自從貼了上一篇 該如何學好 “寫程式” 一文,原本以為這種老生常談的內容沒什麼人會看,沒想到還有人給我回應.. :D 原來這種文章還是有市場的。接下來這篇,是延續上一篇,來談談要成為合格的 programmer, 我認為應該要俱備的 “內功” 是什麼。上篇我提到,我認知的 programmer,就是要有實作 (CODING) 的能力。要有能力把技術規格 (像是輸入格式,操作介面等等) 具體的寫成可以執行的程式碼。當然是要寫的又快又好,穩定不當機又沒 BUG …。
前言: 如何學好寫程式 系列文章導讀
- 該如何學好 “寫程式” #1, 2008/09/27
- 該如何學好 “寫程式” #2. 為什麼 programmer 該學資料結構 ??, 2008/10/01
- 該如何學好 “寫程式” #3. 進階應用 - 資料結構 + 問題分析, 2008/10/08
- 該如何學好 “寫程式” #4. 你的程式夠 “可靠” 嗎?, 2008/10/20
- 該如何學好 “寫程式” #5. 善用 TRACE / ASSERT, 2008/11/03
在這個階段 (programmer),會一些具體的工具或是技術是必要的,但是它絕對不是主角。如何去運用你的工具才是關鍵。我認為 “資料結構” 就是能正確運用你的工具 (程式語言及函式庫) 最重要的知識。我常看到很多會一堆 “先進” 的技術,卻寫出很可笑的 code … 。這種例子太多了,兩層迴圈擺錯順序,或是某些動作 不小心 擺到迴圈內,多花了好幾倍的時間在做冤枉事…。這種例子我通通把它規在基本功夫不好,或是常聽的邏輯觀念不佳。所以在上一篇我會提到,好的 programmer 至少能滿足我講的三個基本要求:
- 丟一付洗過的撲克牌給你 (不要多,黑桃1 ~ 13就好),你知道怎麼用 Bubble Sort / Quick Sort 的步驟把它排好嗎? 丟一個陣列,裡面隨便打幾個數字,你能寫程式把它由小到大排好印出來嗎?
- 假設記憶體夠大的話,你有辦法把一百萬筆通訊錄資料讀到記憶體內 (用什麼物件都隨你),然後還能用很快的速度找到你要的資料嗎? 不同的搜尋方式,你知道該用什麼樣的方式找才有效率嗎?
- 以台灣高速公路為題 (中山高、北二高、國道二號),你有辦法寫程式,讓使用者指定起點跟終點的交流道,然後替它找出建議的路線嗎? (把延路經過的交流到跟收費站列出來就好)
第一個只要你知道排序的方法,剩下的就是你有沒有本事把腦袋的想法寫成 CODE 而以。這個要求大部份的人都能過關,我就不多作解釋了。來看看第二個要求,它考驗的是你該用什麼樣的方式 “SEARCH” ?
我就以 C# 為例來說明這個問題該怎樣思考。以資訊系的 “資料結構” 這門課的角度來思考,你應該要找出個適合的資料結構 (Binary Tree, Heap, Linked List … etc) 來存放這堆資料。不過資料結構這麼多種,你都要自己做嗎? .NET framework 已經在 System.Collection.Generic 這命名空間內提供了一堆好用的 Collection 給你用了,你該怎麼挑選才好? 課堂上老師不會教你實作的東西,而公司的前輩也不會教你這種基礎的東西,那你該怎麼把這兩者應用在一起?
就先從 (2) 的例子開始吧! 通訊錄最基本的要求,就是儲存的資料要能按照姓名/EMAIL/電話號碼排序。輸入名字後,要能很快的找到這個人完整的通訊錄。如果能像手機一樣,邊輸入名字就邊過濾名單,直到名字打完人就找到的話更好。在宣告了 class ContactData { ... } 類別來處理一筆資料後,下一步你會怎麼做?
ContactData 類別定義:
public class ContactData
{
public string Name;
public string EmailAddress;
public string PhoneNumber;
public void OutputData(TextWriter writer)
{
writer.WriteLine("Name:\t{0}", this.Name);
writer.WriteLine("Email:\t{0}", this.EmailAddress);
writer.WriteLine("Phone:\t{0}", this.PhoneNumber);
writer.WriteLine();
}
}
開始來看看,有基本功夫的 programmer 跟一般 “熟 C# 熟 .NET” 的 programmer 差在那裡吧! 程式很簡單,先產生一百萬筆假資料,然後去找 A123456 這個人的資料,接著再找出手機號碼為 0928-1234 開頭的所有人資料。事後會分別計算花掉的時間跟程式佔用的記憶體大小。
- 大概有 70% 的人,會選擇用
List<ContactData>,不為什麼,只因為他沒想到別的方法,或是直覺就覺的要這樣寫… 來看看這樣的 code:
用 List<ContactData> 寫的範例程式
private static void Sample1()
{
Stopwatch timer = new Stopwatch();
timer.Reset();
timer.Start();
// 產生假資料庫
List<ContactData> contacts = new List<ContactData>();
{
for (int index = 999999; index >= 0; index--)
{
ContactData cd = new ContactData();
cd.Name = string.Format("A{0:D6}", index);
cd.EmailAddress = string.Format("{0:D6}@chicken-house.net", index);
cd.PhoneNumber = string.Format("0928-{0:D6}", index);
contacts.Add(cd);
}
}
Console.WriteLine("建資料花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
timer.Reset();
timer.Start();
{
// 搜尋 A123456 這個人的資料
ContactData data = null;
data = contacts.Find(delegate(ContactData x) { return x.Name == "A123456"; });
Console.WriteLine("搜尋 A123456 花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
//data.OutputData(Console.Out);
}
timer.Reset();
timer.Start();
{
// 列出電話號碼為 0928-1234* 開頭的使用者
foreach (ContactData match in contacts.FindAll(delegate(ContactData x) { return x.PhoneNumber.StartsWith("0928-1234"); }))
{
//match.OutputData(Console.Out);
}
Console.WriteLine("搜尋 0928-1234* 資料花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
}
Console.WriteLine("共使用記憶體: {0}MB", Environment.WorkingSet / 1000000);
}
憑良心說,寫的出這樣程式碼的人,已經算是高手了。因為這樣已經用到不少高級技巧,像是 delegate, anonums method, 還有知道
List<T>.Find( ) 怎麼用等等… 以下是他的執行結果:
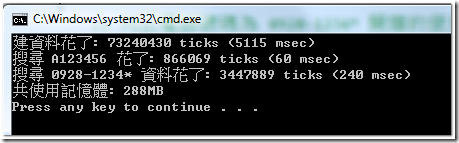
- 更進階一點的人 (另外 25%),也許會額外加上
Dictionary當作索引,來改善 search A123456 這筆資料的效率:
加上 Dictionary 當作索引的 code:
// 略
// 產生假資料庫
Dictionary<string, ContactData> name_index = new Dictionary<string, ContactData>();
List<ContactData> contacts = new List<ContactData>();
{
for (int index = 999999; index >= 0; index--)
{
ContactData cd = new ContactData();
cd.Name = string.Format("A{0:D6}", index);
cd.EmailAddress = string.Format("{0:D6}@chicken-house.net", index);
cd.PhoneNumber = string.Format("0928-{0:D6}", index);
name_index.Add(cd.Name, cd);
contacts.Add(cd);
}
}
Console.WriteLine("建資料花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
timer.Reset();
timer.Start();
{
// 搜尋 A123456 這個人的資料
ContactData data = name_index["A123456"];
//data = contacts.Find(delegate(ContactData x) { return x.Name == "A123456"; });
Console.WriteLine("搜尋 A123456 花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
//data.OutputData(Console.Out);
}
// 略</pre>
會寫到這樣,也算強者了。不但對 C# 夠熟,也有用 Collection 物件來當作索引的觀念。程式碼只有兩行不同,一個是多宣告了 Dictionary 物件 (第3行),另一個是搜尋的地方 (第21行)。來看看執行結果:
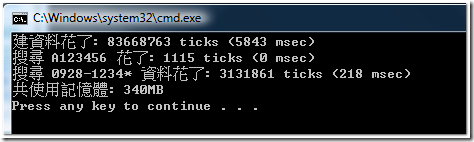
果然有效,建資料從 5151ms 變成 5843ms, 記憶體從 288MB 變成 340MB,不過 search(A123456) 卻快的嚇人, 0ms… 破錶了!
但是這樣的 CODE 老實說只能算是及格而以,因為它沒有挑對 Collection 來用。怎麼說? 我的理由有這幾個:
List<T>的搜尋效能不好- 沒能滿足用多種排序方式的要求 (需要時要當場執行
List<T>.Sort( ))
如果這是某個 Mail Client 內的 CODE,產品經理一定會問:
“如果資料從一百萬筆,變成一億筆,程式的表現會是什麼情況?”
有沒有基本功夫,這裡開始有差別了。唸過資料結構的都知道有個叫 “時間複雜度” (time complexity) 的東西,用 O(n) 表示。O(n) 代表花費的時間會跟資料比數成線性的成長。100倍的資料大概就要花上100倍的時間.. 如果是 O(n^2) 的演算法,則 100 倍的資料就會花上 10000 倍的時間。
MSDN 專業的地方就在這裡。Microsoft 真的很細心的在每一個 Collection 物件的說明文件上,都會標上 time complexity。有唸書有保佑,瞄到那行字我的問題就都解決掉了。先來看看 List<T> 的行為:
**List
If Count is less than Capacity, this method is an O(1) operation. If the capacity needs to be increased to accommodate the new element, this method becomes an O(n) operation, where n is Count.
[List
.FindAll(Predicate match)](http://msdn.microsoft.com/en-us/library/fh1w7y8z.aspx) This method performs a linear search; therefore, this method is an O(n) operation, where n is Count.
再來看看 Dictionary<TKey, TValue> 的行為:
Dictionary<TKey, TValue>.Add(TKey key, TValue value)
If Count is less than the capacity, this method approaches an O(1) operation. If the capacity must be increased to accommodate the new element, this method becomes an O(n) operation, where n is Count.
Dictionary<TKey, TValue>.Item[TKey key] {get; set;}
Getting or setting the value of this property approaches an O(1) operation.
好,答案出來了。當資料變成一百倍時,List.Add 是 O(1), 所以每加一筆資料的時間不會越來越久 (safe). 但是搜尋時間是 O(n), 意思是現在找 A123456 要花 60ms, 未來有一億筆就要花 60x100=6000ms=6sec, 找 0928-1234* 則要花 240x100=24000ms=24sec… 以這樣的成長速度,記憶體還沒用完,你的程式就會慢到受不了了。有沒有其它的解決辦法?
換成 Dictionary 就酷多了,搜尋時間是 O(1), 代表不管你有幾筆,搜尋的時間都差不多。為什麼? MSDN 說的很清楚…
http://msdn.microsoft.com/en-us/library/xfhwa508.aspx
The Dictionary<(Of <(TKey, TValue>)>) generic class provides a mapping from a set of keys to a set of values. Each addition to the dictionary consists of a value and its associated key. Retrieving a value by using its key is very fast, close to O(1), because the Dictionary<(Of <(TKey, TValue>)>) class is implemented as a hash table.
什麼是 HashTable? 又是一個好例子,唸過資料結構的都知道吧? 我就不多說了,請看 wiki:
http://en.wikipedia.org/wiki/Hashtable
一樣是看 MSDN 文件,有沒有唸過資料結構,到這裡就差這麼多了。體會到學校教的東西真的有用了嗎? 這個例子還沒完,再看下去。
事實上,以上的實作方式都不合格。LIST 效能不好,Dictionary 拿來作索引有個致命的缺點:
它的 KEY 不能重複!!!
是的,對應到資料庫的話,它就好像是個 unique key 一樣。拿來當 NAME 的索引還沒問題,拿來當其它欄位的索引就糟糕了,別說效能問題,連用都不能用。
另外,針對排序的問題也是無解,這是 HashTable 的特性,要照順序排,就要另請高明。
事實上,以上的實作方式都不合格。List 搜尋的效能不算好,而 Dictionary 也只能處理 exact match 的狀況,同時也無法處理需要排序的問題。
唸過書的再想想,這時該怎麼辦?
標準解法是分別照這幾個欄位排序,然後用 Binary Search. 這才是正解。因為排序好的資料就像一般資料庫的 index, 可以讓你很容易的 order by, 同時又能讓你很快的找到你要的資料,甚至是列出某一段範圍的資料都沒問題。
不過寫成程式要怎麼作? MSDN 就在手上嘛,System.Collection.Generic 就把它當購物網站,逛一逛… 看有沒有其它合用的。
不錯,又找到兩個: SortedList 跟 SortedDictionary,還是一樣,那一個比較合適? MSDN 都寫的很清楚,足夠你判斷了,前題是資料結構教的幾個基本觀念 (像是前面講的 Hash Table, Time Complexity 等) 人家寫出來你要看的懂,看的懂就知道該挑那一個。
至於挑選的過程我就不多說了。我最後決定用 SortedList, 列一下這個 Collection 的特性:
SortedList.Add( )
This method is an O(n) operation for unsorted data, where n is Count. It is an O(log n) operation if the new element is added at the end of the list. If insertion causes a resize, the operation is O(n).
新增一筆需要的時間是 O(n), 唯一特例是加在最後面,而且沒引發 resize 的動作,就是 O(log n)。至於排序? 通通是 O(1),因為在 Add() 把資料加進來時就排好序了,所以 Add() 花的 O(log n) 就是在排序。要照順序印資料或找資料,完全不費吹灰之力,拿來印就是了。不過比較可惜的是,SortedList 並沒有提供 BinarySearch,因此要找 “0928-1234*” 這樣的資料要辛苦點,自己用 BinarySearch 的邏輯,簡單寫一下吧。如果前面的關卡都過了,這應該不難吧?
改用 SortedList 最大的缺點就是載入資料時會比較慢,不過其它在程式的處理上,還有效能都更貼近這個題目的需求。來看看程式碼,這次我用了兩個 SortedList,分別代表替 name 及 phone number 作排序:
改用 SortedList<T> 的範例:
private static void Sample3()
{
Stopwatch timer = new Stopwatch();
timer.Reset();
timer.Start();
// 產生假資料庫
SortedList<string, ContactData> name_index = new SortedList<string, ContactData>();
SortedList<string, ContactData> phone_index = new SortedList<string, ContactData>();
{
for (int index = 0; index < 1000000; index++)
{
ContactData cd = new ContactData();
cd.Name = string.Format("A{0:D6}", index);
cd.EmailAddress = string.Format("{0:D6}@chicken-house.net", index);
cd.PhoneNumber = string.Format("0928-{0:D6}", index);
name_index.Add(cd.Name, cd);
phone_index.Add(cd.PhoneNumber, cd);
}
}
Console.WriteLine("建資料花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
timer.Reset();
timer.Start();
{
// 搜尋 A123456 這個人的資料
ContactData data = name_index["A123456"];
Console.WriteLine("搜尋 A123456 花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
//data.OutputData(Console.Out);
}
timer.Reset();
timer.Start();
{
// 列出電話號碼為 0928-1234* 開頭的使用者
for (int pos = BinarySearch<string, ContactData>(phone_index, "0928-1234");
pos < BinarySearch<string, ContactData>(phone_index, "0928-1235");
pos++)
{
//phone_index.Values[pos].OutputData(Console.Out);
}
Console.WriteLine("搜尋 0928-1234* 資料花了: {0} ticks ({1} msec)", timer.ElapsedTicks, timer.ElapsedMilliseconds);
}
Console.WriteLine("共使用記憶體: {0}MB", Environment.WorkingSet / 1000000);
}
private static int BinarySearch<TKey, TValue>(SortedList<TKey, TValue> index, TKey key)
{
return BinarySearch<TKey, TValue>(index, key, 0, index.Count - 1);
}
private static int BinarySearch<TKey, TValue>(SortedList<TKey, TValue> index, TKey key, int start, int end)
{
if (start == end) return end;
int pos = (start + end) / 2;
int compareResult = index.Comparer.Compare(key, index.Keys[pos]);
if (compareResult == 0)
{
return pos;
}
else if (compareResult > 0)
{
return BinarySearch<TKey, TValue>(index, key, pos + 1, end);
}
else
{
return BinarySearch<TKey, TValue>(index, key, start, pos - 1);
}
}
執行結果:
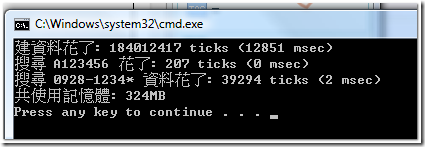
至於前面產品經理問的問題,各位就試著自己到 MSDN 找看看答案吧! 比較過之後,你就會瞭解為什麼我會挑選 SortedList .. 我只挑 SEARCH 時間來看,List 的搜尋是 O(n), 而 SortedList 的搜尋是排序過的資料作 BinarySearch, 找找書就知道是 O(log n), 分別來比較一下:
當 N 等於 1000000 時:
List: 3131861 ticks SortedList: 39294 ticks (快 80 倍)
推算一下,N 放大為 100 倍 (100000000) 時:
List: 3131861 x 100000000 / 1000000 = 313186100 ticks
SortedList: 39294 x log 100000000 / log 1000000 = 52392ticks (快 5978 倍)
看到了嗎? 換個 Collection 物件,對於 Search 這個動作,一百萬筆資料時差了 80 倍,當資料成長一百倍 (100000000 筆) 時,搜尋速度差異爆增為近 6000 倍! 這就是資料結構或是演算法的差異,這樣的差異已經大到其它地方最佳化怎麼作都補不回來的地步,唯一一個關鍵就是要用對演算法!
終於打完這篇了。沒想到前一篇寫一堆老生常談的話,這次又變成一堆 sample code 了。不過我的目的就是讓各位瞭解,基礎一定要顧好啊,不然寫程式是一定會碰到瓶頸的。這次從很簡單的需求,帶到資料結構的觀念,再帶到 MSDN 裡面特別標記的資訊…。看完後應該不會再有人說學校教的東西沒用了吧?
有網友問過我有沒有推薦什麼書? 很抱歉,我也只看過課本而以 … 哈哈,這些純粹是出來工作後,無意間還想到要去翻翻課本得來的經驗。其實這種例子很多,過去我常貼的 multi-thread 的文章也是很多這樣的例子,只不過課本從資料結構換成作業系統了,這個主題才寫到 1-2, 後面還有, 有什麼看法或心得就請留在回應給我吧! 如果能支持一下旁邊的讚助商的話也算是種鼓厲啦.. 敬請期待下一篇..
–
調查一下,有人看這篇之前就知道 SortedList 嗎? 留個話給我吧,我很好奇這種東西有多少人會去用… :D
