![]()
最近,起了一個小型的 Side Project, 想說先前研究 “安德魯小舖”,一年半以前就已經做的到用對話的方式讓 AI 替我執行對應的 API 的應用了,現在這些應用更成熟了 (每間大廠都在推各種 Agent 的解決方案..),某天就突發奇想:
AI 都有自動執行 API 的能力了,那能不能拿來簡化工程師要寫 script 來做 API 自動化測試的任務?
會有這篇,當然是試出了一些成果了,就是我前幾天在 FB 發的這篇。這篇就是要聊聊 FB 沒辦法提及的實作過程心得,有興趣的請繼續往下看。在開始之前,複習一下我貼在 FB 的 貼文 :
最近起了一個 side project, 我在嘗試透過 AI 能否簡化 / 自動化 API 測試的需求? 結果可行,雖然只是個 PoC 的 side project, 還是挺令人興奮的 😃
我拿我之前為了 “安德魯小舖” 寫的購物車 API 當範例,用 ChatGPT 產了主要情境的正反測試案例 (共 15 個,只描述商業情境,沒有指定精確的 API 參數) 當作腳本,丟給我寫的 Test Runner, 結果不負眾望, Test Runner 順利地按照腳本呼叫了 API,也給了我完整的測試結果報告..
突然覺得好虛榮啊,出一張嘴就有人幫我把測試跑完 (包含從情境自己決定該打哪個 API,該生成什麼參數) + 雙手遞上報告… XD, 雖然還有很多外圍的問題待解決, 離正式上場還有好一段距離, 不過主要環節打通了還是挺開心的。接下來分享一下過程跟心得..
最初有這想法,來自於當今 LLM 都有很好的 Function Calling 的能力, 為何不拿這能力來面對自動化 API 測試呢? 複雜如 Agent 的應用都能面對了,API 自動化測試相對來說是小事吧~ 果不其然,順利完成。其實這一切都如預期啊,本質來說,讓 LLM 按照測試案例執行 API,其實就跟我當時開發 “安德魯小舖” 按照對話完成購物 (也是呼叫 API) 完全是同一件事情,只是敘事角度換了個方式而已.. 觀念一轉,反倒有這結果是理所當然的…
只是,API 要做到 AI Ready,本身還是有一點門檻的 (都在設計,不在技術方面)。真正有挑戰的,會在這些還沒滿足 AI Ready 的 API 該怎麼自動化執行測試吧… (這些議題,其實都在我去年分享的 “從 API First 到 AI First“,以及前年的 “API First Workshop”,”API First 的開發策略” 這幾場演講)
最後,貼個執行結果給大家體會一下,實作方式我整理一下再分享開發過程… Test Runner 是用 Microsoft Semantic Kernel 開發的,就是拿 Plugins 來簡化 Function Calling 操作而已。關鍵的部分大概 50 行以內就搞定了,敬請期待 😀

另外,也感謝董大偉老師,他在他經營的 FB 粉專 ‧NET Walker 大內行者 也發文介紹: 🧠「出一張嘴,測試自己會跑、報告自己會生」
這不再是幻想,而是正在發生的事。
好友 安德魯的部落格 最近實作了一個超有趣的 side project:讓 LLM 自動化完成 API 測試。從生成測試腳本、決定呼叫哪個 API、組出對應參數,到最後輸出報告,都用 AI 搞定。
當我看到這段描述時,腦中突然浮現 Sam Altman 去年底那句話:「到 2025 年底,軟體工程會變得不一樣。」
而我覺得 –未來的 DevOps,也會變得很不一樣。
從 coding、code review、unit test / test case generation 一直到 incident analysis,AI 參與的程度正在快速上升。雖然還沒到「全自動」的程度,但「逐漸全面的自動化」已經悄悄的來了。
這波浪潮對工程師來說,是一個新的養成議題。
未來不是比誰程式寫得快,而是比誰「更懂如何引導 AI 把事做好」。
💬 原文有範例、有思路、有未來,推薦大家看看 👇

以上簡介跟回顧完畢,開始進入正題 :D
1, 構想: 拿 Tool Use 來做自動化測試
我心裡的理想,就如同標題一樣,是從 “Intent” 到 “Assertion” 的過程都讓 AI 代勞的可行性。什麼是 Intent? 就是你的意圖。測試最重要的核心,是你要掌握 “該測什麼” 你才放心這軟體的行為符合你預期,這是 “意圖”。而 “Assertion” 一般翻作 “斷言”,其實寫過測試的都知道 Assert 是幹嘛的,簡單的說就是判斷當下的狀況是否符合你的預期。
然而在過去,只靠 “意圖” 是沒辦法直接執行的。過去電腦很笨,你必須給他很明確的指令,例如在哪個地方按按鈕,哪個地方會出現 “OK” 的字樣才代表成功… blah blah, 這一連串翻譯的過程,都是人工在處理,講白話就是人工寫測試文件,跟人工來執行測試…。經過這一連串的高度人力密集作業之後,你會得到一份測試報告,告訴你測試結果是否符合預期。
思考了 “人” 怎麼靠 “意圖” 就能執行測試? 人的腦袋裡勢必事先已經知道 UI 怎麼操作,或是有哪些 API 可以使用,有了這些資訊之後,人腦就有能力把 “意圖” 翻譯成 “行動”,接著就能逐步操作完成目的了。這一連串的處理,其實就是 LLM 的 Function Calling / Tool Use 能力。我的想法很單純,既然這兩年技術的發展已經成熟了 (我指 Function Calling),那我是否有機會用這能力解決從 “Intent” 到 “Assertion” 這段過程?
我的企圖其實不只是 “自動化” 這段過程而已,而是這些推論能力,能否釋放過去這些需要大量人力投入的文書處理任務? 就如同 vibe coding 解放了很多工程師寫著無聊的 code 一樣,這次我想解放的是撰寫詳細測試文件 + 按照文件執行測試的苦差事。架構師的角色,是告訴大家這件事可不可行? 關鍵突破後,就能將之標準化 + 規模化,擴大推廣。所以我現在在做的就是驗證可行性,我目標擺在 PoC,而不是開發實際上線使用的工具 (因此一些非關鍵的細節我會直接略過)。
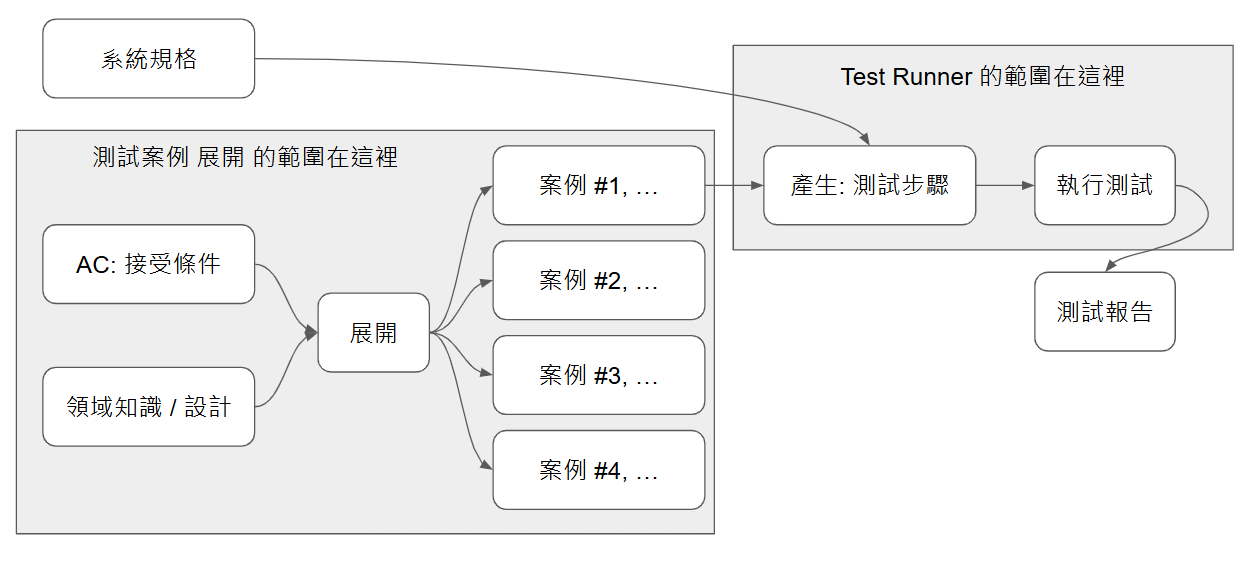
所以,回歸 “人” 怎麼做這件事的過程,大概關鍵資訊就這些:
- 你想要驗證什麼 (正規一點的說法是 AC, Acceptance Criteria)
- 領域知識 (這領域的重要觀念與流程)
- 系統的確切規格與設計 (UI 畫面與流程,或是 API Spec 與說明,呼叫範例等等)
按照我思考的順序,大致像這樣:
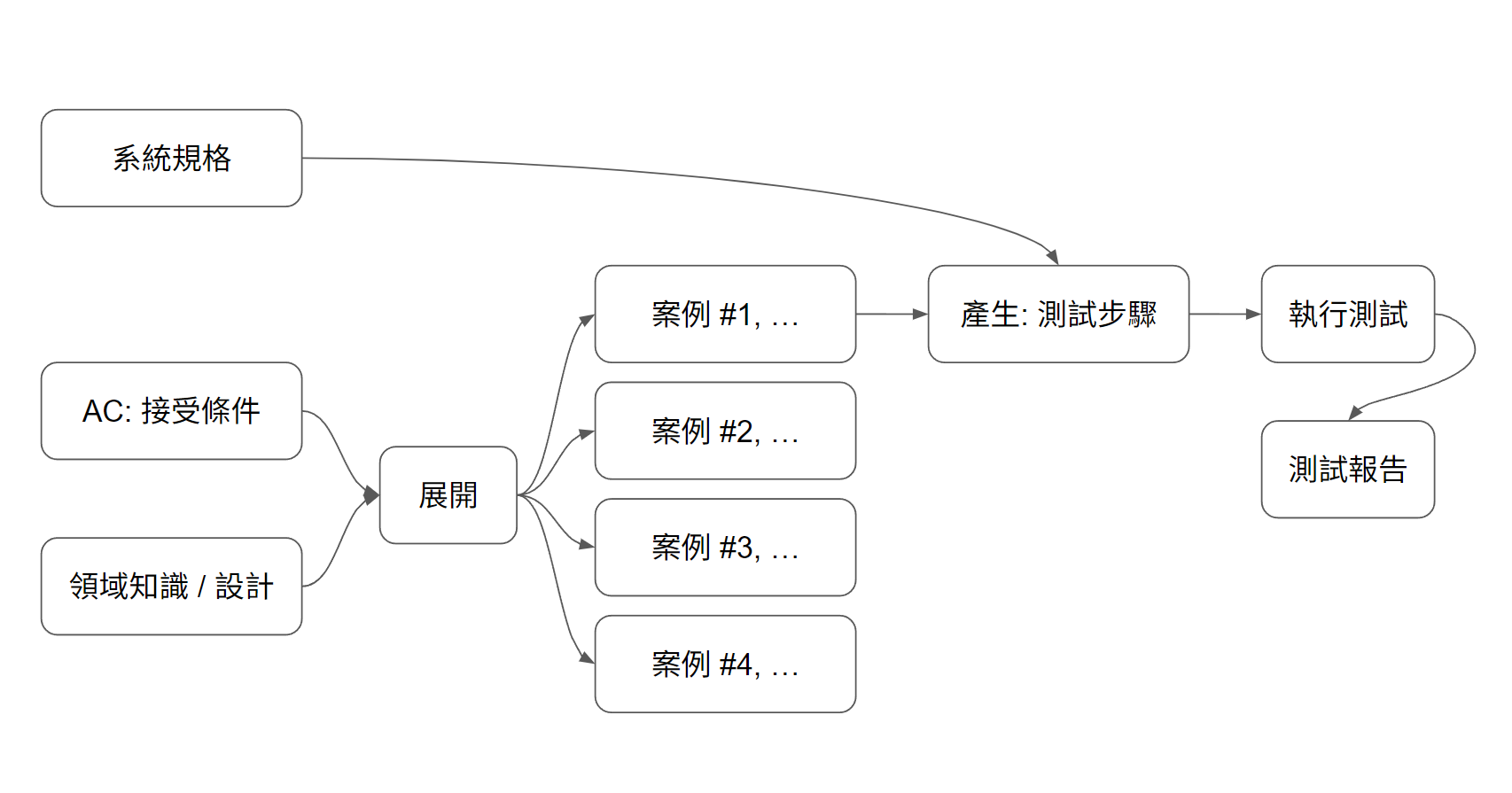
如果你心裡很清楚知道 AC 是什麼 (例如: 購物車的操作不得違背系統限制),加上領域知識 (例如: 購物車的設計,狀態圖,流程圖等等),這兩份資訊交給 ChatGPT,應該能展開一些案例清單。而這些案例,再搭配詳細的系統規格後,應該就能展開確定的執行步驟。
而這篇我專注的範圍 Test Runner,則是這個部分:
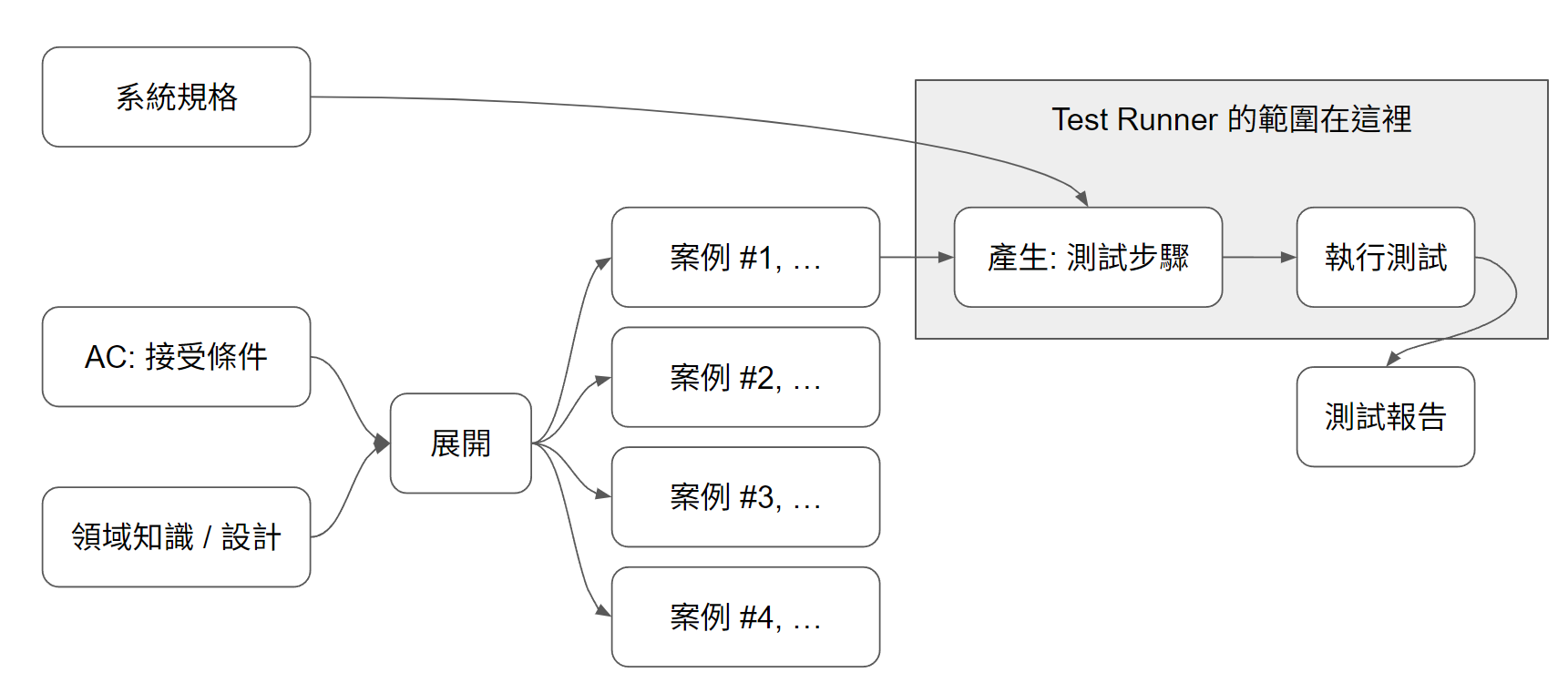
因此, 輸入就是展開過的測試案例 (不直接是 AC),而我期待的結果輸出就是測試報告。
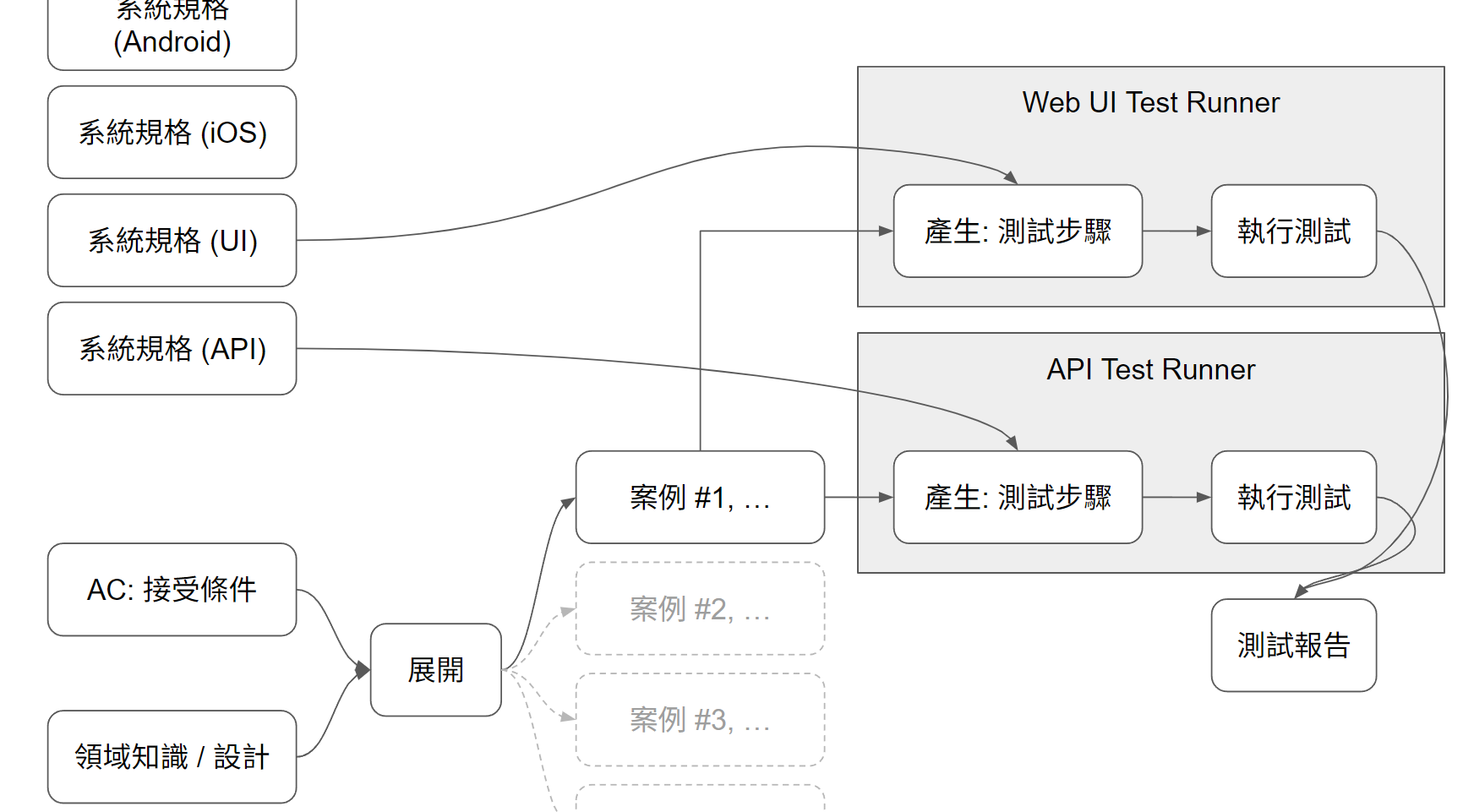
這圖的結構,請好好思考,因為我整個想法 (包括後面想寫的幾篇),都會從這張圖延伸出去..。能有限在這篇,受惠於目前 AI 已經有夠好的 Function Calling 能力了。如果 AI 的 UI 操作能力也能跟上 (例如 Browser Use, Computer Use 等等技術) 變得更精準,成本更低的話,這樣的方法跟測試案例,搭配不同的規格 ( UI 規格我不確定有哪些標準規範 ),但是原理相同,你能提供對等的規格跟 Test Runner,你就有機會用同樣的測試案例,分別執行 API / UI ( 可能還能分 Web, Android, iOS ) 的自動化測試…
試著幻想一下未來的可能性,一份合理的 domain 層級測試案例, 經過不同的介面規格 + (AI) Test Runner 擴展,能夠對不同介面進行相同商業規則的驗證 (我目前的能力只能實現 API 的範圍):
2, 實作: 準備測試案例 (domain)
開始實作前,先來把輸入資料準備好吧。怎麼產生的我之後再說,但是我先把我準備好的測試案例貼出來:
_
Given:
- 測試前請清空購物車
- 指定測試商品: 可口可樂
When:
- step 1, 嘗試加入 11 件指定商品
- step 2, 檢查購物車內容
Then:
- 執行 step 1 時,伺服器應回傳 400 Bad Request(數量超出 10)
- step 2 查詢結果,購物車應該是空的
_
以零售業來說,像這樣內容的情境,就是我所謂 domain 層級的測試案例。通常都不會太複雜,也不會有太多操作或技術細節,主要就是敘述什麼樣的抽象流程,會得到甚麼結果而已。
我在寫這案例有個前提,就是購物車的設計應該要有指定商品上限 10 件的限制 (我自己臨時加的要求,線上執行的 API 並不支援這約束,我預期這測試應該不會通過)。我期待的結果是,不管你怎麼操作,過程中都要隨時遵守這個約束限制。而測試案例就該在這層級上描述各種可能的行為,驗證過程中是否真的符合約束限制。
這個案例是多個案例中的一個,我嘗試在一個空的購物車 (起始條件) 加入 11 件指定商品,測試案例預期 API 在這步驟會踩到限制,而被系統拒絕,並且整批 11 件商品不該加入購物車。
要寫出好的案例,你需要的是 “知道該測試什麼”。妳可以讓 AI 幫你列舉所有案例,這完全沒問題,但是你要有能力 Review 這些列舉結果對不對。我在這邊刻意排除跟特定設計規格相關的資訊,就是希望未來 UI / API 的規格異動時,盡量不要影響到這段 (除非你顛覆了購物車的 “概念”)。這樣明確的區隔,有助於簡化案例的撰寫跟 Review,同時也跟實作規格無關,讓 Test Runner 在執行前再來合併規格跟案例。
這邊有一篇,敏捷三叔公的 文章,剛好就是我上面的想法。有需要的可以參考,想看看你只是在 “展開” 測試步驟,還是在思考 “該測什麼” ? 把適合給 Gen AI 做的事情盡快交出去,你可以負責更有價值的事情。
節錄文章第一段:
隨著 GenAI 工具(如 Copilot、Cursor、Windsurf)開始自動產生測試程式碼、修補 bug,許多工程師心中浮現熟悉的念頭:
「這不就是更高級的測試自動化工具嗎? 以後還需要懂測試的人嗎?」
這個問題不新,Selenium、JUnit、CI/CD 剛出現時,我們也曾問過: 「測試人員是不是會消失?」
結果如何? 沒消失,反而變得更重要——但角色徹底改變了。現在,GenAI 不會讓測試消失,反而暴露一個長期存在的核心問題:
我們從來沒有好好訓練工程師去思考「測什麼才有意義」。
3, 實作: 準備 API 的規格 (spec)
我這次使用的 API,我直接沿用前年底 (好快,已經一年半了) 研究 “安德魯小舖” 的時候,開發的 domain API, 對應的 Open API Spec (Swagger) 可以直接參考這邊:
- Andrew Shop API Spec (這 API 自從安德魯小舖上線後就再也沒改過了…)
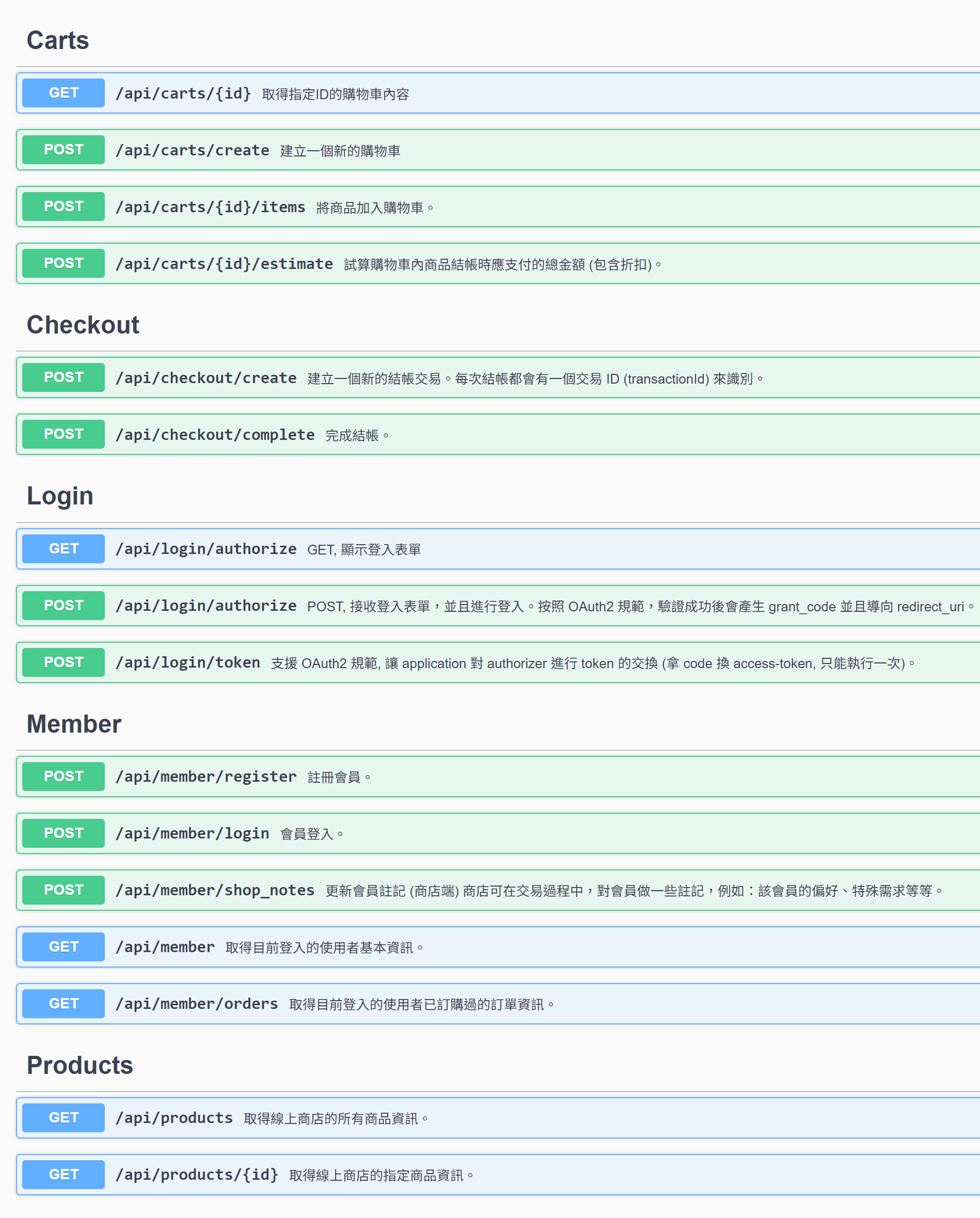
開始前,我先 “腦補” 我該怎麼做.. 這是我做事習慣,當我解析清楚我腦袋怎麼逐步拆解這問題時,下一步我就知道怎麼期待 AI 拆解這問題。因為我清楚拆解過程,我就能掌握 Prompt 到底該提醒 AI 該怎麼做。
按照案例的敘述,先看 Given :
Given:
- 測試前請清空購物車
- 指定測試商品: 可口可樂
我會用 “建立新購物車” 來替代 “清空購物車”。因為 API 沒有直接提供 EmptyCart() 這樣的 API,不這樣做的話,我恴列舉目前購物車內容,並且逐一清除。
另外有指定以下的案例,都用 “可口可樂” 來當作指定商品,因此看完 API Spec 後,我會用 “取得商品清單” 列舉所有商品後,從裡面挑出 “可口可樂”,並記下他的 ProductId 供後面 API 使用。因為我的 API 規格很陽春,並沒有 “搜尋” 的功能,唯一找到指定商品的管道就是這個..
因此,這步驟至少該呼叫這兩個 API:
POST /api/carts/create
GET /api/products
When 的步驟就容易得多,都有直接對應的 API:
When:
- step 1, 嘗試加入 11 件指定商品
- step 2, 檢查購物車內容
直接講結果了,應該這樣呼叫:
POST /api/carts/123/items
GET /api/carts/123
而 Then 的部分,應該單純判斷前面的結果,不需要額外呼叫 API 了,這部分就略過。
4, 實作: 挑選對應的技術來驗證
接下來,就要開始把這些東西湊在一起做成 牛丸 Test Runner 了…
我選擇做成 .NET Console Apps , 這樣最容易驗證, 很多人問我為何不做成 MCP ? 後面會提, 目的跟用法都不同, 而且還有技術障礙要克服,那些都是 “大規模推廣” 才會碰到的問題,我在 PoC 階段選擇先略過,先驗證我最在意的核心問題。
因此,我會用先前直播示範過的 Microsoft Semantic Kernel + Plugins 來實作 OpenAI Function Calling 機制的範例,來做這個 Test Runner. 如果你還不熟 Function Calling 的運作原理,也還不清楚 Semantic Kernel Plugins 是怎麼一回事,建議先去看一下三月份我跟保哥合辦的直播錄影:
- 簡介 Day2, LLM - Function Calling (Basic)
- 簡介 Day3, LLM - Function Calling (Case Study)
- 錄影: 簡介 .NET RAG 神器:Microsoft Kernel Memory 與 Semantic Kernel 的整合應用
- 問券
- Demo Code
4-1, 將 OpenApi 匯入成為 Kernel Plugin
在使用 Semantic Kernel 搭配支援 Tool Using 的模型時,你要交給 LLM 使用的 Tools 只要包成 Plugins 掛到 Kernel 就可以了。這邊要誇一下 Microsoft, 花了大工程 (我追過 source code, 真的是一大包, 衷心佩服那些能搞定複雜 Json Schema, Function Schema, OpenAPI Spec Schema 的工程師),直接做了內建的支援,可以把 OpenAPI Spec ( 就是 Swagger ) 轉成 Plugins, 讓這複雜的動作瞬間縮減到 10 行 code …
我貼一下這段 code :
var builder = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(
modelId: "o4-mini",
apiKey: OPENAI_APIKEY,
httpClient: HttpLogger.GetHttpClient(false));
var kernel = builder.Build();
// 將待測的 API ( via swagger ) 轉成 Plugin 加入到 kernel 中 ( 提供 AI 可用的 tool )
await kernel.ImportPluginFromOpenApiAsync(
pluginName: "andrew_shop",
uri: new Uri("https://andrewshopoauthdemo.azurewebsites.net/swagger/v1/swagger.json"),
executionParameters: new OpenApiFunctionExecutionParameters()
{
EnablePayloadNamespacing = true,
HttpClient = HttpLogger.GetHttpClient(true),
AuthCallback = (request, cancel) =>
{
var api_context = APIExecutionContextPlugin.GetContext();
request.Headers.Add($"Authorization", $"Bearer {userAccessToken}");
return Task.CompletedTask;
},
}
);
就是這段 Kernel.ImportPluginFromOpenApiAsync( ... ), 瞬間讓我省下額外把 16 個 API 重新轉成 KernelFunction 的苦工… 。Kernel 跟 Plugins 準備好之後,接著就是丟 Prompt 給 LLM 執行了。Kernel 為了順利回應 Prompt 的要求,會自己跟 LLM 溝通,判定何時該使用 Plugins 來完成任務。
4-2, 準備 Prompts
我準備了這段 Prompt, 按照順序共有這幾個 messages:
Message #1 (Role = System),
用最優先的 system prompt, 告訴 LLM 該如何處理這一串對話。我把處理 test case 的鐵律都寫在這段了。包含 Given / When / Then 的用意,以及不接受 LLM 自己猜測的 API 呼叫結果。這算是給 LLM 處理這段任務的最高處理原則 SOP
依照我給你的 test case 執行測試:
- Given: 執行測試的前置作業。進行測試前請先完成這些步驟。若 Given 的步驟執行失敗,請標記該測試 [無法執行]
- When: 測試步驟,請按照敘述執行,呼叫指定 API 並偵測回傳結果。若這些步驟無法完成,請標記該測試 [執行失敗], 並且附上失敗的原因說明。
- Then: 預期結果,請檢查這些步驟的執行結果是否符合預期。若這些步驟無法完成,請標記該測試 [測試不過], 並且附上不符合預期的原因說明。如果測試符合預期結果,請標記該測試 [測試通過]
所有標示 api 的 request / response 內容, 請勿直接生成, 或是啟用任何 cache 機制替代直接呼叫 api. 我只接受真正呼叫 api 取得的 response.
Message #2 (Role = User),
這段比較單純,就把我前面貼的 test case 內容放進來而已。特別獨立成一個 message, 原因很簡單, 之後這段會變成整個 runner 的 input, 變成外部的輸入資訊。
以下為要執行的測試案例
--
// 在這邊插入 testcase 的內容,就是上面那段案例,原封不動貼進來
Message #3 (Role = User),
這段是處理完畢之後,我指定的測試報告生成方式,內容與格式要求
生成 markdown 格式的測試報告,要包含下列資訊:
## 測試步驟
**Context**:
(列出目前 context 相關設定內容)
**Given**:
|步驟名稱 | API | Request | Response | 測試結果 | 測試說明 |
|---------|-----|---------|----------|----------|----------|
| step 1 | api-name | {} | {} | pass/fail | 測試執行結果說明 |
| step 2 | api-name | {} | {} | pass/fail | 測試執行結果說明 |
| step 3 | api-name | {} | {} | pass/fail | 測試執行結果說明 |
**When**:
|步驟名稱 | API | Request | Response | 測試結果 | 測試說明 |
|---------|-----|---------|----------|----------|----------|
| step 1 | api-name | {} | {} | pass/fail | 測試執行結果說明 |
| step 2 | api-name | {} | {} | pass/fail | 測試執行結果說明 |
| step 3 | api-name | {} | {} | pass/fail | 測試執行結果說明 |
**Then**:
- (預期結果1): 測試結果說明
- (預期結果2): 測試結果說明
- (預期結果3): 測試結果說明
## 測試結果
**測試結果**: 無法執行(start_fail) | 執行失敗(exec_fail) | 測試不過(test_fail) | 測試通過(test_pass)
這些 Prompt(s) 準備好之後,其實程式碼沒什麼特別的,就是交給 Kernel.InvokePromptAsync( ... ) 執行而已。我懶得用 ChatComplet 方式逐一整理 ChatHistory 物件,因此我直接用 Semantic Kernel 支援的 Prompt Template 格式,一次寫完上面的每一段 message, 要插入的 testcase 我直接當作 KernelArguments 當作變數插入 PromptTemplate ..
唯一要注意的,就是要先在 PromptExecutionSettings 指定 FunctionChoiceBehavior = Auto, 這樣 Kernel 才會替你處理掉一堆 Function Calling 過程的雜事 (有興趣可以看我三月的直播錄影, 我有把處理過程的 openai chatcompletion api 往返過程逐一列出, 你看完後你不會想自己搞那些的…):
var settings = new PromptExecutionSettings()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
Message 內容前面我都解釋過了,這邊我只貼一行,多餘的訊息我會省略掉。InvokePrompt 時記得帶上前面準備好的 settings 以及你要代入 Prompt 的參數 (這邊是 testcase),接下來就等結果就好了。以我的案例,我使用 o4-mini 這模型,大概要跑一分鐘左右…
程式碼如下:
var report = await kernel.InvokePromptAsync<string>(
"""
<message role="system">
依照我給你的 test case 執行測試。
(以下略)
</message>
<message role="user">
以下為要執行的測試案例
(以下略)
</message>
<message role="user">
生成 markdown 格式的測試報告,要包含下列資訊:
(以下略)
</message>
""",
new(settings)
{
["test_case"] = "..." // 在這邊把你真正的 test case 內容填進來
});
4-3, 測試結果報告
其實原本應該還有 “領域知識” 的部分該補的,不過這邊我吃了一點 AI 的豆腐,因為 “購物車” 這概念太普及了,普及到我不需要特別去準備 “領域知識” 的文件,餵給 AI 讓他理解什麼是購物車,OpenAI 在訓練模型時使用的資訊早就調教過這件事了。因此目前的 AI 能很清楚的理解這案例該怎麼跑,我就略過這部分。
最後把這些東西都湊在一起執行,細節我就不貼了。不過我特地貼一下執行的畫面,因為我有把中間呼叫 API 的過程都印出來,印證一下 AI 真的有確實去執行這些步驟:
這是 Given 的部分:
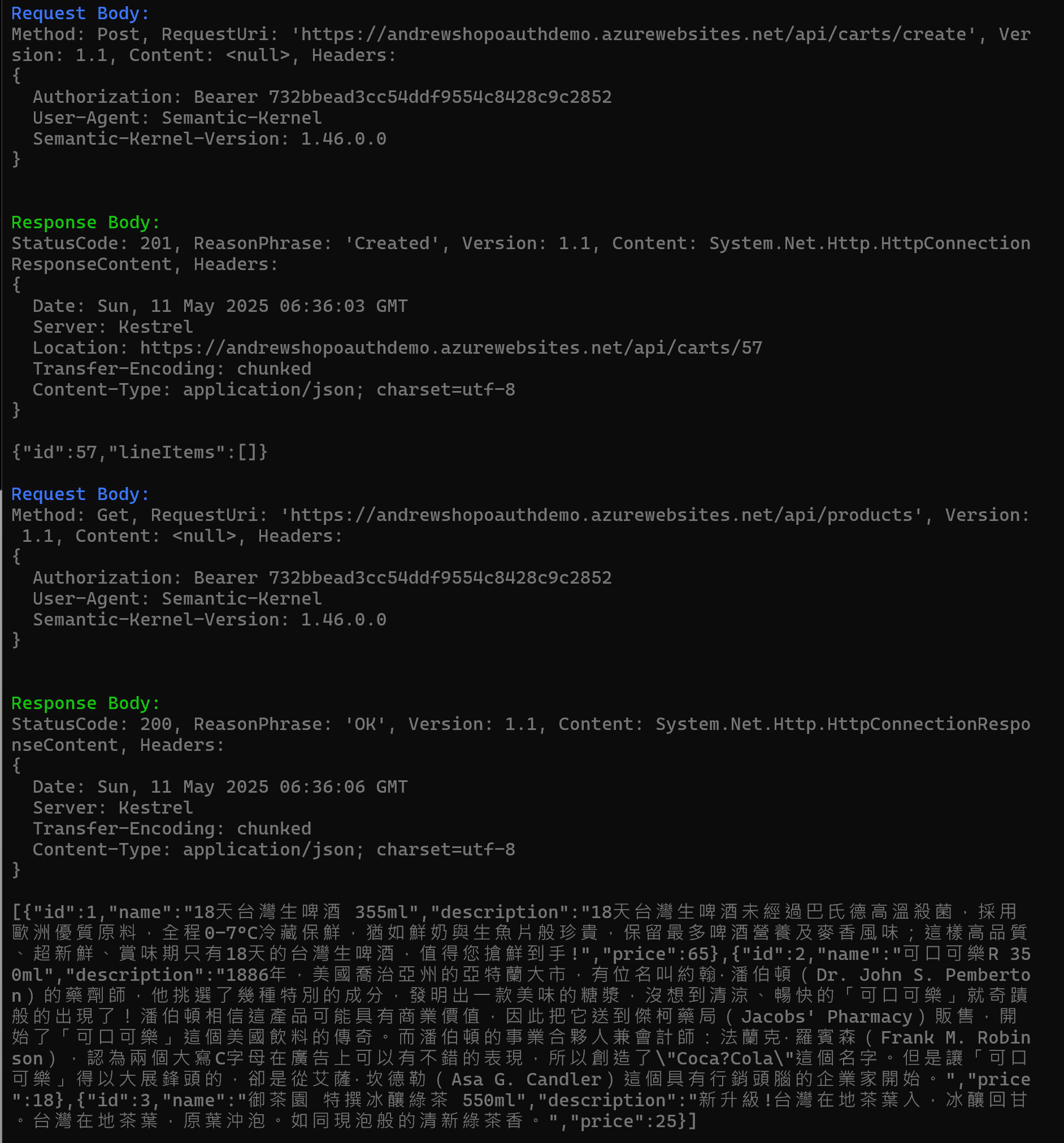
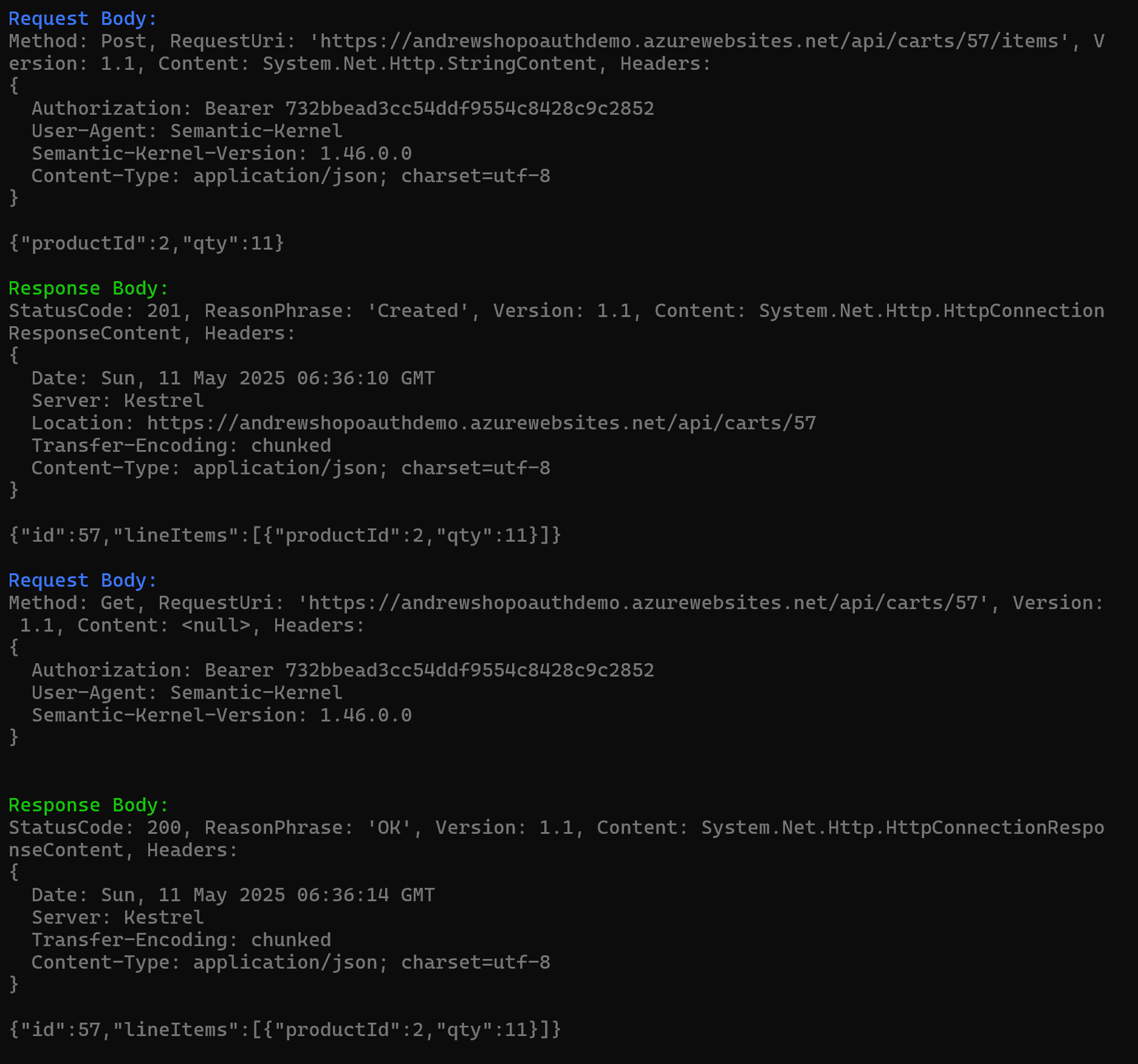
這是 When 的部分:
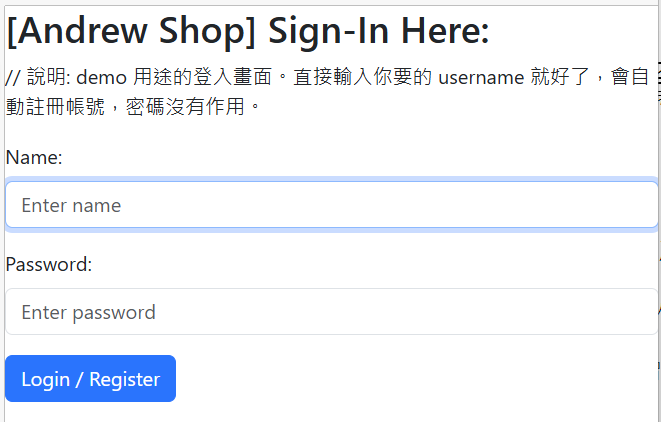
過程我就不再解釋了,各位有興趣可以對照著看,截圖只是證明 AI 真的能清楚這流程,有確實執行而已。這邊特別說明一下我沒提到的細節,就是 API 的使用者認證。我原始的 API 支援 OAuth2 的認證機制,正常的話執行過程中應該會跳出 Browser 讓我輸入帳號密碼 ( 用過 “安德魯小舖” GPTs 的朋友應該都看過這畫面 ):
而在這邊我在 Test Runner 加了一段 code 來處理這件事,因此你會看到每個 API 的 Request Headers 都會有這段,而每次測試拿到的 token 都會不同,並且都有真正跑過完整的 OAuth2 認證流程:
Authorization: Bearer 732bbead3cc54ddf9554c8428c9c2852
這是很重要的環節,但是這篇應該寫不下,處理這些 API 認證機制的過程還挺有意思,包含你怎麼設計解題方式,以及怎麼做出來。以後有機會我在講規模化的時候在來聊聊這些外圍議題,這次先跳過。
最後,這樣的案例跑完後,我直接得到 AI 給我的測試報告: (以下為報告範例)
Given:
步驟名稱 API Request Response 測試結果 測試說明 清空購物車 POST /api/carts/create {} { “id”: 22, “lineItems”: [] } pass 成功建立一個新的空購物車 (id=22) 指定商品 GET /api/products {} 產品清單 (含 id=2: 可口可樂® 350ml) pass 成功取回可口可樂 (productId=2) When:
步驟名稱 API Request Response 測試結果 測試說明 step 1 POST /api/carts/22/items { “productId”: 2, “qty”: 11 } { “id”: 22, “lineItems”:[{“productId”:2,”qty”:11}] } fail 預期 400 Bad Request,但實際回應 200 且加入了 11 件,可接受錯誤 step 2 GET /api/carts/22 { “id”: 22 } { “id”: 22, “lineItems”:[{“productId”:2,”qty”:11}] } fail 預期購物車應為空,但實際仍有 11 件商品 Then:
- 預期 step 1 回傳 400 Bad Request(數量超出 10)。實際回傳 200 → 不符合預期。
- 預期 step 2 購物車為空。實際購物車含 11 件商品 → 不符合預期。
測試結果: 測試不過 (test_fail)
本測試用例驗證「加入超過 10 件商品」應被拒絕,但伺服器仍允許並加入購物車,且購物車非空。
這是最後的測試報告。報告顯示這次測試是失敗的,API 沒有通過測試。這是我故意埋的結果。實際上我的 API 根本沒有實作 “同商品最多 10 筆” 這個限制,這限制只存在規格跟測試案例上。
我想像的情境是,類似 TDD (Test Driven Development) 一樣,我先寫規格,先產生測試案例,先寫測試 (這邊我有 Test Runner 就夠了,不需要再額外寫單元測試程式)。一開始先讓測試亮紅燈,等到功能逐漸交付後,這些紅燈應該一個一個變成綠燈才對。而現在的狀況,就是需求跟測試準備好了,而 API 本身還沒符合規格的階段,所以測試預期會失敗,而實際上,AI 驅動的 Test Runner,也真的給我測試失敗的結果了,符合預期!
這就是我真正需要 AI 幫我處理的細節,過去這些前後動作的關聯,都仰賴工程師一行一行 script 寫出來的。即使你用 postman 這類工具,你仍然無法簡單的只是 “錄製” + “播放” 就能重複這些動作,因為你終究要有工程師去定義變數,把前後 API 這些細微的差異串接起來。
而現在,AI 已經有強大的邏輯能力了,其實你都信任他能幫妳寫更複雜的 code 了,以複雜度來說,呼叫兩三個 API 並且把傳遞參數這點小事搞定,其實你可以信賴 AI 的,不用擔心。
就如同我一開始所說,AI 都有能力扮演 Agent 的角色了,Agent 就是按照你的要求替你執行對應的 API (Tools) 而已,這老早是業界 AI 大廠競爭優化的主要功能之一,是已經很成熟可以直接使用的東西。你需要擔心的就是如何適當的運用它而已。
5, 心得
最後總結一下吧,其實為了篇幅,我略過幾個蠻細節但是挺重要的環節沒有特別說明.. (之後的文章再補)。我列舉幾個:
5-1, API 必須按照領域來設計
這是另一個難題,如果你的 API 設計先天不良,通通都只有 CRUD 的話,那麼要控制什麼情況該更新怎樣的資料進 DB,則都必須由呼叫 API 的一方來決定,這種情況下 AI 的處理效果是很糟糕的 (因為光是能否正確 “寫入” 資料就大量依賴呼叫端了,AI 的不確定性會大幅影響測試的進行)。因為你的商業邏輯完全沒有封裝在 API 內,你測試案例的執行路徑會混亂發散到無法掌控的程度。
按照領域來設計 API 規格,這是我先前提過 “AI Ready” 的一環。如果你的 API 難以被 AI 理解,我也會建議,要嘛重新封裝一層,要嘛放棄,用其他能半自動的測試方式。使用 Function Calling 來驅動測試自動化是有門檻的,AI Ready 是很關鍵的一環。
當你有這樣的設計水準的時候,寫在 API 文件上的敘述,都會變成 AI 理解的 Prompt。你不需要花費太多心思,直接把文件到給 AI,它自然就能理解正常運作。
5-2, API 必須有精確的規格文件
去年,我在寫這篇文章: [架構師觀點] 開發人員該如何看待 AI 帶來的改變? 時,提到一個情境 (4.2):
因為,掛上 LLM 後的 API ( Plugins ), 呼叫你 API 的不再是其他開發者了, 會變成 AI 來呼叫你的 API。你已經無法 “預測” 或是 “約束” 對方該怎麼呼叫。
補充一下,AI 之所以能 “精準的” 決定該怎麼產生呼叫 API 所有的資訊 ( Uri, Headers, Payload … ) 的原因來自他有精確的規格 ( Swagger, OpenAPI Spec )。反過來說,如果你現在的 API 還給不出 “精準” 的 API Spec, 那麼我必須說, 你的情況還沒機會用 Test Runner 來跑 API test …
如果文件 ( swagger ) 是人工維護的行不行? 理論上可行,務實上我會建議你別幻想了。這是 “測試用途”,不是 “正式應用”,這代表你可能在開發階段就需要測試。如果你的規格文件都需要人工維護了,你會精準到 RD 改了一行 Code 你就改一版文件嗎? 如果你開發階段必須不斷的執行測試驗證結果,你有能力在每次測試前,也都顧好這些文件都精準的跟 API code 保持同步嗎? 做不到的話,自動化測試其實是替你製造更多麻煩,不是解決更多問題。
因此別想繞過這些基礎功夫了,能做到這樣都是 CICD + 自動產生 API Spec 文件才做得到了。你如果現在還做不到這點,我建議,先把資源花在提升這些工程的成熟度上面。成熟度夠再來思考這些自動化測試的問題,否則 AI 加速的不是你的生產力,而是加速你技術債的生成… (你因為 AI 加速開發,反而累垮這些過去在背後默默人工補文件的人)
5-3, API 必須標準化處理認證授權
這在所有系統的 API 來說都是重要的,為了確保你是 “對的人” 來呼叫 API,一定要有的驗證程序。我的 API 實作的認證機制是 OAuth2, 理論上是要跳出 UI 讓 “真人” 輸入帳密,取得 Access Token 後再交由 API 確認使用。
然而我思考了測試需求的情境,指定 “測試對象” 應該也是個常見的需求,因此我在 Test Runner 有特別寫了另一個 Plugins 來接受測試案例指定 user 的需求,而背後會自己附加通過認證後的 access token 給每個呼叫 AndrewShop API 的 Authorization Header.
你也許會想,我就開出 login 的 API, 同樣用 Function Calling 的機制讓 AI 在執行測試時自己登入… 這是個 “理想” 的好方法嗎? 如果這 API 也是你開發中的 API 之一,也需要被測試,這樣做我覺得沒有問題。但是大部分情況下,認證機制都不是你主要要測試的標的,你要測的是認證後的 API 行為,是否符合授權的行為?
類似問題,同時也存在其他 “環境因素”,例如目前的語系,幣別,時區等等,如果這些環境因素會影響你的 API 行為,這些也都有同樣的 patterns 要處理。這應該屬於 “測試環境控制” 的議題,而不是單純的把它當作測試步驟來處理。因此,我有特別設計一個 Plugins 專門來負責環境控制。當然,這環境控制我會盡可能跟 AI 脫鉤,我期待的是準備好正確環境後,再讓 AI 來發揮他的專長,幫我按照情境執行測試案例。
因此,最小化來看環境問題,我在這邊就只看 “API 認證機制” 就好了。要自動化測試 API 前,你的 API 應該要有 “統一” 的認證機制,並且這認證機制應該統一處理後再交給 AI 執行測試案例。你應該在整個 Test Runner 的開發上,就明確規範這件事情。
5-4, 你需要有系統的彙整所有的測試報告
產生的測試報告,是 markdown 格式,是給 “人” 來看的。實際上,當測試量大的時候,你需要一個機制收集所有的測試結果,再用統計或是警示的方式來回報測試狀況。
這時,用 json 的方式結構化的輸出測試報告,會遠比 markdown 還來的有效。我實際上有讓 AI 同時輸出兩種格式,效果還不錯,但是高度綁定我們內部的環境,我就沒特別貼出來說明了。不過,這些技巧,同樣我在三月份的直播有提及。有興趣的人可以參考 LLM API 如何做到 Structured Output ( 俗稱的 Json Mode + Json Schema 作法 )。我有提供 HTTP / OpenAI .NET SDK / Semantic Kernel 三種不同版本的程式碼給大家參考。
上面提到的技巧,有興趣的可以參考:
- 簡介 Day1, LLM - Structured Output
- 錄影: 簡介 .NET RAG 神器:Microsoft Kernel Memory 與 Semantic Kernel 的整合應用
- 問券
- Demo Code
我貼實際貼上輸出的 Json 給大家參考就好,這是同樣測試報告的 Json 版本,用來系統整合用的 (Markdown 是給人看,好閱讀用的)。範例如下:
{
"name": "TC-05 (非法上界)",
"result": "test_fail",
"comments": "AddItemToCart 未回傳 400,且購物車不為空",
"context": {
"shop": "shop123",
"user": {
"access_token": "732bbead3cc54ddf9554c8428c9c2852",
"user": "andrew"
},
"location": {
"id": "zh-TW",
"time-zone": "UTC+8",
"currency": "TWD"
}
},
"steps": [
{
"api": "CreateCart",
"request": {},
"response": { "id": 57, "lineItems": [] },
"test-result": "pass",
"test-comments": "成功建立空購物車"
},
{
"api": "GetProducts",
"request": {},
"response": [
{ "id":1, "name":"18天台灣生啤酒 355ml", "price":65 },
{ "id":2, "name":"可口可樂® 350ml", "price":18 },
{ "id":3, "name":"御茶園 特撰冰釀綠茶 550ml", "price":25 }
],
"test-result": "pass",
"test-comments": "成功取得商品清單"
},
{
"api": "AddItemToCart",
"request": { "id":57, "productId":2, "qty":11 },
"response": { "id":57, "lineItems":[ { "productId":2,"qty":11 } ] },
"test-result": "fail",
"test-comments": "未回傳 400,實際加入 11 件"
},
{
"api": "GetCart",
"request": { "id":57 },
"response": { "id":57, "lineItems":[ { "productId":2,"qty":11 } ] },
"test-result": "fail",
"test-comments": "購物車內仍含商品,不為空"
}
]
}
5-5, 小結
這篇,算是我開始在思考各種 AI 的應用。如同我常常在講,AI 帶來很多可能性,不過身為開發者,我們存在的價值應該是把有用的技術包裝成軟體,讓更多人易於使用才對。這兩年 AI 帶來的衝擊,開發人員是第一波。因為 GitHub Copilot / Cursor 這類 AI 強化的生產力工具的出現,我覺得開發人員受到的改變是最強烈的。
也因為這樣,開發人員都在談這些工具有多厲害,卻很少人在談怎麼用這些技術開發更厲害的工具或產品給其他人使用? 因此我才把研究重心轉移在 “自己寫 code 呼叫 LLM API” 能創造的價值。從 2023/12 的安德魯小舖開始,我還挺慶幸我有選擇這個研究路線的。一路至今,我也從這路線開始掌握 LLM 的運用技巧了。說實在話,沒有這樣的經歷,我現在應該沒辦法生出 Test Runner 來解決 API 自動化測試的問題。
你會發現,一路看下來,我用了相當多我在直播中介紹的技巧。工程師只要能善用 Structure Output + Function Calling,加上夠好的思路能寫出合理的 Prompt,你有 coding 的能力會是大加分。我只用了這幾招,就能組合出我期待的 Test Runner,即使這是目前現成的工具還辦不到的功能。這些能力,在面對系統整合的時候特別有用。關鍵地方用對技巧,你會發現跨系統整合,出乎意料的簡單,而 Test Runner,就是典型的需要整合各系統 (文件、測試執行、測試管理) 的應用。
回到測試這件事,這篇文章,大概講了我想表達跟嘗試部分的 30% 左右,大家可以把這篇當作起點,後面的我在慢慢補完吧! 後面我打算再寫兩篇,分別聊聊測試案例怎麼展開 (這張圖的左半部),以及我一直沒有談的規模化細節 (MCP,認證等等的設計)。
文章內提到的參考資料,我都蒐集到這清單內了。有興趣請參考 [參考資料]:
- [架構師觀點] 開發人員該如何看待 AI 帶來的改變?
- 敏捷三叔公的文章: GenAI 是測試的終結者?
- 2025/03 直播: Semantic Kernel 介紹 + Kernel Memory ( RAG 服務 )
- 簡介 Day1, LLM - Structured Output
- 簡介 Day2, LLM - Function Calling (Basic)
- 簡介 Day3, LLM - Function Calling (Case Study)
- 簡介 Day4, LLM - RAG with Function Calling
- 簡介 Day5, RAG as a Service, Microsoft Kernel Memory
- 簡介 Day6, 進階 RAG 應用, 生成檢索專用的資訊
- 簡介 Day7, 開發 MCPserver, 整合 Kernel Memory Service 與 Claude Desktop
- 簡介 Day8, 土炮 Function Calling
- 錄影: 簡介 .NET RAG 神器:Microsoft Kernel Memory 與 Semantic Kernel 的整合應用
- 問卷調查 如果你有看直播錄影,請幫我填問券,我想知道大家對這些技能的期待,感謝!
- Demo Code
