
面試題這系列來到第二篇,這次來點靈活一點的應用題: 連續資料的統計方式。
這個題目很簡單,例如購物網站,當你的網站每秒都好幾百筆訂單,都是好幾百萬上下時,如果我想看 “過去一小時所有成交金額” 的數字是多少,同時這數字還要每秒更新,你會怎麼設計這功能?
其實這個問題,就跟一般點擊率統計的問題差不多,只是我多埋了兩個阻礙在裡面,提高這問題的困難度。其一是只統計 time window 範圍內的數值,有訂單進來時把數值往上累加很容易,但是要 “精準” 的把超過一小時的數值剔除就很頭痛,讓很多不善思考的工程師就直接改採暴力法解決 (不斷重新計算這小時的加總)。另一個阻礙是這些資料是源源不絕連續的灌進來的,你沒有任何空檔可以停下來整理資料,你的處理方式必須是能連續運行,也不能不斷累積垃圾資料,或是瞬間占用大量資源。否則長時間執行下來應該會垮掉。
別小看這個問題,從最簡單的解法 (直接 SQL query) 到複雜的串流分析 (stream analytics) 都有,甚至還有需要自己土炮的做法… 過去往往很多人在爭論,演算法跟資料結構到底種不重要? 往下看下去你就會知道,當團隊碰到這種層次的問題時,你會很慶幸團隊裡有個腦袋靈活 + 懂資料結構的夥伴。如果你是面試官,花點時間看完這篇吧! 這類的問題,能讓你鑑別出優秀的軟體工程師。如果你想找的是能擔任架構師的人選,而非只是單純接需求把功能做出來的碼農,那麼一定要試試這個考題。如果真的找到有這樣能力的人,記得找來好好栽培他 :D
前言: 微服務架構 系列文章導讀
Microservices, 一個很龐大的主題,我分成四大部分陸續寫下去.. 預計至少會有10篇文章以上吧~ 目前擬定的大綱如下,再前面標示 (計畫) ,就代表這篇的內容還沒生出來… 請大家耐心等待的意思:
- 微服務架構(概念說明)
- 實做基礎技術: API & SDK Design
- API Design #1 資料分頁的處理方式; 2016/10/10
- API Design #2 設計專屬的 SDK; 2016/10/23
- API Design #3 API 的向前相容機制; 2016/10/31
- API Design #4 API 上線前的準備 - Swagger + Azure API Apps; 2016/11/27
- API Design #5 如何強化微服務的安全性? API Token / JWT 的應用; 2016/12/01
- API First Workshop: 設計概念與實做案例
- API First #1 架構師觀點 - API First 的開發策略 - 觀念篇; 2022/10/26
- API First #2 架構師觀點 - API First 的開發策略 - 設計實做篇; 2023/01/01
- (計畫) API First # 微服務架構 - API 的安全機制;
- 架構師觀點 - 轉移到微服務架構的經驗分享
- 基礎建設 - 建立微服務的執行環境
- 案例實作 - IP 查詢服務的開發與設計
- 容器化的微服務開發 #1 架構與開發範例; 2017/05/28
- 容器化的微服務開發 #2 IIS or Self Host ? 2018/05/12
- 建構微服務開發團隊
- 分散式系統的基礎知識
- 分散式系統 #1 如何保證 API 呼叫成功? 談 Idempotency Key 的原理與實作
前言 & 導讀
我先定義一下題目的系統架構。假設既有的系統架構如下:
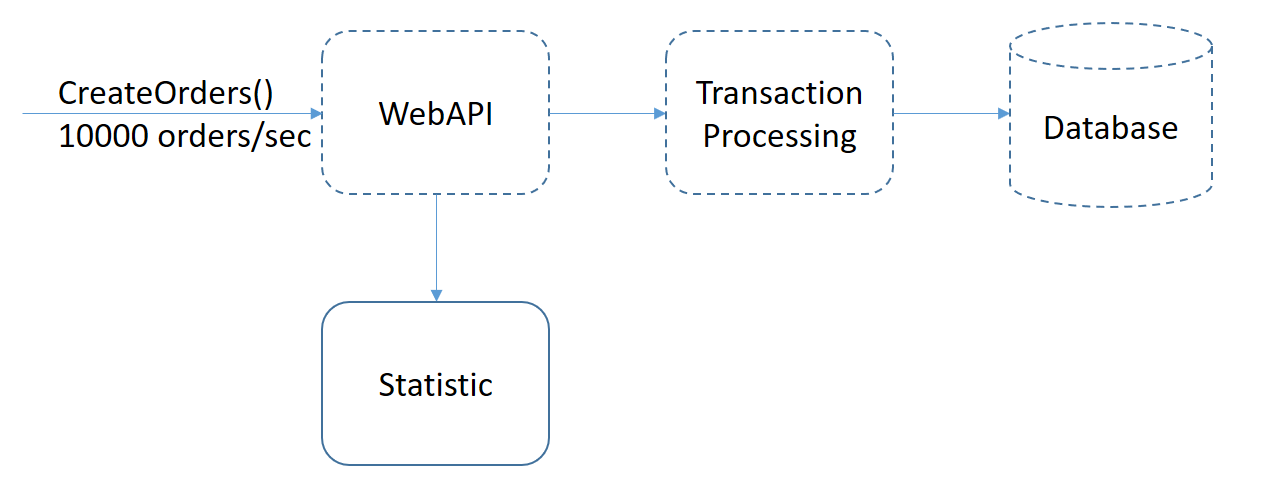
其中虛線框的部分都是現有的處理流程,從 [WebAPI] 接收到訂單之後,有既有的 [Processing] 程序,也有既有的資料庫去儲存交易結果。這些都不用在這次測驗中額外處理。這次的重點在於,如果收到訂單建立的通知時,會即時的把這些資訊轉發到 [Statistic] 統計的模組時,統計模組該怎麼做到上述的要求?? 設計出這個統計模組內部的做法,就是這個題目要考的範圍。
在說明怎麼解這問題之前,我先講講我為何想挑選這個題目的原因吧! 這是個典型的考驗你應用演算法或資料結構的問題。我實際在面試上問過這個問題,大約有 85% 的人都告訴我,只要從資料庫執行這道 SQL:
select sum(amount)
from [orders]
where transaction_time between getdate()
and dateadd(hour, -1, getdate());
不過,如果我的統計資料想要每秒更新,這個案例每秒有 10000 筆訂單,相當於每小時的訂單量有 3600 萬筆,累積在資料庫尚未封存的訂單可能高達上億筆時….
我只能說,這是個結果正確的方法,也是大部分工程師不加思索就可以回答出來的答案,但是他的運算能力很有限,不是個能大規模運用的方案。不同的規模下,需要不同的解決方案,這時你可能需要自己打造輪子,因為你可能找不到現成的 solution (如上例,仰賴的是 SQL server 的運算能力)。這時如何運用你的基礎知識、資料結構、演算法等等,反而是解決這類問題的關鍵。高手跟普通人的能力差距,在這類問題就可以很明顯的區分出來。
如果你嘗試發展的領域越獨特,你越需要這樣特質的人。如果你的問題已經有很多成熟的解決方案 (典型的案例: 台灣一堆接案做系統整合的廠商),你需要的應該是熟悉特定 framework / system 的人。如果你碰到的問題屬於獨特的 business model, 需要自己打造自己的 solution 時, 能否找到這種人選就是關鍵了。這類的人才才能幫你解決問題,這類問題同時就會是競爭對手難以追上的門檻。
考題 & 測試程式
講了一堆,直接來看題目吧。延續 上一篇 的模式,考題一樣先準備好 Contracts 及 TestConsole,答題的人要想辦法生出 Practices 的內容,補上你的實作,然後讓測試程式 TestConsole 通過驗證。原本題目是考 60 分鐘的統計,為了方便測試,以下的範例我都改用 60 秒當作例子。
Contracts 很簡單,一樣定義一個交易處理的引擎 EngineBase, 其中只定義到了幾個 method(s):
public abstract class EngineBase
{
public abstract int CreateOrders(int amount);
public abstract int StatisticResult { get; }
}
其中 int CreateOrders(int amount) 是新增訂單資訊的 method, int StatisticResult { get; } 則是取得統計結果的 property, 就這樣而已,其他沒有了。為了讓測試程式容易一點開發,我直接在題目內提供了一個空白的 DummyEngine, 目的只是讓你的測試程式可以通過編譯及執行而已:
public class DummyEngine : EngineBase
{
public override int StatisticResult
{
get
{
return 0;
}
}
public override int CreateOrders(int amount)
{
return 0;
}
}
到目前為止應該都沒什麼問題,只等你提供一個可以正確運作的版本了。來看看測試程式的部分:
static void FuncTest()
{
EngineBase e =
//new DummyEngine();
new InMemoryEngine();
bool stop = false;
// generate traffic (oders)
Task t1 = Task.Run(() =>
{
Random rnd = new Random();
while (stop == false)
{
Task.Delay(1000).Wait();
//e.CreateOrders(rnd.Next(10));
e.CreateOrders(DateTime.Now.Second);
}
});
int expected_result = (0 + 59) * 60 / 2;
Task t2 = Task.Run(() => {
while (stop == false)
{
Task.Delay(200).Wait();
Console.WriteLine($"statistic: {e.StatisticResult}, expected: {expected_result}, test: {e.StatisticResult == expected_result}");
}
});
Console.ReadLine();
stop = true;
Task.WaitAll(t1, t2);
}
測試程式的邏輯很簡單,先啟動 Task t1, 負責每秒鐘產生一筆訂單資料,訂單的金額 (amount) 就是當時時間的秒數部分。Task t2 則是固定的輪巡,不斷的去 Engine 查閱目前的統計結果,並且把他輸出到畫面上。等到程式 run 超過一分鐘之後,理論上我要統計的訂單一定都是從 0 + 1 + 2 + …. + 59, 隨著時間的流逝,往前一分鐘的訂單總和應該是不變的,都會包括完整的一個週期。直接看下圖比較清楚:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | … | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | # | # | # | # | # | # | # | # | # | ### | # | # | # | # | # | # | # | # | # | # | # | ||||||
| B | # | # | # | # | # | # | # | ### | # | # | # | # | # | # | # | # | # | # | # | # | # |
在 A 時間點,需要納入統計的部分都被我標上 # 了。A 需要統計: 2, 3, 4, 5 … 59, 0, 1 在 B 時間點,需要納入統計的部分都被我標上 # 了。B 需要統計: 4, 5 … 59, 0, 1, 2, 3
除了順序不大一樣之外,統計的範圍剛好都是一整個 0 ~ 59 的完整週期啊,從 0 加到 59 的數值就剛好是 ( 0 + 59) * 60 / 2 = 1770, 這正好可以拿來當作預期的結果,驗證我的統計引擎是否正確。因此,我可以預期暖機 (啟動執行1分鐘後,待統計資料開始能算滿完整的一分鐘) 之後,統計值都能維持在預期的 1770 才對。這就是測試程式的設計原理。
不過,只要跟時間扯上關係,有時就會有精確度的問題。統計上的時間差,有時會把剛好在一分鐘之前的資料,若稍有延遲,則會算在一分鐘之內,若稍有提前則會算在一分鐘之外。因此這邊我沒有像單元測試那樣直接判定驗證失敗,而是單純的把數值印出來,由人工判定,在誤差範圍內都算正確。
解法1, 直接使用資料庫的原始資料來計算
這個方案有很多種變形,基本上只要是從各種型態的 storage (不論是 SQL 或是 MongoDB 等等),不斷的撈出原始資料一筆一筆加起來統計的解法我都歸在這個層級。我會認定這層級的定位是:
- 對應職級: junior engineer
- 系統規模: 1 ~ 10 hosts
- 是否有效降低運重複的算量: 否 (不斷的重複加總區間內的資料)
- 是否適合長時間運行: 否 (orders table 資料筆數會不斷累積, 統計的區間長短會影響系統負載)
這解法很簡單,就是不斷地按照條件,下 SQL 指令查詢統計結果而已。不過這方法有三個致命的缺點:
- 你無法預期這 60 sec 之內有多少筆訂單? 這直接影響到 sum() 動作的效能
- 如果時間擴大到 3600 sec, 運算量馬上擴大到 60 倍。這直接影響到這做法能處理的時間區間大小
- 你無法預期這個 table 累積了多少筆歷史資料? 這直接影響到 where 挑出符合時間範圍資料的效能
當然有些工程師會想出變形的做法,比如替 (1) 加上 cache, 一秒內不用重新計算,或是 (2) 加上 archive 機制,定期搬走過期的資料,將資料筆數控制在一定時間範圍內,降低 (3) 的影響… 不過,即使如此,都沒有根本解決問題。我都認定這做法有他的規模限制… 如果我的訂單量大到沒有辦法一秒內完成至少一次統計,那這個方法就不成立了。曾經不只一個面試者還告訴過我改善的方式,把資料倒到另一個 database,做讀寫分離,讓這台資料庫專心計算…。我聽了心裡三條線… 一樣,這是個技術上正確的解法,但是… 我要為了一個統計多去養一台 DB 嗎?
總之,只要面試者的回答有下列這幾個特徵,不管是不是用 SQL,我都認定是這個層次的解決方案:
- 從 row data / database orders table 統計
- 用
select sum()… 的做法 - 沒有用任何降低數量級,控制計算量的機制
看到這邊,各位讀者們,你有想出更好的方法了嗎?
程式碼我就不做太多說明了,我直接把 Engine code (C#), SQL schema (T-SQL), 還有測試程式執行的 logs 貼在下方:
CREATE TABLE [dbo].[orders]
(
[Id] UNIQUEIDENTIFIER NOT NULL PRIMARY KEY DEFAULT newid(),
[time] DATETIME NOT NULL DEFAULT getdate(),
[amount] MONEY NOT NULL
)
GO
CREATE INDEX [IX_orders_Column] ON [dbo].[orders] ([time])
public class InDatabaseEngine : EngineBase
{
public override int StatisticResult
{
get
{
return this.GetSqlConn().ExecuteScalar<int>(@"select sum(amount) from [orders] where time between dateadd(second, -60, getdate()) and getdate();");
}
}
public override int CreateOrders(int amount)
{
this.GetSqlConn().ExecuteScalar(
@"insert [orders] (amount) values (@amount);",
new { amount = amount });
return amount;
}
private SqlConnection GetSqlConn()
{
return new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDB;Initial Catalog=AccountDB;Integrated Security=True;Connect Timeout=30;Encrypt=False;TrustServerCertificate=True;ApplicationIntent=ReadWrite;MultiSubnetFailover=False");
}
}
statistic: 1752, expected: 1770, test: False
statistic: 1769, expected: 1770, test: False
statistic: 1769, expected: 1770, test: False
statistic: 1752, expected: 1770, test: False
statistic: 1752, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1751, expected: 1770, test: False
statistic: 1751, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1750, expected: 1770, test: False
statistic: 1750, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1749, expected: 1770, test: False
statistic: 1749, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1748, expected: 1770, test: False
statistic: 1748, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1747, expected: 1770, test: False
statistic: 1747, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
Press any key to continue . . .
解法2, 在程式內直接統計
這個方案仰賴的不是背後的服務 (如上例,仰賴 SQL Server),著重在基礎的資料結構應用。基本上回答這種解法的,我會認定這解法能解決的層級在:
- 對應職級: senior engineer / architect
- 系統規模: 1 ~ 10 hosts
- 是否有效降低運重複的算量: 是 (只有非常簡單的累計計算)
- 是否適合長時間運行: 是 (過程中都只占用極低的系統資源)
資料結構,其實就是那幾種而已。我先從問題本身來看看該如何解決,然後再挑選對應的資料結構來處理。其實這類問題,只要一開始就把數字加總起來,放在 cache 等著讀取就可以了。這邊比較討厭的是超過時間的數據必須扣掉。
因此,我的想法是,如果這統計需要的精確度只到秒的話,我可以先做點前置處理,把一小時 3600 萬筆資料,先做局部統計化簡為 3600 筆統計資料 (每秒一筆)。往後的計算,不論是加總,或是剔除過時資料,都只需要針對這 3600 筆,而非 3600 萬筆資料。
如此一來,不論我要面對的訂單量是每秒 10000 orders/sec, 還是 100000 orders/sec, 或是更多, 其實除了累加 counter 的部分忙碌了點之外,其他的動作都一樣啊,簡單又快速。說明到這邊,你開始體會到用對資料結構,對於系統的影響有多大了嗎? 我想這個運算量,跟 [解法1] 的效率應該差到上萬倍以上了吧! 你還覺得學資料結構沒有用嗎? 你還覺得學這個只是應付考試而已嗎? XD
基本的 concept 有了,接下來就是實作了。再進一步,上面那 3600 筆統計資料, 每隔一秒都要把最舊的那筆拿出來處理後踢掉,reset 後放新資料… 這種 FIFO (First In, First Out), 不就是 Queue 的結構嗎?
越想越容易了,這些問題其實最花時間的都是思考而已,想通了之後寫出來其實都不值錢… 大概資工系剛畢業就能寫得出來了… 來看看我的版本,我先把這整個程序說明清楚吧! 我分成幾個步驟來完成這整個程序,可以參考下面這張圖來對照著看:
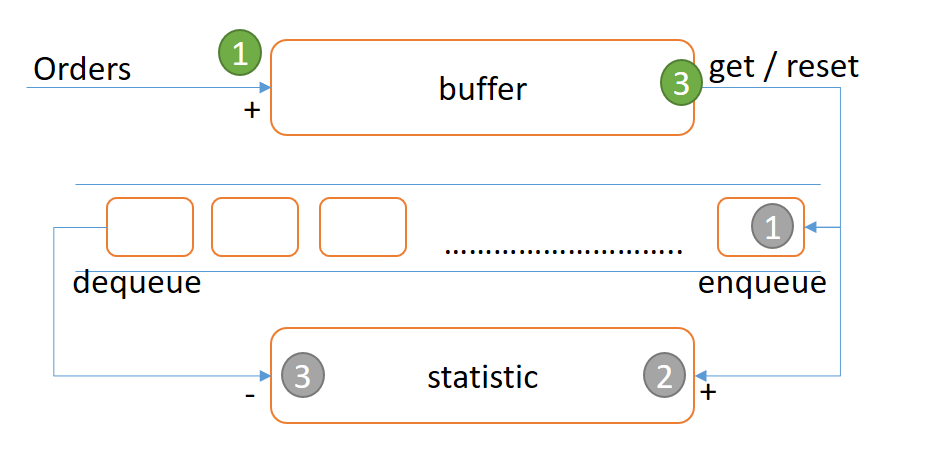
綠色的數字代表下列的項目,灰色的數字則代表 3-N 子項目
- 宣告
buffer變數,存放所有未被 worker 處理的訂單金額暫存區。任何新訂單進來,唯一的一個動作就是把訂單的金額累加到buffer這個變數身上。 - 宣告
statistic變數,存放已被worker處理的訂單金額暫存區。這個數值會隨時反映queue裡面所有資料的總和。 - 當時間過了
_interval後, 會自動觸發worker進行週期性的更新 (假設每 0.1 sec 處理一次):- 把
buffer的數值 reset 成 0, 同時把 reset 之前的數值放進queue - 把放進
queue的數值,累加到statistic變數身上 - 檢查
queue末端的資料,若先前放進queue的資料已經超過時限_period(假設為 60 sec), 則把她從queue移除,並且把被移除的數值從statistic身上扣除
- 把
- 任何時刻,要得知目前時段內 (60sec) 統計的總額時,只要傳回
statistic + buffer即可。
把上面的程序,寫成 code, 大致上就長的像這樣: InMemoryEngine 被建立起來之後,就會在背景執行 worker, 定期執行上述 3-1 ~ 3-3 的動作:
public class InMemoryEngine : EngineBase
{
public InMemoryEngine()
{
this._queue = new Queue<QueueItem>();
Task.Run(() =>
{
while (true)
{
Task.Delay(this._interval).Wait();
this._statistic_timer_worker();
}
});
}
public override int StatisticResult => this._statistic_result + this._buffer;
public override int CreateOrders(int amount) => Interlocked.Add(ref this._buffer, amount);
// 控制統計區間長度
private readonly TimeSpan _period = TimeSpan.FromMinutes(1);
// 控制統計的精確度
private readonly TimeSpan _interval = TimeSpan.FromSeconds(0.1);
private Queue<QueueItem> _queue = null;
private int _statistic_result = 0;
private int _buffer = 0;
private void _statistic_timer_worker()
{
int buffer_value = Interlocked.Exchange(ref this._buffer, 0);
this._queue.Enqueue(new QueueItem()
{
_count = buffer_value,
_time = DateTime.Now
});
this._statistic_result += buffer_value;
while (true)
{
if (this._queue.Peek()._time >= (DateTime.Now - this._period)) break;
{
QueueItem dqitem = this._queue.Dequeue();
this._statistic_result -= dqitem._count;
}
}
}
public class QueueItem
{
public int _count;
public DateTime _time;
}
}
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1722, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1721, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1720, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1718, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1717, expected: 1770, test: False
Press any key to continue . . .
真的不複雜啊,連空白行 + 註解,也不過 60 行… 簡單解釋一下這段 code 在幹嘛:
整個 Engine 關鍵的設定,就是 TimeSpan _period;, 決定要統計的時間範圍 (本例: 1 分鐘), 另外一個參數 TimeSpan _interval; 決定統計的精確度。整個運作機制,背後必須有個 worker, 每隔 _interval 區間要執行一次。每次就是把上次執行到這次之間的所有訂單累計在 _buffer 內的數據放進 _queue, 同時把超過統計範圍的資料從 _queue 拿出來。進出的過程中順便統計一下 _statistic_result (這數值代表目前 _queue 裡面所有數據的總和,不用每次再逐筆計算)。需要取目前的統計值的話,只要 return _statistic_result + _buffer; 就結束了。
唯一要特別注意的,就是 第一篇文章 講到的 lock… 在處理 _buffer 的過程中,要特別留意 lock 的問題。沒有處理好就會像第一篇文章提到的案例一樣,我不斷的 (平行處理) 下訂單,結果統計的機制可能因為 racing condition 導致有些數字被吃掉了。這邊有兩個地方要注意:
- 把訂單數值累加到
_buffer的部分:CreateOrders() - 把
_buffer的數值歸零,同時把歸零之前的數值放進Queue
原本應該用 lock 來解決,這邊我換了一個做法,用 .NET Framework 內建的 Interlocked 物件來處理。他內建 .Add() 可以在 thread safe 的前題下處理好遞增的問題。至於上述 (2) 也有現成的 method: .Exchange(), 會把第二個參數的數值放到第一個參數,同時在替換瞬間原本的值傳回。用這個 method 你不用擔心讀取出 _buffer 的值,到把 _buffer 歸零的這段時間內還有別人亂入,把訂單的金額加進去 (這樣歸零時就吃掉部分數據了)。.Exchange() 能保證這一瞬間不會有額外的動作插入。
接著,來看看這段程式會花掉的運算資源吧! 先用演算法的角度來評估一下時間跟空間的複雜度。精準一點的講這整個過程,假設每秒系統都會產生 N 筆訂單,你會發現:
- 增加訂單的動作:
CreateOrders()的時間複雜度是 O(1) - 取得目前統計資料的動作,時間複雜度是 O(1)
- 定期更新的 worker, 處理的時間複雜度也是 O(1)
- 整個過程中,系統需要的空間複雜度也只有 O(1) (固定為
_period / _interval x sizeof(QueueItem))
看起來真的沒啥好挑的,跑的又快又穩,程式碼又簡單,花的資源又小… 完全適用 N 極大或是極小的狀況…
看到這邊,你有想到這個層次的問題了嗎? 我面試到現在,還沒有完全精準的回答到這個層次的,不過倒是有幾位資質還不錯,方向有摸到邊了…! 如果你還沒看我文章就答的出答案,或是你有認識這種程度的朋友,記得介紹給我 :D
如果想要回頭好好學資料結構,可以回頭參考一下我這系列文章 (Orz, 眼看就要十年了… 有人是看我這幾篇文章入行的嗎?)
- 2008-09-27 該如何學好 “寫程式” ??
- 2008-10-01 該如何學好 “寫程式” #2. 為什麼 programmer 該學資料結構 ??
- 2008-10-08 該如何學好 “寫程式” #3. 進階應用 - 資料結構 + 問題分析
- 2008-10-20 該如何學好 “寫程式” #4. 你的程式夠 “可靠” 嗎?
- 2008-11-03 該如何學好 “寫程式” #5. 善用 TRACE / ASSERT
解法3, 分散式的統計
這個解法是 解法2 的延伸。基本概念是一樣的,但是同時要能掌握資料結構的應用,還要掌握搭配的系統架構才能落實。難度較高,同時考驗理論跟實作的能力:
- 對應職級: architect
- 系統規模: 10 ~ 100 hosts
- 是否有效降低運重複的算量: 是 (只有簡單的累計計算)
- 是否適合長時間運行: 是 (過程中都只占用極低的系統資源)
其實分散式的版本也沒啥不同,不過就是把上面 [解法2] 的 Queue 以及兩個暫存的變數 (buffer, statistic_result) 都搬到快速的 storage 放置而已。這邊想都不用想,繼續用 上一篇 提到的 Redis 來用。還記得上一篇講的 distributed lock 嗎? 你沒有搞好這些基礎就亂用的話,流量一大資料一定亂七八糟。
這種處理最忌諱碰到 racing condition 把數值都搞亂。最佳的解法,一定是優先看看 storage (redis) 本身是否提供這些 atomic operations ? 真的沒有,下下策才是自己搞定 distributed transaction, 或是 distributed lock 等等機制。但是相信我,這種東西你一定要懂,但是不一定要自己實作啊…
回過頭來看看 [解法2] 吧。撇除一般的 code 以及計算,裡面比較值得注意的地方有:
- 需要使用
Queue的資料結構 buffer變數需要increment及exchange兩種 atomic operationsstatistic_result變數需要increment及decrement兩種 atomic operations
還是同一句話,別自己搞這些東西啊,你搞清楚啥時該用這些機制就夠了。你在外面用 library 的型態,怎麼做都做不過內建的。先來看看 redis command list 是否支援這些資料型別,以及這些操作指令? 這時沒有好方法了,直接翻出 redis 的文件,找看看有沒有合適的吧。
Redis 雖然支援 lua script, 可以一次送一整組 script 到 redis server 上面執行,可以達到對等的效果。不過一來 script 要花掉額外的 redis server 效能,二來會把問題複雜化。這個範例主要是示範可行性,還有這是個面試題 XD (最重要的是我也不熟啊),因此就從簡吧… 以下都以內建的指令為準。
首先,在 Redis 支援的 Data Type 內找到 Lists.. (還好總共只有六種)
- Redis Data Type: Lists
Redis Lists are simply lists of strings, sorted by insertion order. It is possible to add elements to a Redis List pushing new elements on the head (on the left) or on the tail (on the right) of the list.
The LPUSH command inserts a new element on the head, while RPUSH inserts a new element on the tail. A new list is created when one of this operations is performed against an empty key. Similarly the key is removed from the key space if a list operation will empty the list. These are very handy semantics since all the list commands will behave exactly like they were called with an empty list if called with a non-existing key as argument.
雖然名字不叫 Queue, 但是就像 javascript 的 array 搭配 push pop 就可以當 stack 使用一樣,Redis 的 Lists 搭配 LPUSH / RPUSH / LPOP / RPOP 這四個指令,一樣可以當作 Queue / Stack 來用啊! 找到這個,算是解決上述 (1) 的問題了。
接下來繼續找找,有無針對特定 key / value 進行 increment / decrement / exchange 這三種 atomic operations… Orz, 要從 206 個指令逐一找出我需要的… 好的開始是成功的一半,至少先找到 redis 所有的 指令列表…
運氣還不錯,找到這三個:
- INCRBY key increment
Increments the number stored at key by increment. If the key does not exist, it is set to 0 before performing the operation. An error is returned if the key contains a value of the wrong type or contains a string that can not be represented as integer. This operation is limited to 64 bit signed integers.
- DECRBY key decrement
Decrements the number stored at key by decrement. If the key does not exist, it is set to 0 before performing the operation. An error is returned if the key contains a value of the wrong type or contains a string that can not be represented as integer. This operation is limited to 64 bit signed integers.
- GETSET key value
Atomically sets key to value and returns the old value stored at key. Returns an error when key exists but does not hold a string value.
看來實在太讚了,完全吻合我的需求啊! 別以為我的運氣真的那麼好,我想要的東西 Redis 都那麼 “剛好” 就幫我準備好。這只是再次驗證基礎知識的重要性而已。這些其實都是資料結構跟作業系統裡面的內容啊,如果我是 Redis 的作者,我也唸過這些課本的話,我自然也會把這些基礎功能放進指令集裡面。學會這些基礎知識,等於跟這些大師級的人物,以及這些系統都有一定程度的默契了,你想的大概都會有現成的支援 (除非你想的都是些旁門左道)。
所以,如果我說我在寫這個飯粒程式之前,對 Redis 是個門外漢,你會相信嗎? 事實上我還真是第一次認真研究 redis command list / data type, 還有第一次認真用 StackExchange.Redis 這個套件… 其實我的重點不是要炫耀什麼,而是再次強調這些基礎知識的重要性。你如果真的有打好這些基礎,自然會相信這些基礎建設 (redis) 一定會支援這些關鍵的操作或是對應的指令,剩下找文件的工作,只要花時間就能得到結果。相對於基礎知識不足的人,搞不好他要下關鍵字還不知道該怎麼 google ..
廢話不多說,既然確認了 Redis 完全支援我想要的功能了,那剩下的就是看看我用的 StackExchange.Redis 這個 .NET 套件,是否有封裝這些功能? 這邊我就不再囉嗦了,直接寫成 code:
public class InRedisEngine : EngineBase
{
private IDatabase redis = ConnectionMultiplexer.Connect("172.18.253.232:6379").GetDatabase();
public InRedisEngine(bool start_worker = true)
{
if (start_worker)
{
Task.Run(() =>
{
while (true)
{
Task.Delay(this._interval).Wait();
this._statistic_timer_worker();
}
});
}
}
public override int StatisticResult
{
get
{
return (int)this.redis.StringGet("statistic") + (int)this.redis.StringGet("buffer");
}
}
public override int CreateOrders(int amount)
{
return (int)this.redis.StringIncrement("buffer", amount);
}
// 控制統計區間長度
private readonly TimeSpan _period = TimeSpan.FromMinutes(1);
// 控制統計的精確度
private readonly TimeSpan _interval = TimeSpan.FromSeconds(0.1);
private void _statistic_timer_worker()
{
int buffer_value = (int)this.redis.StringGetSet("buffer", 0);
this.redis.ListRightPush("queue", QueueItem.Encode(new QueueItem()
{
_count = buffer_value,
_time = DateTime.Now
}));
this.redis.StringIncrement("statistic", buffer_value);
while (true)
{
QueueItem dqitem = QueueItem.Decode((string)this.redis.ListGetByIndex("queue", 0));
if (dqitem._time >= (DateTime.Now - this._period)) break;
dqitem = QueueItem.Decode((string)this.redis.ListLeftPop("queue"));
this.redis.StringDecrement("statistic", dqitem._count);
}
}
public class QueueItem
{
public int _count;
public DateTime _time;
public static string Encode(QueueItem value)
{
return $"{value._count},{(value._time - DateTime.MinValue).TotalMilliseconds}";
}
public static QueueItem Decode(string text)
{
string[] segments = text.Split(',');
return new QueueItem()
{
_count = int.Parse(segments[0]),
_time = DateTime.MinValue + TimeSpan.FromMilliseconds(double.Parse(segments[1]))
};
}
}
}
statistic: 1770, expected: 1770, test: True
statistic: 1767, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1766, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1765, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1763, expected: 1770, test: False
statistic: 1770, expected: 1770, test: True
statistic: 1770, expected: 1770, test: True
statistic: 1762, expected: 1770, test: False
Press any key to continue . . .
程式碼的結構完全跟 [解法2] 一樣,只是把幾個關鍵的變數搬到 Redis 上面而已。至於這樣是否真的有達到 “分散式” 的要求?
其實有的,因為所有的狀態都搬到 Redis 去處理了,所有 atomic operations 也都改成在分散式的狀態下,仍能維持這些操作的不可分割性(atomic operations)。唯獨 worker 的部分 (就是每隔 _interval 時間就要處理 buffer / queue / statistic 三者之間的數據的 worker) 只需要一份就夠了,這部分不需要到多個 instance 一起執行。因此稍微改一下 code, 我啟動 10 組 TestConsole.exe, 其中 9 個不啟動 worker … 來看看執行結果:
statistic: 17728, expected: 1770, test: False
statistic: 17518, expected: 1770, test: False
statistic: 17476, expected: 1770, test: False
statistic: 17730, expected: 1770, test: False
statistic: 17558, expected: 1770, test: False
statistic: 17429, expected: 1770, test: False
statistic: 17644, expected: 1770, test: False
statistic: 17644, expected: 1770, test: False
statistic: 17468, expected: 1770, test: False
statistic: 17689, expected: 1770, test: False
statistic: 17734, expected: 1770, test: False
statistic: 17374, expected: 1770, test: False
statistic: 17419, expected: 1770, test: False
statistic: 17736, expected: 1770, test: False
statistic: 17506, expected: 1770, test: False
statistic: 17460, expected: 1770, test: False
statistic: 17738, expected: 1770, test: False
statistic: 17503, expected: 1770, test: False
statistic: 17409, expected: 1770, test: False
statistic: 17740, expected: 1770, test: False
平行運作的狀態下,大約就是維持在 1770 x 10 = 17700 的每分鐘交易量。跑起來的結果落差不大,符合預期。
加分題: atomic operations
每次面試,只要問到類似的問題 (多執行緒,多工,平行處理,分散式運算… etc) ,往往面試者都會敗在這類的議題上面。不知是台灣的軟體業,大都在做系統整合,都注重在堆功能? 還是都沒機會碰過大流量? 或是需要大量平行處理的情境? 碰到的人都是很會寫功能,但是往往對確保平行處理時的資料正確性該怎麼做的觀念很薄弱…
前面的重點,都擺在資料結構與演算法,不過實作時確保幾個關鍵的動作絕對不會因為多工情況下,做到一半被別的動作打斷導致資料錯誤的狀況發生。通常不能被切割的這些操作,統稱為 atomic operations。如果面試者連這部分都能答的正確,面試官你真的不用考慮了,快點把這個人挖進來….
這邊理論沒啥好講的,實作也都講完了,我就把重點擺在怎麼驗證好了。不知讀者們還記不記得我去年寫的這篇文章?
這篇文章講到 Microsoft Excel 團隊,在 25 年前開發試算表引擎就用到的技巧: 兩個版本互相驗算。在除錯模式下,針對複雜的計算,先用很慢,但是保證正確的版本計算一次答案;之後再緊接著用高度最佳化,效能很好的版本再算一次,之後自動比對兩個版本的結果是否完全一致? 若不一致就觸發 ASSERT 維護警告。這其實就是在執行期做單元測試在做的事情啊! 這邊我也用一樣的技巧,來驗證一下這些統計的引擎是否真的有做好資料的正確性?
因此,測試程式我就稍做調整。原本是用固定的 timer + data, 看看統計出來的數據是否符合預期。現在有對照組 (我假設 InMemoryEngine 是可靠的),我不再需要預測統計的結果是否是 1770 了,直接比對即可。這時我產生訂單的模式就可以換掉了,我改用多執行緒,同時並行的插入大量的訂單,看看 Engine 在這種情況下,是否仍然能維持正確的計算?
我稍微調整一下前面用到的 InMemoryEngine, 在 constructor 加個參數,指定是否需要使用 lock ? 依據這個變數,我寫了兩種版本,一種是透過 Interlocked 物件,另一種就是一般不顧慮到 racing condition 的寫法。語意上完全一致,其餘邏輯通通不變。我貼一下改過的 code: (請自行留意 if (_use_lock) { ... } 的部分)
public class InMemoryEngine : EngineBase
{
private bool _use_lock = false;
public InMemoryEngine(bool use_lock = true)
{
this._queue = new Queue<QueueItem>();
this._use_lock = use_lock;
Task.Run(() =>
{
while (true)
{
Task.Delay(this._interval).Wait();
this._statistic_timer_worker();
}
});
}
public override int StatisticResult => this._statistic_result + this._buffer;
public override int CreateOrders(int amount)
{
if (this._use_lock)
{
return Interlocked.Add(ref this._buffer, amount);
}
else
{
return (this._buffer += amount);
}
}
// 控制統計區間長度
private readonly TimeSpan _period = TimeSpan.FromMinutes(1);
// 控制統計的精確度
private readonly TimeSpan _interval = TimeSpan.FromSeconds(0.1);
private Queue<QueueItem> _queue = null;
private int _statistic_result = 0;
private int _buffer = 0;
private void _statistic_timer_worker()
{
int buffer_value = 0;
if (this._use_lock)
{
buffer_value = Interlocked.Exchange(ref this._buffer, 0);
}
else
{
buffer_value = this._buffer;
this._buffer = 0;
}
this._queue.Enqueue(new QueueItem()
{
_count = buffer_value,
_time = DateTime.Now
});
this._statistic_result += buffer_value;
while (true)
{
if (this._queue.Peek()._time >= (DateTime.Now - this._period)) break;
{
QueueItem dqitem = this._queue.Dequeue();
this._statistic_result -= dqitem._count;
}
}
}
public class QueueItem
{
public int _count;
public DateTime _time;
}
}
再來看看修改過的 TestConsole, 可以任意指定兩種 Engine, 同時開啟 20 個執行緒,用全速產生金額為 1 的訂單… 同時用兩個 Engine, 同時輸入同樣的訂單資料。執行 10 秒鐘之後,比較兩個 Engine 統計的結果是否一致。若有誤差,則會印出誤差的比率(%):
先用兩個 InMemoryEngine (啟用 lock 的版本),來看看我們的程式是否運作正常?
engine #1: 32124680 (InMemoryEngine)
engine #2: 32124680 (InMemoryEngine)
compare: True (diff: 0.00%)
performance: 3212.468 orders/msec
Press any key to continue . . .
每秒鐘產生接近 300 萬筆的交易,結果一致。
接著來看看同樣的 InMemoryEngine, 啟用與停用 lock 的差別:
engine #1: 32428594 (InMemoryEngine)
engine #2: 31141202 (InMemoryEngine)
compare: False (diff: 3.97%)
performance: 3242.8594 orders/msec
Press any key to continue . . .
哈哈,看來不用追下去了,這個版本真是慘不忍睹… 沒有 lock 的版本,大約有 3.97% 的訂單資料在統計時會被吃掉…
接下來看看 InMemoryEngine 跟 InDatabaseEngine 的比較:
engine #1: 133438 (InMemoryEngine)
engine #2: 133438 (InDatabaseEngine)
compare: True (diff: 0.00%)
performance: 13.3438 orders/msec
Press any key to continue . . .
InDatabaseEngine 是寫入 raw data 到 SQL server, 再用 T-SQL 統計出來的,沒有所謂的 lock 與否,這就當對照組吧! 可以看到這做法只要資料都有寫入 DB ,結果是依定正確的。只是效能就大打折扣,跟 InMemoryEngine 相差約 250 倍…
接著再看看 InMemoryEngine 跟 InRedisEngine 的比較:
engine #1: 911738 (InMemoryEngine)
engine #2: 911738 (InRedisEngine)
compare: True (diff: 0.00%)
performance: 91.1738 orders/msec
Press any key to continue . . .
果然,我們針對 atomic operations 的控制發揮效用了,即使在平行處理的狀況下也能確保資料的正確性。數值跟 InMemoryTest 100% 正確,同時執行的效能也比 InDatabaseEngine 好上 6.83 倍。不過這效能還沒經過最佳化,同時跟 InMemoryEngine 的效能完全不能比 (差了 35.57 倍)。
本來我還想再繼續挖下去,不過再寫下去這篇就寫不完了,加分題的部分先到此告一段落….
加分題, 使用串流分析
如果需要做類似處理的問題不少,也達一定的規模,就可針對這樣需求建置適當的後端服務來解決了。其實這類問題就是很典型的串流分析 (stream analytics) 的應用。資料就像串流 (stream) 一樣不斷的流進來,就如同影音的串流處理一樣,串流分析可以連續性,不中斷的處理這些資料。
有經驗的架構師,通常技術能力都具備一定的深度與廣度,廣度足夠就能找到合適的解決方案,深度足夠就能精準的判定是否合用。
這邊的實作我就不弄了,已經遠遠超出面試題與 POC 的範圍了,這個解法容我嘴砲一下,用講的就好… 既然身為 Azure MVP, 拿 Azure Stream Analystic 當作例子也是很合理的… 來看看 Azure 串流分析的介紹與架構:
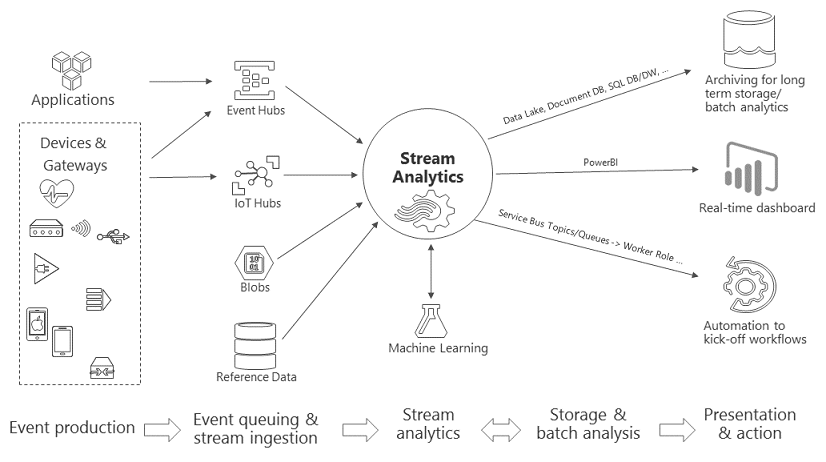
其實跟我們這篇講的模式很接近啊,只是 Azure 這邊的架構完整的多。前端都是有個 Queue 集中收集所有的資料來源,後端有個引擎在資料流入的過程中即時進行 (串流) 分析,之後把原始資料及分析資料往後端的 storage 丟,儲存起來供後續使用。
來看看中間串流分析這段的官方範例: Query examples for common Stream Analytics usage patterns
這段就完全是我們這個面試題的內容啊,連改都不用改,甚至原文就是 markdown, 我連編輯都省了 XD:
Description: Define the types of properties on the input stream. For example, the car weight is coming on the input stream as strings and needs to be converted to INT to perform SUM it up.
Input:
| Make | Time | Weight |
|---|---|---|
| Honda | 2015-01-01T00:00:01.0000000Z | “1000” |
| Honda | 2015-01-01T00:00:02.0000000Z | “2000” |
Output:
| Make | Weight |
|---|---|
| Honda | 3000 |
Solution:
SELECT
Make,
SUM(CAST(Weight AS BIGINT)) AS Weight
FROM
Input TIMESTAMP BY Time
GROUP BY
Make,
TumblingWindow(second, 10)
Azure Stream Analystics 讓我們用 SQL 的語法,可以查詢串流的資料。其中的 Group By 子句裡面 ThumblingWindow(second, 10) 就代表抓取現在時間 10 sec 內的資料,取出 SUM(....) 加總運算的數值出來。雖然看起來像是 SQL 語法,但是背後做的完全是另一回事啊! 有興趣的朋友們可以申請試用帳號來研究看看。
對我而言,我還是會以前面的基礎知識為優先。面試者至少需要了解前面幾種解法後,我認為才具備解決問題的能力。有了自己實作輪子的能力之後,採用這類的解決方案才能運用自如。面試過程中應試者若能答出這樣的 solution, 還能交代清楚這方案的優缺點跟使用時機的話,我會把它當作加分題 (而且是大加分),因為這樣代表面試者有足夠的能力挑選與判斷採用的架構。這種技術選型的能力是大型團隊非常欠缺的人才。
總結
前面一直沒機會做效能測試,最後總結之前,來個效能大亂鬥吧! 測試程式基本上跟上面的自我驗證是一樣的,只是一次只跑一個 Engine, 也不用再驗證計算是否正確了,單純是測試效能而已。看一下 source code:
static void LoadTest()
{
EngineBase e1 =
//new InMemoryEngine();
//new InDatabaseEngine();
new InRedisEngine();
bool stop = false;
int thread_count = 20;
List<Thread> threads = new List<Thread>();
for (int i = 0; i < thread_count; i++)
{
Thread t = new Thread(() =>
{
while (stop == false)
{
Thread.Sleep(0);
e1.CreateOrders(1);
}
});
threads.Add(t);
t.Start();
}
TimeSpan duration = TimeSpan.FromSeconds(10);
Thread.Sleep(duration);
stop = true;
foreach (Thread t in threads) t.Join();
Console.WriteLine($"engine #1: {e1.StatisticResult} ({e1.GetType().Name})");
Console.WriteLine($"performance: {e1.StatisticResult / duration.TotalMilliseconds} orders/msec");
}
用三種 engine, 分別跑一次測試,三段結果我就貼在一起了。按照文章介紹的順序:
engine #1: 34806296 (InMemoryEngine)
performance: 3480.6296 orders/msec
Press any key to continue . . .
engine #1: 170458 (InDatabaseEngine)
performance: 17.0458 orders/msec
Press any key to continue . . .
engine #1: 822800 (InRedisEngine)
performance: 82.28 orders/msec
Press any key to continue . . .
既然都要跑效能測試了,交代一下硬體環境也是很合理的.. 全部的服務我都裝在我的桌機裡面,沒有另外連到別的 server:
OS: Windows 10 Pro, x64, 1709
CPU: Intel Core i7-4785T, 2.20 GHz
RAM: DDR3L 16.0 GB
HDD: Intel SSD DC3520 480GB (MLC, SATA)
SQL: Microsoft SQL Server 2017 Develop Edition
Redis: Redis for Windows 3.2 (我用 windows container, image: alexellisio/redis-windows:3.2)
其實 InMemoryEngine 的效能是最好的 ,每秒高達 340 萬筆交易的乘載量。但是受限於單機版 (所有資料都只存在 memory 裡面),也無法做任何 scale out, 或是備援的機制。這限制了它的應用範圍 (即使它的效能最好)。如果你只是需要在 application 做簡單的統計,那這個做法很適合,大概用 library 的方式就可以發行使用了。
第二是 InRedisEngine, 透過 redis 當作後端的儲存,可以達到每秒 8.2 萬筆交易的乘載量。其實這個數字,透過適當的架構調整,還有 scale up 的空間。架構調整得宜的話,甚至能做到 High Availability 高可用度的要求,在架構規劃上是最理想的做法。
至於 InDatabaseEngine, 基本上這樣做的做法是不及格的,每秒只有 1.7 萬筆交易的乘載量,免強符合這次面試題的要求。除非既有的系統沒辦法調整,只能硬幹,或是其他不得以的原因。不然這個做法我是最不能接受的。效能不好,又把最昂貴的 SQL 運算能力及 IO 能力都賠進去了,得不嘗失。
寫到這裡,還是回到寫這系列文章的初衷。軟體業最缺的就是人才啊,不論是 junior / senior engineer, 或是 architect 都是,挑對一個人選,可以幫你解決 10 個人都解決不了的問題。不過在抱怨千里馬難尋的同時,面試官本身也要做好準備,讓自己具備伯樂的鑑別能力才行啊,否則人才就從你眼前溜走那就更令人扼腕了。我之所以會在這些特定的主題,不斷的往下挖下去,目的就是想看看面試者的能耐在哪邊。這些跟 scalability 相關的技術能力,都是帶領團隊邁向微服務架構的重要能力。
第二篇寫到這邊終於寫完了 T_T,後面還有幾篇,請各位敬請期待! 如果你因為我的文章,找到合適的人選,或是找到合適的工作,也歡迎在底下分享你的經驗 :D
