-
個人檔案 + 版本控制...
自從過年時換了 SERVER 的作業系統,加上過年前 NOTEBOOK 掛掉換 X40 + SSD 之後,這幾個月都陷在東換換西調調的狀態中 @_@, 好在換了 2008 之後,有 Hyper-V 的幫忙,問題簡化不少...。不過今天要講的倒是很不起眼的小東西: SVN (Subversion)。
SVN 這種版本控制系統,通常是用來作程式碼的版本管理。也對啦,除了軟體開發之外,其它場合好像也不大需要這麼複雜的版本機制。不過這類系統弄多了,平常在非軟體開發的場合,也發現其實很多時後都有檔案版本問題要處理。像是平常的文件 (WORD),簡報 (PPT) 等等,都會作好一份通用的,碰到 A 客戶就改一改拿來用,B 客戶再改一改... 這不就是 brench / merge 之類的問題嘛? 所以我一直在找這樣的 solution,看看有沒有適合一般使用的。不過到現在,也換了好幾種作法,歷年來試過的作法有好幾種:
- VSS (Microsoft Visual SourceSafe 5.0)
這個有用過的人,看版本號碼就知道有多古老了… 不過真正在用是 6.0 版開始。因為工作上會用的到,就順便拿來用了。它的好處是很簡單,搞懂它的邏輯就很容易上手。架設也簡單,完全是 File Based, 不需要架設專用的 Server。不過這也是後來換掉它的原因之一。
它的使用方式,是以嚴格的控制為主要邏輯。什麼意思? 意思是你不能隨意更改檔案,要開使改檔案之前,要先 check-out 才能開始改。這樣的邏輯就是要避免未來一連串的版本衝突 (conflict) 及合併 (merge) 帶來的問題。 以軟體開發的角度來看,這樣的作法還不錯,整個團隊的開發是值得這樣作的。不過拿來管理個人檔案的話,就太過頭了。個人檔案不大會發生 LOCK 的問題,就是我改你也改,最後存檔總會有一個人的資料被蓋掉... 不過,如果我是大老闆,有十幾個秘書在幫我打雜的話就難說了 [H]
- VSS (Windows Volume Shadow Copy Service)
Visual Source Safe 用了之後,發現障礙多於它帶來的優點 (以處理一般文件而言)。主要的缺點是,VSS 透過網路 / Internet / VPN 使用的速度實在是龜到可以,雖然後來 Microsoft 推出了 LAN Boost Service (還是很慢),也另外推出了 HTTP / Web Service 的存取方式 (只能透過 Visual Studio) 速度也不快。另一個缺點是一定要先開 VSS Explorer / Visual Studio, 我不過只是想開個 WORD 檔啊...
所以後來換了另一個角度找 solution, 就試用了 windows 2003 內建的 VSS (Volume Shadow Copy Service), 替代版本控制用的軟體。它是做在 File System 層次上的機制,用了 Copy On Write (COW.. 這是縮寫,不是在罵人...) 的方式,做版本的差異控制。因此只要把檔案放在開啟 VSS 的磁碟機,完全不用更改任何使用習慣..。
但是太自動的東西還是不適用。這種作法主要的問題在於版本太不精確了。VSS 仰賴定期作快照 (snapshot) 來作版本的管理。定期做的快照,留下來的版本很可能是無意義的,你也無法針對特定檔案的特定版本作註記 or 回複... 另外自動的快照也無法選則那些檔案要進版本,那些要退出。總之一切全自動,沒有什麼好選的。很簡單,但是功能也很有限。
不過即使如此,一般情況下也夠用了,操作也夠簡單,當作第二種保護機制也不錯。這個 solution 我也用了好一陣子...。
- TFS (Team Foundation Server)
老實說,連一般小型軟體開發,用到 TFS 都太肥了一點,自己的檔案管理用到這個真是太離譜了... 哈哈,因此這個 solution 只是閃過念頭而已,跟本沒實際裝起來試過。用這個方案,工具會是個大問題... 用的時後得開個 Visual Studio, SERVER 還得裝一大票軟體 (IIS, TFS, SQL + Reporting, SharePoint Team Service, AD…)
- USB DISK + PortableApps
其實這個算不上是個 SOLUTION,只不過順便把它列上來,待會說明用。某次無意間,同事告訴我 PortableApps.com 這個工具,它是個灌在 USB 隨身碟上面的工具 & 一些綠色軟體,有自己專用的 "開始" 選單,方便你插上隨便一台電腦,就把它當作你自己的 PC 一樣使用... 老實說還不錯用 (Y),我就試著用一陣子,把所有個人相關的資料都移到上面了。現在的工作環境有點複雜,公司一台 PC,家裡一台 PC,偶爾還需要用 notebook 去客戶那邊簡報 (咳,就是我那台只有 8GB SSD 的 X40,正好沒地方放檔案)
用了一陣子還不錯,不過碰到的又是很常見的問題: 檔案掉了怎辦? 備份問題? 讀寫速度問題? Flash Disk 寫入次數限制問題... 不外乎常備份,每天一份 ZIP 檔,用苦力作好版本控制…
- USB DISK + SVN
最後,就是現在用的方案了... 主要是補 (4) 的不足: 一般的定期 ZIP 備份就跟快照一樣,事後要追出變更其實很麻煩,每次變更想加個註解又更麻煩了。當然搭配 Visual Source Safe 這種工具,把 Working Folder 指到 USB DISK 上就可以兩全齊美了。
不過使用便利則是另一個問題,我希望能夠找個無腦一點的工具,不需事先 check-out (lock) 的動作就可以開始編輯,改完再決定 check-in (commit) 或是 undo (revert) 的模式最好。用了 USB DISK 就是希望能拔來拔去,如果必需配合特定工具 & 要即時連上 SERVER,那就有點麻煩... 想看看,當我 USB DISK 插到 NOTEBOOK 帶到客戶那邊去,都按兩下打開 PPT 在簡報了,臨時要改幾個字,用 VSS 的話,我得關掉 PPT,打開 VSS,CHECK-OUT,打開PPT,修改...
所以後來的首選就變成 SVN 了。SVN 因應 internet / open source project 的開發模式,採取的就跟 Microsoft 是不同的策略,就是先改再說。SVN 賭你不會多人同時編同一個檔案,就算會,也不會編同一段 code … 真的碰到就再人工處理吧。另外它支援各種不同的 protocol, 透過 internet 這種連線來使用,效能也不會很糟糕...
到目前為止,我用的就是 (5) USB DISK + SVN 這種 solution, 老實說越用越覺的它不錯 (Y)。SVN 我還是個新手,應該輪不到我來介紹他的特色吧 XD,不過我還是挑幾個特別的地方介紹一下,這些是我用它的主要原因啊...
- 操作邏輯合適
SVN 是 CVS 的接班人,它先天就繼承了 CVS 的特性: 就是適用 open source 的開發團隊。Open Source 的開發團隊跟一般的開發團隊有什麼差別? 一般商業開發都是正職的工作,很固定且很密集的進行開發及變更,因此像 Microsoft Solution (VSS / TFS) 那種要事先 lock 的機制會比較有效率。不過 open source project 就反過來,業餘的比例比較高,而且人都散布在世界各地,如果真正用 LOCK 的機制大概會哭出來吧...。我要改的檔案被你 LOCK 住了,不過我又不知道你是誰? 除了等就沒辦法了...。
因此 SVN 先天就是以這樣的觀點來設計: 你先改了再說,改完就 commit 。反正只要沒人跟你改同一個檔案就沒事... 如果運氣真的不好,那這個人不要跟你改同一段 code 也沒事,直接 merge 就好... 只有真的很背的時後,有人跟你改同一段,那麼後 commit 的人就要負責處理 merge 的問題。不過機率很低嘛 (沒錯,尤其是只有我自己用的時後),你可以不用管它...
過去用 VSS 常碰到這種情況: 原本只是開個文件起來看 (READ),跟本沒想要去改它,就沒有先作 check-out 的動作了。不過看到一半發現內容有誤,想要修正時... 問題就來了。以 WORD 來說,已經開起來才去 check-out 檔案的話,WORD還是會認為檔案是唯讀的... 除非你關掉 WORD 再開啟一次才有用。不過這麼一來思緒都被打斷了...。
當然,還是一樣,正規的開發動作還可以要求,一般的文書處理要求到這樣就有點過頭了。因此 SVN 這樣的邏輯就佔了點優勢,我最常碰到的案例就是: 要出門開會,把 USB_DISK 拔出來帶走。開會過程中 (在外面,沒有網路連線) 修修改改 PPT 的內容,回到公司後直接在 NB 或是把 USB DISK 插回 PC,再用 SVN 作 commit 的動作...。
- SERVER 的資訊跟著目錄
有些工具 (像是 TFS),你的工作目錄對應到那個 SERVER,是工具在維護的 (TFS 的 workspace),這時搭配 USB DISK 可能會在不同的電腦 (可能是我的 PC,也可能是我的 NOTEBOOK,甚至是帶回家裡用)。一般把設定綁在工具上的作法就很頭痛,因為好幾台都要設成一樣的,而且 USB DISK 還有可能每次的磁碟機路逕都不大一樣...
我用的工具是小烏龜 (TortoiseSVN),它的設定就是在每個目錄下放個 .svn / _svn 的子目錄,檔案總管按右鍵叫出 SVN 的選單後,藏在裡面的設定就自動套上來了。這種操作模式,剛好對於我的用法 (USB_DISK) 很方便...
- 更精確,更有效率的 "備份機制"
現在隨身碟廠商,都很愛在商品上加一些小工具,有的有壓縮,有的有密碼保護... 不過 USB DISK 很容易掉,所以所有廠商都不會忘記附上一個備份工具。連我前面介紹的 PortableApps.com 都有附一個 ( 7-ZIP + SHELL )。不過這些備份工具都有個通病... 它就真的只是 "備份" 而已,是讓你心安的。使用時機是你自己要勤勞點,記得每天按 BACKUP。要還原回來,通常就是整支 USB DISK 的內容都還原回來了,如果你只想要還原某幾個檔,或是只要查看過去備份的某個檔,那你得點好幾下滑鼠,甚至是要把整個備份解開才看的到。
另一個備份問題是,每次都是 FULL BACKUP ... 雖然有些工具作的比較好,有差異備份 ( PortableApps.com 就有提供 7-ZIP 的差異備份),不過不還原還好,一旦要把舊資料撈出來也是很辛苦。當然這些並不是備份工具的錯,備份本來就是作這些事。中間有落差的地方在於 USER 需要的是一個歸檔的機制啊,除了備份也需要調閱舊的版本內容。這時版本控管工具,正好就成為 USB DISK 在 PC 上的第一線 "備份資料庫" 了。當你在 check-in / commit 時,不自覺的就在版本系統內放了一份備份了,不放心的人可以再啟用像 VSS (Volume Shadow Copy Service) 或是定期壓 ZIP 這類一般的備份機制作第二層保護,就很足夠了。
這裡的重點倒不是備份安不安全啦,而是這樣的操作方式,很自然的就會在 SVN Repository 內留下一份內容,同時也方便你替這個版本作註記,未來要調閱,甚至是比對內容差異都很容易...
- 異地存取
USB DISK 雖然很方便,也可以隨身攜帶,但是我就是會常常忘掉它... 常常忘了拔就出門... 在外面如果還要存取我的 USB DISK 的內容,有網路的話,版本控制系統也很好用。我用的 SVN SERVER 是 Visual SVN,它就有個很簡易的 WEB 介面,真的忘了帶還可以連回我自己的 PC,把檔案下載回來。
如果用的電腦有灌 SVN CLIENT,那你還可以做些基本的操作...。這套比起來就比 VSS 強的多。VSS 完全是 file system base, 透過遠端的操作必需先用網芳之類模擬 file I/O 的方式,效能很糟糕... 雖然 2003 年左右 Microsoft 替 VSS 加其了很多功能,像是 LAN Boost Service (我搞不懂它怎麼做的),或是替 VSS 加上 Web Service Interface (可以透過 HTTP),不過效果都不盡理想。
這些功能加一加,就是我現在在用的個人檔案管理方案了啦。家裡有台現成 SERVER,很多問題就更好解了。這套作法正好给有需要的人參考看看,如果你用了有什麼心得,或是有其它更好的用法也歡迎分享 :D
- VSS (Microsoft Visual SourceSafe 5.0)
-
RUNPC 精選文章 - 運用ThreadPool發揮CPU運算能力
果然這個什麼東西都上網的年代,要三不五時的 GOOGLE 一下自己,才會知道那些網站把你的八卦跟內幕爆了出來... 不過應該沒啥週刊記者對我有興趣吧? 哈哈。在 GOOGLE 自己名字時,倒是意外發現,之前投稿的文章,又有一篇被拿來登在網站上的精選文章了 :D
特此留念一下 :D
http://www.runpc.com.tw/content/main_content.aspx?mgo=176&fid=E02
--
順便整理一下懶人包:
另一篇精選文章 [RUN!PC 精選文章 - 生產線模式的多執行緒應用]
過去投過的系列文章 (multi-threading programming using c#):
2008/11. 生產線模式的多執行緒應用
2008/09. 用ThreadPool發揮CPU運算能力
2008/06. SEMAPHORE在ASP.NET的應用
2008/04. 以ASP.NET開發同步WEB應用程式 -
EF#3. Entity & Inheritance
繼承 (inheritance) 是物件技術的核心,就是這個特性提供了 OOP 絕大部份的特色。這東西被拿掉的話,OOP就沒這麼迷人了。繼然談到了 ORM,就不能不來看看 R(關聯式資料庫) 怎麼被對應到 O(物件),同時還能處理好繼承關係。
RDBMS 連基本的物件 (Object Base) 都不支援了,更別說物件導向 (Object Oriented) 了。因此要搞懂 ORM 及繼承的關係,就得先瞭解基本的 OO 是怎麼實作 "繼承" 這個動作。這些知識是古早以前學 C++ 時唸到的,現在的 CLR 不知道有沒有新的作法? 不過應該大同小異吧! C++ 主要是靠 virtual table 來實作繼承關係,當子類別繼承父類別時,父類別定義的 data member 跟 method 就全都遺傳到子類別身上了,這動作就是靠 virtual table 作到的。細節我就不多說了,有興趣的讀者們請先上網找找相關資訊看一看。
ORM 的運氣好多了,只要處理資料的部份。因此前一段提到的 virtual table 如果要拿來應用也會簡單的多。virtual table 可以很直覺的想像成是 DBMS 裡 table schema 的定義,而一個物件 (instance) 的 virtual table 資料,正好就對應到該 table (DBMS) 的一筆資料。這正好是 ORM 基本的動作。大部份 OO 的書都會說,繼承就是 " Is A " 的關係。在資料上則是子類別擁有父類別所有的欄位定義。這很容易對應到資料庫的正規化,該如何切割資料表的規責。你可以切開靠 PK / FK 再併回來,或是直接反正規化讓它重複定義在多個 TABLE... 事實上,兩大 ORM (EF & NH) 都歸納出三種作法,後面來探討一下彼此的差異...
再來看看繼承關係,假設父類別 class A 對應到 table A, 那麼衍生出的子類別 class B 對應的 table B, 則應該要包含所有 table A 定義的欄位才對。從這點出發,就帶出了第一種作法: 就是把 table A 所有的欄位都建一份到 table B (註: table per concrete type)。
不過這樣看起來有點蠢,DBMS 熟悉的人也許會採另一種作法: 沒錯... table B 只要留個 foreign Key, 指向 table A 的 primary Key,需要時再 join 起來就好了,這是第二種作法 (註: table per type)。
唸過 DBMS 的人都還記得 "正規化" (normalization) 跟 "反正規化" 吧? 切割過頭也是很麻煩的,因此有第三種作法逆其道而行,就是建一個 table 給所有的子子孫孫類別共用。因此 table 需要的欄位,就是所有的子類別的所有欄位集大成,通通都建進來... 不用的話就空在那裡,這是第三種作法 (註: table per hierarchy)。
這三種作法,在 Entity Framework (以下簡稱 EF) 或是 NHibernate (以下簡稱 NH) 都有對應的作法,只不過名字不大一樣... 這篇 ADO.NET team blog 借紹的還不錯,可以參考看看。這三種方式,在 EF 裡的說法分別是 (括號裡是 NH 的說法,參考這篇: Inheritance Mapping):
- Table per Hierarchy (NH: Table per class hierarchy)
- Table per Type (NH: Table per subclass)
- Table per Concrete Type (NH: Table per concrete class)
事時上,處理方式大同小異,不外乎用三種不同的對應方式,來處理物件繼承關係。這些不同類別的物件彼此有繼承關係,對應到 TABLE 的方法不同,各有各的優缺點。其實 ADO.NET team blog 講的都很清楚,我就不再多說,簡單列張比較表:
適用於 不適用於 Table Per Hierarchy - 最簡單的實作方式
- 所有同系類別的實體 (instance) 數量不會很多時
- 需要用單一 QUERY 查出所有的子類別物件時
- 繼承階層較簡單的情況
- 類別的欄位要調整很容易
- instance數量太多,會嚴重影響效能
- 無法在table schema上做太多嚴格的檢查
Table Per Type - 繼承關係清楚的對應到 TABLE
- 需要用單一QUERY查出所有子類別的物件
- 不同於 TPH,可以針對每種類別,設定嚴僅的 table constraint
- 每個類別要變動或調整都很容易
- 繼承階層較多時,要取得單一 instance data 需要透過多層 join
- table 數量會隨著類別的數量快速增長
Table Per Concrete Type - 綜合 TPH / TPT 的優點 (也綜合了兩者的缺點)
- 可以針對每種類別設定 table constraint
- ORM mapping 很簡單
- 要用單一QUERY查出所有子類別的物件並不容易 (需要把所有的 TABLE JOIN 起來)
- 父類別的欄位調整很麻煩,所有的 TABLE 都需要配合調整
[未完待續] to be continue…
-
EF#2. Entity & Encapsulation
前一篇講了一堆大道理,這篇就來看一些實作吧。各種 ORM 的技術都有共同的目的,就是能把物件的狀態存到關聯式資料庫,而這樣的對應機制則是各家 ORM 競爭的重點,勝負的關鍵不外乎是那一套比較簡單? 那一套包裝出的 Entity 物件能夠更貼近一般的物件?
會有這樣的 "對應" 機制需求,原因只有一個,物件技術發展的很快,已經能解決大多數軟體開發的需求了,不過資料庫就沒這麼幸運,現在的 DBMS 撇開一些技術規格不談,本質上還是跟廿年前差不多,就是關聯式資料庫而已,本質上就是一堆 table + relationship, 配合 SQL 語法來處理資料。發展至今,物件技術跟資料庫技術能處理的問題,已經是兩個完全不同世界的問題了,三層式的架構在這段出現斷層...。
解決方式大概有兩條路,一種就是想辦法把這兩個世界串起來,就是 ORM framework 想做的事。另一個就是改造 RDBMS,讓 RDBMS 進化成也具有物件導向特性的資料庫。不過以眼前的五年十年來看,ORM 還是大有可為。ORM 只要能把 "對應" 這件事做到完美的地步,其實在某個層面上就已經做到 OODB 的願景了,只差在這些物件是活在 APP 這端,不是活在資料庫那端...。
扯遠了,接下來我會試著從物件技術的三大核心 (封裝、繼承、多型),及資料庫最需要的查尋機制 (QUERY) 來看看 Entity Framework 各能提供什麼支援,才能客觀的評論 Entity Framework 值不值得你投資在它身上。
在繼續看下去之前,請先俱備基本的 Entity Framework 運用的能力。在 MSDN 名家專欄裡 MVP(朱明中) 寫的這幾篇我覺的很不錯,可以參考看看。我就是看這幾篇入門的 :D。幾年前在比賽上碰過他幾次,我還蠻配服他的,可以靠自學而有今天的成就。以下是他寫的幾篇 ADO.NET / Entity Framework 的系列文章:
- 讀寫 ADO.NET Entity Framework (2007 年 9 月)
- 由 LINQ 存取 ADO.NET 物件 (2007 年 9 月)
- 整合 ADO.NET Entity Framework 到應用程式中 (2007 年 9 月)
- 首次接觸 ADO.NET Entity Framework (2007 年 9 月)
- ADO.NET Entity Framework 概觀 (2007 年 9 月)
在開始之前,我們先來看看一個最簡單的 Entity Framework 的範例,然後來看看封裝性能夠對你的程式帶來什麼影響? 先來看看只用到了 ORM 卻沒發揮封裝性的例子:
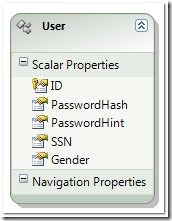
這是存放會員資料的表格,對應的 TABLE 很簡單,SQL 如下:
[copy code]1: CREATE TABLE [dbo].[Users](
2: [ID] [nvarchar](50) NOT NULL,
3: [PasswordHash] [image] NOT NULL,
4: [PasswordHint] [nvarchar](100) NOT NULL,
5: [SSN] [nchar](10) NOT NULL,
6: [Gender] [int] NOT NULL,
7: CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED
8: ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
大部份的人在 EDMX Designer 裡把資料表拉進來後,就開始用這個 Entity Class 了吧? 密碼的部份為了安全及實作上的考量,DB只存放 HASH,而 HASH 的運算則透過 .NET 程式來計算,不透過 SQL 的函數。作法決定後,你可能會寫出這樣的程式碼:
建立帳號的程式碼[copy code]1: // 準備 object context
2: using (Membership ctx = new Membership())
3: {4: // create user account:
5: User newUser = new User();
6: newUser.ID = "andrew";
7: newUser.PasswordHint = "12345";
8: newUser.PasswordHash = HashAlgorithm.Create("MD5").ComputeHash(Encoding.Unicode.GetBytes("12345"));
9: newUser.SSN = "A123456789";
10: newUser.Gender = 1;11: ctx.AddToUserSet(newUser);12: ctx.SaveChanges();13: }檢查密碼的程式碼[copy code]1: // 準備 object context
2: using (Membership ctx = new Membership())
3: {4: string passwordText = "12345";
5: User curUser = ctx.GetObjectByKey(new EntityKey("Membership.UserSet", "ID", "andrew")) as User;
6: bool isPasswordCorrect = true;
7: {8: byte[] passwordTextHash = HashAlgorithm.Create("MD5").ComputeHash(Encoding.Unicode.GetBytes(passwordText));
9: if (passwordTextHash.Length != curUser.PasswordHash.Length)
10: {11: isPasswordCorrect = false;
12: }13: else
14: {15: for (int pos = 0; pos < curUser.PasswordHash.Length; pos++)
16: {17: if (passwordTextHash[pos] != curUser.PasswordHash[pos])
18: {19: isPasswordCorrect = false;
20: break;
21: }22: }23: }24: }25: Console.WriteLine("Password ({0}) check: {1}", passwordText, isPasswordCorrect ? "PASS" : "FAIL");
26: }這樣的 User 類別設計有什麼問題? 我列幾個我認為設計上不妥的地方:
- 直接提供 PasswordHash 曝露過多不必要的實作細節
- 在台灣,身份證字號 (SSN) 跟性別 (Gender) 是相依的欄位 ( functional dependency )
以物件導向的角度來看,User 真正要提供的是接受 "驗證密碼" 的要求,至於你的實作是提供明碼或是用 Hash, 都是實作的細節。提供原始未加密的密碼,或是提供處理過的 HASH,在需求上都是不必要個功能。物件的介面定義要盡量以能滿足需求的最小介面為原則,其它的都不要公開,才滿足 "封裝性" 的要求。因此良好的設計應該把這些細節封裝起來,只在公開的介面表達你要提供的功能。
另外依照台灣的身份證字號規則, SNN 跟 Gender 是連動的。目前 User 的設計是把兩者的關係丟給前端寫網頁的人來維護,一不注意就會發生不一致的情況。DB 對於這種問題的解決方式,不外乎寫 trigger 或是其它 constraint 的方式來阻擋不正確的資料被寫入 DB,不過看了前面提到的規則,要單純用 SQL 的功能完整實作出來,還不大容易。
另一種作法,只儲存 SSN,Gender 欄位則以 VIEW 的方式提供,這樣就不會有不一致的問題。不過這方法的缺點在於,當邏輯太複雜的時後,常常會超出 SQL 能處理的範圍,效能也許會是個問題,或是 constraint 不能完全跟程式端一致。
就我看來,這類看似應該在 data layer 實作的複雜邏輯,又難以在 SQL DB 上面解決的問題,才是 Entity Framework 的強項。現在來看看 Entity Framework 能怎麼解決這些資料封裝的需求:
首先,把不需要公開的細節改成 Private 隱藏起來,包括 PasswordHash 的 Getter / Setter, Gender 更名為 GenderCode, 同時把 Getter / Setter 也改為 Private ...
接下來就要把這些封裝起來的細節,提供另一組較合適的公開資訊的方式。這時 .EDMX designer 替我們產出的 code 就能搭配 partial class 擴充功能了。來看看我們在 partial class 裡寫了什麼?
User.cs 的內容 (partial class)[copy code]1: public partial class User
2: {3: public string Password
4: {5: set6: {7: this.PasswordHash = this.ComputePasswordHash(value);
8: }9: }10: public bool ComparePassword(string passwordText)
11: {12: byte[] hash = this.ComputePasswordHash(passwordText);
13: // compare hash
14: if (this.PasswordHash == null) return false;
15: if (hash.Length != this.PasswordHash.Length) return false;
16: for (int pos = 0; pos < hash.Length; pos++)
17: {18: if (hash[pos] != this.PasswordHash[pos]) return false;
19: }20: return true;
21: }22: public GenderCodeEnum Gender
23: {24: get25: {26: return (GenderCodeEnum)this.GenderCode;
27: }28: }29: partial void OnSSNChanging(string value)
30: {31: // ToDo: check ssn rules.
32: // sync gender code
33: this.GenderCode = int.Parse(value.Substring(1, 1));
34: }35: private byte[] ComputePasswordHash(string password)
36: {37: if (string.IsNullOrEmpty(password) == true) return null;
38: return HashAlgorithm.Create("MD5").ComputeHash(Encoding.Unicode.GetBytes(password));
39: }40: }41: public enum GenderCodeEnum : int
42: {43: FEMALE = 0,44: MALE = 145: }被隱藏起來的 PasswordHash, 公開的介面就用 Password 的 Setter 跟 ComparePassword( ) method 取代,明確的用程式碼告訴所有要用它的 programmer:
"密碼只准你寫,不准你讀 (read only)... 只告訴你密碼對不對, 不會讓你把真正的密碼拿出去"
另一個部份,就是身份證字號跟性別的問題,則改用另一個方式解決。SSN 這個屬性維持不變,在它被更動時就一起更動 GenderCode 這個欄位。GenderCode 完全不對外公開,公開的只有把 int 轉成 GenderCodeEnum 的屬性: Gender。同時為了保護資料的正確性,只開放 Getter, 不開放 Setter。
同樣的程式,在我們調整過 Entity 的封裝之後,再來重寫一次看看:
建立新的使用者帳號[copy code]1: // 準備 object context
2: using (Membership ctx = new Membership())
3: {4: User newUser = new User();
5: newUser.ID = "andrew";
6: newUser.PasswordHint = "My Password: 12345";
7: newUser.Password = "12345";
8: newUser.SSN = "A123456789";
9: ctx.AddToUserSet(newUser);10: ctx.SaveChanges();11: }檢查密碼是否正確[copy code]1: // 準備 object context
2: using (Membership ctx = new Membership())
3: {4: EntityKey key = new EntityKey("Membership.UserSet", "ID", "andrew");
5: User user = ctx.GetObjectByKey(key) as User;
6: // 要比對的密碼
7: string passwordText = "123456";
8: bool isPasswordCorrect = user.ComparePassword(passwordText);
9: Console.WriteLine("Password ({0}) check: {1}", passwordText, isPasswordCorrect ? "PASS" : "FAIL");
10: }修改過的程式簡潔多了。不過比少打幾行程式碼更重要的是,它的邏輯更清楚,更不容易出錯。如果沒有妥善的處理封裝性的問題,可以想像寫出來的程式一定亂七八糟。要嘛不正確的資料都會被寫進 DB,不然就是 DB 有作適當的防範,但是程式沒有作好,最後就是到處都出現 SqlException ...
這裡只是簡單示範一下 Entity Framework 如何替資料提供封裝的特性,後續的文章會繼續示範 Entity Framework 如何能把 DBMS 的資料,進一步的應用到物件技術的繼承及多型等特性。敬請期待下集 :D
-
EF#1. 要學好 Entity Framework? 請先學好 OOP 跟 C# ...
這次為了能順利的學好 Entity Framework,花了不少工夫在研究它的作法。不過有一大半不是在 Entity Framework 本身,而是在 C# 的一些特別的語法跟 LINQ 身上...。也因為這樣,我深切的體認到一個 ORM 技術能不能成功,其實都是在 Hosting 這個 Framework 的環境夠不夠成熟...。
不過在摸索的過程中,找到的資訊都是片斷的,每一篇都是講實作,範例程式,操作步驟... 等等,而當時我最需要的反而是幫助我決定,Entity Framework 到底值不值得我押在上面投資五年開發計劃使用的 ORM 技術? 它跟 NHibernate (考慮中的另一項 ORM framework) 的優缺點為何? 未來發展的優缺點又是什麼? 架構上的差異在那? 另外 Linq to SQL 呢? 這些較偏架構性跟本質的討論及比較資訊,反而少之又少...。
雖然最後還是研究了些心得出來,不過實在是不想寫那些到處都看的到的實作,就來寫點不一樣的吧。第一篇會先寫寫 ORM 的背景知識,還有 Entity Framework 跟 C# 的語法是如何魚幫水,水幫魚,如何解決了過去 ORM 用起來都不大對勁的問題...。
繼續長篇大論前,先老王賣瓜一下。雖然我碰過的 ORM framework 不多,不過相關的理論跟技術則碰了不少。撇開大學就在研究的 OOP 不談,研究所的指導教授就從 SmallTalk 開使教... 兩年的專題研究都是 OODB (物件導向資料庫),相關論文也看了一堆。出來工作後又有幸用了幾年的 TAMINO (一套 native xml database), 之後又花了很多時間,在 SQL 2000 上面建立起一套 Object <-> XML <-> Database,類似 ORM 的 Framework ...
不過這麼一路下來,都沒有覺的簡單又可行的方案。除了上面講的是我親自參與過的之外, Microsoft 其實也發表過幾個類似的技術,像是 Typed DataSet 就是個較接近的產物。 Typed DataSet 其實有點接近現在的 Entity Framework 了。DataSet 就等同於 Entity Container / ObjectContext, DataTable 大致就等同於 EntitySet, 而 DataRow 則等同於 Entity, Relation 則大致等同於 Entity Framework 的 Navigation Property.... 不過用起來還是到處都看的到 DataSet 的影子,感覺血統還不夠純正...
不過現在的 Entity Framework 不一樣了,感覺就已經往實用的領域邁進了一大步! 並不是說 Entity Framework 做的很好 (以成熟度來說, NHibernate 比目前的 Entity Framework 好的多), 而是跟 Entity Framework 搭配的技術都成熟了。一套 ORM 要成功,必要的條件很多啊... 實作上的角度看來,我覺的重要的有這幾項:
- 要有優良的 Object / Relationship Mapping 機制、作法、工具等等
- Framework 本身的擴充及自訂的能力要夠
- 要有效的解決以物件角度思考的查詢 (QUERY) 問題
- "物件" 要看起來像 "物件",不是 "資料"
- 處理資料庫典型的問題,效能跟便利性不能跟直接操作 DB 差太多
- 你的牌子夠不夠響亮... (這是心理因素而已... 哈哈)
這些是深切的體認。不然的話 ORM 的東西跟本不難啊,以功能來說,Typed DataSet 其實就解決一大半實際的問題了。先來看看物件導向幾個關鍵的核心技術是啥?
- 封裝 ( Encapsulation ),抽像化型別 (ADT, Abstract Data Type),資料 (Data) 跟行為 (Behavior) 能夠綁在一起
- 繼承 ( Inheritance )
- 多型 ( Polymorphism )
以這樣 "物件" 的關點來看,Microsoft 在 Entity Framework 之前的資料庫技術其實都不合格。先來看看資料庫存取技術,如果能搭配這些物件技術,能有什麼樣的改進?
[封裝]
這就沒啥好講的了。物件技術有很好的封裝機制,public / protected / private 等等 scope modifier 就能提供很棒的封裝機制。不過資料庫很難做的好,資料庫的那套頂多叫作安全機制 (security) 或是授權機制 (authorization), 不是封裝 (encapsulation) ... 真正的封裝不是看你是那個帳號決定能不能讀資料? 而是你是那個 SCOPE 的程式,能不能存取封裝起來的內部資訊。DBMS 對於資料的控制能力很有限,不外呼 Key, Constraint, Relationship / Foreign Key 等等。像加解密,正規運算式 (regular expression) 等等,對 DBMS 來說就太複雜了。更複雜的封裝機制單靠 DB 就很不實際... 無奈在沒有 ORM 的前題下,這些問題則是直接曝露在你的程式碼每個地方...。換句話說,如果 ORM 能提供良好的封裝機制,ORM 就能取代掉目前的 Data Access Layer ,成為 APP 存取 DBMS 的主要 API 。順便吐個苦水,也因為 DBMS 對於資料的控制能力有限,維護的 APP 總是碰到這種問題,就是錯誤的資料總是有辦法鑽進資料庫裡面。不為什麼,只因為 DBMS 本身擋不下來,而 Data Access Layer 又不夠爭氣到足以扛下這重責大任,最後只能靠 APP 自身的開發人員,靠紀律跟自律,還有良心來作好這層把關的動作... -_- 如果有套像樣的 ORM 能夠卡在這個位置,光是資料內容的把關,就是一大進步了。
[繼承]
繼承跟資料庫有什麼關係? 其實 ORM 如果能有效的把繼承的功能跟資料庫整合起來,也是很嚇人的。舉例來說,部落格支援文章,相片等等不同的內容,但是它們都要有一致的抽像行為,如新的內容要能夠訂閱 (rss subscription),要能夠有標簽 (tagging) 等等共通的功能,在物件技術我們會很直覺的用繼承來做到。定義 BlogContent 類別,把這些邏輯擺上去。之後再分別衍生出 ArticleContent / PhotoContent 等類別,把差異的實作補上去就完成了。不過同樣的概念別想直接套用在資料庫上,你的腦袋得負責這兩者之間的對應。懂的這麼多的工程師很難找啊... 去那裡找這種人來寫 APP ? 其實搞懂這些也不難,C++ / C# 在解決這類問題,只是很簡單的利用到 virtual table 就搞定了。換到 DBMS,就把 virtual table 的資料結構套到 database schema 就可以。不過說來簡單,能夠搞懂這些,還能精確的實作出來的人不多... 真的作出來還會被嫌:
"它ㄨ的,誰設計的 table schema ? 亂切一通害我 T-SQL query 這麼難寫..."
嗯,沒事,藉機吐吐苦水。主要要表達的就只有一個,繼承關係要對應到資料庫上面,也是挺麻煩的一件事。Entity Framework / NHibernate 就都提供了三種對應的方法。這三種切割對應的方式,要選那一種? 這又是門學問... Orz, 以後再說。
[多型]
這個就更玄了。多型是建立在繼承的基礎上,不管你是什麼類別的 instance, 多型的機制可以在父類別的角度,對所有各種衍生類別的物件,一視同仁的操作。而在這統一的前題下,每種類別的物件又可以一國兩制的各自為政... (咳,這不是政治版...)。這樣的抽像程度就是資料庫遠遠所不及的。延序前面講的部落格內容的例子,你能想像這個 store procedure 該怎麼寫嗎?"要寫一個 sp_update_blogcontent 的 store procedure, 如果 ID 指向的是 blog, 則要執行更新 HTML 的 code,如果是 photo, 則要更新存放圖檔的 BLOB 欄位..."
天那,在 DB 這個層次,寫這種 CODE 只能用很醜的 IF ELSE 一層一層堆起來...,跟物件技術比起來,程式碼的描述及抽像化能力實在差太遠,在這層次能解決的問題複雜度很有限...。你如果是個聰明人,最好還是別在 DBMS 搞這些物件技術,會死人的...。比較好的作法是移到 APP 那層去作比較實際。
不錯,ORM 存在的原因又多了一個...。
所以,再回頭來看看,ORM真的要發揮它的效益的話,絕對不是只有用 "物件" 來代替 "資料" 而已 (還是老話一句,這樣的話用 Typed DataSet 就夠了)。至少對應出來的 "物件",還能有效的應用到這些物件導向的特性,同時 ORM framework 還能替你維持這些跟資料庫的對應關係,這樣 ORM 技術才能真正發揮它的效益,那些被講到爛的三層式架構才不會在 DBMS 這層就破功了。
來看看比較具體的部份。這些物件技術的特點,C# 早在 2000 年,JAVA 早在 199X 年就有了,沒什麼了不起。不過當年的 ORM 實在難用的很。當時的 OOPL 就是缺了些東西,ORM 的程式寫起來限制一堆... 對應到資料庫的物件,用起來就是跟一般的物件差很多,這也不能用,那也不能用。
現在的 C# 就不一樣了,進化到足以解決這些語言的限制。來看看:
- reflection, attribute:
這個讓物件 (Entity) 可以寫的更簡潔,reflection + attribute 可以解決很多過去得繞一大圈才做的到的事。如 class 對應到那個 table, property 對應到那個 column 等等。 - partial class:
ORM 免不了有些 code generator 的搭配。有 partial class 可以讓程式搭配 code generator 更容易一點。 - extension methods:
現有的物件技術很難讓你在現有的 class 上去作擴充,而 extension methods 可以。 - Linq
這可是一大進步。過去 ORM 的目的就是想把 DB 的細節藏起來,無奈碰到 QUERY 的話什麼都藏不住,往往淪落到要嘛都直接用 SQL, 不然就是只剩幾種基本的 API 可以用,無法完全取代直接用 SQL 的查詢。不過 Linq 出現之後這情況就改觀了,雖然像報表那樣複雜大型的 QUERY 還是得直接下 SQL,不過一般 AP 內的查詢都可以直接用 Linq 搞定了
其它當然還有別的,不過我自己覺的這幾點是關鍵,至少可以讓現在的 Entity Framework 在使用 Entity 時,不會再跟一般的物件有什麼不同。大部份你可以應用在一般物件的技巧,也都能套用在 Entity 身上。第一篇碎碎唸的部份就先寫到這裡。後面會示範一下幾種打造你專屬的 Entity 用到的技巧。想看後面的讀者們請耐心等待 :D

