
最近工作上碰到個案子,其中一個環節需要開發 CLI (Command Line Interface) 的工具,用來處理上百萬筆的資料,處理的步驟有好幾步,希望能按照步驟獨立成數個 CLI ..。資料筆數跟處理步驟是兩個不同的維度,以開發角度當然是按照步驟來區隔 CLI,但是以執行的效能考量則是希望處理好一筆資料的所有步驟,然後再處理下一筆。我跟同事提了 PIPELINE 的作法,也簡單做了些 POC 來說明可行性,所以才起了寫這篇文章的念頭。
如果你熟悉 linux 的 shell script, 你會發現很多內建的指令都能做到這些需求,大量資料的 input / output 都透過 stdio 來進行,shell 也提供 pipe(line) 的指令,讓前一個 CLI 的 stdout, 能夠直接接上下一個 CLI 的 stdin, 就能做到像接火車這樣的串接機制。不過使用的時候很簡單,這彈性的背後,有很多平時不會留意的基礎知識,所以寫了這篇打算來介紹一下 CLI 如何透過 PIPELINE 串流(平行)處理大量資料的開發技巧 (C#)。
歸納一下,會需要用到 CLI 不外乎幾個原因,例如:
- 這個操作必須被自動化或是重複執行,寫成 CLI 才方便放在 shell script 執行。
- 這個操作需要處理大量資料,或是需要長時間執行,必須有足夠的可靠度,及最佳的效能。
- 發展自己的 CLI toolset, 需要跨語言開發,讓 shell script 能夠組合使用。
- 透過 shell “組合” 時, 能善用 batch 及 pipeline 的組合方式。
為了搞定這幾件事情,你的 CLI 可不是 “能動” 就好了。你提供的操作方式 (參數,輸入輸出的設計) 會直接影響你寫的 CLI 用起來順不順手。我這篇就特別針對 CLI 之間透過 pipeline 串接進行串流處理的方式介紹一下好了。我一直認為使用與開發 CLI,應該是後端工程師必備的技能,唯有熟悉這些技巧你才有能力有效率的工作。後端的任務不是只有開發 REST API 而已啊,很多背景處理的服務也是關鍵的一環,與其直接開發成 windows service,我相信開發 CLI + 排程服務會更有效率。看完這篇文章,你可以想一想,過去開發的 CLI 有沒有辦法做得更好?
PIPELINE 的基本概念
我很愛找那種 code 寫起來沒幾行,但是背後很多觀念的文章。這篇要講的又是一樣的東西,我先在這個段落把幾個重要觀念先交代一下:
我想要探討的,是如何有效率地做好批次處理? “批次” 講求的是一次能處理大量資料,串流則講求一次處理一筆,但是能持續、連續的進行,講求的是降低資源與傳輸需求。批次跟串流是從不同的維度來切割問題。
兩者的訴求不同,管線則是讓這兩個交錯的維度能完美結合的作法。最常見到管線的案例,就是工廠的生產線了。操作員按照程序來區分,而輸送帶上的半成品則按照處理的數量來安排。兩者交錯進行,就能用持續穩定的速度,不斷的產生成品,處理過程中就像自來水一樣,打開水龍頭,產品就源源不覺得從輸送帶上面運送過來。
管線處理運用得當的話,能夠大幅提升生產效能,也能減化生產程序,可謂一舉多得。另一個常被運用的例子就是 CPU 的指令,一個指令的執行,切成解碼等等多道程序,沒有 pipeline 的狀況下,每個指令至少都得花 5 cycle (就是常聽到的時脈) 以上來執行。如果用上 pipeline 技巧,則可以讓 CPU 每個時脈週期都有一道指令 (甚至更多) 被執行完成。
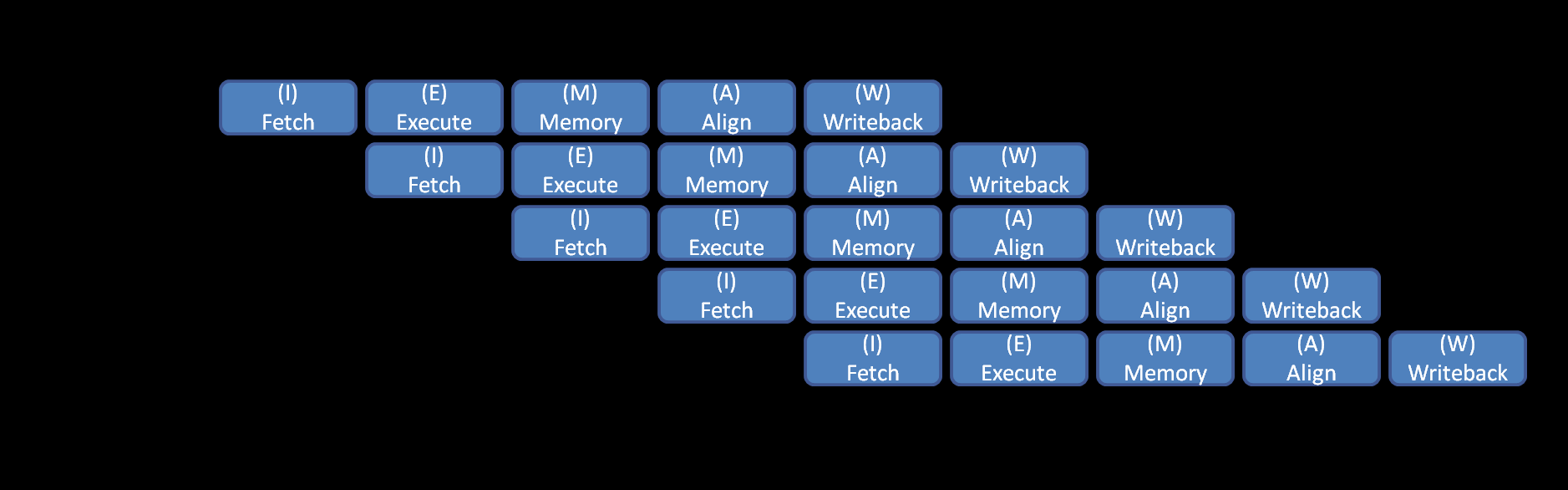
Instruction Pipeline, 說明 CPU 指令執行的過程。簡單的說拆成多個階段,用 PIPELINE 的方式執行,理想狀況下拆越多階,整體效能就越高。
舉個實際的案例,後面的 POC 都會以這案例為前提來示範:
- 我有總共有 N 筆資料需要加工
- 每筆資料要經過三個步驟 P1, P2, P3 的處理才能完成
- 每筆資料每個步驟需要花費 M1, M2, M3 的時間
我打算從幾個指標來看看執行的效果:
- 第一筆資料完成時間 (代表回應速度)
- 全部(最後一筆)完成時間 (代表整體效率)
- 過程中最大半成品數 (代表過程中需要的暫存空間與風險,若作業終止半成品都需要被丟棄)
用講的不大好說明,我簡單的畫了幾張圖,來代表三種處理流程的差異。其中,藍色的箭頭,代表第一筆資料完成的時間,橘色的箭頭代表最後一筆資料完成的時間。整個橘色的框框則是處理的邊界,框框結束才能拿到裡面的資料。
Batch Processing:

- 第一筆資料完成時間: N x (M1 + M2 + M3)
- 全部(最後一筆)完成時間: N x (M1 + M2 + M3)
- 過程中最大半成品數: N
Stream Processing:

- 第一筆資料完成時間: M1 + M2 + M3
- 全部(最後一筆)完成時間: N x (M1 + M2 + M3)
- 過程中最大半成品數: 1
Pipeline Processing:
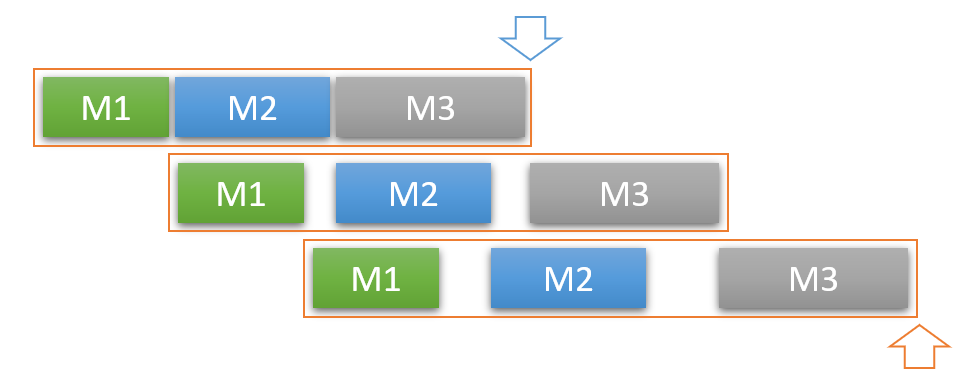
- 第一筆資料完成時間: M1 + M2 + M3
- 全部(最後一筆)完成時間: N x Max(M1, M2, M3) (如果 M1 = M2 = M3, 那麼就有三倍的效率了)
- 過程中最大半成品數: 3
看得出差異了嗎? 你如果有能力精準的用 pipeline 的方式處理資料,加上不同階段之間的資源不會互相占用 (例如 CPU, DISK … etc) 的話,你就能得到戲劇性的效能增長。這些觀念,是我認為的後端工程師必備的技巧。後端工程師不是只會寫 WEB 跟 API 而已,有些需要非同步,或是資料轉檔匯入等等輔助工具時,這些都是很關鍵的技巧。
其實這類的探討,我以前寫過很多篇了。從當年投稿 RUN!PC,寫了十來篇探討平行處理的文章,就有講到生產線的處理模式,就是在講這個。另外在探討 C# async 處理的技巧,也有談到類似的問題。這邊我就不另外再重打一次,十年前的老文章了,有興趣的朋友們可以翻回去看:
- 處理大型資料的技巧 – Async / Await, (2009/04/14)
- RUN!PC 精選文章 - 生產線模式的多執行緒應用, (2009/01/16)
- 生產線模式的多執行緒應用, ([RUN! PC] 2008 十一月號, 2008/11/04)
- 生產者 vs 消費者 - BlockQueue 實作, (2008/10/18)
- MSDN Magazine 閱讀心得: Stream Pipeline, (2008/01/19)
在單一專案內 (code) 的處理方式
別急著馬上就要開始寫 CLI … 先掌握好幾個基本技巧再說吧! 我就用上面的例子,把他變成程式碼,先來 POC 看看你有沒有能力用 C# 來達到想像中的效果。我們先在單一一個 .NET Console App 內完成這整件事,稍後再來把它換成 CLI。
先來準備一下環境,模擬資料 (DataModel) 以及處理資料的程序 (DataModelHelper) 的 code:
public class DataModel
{
public string ID { get; set; }
public int SerialNO { get; set; }
public DataModelStageEnum Stage { get; set; } = DataModelStageEnum.INIT;
public byte[] Buffer = null;
}
public enum DataModelStageEnum : int
{
INIT,
PHASE1_COMPLETE,
PHASE2_COMPLETE,
PHASE3_COMPLETE
}
我簡單用 class DataModel { ... } 來代表資料,其中的 Stage 代表狀態,分為 INIT, PHASE1_COMPLETE, PHASE2_COMPLETE, PHASE3_COMPLETE 來代表處理狀態。
接著看一下 Phase 1 ~ 3 的處理程式碼:
public static class DataModelHelper
{
public static bool ProcessPhase1(DataModel data)
{
if (data == null || data.Stage != DataModelStageEnum.INIT) return false;
Console.Error.WriteLine($"[P1][{DateTime.Now}] data({data.SerialNO}) start...");
Thread.Sleep(1000);
data.Stage = DataModelStageEnum.PHASE1_COMPLETE;
Console.Error.WriteLine($"[P1][{DateTime.Now}] data({data.SerialNO}) end...");
return true;
}
public static bool ProcessPhase2(DataModel data)
{
if (data == null || data.Stage != DataModelStageEnum.PHASE1_COMPLETE) return false;
Console.Error.WriteLine($"[P2][{DateTime.Now}] data({data.SerialNO}) start...");
Thread.Sleep(1500);
data.Stage = DataModelStageEnum.PHASE2_COMPLETE;
Console.Error.WriteLine($"[P2][{DateTime.Now}] data({data.SerialNO}) end...");
return true;
}
public static bool ProcessPhase3(DataModel data)
{
if (data == null || data.Stage != DataModelStageEnum.PHASE2_COMPLETE) return false;
Console.Error.WriteLine($"[P3][{DateTime.Now}] data({data.SerialNO}) start...");
Thread.Sleep(2000);
data.Stage = DataModelStageEnum.PHASE3_COMPLETE;
Console.Error.WriteLine($"[P3][{DateTime.Now}] data({data.SerialNO}) end...");
return true;
}
}
其實也沒啥,就是檢查傳進來的物件狀態對不對,印出開始結束時間,同時 P1 ~ P3 分別延遲 1000ms, 1500ms, 2000ms, 代表不同的處理時間。
最後,是產生測試資料,我循序產生五筆測試資料:
static IEnumerable<DataModel> GetModels()
{
Random rnd = new Random();
byte[] allocate(int size)
{
byte[] buf = new byte[size];
rnd.NextBytes(buf);
return buf;
};
for (int seed = 1; seed <= 5; seed++)
{
yield return new DataModel()
{
ID = $"DATA-{Guid.NewGuid():N}",
SerialNO = seed,
Buffer = allocate(1024)
};
}
}
接下來就開始看各種不同的處理方式 DEMO 了。
DEMO 1, 批次處理
不囉嗦,直接看 code, 應該不用解釋了:
static void Demo1()
{
DataModel[] models = GetModels().ToArray();
foreach (var model in models)
{
DataModelHelper.ProcessPhase1(model);
}
foreach (var model in models)
{
DataModelHelper.ProcessPhase2(model);
}
foreach (var model in models)
{
DataModelHelper.ProcessPhase3(model);
}
}
看一下輸出:
[P1][2019/6/15 上午 04:07:21] data(1) start...
[P1][2019/6/15 上午 04:07:22] data(1) end...
[P1][2019/6/15 上午 04:07:22] data(2) start...
[P1][2019/6/15 上午 04:07:23] data(2) end...
[P1][2019/6/15 上午 04:07:23] data(3) start...
[P1][2019/6/15 上午 04:07:24] data(3) end...
[P1][2019/6/15 上午 04:07:24] data(4) start...
[P1][2019/6/15 上午 04:07:25] data(4) end...
[P1][2019/6/15 上午 04:07:25] data(5) start...
[P1][2019/6/15 上午 04:07:26] data(5) end...
[P2][2019/6/15 上午 04:07:26] data(1) start...
[P2][2019/6/15 上午 04:07:27] data(1) end...
[P2][2019/6/15 上午 04:07:27] data(2) start...
[P2][2019/6/15 上午 04:07:29] data(2) end...
[P2][2019/6/15 上午 04:07:29] data(3) start...
[P2][2019/6/15 上午 04:07:30] data(3) end...
[P2][2019/6/15 上午 04:07:30] data(4) start...
[P2][2019/6/15 上午 04:07:32] data(4) end...
[P2][2019/6/15 上午 04:07:32] data(5) start...
[P2][2019/6/15 上午 04:07:33] data(5) end...
[P3][2019/6/15 上午 04:07:33] data(1) start...
[P3][2019/6/15 上午 04:07:35] data(1) end...
[P3][2019/6/15 上午 04:07:35] data(2) start...
[P3][2019/6/15 上午 04:07:37] data(2) end...
[P3][2019/6/15 上午 04:07:37] data(3) start...
[P3][2019/6/15 上午 04:07:39] data(3) end...
[P3][2019/6/15 上午 04:07:39] data(4) start...
[P3][2019/6/15 上午 04:07:41] data(4) end...
[P3][2019/6/15 上午 04:07:41] data(5) start...
[P3][2019/6/15 上午 04:07:43] data(5) end...
C:\Program Files\dotnet\dotnet.exe (process 15828) exited with code 0.
Press any key to close this window . . .
簡單算一下執行的結果:
- 第一筆資料完成時間: 12 sec (04:07:21 ~ 04:07:33)
- 全部的資料完成時間: 22 sec (04:07:21 ~ 04:07:43)
這就當作對照組吧,沒啥好解釋的 code … XDD, 就把他當作最基本最常見的寫法。以處理程序為主的角度來撰寫,P1 都處理完之後再處理 P2, 以此類推。這個做法理論上有最好的效能,程式碼也能把每個階段區隔得很清楚,也算是最容易維護的結構 (因為簡單明瞭)。缺點是第一筆資料完成的時間會跟總比數有關 (時間複雜度 O(n))。
DEMO 2, 串流處理
串流處理的版本,開始有點不一樣了。前面鋪的梗可以開始拿出來講了… 一樣先看 code 跟執行結果:
static void [DEMO2](#demo2) ()
{
foreach(var model in GetModels())
{
DataModelHelper.ProcessPhase1(model);
DataModelHelper.ProcessPhase2(model);
DataModelHelper.ProcessPhase3(model);
}
}
執行結果
[P1][2019/6/15 上午 04:13:04] data(1) start...
[P1][2019/6/15 上午 04:13:05] data(1) end...
[P2][2019/6/15 上午 04:13:05] data(1) start...
[P2][2019/6/15 上午 04:13:07] data(1) end...
[P3][2019/6/15 上午 04:13:07] data(1) start...
[P3][2019/6/15 上午 04:13:09] data(1) end...
[P1][2019/6/15 上午 04:13:09] data(2) start...
[P1][2019/6/15 上午 04:13:10] data(2) end...
[P2][2019/6/15 上午 04:13:10] data(2) start...
[P2][2019/6/15 上午 04:13:11] data(2) end...
[P3][2019/6/15 上午 04:13:11] data(2) start...
[P3][2019/6/15 上午 04:13:13] data(2) end...
[P1][2019/6/15 上午 04:13:13] data(3) start...
[P1][2019/6/15 上午 04:13:14] data(3) end...
[P2][2019/6/15 上午 04:13:14] data(3) start...
[P2][2019/6/15 上午 04:13:16] data(3) end...
[P3][2019/6/15 上午 04:13:16] data(3) start...
[P3][2019/6/15 上午 04:13:18] data(3) end...
[P1][2019/6/15 上午 04:13:18] data(4) start...
[P1][2019/6/15 上午 04:13:19] data(4) end...
[P2][2019/6/15 上午 04:13:19] data(4) start...
[P2][2019/6/15 上午 04:13:20] data(4) end...
[P3][2019/6/15 上午 04:13:20] data(4) start...
[P3][2019/6/15 上午 04:13:22] data(4) end...
[P1][2019/6/15 上午 04:13:22] data(5) start...
[P1][2019/6/15 上午 04:13:23] data(5) end...
[P2][2019/6/15 上午 04:13:23] data(5) start...
[P2][2019/6/15 上午 04:13:25] data(5) end...
[P3][2019/6/15 上午 04:13:25] data(5) start...
[P3][2019/6/15 上午 04:13:27] data(5) end...
C:\Program Files\dotnet\dotnet.exe (process 1780) exited with code 0.
Press any key to close this window . . .
執行的結果:
- 第一筆資料完成時間: 5 sec (04:13:04 ~ 04:13:09)
- 全部的資料完成時間: 23 sec (04:13:04 ~ 04:13:27)
結果如預期,相信也不需要太多解釋了。不過這邊開始回頭看一下,這兩種做法,除了時間之外,其實還有隱藏的差異…。由於串流處理一次會把一筆資料的所有步驟從頭到尾處理完畢,因此不論你總共有幾筆資料要處理,任何瞬間的半成品一定只有一個。這個案例我的資料是擺在記憶體內,因此串流處理的做法我只需要花費固定 (一筆) 的記憶體空間而已。
這段 sample code 我只替每個 data 準備 1024 bytes 的 buffer 而已,如果我把它改成 1GB 會發生甚麼事?
我把產生測試資料的這段,把 allocate 的 size 從 1024 (1KB) 換成 1024 x 1024 x 1024 (1GB):
static IEnumerable<DataModel> GetModels()
{
Random rnd = new Random();
byte[] allocate(int size)
{
byte[] buf = new byte[size];
rnd.NextBytes(buf);
return buf;
};
for (int seed = 1; seed <= 5; seed++)
{
yield return new DataModel()
{
ID = $"DATA-{Guid.NewGuid():N}",
SerialNO = seed,
Buffer = allocate(1024 * 1024 * 1024)
};
}
}
改完後重新執行這兩個案例。這次我們不看 output, 我們開啟 performance profiler 來看看記憶體使用量:
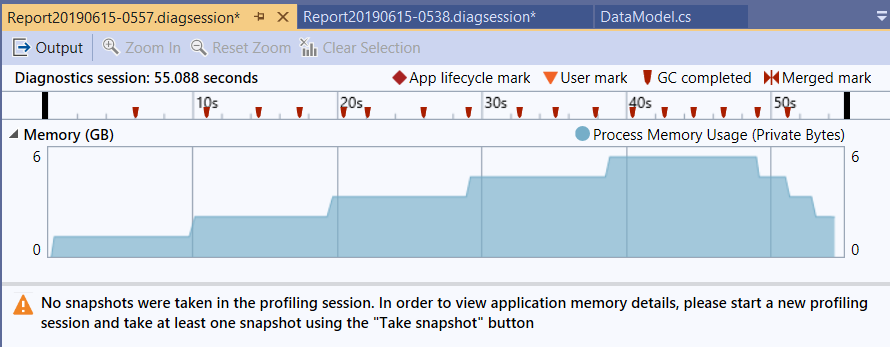
為了避免以前踩過的地雷 (沒有填資料進去的記憶體,OS / CLR 可能會幫我最佳化延遲 allocale, 造成這測試根本沒作用 XDD),因此配置出來的記憶體我都填亂數進去,執行速度比較慢。先來看看 DEMO1 的數據:
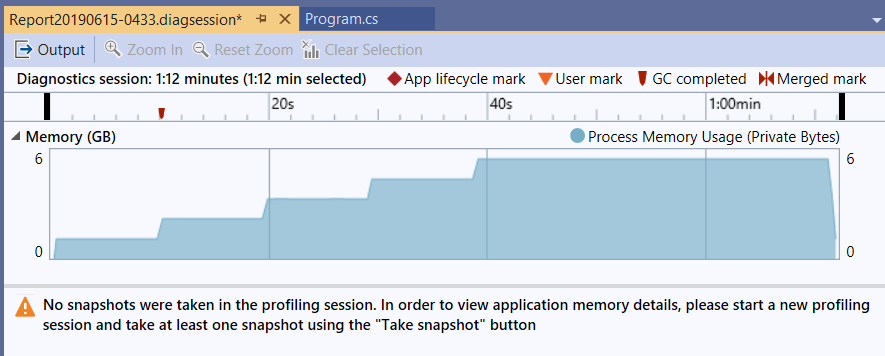
可以看到記憶體一直飆上去,前面 45 sec 都在準備物件,配置了 5GB 記憶體,大約 45 sec 後才開始在執行程式。結束之後 5GB 記憶體都釋放出來了。過程中我就算按了 force GC 也沒有用,就是會吃這麼多記憶體。
留意一下,這裡測試資料才 5 筆… 如果是 5000 筆,你的 server 有 5000GB 的 RAM 可以用嗎? 應該馬上就 OOM (OutOfMemoryException) 了吧…
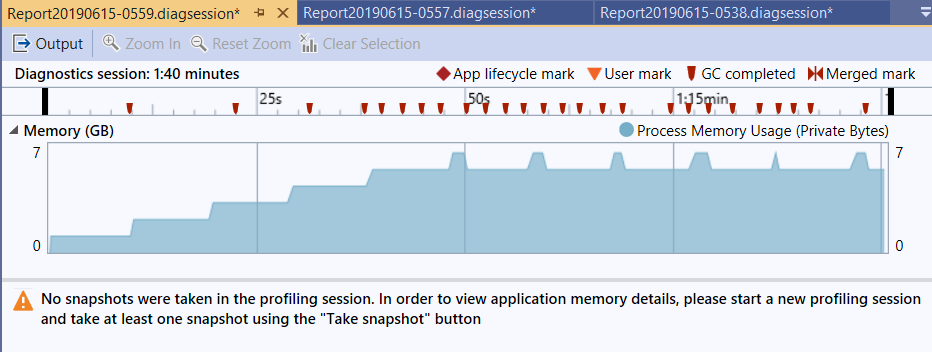
接著來看 DEMO2 :
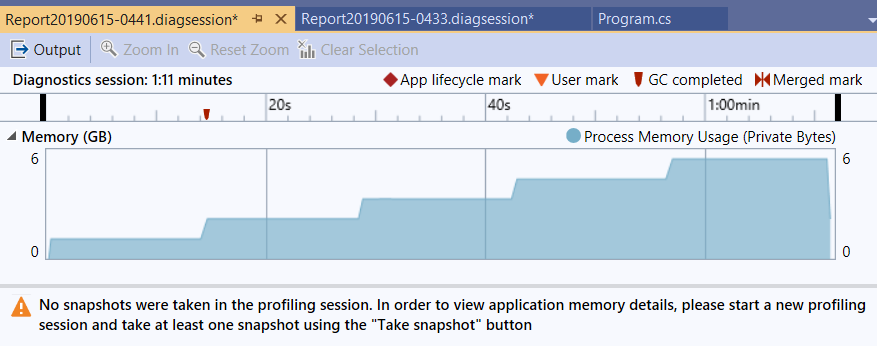
過程可以看到記憶體仍然會往上飆,但是我再跑一次,這次我看到往上飆我就順手按一下 [Force GC] 看看:
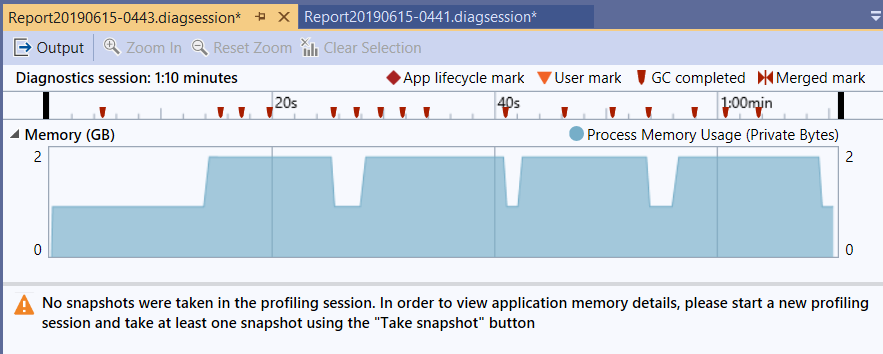
上面有紅色的標記,就是 GC completed 的 mark, 可以看到 GC 是有效的,代表你的程式已經釋放物件了,只是 CLR 沒那麼勤勞沒有立刻回收而已。記憶體使用量大致上都維持再 1 ~ 2GB, 意思是過程中只需要處理中的物件被保留在記憶體內就好了,測試資料不論改成多少筆,測試結果都差不多。
“處理過程中需要占用的資源是固定的” 這是另一個串流處理的特色,如果你是 backend engineer 你必須要更了解這點。留意一下 DEMO2 我特地用 foreach 直接取用測試資料,而 GetModels() 我也直接用 yield return 傳回,整個從資料產生到處理完畢的過程,通通都用串流模式,就能有這樣的效果。反觀 DEMO1, 我故意 GetModels().ToArray() 轉成陣列一次傳回來,就變成了批次模式。
C# yield return 的使用技巧,我當年也寫過幾篇… (怎麼每次拿出來的文章都超過十年以上了? Orz)
- C#: yield return, How It Work ?, (2008/09/18)
串流處理的方式,是以資料為主的角度去撰寫。盡可能的把第一筆資料處理完後才處理第二筆。這種方式的優點是處理中未完成的資料是固定的 (只有一筆),同時能在最快時間內就取得第一筆資料的處理結果。缺點是處理的程式碼會把多個階段都混再一起,不如 DEMO1 來的簡潔,效能最好也只有跟 DEMO1 一樣而已。
DEMO 3, 管線處理 (yield return)
回頭看一下 DEMO1 / DEMO2 的程式碼結構… 很典型的,DEMO1 以 PHASE 處理的結構為主,DEMO2 則是以 DataModel 為主。兩種各有利弊,沒有好壞之分。想看看,如果 DEMO1 的範例內,foreach 內的邏輯很複雜的話,哪一種比較好維護? DEMO1 or DEMO2 ?
這時,以單一職責原則來看,DEMO1 的方式分工比較明確 (先不管記憶體問題),程式碼結構比較利於處理複雜的 PHASE 內邏輯,是比較好維護的。我們有辦法同時兼顧兩種做法嗎?
有的,這就是 PIPELINE 的雛型了。我們來看看 DEMO3 :
static void Demo3()
{
foreach(var m in StreamProcessPhase3(StreamProcessPhase2(StreamProcessPhase1(GetModels()))));
}
public static IEnumerable<DataModel> StreamProcessPhase1(IEnumerable<DataModel> models)
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase1(model);
yield return model;
}
}
public static IEnumerable<DataModel> StreamProcessPhase2(IEnumerable<DataModel> models)
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase2(model);
yield return model;
}
}
public static IEnumerable<DataModel> StreamProcessPhase3(IEnumerable<DataModel> models)
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase3(model);
yield return model;
}
}
[P1][2019/6/15 上午 05:31:35] data(1) start...
[P1][2019/6/15 上午 05:31:36] data(1) end...
[P2][2019/6/15 上午 05:31:36] data(1) start...
[P2][2019/6/15 上午 05:31:37] data(1) end...
[P3][2019/6/15 上午 05:31:37] data(1) start...
[P3][2019/6/15 上午 05:31:39] data(1) end...
[P1][2019/6/15 上午 05:31:39] data(2) start...
[P1][2019/6/15 上午 05:31:40] data(2) end...
[P2][2019/6/15 上午 05:31:40] data(2) start...
[P2][2019/6/15 上午 05:31:42] data(2) end...
[P3][2019/6/15 上午 05:31:42] data(2) start...
[P3][2019/6/15 上午 05:31:44] data(2) end...
[P1][2019/6/15 上午 05:31:44] data(3) start...
[P1][2019/6/15 上午 05:31:45] data(3) end...
[P2][2019/6/15 上午 05:31:45] data(3) start...
[P2][2019/6/15 上午 05:31:46] data(3) end...
[P3][2019/6/15 上午 05:31:46] data(3) start...
[P3][2019/6/15 上午 05:31:48] data(3) end...
[P1][2019/6/15 上午 05:31:48] data(4) start...
[P1][2019/6/15 上午 05:31:49] data(4) end...
[P2][2019/6/15 上午 05:31:49] data(4) start...
[P2][2019/6/15 上午 05:31:51] data(4) end...
[P3][2019/6/15 上午 05:31:51] data(4) start...
[P3][2019/6/15 上午 05:31:53] data(4) end...
[P1][2019/6/15 上午 05:31:53] data(5) start...
[P1][2019/6/15 上午 05:31:54] data(5) end...
[P2][2019/6/15 上午 05:31:54] data(5) start...
[P2][2019/6/15 上午 05:31:55] data(5) end...
[P3][2019/6/15 上午 05:31:55] data(5) start...
[P3][2019/6/15 上午 05:31:57] data(5) end...
C:\Program Files\dotnet\dotnet.exe (process 15672) exited with code 0.
Press any key to close this window . . .
執行的結果:
- 第一筆資料完成時間: 4 sec (05:31:35 ~ 05:31:39)
- 全部的資料完成時間: 22 sec (05:31:35 ~ 05:31:57)
我善用了 yield return 的結構,把三個 PHASE 的處理動作都隔開了,隔離在個別的 StreamProcessPhaseX(...) 內,這個 method 的 input / output 都是 IEnumerable<DataModel>, 然後就像接力賽一樣,一棒一棒交下去。串完之後,最外圍的主程式,單純用個不做事的 foreach loop 驅動整個引擎運轉,就跑出跟 DEMO2 一樣的結果了 (如上)。
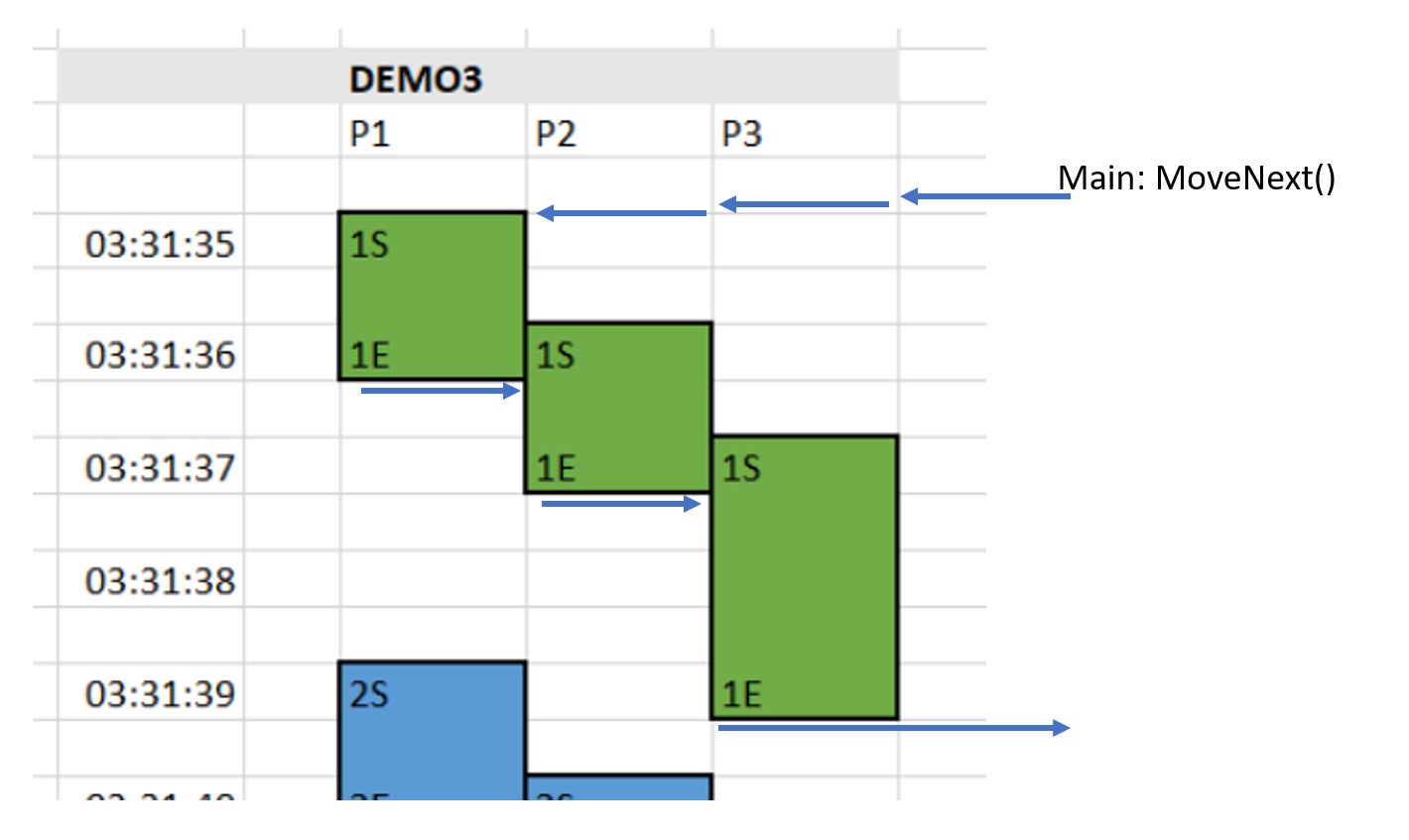
我把 log 上的資訊,用視覺化的時序圖來表達。從左到右是 P1 ~ P3 的處理過程,從上到下代表時間的進行。同樣顏色的區塊代表同一筆資料。畫成圖你比較能想像執行的順序:

為了公平比較效能,這段測試一樣是以 buffer size = 1024 bytes 為主下去測試的。我們一樣補一個 1GB buffer 的測試,看看 memory usage:
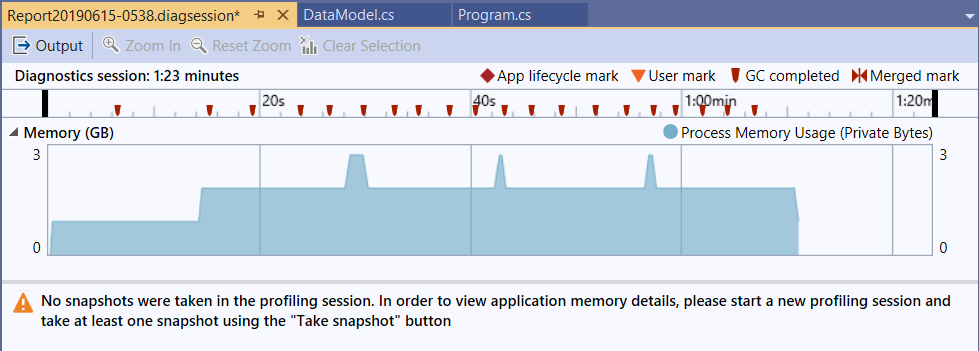
有趣的來了。我一樣在測試過程中不斷的點 Force GC (可以從上面的 GC completed mark 看到我點了幾下)。這個版本跑出來的邏輯跟 DEMO2 一樣,記憶體使用也維持平穩固定,但是固定的記憶體使用量卻比 DEMO2 多…
主要的差異在於,我們包了三層的 IEnumerable<DataModel> , 同一瞬間不同的 IEnumerable<DataModel> 至少會保留 2 ~ 3 個物件,因此我按 GC 的時候,有些物件會晚一點才能被放掉,但是整體長期來看,仍然會維持固定的量,不會像 DEMO1 隨總資料筆數增加而增加。
綜合來看,Pipeline 的做法結合了 DEMO1 DEMO2 兩種做法的優點,能同時兼顧第一筆資料的處理時間,也能兼顧處理過程花費的資源 (固定,但是可能會較 DEMO2 多)。同時程式碼的邏輯也能夠清楚的區隔。唯獨效能仍然沒有變化。
這版本只是程式碼結構改善了而已啊,執行的時間沒有像最前面講概念的部分一樣,看的到執行效能大幅縮短的效果。因為除了流程改變之外,我們還缺了另一個很重要的因素: 非同步 (async)。我們接著看 DEMO4… 進一步的修改 PIPELINE 的運用…
DEMO 4, 管線處理 (async)
變態燒腦的程式碼出現了… 要寫這種文章,精神不好的時候還真寫不下去… 先看 code 跟結果再說。
static void Demo4()
{
foreach (var m in StreamAsyncProcessPhase3(StreamAsyncProcessPhase2(StreamAsyncProcessPhase1(GetModels())))) ;
}
public static IEnumerable<DataModel> StreamAsyncProcessPhase1(IEnumerable<DataModel> models)
{
Task<DataModel> previous_result = null;
foreach (var model in models)
{
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
previous_result = Task.Run<DataModel>(() => { DataModelHelper.ProcessPhase1(model); return model; });
}
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
}
public static IEnumerable<DataModel> StreamAsyncProcessPhase2(IEnumerable<DataModel> models)
{
Task<DataModel> previous_result = null;
foreach (var model in models)
{
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
previous_result = Task.Run<DataModel>(() => { DataModelHelper.ProcessPhase2(model); return model; });
}
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
}
public static IEnumerable<DataModel> StreamAsyncProcessPhase3(IEnumerable<DataModel> models)
{
Task<DataModel> previous_result = null;
foreach (var model in models)
{
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
previous_result = Task.Run<DataModel>(() => { DataModelHelper.ProcessPhase3(model); return model; });
}
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
}
執行結果:
[P1][2019/6/15 上午 05:51:40] data(1) start...
[P1][2019/6/15 上午 05:51:41] data(1) end...
[P1][2019/6/15 上午 05:51:41] data(2) start...
[P2][2019/6/15 上午 05:51:41] data(1) start...
[P1][2019/6/15 上午 05:51:42] data(2) end...
[P2][2019/6/15 上午 05:51:43] data(1) end...
[P1][2019/6/15 上午 05:51:43] data(3) start...
[P2][2019/6/15 上午 05:51:43] data(2) start...
[P3][2019/6/15 上午 05:51:43] data(1) start...
[P1][2019/6/15 上午 05:51:44] data(3) end...
[P2][2019/6/15 上午 05:51:44] data(2) end...
[P3][2019/6/15 上午 05:51:45] data(1) end...
[P3][2019/6/15 上午 05:51:45] data(2) start...
[P2][2019/6/15 上午 05:51:45] data(3) start...
[P1][2019/6/15 上午 05:51:45] data(4) start...
[P1][2019/6/15 上午 05:51:46] data(4) end...
[P2][2019/6/15 上午 05:51:46] data(3) end...
[P3][2019/6/15 上午 05:51:47] data(2) end...
[P3][2019/6/15 上午 05:51:47] data(3) start...
[P2][2019/6/15 上午 05:51:47] data(4) start...
[P1][2019/6/15 上午 05:51:47] data(5) start...
[P1][2019/6/15 上午 05:51:48] data(5) end...
[P2][2019/6/15 上午 05:51:48] data(4) end...
[P3][2019/6/15 上午 05:51:49] data(3) end...
[P3][2019/6/15 上午 05:51:49] data(4) start...
[P2][2019/6/15 上午 05:51:49] data(5) start...
[P2][2019/6/15 上午 05:51:50] data(5) end...
[P3][2019/6/15 上午 05:51:51] data(4) end...
[P3][2019/6/15 上午 05:51:51] data(5) start...
[P3][2019/6/15 上午 05:51:53] data(5) end...
C:\Program Files\dotnet\dotnet.exe (process 20236) exited with code 0.
Press any key to close this window . . .
執行的結果:
- 第一筆資料完成時間: 5 sec (05:51:40 ~ 05:51:45)
- 全部的資料完成時間: 13 sec (05:51:40 ~ 05:51:53)
看到了嗎? 有兩個重要的差異,請留意看執行結果…
- 全部完成的時間大幅縮短,前面幾個案例大約都在 22 sec 上下,現在變成 13 sec …
- 執行的順序開始有交錯的狀況發生了。每個 phase 的範圍內都是按照順序進行的,但是每個 phase 之間則是平行處理的。
- 執行的順序開始有交錯的狀況發生了。每個 data 的處理順序一定是對的 (P1, P2, P3),但是每個 data 之間則是平行處理的。
這版改變的地方,主要是: 前面原本的 StreamProcessPhaseX(), 我另外寫了一個版本: StreamAsyncProcessPhaseX(). 主要的差異在於改用 async 的方式,呼叫 DataModelHelper.ProcessPhaseX()… 呼叫後立即返回,繼續等待下一筆資料進來。如果下一筆資料進來,前一筆還未完成就繼續等。主要的改善點在於 “等待下一筆” 跟 “等待這筆處理完畢” 這兩件事都是要等待,為何不同時等?
人的腦袋天生不適合思考平行處理的流程… 這邊要燒點腦… 來看看我們在 StreamAsyncProcessPhaseX() 裡面做了啥:
public static IEnumerable<DataModel> StreamAsyncProcessPhase1(IEnumerable<DataModel> models)
{
Task<DataModel> previous_result = null;
foreach (var model in models)
{
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
previous_result = Task.Run<DataModel>(() => { DataModelHelper.ProcessPhase1(model); return model; });
}
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
}
結構跟前面的 DEMO3 一樣,但是差別在於真正呼叫 DataModelHelper.ProcessPhase1() 的時候,我改用 Task 包裝起來,用 Async 模式去執行。執行後我不管結果,把 task 放在 previous_result 等著待會 await,就先結束目前這圈 foreach loop, 讓 foreach 繼續拉下一筆資料進來。
但是,管線處理有個假設,就是同一個 PHASE,一次只能處理一筆啊,否則我就需要多倍的計算資源了… 因此 foreach 拉了下一筆之後,要等前一筆結束才能再交給 DataModelHelper.ProcessPhase1() 處理。因此多插了一段 previous_result.GetAwaiter().GetResult()。
因為我在每個階段都動了一樣的手腳,因此整個處理的流程,就再允許的限制下,部分的被平行化處理了。用視覺化的方式來呈現這過程:
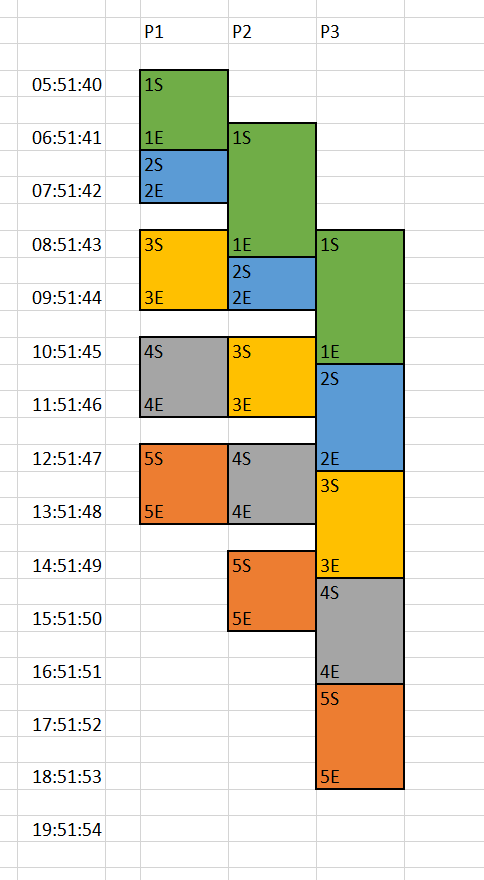
左邊是 Log 的時間,上面的 P1 ~ P3 就是 Log 上的 P1 ~ P3, 每一筆資料都有開始結束,我用 1S / 1E 代表第一筆資料的每個階段啟始結束時間,把他標在正確的格子上。最後加點美工,把他框起來上色 (同樣顏色代表同一筆 data),就變成這張圖了。
仔細看一下,你會發現這跟前面介紹 pipeline 我畫的示意圖是一樣的結果,代表這樣的程式碼真的在時序的處理上有如我們的預期。 這邊很容易想到腦袋打結 (Orz, 我也沒辦法)… 其實想不通也沒關係,可以直接放棄 XDD, 因為後面有簡單的替代方案…
再繼續之前,我一樣補一下記憶體使用的狀況:
 (記憶體, 5)
(記憶體, 5)
因為這方式的平行化程度更高了,代表要保留的半成品也更多,因此記憶體使用量也變多了。由於我們才測五筆看不大出來記憶體使用量是否平穩,我改成 20 筆再測一次:
 (記憶體, 50)
(記憶體, 50)
看來結果一樣維持平穩,只是平行處理的前提下,必須保留在記憶體內的資料比前面的 demo 更多而已。
DEMO 5, 管線處理 (BlockingCollection)
為了解決 DEMO4 碰到 P1 因為跑太快,仍然有空檔的現象,我決定再換個做法,盡可能的加速 P1 的整體處理速度。DEMO4 採用 Async 的做法,頂多讓每個階段預先多處理一筆資料而已。如果我要允許多處理幾筆呢?
這次我改用以前寫過的 BlockQueue 的做法了,Queue 跟 Pipeline 的運作模式很類似,如果再加上同步的控制,兩者根本就是同樣的東西了。Queue 允許的最大長度就是 pipeline buffer 的大小。我在之前的文章花了不少力氣自己刻了一個 BlockQueue 來用,現在不用這麼辛苦了,Microsoft 直接在 .NET 內建了一組,只不過名字跟我取的不大一樣,叫做 BlockedCollection<T> !!
想看 BlockQueue 運作原理的,可以直接看我 11 年前的那篇文章,想看 .NET 內建的 BlockedCollection<T> 用法,可以直接看官方文件就好。我們直接來看改用 BlockedCollection<T> 的版本及執行結果:
const int BLOCKING_COLLECTION_CAPACITY = 10;
static void Demo5()
{
foreach (var m in BlockedCollectionProcessPhase3(BlockedCollectionProcessPhase2(BlockedCollectionProcessPhase1(GetModels())))) ;
}
public static IEnumerable<DataModel> BlockedCollectionProcessPhase1(IEnumerable<DataModel> models)
{
BlockingCollection<DataModel> result = new BlockingCollection<DataModel>(BLOCKING_COLLECTION_CAPACITY);
Task.Run(() =>
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase1(model);
result.Add(model);
}
result.CompleteAdding();
});
return result.GetConsumingEnumerable();
}
public static IEnumerable<DataModel> BlockedCollectionProcessPhase2(IEnumerable<DataModel> models)
{
BlockingCollection<DataModel> result = new BlockingCollection<DataModel>(BLOCKING_COLLECTION_CAPACITY);
Task.Run(() =>
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase2(model);
result.Add(model);
}
result.CompleteAdding();
});
return result.GetConsumingEnumerable();
}
public static IEnumerable<DataModel> BlockedCollectionProcessPhase3(IEnumerable<DataModel> models)
{
BlockingCollection<DataModel> result = new BlockingCollection<DataModel>(BLOCKING_COLLECTION_CAPACITY);
Task.Run(() =>
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase3(model);
result.Add(model);
}
result.CompleteAdding();
});
return result.GetConsumingEnumerable();
}
執行結果:
[P1][2019/6/18 下午 11:05:23] data(1) start...
[P1][2019/6/18 下午 11:05:24] data(1) end...
[P1][2019/6/18 下午 11:05:24] data(2) start...
[P2][2019/6/18 下午 11:05:24] data(1) start...
[P1][2019/6/18 下午 11:05:25] data(2) end...
[P1][2019/6/18 下午 11:05:25] data(3) start...
[P2][2019/6/18 下午 11:05:25] data(1) end...
[P2][2019/6/18 下午 11:05:25] data(2) start...
[P3][2019/6/18 下午 11:05:25] data(1) start...
[P1][2019/6/18 下午 11:05:26] data(3) end...
[P1][2019/6/18 下午 11:05:26] data(4) start...
[P1][2019/6/18 下午 11:05:27] data(4) end...
[P2][2019/6/18 下午 11:05:27] data(2) end...
[P1][2019/6/18 下午 11:05:27] data(5) start...
[P2][2019/6/18 下午 11:05:27] data(3) start...
[P3][2019/6/18 下午 11:05:27] data(1) end...
[P3][2019/6/18 下午 11:05:27] data(2) start...
[P1][2019/6/18 下午 11:05:28] data(5) end...
[P2][2019/6/18 下午 11:05:28] data(3) end...
[P2][2019/6/18 下午 11:05:28] data(4) start...
[P3][2019/6/18 下午 11:05:29] data(2) end...
[P3][2019/6/18 下午 11:05:29] data(3) start...
[P2][2019/6/18 下午 11:05:30] data(4) end...
[P2][2019/6/18 下午 11:05:30] data(5) start...
[P3][2019/6/18 下午 11:05:31] data(3) end...
[P3][2019/6/18 下午 11:05:31] data(4) start...
[P2][2019/6/18 下午 11:05:31] data(5) end...
[P3][2019/6/18 下午 11:05:33] data(4) end...
[P3][2019/6/18 下午 11:05:33] data(5) start...
[P3][2019/6/18 下午 11:05:35] data(5) end...
C:\Program Files\dotnet\dotnet.exe (process 4156) exited with code 0.
Press any key to close this window . . .
執行的結果:
- 第一筆資料完成時間: 4 sec (11:05:23 ~ 11:05:27)
- 全部的資料完成時間: 12 sec (11:05:23 ~ 11:05:35)
記憶體使用的狀況, 記憶體直升到 6GB 才掉下來:
跟 DEMO4 當對照組,一樣把筆數擴大到 20 筆,看看記憶體使用量, 記憶體飆升到 14GB:
如果就這些數據來看,DEMO4 跟 DEMO5 其實不相上下。但是如果只看 P1 全部完成的時間:
用 EXCEL 把這兩個 DEMO 畫成時序圖,視覺化更容易理解:
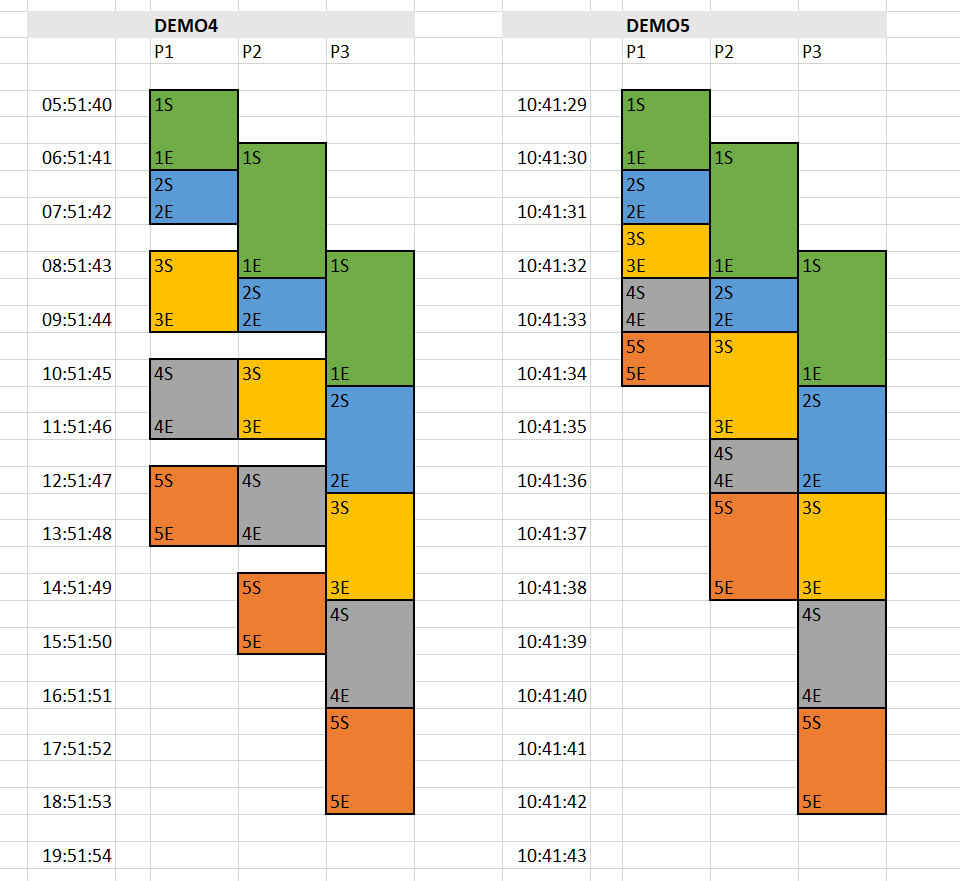
看出這種做法的特色了嗎? 強化了緩衝區的表現,每個階段都可以更緊湊的執行了。現在可以回頭來看一下 source code 了。先前 DEMO3 / DEMO4 的基礎都是用 IEnumerable
DEMO4 用了 async 的技巧,每個階段之間至多可以多一個半成品等著被下一關拿走,記憶體使用量大約是兩倍,平均 6GB 上下:
const int BLOCKING_COLLECTION_CAPACITY = 10;
static void Demo5()
{
foreach (var m in BlockedCollectionProcessPhase3(BlockedCollectionProcessPhase2(BlockedCollectionProcessPhase1(GetModels())))) ;
}
來看看每一關的程式碼:
public static IEnumerable<DataModel> BlockedCollectionProcessPhase1(IEnumerable<DataModel> models)
{
BlockingCollection<DataModel> result = new BlockingCollection<DataModel>(BLOCKING_COLLECTION_CAPACITY);
Task.Run(() =>
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase1(model);
result.Add(model);
}
result.CompleteAdding();
});
return result.GetConsumingEnumerable();
}
從介面來看,跟 DEMO3 完全一樣,都用 IEnumerable<DataModel> 當作 input / output, 不同的地方在於這兩點:
- 內部用
BlockingCollection取代直接yield return的操作。 - 為了模擬
yield return類似的效果,立即就return, 但是留一個背景執行緒持續的處理資料。
這段 code 我並沒有妥善處理好 thread, 這種寫法很容易造成孤兒的執行緒在背景亂竄,請勿直接拿去用在 production code …
這次 DEMO5 , 我直接用 BlockedCollection 來做每個階段之間的串接緩衝區,我設定最大的 Queue Size 是 10, 因此半成品數量大幅提升,跑到 14GB 之譜。不過這樣還看不大出來維持平穩的趨勢,我再把處理的筆數,從 20 筆擴大到 100 筆看看:
記憶體的增長,大概維持到 25GB 就停止了,穩定下來不會隨著資料持續處理而增加。
簡單的下個結論,DEMO5 善用了 BlockingCollection 當作每個階段之間的緩衝,有效的加速了每個階段的執行速度 (不會因為後面處理的慢而被卡住)。但是生產速度不協調,會造成每個關卡之間堆積過多半成品,因此這些效率是需要花費空間的,而且整體效果並沒有明顯提升。
DEMO 1 ~ 5 總結
同樣做個總結, DEMO4 的作法有 DEMO3 所有的優點,包含第一筆資料能最快的傳回;中間處理過程耗費的資源維持固定 (但是會比 DEMO3 多);程式碼的結構雖然變複雜了 (需要處理非同步的問題),但是至少還是切割得很獨立不會互相影響;同時改善了平行處理的部分,讓 P1 ~ P3 的處理更為緊湊,因此整體處理程序花的時間也大幅縮短。
DEMO5 則保有 DEMO4 的優點,寫法更簡潔易懂,我們也對中間的緩衝區有更好的控制,能讓每個階段更快的結束。不過代價是緩衝區越大,需要占用的記憶體也越大。看來 DEMO4 , DEMO5 都很理想,不過我想這樣的程式碼的門檻有點高… 加上 C# 已經是對 stream (yield return) 跟 async (async / await) 很友善的語言了,換做其他不直接支援的語言,這些問題你處理起來會更想哭… 不過別難過,伴隨 .NET Core 3.0 一起推出的 C# 8.0, 開始支援 async stream, 可以讓這件事變得更容易了。不過我還是打算講觀念,即使你沒用到 C# 最新語法也應該要能做得到。這部分我提供參考連結就好,請各位自行研究:
- Tutorial: Generate and consume async streams using C# 8.0 and .NET Core 3.0
- Async Streams in C# 8
- Before C# 8.0 Async Streams Come Out
CLI 的處理方式
我應該辦個投票嗎? 請告訴我你是否理解上面最後一個 DEMO5 … (我自己都想到頭快炸了)。要寫出這樣的 code 要求有點高,我有沒有簡便一點的方式? 有的。接下來要介紹的就是用 CLI 來解。
我畫一張簡單的架構圖,來說明一下 DEMO5 的架構:
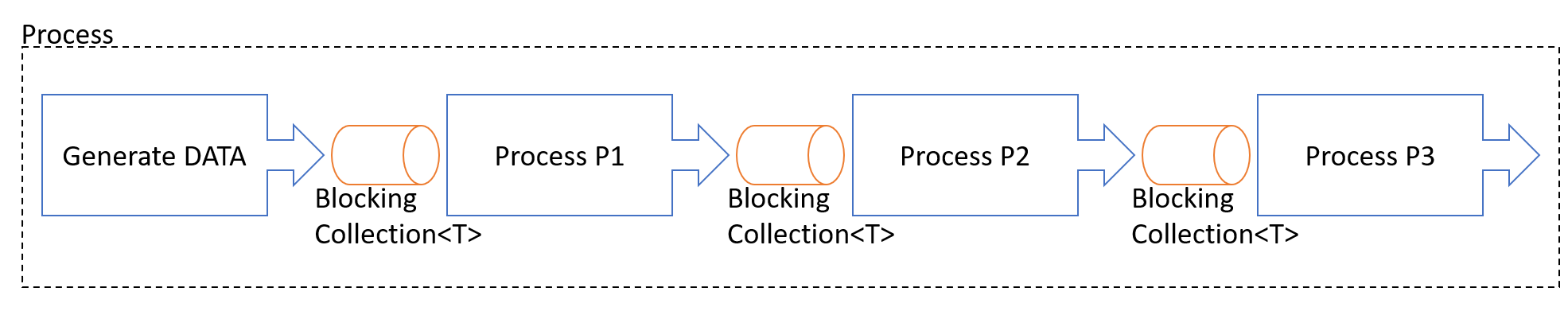
想想看,我們花了那麼多工夫,雖然加速 P1 整體的執行,不過全部的處理都還是在同一個 Console Project 啊,對於 OS 來說還是通通包在同一個 Process 內。提早 P1 的結束,不見得能夠完全把所有的資源都放掉。
如果 P1, P2, P3 都是個獨立的 CLI, 加速執行就有意義了 (OS 可以提早結束這個 Process 完全釋放資源), 中間的 buffer 自己處理也很麻煩,如果也能委託 OS 統一處理的畫就好了。那麼我就可以繼續寫跟 DEMO3 一樣簡單的 code, 還能有同樣的優點….。想像一下,換成 CLI 的話架構圖應該變這樣:
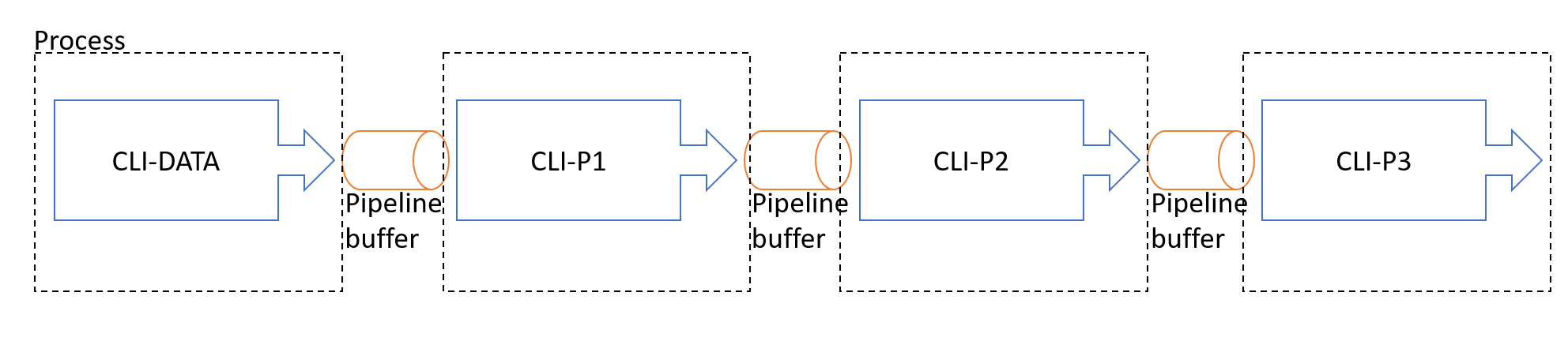
完全一樣的效果,完全一樣的架構,差別在於部分機制不需要你自己寫 code, 改成直接由 OS 幫你管理。沒錯,善用 CLI + PIPELINE 就有這些優點。我們接下來換 CLI 的方式來實作這個例子 POC 看看。
CLI: 獨立的 PROCESS
不同的 CLI,先天就是不同的 process, 很多時候分成 完全 獨立的兩個 program, 平行處理的問題就可以交給 OS 跟 shell 去傷腦筋就好,這就是我這段要講的重點。我想藉著 shell 本身提供的 STDIO 轉向 (就是 PIPELINE),搭配簡單的處理技巧,直接把 P1 ~ P3 從三個 method 拆成三個 console app, 然後再 shell script 裡面利用 PIPELINE 把三個 CLI 串起來,達成一樣的目的…
Shell 的 Pipe 是個很優雅的 IPC (Inter Process Communication) 通訊機制,這部分不論是 windows / linux 運作方式都很類似,我就用 windows 的命令提示字元示範。如果我下了這段指令:
c:\> tasklist.exe | find.exe "Console"
這段指令代表 shell 啟動了兩個 process: tasklist.exe 及 find.exe, 同時替這兩個 process 配置了 stdio (input, output, error)。中間的 | 就是 pipe, shell 會在背後準備 pipe buffer, 把前面指令的 standard output 的內容,透過 buffer 的調節,導引到後面指令的 standard input。透過 pipe 轉送 stdio, 你可以把它當作幾乎是及時的, I/O buffer 目的只是提高效能而已,在我們這篇文章的應用,其實不大需要擔心他。
回頭來看這個指令: tasklist.exe 是 CLI 版本的工作管理員,他會列出目前 windows 所有執行的 process list, 並且把這些內容輸出到 standard output. 如果你沒透過 pipe 轉向,那這些內容會直接顯示在 console 上面 (我只節錄片段):
D:\>tasklist
Image Name PID Session Name Session# Mem Usage
========================= ======== ================ =========== ============
System Idle Process 0 Services 0 8 K
System 4 Services 0 2,804 K
Secure System 72 Services 0 56,708 K
Registry 124 Services 0 73,152 K
smss.exe 560 Services 0 1,000 K
csrss.exe 772 Services 0 2,624 K
wininit.exe 876 Services 0 3,444 K
csrss.exe 884 Console 1 4,048 K
services.exe 948 Services 0 7,896 K
LsaIso.exe 972 Services 0 2,416 K
lsass.exe 980 Services 0 20,196 K
svchost.exe 764 Services 0 3,024 K
winlogon.exe 1028 Console 1 7,032 K
... (以下省略)
下一個指令 find.exe "Console" 則是從 standard input 或是指定的檔案內容,逐行搜尋是否有 “Console” 字樣? 如果有找到,就會把這行送到 standard output。因為 pipe 的關係, tasklist.exe 的所有輸出就會被 find.exe 指令過濾,只印出包含 “Console” 的那整行內容:
D:\>tasklist | find "chrome.exe"
chrome.exe 3456 Console 1 264,804 K
chrome.exe 3876 Console 1 5,596 K
chrome.exe 4060 Console 1 5,104 K
chrome.exe 5336 Console 1 163,980 K
chrome.exe 4700 Console 1 52,156 K
chrome.exe 11528 Console 1 10,424 K
chrome.exe 11544 Console 1 54,772 K
chrome.exe 12276 Console 1 50,748 K
chrome.exe 9836 Console 1 19,308 K
chrome.exe 11944 Console 1 12,984 K
chrome.exe 12944 Console 1 130,832 K
(以下省略)
OK,基本的介紹講完,開始要動手寫 CLI 了 (終於…) ! CLI 的版本,我們就直接從 PIPELINE 的版本開始了。
CLI-DATA, Data Source
既然都打算用 pipeline 的方式設計 CLI, 那麼我們就可以很明確地把幾個階段完全的隔開成獨立的 CLI。第一步是資料來源,如果要透過 STDIO 來溝通,那物件的序列化是必要的,我就直接選用 Json 格式了。
任何串流處理的原則都一樣,你要預期你的資料筆數是無限大,從頭到尾每個環節都需要接受這種處理模式 (接收一部份,處理一部份,輸出一部份)。因此這邊我用 jsonl (json line) 的格式來處理。其實就是一般的 json, 只是一行是一個獨立完整的 json 字串而已。
我開了個 CLI-DATA 的專案,把前面產生 DataModel 的部分搬過來:
static void Main(string[] args)
{
Random rnd = new Random();
byte[] allocate(int size)
{
byte[] buf = new byte[size];
rnd.NextBytes(buf);
return buf;
};
var json = JsonSerializer.Create();
for (int seed = 1; seed <= 5; seed++)
{
var model = new DataModel()
{
ID = $"DATA-{Guid.NewGuid():N}",
SerialNO = seed,
//Buffer = allocate(1024 * 1024 * 1024)
Buffer = allocate(16)
};
json.Serialize(Console.Out, model);
//Console.Out.WriteLine(JsonConvert.SerializeObject(model));
Console.Out.WriteLine();
}
}
再強調一次,每個環節都要顧好串流處理的要求,一個環節沒顧好整個程序就會掛掉。還記得前面 DEMO1 因為用了 .ToArray() 就讓整個記憶體往上飆的案例嗎? 這邊也有類似狀況。如果過去你為了方便,直接用 JsonConvert.SerializeObject() 的話,這邊碰到 1GB size 的物件就會爆掉了。請改成用 JsonSerializer, 讓他自己一點一點的序列化,一點一點的輸出到 STDOUT。
為了容易說明,我把 buffer size 改成 16bytes, 待會實測會調回 1GB。這段程式執行後會輸出這樣的資料:
{"Buffer":"z/AvKF+irJQDCp0QsL/mtw==","ID":"DATA-ef63e0b6e4fc487db71ad6ffae91ddf9","SerialNO":1,"Stage":0}
{"Buffer":"jm0vYujxmKWfvG/NhijKpg==","ID":"DATA-9890b9d0e2f24f7d92f5849d197c3e9a","SerialNO":2,"Stage":0}
{"Buffer":"0CoMiL2Z+rzntCOKjBCfTw==","ID":"DATA-82b83bb24494492f855311f51c6f64cf","SerialNO":3,"Stage":0}
{"Buffer":"rBtQh4Ivjd5YiYmjM98N2g==","ID":"DATA-5faac5f2115f4879876ed9604ebc09fe","SerialNO":4,"Stage":0}
{"Buffer":"QPdAhbNe+fRycnozzQ0Zjg==","ID":"DATA-fa299a5977ba4c83a12708a49820a42d","SerialNO":5,"Stage":0}
後面接手的其他 CLI,就都以這個格式作為標準的 STDIN 輸入了。
CLI-P1, Data Processing
資料源準備好了之後,接下來就是要在另一個 CLI 接收資料了。我先用蠢一點的方式,直接在 Main() 裡面接收。接收過程同樣要留意,你必須用串流的原則來處理,讀取一筆後就處理,然後釋放資源,再處理下一筆。這部分 P1 ~ P3 通通都一樣,我就拿 P1 當作代表了:
static void Main(string[] args)
{
var json = JsonSerializer.Create();
var jsonreader = new JsonTextReader(Console.In);
jsonreader.SupportMultipleContent = true;
while (jsonreader.Read())
{
var d = json.Deserialize<DataModel>(jsonreader);
DataModelHelper.ProcessPhase1(d);
}
}
同樣的,為了應付未知的資料筆數,你不能直接偷懶的使用 JsonConvert.Deserialize<DataModel>() … 這邊要自己從 Console.In 這資料源,建立 JsonTextReader, 然後逐筆 Deserialize, 直到結束為止。因為我們採用 jsonl 的結構,可能包含多筆 json 資料,因此要把 SupportMultipleContent 設為 true ..
測試結果 (我用 buffer size: 16 bytes):
[P1][2019/6/16 下午 02:31:28] data(1) start...
[P1][2019/6/16 下午 02:31:29] data(1) end...
[P1][2019/6/16 下午 02:31:29] data(2) start...
[P1][2019/6/16 下午 02:31:30] data(2) end...
[P1][2019/6/16 下午 02:31:30] data(3) start...
[P1][2019/6/16 下午 02:31:31] data(3) end...
[P1][2019/6/16 下午 02:31:31] data(4) start...
[P1][2019/6/16 下午 02:31:32] data(4) end...
[P1][2019/6/16 下午 02:31:32] data(5) start...
[P1][2019/6/16 下午 02:31:33] data(5) end...
這邊我用的指令是: dotnet CLI-DATA.dll | dotnet CLI-P1.dll, 用了 shell 的 pipe | 把兩個指令串接起來了。不過既然都切成兩個 CLI 了,理論上可以有更靈活的用法。
如果 CLI-DATA 這專案是從資料庫載入檔案,我測試過程一定要每次都讀資料庫嗎? 我把這串指令改變一下:
- 先一次性地把資料源輸出到文字檔:
dotnet CLI-DATA.dll > data.jsonl - 接著將文字檔的內容透過 pipe 轉給 CLI-P1:
type data.jsonl | dotnet CLI-P1.dll
我們可以得到一模一樣的結果,受惠於 I/O 轉向,我們有更容易地測試方式了。
CLI-P1 ~ P3 整合測試
接著,我們把 P2, P3 都改完,整個串起來測試一次看看。因為要串接,因此前面 P1 的程式碼,最後記得要把處理後的結果輸出到 STDOUT, 後面才串的到:
static void Main(string[] args)
{
var json = JsonSerializer.Create();
var jsonreader = new JsonTextReader(Console.In);
jsonreader.SupportMultipleContent = true;
while (jsonreader.Read())
{
var d = json.Deserialize<DataModel>(jsonreader);
DataModelHelper.ProcessPhase1(d);
json.Serialize(Console.Out, d);
}
}
至於跟 STDIN / STDOUT 無關的 LOG 訊息該怎麼輸出? 我利用了第三個不相關的管道: STDERR。這邊有興趣的可以看 ProcessPhaseN() 裡面的 code. 除了改輸出到 STDERR 之外就沒特別的了,這邊我就不花篇幅貼程式碼。
串起來一起測試吧! 整個資料流的結構應該是這樣:
CLI-DATA > CLI-P1 > CLI-P2 > CLI-P3 > nul
因為最後 CLI-P3 產出的結果沒人要接收了,直接印在畫面上又會影響我看 LOG,我先把最後的 STDOUT 輸出丟掉 (轉到 nul):
dotnet CLI-DATA.dll | dotnet CLI-P1.dll | dotnet CLI-P2.dll | dotnet CLI-P3.dll > nul
來看看輸出的 LOG:
[P1][2019/6/16 下午 02:43:27] data(1) start...
[P1][2019/6/16 下午 02:43:28] data(1) end...
[P1][2019/6/16 下午 02:43:28] data(2) start...
[P2][2019/6/16 下午 02:43:28] data(1) start...
[P1][2019/6/16 下午 02:43:29] data(2) end...
[P1][2019/6/16 下午 02:43:29] data(3) start...
[P2][2019/6/16 下午 02:43:29] data(1) end...
[P2][2019/6/16 下午 02:43:30] data(2) start...
[P3][2019/6/16 下午 02:43:30] data(1) start...
[P1][2019/6/16 下午 02:43:30] data(3) end...
[P1][2019/6/16 下午 02:43:30] data(4) start...
[P1][2019/6/16 下午 02:43:31] data(4) end...
[P1][2019/6/16 下午 02:43:31] data(5) start...
[P2][2019/6/16 下午 02:43:31] data(2) end...
[P2][2019/6/16 下午 02:43:31] data(3) start...
[P3][2019/6/16 下午 02:43:32] data(1) end...
[P3][2019/6/16 下午 02:43:32] data(2) start...
[P1][2019/6/16 下午 02:43:32] data(5) end...
[P2][2019/6/16 下午 02:43:33] data(3) end...
[P2][2019/6/16 下午 02:43:33] data(4) start...
[P3][2019/6/16 下午 02:43:34] data(2) end...
[P3][2019/6/16 下午 02:43:34] data(3) start...
[P2][2019/6/16 下午 02:43:34] data(4) end...
[P2][2019/6/16 下午 02:43:34] data(5) start...
[P2][2019/6/16 下午 02:43:36] data(5) end...
[P3][2019/6/16 下午 02:43:36] data(3) end...
[P3][2019/6/16 下午 02:43:36] data(4) start...
[P3][2019/6/16 下午 02:43:38] data(4) end...
[P3][2019/6/16 下午 02:43:38] data(5) start...
[P3][2019/6/16 下午 02:43:40] data(5) end...
各位觀眾,這就是成果了。你可以看到,雖然是三個完全獨立的 CLI, 每個 CLI 的程式碼都只有 10 行左右,但是透過 pipeline 的處理技巧,也可以達到串流處理的效果。我們比照 DEMO4 的作法,我用 EXCEL 把這 LOG 改用視覺化的方式呈現。兩張圖我擺再一起比較,由左至右分別是 DEMO3 , DEMO4 , DEMO5 , CLI PIPELINE:

有看出差別嗎? 我列一下幾個我從圖裡看出來的結論:
- 都能達到 PIPELINE 分工處理的目的
- 運用到 PIPELINE 技巧的就能平行處理
- CLI 的版本及 DEMO5 表現相當,這兩者的執行順序明顯較 DEMO3 及 DEMO4 為緊湊,中間少了間隔等待的時間。P1, P2 處理每一筆資料的過程中間隔較少
- 因為 (2) 的關係,CLI 版本的 P1, P2 整體執行結束的時間明顯縮短。
眼尖的讀者們,你們知道其中的差異嗎? 最主要的差異,在於 PUSH / PULL 的差別,另外就是 PIPE 中間提供了 buffer 帶來的效益。我們回頭來看 DEMO3 , DEMO4 , DEMO5 的主程式, 看起來都差不多:
static void Demo4()
{
foreach (var m in StreamAsyncProcessPhase3(StreamAsyncProcessPhase2(StreamAsyncProcessPhase1(GetModels())))) ;
}
知道為何最外面需要一個啥事都不做的 foreach 嗎? IEnumerator<T> 只是個導覽物件,他可以引導你順利的取得下一筆資料,因此你看他的 interface 定義很單純,就是 T MoveNext() 而已。這裡串的每個 method, 都只是傳回各自的 IEnumerator<T> 物件而已,等到你要的時候就才會觸動 method 內的程式碼,直到碰到一筆 yield return 為止。
因此,如果我的主程式少了最外面那圈 foreach, 會發生啥事? 大家都只把 IEnumerator<T> 準備好傳回去而已… 但是沒有任何資料會被產生或處理。直到最外圈的 foreach 對 StreamAsyncProcessPhase3() 傳回的 IEnumerator<T> 下達 MoveNext() 要求,P3 才驅動執行,直到 P3 的 yield return 為止。過程中,P3 需要由 P2 來的資料,因此也驅動了 P2 執行到 yield return, 然後驅動 P1, 然後驅動 GetModels() …
這種模式,是靠程式碼,在有需要的時候才往前一階 “拉” 資料過來,進而驅動整個體系運轉。所以回到上面那張時間軸的圖,你就可以理解每一階裡的程式碼在做啥事。先看看 DEMO3 的部分:
public static IEnumerable<DataModel> StreamProcessPhase1(IEnumerable<DataModel> models)
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase1(model);
yield return model;
}
}
看到了嗎? 這就是一層一層驅動的結構:
至於 DEMO4 改用非同步,實際上只是動一點技巧,用非同步的做法,在等這一筆的同時,自己也先準備下一筆資料,實際上這還是 PULL 的模式,只是每個 Phase 都可以提前多預備一筆資料而已。換句話說,每一階之間多了一點點 buffer (都預先多做一筆放著等) 就能提高並行處理的效率:
public static IEnumerable<DataModel> StreamAsyncProcessPhase1(IEnumerable<DataModel> models)
{
Task<DataModel> previous_result = null;
foreach (var model in models)
{
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
previous_result = Task.Run<DataModel>(() => { DataModelHelper.ProcessPhase1(model); return model; });
}
if (previous_result != null) yield return previous_result.GetAwaiter().GetResult();
}
不過 DEMO5 骨子裡就完全不同了。DEMO5 背後埋了背景執行緒,是不斷的產生資料餵 (PUSH) 給下一階的 buffer (BlockingCollection), 即使下一關仍然是用 foreach 的方式把資料拉 (PULL) 來用,中間透過了 BlockingCollection 雙向緩衝,因此能讓 BlockingCollection 滿了之前,讓兩端都用最佳效能運行。這種就要算是 PUSH 模式了。
再次複習一下 DEMO5 的程式碼片段:
public static IEnumerable<DataModel> BlockedCollectionProcessPhase1(IEnumerable<DataModel> models)
{
BlockingCollection<DataModel> result = new BlockingCollection<DataModel>(BLOCKING_COLLECTION_CAPACITY);
Task.Run(() =>
{
foreach (var model in models)
{
DataModelHelper.ProcessPhase1(model);
result.Add(model);
}
result.CompleteAdding();
});
return result.GetConsumingEnumerable();
}
想通了嗎? 最後來看別人對於 OS 提供的 pipeline 說明, 雖說是 Linux 的設計,不過這方面的設計方式各家 OS 都大同小異,可以參考:
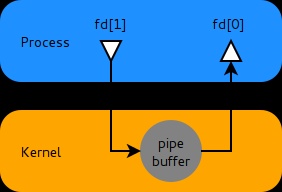
對比一下前面畫過的 DEMO5 架構圖,是不是很類似?
OS 層級的 pipeline, 是直接對 STDIO 直接提供 buffer, 他不管你有幾筆資料,只要空間夠塞你就可以先跑。比起我們固定一筆資料的 buffer 來的更靈活更有彈性,泛用性也更高,因此會看到更理想的執行順序。其實這背後隱含著一個成本,你有想過嗎?
如果 P1 跑得越快,P2 P3 追不上的話,那不就代表半成品就更多了? 半成品越多,就需要花費空間去暫存他。不論這空間是程式碼自己準備,還是 OS 的 pipeline buffer 準備…
是的,做任何事都是需要成本的。只是這個機制我們可以撿現成,OS 都幫我們準備好了,不用自己寫 code, 只是占用的空間是由 OS 提供維護而已… 不代表不需要成本。另外 OS 來管理 buffer, 會遠比你自己管理來的穩定可靠。舉例來說,如果 P1 ~ P3 的處理速度差異過大,造成巨量的資料都卡在 pipe buffer 怎麼辦? 這倒是不用擔心,STDIO 是 blocked I/O, 如果你的 pipeline buffer 真的要用光了,OS 會開始 block 前一關的 STDOUT 寫入,直到後面消化掉把 buffer 清出來為止。
其實這行為,就跟前面 DEMO4 的狀況類似,只是 OS 來執行這件事,精巧的程度遠高於我們用幾行 code 表達出來的 POC。我寫的 POC code, buffer size 固定是一筆資料,而 OS 有能力動態決定這空間的運用,看物件大小能塞幾個就塞幾個。
PIPELINE 效能與記憶體測試
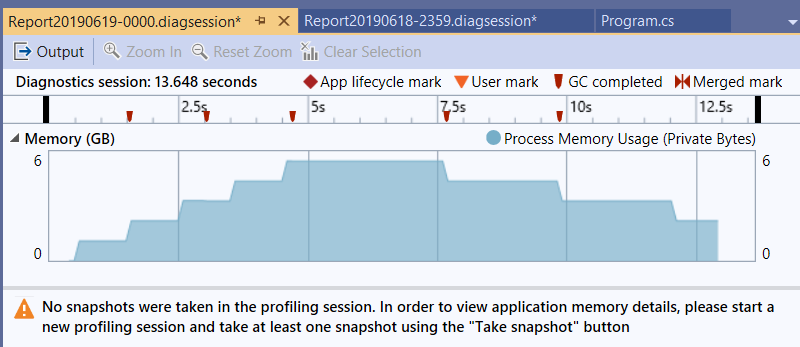
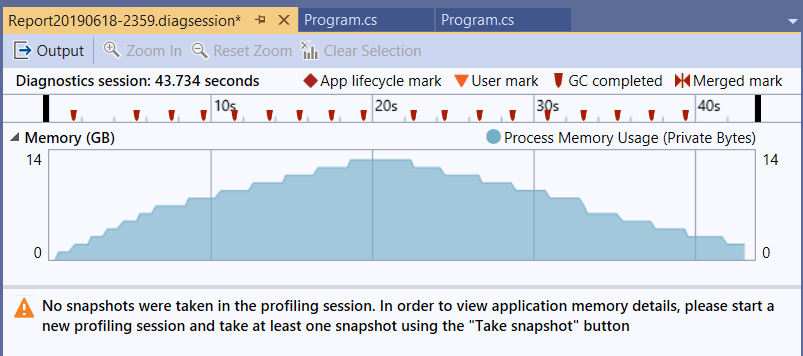
這邊情況有點尷尬,加上序列化的處理,一次 1GB 的物件要進行序列化與反序列化的壓力實在太大了,結果卡在 Json 無法消化就 OutOfMemoryException 了。雖然我覺得這應該還有辦法解決,不過 Json 序列化 / 反序列化單一大型物件的處理,不是我這篇的主題,我決定先跳過去了。後面的測試我最大就用到單一物件 (buffer size) 設定到 64MB 就好。
另一個尷尬的點,在於我前面用的 visual studio performance profiler, 只能監控 “單一” process, 像我這樣用 pipeline 一次串起四個 process 的案例就搞不定了。不過為了能衡量這數據,我決定換個方式來觀察。
我先做個基本測試,我用 4MB x 1000 個物件,個別測量一次 CLI-P1 ~ CLI-P3 各要花多少時間。為了降低 CLI-DATA 產生資料的干擾,我決定先把這些資料輸出到暫存檔案,直接用 I/O 轉向的方式來測試 CLI-P1 ~ P3:
先產生資料檔:
dotnet CLI-DATA.dll > data-4M-1000.jsonl
CLI-P1 執行過程的 memory usage:
測試指令:
type data-4M-1000.jsonl | dotnet CLI-P1.dll > nul
前 100 筆的執行時間: 108 sec
可以看到整個過程,雖說有上上下下,但是只要經過 GC 之後,大致上都會回覆到 160mb 的水位。至於 CLI-P2, P3 的程式碼通通都一樣,我就省略不測了。接下來直接測試整合測試:
type data-4M-1000.jsonl | dotnet CLI-P1.dll | dotnet CLI-P2.dll | dotnet CLI-P3.dll > nul
處理的 LOG,我截兩段,第一段是前 5 筆資料處理的歷程 (我把 P1 data(5) 紀錄標上 * 號), P1 跟 P3 的處理速度大概只領先 2 筆。這趨勢一直到 100 筆都一樣:
[P1][2019/6/16 下午 09:37:08] data(1) start...
[P1][2019/6/16 下午 09:37:09] data(1) end...
[P2][2019/6/16 下午 09:37:09] data(1) start...
[P1][2019/6/16 下午 09:37:09] data(2) start...
[P1][2019/6/16 下午 09:37:10] data(2) end...
[P2][2019/6/16 下午 09:37:11] data(1) end...
[P3][2019/6/16 下午 09:37:11] data(1) start...
[P2][2019/6/16 下午 09:37:12] data(2) start...
[P1][2019/6/16 下午 09:37:13] data(3) start...
[P3][2019/6/16 下午 09:37:13] data(1) end...
[P1][2019/6/16 下午 09:37:14] data(3) end...
[P2][2019/6/16 下午 09:37:14] data(2) end...
[P3][2019/6/16 下午 09:37:14] data(2) start...
[P2][2019/6/16 下午 09:37:14] data(3) start...
[P1][2019/6/16 下午 09:37:14] data(4) start...
[P1][2019/6/16 下午 09:37:15] data(4) end...
[P2][2019/6/16 下午 09:37:16] data(3) end...
[P3][2019/6/16 下午 09:37:16] data(2) end...
[P3][2019/6/16 下午 09:37:16] data(3) start...
[P2][2019/6/16 下午 09:37:16] data(4) start...
* [P1][2019/6/16 下午 09:37:16] data(5) start...
* [P1][2019/6/16 下午 09:37:17] data(5) end...
[P2][2019/6/16 下午 09:37:18] data(4) end...
[P3][2019/6/16 下午 09:37:18] data(3) end...
再來是我要觀察的第 100 筆前後完整的歷程,一樣處理速度落差大概只有 2 筆:
[P3][2019/6/16 下午 09:40:53] data(97) end...
[P3][2019/6/16 下午 09:40:53] data(98) start...
[P2][2019/6/16 下午 09:40:53] data(99) start...
* [P1][2019/6/16 下午 09:40:54] data(100) start...
* [P1][2019/6/16 下午 09:40:55] data(100) end...
[P2][2019/6/16 下午 09:40:55] data(99) end...
[P3][2019/6/16 下午 09:40:55] data(98) end...
[P3][2019/6/16 下午 09:40:56] data(99) start...
* [P2][2019/6/16 下午 09:40:56] data(100) start...
[P1][2019/6/16 下午 09:40:56] data(101) start...
[P1][2019/6/16 下午 09:40:57] data(101) end...
* [P2][2019/6/16 下午 09:40:57] data(100) end...
[P3][2019/6/16 下午 09:40:58] data(99) end...
* [P3][2019/6/16 下午 09:40:58] data(100) start...
[P2][2019/6/16 下午 09:40:58] data(101) start...
[P1][2019/6/16 下午 09:40:58] data(102) start...
[P1][2019/6/16 下午 09:40:59] data(102) end...
[P2][2019/6/16 下午 09:41:00] data(101) end...
* [P3][2019/6/16 下午 09:41:00] data(100) end...
[P3][2019/6/16 下午 09:41:00] data(101) start...
[P2][2019/6/16 下午 09:41:00] data(102) start...
前 100 筆的執行時間: 232 sec
雖然沒辦法用 visual studio 的 performance profiler 監控記憶體使用狀況,但是從工作管理員可以追到一些蛛絲馬跡:

看的出來,在 OS 看到的是四個 process, 包含由 cmd.exe 執行的 type …. 指令,以及個別執行的 dotnet.exe 指令。我特地把工作管理員的 “command line” 欄位打開,大家可以看的到執行時的命令列參數,也看的到 Memory usage, dotnet 的三個 process 大都維持在 170mb 上下,跟前面觀察到的雷同。
同樣的測試,我把物件的 size 調整成 16 bytes 就好。我想看看如果是小型物件,使用 pipeline 是否有助於提升效率?
我使用的指令 (就直接貼一起了), 改完 code 後重跑一次:
dotnet CLI-DATA.dll > data-16B-1000.jsonl
type data-16B-1000.jsonl | dotnet CLI-P1.dll | dotnet CLI-P2.dll | dotnet CLI-P3.dll > nul
工作管理員的狀況, dotnet 三組 process 的記憶體使用量都穩定的維持在 5MB 上下:

當 P1 跑到 1000 筆的時候, P2 大約跑到 959 筆, P3 大約跑到 918 筆。 這段時間的紀錄:
[P1][2019/6/16 下午 10:27:32] data(999) end...
[P1][2019/6/16 下午 10:27:32] data(1000) start...
[P3][2019/6/16 下午 10:27:33] data(917) end...
[P3][2019/6/16 下午 10:27:33] data(918) start...
[P2][2019/6/16 下午 10:27:33] data(958) end...
[P2][2019/6/16 下午 10:27:33] data(959) start...
[P1][2019/6/16 下午 10:27:33] data(1000) end...
[P2][2019/6/16 下午 10:27:34] data(959) end...
[P2][2019/6/16 下午 10:27:34] data(960) start...
[P3][2019/6/16 下午 10:27:35] data(918) end...
[P3][2019/6/16 下午 10:27:35] data(919) start...
[P2][2019/6/16 下午 10:27:36] data(960) end...
[P2][2019/6/16 下午 10:27:36] data(961) start...
[P3][2019/6/16 下午 10:27:37] data(919) end...
[P3][2019/6/16 下午 10:27:37] data(920) start...
[P2][2019/6/16 下午 10:27:37] data(961) end...
往前尋找 log, 從程式啟動開始,P1 處理速度就一直領先, 大約在 P1 120 筆左右,P2 79筆, P1 / P2 的差距就不再擴大了 (40):
[P1][2019/6/16 下午 09:58:48] data(119) end...
[P1][2019/6/16 下午 09:58:48] data(120) start...
[P2][2019/6/16 下午 09:58:49] data(79) end...
[P2][2019/6/16 下午 09:58:49] data(80) start...
[P1][2019/6/16 下午 09:58:49] data(120) end...
[P1][2019/6/16 下午 09:58:49] data(121) start...
[P3][2019/6/16 下午 09:58:50] data(59) end...
[P3][2019/6/16 下午 09:58:50] data(60) start...
[P2][2019/6/16 下午 09:58:50] data(80) end...
[P2][2019/6/16 下午 09:58:50] data(81) start...
[P1][2019/6/16 下午 09:58:50] data(121) end...
[P1][2019/6/16 下午 09:58:50] data(122) start...
[P1][2019/6/16 下午 09:58:51] data(122) end...
[P2][2019/6/16 下午 09:58:52] data(81) end...
[P1][2019/6/16 下午 09:58:52] data(123) start...
[P2][2019/6/16 下午 09:58:52] data(82) start...
[P3][2019/6/16 下午 09:58:52] data(60) end...
同樣的, P1 跑到 201 筆時, P2 160 筆, 此時 P2 / P3 的差距也不再擴大了 (40筆):
[P1][2019/6/16 下午 10:00:46] data(201) start...
[P3][2019/6/16 下午 10:00:46] data(117) end...
[P3][2019/6/16 下午 10:00:46] data(118) start...
[P2][2019/6/16 下午 10:00:47] data(157) end...
[P2][2019/6/16 下午 10:00:47] data(158) start...
[P1][2019/6/16 下午 10:00:47] data(201) end...
[P2][2019/6/16 下午 10:00:48] data(158) end...
[P2][2019/6/16 下午 10:00:48] data(159) start...
[P3][2019/6/16 下午 10:00:48] data(118) end...
[P3][2019/6/16 下午 10:00:48] data(119) start...
[P2][2019/6/16 下午 10:00:50] data(159) end...
[P2][2019/6/16 下午 10:00:50] data(160) start...
[P3][2019/6/16 下午 10:00:50] data(119) end...
[P3][2019/6/16 下午 10:00:50] data(120) start...
[P2][2019/6/16 下午 10:00:51] data(160) end...
[P2][2019/6/16 下午 10:00:51] data(161) start...
[P1][2019/6/16 下午 10:00:51] data(202) start...
[P1][2019/6/16 下午 10:00:52] data(202) end...
[P1][2019/6/16 下午 10:00:52] data(203) start...
[P3][2019/6/16 下午 10:00:52] data(120) end...
看起來每一階的 pipeline buffer, 大致上就是能容許放上 40 筆資料。
至於 P1 最多可以領先多少筆? 我程式碼的設定是 P1 每處理一筆要 1000 msec, P2 1500 msec, P3 2000 msec, 理論上都全速執行的話,P1 應該是 P2 的兩倍,到 1000 筆處理完的時候,P1 應該能領先 500 筆左右。不過實際上狀況,領先的幅度不會無限制擴大,會受限於中間的 pipeline buffer 大小。用實驗可以推測這 buffer 大致上就是能放 40 筆資料的程度。超過這限制時,P1 的產出開始寫不進 STDOUT, 因而被 blocked 速度慢下來了 (要等 P2 P3)…
如果我用 P1 120 筆當作分界點,來看 P1 在那前後的處理速度 (我跳過前後 10 筆, 各抓 10 筆計算總執行時間):
- 之前 (101 ~ 110): 10 sec
- 之後 (131 ~ 140): 14 sec (受限於 P2 的速度)
如果我用 P1 200 筆當作分界點,來看 P1 在那前後的處理速度 (我跳過前後 10 筆, 各抓 10 筆計算總執行時間):
- 之前 (181 ~ 190): 15 sec
- 之後 (211 ~ 220): 19 sec (受限於 P3 的速度)
當 P1 已經把全部的資料 1000 筆都跑完,而 P2 P3 還沒處理完的時候,這時 OS 已經可以把 P1 process 結束掉了,P1 如果有占用任何資源或是連線,就會提早完全被釋放掉。可以想像一下,讓 P1 全速跑完,搞不好整體還能降低對 DB 或是其他系統的負擔。我在看到 P1 1000 end 的訊息之後,重新截取一次工作管理員的畫面,證實 CLI-P1 的 process 已經完全結束了:
了解這些有甚麼好處? 好處可多了,你會有更多的機會做好最佳化。舉例來說,如果執行這些任務時,P1 需要停掉網站,P2 P3 不需要,可以在線上處理的話,我就可以先用全速把 P1 跑完 (處理結果我輸出到檔案,事後再轉向給 P2 P3 接手),這時我就可以用更短的停機時間完成任務。或是後面階段出錯,我有保留 P1 的結果,我也可以更容易得重新執行一次 P2 P3 …
其實這些都是 pipe 抽象化帶來的好處,我相信這些場景,後端工程師或多或少都會遭遇到的,只是你當時有沒有想到好好的開發 CLI tools 能有這些幫助而已。
PIPELINE 其他應用
其實因為這個案例,我想到不少東西可以一起談的,不過實在是寫不完,我留一些 hint 跟 reference, 有興趣的朋友可以自己參考, 或是在 FB 上找我聊聊。
I/O 導向分散式處理:
這點其實不難理解。如果你都能利用 pipeline 把工作切割在不同的 process 分頭執行,I/O 導向的部分如果能透過 ssh 那樣的機制跨越網路的話,你的批次作業要能跨機器處理還有什麼困難呢? 只要 shell 幫你重新導向 STDIO 就夠了。
最少,你會有能力透過輸出檔案做到一樣的事情,而這些能力都不需要你改寫任何一行 code, 只要你在設計之初就有明確遵循走 STDIO 即可。這也是為何那麼多成熟的 CLI tools 通通都走 STDIO 的原因。
能自由選擇批次或是管線處理:
不過就是檔案嘛! 這次案例的 CLI 你能自由的直接串 CLI-DATA —- CLI-P1 … 你也可以把 CLI-DATA 轉到檔案後,直接從檔案開始,不用重新執行一次 CLI-DATA … 透過管線的操作,你能夠很容易的 “只” 重複其中某個階段,而不用整個重來。甚至有些指令 (例如: tee) 還可以讓你更靈活的操作 pipe, 能把資料流一分為二。這些用法就讓你自行體會了。
dotnet tool:
由於 Microsoft 開始大規模的擁抱 linux, 原本在 windows 世界一直不是主角的 CLI, 在 .net core 的世界也開始改觀了。Microsoft 在 .NET core 特別加入了 .NET tool 的設計, 讓你 CLI 的開發,部署都有標準規範。簡單的說你可以把你的 CLI 打包成 NuGet package, 然後用 dotnet tool install 指令來安裝,然後… 就可以開始使用了 :D
有興趣的可以參考 Microsoft 官方文件: 使用 .NET Core CLI 建立 .NET Core 通用工具
總結
又是一大篇!
寫到這邊總算又把一個主題完整的交代結束了。我一直認為 “後端工程師” 是很有挑戰的職位,因為你開發出來的系統可能要面對各種考驗。寫 WEB / API,可能要面對巨大流量的考驗;寫背景程式或是背景服務,也需要面對 long running 的挑戰,不允許有 memory leak, 處理大量資料又要有效率 (要顧慮時間與空間的複雜度),同時還要面對各種平行處理的挑戰,搞定 lock, race condition 等等問題。
也因此,我不斷地強調 “基礎知識” 是非常重要的。其實我寫的東西,新東西並不多,我很少寫 “框架” 類的文章。我頂多偶爾用一下 C# 新語法而已,因為 C# 是個很洗鍊的語言,往往新的語法可以更簡潔的表達出我腦袋裡想的處理流程。我文章內同樣的例子,換做其他語言來實作,應該行數都至少是兩倍以上吧! 我愛用 .NET, 主要原因就是 C# 而已。
回到基礎知識,你會發現善用基礎知識,你可以不需要依靠肥大的框架,就能有效的解決各種問題。這對團隊絕對是件好事,如果你能好好利用這些技能的話。我最忌諱的場景,就是團隊碰到某個問題,就搬出框架來 (殺雞用牛刀)。框架之所以會成為框架,就是他累積了相當多的細節在背後。你當然可以用他,但是沒充分了解一個框架前就貿然採用是很危險的,因為框架的學習,除錯,替換成本都很高,你應該在使用的效益遠大於使用成本時才該使用他。多累積基礎知識,你可以降低對框架的依賴。
這篇我最後沒有把他歸類在微服務架構系列的文章,也沒有把他歸類在架構面試題系列,但是你一定會在這些領域用的到這篇文章的知識。希望內容對大家有幫助,任何意見都歡迎在我的粉絲團留言給我 :)
