今年三月, 跟保哥開了一場直播, 從 LLM 的基礎 ( OpenAI ChatCompletion API 開始 ), 談基本的 API 操作。使用方式從 HttpClient, 到 OpenAI .NET SDK, 再到 Microsoft Semantic Kernel, 示範了 Chat, Json Mode, 到 Function Calling 的操作, 最後示範了用 Microsoft Kernel Memory 這套服務來實作 RAG …
![]()
這次直播,我決定調整一下過去的做法: 先持續釋出片段資訊, 之後再整理成文章。對比過去我先整理文章再發表的習慣, 每次就要花上幾個禮拜… 現在的資訊更新速度實在太快了, 過去的步調已經跟不上變化了 (我有好幾篇文章躺在 draft branch, 結果寫一半就… 就不用寫了 XDD)。所以這次我在直播前一週, 每天在 Facebook PO 文介紹直播的八個主題… 而現在,這篇就是事後收整內容的文章。想要回顧或是查詢資料的就來這邊吧!
相關資源與連結
- 臉書: 安德魯的部落格
- 錄影: 簡介 .NET RAG 神器:Microsoft Kernel Memory 與 Semantic Kernel 的整合應用
- 問券: Google 表單 (別懷疑, 我還有在收 feedback XDD)
- 範例程式碼: AndrewDemo.DevAIAPPs
- .NET Conf 2024 簡報: .NET RAG 神器, Microsoft Kernel Memory (同主題, 我就放這邊了)
Day 0, Chat Completion API
這場所有範例,都來自 LLM 的 Chat Completion 操作。我不想所有同性質的 API 都示範一次 (反正都相容,或是同模式),所以我就直接用 OpenAI 的 API 規格為準了。LLM 的 API 很 “單純”,主要就只有一個 Chat Completion API,這 API 的用途就是回答你的問題。只靠這個 API 就足以解決所有需要 AI 回答問題的需要,複雜度都不在 API 本身,而是在於你怎麼運用他來解決 (對應) 你的問題與需求。
因此,你該學習的是各種解題需要的 “設計案例” (你也可以說是 AI APP 的 Design Patterns),在開始之前我們先來看最基本的使用方式…
Demo:
Simple Chat
第一個例子,我說明詳細一點,後面就貼 code 就不再多做說明了。從 http request / response 的角度來看, 整個 chat 的通訊模式就是:
把過去所有對話的紀錄 POST 過去 (包含你問的,跟 AI 回答的),API 會回應下一段回答給你。如果你收到了還想再繼續問,就連同這次 API 的回答,跟你下一次的問題,再打包一次重新呼叫一次 Chat Completion API ..
我拿基本的案例示範,任何 AI chat 你起始了這樣的對話:
system: you are a tester, answer me what I ask you.
然後你問 AI:
user: Say: 'this is a test'.
實際上, 你可以延遲到真正要問 AI 時再打 API 就好。把兩句 message 標示清楚 role, 包成一包送出去:
POST https://api.openai.com/v1/chat/completions
Content-Type: application/json
Authorization: Bearer
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "you are a tester, answer me what I ask you."
},
{
"role": "user",
"content": "Say: 'this is a test'."
}
],
"temperature": 0.2
}
這就是基本型, 以區塊來說, chat completions api 大概就只有:
- headers, 主要是 apikey 等建立通訊的必要資訊
- model + parameters, 你調用的 model, 以及該 model 需要的參數 (最常見的就是 temperature 了)
- messages, 就是常見的 context window, 這次的案例就兩段 message + role
- (option) tools, 允許 AI 使用的 tools 列表 (包含定義)
- (option) response format, 指定 AI 回應的格式, 例如 json object, 或是指定 json schema
你會得到這樣的 response (header 我就略過了, 只留 body):
{
"id": "chatcmpl-BiIC25mIqyGqDK1ePyzRZk71eES1B",
"object": "chat.completion",
"created": 1749896066,
"model": "gpt-4o-mini-2024-07-18",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "This is a test.",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 31,
"completion_tokens": 5,
"total_tokens": 36,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default",
"system_fingerprint": "fp_34a54ae93c"
}
如果你想要實作出類似 ChatGPT 那樣的對話應用, 每次 user 送出訊息就重複呼叫一次, 直到對話結束為止。這篇文章所有的案例, 都是從這個基本型態的 API 出發, 如果你看懂了, 就繼續往下看吧!
以下段落的格式說明:
接下來,就是蒐集先前 FB 貼文的部分了。當時我每天在 FB 說明一個主題介紹,而實作說明則都在影片中,兩者我都附在下方。介紹的部分我建議都看一看,有興趣再看對應的影片就好。如果你碰到特別有興趣的主題,則 FB 的連結我也建議點進去看一下,也許會看到有幫助的留言或是討論。這些都是大家的見解, 對我而言這些 feedback 其實幫助很大, 建議你別錯過這些片段的資訊。
以上說明到此,歡迎繼續往下看~
Day 1, Structured Output
Link: FB POST
這是我在 .NET Conf 2024 的其中一張簡報, 今天想聊一下這題..
Developer 應該怎樣善用 AI?
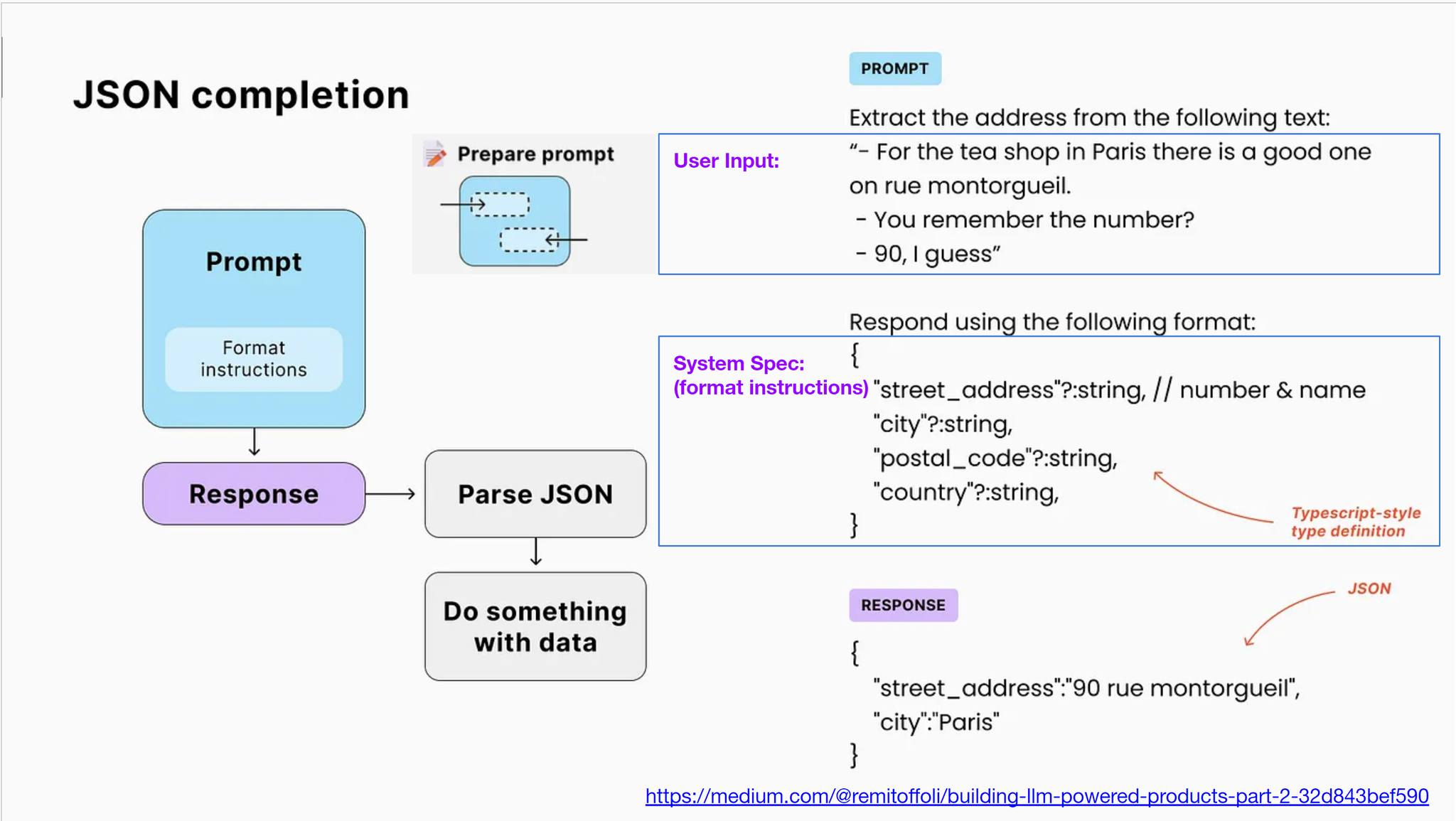
別誤會了,我沒有要聊 GitHub Copilot / Cursor 寫 code 有多厲害, 那個大家講到爛了, 我來講並沒有比較厲害, 反正用 AI 輔助 coding 早就不可逆了, 用就對了。我要談的是, 如果把 LLM 當作你的可用套件或是服務之一, 你會怎樣應用在你的 Application? 當 LLM 在各位開發人員手上, 各位你知道你手上的武器有多大的威力嗎? 這頁簡報,談的是先進的 LLM ( 我拿 GPT4o-mini 當分界 ),開始正式支援 Json Schema. 圖中的例子是要從一段對話, 擷取出對話中提及的那家 tea shop 正確的 address .. 如果這是別人問我的問題,我第一時間的反射動作一定是:
ChatGPT, 告訴我下列對話提及的地址...
(貼上對話內容)
如果我還有其他雜七雜八的要求,我一定一起丟給 ChatGPT 幫我處理,例如找出附近的景點,或是多告訴我那個地點的相關資訊等等。但是 ( 就是這個 BUT ),如果這功能是要埋在你某個 application 內呢? 如果你有幾百萬組這樣的對話,你都要抽出地址資訊呢? 反射式回答: 那就 call chat-completion api 就好了啊… 不過,你是 Developer, 你其實可以想得更多一點。我試著多列幾個思考題:
- 你要 LLM 用什麼格式回答你?
- 如果有 1% 的機率 LLM 回答不出來,你程式能怎麼判斷?
- 你還該讓 LLM 處理雜七雜八的要求嗎? 通通寫在 prompt 讓 AI 一氣呵成比較好? 還是取得地址後自己打 google map api 處理比較好?
開發應用程式就是這樣,依靠開發團隊的經驗,把處理過程寫成應用程式,使用者就能站在你的肩膀上不用再踩一次地雷。如果你的服務使用量夠大,你的一念之間的決定可能影響著巨大的效率提升.. 這才是身為 Developer 的職責,也是身為 Developer 的優勢。這世界有更多這種新的服務需要開發,要讓 AI 來開發 AI 的應用程式,現階段也還沒那麼容易,這會是 Developer 大顯身手的地方。回到這題來看,你會發現你平常在 ChatGPT 下的 prompt, 都不見得適合直接拿到程式內使用。 那麼怎麼弄才是 Developer 的作法?
上面的問題,我的答案是:
- 用 Json output
最好還能定義 Json Schema, 拿到結果後立刻 deserialize 成 C# object, 以利後續讓非 AI 的程式碼能無縫的接手處理。 - 直接在 output 就 “明確” 標明執行結果成功或失敗
(就像 HTTP status code 一樣),不要用猜的,對你好,對 LLM 也好。明確的讓 AI 輸出能否判定答案 (輸出地址),比起你自己 parsing 後再丟出 exception 優雅的多。LLM 的幻覺跟不確定性已經夠多了,不需要多妳一個.. - 單一職責,只讓 LLM 處理非他不可的任務就好。
其餘任務,只要用 json 傳出必要資訊,用程式碼來處理就夠了。講直白一點,搜尋,格式轉換,數值計算等等,這些都是 code 來處理遠遠強過 LLM 的領域。你不需要為了少打那幾行 code (都可以 AI coding 了),結果原本幾百個 CPU instructions 能處理完畢的事情,變成每次都花費幾百個 tokens 才能處理… 你知道一個 Azure Function Call 的費用,跟一個 ChatCompletion API Call 的費用差多少嗎? 別忘了妳的決定會被放大 100 萬倍…. 所以,回到這張簡報,你知道為何你該了解 LLM 的 Json Mode 了嗎? 實際的 code 我就不貼了,這是我在 03/25 直播的前半段會提及的 AI APPs 開發基本技巧的內容 XDD,因為我必須交代完他,我才能讓大家充分體驗我要談的主角: Microsoft Kernel Memory 啊 …
當天,這個案例 (還包含接下來我每天會貼一則案例),我會用 OpenAI 的 ChatCompletion API 當基礎,我會分享:
- 用 Http Client 示範
- 用 OpenAI .NET SDK 示範
- 用 Microsoft Semantic Kernel 示範
用不同方式寫這段 code… 其實有很大的差別。SDK 相依姓的取捨,跟帶來的便利,你要懂得之間的差別。別以為只是 call API 就結束,如果你看到你 call api 要自己寫 json schema, 而用 semantic kernel 的時候只需要給 C# type, 你的想法就會改變了…
Demo:
Structured Output:
- Chat GPT, 直接在 ChatGPT 測試這段 prompt 的紀錄
- HTTP Client, 直接 call openai chat completion API
- OpenAI .NET SDK, 用 OpenAI C# SDK 的範例程式碼
- Microsoft Semantic Kernel, 用 Microsoft Semantic Kernel 的範例程式碼
以下是簡報內純文字的資訊 (對話):
Extract the address from the following text, Response using the following json format:
{
'street_address'?: string,
'city'?: string,
'postal_code'?: string,
'country'?: string
}
- For the tea shop in Paris there is a good one on rue montorgueil.
- You remember the number?
- 90, I guess.
Day 2, Function Calling (Basic)
Link: FB POST
昨天聊完 Json Mode, 今天繼續來聊聊 Function Calling… 同樣是我在 .NET Conf 2024 的簡報:
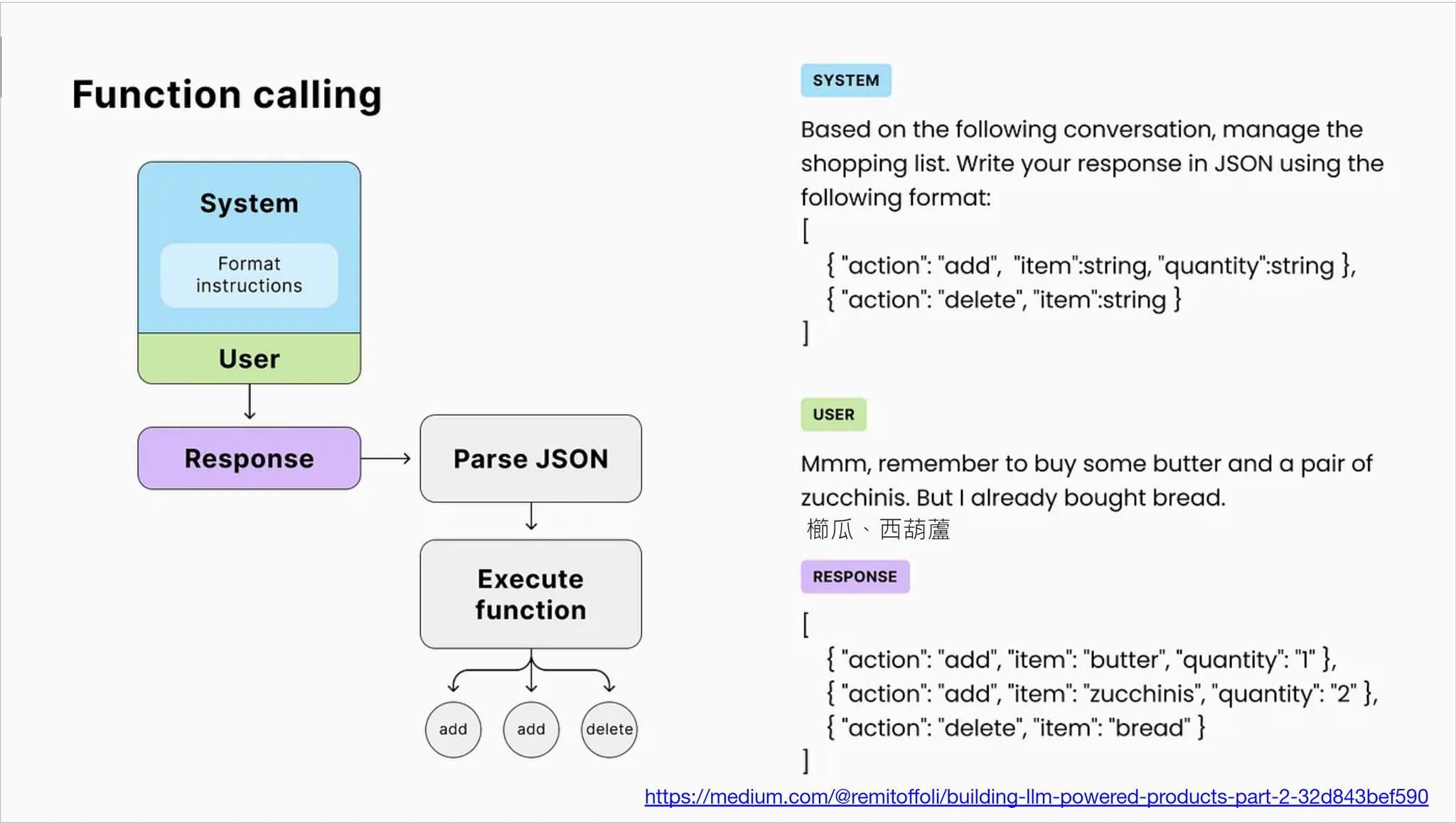
Function Calling (或稱為 Tool Use), 我覺得這是 LLM 普及以來, 威力最大的功能了。就因為 LLM 有了這能力,才開啟了各種 Agent 以及透過 AI 來主控各個週邊系統的能力。所有想要在你的 App 內應用 LLM 的 Developer, 請務必要搞清楚 Function Calling 是怎麼回事, 這我認為是下個世代最重要的基礎知識了。
我先分解動作,今天只聊基本動作,明天再來談連續動作…。昨天聊到 Json Mode, 當你問 LLM 問題,指定 LLM 要用你提供的 Json Schema 輸出 Json Object, 這能力其實是開啟了 LLM 跟 code 之間 (用 json) 資料交換的通訊基礎了。而 Function Calling, 則開啟了 LLM 跟 code 之間的函數呼叫 ( 正是 Function Calling ) 的通訊基礎。蹭一下最近不知道在紅什麼的 MCP, 其實就只是 Function Calling 的實體化通訊協定。
Function Calling 是在對話開始之前, 預先告知 LLM 你有那些 “Function” 可以使用? 然後在對談過程中,讓 LLM 自己決定他要告訴 User 結果 ( Text ), 或是他要先執行指令 ( Function ) 並看看結果後再決定 ( 繼續執行指令 Function , 或是直接給結果 Text ) ?
極度簡化過的基本型,就如這頁簡報,一開始的 system prompt, 我告訴 LLM:
Based on the following conversation, manage the shopping list,
write your response in JSON using the following format:
[
{ "action": "add", "item": string, "quantity": string },
{ "action": "delete", "item": string }
]
告知有哪些動作 ( action + parameters ) 可以用來維護購物清單後,接著就是給他需求:
Mmm, remember to buy some butter and a pair of zucchinis.
But I already bought bread.
推理能力夠好的 LLM 就能夠解讀這段對話的意圖。知道這段對話要提醒你記得買奶油,兩個櫛瓜 (我今天才知道 zucchinis 這單字的意思 XDDD),麵包我已經有了不用再買。
依靠強大的推理能力,跟前後文 (其實這裡也包含了昨天介紹 Json Mode 的能力),LLM 已經能將這段對話的意圖,用你給他的指令集表達出來。某種程度,已經是自然語言跟你給他的指令集的編譯器了。這些對話,你貼在幾個主流的 LLM 都能得到一樣的答案:
[
{ "action": "add", "item": "butter", "quantity": "1" },
{ "action": "add", "item": "zucchinis", "quantity": "2" },
{ "action": "delete", "item": "bread" },
]
基本上這樣已經完成一大半了, 都已經用 Json 告訴你接下來該依序執行那些指令了, 剩下的只要寫一段 code, 依序真的執行這些指令就能真的完成任務了。
這就是 Function Calling 的基本原理, 當然實際應用不需要這麼土炮, API / Framework 層級都有更方便使用的模式, 不過 LLM 變化快速, 我高度建議大家還是要搞懂這原理。某些情況下 (例如你同時要 call 前端跟後端的 function),你沒辦法用內建的機制來運作,或是你要處理更高層級的 Planning 時, 你都會需要自己手動下這樣的 Prompt..
回到 Function Calling, 其實到這裡為止, 你只完成了 “Call”, 還沒完成 “Return” … 更完整的應用案例,我留到明天第三頁簡報再來聊~
Demo:
Function Calling (Basic)
以下為原始對話內容, 你可以貼到手邊的 AI chat 工具試試看:
Based on the following conversation, manage the shopping list,
write your response in JSON using the following format:
[
{ "action": "add", "item": string, "quantity": string },
{ "action": "delete", "item": string }
]
--
Mmm, remember to buy some butter and a pair of zucchinis.
But I already bought bread.
其他進階的範例 ( http request / response, 以及對應的 C# code, 我等隔天的 PO 文一起說明 )
Day 3, Function Calling (Case Study)
Link: FB POST
昨天談完 Function Calling 的基本型態, 今天來看看實際上可以做出什麼類型的應用吧~ 簡單的說,推理能力夠好的 LLM, 已經有辦法從:
- 可用的指令規格 (你手上有的工具)
- 你的意圖
直接產生符合 (1) 跟 (2) 的對等 “指令執行順序” …, 如昨天所說, 這是將文字敘述的意圖, 翻譯成指令集執行順序的編譯器了。這在過去不靠 AI 是完全做不到的事情,我才會說所有 AI 神奇的應用,大半都是從 Function Calling 的能力累積而來的。
不過,昨天只談了一半,解譯出 “指令執行順序(含參數)”,只有 “Calling” 啊,Function 應該是有 Return 結果的,而且有時應該要有順序相依關係的 (你要執行完 Func1, 拿到結果後才決定怎麼執行 Func2 ..)
於是,來看看這頁簡報 (同樣是來自 .NET Conf 2024 我那場的簡報) 吧:
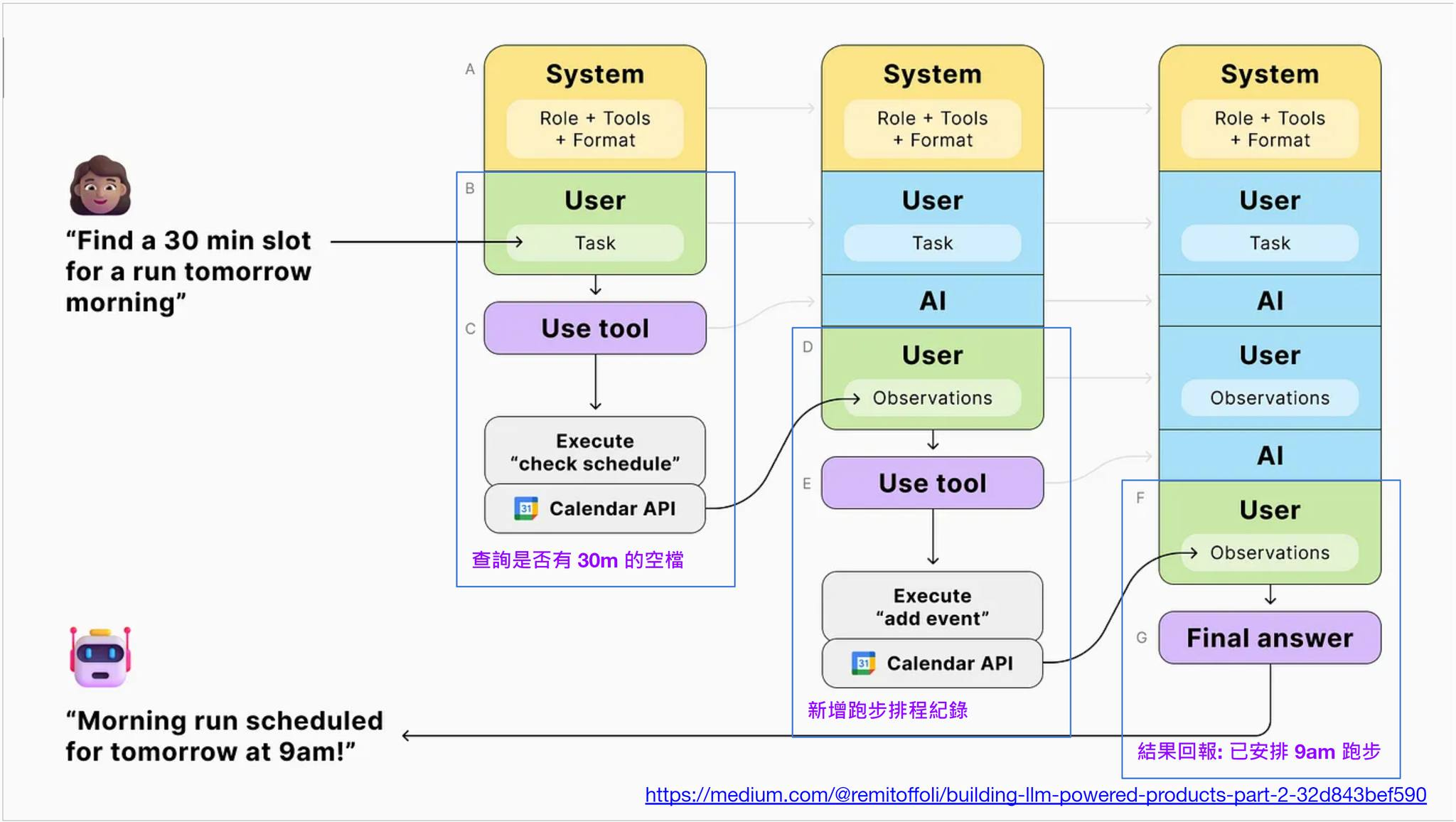
這情境是:
User: find a 30 min slot for a run tomorrow morning
(幫我找明早 30min 空檔, 我要慢跑)
先省略中間過程,我期待 AI 能幫我處理好所有事情 ( 按照要求 Booking 行事曆 ),並且回覆我這段訊息:
AI: Morning run scheduled for tomorrow at 9am !
(已經幫您預約好明早 9:00 慢跑)
這神奇的結果,是怎麼靠 Function Calling 辦到的? 我就列出檯面上 & 檯面下的對談過程,你大概就能理解這整件事的來龍去脈了。
- system: tools: [ “check_schedules”, “add_event” ]
- user: find a 30 min slot for a run tomorrow morning
送出這段歷程後, 第一次 AI 會回應: - tool: [ check_schedule( 03/21 06:00, 03/21 12:00 )]
收到這段回應後, 代表 AI 需要叫用 check_schedule 這工具, 並且給他時間範圍, 明天 (03/21) 的 06:00 ~ 12:00…
當你的應用程式, 代替 AI 執行完這段指令, 並且回覆結果 ( append 對話紀錄 ) - tool-result: [ “07:00-08:00, 起床換裝”, “08:00-09:00, 吃早餐”, “10:00~12:00, 跟同事視訊會議” ]
送出後, AI 得到結果,判定思考後,會再次送出這回應: - tool: [ add_event( 03/21 09:00 - 09:30 )]
同上面的過程,AI 表達他需要使用 add_event 這工具。你的應用程式應該替他執行並且給 AI 執行結果: - tool-result: [ “success” ]
再次送出結果給 AI,最後 AI 判定任務完成,就彙整上面的過程,最後直接回應這訊息: - assistant: morning run scheduled for tomorrow at 9am!
以上就是完整的對話過程。這邊留意,我標示的 (1) ~ (7), 是 chat history 的序號跟內容。每次呼叫 AI Chat Completion,都是把 history 當下為止的所有內容 (從 0 開始) 都送出去。
- system 代表 system prompt, 最高優先權, 背景設定用
- user 則代表使用者直接輸入的訊息
- assistant 則代表 AI 要回應給使用者的訊息
其中 tool 代表 AI 回應給 APP 的訊息, 需要 APP 檯面下替他執行這指令,而 tool-result 則是 APP 執行後在檯面下回覆 AI 執行結果的兩種特殊 message. 每次呼叫 AI Chat Completion, AI 就都能根據目前的前後文做出下一步的決定,直到完成任務為止。
是否很神奇? 原來這一連串不可思議的動作,其實拆解下來也很普通,就真的是昨天介紹的基本型態 function calling, 以及前天介紹的 structure output 的組合應用而已。實際上的狀況是,你要寫這種應用程式不用那麼辛苦,跟我一樣土炮這整個過程… 這過程主要是研究用,當你搞清楚後,有很多成熟的 framework 可以讓你簡化這一連串的動作。
這部分我就不推薦直接使用 Http, 也不推薦直接用 OpenAI SDK 了, 因為你程式碼要處理的細節太多, 你可以直接選擇成熟的框架 ( 例如: Semantic Kernel ),成熟的 No Code 平台 ( 例如: n8n, dify ),或是成熟的 LLM Client + MCP server ( 例如: Claude Desktop, Cursor … ), 其實都是在做同樣的事情。
連續三天,看到這邊,是否有解開一些疑問? 是否想通了 AI 這些神奇的能力是怎麼被創造出來的? 這三部分,我常常都稱他為 AI 時代的開發基礎技巧,它的重要性不亞於當年我剛開始學寫程式時,書上交給我的基本流程控制技巧 ( 例如: If, For Loop 等等 )。我強烈建議所有的 Developer, 應該把這些應用方式當作基礎能力, 確實的掌握清楚後再來學各種框架或是快速開發的技能。
Demo:
- Schedle Event Assistant
Day 4, RAG with Function Calling
Link: FB POST
講完 Json Mode, Function Calling 之後, 今天的主題是: RAG

同樣截了張我在 .NET Conf 2024 的一頁簡報, RAG ( 檢索增強生成, Retrieval Augmented Generation ), 其實就是用檢索的技術, 讓 LLM 依據這些檢索的結果來生成內容 (回答) 給使用者的技巧。若沒有 RAG, LLM 則會用他被訓練得那些知識來回答。這些來源通常會有幾個月以上的時間差,而且會因為訓練內容的不同而有所偏差…
這邊我把 RAG 分成兩段來看,一個是 RAG 本身的處理流程,另一個是如何觸發 RAG 的運作機制。處理流程其實並不難懂 (難的是怎麼調教到精準 & 滿意),分成幾個步驟:
- 先收斂 “問題”,把她轉換成檢索內容的條件或查詢
- 檢索出相關內容 (一般而言都是到向量資料庫,但是非必要,你要到全文檢索系統,或是搜尋引擎其實也可以)
- 將上述這些資訊組合成 prompt, 讓 LLM 依據你提供的內容 (2), 搭配 (1) 的問題,讓 LLM 替你彙整生成最後的答案
其實這就是 RAG 的基本流程了。不過我刻意把 RAG 擺在 Function Calling, 其實這就是 Function Calling 的一種應用啊.. 試著看一下這段 system prompt:
你的任務是協助使用者,代替他到 xxxxxx 檢索資料,並且依據這些檢索的結果來回答使用者的問題。
回答問題時請附上檢索的來源網址,並且請勿回答檢索內容沒有提及的內容
如果你又很剛好的,有給他這個 “tools” 的定義的話.. ( 回想前面的 Function Calling 案例 ),那麼 LLM 就會自動將你提問的問題,解讀成要先 “檢索” ,然後再回答內容。而這整個過程,其實就是靠 Function Calling 觸發的。
至於要給搜尋引擎的條件與參數 ( 例如 query, limit, tags 等等過濾條件 ),其實就是靠 Json Mode, 將呼叫這 Function 需要的各種參數,從前後文抽取出來 ( 還記得聊 Json Mode 時, 從對話中抽取格式化的地址資訊這例子嗎? )。這些資訊都備齊,LLM 就能隨時指示你的 AI APPs, 該替 AI 去呼叫搜尋引擎了 ( 指令跟參數 LLM 都幫你準備好了 )
如此一來,你的對談內容,突然就搖身一變,從原本只能回答 LLM 腦袋本來就有的世界資訊之外,他彷彿開始懂得使用 Google 了一般,當你問了他不知道,或是他判斷應該去 DB 檢索的時候,他就會自動呼叫搜尋引擎,並且自己生成必要的查詢參數,找到結果後消化吸收,再變成答案回覆給你。感覺很熟悉嗎? 沒錯,這就是 Search GPT 這類功能的工作原理,弄懂它之後,你也有能力自己實作一樣的功能,並且可以把 Search 的對象換成自己的知識庫。
看到這邊,如果你熟悉 Function Calling 的使用技巧,要做出 Search GPT 其實是輕而易舉的事情。03/25 我有準備一個範例程式,我用 BingSearch ( 人家有現成的 API + SDK, 我為了方便 demo 就拿來用了 ) 當作 Plugins 掛上 Semantic Kernel, 同時也掛上了幾個其他的 Plugins ( 例如回答我現在在哪裡,現在的天氣資訊等 ),你就可以這樣問他:
請問我現在這邊有哪些值得逛逛的景點? 以及提醒我出門前應該準備哪些東西
推理能力夠好的 LLM,就會聰明的充分運用他手上所有的工具,會先去查你在哪裡 (我只回應到 City),會查你當地現在天氣,然後根據地點去搜尋引擎找資訊,並且提醒你要不要帶傘,或是穿外套等。
你會發現,到最後你只要選擇一個夠可靠的檢索服務就夠了 (你不一定要從零開始,自己用向量資料庫慢慢打造),只要他能夠被當成 Semantic Kernel 的 Plugins, 就能被 LLM 納入他的工具箱內,需要時隨時取用了。那個檢索服務最合適? 我鋪梗鋪那麼久,主角終於能現身了,就是 Microsoft Kernel Memory … , 明天就來聊這個服務能幹嘛 ?
Demo:
Day 5, MSKM: RAG as a Service
Link: FB POST
鋪了四天的梗, 第五天終於來到正題, 今天就直接來聊聊 Microsoft Kernel Memory 這個 open source project 吧~
Microsoft Kernel Memory ( 以下簡稱 MSKM ), 背後的開發團隊跟 Semantic Kernel ( 以下簡稱 SK ) 是同一個團隊,因此有幾個地方, 是 .NET 人員可以期待的。不但架構設計上格局夠大,可以橫向擴充到極大的規模,也可以小到像 SQLite 那樣內嵌在你的應用程式內。而軟體功能的擴充性也很棒,除了有各種 AI service 的連接器之外,文件匯入 MSKM 的 pipeline, 你也可以完全自訂自己的 handler, 將自己的邏輯內建在 MSKM 內..
這次我截了兩頁簡報,分別代表了 MSKM 的兩種應用方式。第一個是 as web service, 你可以透過 http api 來存取 MSKM, 或是你也可以用 serverless 的模式, 直接把整套 MSKM 核心機制直接內嵌在你的應用內 (不是跑個 localhost 再用 http api 的做法喔),基本上已經顧及到各種規模跟應用的方式了。
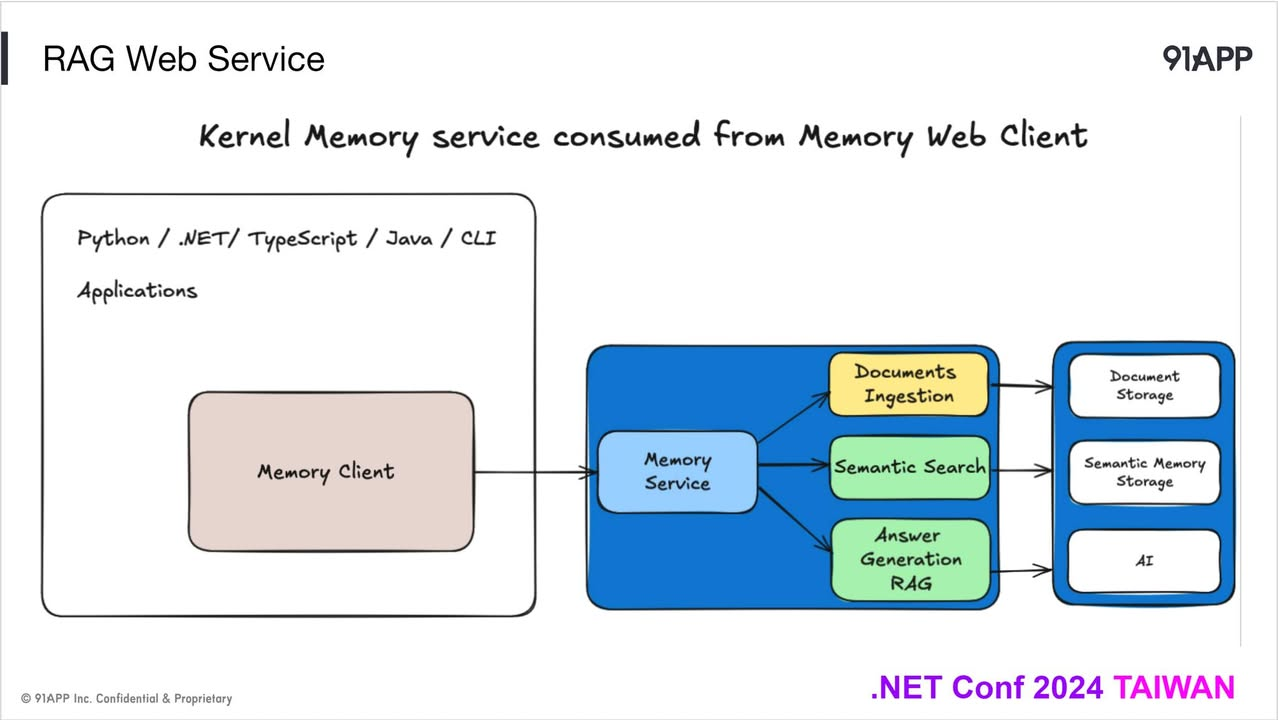
回到 MSKM 這專案本身,他要解決的環節,主要就是 AI APP 最棘手的 “ long term memory “ 的管理問題。在 SK 內,短期記憶是用 Chat History 來處理的,而長期記憶只是定義了 Memory ( Vector Store ) 來處理。不過,仔細看他的說明,你會發現 Memory 其實比較像是抽象化的向量資料庫,有點像 EF (Entity Framework) 之於關聯式資料庫,Vector Store 就是讓你定義你的 Vector Store 結構,方便你 CRUD,並且直接定義好相似性檢索的 interface ..
但是如果你理解 RAG ( 尤其是 document ingestion ) 怎樣匯入文件內容的話,你會發現,從內容的文字化,內容的分段,合成,貼標籤,向量化,寫入,查詢… 這一大段的流程,SK Memory 只處理了最後一小段而已。所以,MSKM 這專案就因為這樣,被獨立出來了。由於你要做大量文字的處理,通常也很吃你的長時間任務處理的機制是否成熟 (大概就式分散式任務處理那類的問題),因此與其像是 SK 那樣用 Framework 的方式發行,MSKM 則選擇用了 “獨立服務” + SDK 的方式來發行。
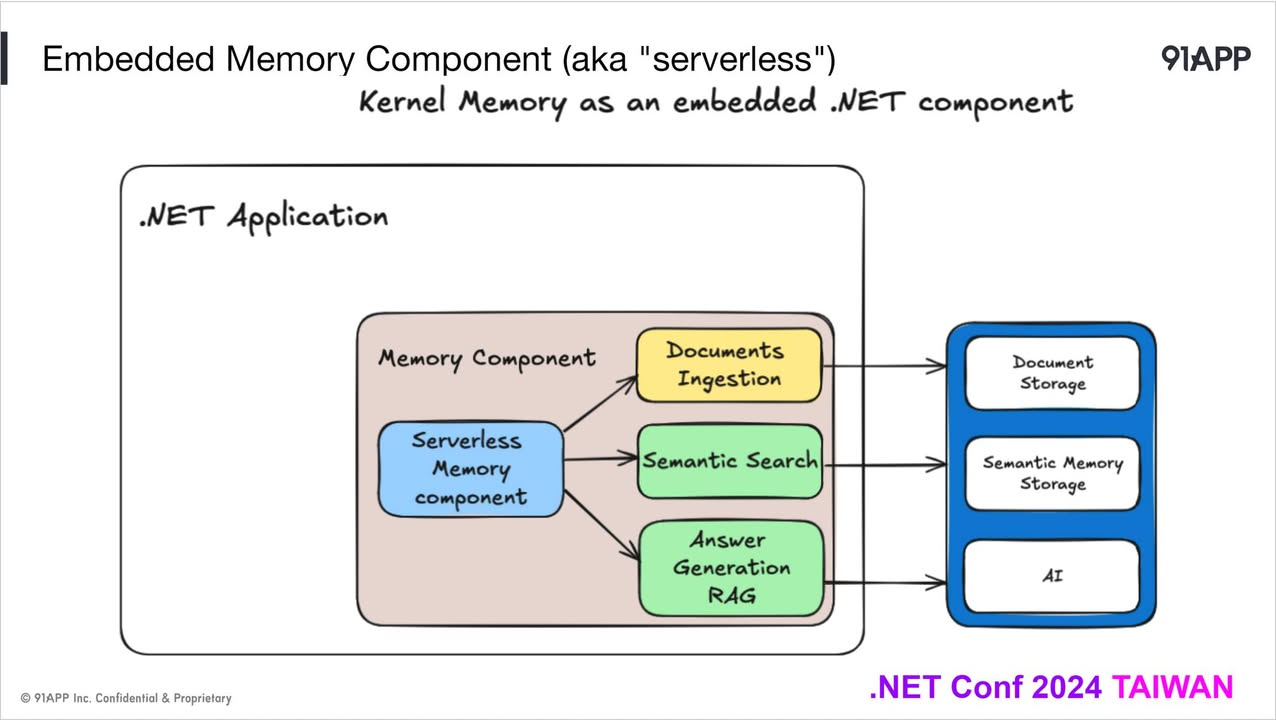
你可以直接拿 source code ( 從 github clone ) 來使用,你也可以直接從 docker hub 拉 image 回來直接部署 ( 不用寫 code ),在呼叫端你可以直接用他的 NuGet Package … 都是為了這個目的而設計的而被當成獨立服務來看待,那 MSKM 跟 SK 就算是同一個團隊開發的,好像也沒有什麼特別的關聯… 這樣想你就錯了,我在這邊特別提兩個地方,特別適合兩者搭配使用的情境:
-
MSKM 內建支援 SK 的 Memory Plugin
MSKM 已經在他的 NuGet package 內準備好 SK 使用的 Memory Plugins 了,你可以直接將他掛上 SK Plugins 內使用的。一旦掛上去之後,其實你就等於替 AI 追加了一組能直接操作 MSKM 的 tools 了。前面聊到的 Function Calling, 你可以想像 MSKM 支援的功能也都能被 AI 判斷與呼叫使用了 -
MSKM 本身也同樣是用 SK 開發的,SK 支援的各種 connector 你都不用擔心,都可以在 MSKM 上直接使用。例如 LLM / Embedding 的 AI 服務 ( openai, azure openai, ollama, claude … 等等 ) 通通都支援
這一切這樣組合起來,我覺得是目前 .NET 領域最成熟的組合了,MSKM 不適合那種開箱即用,需要配套的 UI 跟管理工具的終端服務,她更適合的是給開發人員使用的獨立服務。既然對象是 Developer, 那麼先具備基礎的 AI APP 開發知識是必要的。這也是為何我會先安排 #1 ~ #4, 花了些篇幅先介紹前面的基礎知識,因為你掌握了這些,才能充分體會 MSKM 設計的精妙之處
Demo:
- RAG with Kernel Memory Plugins
- RAG with Kernel Memory Custom Plugins
- Demo from Kernel Memory Offical Repo
Day 6, 進階 RAG 應用, 生成檢索專用的資訊
Link: FB POST
有了 SK ( Semantic Kernel ) 跟 MSKM ( Microsoft Kernel Memory ), 對於 RAG 這樣的應用, 我們開始有了高一層的控制能力了。今天就來聊聊面對 RAG 的應用時, 有哪些在設計之初就能改善檢索效果的技巧吧
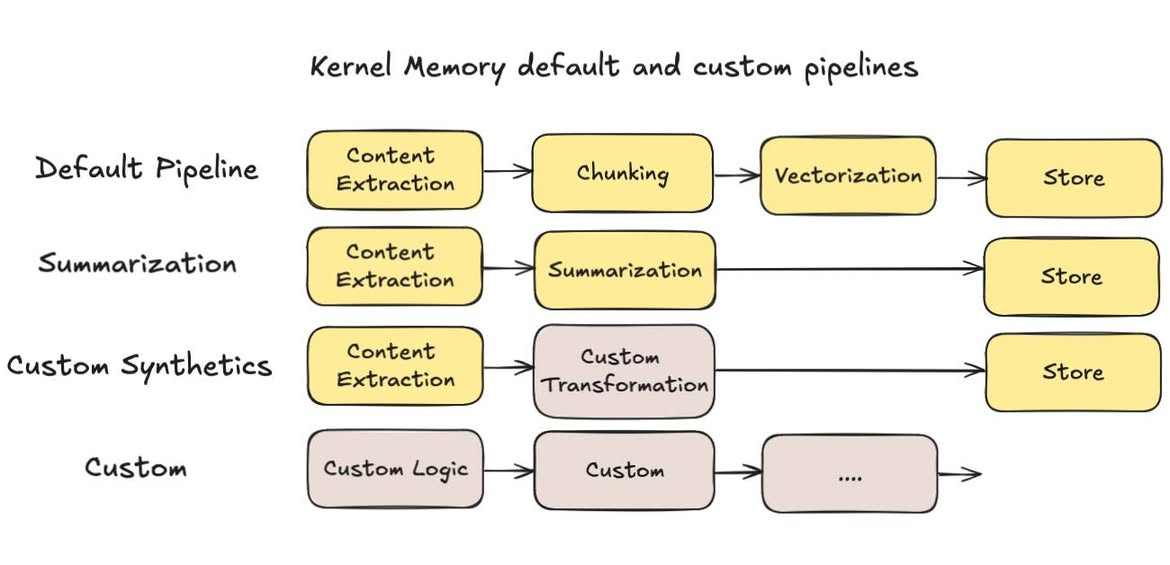



大部分教科書, 都是教你要把內容分段 (分段有很多策略, 長度, 分段符號, 重疊範圍等等),不過我實際拿我自己部落格文章來測試,老實說效果並沒有很好.. 拿最基本的 MSKM 預設設定 ( pipeline ),流程大致上是這樣:
- 文字化 ( content extraction ) 如果你的內容不是純文字, 會先有一個 handler 來處理。例如 PDF 先轉成文字, 或是圖片先進行 OCR 等等
- 分段 ( chunking )
RAG 主要檢索用的技巧, 就是把內容向量化。向量化的模型通常都有最適合的內容大小。以我使用的 OpenAI text-embedding-large3 來說, 建議輸入是 512 tokens, 上限是 8191 tokens .. 文字太長的話就需要先分段, 也就是 chunking 在做的事情 - 向量化 ( vectorization )
就是把 (2) 分段後的文字,逐段都交給模型轉成向量。這過程有的地方會稱他為 “內嵌” (embedding) - 儲存 ( store )
單純的把前面處理的資訊, 原始內容, meta data, 還有向量通通都存起來。一般會直接存到支援向量搜尋的 database, 作為後續檢索查詢使用的資料來源
然而,我實際拿我部落格文章測試,基本檢索其實還不錯,但是當我問題問的遠一點就很糟糕了。有在看我文章的人,大概都知道,我文章寫得很長… 初步統計一下,我部落格的 .md 檔案統計:
- 總共有 330 篇文章 ( 後期都是 .md , 早期用 .html )
- 單篇文章純文字內容, 約在 50k ~ 100k
而向量檢索的基本動作,是把你的詢問也轉換成向量, 然後拿著這向量 (query) 到資料庫內挑出相關度高的內容,最後把這些資料交給 LLM 合成最終答案。如果你不對你自己的檢索內容做任何調整,那麼一篇文章平均會被切成 100+ 個分段 ( partitions ),你的查詢,會從這些分段中找出相關度高的來使用。但是,資訊的密度根本對不齊,往往會得到牛頭不對馬嘴的狀況。
舉幾個例子,我寫了篇 WSL 的應用,花了很多篇幅介紹 WSL 應用的細節跟隱藏的地雷,然後有人問了 “WSL 能幹嘛” 的時候,你希望向量資料庫給你那些分段?
基本上這是無解的題目,因為給哪一段都不對啊… 除非我自己寫文章時候習慣很好,最前面的簡介就寫得很好,把整篇文章的摘要都濃縮在一個分段內,那麼 RAG 檢索時候這簡介應該會排到比較高的分數,會被拿來生成答案。雖然有解法了 (我自己替每篇文章補上一段 1000 字以內的摘要..),不過這時代有 LLM,我應該不用那麼辛苦才對。因此,我開始嘗試,能不能在把文章送進去檢索前,我自己先靠 LLM 生成我欠缺的部分? (摘要)
果然效果好的多,而且 MSKM 的 pipeline 也內建這機制了,你只要在 ImportText 時指定自訂的 pipeline, 加上 Summarization 這個 handler 就夠了。不過我想做更多嘗試,因此我先選擇在 MSKM 外面先自己處理好內容,暫時沒有直接搬進 MSKM 的 Handlers. 除了前面做的摘要 ( summarization ) 之外,我多做了好幾種嘗試,包含:
- 全文章的摘要 ( abstract )
- 文章每個段落的摘要 ( paragraph-abstract )
- 轉成 FAQ 清單 ( question / answer )
- 轉成解決方案案例 ( problem / root cause / resolution / example )
其餘還有別的嘗試,我就不一一列出了。這效果比起之前無腦的 RAG 好得多,因為很多查詢的角度,我可以得到語意更正確的檢索結果了。除了前面提到的摘要之外,我拿 FAQ 跟解決方案當例子,我的文章寫了很多我解題的思路,但是大家應該都是抱著問題來找答案的,所以提出的查詢應該都是以問題為主 ( 包含: question, 也包含 problem, 中文都叫做 “問題”,其實意義上有區隔 )。
這是視角的問題,使用者用他的視角來詢問,而我用我的視角來寫文章內容。當兩邊的視角不一致的時候,單純向量化的相似性是挑不出兩者的關聯的。因此我主要解題的方向就是,靠 LLM 良好的推理與彙整能力,將我文章內容生成成對應視角的內容 (我列了那四項就是四種視角),再把這些內容標上合適的 tags, 通通向量化加入檢索。
因此,應用的方式開始更靈活也更有趣了。由於這些是文章產生或異動時處理一次就好的任務,跟使用者查了幾次無關,因此我挑了貴一點的模型來測試 ( 我用 OpenAI 的 o1 ),效果還不錯,用 SK 先生成這些檢索用的內容後,再交給 MSKM 檢索處理。最後讓 AI APPs, ChatBot, Agent 等前端介面直接到 MSKM 查詢相關資訊,用 RAG 來生成最終答案回應使用者。
當我搞懂這一切後,我才發覺 RAG 不應該是一套 “系統”,或是 “產品” 才對,她更像是 design patterns 那樣的設計模式,告訴你 AI 的知識檢索該怎麼做。RAG 終究需要做某種程度的客製化調整才會好用,因此你如果想做好 RAG,應該要有對應的技能,也要對你要檢索的內容,跟怎麼被查詢的方式有所掌握。最後你手邊應該要有一些你掌握度高的工具箱,必要時能隨時拿出來應用。這時 SK, MSKM, 還有其他 No Code 的 AI APPs 平台,都會是你的好幫手。
Demo:
Day 7, MSKM 與其他系統的整合應用
Link: FB POST
前面聊了很多 function calling 的應用,但是主要的 demo 方式都是透過 SK + Plugins.
實際上 LLM 的 function calling 能力有很多種不同管道都能使用的,按照不同的 LLM 應用程式來區分,有這些用法:
- 透過 Chat GPT (plus): 我在部落格文章, 還有 DevOpsDays Taipei 2024 介紹的是用 GPTs + Custom Action ( 透過 OpenAPI Specs + OAuth )
- 透過 No Code Platform: 我在 .NET Conf 2024 介紹的是用 Dify + Custom Tools ( 也是透過 OpenAPI Specs )
- 透過 Claude Desktop 等支援 MCP 的 Host: 這次會示範用 ModelContextProtocol 官方的 csharp-sdk, 將 MSKM 封裝成 MCPServer 使用
- 自己 coding, 透過 Semantic Kernel 將 MSKM 掛上 Kernel, 讓 LLM 來驅動並且進行本地端的 (Native) Function Calling
這些方式,背後運作的流程其實都一樣。你都需要在一開始告知 LLM 有哪些 function 可以使用 (說明規格,參數)。而 LLM 在對話過程中會推論要完成任務需要依賴那些 function, 藉著回應這些 function calling 的要求跟取得的回應, 來逐步完成任務。而這些不同的工具跟手段,說穿了只是用不同的方式在跟 LLM 溝通而已。
攤開來看,每種方式都巧妙地提供了兩件事:
- 告知 LLM 可用的 function specs
- Host 能有統一的方式代替 LLM 來執行指定的 function 並回傳 function result
回頭看看, OpenAPI Spec ( swagger ), 不就是用靜態檔案 ( json / yaml ) 來做到第一件事嗎? 知道規格後寫個通用的 Http Client 來呼叫也不是難事。這種作法,Chat GPT, 跟 Semantic Kernel 都支援 ( SK 支援直接注入 Swagger ) 藉著這次機會,我也研究了一下 MCP 這標準規範,他用實體通訊協定的作法,規範了這些操作:
- initialize
- noticication
- tools/list, tools/invoke
- resources/list, …
- prompts/list, …
而這 protocol, 內建支援兩種通訊方式, 一個是 stdio, 另一個是 http ( based on SSE, server side event, 單向的串流機制 )。這樣的設計,讓你可以用任何語言, 任何平台, 任何通訊方式, 來跟 LLM 進行通訊。所以也有人說 MCP 就是 AI 的 USB-C 也不為過。這次的主題,我最後就 demo 一下 MCP 官方的 csharp-sdk 來實作 MCPserver, 整合 Claude Desktop 跟 MSKM 來做 RAG 的應用…
不過,只要你要 live demo 就會有魔咒… XDD, 這次的 demo 有兩個地方要注意:
- MSKM 官方 docker image 請退版退到 0.96.x, 2025/02 release 的版本重寫過 chunking 的程式碼, 按照 token 將內容分段, 結果中文的部分沒處理好, 會變成 “晶晶體” XDD (會有疊字)。我已經發了 issue, 不過還沒解決的樣子…
- MCP/csharp-sdk 也是, 回應的 json-rpc 包含中文的 json 資料, 直接讀取沒問題, 但是 Cloud Desktop 似乎無法很好的處理帶中文字的 json data, 必須將編碼轉為 /u1234/u1234 這樣的方式才能動… 同樣的我也發 issue 了,這次 demo 我先自己 build sdk, 手動換掉 JsonSerializationOption 後暫時能解決, 各位可以等官方 SDK 的修正…
我會展示直接用 console + stdio 來操作 MCP server, 讓大家了解通訊過程,也會真的拿 Claude Desktop 來示範, 實際使用 RAG 的感受。
完整的 demo 請直接看影片,我這邊放截圖給大家搶鮮看:
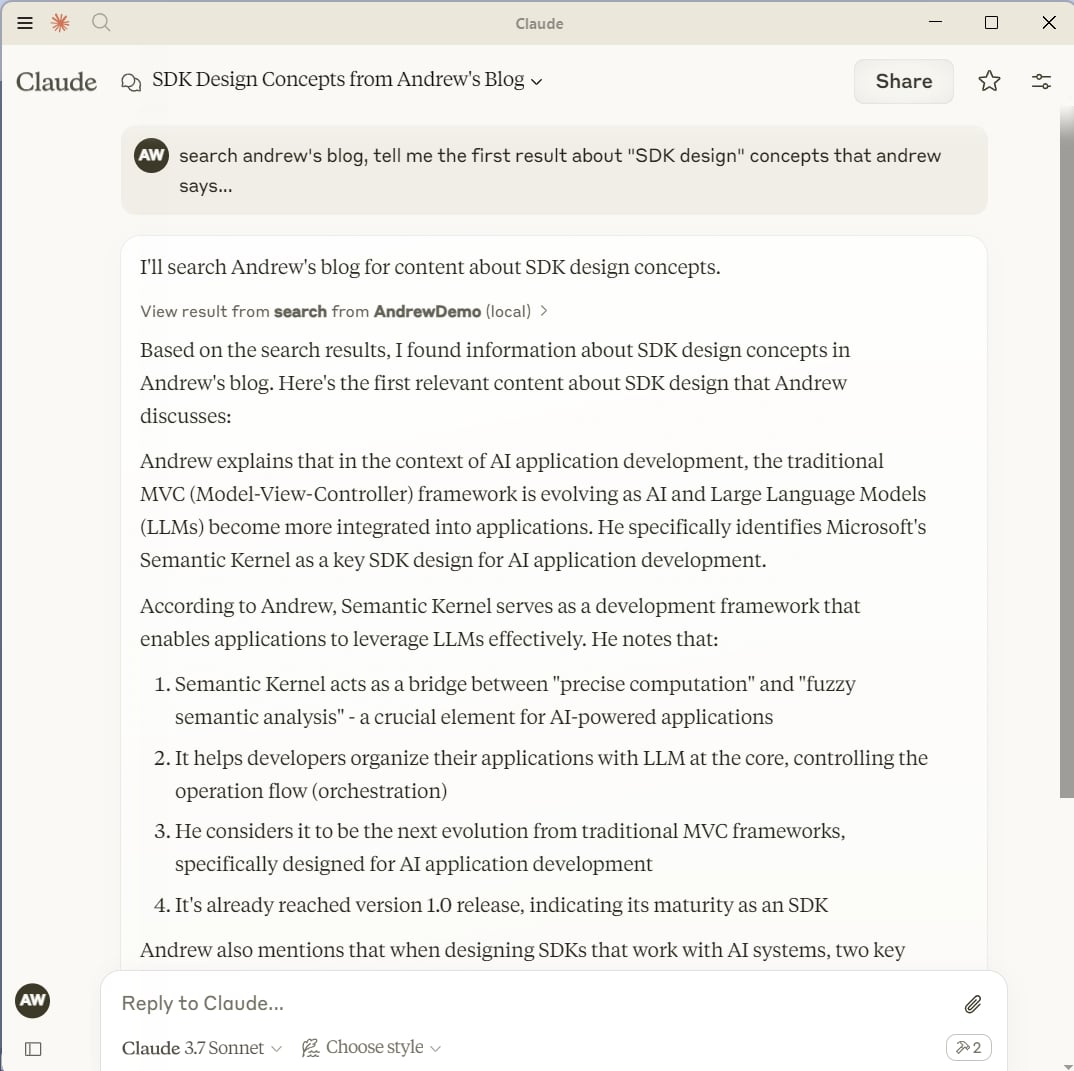 MSKM MCPServer 直接掛上 Claude Desktop, 讓 LLM 直接搜尋我的部落格資訊的示範
MSKM MCPServer 直接掛上 Claude Desktop, 讓 LLM 直接搜尋我的部落格資訊的示範
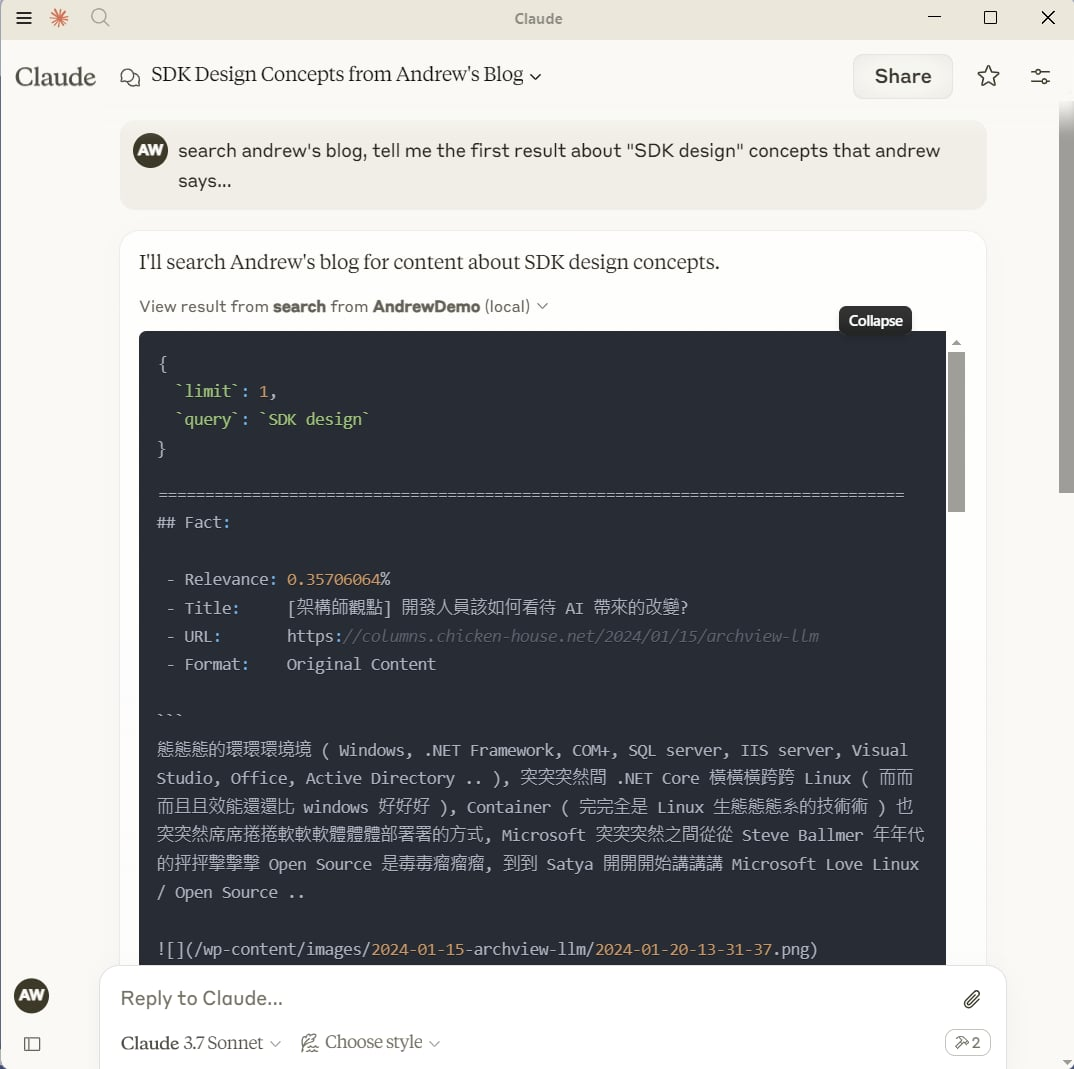 點開 Claude Desktop 呼叫 MCPServer 的過程,可以看到 MCPServer 從 MSKM 抓了哪些資訊餵給 LLM
點開 Claude Desktop 呼叫 MCPServer 的過程,可以看到 MCPServer 從 MSKM 抓了哪些資訊餵給 LLM
Demo:
MCP command(s):
{"method":"initialize","params":{"protocolVersion":"2024-11-05","capabilities":{},"clientInfo":{"name":"claude-ai","version":"0.1.0"}},"jsonrpc":"2.0","id":0}
{"method":"notifications/initialized","jsonrpc":"2.0"}
{"method":"resources/list","params":{},"jsonrpc":"2.0","id":1}
{"method":"tools/list","params":{},"jsonrpc":"2.0","id":2}
{"method":"tools/call","params":{"name":"search","arguments":{"query":"SDK design","limit":3}},"jsonrpc":"2.0","id":9}
Sample Claude Prompt:
search andrew's blog, tell me about "SDK design" concepts that andrew says...
in traditional chinese, and give me the source URL that you referenced from.
Day 8, 土炮 Function Calling
Link: FB POST
前天直播的時候, 在 zoom chat 看到一段話, 不過直播當下沒辦法分神去回應那些訊息… 事後想起來,我就補了 #8 來聊聊這題吧。聊天室是這樣講的:
某些 MCP Client 有支援 Deepseek r1,但是 Deepseek r1 並沒有支援 function calling
他們會是怎麼實現的@@? 好好奇
其實,只要模型本身的推理能力夠強,支不支援 function calling 只是封裝的 API 問題而已,認真要土炮,懂得原理的還是變得出來的… 我在 .NET Conf 2024 有示範這件事耶,只是當時只有 40min,根本沒辦法好好的講這題,我猜當下也沒多少人聽得懂我要表達的意思吧…
不過,直播當天我有好好地交代這個案例 (我特地把 function calling 整個過程的 Http Traffic 都 Dump 出來給大家看過程)。在 OpenAI Chat Completion API 替所有的訊息定義了幾種角色 (role), 常見的有這三個:
- system ( 用作 system prompt, 規範整個對話層級用的 prompt )
- user ( 由使用者端直接發出的訊息 )
- assistant ( 由 LLM 端發出, 給 user 閱讀的訊息 )
而加上了 function calling, 訊息結構也擴充了。除了 request payload 多了一段 tools 的定義之外,訊息也多了 tools 溝通專用的模式:
- assistant ( +tool_calls , 由 LLM 端發出, 指示需要調用的 tool 資訊 )
- tool ( 由 tool 執行後回應的訊息內容 )
其實抽象化之後,所謂的 Function Calling,只有三個要點:
- 要先定義好有哪些 tools 可以給 LLM 使用
- 對話就變成三方對話,LLM 要區別 user 以及 tools 的對話
- LLM 要生成該使用哪個 tool, 以及使用 tool 必要的參數
而 Chat Completion API, 則只是把這三個要點,精確的定義成 API / Message 的格式定義而已。想像成你是老闆 (role: user),旁邊有幫他辦事的秘書 (role: tool),老闆的行事曆控制全掌握在秘書手上,因此管家 (role: assistant) 要替老闆安排活動的話,應該聽完老闆要求,私下跟祕書協調後,最後回報老闆任務完成。
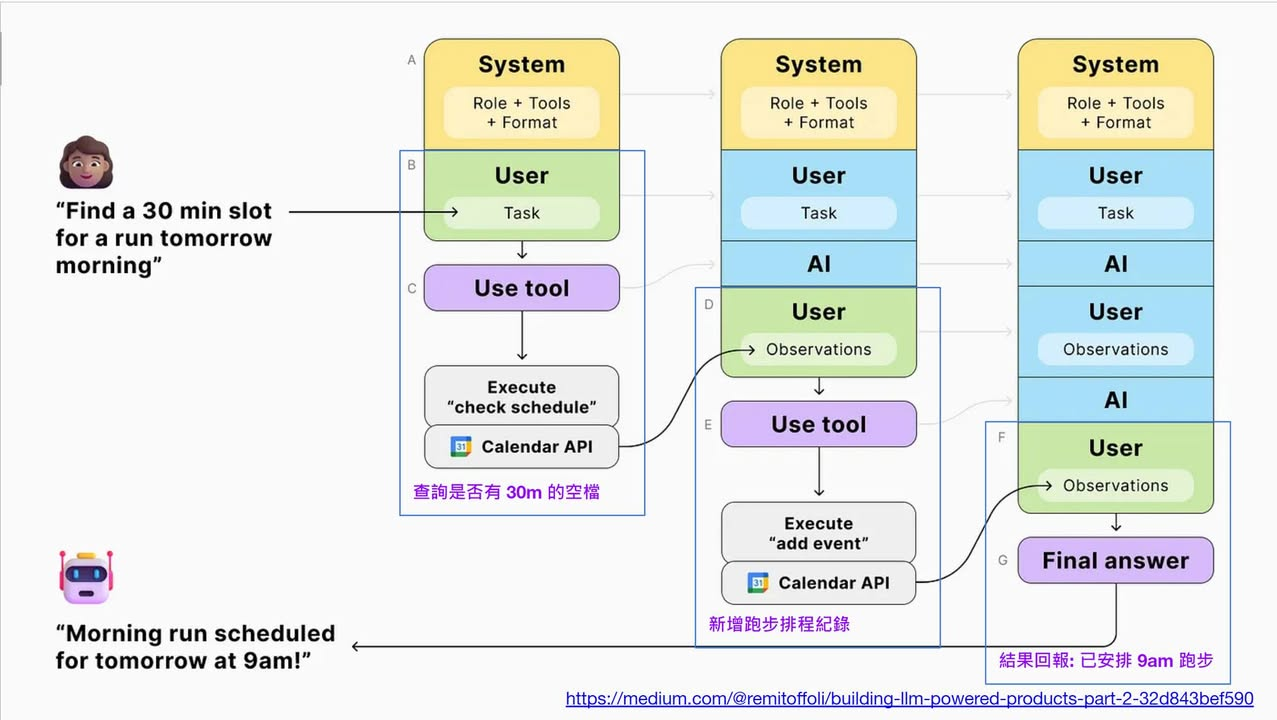
上圖 (圖1) 是案例,直播時候已經說明過了。

圖二則是土炮的 system prompt, 我用白話文, 自己定義了兩個角色,要 LLM 用不同的前置詞來區別 LLM 是要跟誰對話。如果訊息最前面是 “安德魯大人您好” ,就代表這句話是給我看的。如果訊息最前面是 “請執行指令”,則代表這是給秘書看的訊息。
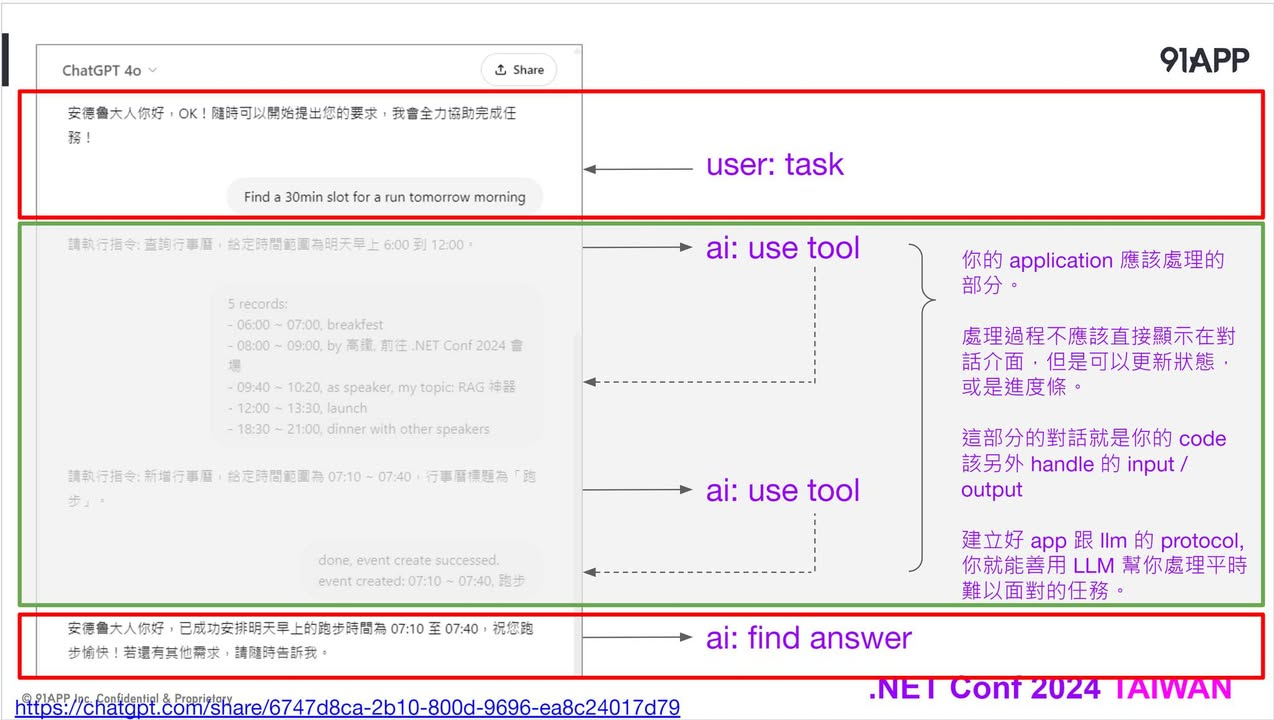
對話原則 setup 好了之後,對話過程就是圖三 了。你只要眼不見為淨,忽略掉中間灰色不是跟我對話的區段,其實整個過程就通了。如果你要在不支援 Function Calling 的 LLM 土炮 Function Calling 功能,只要用 Chat Completion API 照順序呼叫,並且由你的 Application 攔截這些 “請執行指令” 開頭的訊息就夠了。
每次我在說明這個例子,當下就覺得很羞恥.. (我是多期待大家叫我 “安德魯大人您好” 啊啊啊啊…) XDD,不過,這個例子我原封不動貼在 Chat GPT 上,還真的能夠正常運作,當然正規場合你別這麼土炮,乖乖地用支援 Function Calling 的模型,搭配 Semantic Kernel 這種能幫你處理 Function Calling 的框架就好。貼在 Chat GPT 上,只是為了讓大家理解背後的通訊過程而已。
懶得自己嘗試的,我附上我自己測試用的 對話紀錄
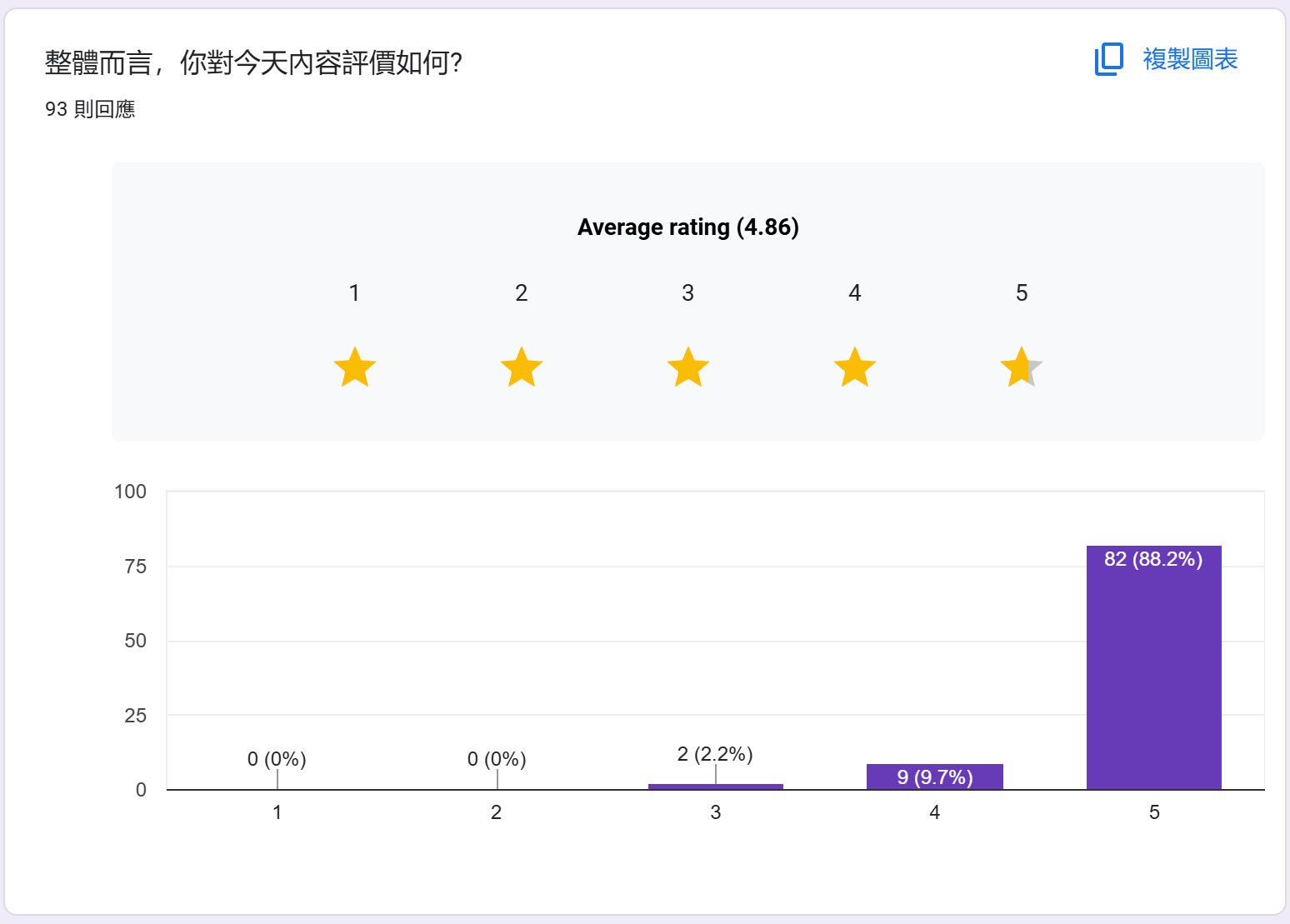
問券回饋 (統計至 2025/06/22)
感謝大家熱烈的回應,這次直播 + 事後觀看錄影的朋友們,我總共回收了 93 份問券。問券我會一直開著喔,如果你看完 YouTube 的錄影,仍然可以繼續填問券讓我知道你的想法。
截至今天 (2025/06/22),我統計一下問券的結果,有些有趣的觀察我最後再聊..
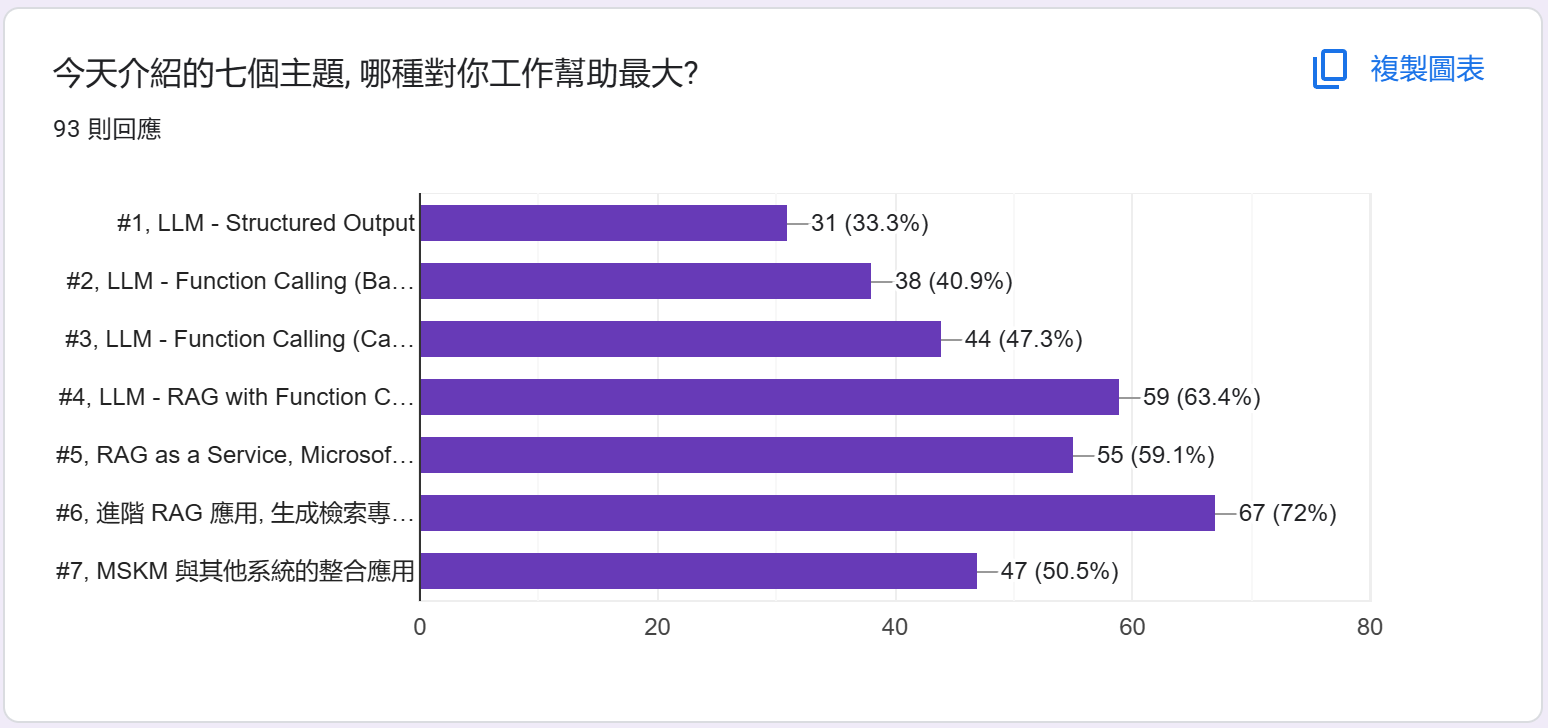
統計: 哪個主題對你工作幫助最大?
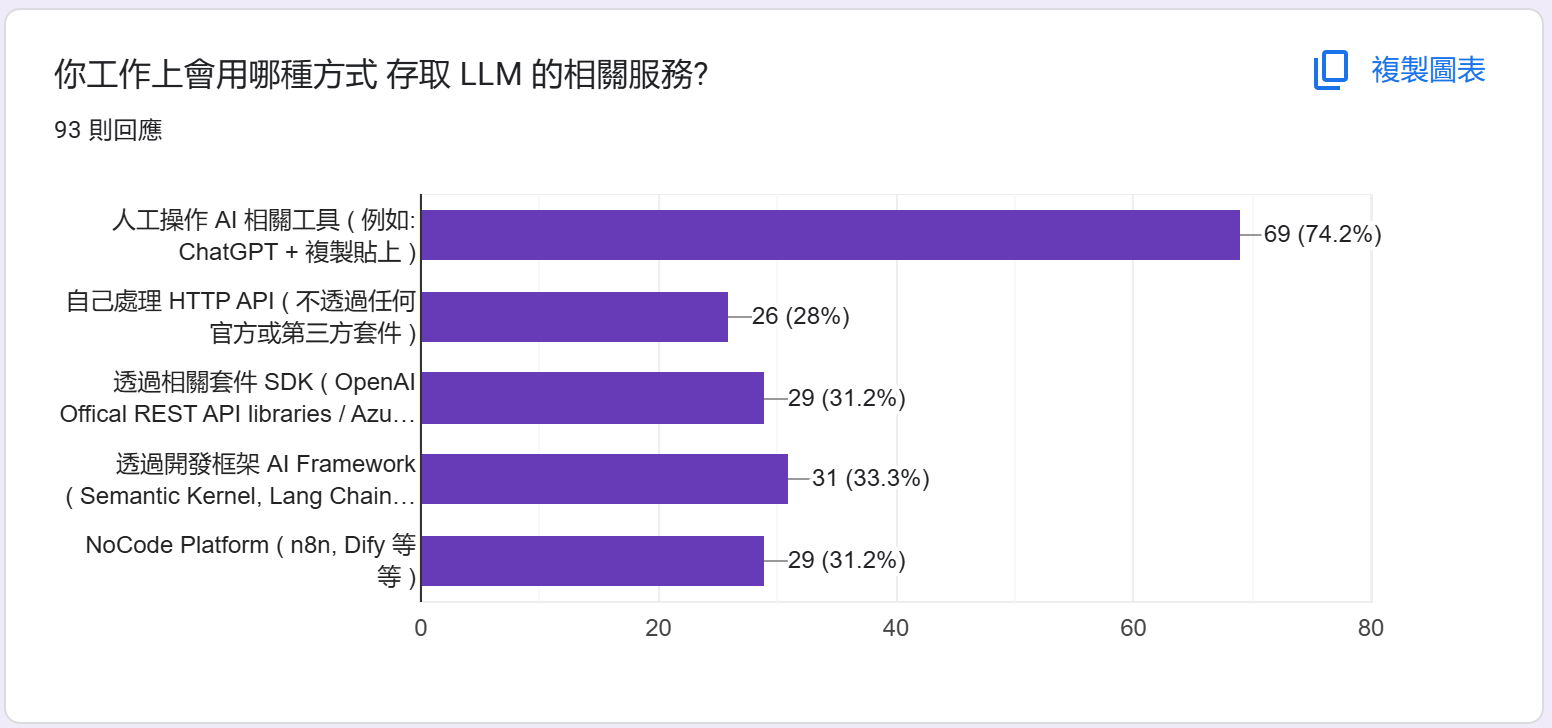
統計: 會用哪種方式存取 LLM?
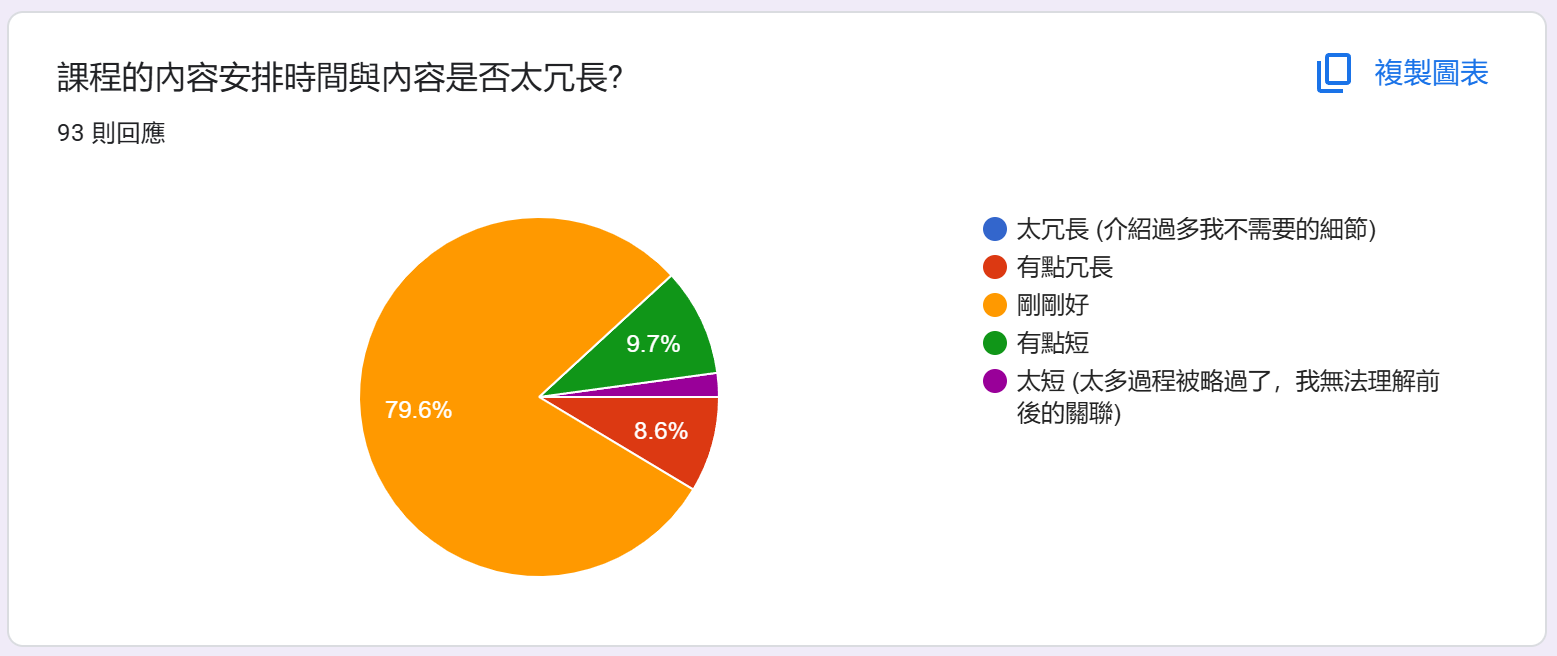
統計: 內容安排時間是否太冗長?
統計: 你覺得最有收穫的部分
原文照貼,我只是單純的分類一下:
架構介紹, 觀念說明:
整體的架構說明
實際看大神演示
可以親眼看到 Andrew 老師示範的程式碼,相當有幫助!
循序漸進的了解底層的原理,一直到進階的整合應用。看官方的文件跟sample還是很多不太懂,導致一知半解
原來AI還有這種用法 而且可以理解底層運作方式
basic introduction to function calls and extend to MCP,extract data from context then through invoke API interaction with user request and response
實戰操作的心得非常有幫助,建構多面向的索引資料很有啟發性
都蠻有收穫的,原本只是大概模糊知道一些,經過課程介紹後整個都梳理清楚了
認證了自己研究的內容,是否為正確的方向
蠻多都很重要的,
有跟到最後大絕招 混和式應用
了解背後的原理
都很實用
深入淺出,條理分明
了解LLM底層邏輯
LLM 基本技巧 ( json, function calling ):
function calling auto
Function Calling、Microsoft Kernel Memory
Function calling 給我最大的啟發,因為原本無法想像其背後的request/response 邏輯。謝謝Andrew 老師!
更加了解 Function Calling 的互動過程, 才明白為什麼文章說 context 互動過程會越來越大
Function calling到最後的部分都非常的有收穫
LLM function call
Json Sechema
了解 function call
補齊自己還沒 Study 的 function calling request / reponse format & 更了解 Kernel Memory 的用途 !
json schema對LLM的重要性,比起單純給予範例好像更為重要
使用JSON Schema, RAG
RAG Function Calling 範例說明
Function Calling
RAG 進階處理、MCP、Function Calling
JSON schema 轉換、長文章的 RAG 技巧
LLM 的運作模式
對 LLM function call 的底層有更清晰的認知
開發框架 / Semantic Kernel / SDK / API / MCP 相關:
整合AI開發框架,和RAG的資料處理作法
SK + Kernel Memory
看到開發框架的方便性,還有切部落格文章的實際應用
Semantic Kernel 的各種用法,以及微軟的文件有坑
有底層 API 跟 SDK 的對照, 更了解 SDK 實作方式
微軟新推出MCP
MCP概念
RAG / Kernel Memory 相關:
RAG
進階 RAG 應用, 生成檢索專用的資訊
RAG 運作原理
切片的那塊處理超棒的
RAG的落地運用
不要傻傻的將pdf塞vector資料庫
Kernel Memory 的介紹。之前剛推出時有稍微看官方文件,但不是很懂實際的架構,今天的解說就很清楚了
幫文章建立各個面向的chunk,更容易讓 LLM 能更精準取得趨近我們要的答案
安德魯優化BLOG切RAG的做法
利用LLM生成檢索專用的資訊,掛回提高精度
了解一些RAG的問題
RAG as a Service, Microsoft Kernel Memory
Microsoft Kernel Memory 的介紹
RAG
Kernel memory的細節
RAG Chunk method
kernel memory client
5, 6, 7三個主題
統計: 你覺得沒有幫助的部分?
單純移除 none 的部分,其餘保留:
都很有幫助
開什麼玩笑怎麼有這種沒答案的問題
有幫助
每個部分都有獲得知識點
沒有誒
我想不出來!
都有幫助
我不會.net(我看的是解決問題和提出問題思路
不清楚要怎麼餵大量資料
Andrew 老師漸進式的解說,其實整個演講的每個段落都是後面的鋪陳,並沒覺得哪斷沒幫助或沒價值
chunking 的部分挺有趣
沒有~滿硬的一堂課
都很實用
沒有,都很實用
統計: 對於後續的系列課程建議?
原文照貼,單純移除 none, 無 這類回覆
更進階的各種應用
介紹 MCP 的運作原理及如何寫 MCP 服務
實作產業領域的AI知識庫
AI的開發flow還有plugin整合的邏輯跟最常使用的restful api還有很多DDD或是code設計的概念上有很多的不同,如何建立一個好的思維跟習慣來開發,是一個CRUD工程師很需要學習的事。很像你原本是東方的武功流派,突然要學習改用西方的格鬥術
可以的話 請再多分享類似課程
Microsoft.Extension.AI這個東西可能可以考慮加一下(?
後續想要知道更多關於 MCP 的應用,以及在 AI 的時代,關於事件驅動的概念可以如何被整合進到我們的 AI 應用程式
更多有關 Net Core 搭配 MCP 搭配 NoCode,新手上手
實作工作坊
可以加入AgentGroup 跟Process
有機會多直播
結合電商平台的應用
有時候可能講解的節奏可以再慢一點點
MCP Serve Client 相關應用
多開幾場
若可以的話,多一些商務應用情境
很有想像空間 👍
後有後續嗎? 有機會想看看之後 SemanticKernal 是否會與 MCP 做最大化的結合,能夠有更實用的 Agent 模式能夠作為更大威力的 plugin 來使用,如果有這一天的到來,相信 Andrew 老師走在技術的前緣,應該會有更多體會能跟大家做分享。
希望還是可以有簡報,感謝講師無私奉獻
向量的部分 可以再講清楚一點點
MCP和 MSKM的抉擇介紹
多點討論與互動
想知道更多實際商用/應用案例
可加入更多實際運用案例
加入多模態的應用
如果可以,跪求影片回放,今天太晚下班,前面沒有參與到QQ
講Code的部分有些太快了
也不算是建議,只是很擔心這種內容回需要不斷隨著產品一直更新,感覺很累 😅
多多分享實務經驗
覺得投影片還是需要做不然容易在講話之中迷失目前的話題
是否有落地LLM 方案
感謝大神的分享,知識非常豐富,大腦 CPU 負荷過重
能有工作上實際工作流程的應用範例。
統計: 你會如何介紹這門課?
原文照貼, 單純移除 “會不會推薦” 的回應,保留有額外意見的部分:
如果覺得現有的 AI 工具不好用,想要擴展 AI 用途與價值就來上這堂課吧 !
你不能不知道的 RAG - 入門篇
AI Agent 從開發到放棄
會分享。用.net 開發AI client,不輸!
觀念很清楚的課程
不用介紹 來就對了
會分享,我會說寫C#的人想要趕上AI的潮流必上,C#寫AI不輸python
RAG 神器 - Microsoft Kernel Memory 與 Semantic Kernel 的整合應用
如何更精準的使用RAG
我覺得可以讓有想學的可以聽聽
會, 了解 llm 應用服務的設計原理
會,詳細介紹了 SK 與 Kernal Memory 以及 MCP
會,一個會從底層講到SK的應用,保證受益良多!
當然會分享。進入 AI Application 的第一堂課!
學習llm function call原理
會,LLM RAF紮實的運作
LLM 應用入門簡介 - 使用 MS KernelMemory, Semantic Kernel
歡迎來上這整個前世今生
會,RD關鍵字搜集SQL。
RAG 神器
我已經介紹給很多朋友了,但是我不太會講哈哈,我只能說這是很讚的課你們一定要看看
與RAG共舞
如何在地端整合AI運用開發,蠻推薦的!
如何使用打造給AI使用的API
從底層原理實務應用
SK + Kernel Memory
會,Microsoft Kernel Memory 與 Semantic Kernel 的整合應用
會,LLM跟RAG應用的相關應用介紹
會,LLM in application
會,安德魯大神AI開發應用
會喔,今天 Andrew 老師很好的演示了理解 RAG 的最佳實作課程
是,有 Andrew Wu 的分享就去聽 !
要了解正確整合LLM的方法
會喔! 我會分享給同樣對RAG有興趣的同事
Memory Kernal 入門
朋友多半還是想用 dify 之類的,或是只要丟資料&視覺化拉流程&Saas型有團公司維護的工具
超級實用!
內容豐富
會, 只是對我而言, 內容有難度, 不知該如何跟其人介紹
會, 太重要了
從這堂講座中,可以知道工程師在開發 LLM 應用時,需要注意的工程實務
會,認識RAG應用做法
大推部落格文章怎麼轉換RAG的經驗技巧
如何整合大語言模型 - Semantic Kernel實戰演練
會~有需要接觸 RAG 的不管用甚麼方式, 看過都會有收穫.
會。RAG進階課程
會,Kernel Memory 與 Semantic Kernel 的整合應用,運用LLM介入程式邏輯處理實際問題
使用Net整合LLM開發應用程式
會,會說明介紹的仔細可以學習到許多事情
會,適合已經知道AI、ChatGPT但對於semantic kernel不了解的人
會,但是要確認對方是開發者。有點難介紹,感覺把FB的文章附上就可以讓其他人知道內容的豐富度!!
自炊 NotebookLLM/AI Agent
會、LLM應用實戰大招
是,很有深度且收穫良多
會,是一門讓人了解實務上 LLM 整合方式、進階 RAG 應用等技術的好課
AI 時代,必上的一門課程。
RAG 神器
會 可以增加對AI的領會
是個初步認識SK的好課程
大概了解目前可以如何串接sdk&llm
如何強化 LLM 的應用
會。讓你更了解 function call 與 MCP 的底層觀念
會。深入淺出Agentic
從基礎開始打造RAG系統
對基礎很有幫助
會 推薦AI 相關工作者都應學習
目前尚不會,尚待多加學習了解!
是,了解AI底層邏輯的好課程
統計: 整體評分