-
Rancher - 管理內部及外部 (Azure) Docker Cluster 的好工具
 過去快20年的經驗裡,很少看到有哪個技術在短短的三年就可以發展成這個樣子的... 半年前剛開始研究 Docker 時,就想找個好用的 WEB / GUI 管理工具,結果都沒滿意的,沒想到現在就一堆選擇了...
這次要介紹的 Rancher, 除了是套完整的 Docker Engine 管理工具之外,也是個 Docker Cluster 管理工具及平台,讓你在佈署 Containers 的時候,不用去傷腦筋你要怎麼分配資源等等瑣碎的事情,你只管把你的 Container 組態設定好,丟上去就行了。這感覺跟當年 (2009) 初次接觸到 Winows Azure 的 Cloud Service 一樣令人感動。當年只要把你的 Application 打包成 Cloud Service Package,開發階段設定好組態,佈署階段可直接手動或自動的設定 Scale,具備 Production / Staging Environment 切換上線,可以不中斷服務的升級系統...,整個就是靠 Visual Studio Deploy 就足以取代過去要 OP team 搞半天的升級程序。
只可惜 Azure Cloud Service 的種種優異的管理及佈署能力,至今都還只限於 Azure Only,沒有下放到地面版本的 Platform ... 真的是 "此物只應天上有" 啊... 但是站在地上的凡人沒機會用啊... 現在看到 Docker Cluster + Management Tools 的發展,這種威力已經變成隨手可得了... 為了紀念一下當年 Microsoft 早在 Azure 就達成的成就 (而且早已商業化),這次的實作案例就拿 Azure 示範位於公有雲的 Production Environment,如何做到服務的管理及升級程序吧!
過去快20年的經驗裡,很少看到有哪個技術在短短的三年就可以發展成這個樣子的... 半年前剛開始研究 Docker 時,就想找個好用的 WEB / GUI 管理工具,結果都沒滿意的,沒想到現在就一堆選擇了...
這次要介紹的 Rancher, 除了是套完整的 Docker Engine 管理工具之外,也是個 Docker Cluster 管理工具及平台,讓你在佈署 Containers 的時候,不用去傷腦筋你要怎麼分配資源等等瑣碎的事情,你只管把你的 Container 組態設定好,丟上去就行了。這感覺跟當年 (2009) 初次接觸到 Winows Azure 的 Cloud Service 一樣令人感動。當年只要把你的 Application 打包成 Cloud Service Package,開發階段設定好組態,佈署階段可直接手動或自動的設定 Scale,具備 Production / Staging Environment 切換上線,可以不中斷服務的升級系統...,整個就是靠 Visual Studio Deploy 就足以取代過去要 OP team 搞半天的升級程序。
只可惜 Azure Cloud Service 的種種優異的管理及佈署能力,至今都還只限於 Azure Only,沒有下放到地面版本的 Platform ... 真的是 "此物只應天上有" 啊... 但是站在地上的凡人沒機會用啊... 現在看到 Docker Cluster + Management Tools 的發展,這種威力已經變成隨手可得了... 為了紀念一下當年 Microsoft 早在 Azure 就達成的成就 (而且早已商業化),這次的實作案例就拿 Azure 示範位於公有雲的 Production Environment,如何做到服務的管理及升級程序吧!
-
//build/2016 - The Future of C#
在寫這篇文章之前,一定要先秀一下我用了好幾年的桌布... :D
 從開始學寫 code 的第一天起 (正規開始學 coding 是大一計概,學寫 Fortran & C),我就很講究 code 到底寫的漂不漂亮? 好不好懂? 好不好維護? 寫到後來,連 code 寫的夠不夠優雅都開始計較起來... 學了 OOP / Design Patterns 之後,就開始計較起 code 的結構到底正不正確? 是否跟真實要描述的事物有沒有正確的對應? 沒有的話就要改到滿意為止才罷休...
所以,當年在 MSDN 逛到這張桌布的時候 (現在找不到原始連結了) 就立刻拿來用了。我平常是不用桌布的,一裝好 windows 就把它改成黑色來用... 直到看到這張桌布為止...
從開始學寫 code 的第一天起 (正規開始學 coding 是大一計概,學寫 Fortran & C),我就很講究 code 到底寫的漂不漂亮? 好不好懂? 好不好維護? 寫到後來,連 code 寫的夠不夠優雅都開始計較起來... 學了 OOP / Design Patterns 之後,就開始計較起 code 的結構到底正不正確? 是否跟真實要描述的事物有沒有正確的對應? 沒有的話就要改到滿意為止才罷休...
所以,當年在 MSDN 逛到這張桌布的時候 (現在找不到原始連結了) 就立刻拿來用了。我平常是不用桌布的,一裝好 windows 就把它改成黑色來用... 直到看到這張桌布為止...
-
如何在 VM 裡面使用 Docker Toolbox ?
這篇一樣是意料之外的文章,不在原本的寫作計畫內 XD 上個禮拜是 Docker 三周年的生日,很難想像一個才剛滿三歲的技術,就已經在整個資訊業界掀起一陣風潮了.. 這次剛好無意間在 FB 的 Docker 社團,看到保哥問了個問題 (借保哥的圖用一下):
請問有人知道如何在 Hyper-V 下執行 Docker Toolbox 嗎?
一時手又癢了起來,於是就多了這篇意料之外的文章 XD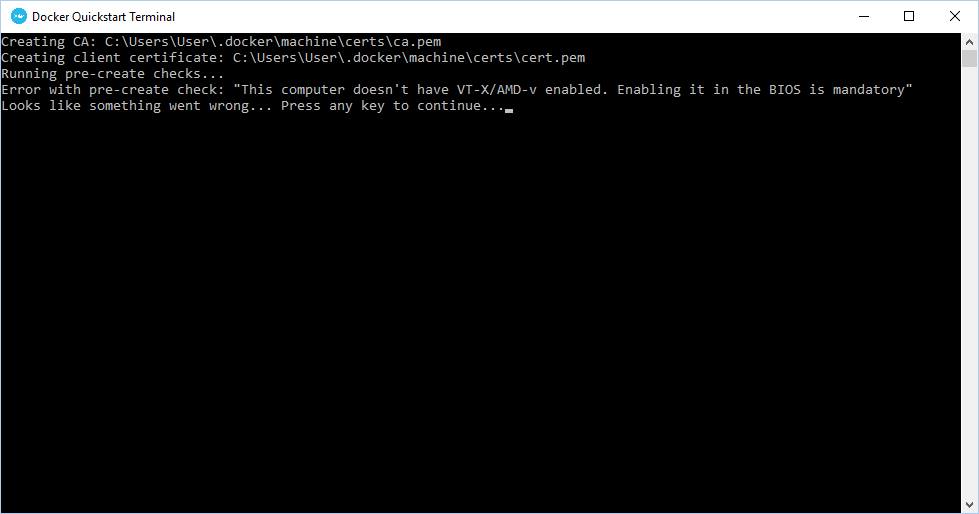
-
[設計案例] “授權碼” 如何實作? #3 (補) - 金鑰的保護
 前一篇 #3 介紹了如何利用 "數位簽章" 簡單又可靠的做好 "授權碼" 的驗證,主要都在說明程式架構的實作,沒有對實際運作的情況做太多補充,這篇就來補足這些遺漏的部分。運用這些公開的加密演算法,既安全又可靠,不過這些東西大家都拿的到啊,因此安全與否,完全取決於你的金鑰是否有妥善的被管理。
前一篇 #3 介紹了如何利用 "數位簽章" 簡單又可靠的做好 "授權碼" 的驗證,主要都在說明程式架構的實作,沒有對實際運作的情況做太多補充,這篇就來補足這些遺漏的部分。運用這些公開的加密演算法,既安全又可靠,不過這些東西大家都拿的到啊,因此安全與否,完全取決於你的金鑰是否有妥善的被管理。
-
[樂CODE] Microsoft 面試考題: 用 CPU utilization 畫出正弦波

故事的開頭很簡單,起因就只是某個上了年紀的大叔,逛到別人的面試題目,發現答不出來就一頭鑽進去,輸不起的故事而已 XD
