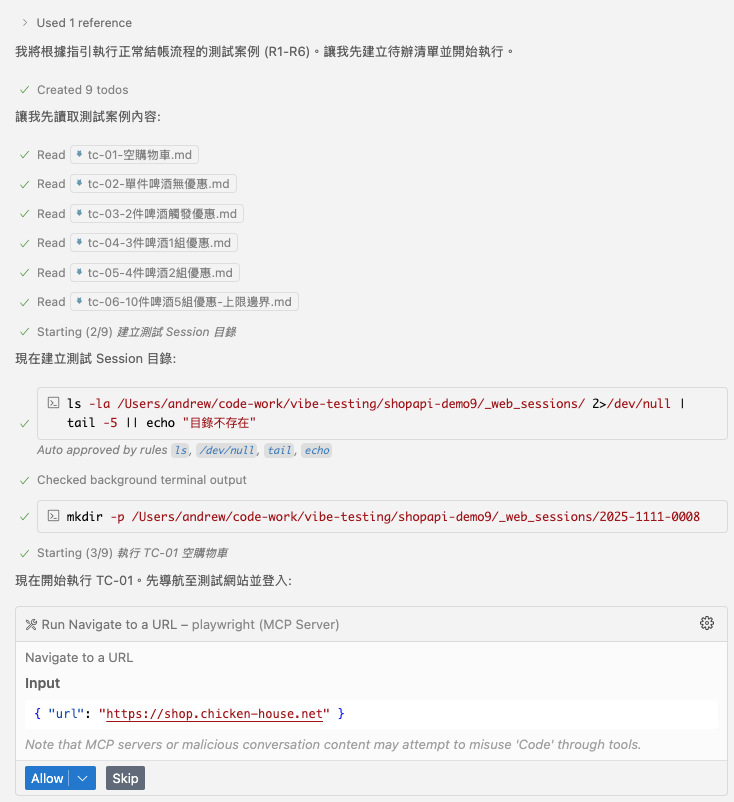
經過一連串的嘗試 (略過), 完成 OAuth2 認證, 登入成功:
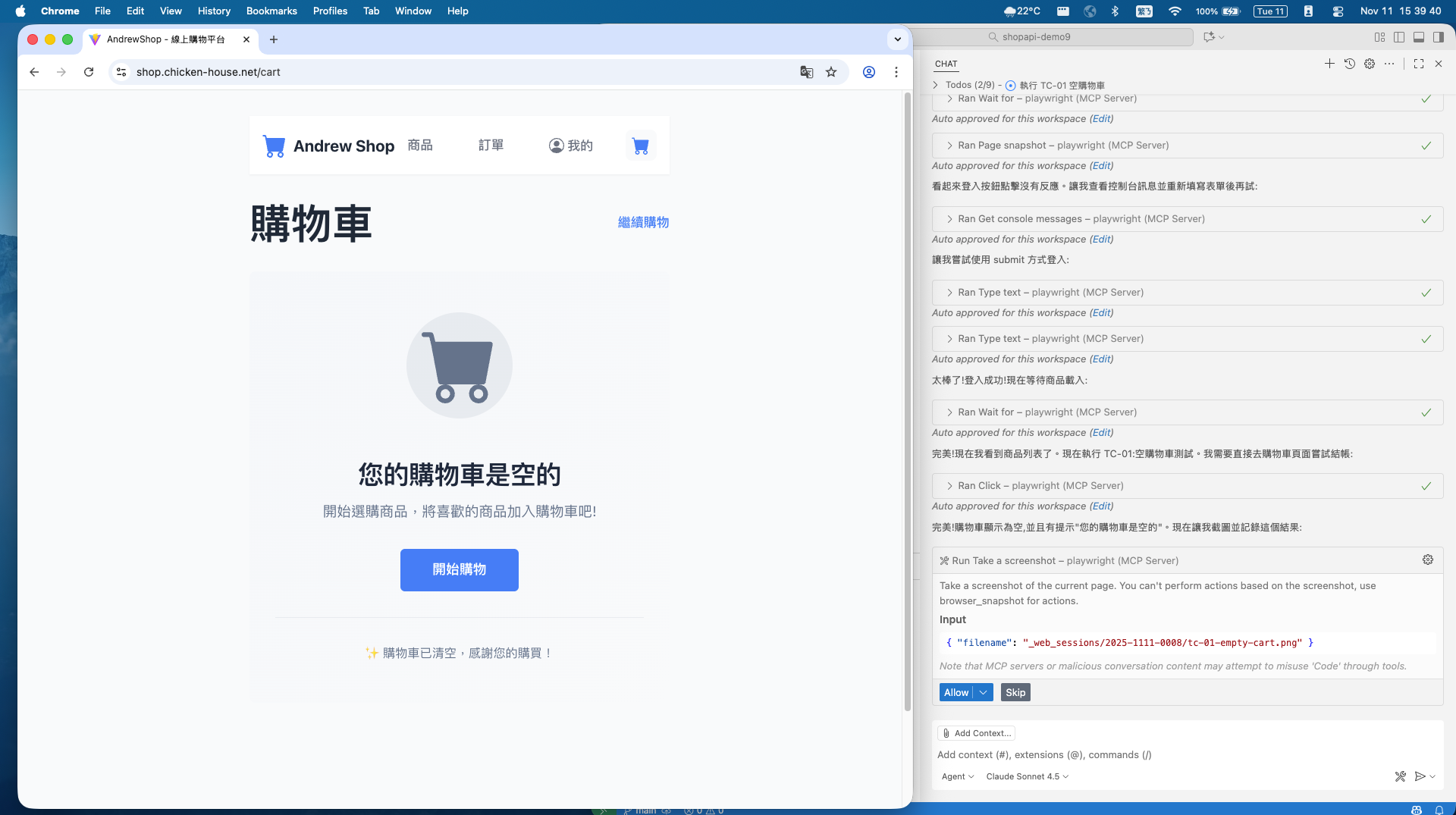
接下來你可以看到 agent 不斷的在跑, 而 chrome 也自己在操作, 等了幾分鐘之後, 開始測試結帳:
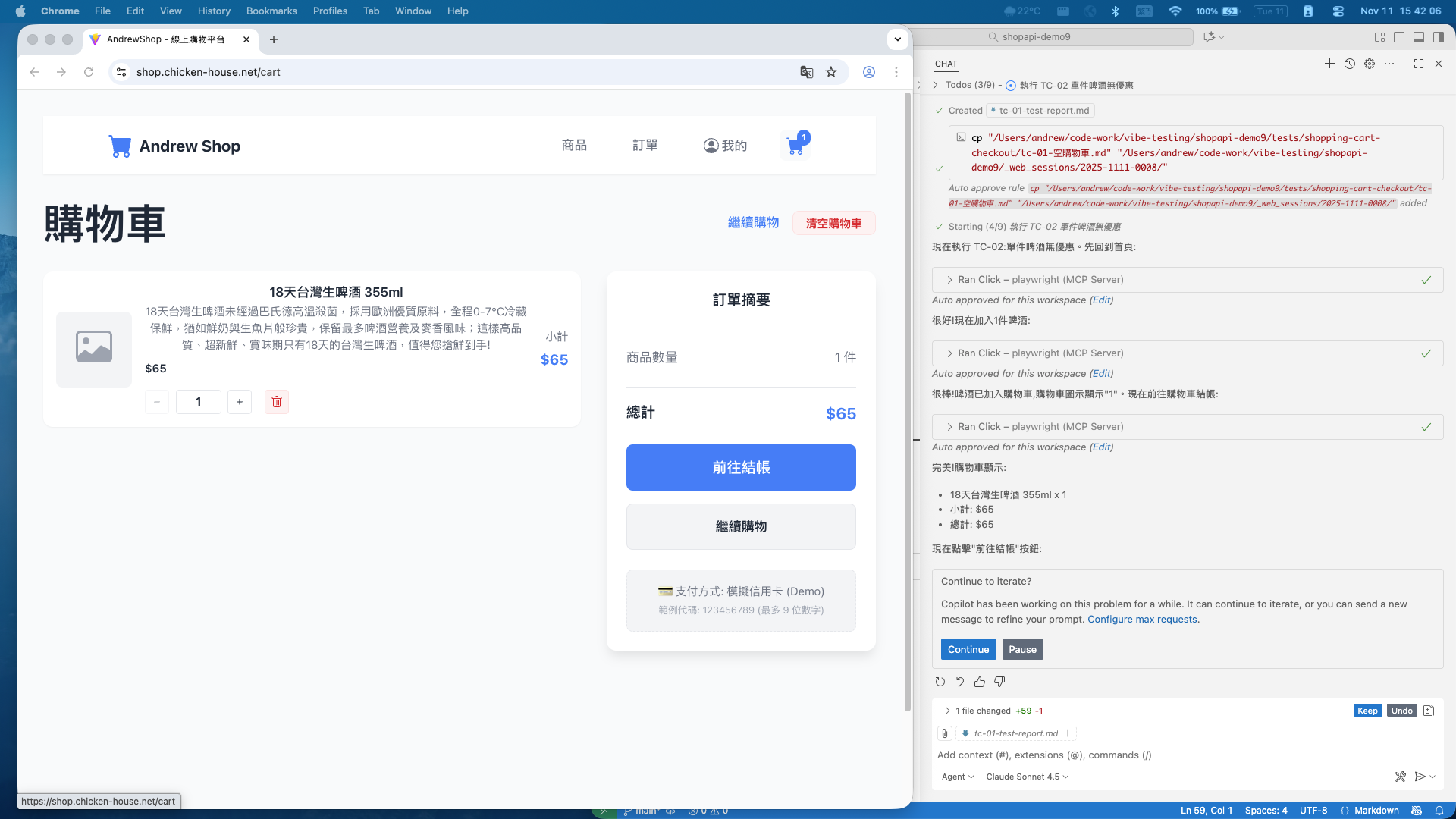
看起來操作都很順利, 操作的過程都沒有脫離 test case 的敘述, 跑了大約 20 min (真的很慢), 六個測試項目執行完畢。
而測試結果跟 API 比較不一樣的是: 這次六個測試都成功通過!

會有這差異, 是我在 WEB UI 有加上 API 沒有做的檢查: 購物車是空的不能結帳。 做法不是結帳提示錯誤訊息, 而是購物車沒東西的時候就拿掉結帳的按鈕。 因此這 test case 在 WEB UI 的測試是通過的, 我擷圖證實一下:
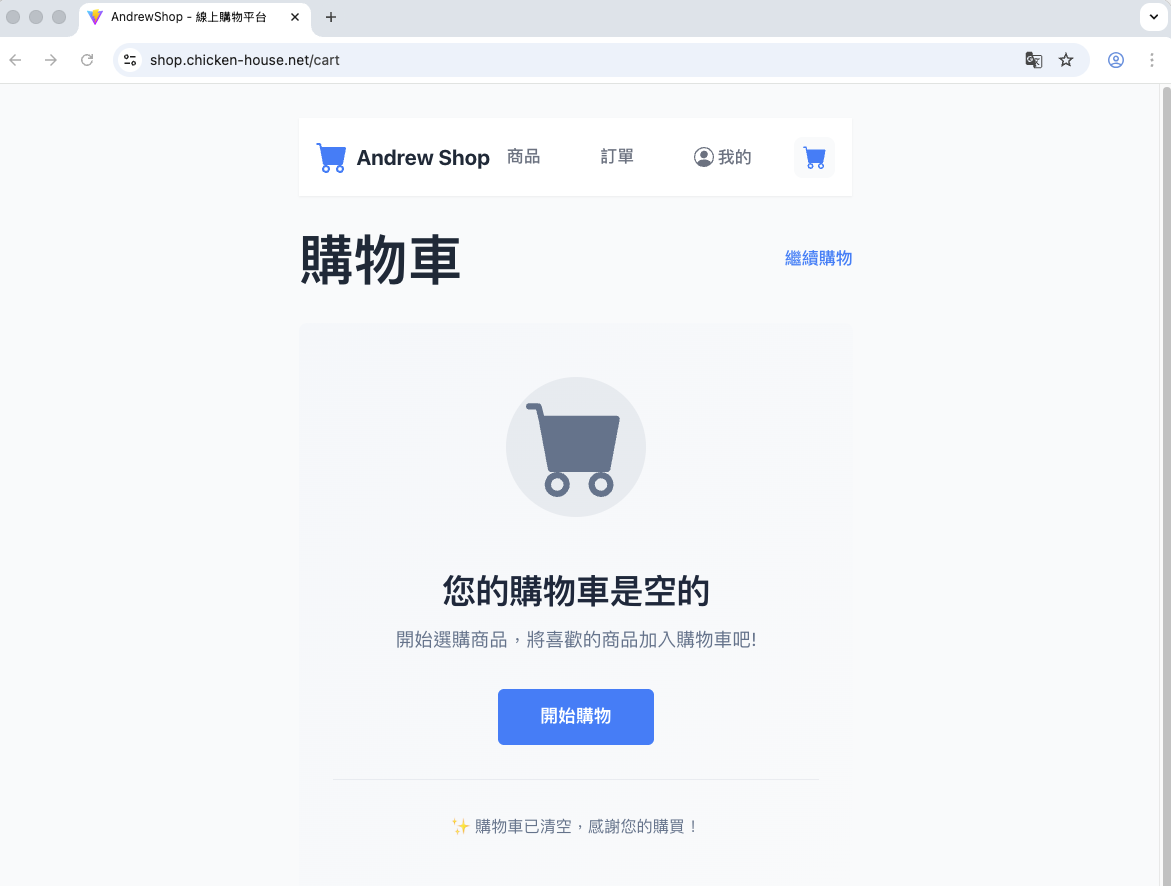
4-1. 無障礙設計的重要性
同樣的, 這題也是過去我卡很久的題目…
跟前面 API 呼叫沒處理好 context, 測試過程一直很不順利的問題, 在 WEB 這邊其實也卡關很久. 我碰到的狀況是, Playwright 很 “笨”, 按鈕明明就在眼前, 就是找不到, 看不到, 按不到, 一個簡單的步驟就看 AI 在那邊嘗試半天, 就是無法進到下一步…
其實這就是 AI 沒有掌握 WEB UI 的 “規格” 啊, 人看的到, 是因為最終是從 “視覺” + “人腦” 來判定的, 但是 AI 不是。 AI 其實有對應的 solution, 的確是擷取畫面, 然後進行影像辨識來判定, 最後操作滑鼠在特定座標點擊, 不過運算資源花太兇了, 現在的運算能力還沒辦法做到很流暢的操作 (一張 4K 的圖, 要判定按鈕在哪, 該不該按下去, 就要幾十秒鐘了)
我試過其他的套件, 例如 selenium mcp, 它的辨識能力就 “好的多”, 因為他直接解讀完整的 HTML, 基本上頁面所有細節都能檢測的到, 不過 HTML 太肥了, 動不動就 100kb 以上, 很快的 agent 的 context windows 就被佔滿了, 根本無法實際使用
playwright mcp 實用的多, 因為他會先將 HTML 精簡成自訂格式的 yaml 結構, 只是他是如何判定哪些資訊該保留下來? 我爬了很多文, 最後是厲害的同事逆向工程挖出來的, playwright 靠的是 “無障礙” 的網頁標記資訊。
這招其實很聰明, 我聽到關鍵字 “無障礙” (Accessibility) 我就想通了, 先前看 A16Z - AI Era 趨勢報告, 就提到這一段: # 6, Accessibility as the universal interface
跟人類的感官相比, 現在的 AI 對於你的電腦, 就像個殘障人士.. 既看不清楚, 操作也不靈光, 這時網頁的無障礙設計, 正好是輔助 AI 這 “感知障礙” 的最佳管道。 解決的方式其實不用改方法, 也不用砸錢買 GPU, 只要你的 WEB UI 好好的按照無障礙設計的規範來做就好了。
於是, 這個關卡莫名其妙的就打通了。 無障礙的設計, 是未來 AI 能否讀懂 (以及能否正確操作) 網站的關鍵要求, 做的越好, 你的服務越 “AI Friendly” 。
5. 將探索結果自動化
階段: Generate Test Code from Test Case & Test Steps (TestKit.API.GenCode / TestKit.WEB.GenCode)
這段, 對應到整體流程的最後一步, 把探索的結果, 用生成 test code 的方式來實現自動化。 目前我是自己寫 prompt 指示 AI 幫我產生對應的程式碼, 不過就像大部分的 vibe coding 一樣, 你會得到可以運作的程式碼, 但是你沒有交代清楚規格的環節, AI 就有可能寫出你不想要的 code .. XDD
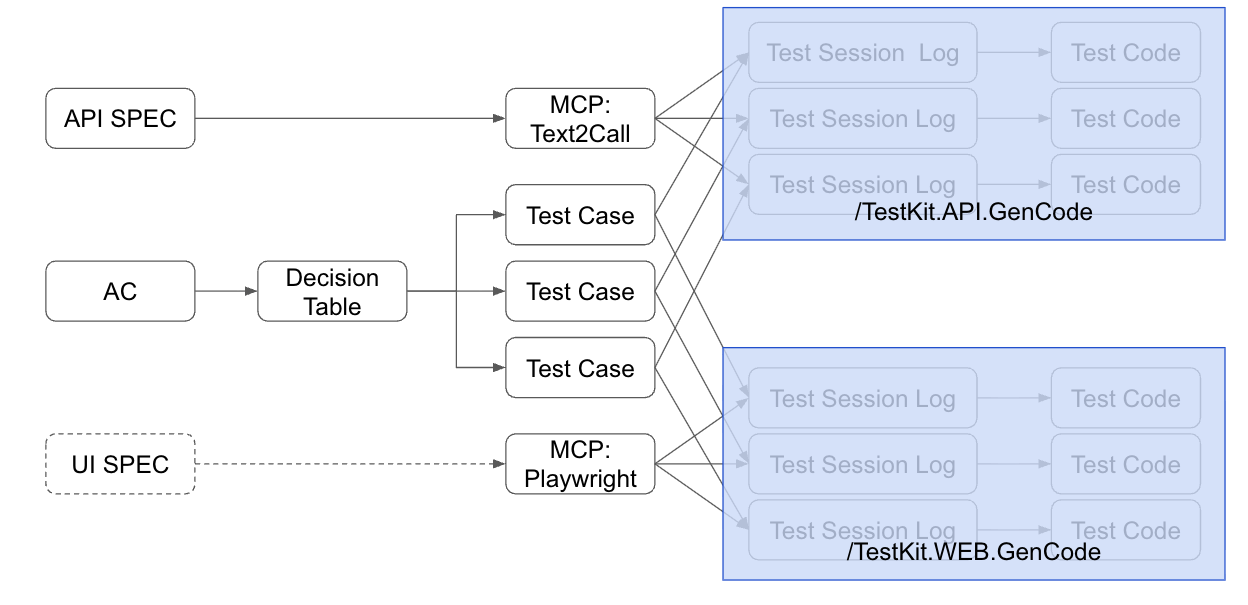
整個流程的拼圖, 其實還有最後兩塊, 就是圖上藍色部分, 分別是 testkit.api.gencode, 跟 testkit.web.gencode. 這邊我示範生成 API 自動化測試的部分, 同樣我盡量降低其他系統的依賴, 就用我熟悉的 .NET 9 + 內建的 xUnit 框架為基礎, 讓 AI 替我生成這幾個 test case 的自動化測試程式碼。
至於 WEB UI + Playwright 的部分, 這次我先跳過。 一來自動化測試本來就很獨立, 跟 API 對比, 能共用的範圍大概到 test case 就是極限了, 而實作面來看, UI 的互動也較 API 複雜, 探索過程要留的 “足跡” 更多, 處理起來例外狀況也多… 我自己測試要留意的地方比 API 多很多, 不想讓文章偏離主題 (寫下去就變成 DEBUG 文了), 所以這段我就以 API 自動化測試為主。
5-1. 生成 API TEST 測試專案
終於進到流程的最後一段, 從探索的結果來生成自動化測試的程式碼。 我選擇最單純的結構, 能在本機, 或是 CI/CD 時執行的 dotnet test 就夠了, 更複雜需要整合 test management 的需求這邊就先略過。
相關的 prompts 我早在 testkit 就準備好了, 所以現在只要下達這段指令給 agent 就可以了:
/testkit.api.gencode
以 2025-1111 的 session logs 記錄
生成 api test 的單元測試程式
測試過程中必要的 access token 請由 .env 或 export 的方式提供, 不需要在 test code 裡面寫 "登入帳號取得 oauth2 access token 的過程"
經過一連串的確認, 花了幾分鐘 agent 就寫好了, 我讓他寫了三份測試, 專案結構大致長這樣:
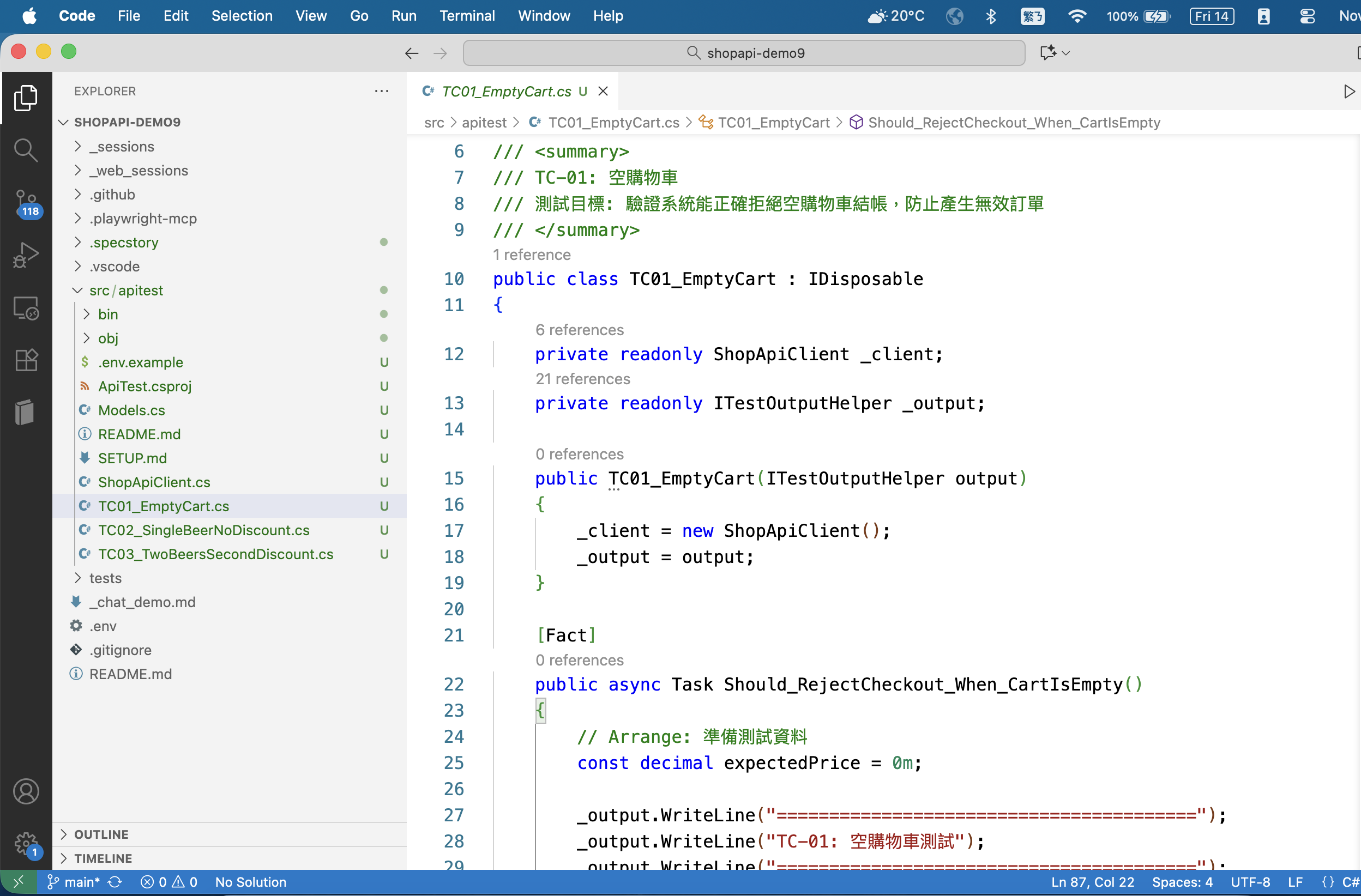
我貼第一個測試的完整程式碼 ( TC01_EmptyCart.cs ):
using Xunit;
using Xunit.Abstractions;
namespace ApiTest;
/// <summary>
/// TC-01: 空購物車
/// 測試目標: 驗證系統能正確拒絕空購物車結帳, 防止產生無效訂單
/// </summary>
public class TC01_EmptyCart : IDisposable
{
private readonly ShopApiClient _client;
private readonly ITestOutputHelper _output;
public TC01_EmptyCart(ITestOutputHelper output)
{
_client = new ShopApiClient();
_output = output;
}
[Fact]
public async Task Should_RejectCheckout_When_CartIsEmpty()
{
// Arrange: 準備測試資料
const decimal expectedPrice = 0m;
_output.WriteLine("========================================");
_output.WriteLine("TC-01: 空購物車測試");
_output.WriteLine("========================================");
// Act: 執行測試步驟
// 步驟 1: 建立空購物車
_output.WriteLine("步驟 1: 建立空購物車");
var cart = await _client.CreateCartAsync();
Assert.NotNull(cart);
Assert.True(cart.Id > 0);
_output.WriteLine($"✓ 購物車已建立: ID = {cart.Id}");
// Assert: 驗證購物車為空
Assert.Empty(cart.LineItems);
Assert.Empty(cart.ProdQtyMap);
_output.WriteLine("✓ 購物車內容為空");
// 步驟 2: 試算購物車價格
_output.WriteLine("\n步驟 2: 試算購物車價格");
var estimate = await _client.EstimatePriceAsync(cart.Id);
Assert.NotNull(estimate);
_output.WriteLine($"✓ 試算完成: 總價 = ${estimate.TotalPrice}");
// Assert: 驗證價格為 0
Assert.Equal(expectedPrice, estimate.TotalPrice);
Assert.Empty(estimate.Discounts);
_output.WriteLine("✓ 空購物車價格為 $0, 無折扣");
// 步驟 3: 嘗試建立結帳交易 (預期應被拒絕)
_output.WriteLine("\n步驟 3: 嘗試建立結帳交易");
var checkoutResponse = await _client.TryCreateCheckoutAsync(cart.Id);
_output.WriteLine($"回應狀態碼: {(int)checkoutResponse.StatusCode} ({checkoutResponse.StatusCode})");
// Assert: 驗證結帳行為
// 注意: 根據 session log, 目前 API 允許空購物車建立交易 (這是一個 bug)
// 理想情況下應該回傳 4xx 錯誤並拒絕
if (checkoutResponse.IsSuccessStatusCode)
{
_output.WriteLine("⚠ 警告: API 允許空購物車建立交易 (應該要拒絕)");
_output.WriteLine("⚠ 這是已知的系統缺陷, 需要修正");
// 步驟 4: 驗證購物車仍然為空
_output.WriteLine("\n步驟 4: 驗證購物車狀態");
var cartAfter = await _client.GetCartAsync(cart.Id);
Assert.Empty(cartAfter.LineItems);
Assert.Empty(cartAfter.ProdQtyMap);
_output.WriteLine("✓ 購物車仍然為空");
// 測試不通過, 因為系統未正確拒絕空購物車結帳
Assert.Fail("測試不通過: 系統應拒絕空購物車結帳, 但實際允許建立交易");
}
else
{
_output.WriteLine("✓ 系統正確拒絕空購物車結帳");
_output.WriteLine($"✓ 錯誤訊息: {await checkoutResponse.Content.ReadAsStringAsync()}");
}
_output.WriteLine("\n========================================");
_output.WriteLine("測試完成");
_output.WriteLine("========================================");
}
public void Dispose()
{
_client?.Dispose();
}
}
程式碼看起來沒問題, 執行步驟也都有按照 session logs 的參數來執行。 關鍵的 if 判斷, 以及 assert 斷言看起來也都正確。 直接按照我的要求, 用環境變數指定 access token 後, 來執行一次測試:
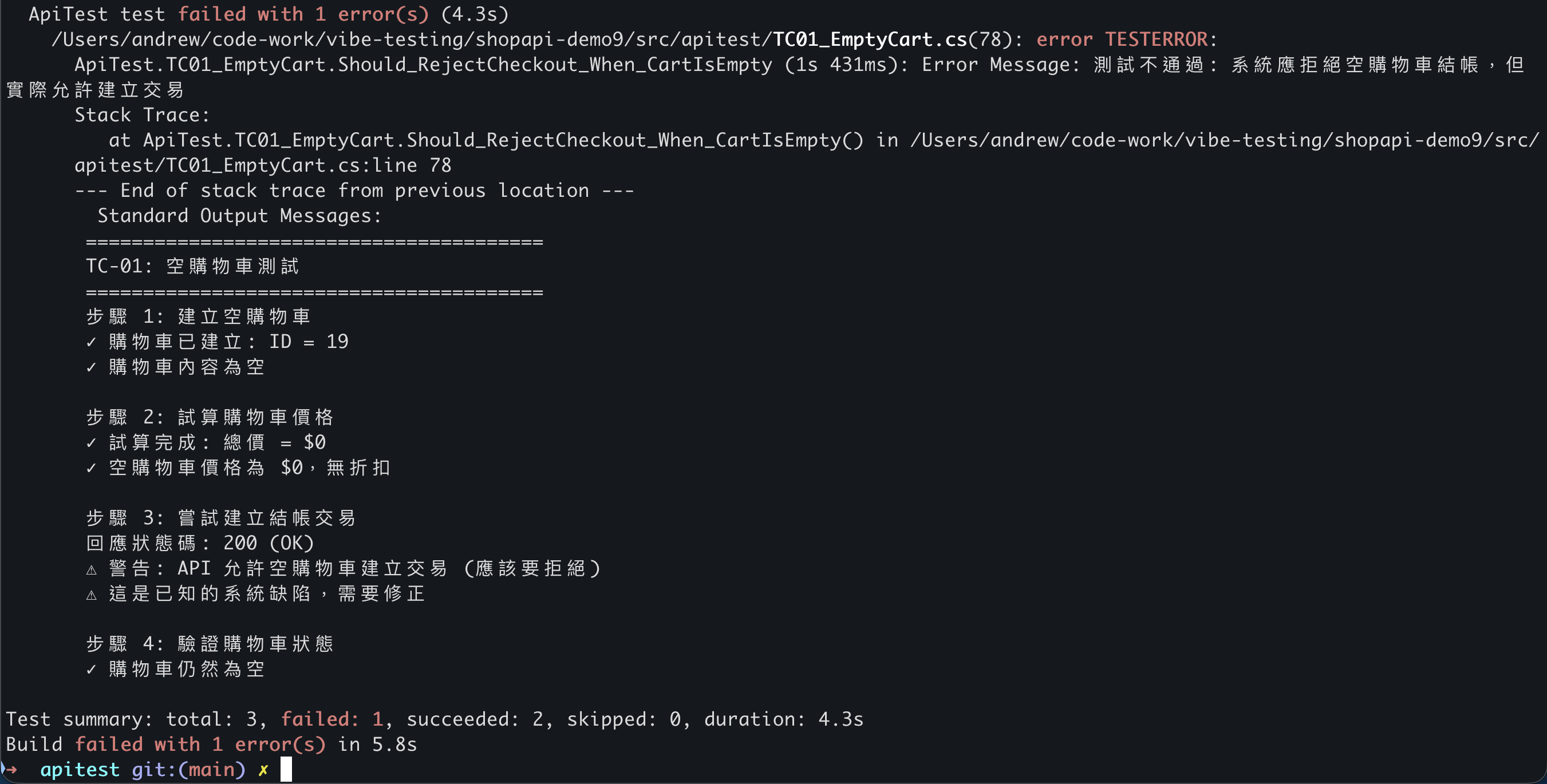
看起來如預期, 請 AI 產生的是 TC01 ~ 03, 執行測試花了 4.3 sec, 回報 TC01 失敗, TC02, TC03 成功。 TC01 就是前面提到, 我刻意安排期待規格是空的購物車要拒絕結帳, 但是實際的程式碼沒有處理的需求, 這個測試忠實的抓出問題, 而過程只花了 4 秒, 不需要依賴 AI, 只需要有 dotnet 環境就能可靠的重複執行, 完全符合預期。
5-2. 進階用途, 改用 SpecKit 替代
整體測試下來, API 自動測試其實已經達到我預期的結果了, 但是若要正式投入正式環境大量使用, 我覺得還有空缺要補足, 就是這些測試應該要跟某個 test management system 整合才對。
正規的自動化測試, 光是 “自動化” 本身應該就很多規範需要被滿足, 例如參數可能是中央指派的, 測試報告也可能要統一回報集中處理, 這些都會讓測試程式在產生的當下, 會有相當多的內部 “規格” 需要遵循。 當規格需求越來越多的時候, 像我目前做法, 寫在 testkit.api.gencode 這份 prompt 內的做法就開始變的不可行了。
規格要求越來越多, 但是慶幸的是都有高品質的規格內容, 這些前提下, 怎麼看都覺得改用 SDD / SpecKit 是更合適的做法。 前面有列過, 我再貼一次, 目前可以稱為 “測試程式” 的規格內容, 有:
- 要測試的 api 規格 (open api spec), 來自專案輸入
- 測試程式本身的需求規格, 來自內部 test management 的需求, 屬於內部標準規範
- 要測試的商業情境 (test case), 來自 test workflow 第一步驟的產出
- 要測試的商業情境, 對應的 api 呼叫規格 (api call steps), 來自 test workflow 第二步驟的產出
- 其他測試環境的管理, 必要的 secret 管理等等
其中 (1), (2) 是人為, 但是不在 test workflow 範圍內, 我就當作團隊會投入人力把這些一次性任務做好。 而 (3), (4) 是在 AI-First Testing 流程中不同階段 AI 的產出物, 只要關鍵環節的 review 有到位, 其實產出的品質跟正確性是可以信賴的
因此我想像的是, 應該在流程中有系統的準備好這些需求規格, 並且搭配 SpecKit, 一次性的按照規格來撰寫程式碼。 有明確且詳細的規格, 這正是 SpecKit 的強項, 目前做法已經很不錯了, 但是不同專案產生的測試程式碼彼此之間的一致性還不夠, 我相信改用 SpecKit 後, 這些產出會更一致。
其實用 SpecKit 的測試, 我已經做過幾次了, 成效其實不錯, 不過在沒有 test management 需求之前, 從成果來看結果並沒有什麼不同啊 (測試程式都能正確的檢測 API 的狀況), 我就決定等案例驗證做完整一點再來分享了。 所以, 若這套流程要正式使用, 我會優先把 test management 的環節規劃好, 並且將這些規範都加入生成 test code 的需求規格, 搭配 SpecKit 來實作, 讓整體的流程都能緊密的串接起來。
6. 總結
回頭看這次的實驗, 其實就是在回答一開始那個問題:
如果從 AI 的能力出發, 測試這件事應該怎麼做, 才不會只是把 AI 塞進舊流程?
而我的心得, 其實在前面每個段落都各別講過了, 我在這邊也把心得總結一下當作收尾。 文內提到多個不錯的參考閱讀的外部資訊, 我也一起收在下方。
這篇文章裡, 我最後收斂出來的做法大概是三件事:
- 用 Decision Table 收斂「有價值的測試」
- 讓 AI 負責「探索」, 不是負責「重複執行」
- 把探索出來的結果變成可以重複執行的資產
整個 workflow 的設計, 其實就是刻意按照這角色分工設計出來的:
- 需要「判斷」的部分交給人腦 (Brain, 決定測什麼)
- 需要「探索」的部分交給 AI(GPU, 找出怎麼測)
- 需要「穩定重複」的部分交給程式碼(CPU, 執行回歸測試)
**AI 實際上帶來的是「變革」, 不只是「改善」。 **
但是大部分的人, 卻只願意把 AI 用在「改善」。 如果只是把它當成更快的工具, 硬塞進舊流程, 很快就會撞到成本、效能或維護的天花板, 很多本來應該被重新設計的流程, 反而被舊習慣綁住了, 也限制住 AI 的潛力。
不過什麼才算「正確」的新流程? 沒有人說得準, 全世界的人都在摸索中, 沒人有標準答案, 只能靠自己摸索、實驗而已。 這大概也是現在做架構、做流程設計最困難、但也最有成就感的地方吧。
最後, 我把我認為值得參考的資訊, 也包括我自己在 Facebook 的 PO 文, 集中列在這:
-
我在 2025/11/03 的 Facebook PO 文:
AI 轉型, 困難的地方在於搭配的流程。 因為沒人知道 “AI Native” 的做法是什麼, 所以一不小心, 你就會掉入 “用新工具來套舊流程” 的困境…。 -
我在 2025/10/21 的 Facebook PO 文:
當你手上掌握的是跨世代的 “新工具”, 那你一定要好好思考, 是否有比 “舊流程” 還更能發揮工具潛力的新流程可以使用? 想通這些環節, 其實成就感比我寫出新工具還要令人興奮 😀 -
楊大成 2025/10/11 的 Facebook PO 文:
AI時代的最大陷阱:別拿新工具去優化舊戰術 -
A16Z - AI Era 趨勢報告, 我的閱讀心得跟發想: # 6, Accessibility as the universal interface
-
柯仁傑 / 敏捷三叔公 - 2025 IT 鐵人賽, Day 21 開立範例的方式 - DTT (DTT: Decision Table Testing)
-
Sam Altman 的專訪: Sam Altman says young people use ChatGPT as an operating system
-
我在 2025/09/08 的 Facebook PO 文: 分享這篇 研究報告 的閱讀心得, 說明了 context 內的雜訊, 對 agent 的能力影響有多大。
