好久沒寫文章了,看了一下上一篇的日期… 嚇,再撐幾天就 10 個月了 =_=, 週末看了 darkthread 的這篇文章: 當心LINQ搜尋的效能陷阱,想說 LINQ to SQL, LINQ to Entity Framework, LINQ to … 都支援索引, 沒道理 LINQ to Object 不行啊, 一定只是沒人補上實作而已.. 動了這個念頭之後, 接下來的時間就都在研究這些…
回到主題,年紀夠大的網友,大概都還聽過 Embedded SQL 吧? 當年用 C/C++ 要存取資料庫,實在不是件簡單的事… 光是那堆 initial database connection 的動作就搞死人了,因此有些開發工具廠商,就搞出了 Embedded SQL 這種內嵌在程式語言內的 SQL .. 貼一段 CODE,看起來大概像這樣:
Embedded SQL sample code:
/* code to find student name given id */
/* ... */
for (;;) {
printf("Give student id number : ");
scanf("%d", "id);
EXEC SQL WHENEVER NOT FOUND GOTO notfound;
EXEC SQL SELECT studentname INTO :st_name
FROM student
WHERE studentid = :id;
printf("Name of student is %s.\n", st_name);
continue;
notfound:
printf("No record exists for id %d!\n", id);
}
/* ... */
有沒有跟現在的 LINQ 很像? CODE 就不多解釋了,這類的工具,大都是遵循這樣的模式: 透過編譯器 (或是 code generator / preprocessor),將 query language 的部份代換成一般的 data access code,最後編譯成一般的執行檔,執行起來就有你預期的效果…
看到 darkthread 探討 LINQ to Object 效能問題之後,第一個反應就是:
“該怎麼替 LINQ to Object 加上索引??”
LINQ 這堆指令,最終是會被翻譯成 extension method, 而這些 extension method 是可以自訂的,就先寫了一個小程式試看看..
public class IndexedList : List<string>
{
}
public static class IndexedListLinqExtensions
{
public static IEnumerable<string> Where(this IndexedList context, Expression<Func<string, bool>> expr)
{
Console.WriteLine("My code!!!");
foreach (string value in context.Where(expr)) yield return value;
}
}
class Program
{
static void Main(string[] args)
{
IndexedList list1 = new IndexedList();
// init list1 ...
foreach (string value in (from x in list1 where x == "888365" select x)) {
Console.WriteLine("find: {0}", value);
}
}
}
程式很簡單,只是做個 POC,證明這段 CODE 會動而已。從 List<string> 衍生出一個新類別: IndexedList, 然後針對它定義了專屬的 Extension method: Where(...), 然後試著對 IndexedList 這集合物件,用 LINQ 查詢… 果然 LINQ 在執行 where x == “888365” 這語句時,會轉到我們自訂的 extension method !
接下來的工作就不是那麼簡單了,我自認很愛挖這些 framework 的設計,又自認 C# 語法掌握能力也不差,結果我也是花了一些時間才摸清楚它的來龍去脈… 事情沒這麼簡單,所以我做了極度的簡化…
首先,我只想做個 POC (Proof of concept), 證明可行就好, 完全沒打算把它做成可用的 library .. 因為在研究的過程中,早已找到有人在做這件事了 (i4o, index for objects)。為了讓 code 簡短到一眼就看的懂的程度,我的目標定在:
- 查詢對相只針對
List<string>處理,不做泛型及自訂索引欄位。 - 查詢只針對
==做處理。如下列 LINQ 語句的 where 部份:from x in list1 where x == "123456" select x - 條件只限於
x == "123456", 只提供==運算元,只提供常數的比對,常數只能放在右邊…
接下來就是索引的部份了,因為 where 只處理 == 這種運算,也不用排序了,採用 HashSet 就很夠用了,速度又快又好用,時間複雜度只有 O(1) .. 看起來很理想,於是剛才的 Sample Code 就可以改成這樣:
IndexedList : 加上索引的 List<string> 實作
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Linq.Expressions;
namespace IndexedLinqTest
{
public class IndexedList : List<string>
{
public readonly HashSet<string> _index = new HashSet<string>();
public void ReIndex()
{
foreach (string value in this)
{
this._index.Add(value);
}
}
}
public static class IndexedListLinqExtensions
{
public static IEnumerable<string> Where(this IndexedList context, Expression<Func<string, bool>> expr)
{
if (expr.CanReduce == false "" expr.Body.NodeType == ExpressionType.Equal)
{
BinaryExpression binExp = (BinaryExpression)expr.Body;
string expectedValue = (binExp.Right as ConstantExpression).Value as string;
if (context._index.Contains(expectedValue)) yield return expectedValue;
}
else
{
//return context.Where(expr);
foreach (string value in context.Where(expr)) yield return value;
}
}
}
}
程式碼稍等再說明,先來看看怎麼用! darkthread 的作法真不錯用,借兩招來試試… 程式大概執行這幾個步驟:
- 準備 10000000 筆資料,用亂數打亂,建立 list1 (含索引, type:
IndexedList) 及 list2 (不含索引, type:List<string>) - 呼叫
list1.ReIndex(), 替 list1 重建索引 (HashSet), 記錄建立索引花費的時間 - 分別對list1, list2進行LINQ查詢,查出四筆指定的資料,計算查詢花費的時間
直接來看看程式碼吧:
測試 Indexed LINQ 的程式碼
class Program
{
static void Main(string[] args)
{
Stopwatch timer = new Stopwatch();
IndexedList list1 = new IndexedList();
list1.AddRange(RndSeq(8072, 10000000));
List<string> list2 = new List<string>();
list2.AddRange(list1);
timer.Restart();
list1.ReIndex();
Console.WriteLine("Build Index time: {0:0.00} msec", timer.Elapsed.TotalMilliseconds);
Console.WriteLine("\n\n\nQuery Test (indexed):");
timer.Restart();
foreach (string value in (from x in list1 where x == "888365" select x))
Console.WriteLine("find: {0}", value);
foreach (string value in (from x in list1 where x == "663867" select x))
Console.WriteLine("find: {0}", value);
foreach (string value in (from x in list1 where x == "555600" select x))
Console.WriteLine("find: {0}", value);
foreach (string value in (from x in list1 where x == "888824" select x))
Console.WriteLine("find: {0}", value);
Console.WriteLine("Query time: {0:0.00} msec", timer.Elapsed.TotalMilliseconds);
Console.WriteLine("\n\n\nQuery Test (non-indexed):");
timer.Restart();
foreach (string value in (from x in list2 where x == "888365" select x))
Console.WriteLine("find: {0}", value);
foreach (string value in (from x in list2 where x == "663867" select x))
Console.WriteLine("find: {0}", value);
foreach (string value in (from x in list2 where x == "555600" select x))
Console.WriteLine("find: {0}", value);
foreach (string value in (from x in list2 where x == "888824" select x))
Console.WriteLine("find: {0}", value);
Console.WriteLine("Query time: {0:0.00} msec", timer.Elapsed.TotalMilliseconds);
}
private static IEnumerable<string> SeqGenerator(int count)
{
for (int i = 0; i < count; i++) yield return i.ToString();
}
private static IEnumerable<string> RndSeq(int seed, int count)
{
Random rnd = new Random(seed);
foreach (string value in (from x in SeqGenerator(count) orderby rnd.Next() select x)) yield return value;
}
}
而程式執行的結果:
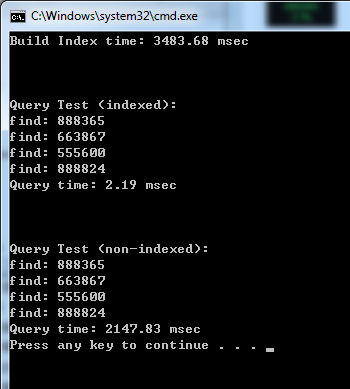
貼一下參考配備 (這是炫耀文…),給大家體會一下速度…
CPU: INTEL i7 2600K, INTEL Z68 主機板 RAM: 8GB OS: Windows 7 (x64)
看起來藉著 HashSet 當索引,來加速 LINQ 查詢的目的已經達到了。不加索引需要 2147.83 ms, 而加上索引只需要 2.19ms … 兩者時間複雜度分別是 O(1) v.s. O(n), 要是資料的筆數再往上加,兩者的差距會更大…
回過頭來看看程式碼吧! 關鍵在 LINQ 的 Extension 上面:
支援索引的 LINQ extension: where( )
public static IEnumerable<string> Where(this IndexedList context, Expression<Func<string, bool>> expr)
{
if (expr.CanReduce == false "" expr.Body.NodeType == ExpressionType.Equal)
{
BinaryExpression binExp = (BinaryExpression)expr.Body;
string expectedValue = (binExp.Right as ConstantExpression).Value as string;
if (context._index.Contains(expectedValue)) yield return expectedValue;
}
else
{
//return context.Where(expr);
foreach (string value in context.Where(expr)) yield return value;
}
}
line 1 的宣告,限制了只有對 IndexedList 型別的物件,下達 WHERE 語句的情況下,才會交由你的 extension method 執行。而 Microsoft 會把整個 where 語句,建構成 Expression 這型別的物件。
前面我下的一堆條件,像是只能用 == 運算元,只針對字串常數比對等等,就都寫在 line 3 的判段式了。基本上只要不符合這些條件,就會跳到 line 12, 索引等於完全無用武之地了。
要是符合使用索引的條件,則程式會進到 line 5 ~ line 7. 程式會透過 HashSet 去檢查要找的 data 是否存在於 List 內? 前面提過了,用 HashSet.Contains(...) 來檢查 (O(1)),效能遠比 List<string>.Contains(...) 的效能 (O(n) ) 好的多。
實驗的結果到此為止,很明顯了,索引的確發揮出效果了,不過老實說,這段 code 真的沒什麼實用的價值… 哈哈,與其這樣繞一大圈,用 LINQ 很帥氣的查資料,還不如直接用程式找 HashSet 就好… 這只是證明 it works, 不繼續完成它,主要的原因是已經有人做了,而且做的比我好 XD! 需要的人可以參考看看 i4o 這套 library. 想體會這東西怎麼用,可以先看看作者的 BLOG,這篇是使用範例:
http://staxmanade.blogspot.com/2008/12/i4o-indexspecification-for.html
要下載的話,它的 project hosted 在 codeplex: http://i4o.codeplex.com/
