這類文章還真不好寫,想了好幾天,才擠的出一篇文章。第一篇已經講了一堆教條了,第二篇也舉了簡單的例子,說明挑對資料結構的重要性,接下來這篇會把主題放在更複雜的例子上,到底那些地方該注重技術,而那些地方該把重點放在基礎的資料結構及演算法身上。
接續前文:
前言: 如何學好寫程式 系列文章導讀
- 該如何學好 “寫程式” #1, 2008/09/27
- 該如何學好 “寫程式” #2. 為什麼 programmer 該學資料結構 ??, 2008/10/01
- 該如何學好 “寫程式” #3. 進階應用 - 資料結構 + 問題分析, 2008/10/08
- 該如何學好 “寫程式” #4. 你的程式夠 “可靠” 嗎?, 2008/10/20
- 該如何學好 “寫程式” #5. 善用 TRACE / ASSERT, 2008/11/03
這次不囉唆半天了,先來回顧一下第一篇,我出的題目是這樣:
以台灣高速公路為題 (中山高、北二高、國道二號),你有辦法寫程式,讓使用者指定起點跟終點的交流道,然後替它找出建議的路線嗎? (把延路經過的交流到跟收費站列出來就好)。
舉這個題目,是怕前面的例子被嫌太簡單,一點都不能符合實際的情況。沒錯,絕大部份的情況都不會像上一篇的範例一樣,放一堆資料在記憶體裡 SEARCH 出來就了事那麼簡單。高速公路的問題核心一樣是在資料結構,不過這次多了必需自己實作的演算法。
跟我一樣五六年級的人,都聽過這句話吧,PASCAL 之父 (Niklaus Wirth) 講的這句名言: “程式 = 資料結構+演算法“,沒錯,這個範例就需要用到這兩種能力才搞的定。依我的看法,解決這問題有三道關卡要闖:
- 你該用什麼樣的方式來儲存這樣的地圖資訊?
這裡會用到的知識,是資料結構裡的 GRAPH,典型的方法就是分成點跟線來記錄.. - 你該用什麼樣的演算法,找出你要的最佳路線?
最基本的是要找出所有可走的路線 (走迷宮),再找出其中最便宜的一條路。 - 你的程式的結構該如何設計?
這部份跟課本比較無關,講的是你對程式語言及可用的函式庫/工具的掌握,還有架構等等。
這三道關卡,要依序破解,前一關的決定會影響到後面的解決方式。先從資料來說,連該怎麼記錄這些資料,就別想解題了。最基本的 GRAPH 需要點 (NODE) 及點跟點之間的連線 (LINK) 組成。很直覺的就可以定出這兩個類別:
描述交流道/收費站的 class:
public class Node
{
public string Name = null;
public int TollFee = 0;
public List<Link> Links = new List<Link>();
public Node(string name, int tollFee)
{
this.Name = name;
this.TollFee = tollFee;
}
}
描述兩個點之間的路段 (Link) 的 class:
public class Link
{
public double Distance = 0D;
public Node FromNode = null;
public Node ToNode = null;
public RoadNameEnum Road;
public Link(Node from, Node to, double distance, RoadNameEnum road)
{
this.FromNode = from;
this.ToNode = to;
this.Distance = distance;
this.Road = road;
}
public enum RoadNameEnum
{
Highway1,
Highway2,
Highway3
}
}
好像沒什麼特別的,每個點除了搭配 List 來記錄所有經過它的路段 (Node.Links) 之外,也標上了這個點的名字 (Node.Name),跟過路費 (Node.TollFee)。而每個路段則記錄了它兩個端點 (Link.FromNode, Link.ToNode) 之外,也額外記錄了路段的距離 (Node.Distance),及它是屬於那一條高速公路的資訊 (Link.Road)。
接下來就要載入資料了。我偷個懶,只記中山高跟北二高新竹以北的部份,還有機場國道。實在是沒力氣把全部的路段打完… 哈哈。資料來源是參考國道高速公路局 的網頁。以下是 Map 類別的部份程式碼,及載入部份地圖資訊的程式碼:
public class Map
{
private Dictionary<string, Node> _nodes = new Dictionary<string, Node>();
public Map()
{
//
// construct / load map data
//
this.AddNode("基金", 0);
this.AddNode("七堵收費站", 40);
this.AddNode("汐止系統", 0);
this.AddNode("樹林收費站", 40);
// 略
this.AddLink("基金", "七堵收費站", 4.9-0, Link.RoadNameEnum.Highway3);
this.AddLink("七堵收費站", "汐止系統", 10.9-4.9, Link.RoadNameEnum.Highway3);
// 略
}
private void AddNode(string name, int tollFee)
{
Node n = new Node(name, tollFee);
this._nodes.Add(name, n);
}
private void AddLink(string n1, string n2, double distance, Link.RoadNameEnum road)
{
Node node1 = this._nodes[n1];
Node node2 = this._nodes[n2];
Link link = new Link(this._nodes[n1], this._nodes[n2], distance, road);
node1.Links.Add(link);
node2.Links.Add(link);
}
public Link FindLink(string name1, string name2)
{
foreach (Link way in this._nodes[name1].Links)
{
if (way.GetOtherNodeName(name1) == name2) return way;
}
return null;
}
}
第一步準備動作完成了。接下來就是想辦法在 class Map 裡加上 FindBestWay( ) method, 來找出最佳路線。在這邊先定義一下什麼叫最佳路線。一般不外乎是找最短的路線,或是通過最少的收費站,我們來點實際的,以油價每公升 30 元為例,車子就假設一公升可以跑 15 公里好了,因此每跑一公里要花兩塊錢。最佳路逕就是花的油錢跟過路費最少的為準。
沒唸過資料結構的朋友們,現在大概卡住了。該怎樣找出最佳的路逕? 電腦什麼不行,就是計算很快,這種最佳解的問題,通常都可以用暴力法解決。只要把所有的路線找出來,然後找出總花費最便宜的那個路線就好。雖然資料結構的書通常會舉其它更有效率的演算法,其中一個演算法的名字我不記得了,大致的步驟是由起點開始往外擴散,先算走一步可以走到那些點,再往外推,如果到同一點有兩條以上的路線,就保留便宜的那個… 直到推到終點為止。
不過這方法寫起來比較麻煩,我挑另一個簡單一點的 (相對的比較沒效率),就是搭配 STACK 走迷宮的方法,把所有路線試過一次,找出所有能從起點到終點的路線,再從其中挑出最經濟的。
為什麼我會挑這個? 只是因為它的邏輯比較簡單易懂,畢竟這個程式不是在比賽,要去拼最快的話就不用了.. 哈哈。資料結構在講到 TREE 一定會講到怎麼樣把 TREE 的每個節點都走一次的方法,就是要搭配 STACK,把走過的點都 PUSH 進去,當作麵包屑來用,等走到沒路了就 POP 退回上一步,改走第二個分岔,直到所有的點都走完為止。
接下來就要把 GRAPH 切掉幾條線,把它想像成長的不大整齊的 TREE,就從起點開始走下去。因為 GRAPH 不像 TREE,有可能會走回原點,因此我們在走的過程中需要跳過已經走過的點,免的最後都在兜圈子繞不出去。
這邊我搭配了遞迴 (RECURSIVE) 的方式來簡化問題。其實就邏輯來說,遞迴幾乎可以跟 STACK 劃上等號。因為遞迴的過程中也是有 STACK 在輔助 (就是 CALL STACK)。不過我偏愛 RECURSIVE,因為藉著 CALL STACK 加上 FUNCTION CALL 傳遞的參數,可以自動幫我處理不少 push / pop, 及替每個階段保存暫時的資料,程式看起來會簡單很多。
找出最經濟路線的程式碼:
private double _cost = 0;
private string[] _best_path = null;
private Stack<string> _path = null;
private void Search(string startName, string endName, double current_cost)
{
this._path.Push(startName);
if (startName == endName)
{
if (this._cost == 0 || current_cost < this._cost)
{
this._cost = current_cost;
this._best_path = this._path.ToArray();
}
this._path.Pop();
return;
}
foreach (Link way in this._nodes[startName].Links)
{
string next = way.GetOtherNodeName(startName);
if (this._path.Contains(next) == false)
{
this.Search(
next,
endName,
current_cost + this._nodes[next].TollFee + way.Distance * 3);
}
}
this._path.Pop();
}
public string[] FindBestPath(string startName, string endName, out double cost)
{
try
{
this._cost = 0;
this._path = new Stack<string>();
this.Search(startName, endName, 0);
cost = this._cost;
return this._best_path;
}
finally
{
this._cost = 0;
this._path = null;
}
}
先來看看結果。主程式是要找出 “機場端” 跟 “基金” 交流道之間的最經濟路線,看看程式跑出來的結果:
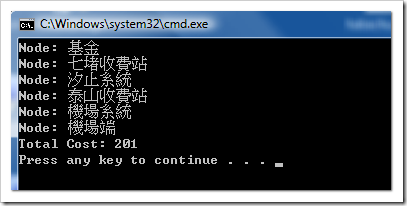
不相信的人就拿紙筆畫一畫算一算吧! 應該是沒算錯啦。這個例子我就不像上一個例子,放上千萬個節點來拼拼看速度到底多快了,因為我沒有現成的資料啊,這東西要產生假資料也麻煩的多,就略過這個步驟了。不過我們倒是可以回過頭來看看,目前這段程式有什麼可以改進的?
首先,在資料數量遽增的情況下,演算法的改善一定是第一要務。你會發現程式碼從五行變成三行,或是從 100ms 進步到 90ms, 這種程度的改善相較之下都是微不足道的,一來這種改善程度通常是固定的,因為演算法沒有變,整體來說可能只是從 100sec 進步到 90sec,我是客戶的話,還不如換顆快一點的 CPU 就好了…。但是演算法的改進,則是讓你迴圈的次數變少,或是比較的次數變少等等,改變幅度通常是以倍數來算,隨便就提升好幾倍的效能。這就不是升級 CPU 可以解決的問題…。還記得上個例子嗎? 從 List 換成 SortedList, 搜尋速度差了 6000 倍… 你要花多少錢才買的到運算速度快 6000 倍的電腦?
除了演算法之外,程式也是有其它地方可以改善的。看到第 20 行程式碼了嗎? 就是找出下一步是不是已經走過了的程式碼:
if (this._path.Contains(next) == false)
其中 _path 是 Stack
This method performs a linear search; therefore, this method is an O(n) operation, where n is Count.
看起來它的效果跟 List 一樣,搜尋都很慢,有幾筆就要比對幾次。還記得上一篇提過什麼方法? 如果排序過的資料,要花的時間是 O(log n), 如果是採用 HashTable 結構的,則只要 O(1)… 再把 MSDN 拿出來翻翻看,發現除了 Dictionary<TKey, TValue> 之外,還有另一個更適合的 HashSet (.NET 3.5 only):
The HashSet
class provides high performance set operations. A set is a collection that contains no duplicate elements, and whose elements are in no particular order. The capacity of a HashSet
object is the number of elements that the object can hold. A HashSet object's capacity automatically increases as elements are added to the object.
馬上看一下,新增一筆及找出某一筆需要的時間複雜度:
HashSet
If Count is less than the capacity of the internal array, this method is an O(1) operation. If the HashSet
object must be resized, this method becomes an O(n) operation, where n is Count.
HashSet
This method is an O(1) operation
看起來沒什麼好挑的了。把資料塞進去跟找出來的時間都是固定的,當地圖的節點夠多,你要找的目標夠遠,多花一倍的空間另外放一份 HashSet 絕對是值得的。也因為 HashSet 有這樣的特性,因此它特別適合拿來作集合的運算。比如兩堆資料要找出交集 (Intersection),聯集 (Union) 等等都很方便。既然都講了就順手查看看:
HashSet
If the collection represented by the other parameter is a HashSet
collection with the same equality comparer as the current HashSet object, this method is an O(n) operation. Otherwise, this method is an O(n + m) operation, where n is Count and m is the number of elements in other.
本系列文章 [該如何學好 “寫程式”] 第一部份就先到這裡。在這裡作個小結。既然第一部份我是在探討要成為一個好的 “programmer” 該具備的能力,我自然是把重點放在怎樣把你拿到的需求,忠實且正確的寫成 code 為主。這時邏輯及觀念,還有資料結構等等基礎的知識是我認為的重點。也許有些讀者很不以為然,我猜想的大概會有這幾個理由:
- 我不會這些,程式還不一樣寫的好好的?
- 都什麼年代了,現在講求的是程式架構!
- 物件導向不是都講求封裝? 幹嘛還要去挖這些?
- 現在資料都放資料庫了,還學這幹嘛?
- …
其實這些論點也沒錯,不過上一篇可以看到,不懂得這些基礎的話,現成的物件給你挑也不見得知道要挑那一個,更慘的是連之間的差別都不曉得。還有,資料結構通常包含兩個層面,一個是怎麼 “描述” 你的資料? 另一個是怎麼去應用你的資料? 以這題為例,如果你都不曉得要把地圖拆成點跟線來記錄,你會知道 TABLE 該怎麼建嗎?
另外,很多資料庫上面效能的問題,也都跟資料結構有關。就跟上一篇該挑那一種 Collection 一樣,資料庫也可以把它當成一個更巨大,功能更多的 Collection 來看待,因此能不能有效的利用它,資料結構也是很重要的觀念之一。
再來講到架構的部份,我覺的 這位網友在他的 blog (我不認得他本人,只是常看他文章) 發表的這兩篇文章很不錯:
他這兩篇講的就是兩個極端,一個講求效率跟演算法,另一個則是講求架構跟程式的美感。而這兩者通常不容易兼顧。以我來說我比較偏後者,效能的部份,我會捨棄一些小地方以換來程式碼的可擴充性,可讀性,架構等等。不過我不會放棄的是資料結構跟演算法的正確性,就如同前面寫的例子一樣,程式碼有沒有最佳化,差的是 xx % 的效能,但是演算法跟資料結構的差距,則是好幾倍。我一向認為不會跑就要學飛,遲早會跌下來的,所以才會寫這三篇針對 programmer 的文章。
接下來,就換到 software engineer 了。這個階段就不只是把程式碼 “寫對” 或是 “寫出來” 而以,而是要開始考慮怎樣才 “寫的好” 了。有興趣的讀者們請耐心等待續集 :D
– 範例程式下載: Taiwan-Highway.zip
